

Prediction and Classification of User Activities Using Machine Learning Models from Location-Based Social Network Data

Abstract
:1. Introduction
- How can we use machine learning to categorize LBSN data into specialized fields? And which machine-learning model best fits the LBSN data to predict a specific class of venues (tourism) for the study of a particular research domain.
2. Literature Review
3. Materials and Methods
- Data collection and preprocessing: The first step is to collect the data and prepare it for the analysis. This involves cleaning the data, removing any duplicates, and encoding categorical variables. The data used in this research can be acquired using Weibo API.
- Feature Selection and Data splitting: The data attributes used in this research are selected after verifying the variable significance using linear regression. The data are then split into training and testing sets. The training set is used to build the model, while the testing set is used to evaluate the performance of the model.
- Model Training: Several machine-learning models are used to classify the location categories, including generalized linear model, deep learning, logistic regression, and gradient-boosted trees. Each model is trained and evaluated on the training and testing sets.
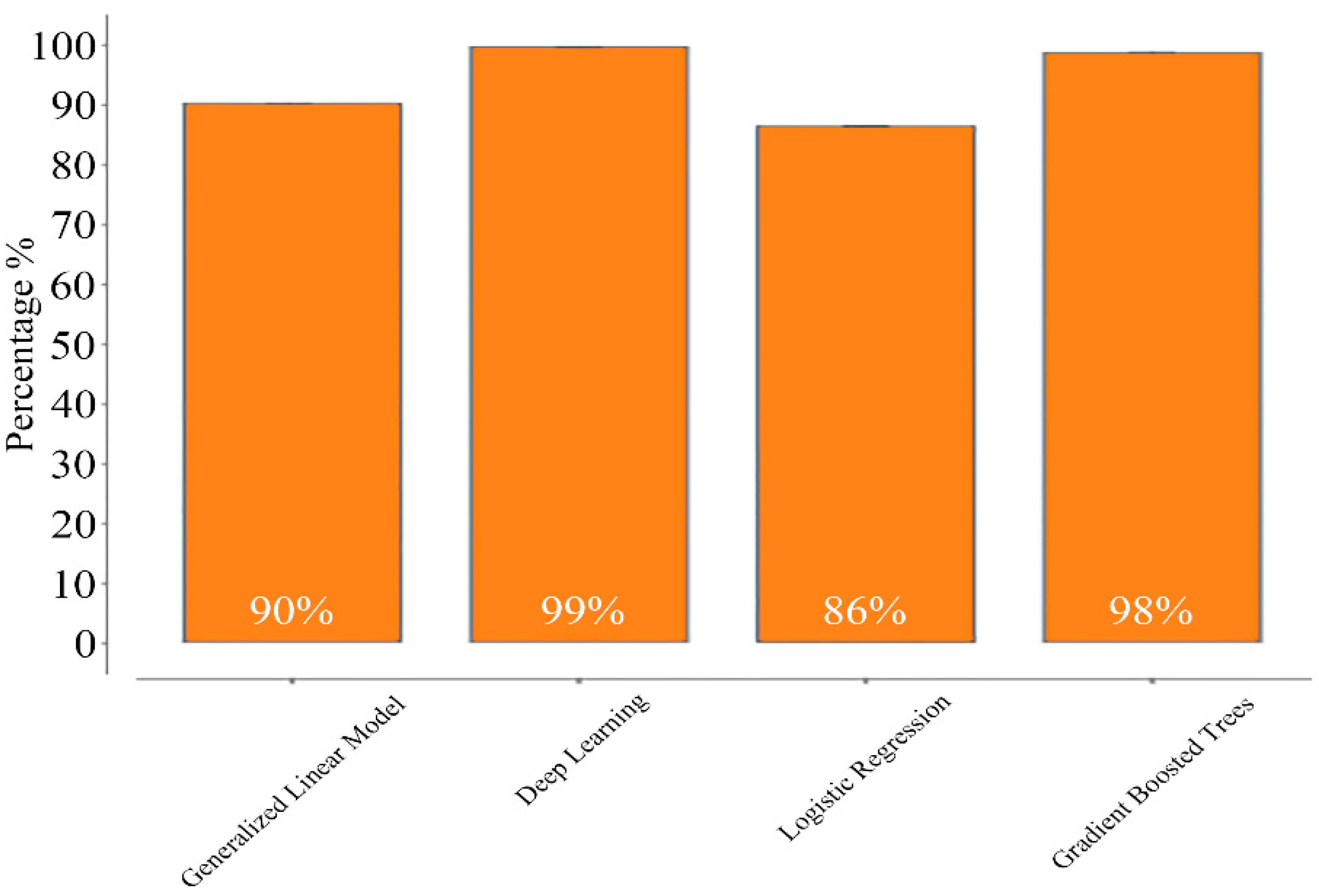
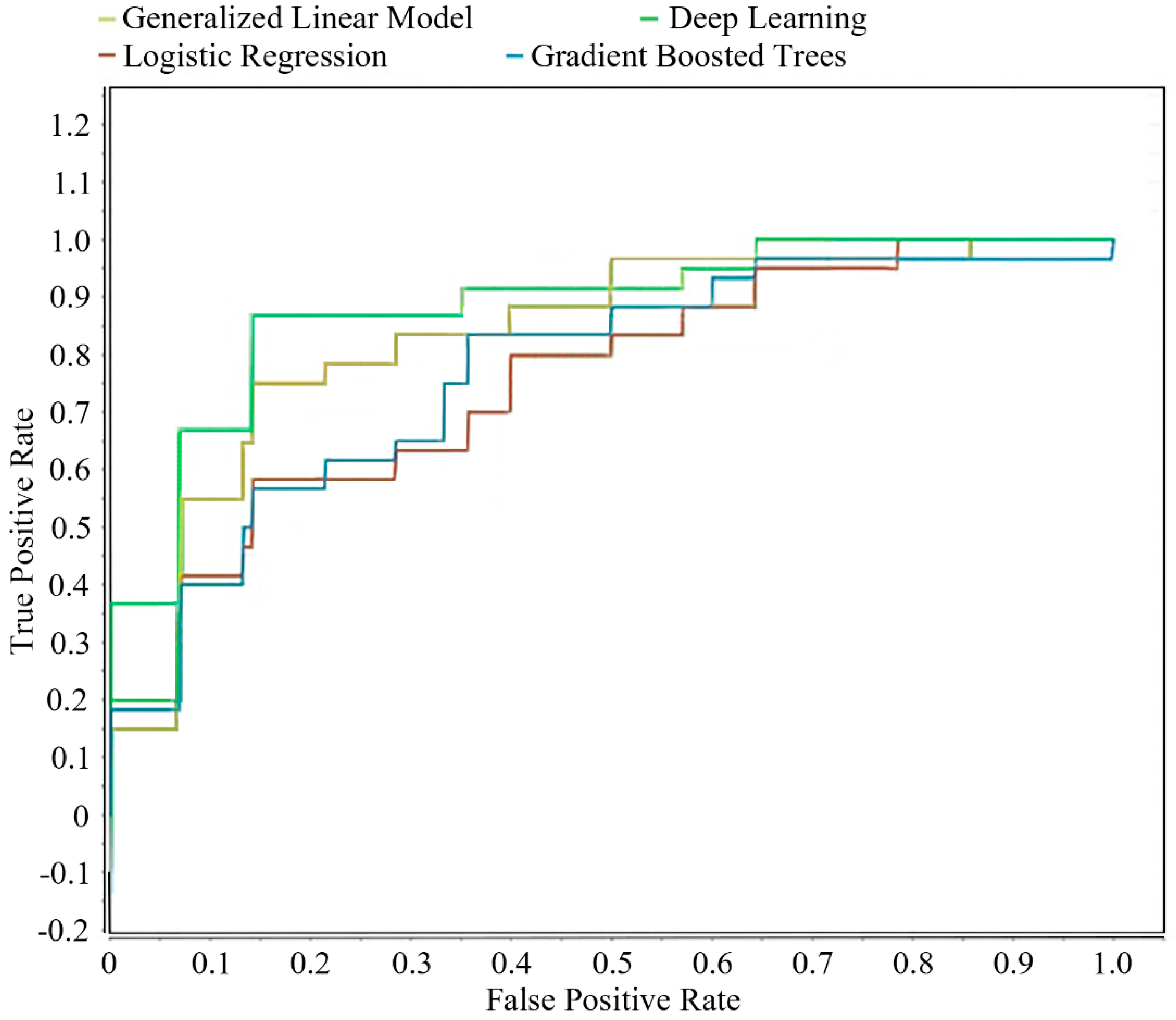
- Model evaluation: The performance of each model is evaluated using metrics such as accuracy, precision, recall, F1-score, ROC curve, AUC, confusion matrices, and lift chart.
