1. Introduction
Massive Open Online Courses (MOOCs) are now an option for students from all over the world who seek to learn at their own pace and with flexible deadlines from a wide range of courses and programs [
1]. Since they can scale seamlessly to hundreds or thousands of students [
2] and are commonly free for people who have no intention of getting a certificate, interest in these courses continues to grow [
3]. Despite this, MOOCs face significant challenges, such as high attrition, low enrollment of users from developing countries, and poor completion rates [
1]. Although these problems have afflicted MOOCs since their inception, interest in understanding student behavior through research on phenomena such as dropout, motivation, and self-regulated learning has increased in recent years [
3]. This has led to the study of more specific behaviors, such as actions [
4], strategies [
5], tactics [
6], sessions [
2] and, temporal dynamics [
7]. In particular, the study of learning dynamics within a session, that is, during a period of uninterrupted work, is receiving increasing attention [
2,
8].
The field of
Process Mining [
9,
10,
11] has been viewed as a promising tool for answering research questions in educational settings due to its ease of use for users who are not necessarily experts in data mining or process science [
5,
12]. Process mining algorithms are able to automatically discover (or mine) a model representing the dynamic behavior of end-to-end processes based directly on event data. In the literature, a common approach is to use columns directly from a database table as activities (i.e., steps of the process) for process mining algorithms, such as the accessed MOOC resource [
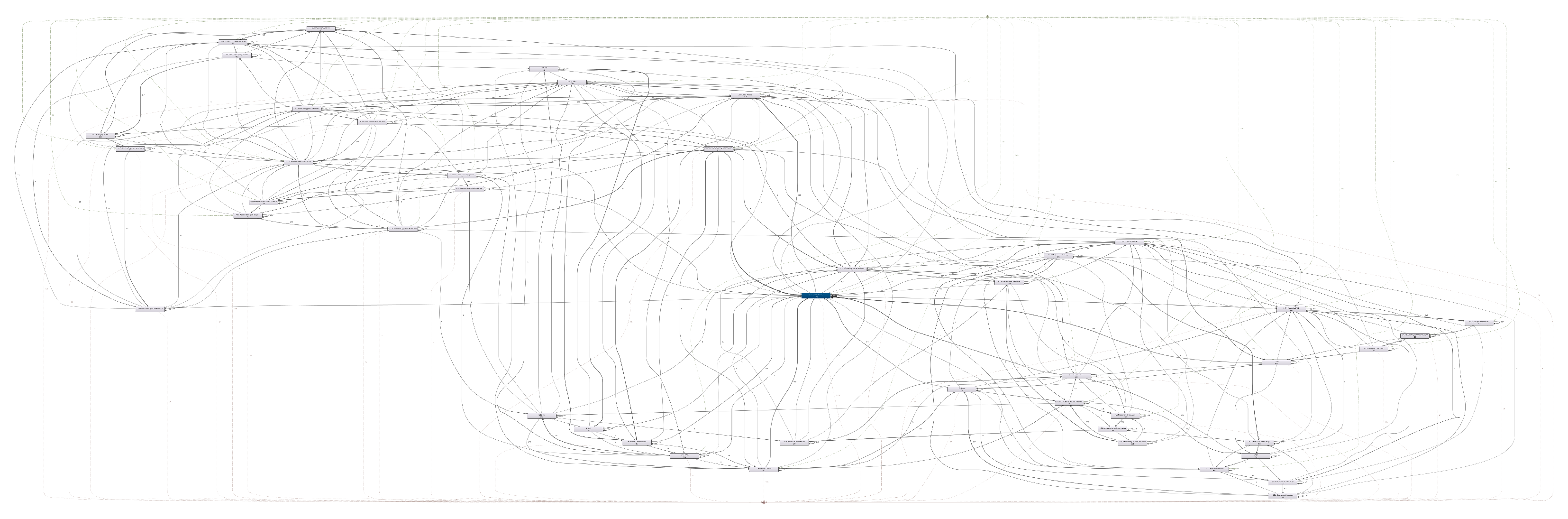
12]. Due to the freedom students have to navigate through the resources, they often generate “spaghetti models", as shown in
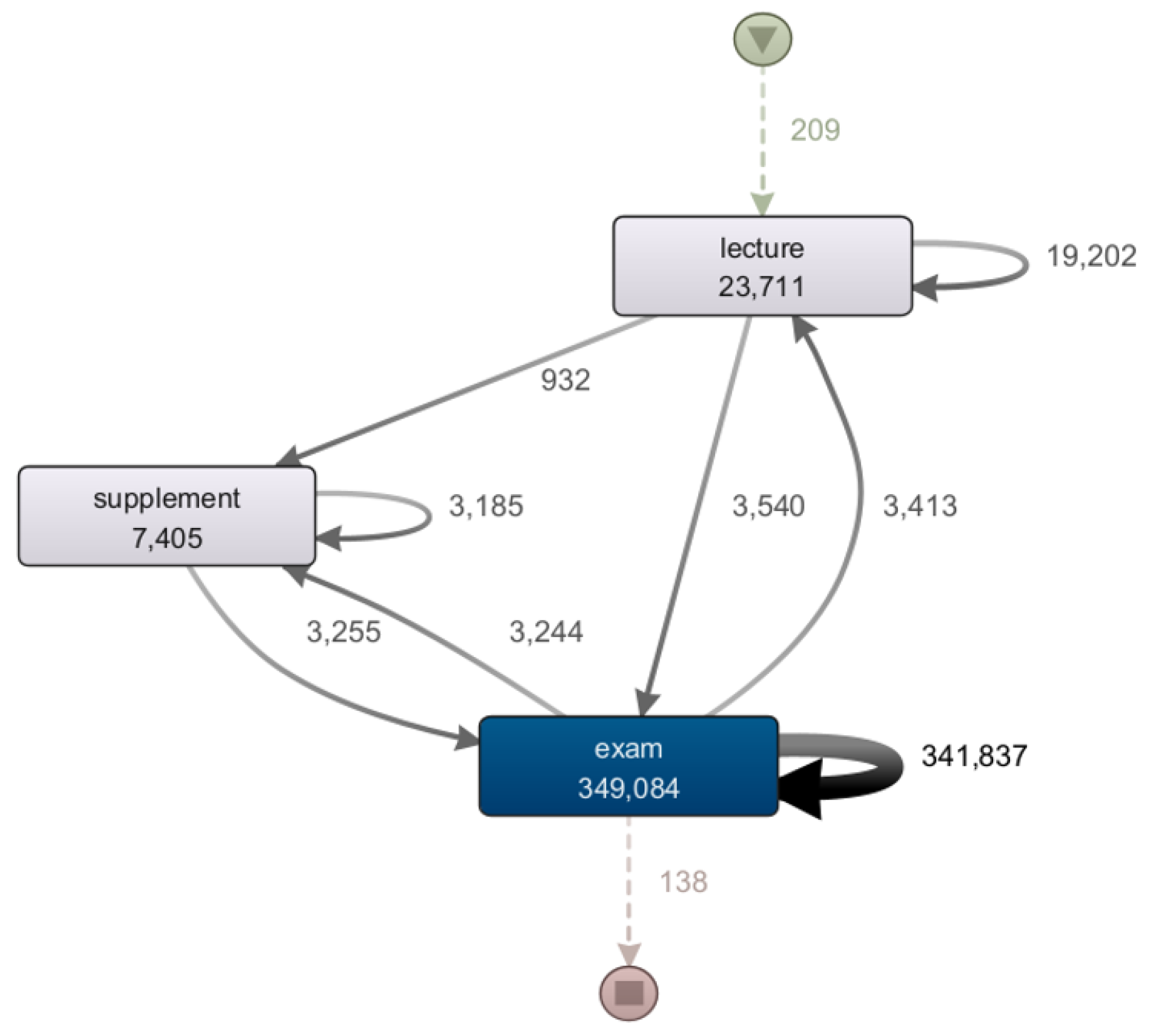
Figure 1. To overcome these scenarios, most authors end up tinkering with process discovery tools, applying filters to routes and activities, or altering activity and case ID until they obtain a readable, albeit incomplete, model, as depicted in
Figure 2. This narrows the scope of questions that can be answered using these techniques.