- Model Comparisons: The best-performing model can be highlighted based on its overall performance and ability to accurately classify and predict the location categories.
3.1. Data Source
- User ID (unique for every user; however, available multiple times with subsequent check-ins).
- Gender of the user.
- Check-in day (day of the week including weekends/weekdays).
- Check-in time.
- Check-in location name (such as Shanghai University, Lingnan Park, etc.).
- Check-in category (used for training during the supervised learning).
3.2. Statistical Analysis
3.3. Model Evaluation
4. Results
4.1. Statistical Modelling
4.2. Classification into Multiple Venue Types
4.2.1. Generalized Linear Model
4.2.2. Deep Learning
4.2.3. Logistic Regression
4.2.4. Gradient-Boosted Trees
4.3. Binary Classification for Predicting Tourism Class
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wu, J.; Li, J.; Ma, Y. A comparative study of spatial and temporal preferences for waterfronts in Wuhan based on gender differences in check-in behavior. ISPRS Int. J. Geo-Inf. 2019, 8, 413. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.Y.; Chen, J.; Li, H. Linking migrant enclave residence to employment in urban China: The case of Shanghai. J. Urban Aff. 2019, 41, 189–205. [Google Scholar] [CrossRef] [Green Version]
- Muhammad, R.; Zhao, Y.; Liu, F. Spatiotemporal analysis to observe gender based check-in behavior by using social media big data: A case study of Guangzhou, China. Sustainability 2019, 11, 2822. [Google Scholar] [CrossRef] [Green Version]
- Ali Haidery, S.; Ullah, H.; Khan, N.U.; Fatima, K.; Rizvi, S.S.; Kwon, S.J. Role of big data in the development of smart city by analyzing the density of residents in Shanghai. Electronics 2020, 9, 837. [Google Scholar] [CrossRef]
- Khan, N.U.; Wan, W.; Yu, S. Location-based social network’s data analysis and spatio-temporal modeling for the mega city of Shanghai, China. ISPRS Int. J. Geo-Inf. 2020, 9, 76. [Google Scholar] [CrossRef] [Green Version]
- Rizwan, M.; Mahmood, S.; Wanggen, W.; Ali, S. Location based social media data analysis for observing check-in behavior and city rhythm in shanghai. In Proceedings of the 4th International Conference on Smart and Sustainable City (ICSSC 2017), Shanghai, China, 5–6 June 2017. [Google Scholar]
- Rizwan, M.; Wan, W. Big data analysis to observe check-in behavior using location-based social media data. Information 2018, 9, 257. [Google Scholar] [CrossRef] [Green Version]
- Singh, R.; Zhang, Y.; Wang, H. Exploring human mobility patterns in Melbourne using social media data. In Proceedings of the Databases Theory and Applications: 29th Australasian Database Conference, ADC 2018, Gold Coast, QLD, Australia, 24–27 May 2018; pp. 328–335. [Google Scholar]
- Khan, N.U.; Wan, W.; Yu, S.; Muzahid, A.; Khan, S.; Hou, L. A Study of User Activity Patterns and the Effect of Venue Types on City Dynamics Using Location-Based Social Network Data. ISPRS Int. J. Geo-Inf. 2020, 9, 733. [Google Scholar] [CrossRef]
- Loo, B.P.; Yao, S.; Wu, J. Spatial point analysis of road crashes in Shanghai: A GIS-based network kernel density method. In Proceedings of the 2011 19th International Conference on Geoinformatics, Shanghai, China, 24–26 June 2011; pp. 1–6. [Google Scholar]
- Colombo, G.B.; Chorley, M.J.; Williams, M.J.; Allen, S.M.; Whitaker, R.M. You are where you eat: Foursquare checkins as indicators of human mobility and behaviour. In Proceedings of the 2012 IEEE International Conference on Pervasive Computing and Communications Workshops, Lugano, Switzerland, 19–23 March 2012; pp. 217–222. [Google Scholar]