This raw, unfiltered data does not fit more complex questions, so we need techniques that allow us to group low-level events into high-level activities, i.e., event abstractions. There are numerous event abstraction methods described in process mining literature (for a review, see [
13]). Most event abstraction approaches are data-driven (bottom-up), that is, they use domain-agnostic or unsupervised methods to detect frequent patterns in data. However, in some circumstances, high-level activities have already been specified in a domain-driven (top-down) manner, and the objective is to find those activities in the data. Such approaches are not appropriate in these cases. For example, the same behavior of accessing a MOOC resource may indicate if a learner is studying from it or just scanning it to understand what will come next in a lesson. Finally, constructing an event abstraction might be a difficult task for educational decision-makers who are not specialists in process mining. This is due to the fact that it requires a complete understanding of concepts such as case ID, activity ID, and event ID. As a result, easy-to-follow recipes must be defined in order to apply process mining in interdisciplinary contexts such as education.
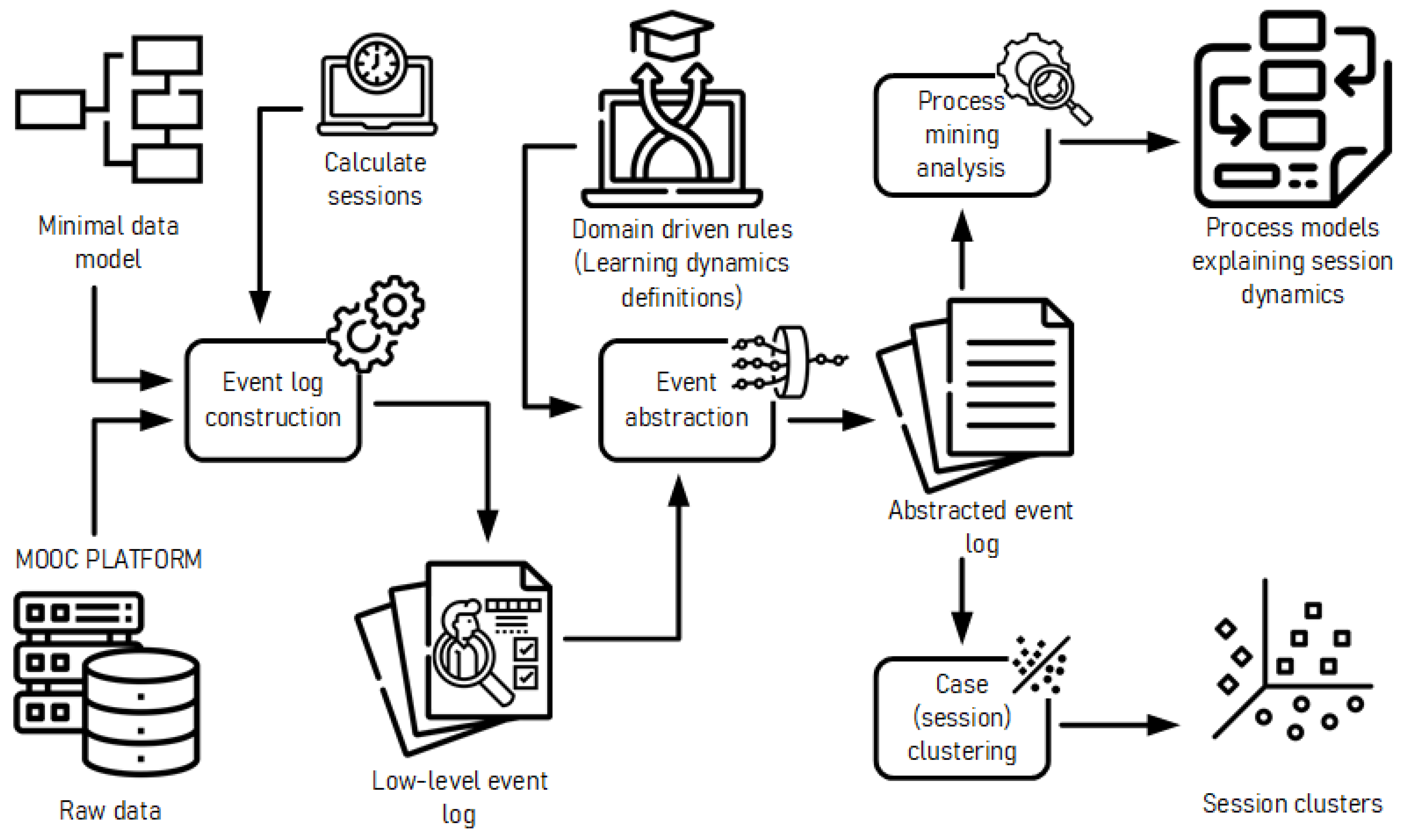
We propose a domain-driven event abstraction framework to analyze learning dynamics in MOOC sessions, involving three steps: (1) a minimal data model that can be adapted to most MOOC systems; (2) the definition of a low-level event log, including the definition of case ID and user sessions; and (3) the definition of seven high-level activities, our learning dynamics, and its corresponding high-level event log. The framework maps all low-level events to the seven learning dynamics discussed here, making it straightforward enough for educational managers to replicate. After which, this event log can be analyzed using traditional process mining methods or machine learning approaches to gain insights into the dynamics of students in MOOC sessions. Furthermore, the framework is adaptable enough to be used for courses that include other types of content, such as summaries or
cheat sheets, self-reflection activities, formative assessments, projects, and forums. We validate and demonstrate the framework’s use with a case study of sessions from students who successfully completed an introductory programming course on the Coursera platform (
Figure 3). To that end, we propose three research questions on how students interact throughout Coursera course sessions:
RQ1: What are the characteristics of the sessions that involve learning dynamics in which a resource is revisited?