- Li, Y.; Steiner, M.; Wang, L.; Zhang, Z.-L.; Bao, J. Exploring venue popularity in foursquare. In Proceedings of the 2013 Proceedings IEEE INFOCOM, Turin, Italy, 14–19 April 2013; pp. 3357–3362. [Google Scholar]
- Hu, Q.; Bai, G.; Wang, S.; Ai, M. Extraction and monitoring approach of dynamic urban commercial area using check-in data from Weibo. Sustain. Cities Soc. 2019, 45, 508–521. [Google Scholar] [CrossRef]
- Vassakis, K.; Petrakis, E.; Kopanakis, I.; Makridis, J.; Mastorakis, G. Location-based social network data for tourism destinations. In Big Data and Innovation in Tourism, Travel, and Hospitality: Managerial Approaches, Techniques, and Applications; Springer: Berlin/Heidelberg, Germany, 2019; pp. 105–114. [Google Scholar]
- Maeda, T.N.; Yoshida, M.; Toriumi, F.; Ohashi, H. Extraction of tourist destinations and comparative analysis of preferences between foreign tourists and domestic tourists on the basis of geotagged social media data. ISPRS Int. J. Geo-Inf. 2018, 7, 99. [Google Scholar] [CrossRef] [Green Version]
- Gu, Z.; Zhang, Y.; Chen, Y.; Chang, X. Analysis of attraction features of tourism destinations in a mega-city based on check-in data mining—A case study of ShenZhen, China. ISPRS Int. J. Geo-Inf. 2016, 5, 210. [Google Scholar] [CrossRef] [Green Version]
- Hussain, M.; Zhu, W.; Zhang, W.; Abidi, S.M.R.; Ali, S. Using machine learning to predict student difficulties from learning session data. Artif. Intell. Rev. 2019, 52, 381–407. [Google Scholar] [CrossRef]
- Wang, Y.; Baker, R. Content or platform: Why do students complete MOOCs. MERLOT J. Online Learn. Teach. 2015, 11, 17–30. [Google Scholar]
- RapidMiner. RapidMiner Documentation. Available online: https://docs.rapidminer.com/latest/studio/operators/ (accessed on 1 March 2023).
- Chai, Y.; Shen, Y.; Xiao, Z.; Zhang, Y.; Zhao, Y.; Ta, N. Review for space-time behavior research: Theory frontiers and application in the future. Prog. Geogr. 2012, 31, 667–675. [Google Scholar]
- Kwan, M.-P.; Lee, J. Geovisualization of human activity patterns using 3D GIS: A time-geographic approach. Spat. Integr. Soc. Sci. 2004, 27, 721–744. [Google Scholar]
- Polak, J.; Jones, P. The acquisition of pre-trip information: A stated preference approach. Transportation 1993, 20, 179–198. [Google Scholar] [CrossRef]
- Che, Q.; Duan, X.; Guo, Y.; Wang, L.; Cao, Y. Urban spatial expansion process, pattern and mechanism in Yangtze River Delta. Acta Geogr. Sin 2011, 66, 446–456. [Google Scholar]
- Graham, M.; Shelton, T. Geography and the future of big data, big data and the future of geography. Dialogues Hum. Geogr. 2013, 3, 255–261. [Google Scholar] [CrossRef] [Green Version]
- Gonzalez, M.C.; Hidalgo, C.A.; Barabasi, A.-L. Understanding individual human mobility patterns. Nature 2008, 453, 779–782. [Google Scholar] [CrossRef]
- Todd, A.W.; Campbell, A.L.; Meyer, G.G.; Horner, R.H. The effects of a targeted intervention to reduce problem behaviors: Elementary school implementation of check in—Check out. J. Posit. Behav. Interv. 2008, 10, 46–55. [Google Scholar] [CrossRef]
- Hollenstein, L.; Purves, R. Exploring place through user-generated content: Using Flickr tags to describe city cores. J. Spat. Inf. Sci. 2010, 21–48. [Google Scholar] [CrossRef]
- Zhu, X. GIS and urban mining. Resources 2014, 3, 235–247. [Google Scholar] [CrossRef] [Green Version]
- Yuan, J.; Zheng, Y.; Xie, X. Discovering regions of different functions in a city using human mobility and POIs. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 186–194. [Google Scholar]
- Wesolowski, A.; Qureshi, T.; Boni, M.F.; Sundsøy, P.R.; Johansson, M.A.; Rasheed, S.B.; Engø-Monsen, K.; Buckee, C.O. Impact of human mobility on the emergence of dengue epidemics in Pakistan. Proc. Natl. Acad. Sci. USA 2015, 112, 11887–11892. [Google Scholar] [CrossRef] [Green Version]
- Pappalardo, L.; Simini, F.; Rinzivillo, S.; Pedreschi, D.; Giannotti, F.; Barabási, A.-L. Returners and explorers dichotomy in human mobility. Nat. Commun. 2015, 6, 1–8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Preoţiuc-Pietro, D.; Cohn, T. Mining user behaviours: A study of check-in patterns in location based social networks. In Proceedings of the 5th annual ACM Web Science Conference, Paris, France, 2–4 May 2013; pp. 306–315. [Google Scholar]
- Cheng, C.; Jain, R.; van den Berg, E. Location Prediction Algorithms for Mobile Wireless Systems. 2003. Available online: https://dl.acm.org/doi/10.5555/989684.989696 (accessed on 1 March 2023).
- Cho, E.; Myers, S.A.; Leskovec, J. Friendship and mobility: User movement in location-based social networks. In Proceedings of the 17th ACM SIGKDD International Conference on KNOWLEDGE Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 1082–1090. [Google Scholar]
- Gao, H.; Tang, J.; Liu, H. Exploring social-historical ties on location-based social networks. In Proceedings of the International AAAI Conference on Web and Social Media, Dublin, Ireland, 4–7 June 2012; pp. 114–121. [Google Scholar]
- Fan, C.; Liu, Y.; Huang, J.; Rong, Z.; Zhou, T. Correlation between social proximity and mobility similarity. Sci. Rep. 2017, 7, 1–8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, J.-D.; Chow, C.-Y. iGSLR: Personalized geo-social location recommendation: A kernel density estimation approach. In Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Orlando, FL, USA, 5–8 November 2013; pp. 334–343. [Google Scholar]
- Alrumayyan, N.; Bawazeer, S.; AlJurayyad, R.; Al-Razgan, M. Analyzing user behaviors: A study of tips in Foursquare. In Proceedings of the 5th International Symposium on Data Mining Applications, Riyadh, Saudi Arabia, 21–22 March 2018; pp. 153–168. [Google Scholar]
- Lin, S.; Xie, R.; Xie, Q.; Zhao, H.; Chen, Y. Understanding user activity patterns of the swarm app: A data-driven study. In Proceedings of the 2017 ACM International Joint Conference on Pervasive and Ubiquitous Computing and 2017 ACM International Symposium on Wearable Computers, Maui, HI, USA, 11–15 September 2017; pp. 125–128. [Google Scholar]
- Shi, B.; Zhao, J.; Chen, P.-J. Exploring urban tourism crowding in Shanghai via crowdsourcing geospatial data. Curr. Issues Tour. 2017, 20, 1186–1209. [Google Scholar] [CrossRef]
- Long, Y.; Han, H.; Tu, Y.; Shu, X. Evaluating the effectiveness of urban growth boundaries using human mobility and activity records. Cities 2015, 46, 76–84. [Google Scholar] [CrossRef]
- Alam, T.M.; Shaukat, K.; Khelifi, A.; Khan, W.A.; Raza, H.M.E.; Idrees, M.; Luo, S.; Hameed, I.A. Disease diagnosis system using IoT empowered with fuzzy inference system. Comput. Mater. Contin. 2022, 70, 5305–5319. [Google Scholar]
- Hassan, M.U.; Shaukat, K.; Niu, D.; Mahreen, S.; Ma, Y.; Zhao, X.; Shabir, M.A. Web-Logs Prediction with Web Mining. In Proceedings of the 2018 2nd IEEE Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Xi’an, China, 25–27 May 2018; pp. 1295–1299. [Google Scholar]