RQ2: Are there differences in terms of learning dynamics between the first and final sessions carried out by students?
RQ3: What types of MOOC sessions do successful students go through and how do they differ from each other?
Although these are the questions we employed for the case study, our framework is flexible enough to handle different ones as long as they fit within the context of study sessions.
This research builds on a preliminary workshop paper published in [
14]. In particular, among the additions, we highlight (1) a comparison of the proposed learning dynamics with what is known from research, (2) an expanded explanation of the framework, (3) an analysis of the abstracted study sessions applying clustering, and (4) an extended discussion based on the most recent works published on the subject.
The remainder of the paper is organized as follows:
Section 2 discusses related works in process mining in education as well as event abstraction.
Section 3 presents the framework’s stages and the proposed learning dynamics for constructing an abstracted high-level event log.
Section 4 outlines the clustering process that was used to analyze the sessions that resulted from the case study application.
Section 5 describes the case study that was used to demonstrate the framework’s application and evaluate the results obtained from it. The dataset used and the process of applying the framework are detailed here, as well as an analysis of the research questions and their corresponding outcomes and a discussion of what was achieved. Finally, in
Section 6, we summarize our results and limitations, as well as future research directions in the topic.
4. Learning Session Classification
We use cluster analysis with the K-means clustering method [
35] and an Euclidean distance metric to distinguish differences between sessions and identify defining characteristics. The number of times each of the seven high-level learning dynamics appears is used as input for each session. Euclidean distance was selected in order to leverage existing tools and avoid implementation errors. Although studies have shown that distance metrics such as Manhattan [
36] and Canberra [
37] produce better results, determining which metric is superior in a dataset of this type is beyond the scope of this work.
To determine the number of clusters, we employ two k-means techniques: the elbow method and the silhouette method [
38]. Following that, we calculate the z-scores of each of the clusters in every dimension to visualize their differences.
The metrics that were left out of the clustering method, such as the duration of each session and the quintile in which they are placed, as well as the z-score values obtained, are used to characterize the traits that set the discovered clusters apart. It is significant to note that because this study focuses on MOOC sessions rather than students, factors that describe the user who completes a session are not included in the clustering method. Nevertheless, unusual session patterns are excluded from the process. We specifically aim to rule out patterns that represent a user’s unique behavior that is not reflected in any other instances.
5. Case Study: Successful Student Sessions in Coursera
A case study was conducted utilizing data from the Coursera platform’s “Introduction to Programming in Python” course to demonstrate the framework’s application and confirm its applicability with real data. The case study’s goal was to investigate the learning dynamics that occurred in the sessions of students who successfully completed the course. We aim to address three research questions, which were first presented in
Section 1.
Based on this, the following sections are presented: first, a description of the course and the application of the three levels of the framework related to the case study; second, the results obtained for the proposed research questions; and third, a discussion of the implications of these results and how they compare to other research on the subject.
5.1. Case Study & Framework
This study takes into account data gathered from a Coursera course held between 23 June 2017 and 14 April 2018. The course required a total of 17 h of time commitment and was divided into 6 modules, one for each week. In this research, 58 potential resources for interaction were considered, including 35 video lectures and 23 assessments. The decision to use this course for the case study was made for two reasons: first, ethics clearance had already been obtained on the data, as this is a secondary analysis of data previously used, and second, it was thought necessary to use pre-COVID-19 data so that it was not skewed by changes in MOOC use as a result of the pandemic.
15,420 people interacted with the platform during the observation period, of which 13,861 started the course during this time frame; we only keep the data of those who finished the course. Data was utilized in compliance with Coursera’s Terms and Conditions of use for research in learning analytics and additional ethics clearance was provided by Pontificia Universidad Católica de Chile. Prior to being provided to the researchers, the data was anonymized, so it was impossible to individualize particular users.
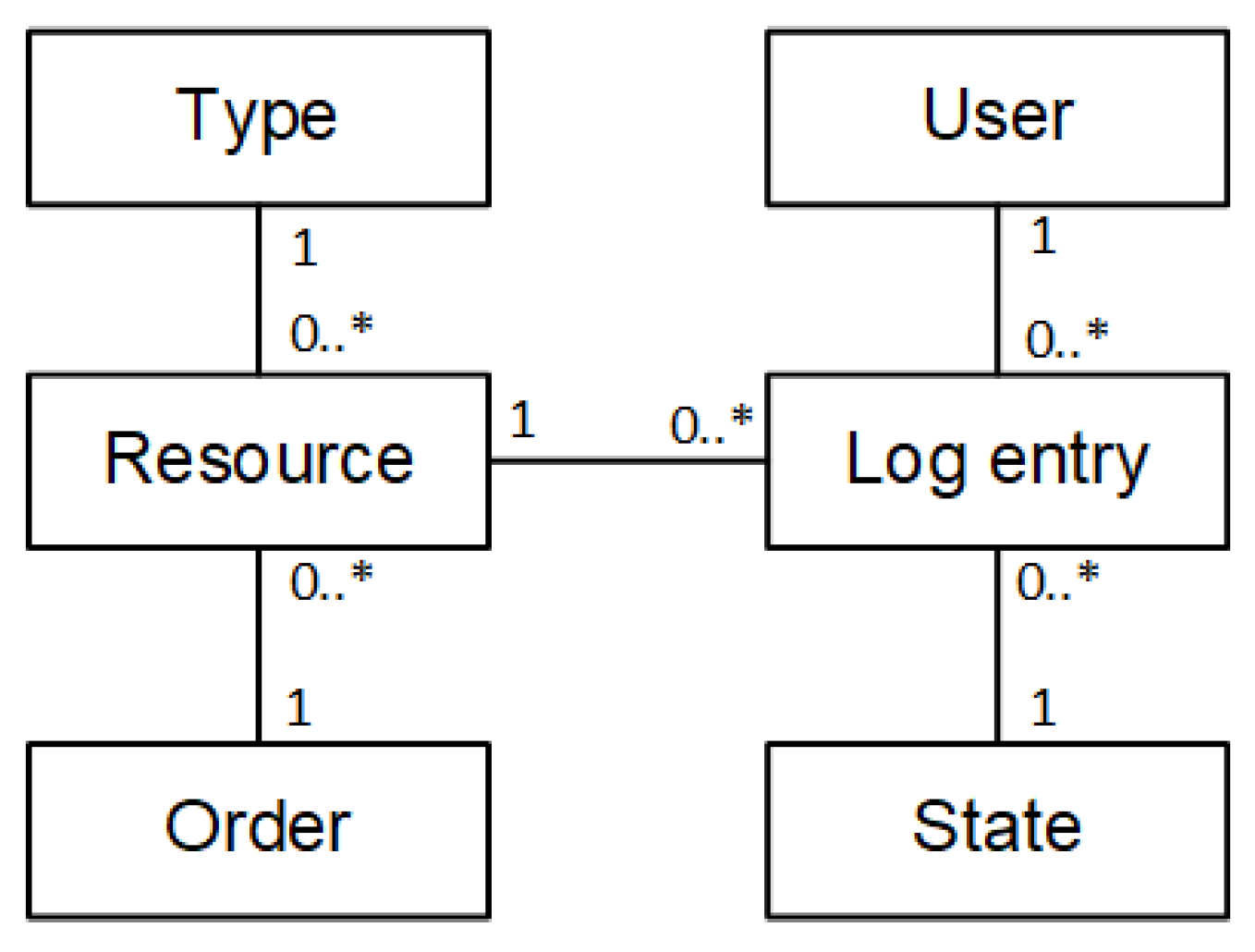
The initial step in implementing the framework was to match Coursera’s simple data model with the minimum data model proposed here. The Coursera data model had almost 75 tables. The Course Progress table was the most significant for this study since it tracked the course ID, the resource interacted with, the user who performed the interaction, the state (start/complete), and the date specifying when it occurred. However, because this table only contained IDs, it needed to be supplemented with the course information tables (Course Item Types, Course Items, Course Lessons, Course Modules, and Course Progress State Types) in order to establish the order of the resources within the course and obtain contextual information about each resource.