- Saleem, A.; He, Y. Investigation of Massive MIMO Channel Spatial Characteristics for Indoor Subway Tunnel Environment. In Proceedings of the 2021 Computing, Communications and IoT Applications (ComComAp), Shenzhen, China, 26–28 November 2021; pp. 162–167. [Google Scholar]
- Shaukat, K.; Alam, T.M.; Luo, S.; Shabbir, S.; Hameed, I.A.; Li, J.; Abbas, S.K.; Javed, U. A review of time-series anomaly detection techniques: A step to future perspectives. In Proceedings of the Future of Information and Communication Conference, Vancouver, BC, Canada, 29–30 April 2021; pp. 865–877. [Google Scholar]
- Khan, N.U.; Wan, W. A review of human pose estimation from single image. In Proceedings of the 2018 International Conference on Audio, Language and Image Processing (ICALIP), Shanghai, China, 16–17 July 2018; pp. 230–236. [Google Scholar]
- Ali, S.; Adeel, M.; Johar, S.; Zeeshan, M.; Baseer, S.; Irshad, A. Classification and Prediction of Software Incidents Using Machine Learning Techniques. Secur. Commun. Netw. 2021, 2021, 9609823. [Google Scholar] [CrossRef]
- Saleem, A.; Cui, H.; He, Y.; Boag, A. Channel Propagation Characteristics for Massive MIMO Systems in Tunnel Environment. IEEE Antennas Propag. Mag. 2022, 64, 126–142. [Google Scholar] [CrossRef]
- Abidi, S.M.R.; Hussain, M.; Xu, Y.; Zhang, W. Prediction of confusion attempting algebra homework in an intelligent tutoring system through machine learning techniques for educational sustainable development. Sustainability 2018, 11, 105. [Google Scholar] [CrossRef] [Green Version]
- Abidi, S.M.R.; Ni, J.; Ge, S.; Wang, X.; Ding, H.; Zhu, W.; Zhang, W. Demystifying help-seeking students interacting multimodal learning environment under machine learning regime. In Proceedings of the Eleventh International Conference on Graphics and Image Processing (ICGIP 2019), Hangzhou, China, 12–14 October 2019; p. 113732V. [Google Scholar]
- Abidi, S.M.R.; Xu, Y.; Ni, J.; Wang, X.; Zhang, W. Popularity prediction of movies: From statistical modeling to machine learning techniques. Multimed. Tools Appl. 2020, 79, 35583–35617. [Google Scholar] [CrossRef]
- Ng, V.K.; Cribbie, R.A. The gamma generalized linear model, log transformation, and the robust Yuen-Welch test for analyzing group means with skewed and heteroscedastic data. Commun. Stat. Simul. Comput. 2019, 48, 2269–2286. [Google Scholar] [CrossRef] [Green Version]
- Xing, W.; Du, D. Dropout prediction in MOOCs: Using deep learning for personalized intervention. J. Educ. Comput. Res. 2019, 57, 547–570. [Google Scholar] [CrossRef]
- Li, W.; Gao, M.; Li, H.; Xiong, Q.; Wen, J.; Wu, Z. Dropout prediction in MOOCs using behavior features and multi-view semi-supervised learning. In Proceedings of the 2016 international joint conference on neural networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; 2016; pp. 3130–3137. [Google Scholar]
- Peng, C.-Y.J.; Lee, K.L.; Ingersoll, G.M. An introduction to logistic regression analysis and reporting. J. Educ. Res. 2002, 96, 3–14. [Google Scholar] [CrossRef]
- Cobos, R.; Wilde, A.; Zaluska, E. Predicting attrition from massive open online courses in FutureLearn and edX. In Proceedings of the 7th International Learning Analytics and Knowledge Conference, Simon Fraser University, Vancouver, BC, Canada, 13–17 March 2017; pp. 13–17. [Google Scholar]
- Metz, C.E. Basic Principles of ROC Analysis. Available online: http://gim.unmc.edu/dxtests/ROC1.htm (accessed on 1 March 2023).