Table 3 shows the details of the fields in each of the tables used for the framework’s application.
The second step to apply the framework was to build the low-level event log, including the concept of session ID. To achieve so, an action was regarded to occur in the same session as the previous activity if there was a lapse equal to or less that 60 min between them. This was determined using [
30] maximum value of time-on-task. As a result, the case ID for the low-level event log was assigned as the pair (user ID, session ID). Our study only considered users who started and completed the course during the observation period. The completion of one of the two end-of-course tests determines if a user has finished the course. This results in a total of 320,421 low-level events. Furthermore, Coursera records progress through each question within an assessment as if it were a new event; for example, a student finishing an evaluation with 10 questions results in 11 events started and 1 completed. This duplication was later reduced, yielding a low-level event log of 39,650 events, 209 users for study, and a total of 7087 sessions.
Each event at this stage is made up of seven attributes, as exemplified in
Table 1: the user performing the event, the resource viewed, the timestamp of when this interaction occurs, the order of the resource in the progression (which is used to determine if the progression is sequential or chaotic), the type of the resource (to determine if it is a lecture or assessment), the state of the interaction (started or completed), and the session identifier to determine in which session this interaction occurs.
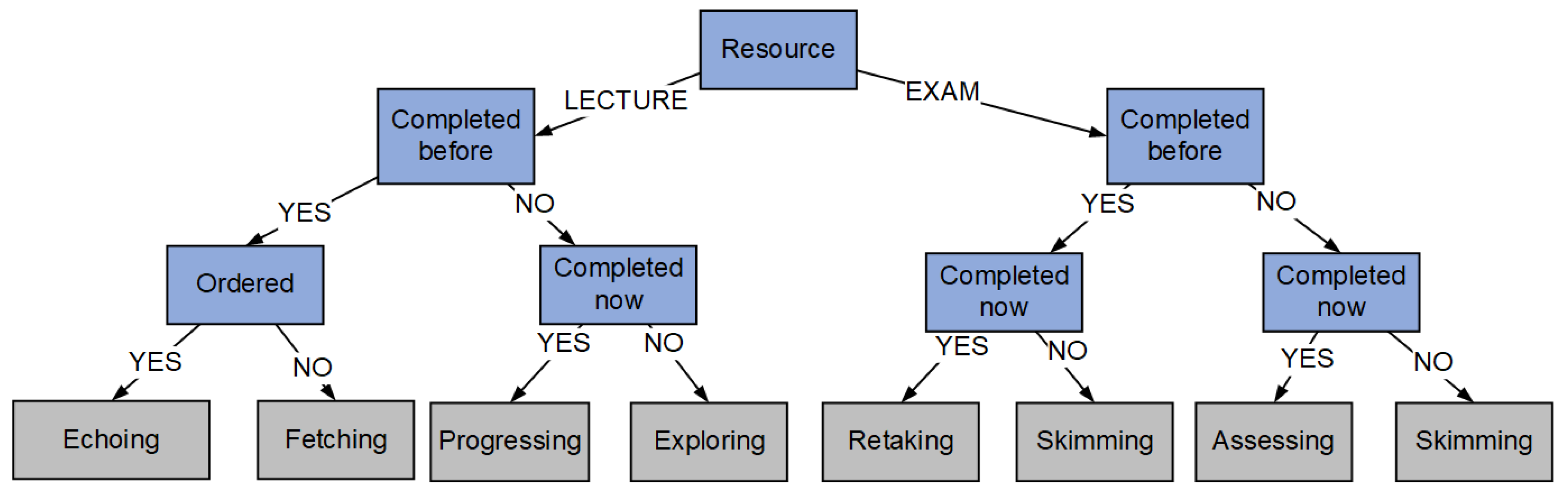
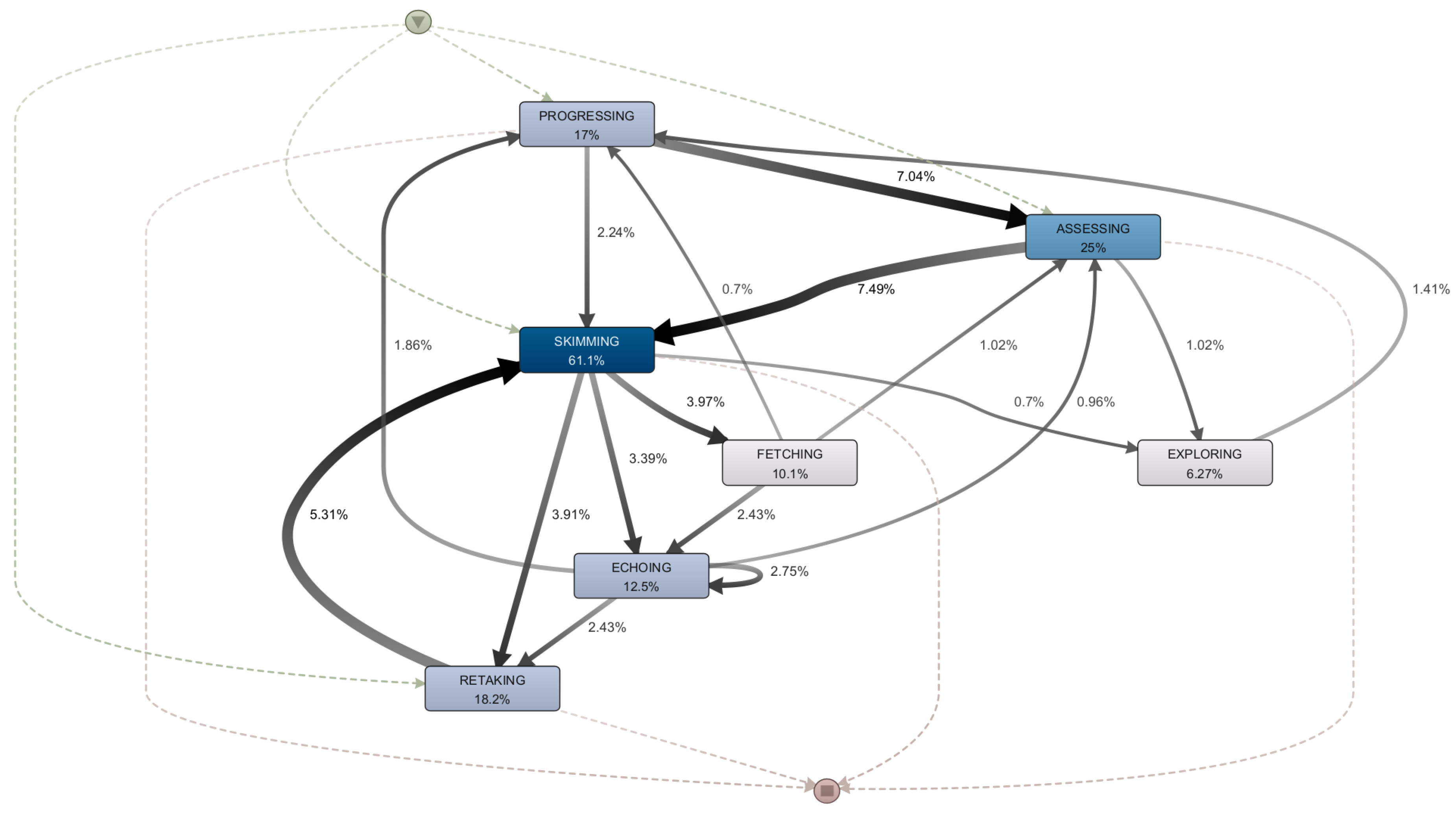
As a final step in applying the framework, we build the high-level event log by consolidating sequences of events into each of the seven high-level learning dynamics, using the criteria depicted in
Figure 5. The resulting event log contained 18,029 events. When compared to the low-level log, this showed a 54.5% reduction in activities. The case ID for the high-level event log was established in the same way as it was for the low-level log (user ID, session ID). From the 7087 sessions and 209 users this yielded 1237 process variants. It should be noted that the five most common cases were associated with single activity sessions and accounted for 51.3% of all cases, with Skimming accounting for 26.7% of all cases.
5.2. RQ1: What Are the Characteristics of the Sessions That Involve Learning Dynamics in Which a Resource Is Revisited?
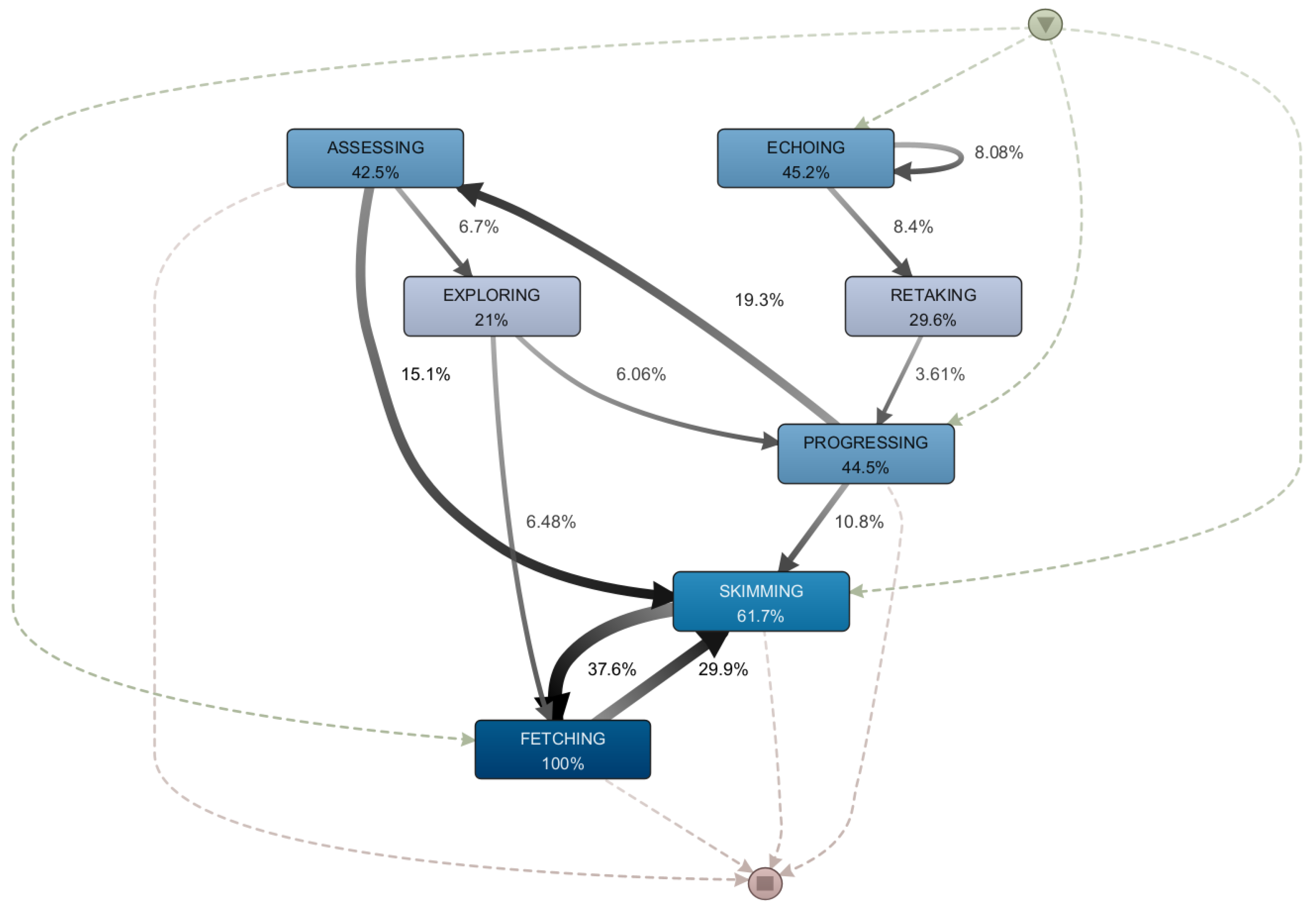
Our study discovered variations in learning dynamics when a resource is revisited, namely Echoing, Fetching, and Retaking. An exploratory analysis of the sessions using the Disco software revealed that Fetching appears in 13% of the cases, and that this activity appears to be significantly tied to the dynamics associated with assessment (i.e., Assessing, Skimming, Retaking); In 54.3% of cases when this action appears, it is preceded by one of the assessment-related activities; and in 50.9% of cases, Fetching is followed by some type of assessment.