- Microsoft. Lift Chart (Analysis Services—Data Mining). Available online: https://learn.microsoft.com/en-us/analysis-services/data-mining/lift-chart-analysis-services-data-mining?view=asallproducts-allversions (accessed on 1 March 2023).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Coefficients | Estimate | Std. Error | t Value | Pr (>|t|) | |
|---|---|---|---|---|---|
| Intercept | 4.8321088 | 0.0158305 | 289.703 | <2 × 10−16 | *** |
| User_ID | 1.866674 | 0.177615 | 10.51 | <2−16 | *** |
| Gender | 0.612028 | 0.166562 | 3.674 | 0.000249 | *** |
| Time | 0.940388 | 0.126142 | 7.455 | 1.71 × 10−13 | ** |
| Day | 0.871949 | 0.22472 | 3.88 | 0.00011 | *** |
| Location_Name | 0.837961 | 0.202606 | 4.136 | 3.78 × 10−5 | *** |
| Educational | 0.0165532 | 0.0030441 | 6.382 | 5.69 × 10−8 | *** |
| Entertainment | 0.0055856 | 0.0019546 | 4.106 | 0.002245 | ** |
| Food | 0.0080145 | 0.0019644 | 4.191 | 0.001325 | ** |
| General_Location | 0.0153966 | 0.0020293 | 8.669 | 1.88 × 10−14 | *** |
| Hotel | 0.0015987 | 0.002076 | 3.814 | 0.004152 | ** |
| Professional | 0.0040008 | 0.0009275 | 3.938 | 0.003307 | ** |
| Residential | 0.0079851 | 0.0019825 | 4.717 | 0.000202 | *** |
| Shopping & Services | 0.015082 | 0.0030092 | 6.333 | 9.86 × 10−8 | *** |
| Sports | 0.0088736 | 0.0018375 | 4.71 | 2.50 × 10−6 | *** |
| Travel | 0.0090936 | 0.0019494 | 5.184 | 2.89 × 10−5 | *** |
| Time | Gender | Category | Check-In Date | Weekdays | |
|---|---|---|---|---|---|
| Time | 1 | −0.050 ** | −0.005 | −0.053 ** | 0.017 ** |
| Gender | −0.050 ** | 1 | 0.015 ** | −0.017 ** | −0.012 ** |
| Category | −0.005 | 0.015 ** | 1 | −0.039 ** | −0.013 ** |
| Check-in Date | −0.053 ** | −0.017 ** | −0.039 ** | 1 | −0.037 ** |
| Weekdays | 0.017 ** | −0.012 ** | −0.013 ** | −0.037 ** | 1 |
| True | Travel | Residential | Professional | Educational | Shopping & Services | Food | General Location | Entertainment | Sports | Hotel | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Predicted | |||||||||||
| Travel | 4378 | 22 | 9 | 13 | 12 | 6 | 3 | 14 | 0 | 11 | |
| Residential | 99 | 7764 | 133 | 137 | 51 | 19 | 14 | 93 | 32 | 66 | |
| Professional | 5 | 17 | 2685 | 12 | 5 | 4 | 6 | 41 | 1 | 8 | |
| Educational | 28 | 52 | 15 | 7288 | 60 | 15 | 5 | 56 | 47 | 32 | |
| Shopping & Services | 27 | 38 | 19 | 55 | 8883 | 37 | 6 | 173 | 11 | 15 | |
| Food | 391 | 186 | 248 | 378 | 481 | 2100 | 106 | 865 | 134 | 153 | |
| General | 77 | 139 | 44 | 62 | 104 | 29 | 2281 | 199 | 49 | 35 | |
| Location | |||||||||||
| Entertainment | 25 | 22 | 108 | 42 | 64 | 58 | 45 | 14,288 | 98 | 30 | |
| Sports | 8 | 6 | 11 | 30 | 3 | 13 | 8 | 151 | 3829 | 0 | |
| Hotel | 52 | 13 | 13 | 21 | 21 | 3 | 4 | 30 | 13 | 2514 | |
 | |||||||||||
| True | Travel | Residential | Professional | Educational | Shopping & Services | Food | General Location | Entertainment | Sports | Hotel | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Predicted | |||||||||||
| Travel | 5008 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Residential | 0 | 8124 | 4 | 0 | 0 | 1 | 4 | 0 | 0 | 0 | |
| Professional | 0 | 0 | 3231 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | |
| Educational | 2 | 3 | 0 | 8041 | 0 | 0 | 1 | 0 | 0 | 0 | |
| Shopping & Services | 0 | 3 | 1 | 0 | 9695 | 2 | 2 | 0 | 0 | 0 | |
| Food | 4 | 6 | 1 | 0 | 0 | 2255 | 1 | 0 | 0 | 0 | |
| General Location | 3 | 7 | 4 | 0 | 0 | 1 | 2427 | 0 | 0 | 0 | |
| Entertainment | 75 | 120 | 45 | 0 | 0 | 31 | 46 | 15,931 | 0 | 0 | |
| Sports | 0 | 1 | 2 | 0 | 0 | 0 | 0 | 0 | 4222 | 0 | |
| Hotel | 1 | 0 | 2 | 0 | 0 | 0 | 2 | 0 | 0 | 2862 | |
| |||||||||||
| True | Travel | Residential | Professional | Educational | Shopping & Services | Food | General Location | Entertainment | Sports | Hotel | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Predicted | |||||||||||
| Travel | 4814 | 5 | 0 | 1 | 2 | 4 | 0 | 1 | 0 | 9 | |
| Residential | 1 | 8080 | 0 | 22 | 0 | 21 | 7 | 0 | 22 | 38 | |
| Professional | 2 | 79 | 1954 | 7 | 0 | 9 | 8 | 1 | 0 | 11 | |
| Educational | 1 | 0 | 34 | 6981 | 0 | 32 | 3 | 0 | 1 | 2 | |
| Shopping & Services | 171 | 3 | 3 | 11 | 9682 | 2 | 0 | 2 | 5 | 1 | |
| Food | 0 | 0 | 4 | 3 | 0 | 650 | 1 | 0 | 3 | 0 | |
| General Location | 4 | 94 | 22 | 0 | 0 | 43 | 1753 | 0 | 62 | 9 | |
| Entertainment | 104 | 13 | 1232 | 947 | 10 | 1539 | 704 | 15,928 | 1297 | 848 | |
| Sports | 2 | 0 | 12 | 7 | 0 | 6 | 1 | 0 | 2717 | 3 | |
| Hotel | 0 | 0 | 2 | 9 | 0 | 4 | 1 | 0 | 2 | 1916 | |
| |||||||||||
| True | Travel | Residential | Professional | Educational | Shopping & Services | Food | General Location | Entertainment | Sports | Hotel | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Predicted | |||||||||||
| Travel | 1432 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Residential | 0 | 2310 | 1 | 0 | 0 | 1 | 0 | 2 | 0 | 0 | |
| Professional | 0 | 0 | 876 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Educational | 0 | 0 | 0 | 2245 | 0 | 9 | 0 | 1 | 10 | 0 | |
| Shopping & Services | 0 | 0 | 2 | 0 | 2725 | 3 | 0 | 1 | 0 | 0 | |
| Food | 0 | 0 | 0 | 0 | 0 | 501 | 0 | 0 | 0 | 0 | |
| General Location | 0 | 9 | 2 | 0 | 0 | 12 | 696 | 7 | 0 | 0 | |
| Entertainment | 0 | 0 | 40 | 9 | 0 | 116 | 0 | 4422 | 0 | 0 | |
| Sports | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 41 | 1174 | 0 | |
| Hotel | 0 | 0 | 1 | 0 | 0 | 2 | 0 | 0 | 0 | 807 | |
| |||||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, N.U.; Wan, W.; Riaz, R.; Jiang, S.; Wang, X. Prediction and Classification of User Activities Using Machine Learning Models from Location-Based Social Network Data. Appl. Sci. 2023, 13, 3517. https://doi.org/10.3390/app13063517
Khan NU, Wan W, Riaz R, Jiang S, Wang X. Prediction and Classification of User Activities Using Machine Learning Models from Location-Based Social Network Data. Applied Sciences. 2023; 13(6):3517. https://doi.org/10.3390/app13063517
Chicago/Turabian StyleKhan, Naimat Ullah, Wanggen Wan, Rabia Riaz, Shuitao Jiang, and Xuzhi Wang. 2023. "Prediction and Classification of User Activities Using Machine Learning Models from Location-Based Social Network Data" Applied Sciences 13, no. 6: 3517. https://doi.org/10.3390/app13063517