Figure 6 depicts the process map of the fetching-related sessions. In this scenario, the Fetching of a content implies a specific search-related activity, either in preparation for an assessment or in reaction to a specific element that surfaced in an assessment and about which a specific doubt should be clarified. However, when the sessions included an Assessing or Retaking activity in addition to Fetching, the proportion shifted, with 25.6% executing the Fetching dynamic prior to the evaluation and 21.5% afterwards.
An examination of the material associated with Fetching revealed that the most frequently fetched resources were 2.2.2 Input, 3.1.1 If/Else, 3.2.2 For, 2.1.1. Data Types (which makes sense because they are the basic building blocks required to create programs), and 6.1.4 List Functions.
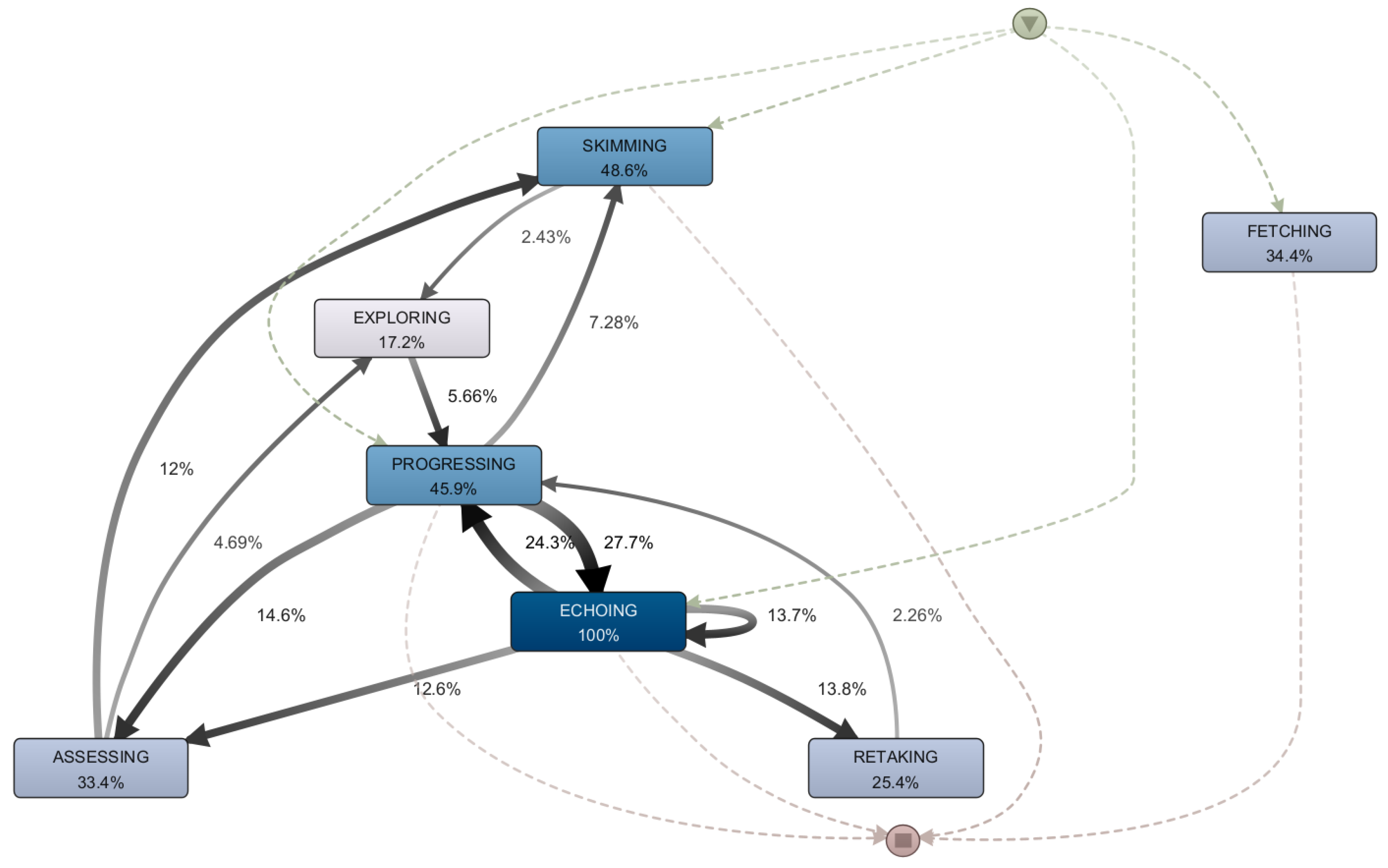
In sessions where the Echoing dynamic appears, students’ behavior shifts. As illustrated in
Figure 7, in most cases, this activity is related to Progressing, to the point that it is the activity that precedes or follows Echoing in 35.9% of the cases. This demonstrates that the student was oriented towards learning, and that questions developed during these study sessions, necessitating an in-depth examination of previously studied subjects. This is in stark contrast to Fetching sessions, which appear to be more directly tied to evaluative activities. In addition, there was also a link with the assessment dynamics in Echoing sessions. However, they differed in the order in which they appeared. This is because content repetition happened more frequently before the assessment as compared to the versions that contained Fetching. In contrast, content review took place more frequently after the assessment dynamic occurred. Later, when reviewing the material related to Echoing, the contents of the second (Basic Python) and fifth weeks (Strings) were the most frequently repeated.
Finally,
Figure 8 depicts the behavior of the Retaking dynamic; in this case, it can be assumed that the user performs a session solely for the purpose of repeating assessments. This is due to the most common variant (25.9% of cases) involves repeating assessments and then immediately concluding the session. Similarly, the activity most closely associated with Retaking is Skimming, which denotes a dynamic in which students perform an assessment and then examine their results or consult their prior errors in order to improve their scores before a new attempt. Retaking to Skimming occurred in 33.6% of cases where this learning dynamic was present, while the reverse happened in 32.1% of cases. This means that one (or both) of these interactions occurred in 43.0% of cases with Retaking. When the most frequently repeated retaking-related evaluations were reviewed, one assessment in particular was shown to have a much higher number of Retaking activities than the rest (597 times out of a mean of 285). This assessment, which covered variables and input/output, contained a bug in one of the questions. The bug was later fixed after the observation date was recorded in the log.
5.3. RQ2: Are There Differences in Terms of Learning Dynamics between the First and Final Sessions Carried out by Students?
Although analyzing the activities performed in a session is useful, it is also necessary to determine whether there are differences in the sessions of the students as they progress through the course. To do so, we grouped each session into quintiles based on the total number of sessions each student completed. As a result, the first and last quintiles were compared. This allowed us to confirm the existence of behavioral variations at the start and end of the course.
Table 4 shows several statistics that characterize each quintile.
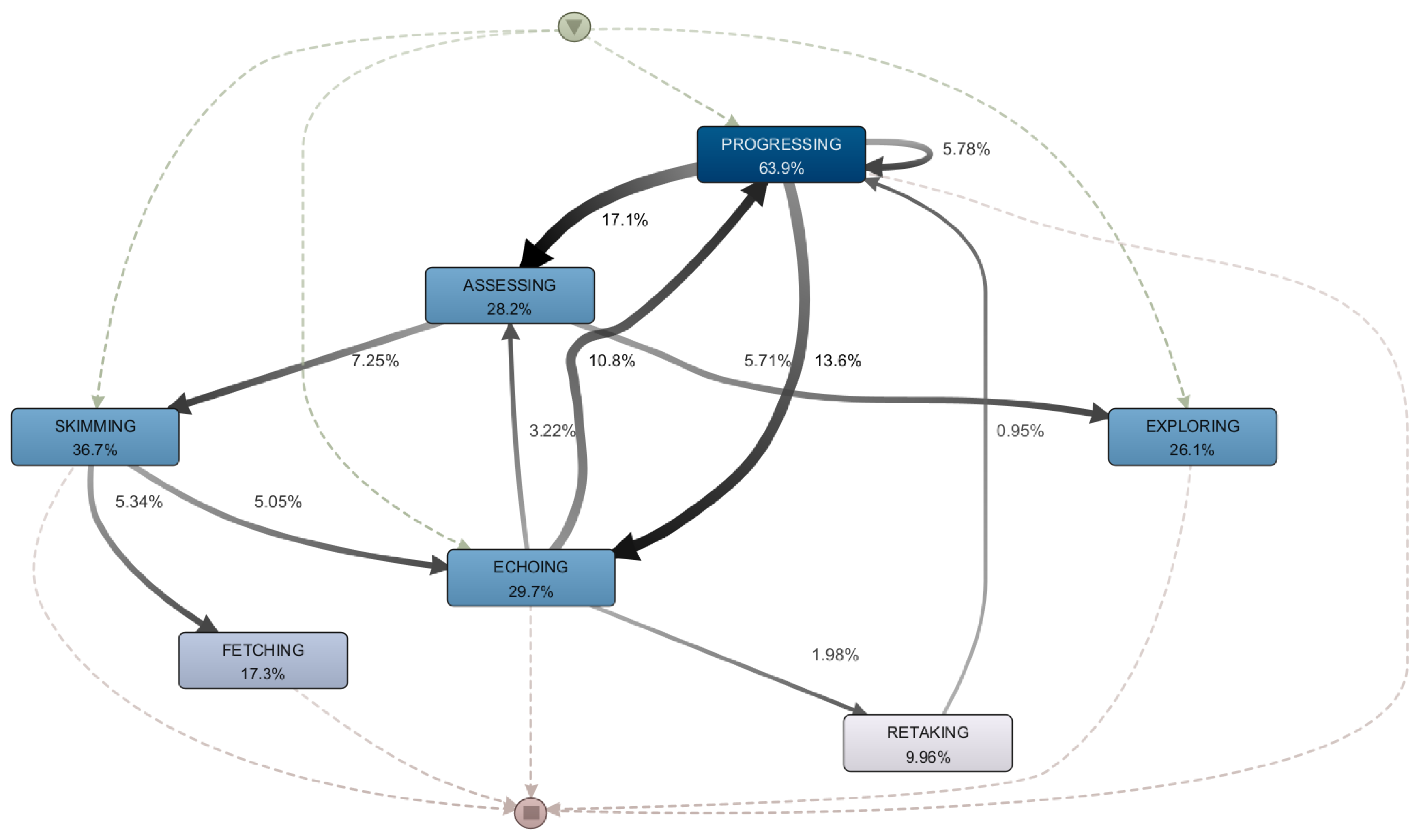
The process model of the initial sessions is depicted in
Figure 9, from which it can be determined that the most prevalent activities are related to the dynamics of orderly and thorough learning (Progressing 63.9% and Echoing 29.7%). Furthermore, a rather low commitment to assessment can be detected at this stage in the course, as students were seen undertaking sessions without completing an assessment in 66.3% of cases, despite the Skimming activity appearing in 36.7% of cases. This notion is reinforced by the fact that the progressing activity appears more than once in 5.78% of the cases. This implies that the students opted not to disrupt their study process by bypassing the assessments that came in between video lectures. We expected the Progressing and Exploring activities to be more frequent at the start of the course and to decrease as the course progressed because they correspond to the first time a piece of content is viewed. It is worth noting, however, that the frequency of Echoing activity was 29.7% during the initial sessions. This is relatively high given that the students have not yet completed all of the course content.
Furthermore, by categorizing the sessions into quintiles, it was possible to illustrate that the sessions at the start of the course had higher changes in terms of learning dynamics. Despite accounting for only 19% of the sessions, the initial ones were shown to account for 23% of all events in the high-level log. The number of events in each quintile decreased as the process was repeated, with the last quintile accounting for only 15% of the total events in the high-level event log.
Examining the process map of the course’s final sessions, as shown in
Figure 10, reveals that these are primarily related to assessment activities. This is because the dynamics of Skimming, Assessing, and Retaking appear more frequently than the dynamics associated with content. For instance, 39.9% of the former engaged in at least one Assessing or Retaking activity. However, it is noteworthy that 40.4% of cases belonged to students who just completed Skimming and then ended the session. This reveals that a considerable proportion of students only signed up to explore the questions without completing the overall evaluation. In terms of content dynamics, the Progressing activity was the one that typically started the sessions in which it featured, and it was usually followed by assessment activities, particularly Assessing. This reflects variations from the initial stages of the course, when the user preferred to study or repeat topics more frequently.
Furthermore, it should be noted that even at the end of the course, the Progressing activity appeared more frequently than the Echoing activity and for a longer average time (23.5 min versus 9.6 min). Similarly, the practice of continuing to study while missing an assessment significantly reduced its incidence, accounting for only 2 incidents, or 0.1% of these sessions.
5.4. RQ3: What Types of Mooc Sessions Do Successful Students Go through and How Do They Differ from Each Other?
Using the results from the processes outlined in
Section 4 for determining the number of clusters, the number that best segregated the data was deemed to be four. The duration, average number of activities, and number of cases classified in each cluster are shown in
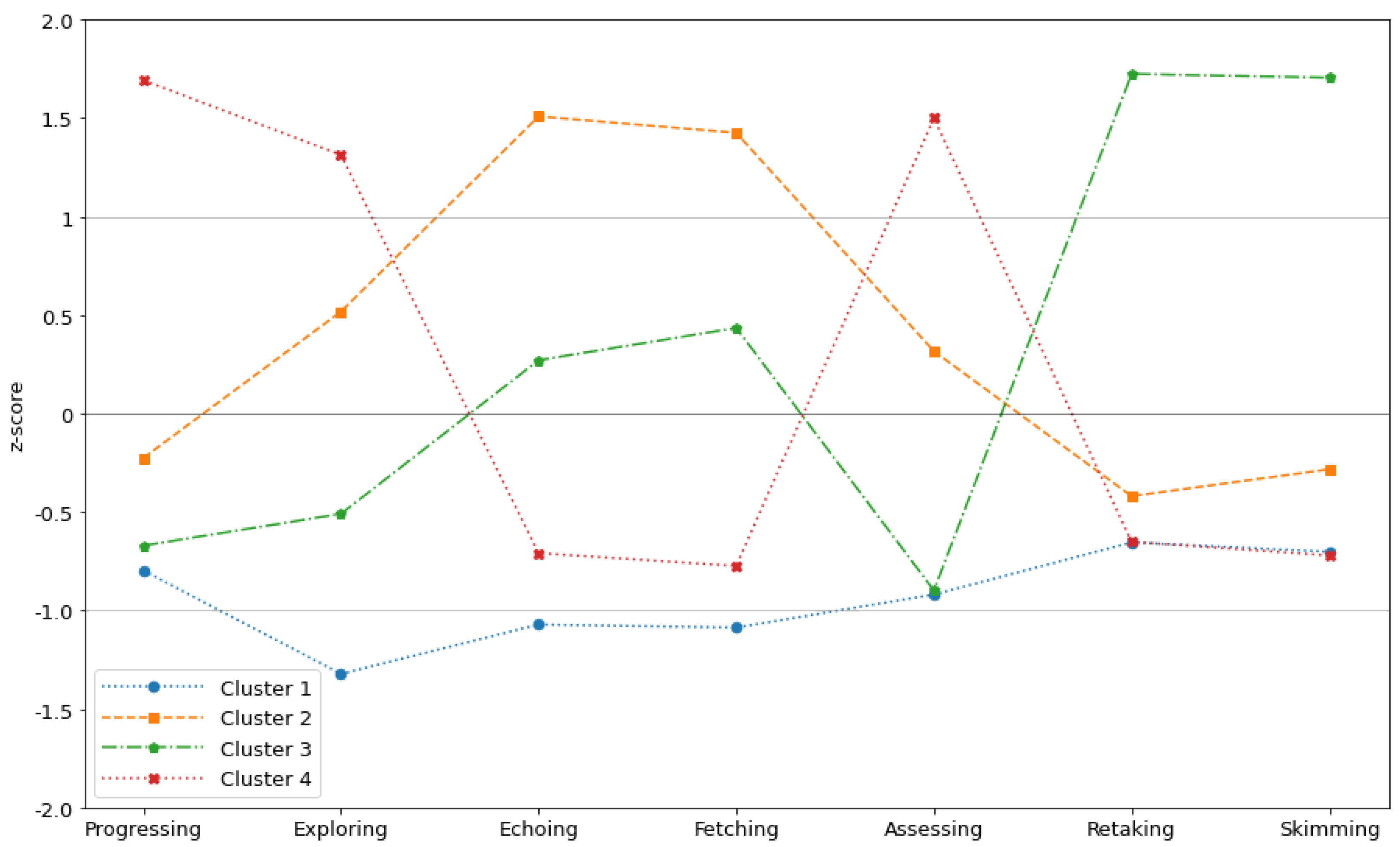
Table 5, while the results for each variable after z-score normalization are shown in
Figure 11. Each cluster’s differences and distinctions are detailed below. It is worth noting that two outliers were detected and deleted from the sample. These two cases in particular had the two longest sessions at 334 and 252 min, respectively, and the cases with the most activities per session at 89 and 73. Both sessions were completed in the middle of the course by the same user and described behavior similar, although exaggerated, to Cluster 3.
Cluster 1 accounts for the majority of the behavior observed in the log, with relatively short (<20 min) sessions containing one or two activities. Given the small number of activities in each session, the z-score for each dimension is expected to be somewhat low. Consequently, the activities with the lowest z-scores in this cluster are Skimming (−0.702) and Retaking (−0.653). When determining the point in the course at which the cases of this cluster appear, it is striking that, despite the low z-score of activities associated with assessment, the sessions of cluster 1 are mostly located in the course’s final quintile (25.92%), while the initial quintile only has 16.43%, and quintiles 2, 3, and 4 have values ranging from 18.68% (Q2) to 19.67% (Q4). Despite the fact that the majority of cases belong to this cluster, at event level, these account for just 42.13% of the reduced log.
Cluster 2 groups about 6% of the instances, however the events in it account for 20.12% of the total events in the log. This cluster is distinguished by longer sessions (about 108 min) and a larger number of activities per session (an average of 8.267 each). In this instance, four dynamics had high z-scores: Assessing (0.315), Exploring (0.518), Echoing (1.509), and Fetching (1.42), with the latter two having the highest scores for their respective activity. It is worth noting that in this situation, the majority of the sessions grouped belong to the middle of the course, with the bulk of them falling into the second quintile (25.75%), third quintile (21.84%), and fourth quintile (19.77%). Sessions in this cluster tend to occur less frequently in initial sessions (17.01%) and final sessions (15.63%). The high z-score of activities involving content repetition, paired with their location in the middle of the course, may imply that these sessions represent an active effort by the student to overcome some barrier, such as learning a new subject or overcoming the difficulty of an assessment.
Cluster 3 makes up 0.5% of all cases and 4.85% of all events. These sessions correspond to long-duration sessions that generally revolve around many interactions between the Retaking and Skimming activities, with the appearance of one of the other 5 learning dynamics in certain cases. As in Cluster 2, the sessions in this scenario take place mostly in the middle of the courseThis is due to 36.36% occurring in the second quintile, 27.27% in the third quintile, and 18.18% in the fourth quintile. With only five cases at the beginning (15.15%) and one at the end of the course.
Cluster 4 is the second largest cluster in terms of size, accounting for 18.88% of all sessions and 33.89% of the events in the high-level event log. The z-score of the progressing activity in this cluster is the highest in the sample, at 1.692. This means that this cluster identifies sessions in which the learner is progressing sequentially and thoroughly following the course program. This is supported by the fact that the Assessing activity, that is, performing assessments for the first time, also had the highest Z-score in the sample at this point, with a value of 1.500. When the distribution of sessions is compared to the quintiles of course progression where they are situated, the majority of the sessions in this cluster appear at the start of the course (31.45%). Then, as the course progresses, the number of sessions of this type gradually decreases, with only 9.17% of them coming from the course’s final quintile. The fact that only 4.42 activities are seen on average during each of these sessions, which last an average of 93.8 min, is also interesting to note. This could indicate an intention to advance through the course, taking into account both assessments and video lectures, in order to successfully complete it.
5.5. Discussion
First and foremost, the findings indicate that students’ behavior evolved throughout the course, as they were initially hesitant to evaluate themselves and preferred to view the content rather than assess their level of knowledge. The situation changed as participants progressed through the course, with 25% of the total number of events reported in the log resulting in completed assessments, either for the first time or by redoing a previously completed assessment. This shows that students’ dedication to the subject grew as the course continued.
According to the case analysis performed, the most frequent variants were of a single activity, and the longest sequences typically featured activities of the same type (e.g., Progressing and Echoing or Skimming and Retaking) indicating a student’s purpose when carrying out a MOOC session. This reinforces [
8] findings that effective learners typically focus their session time on a single learning resource (assessments, lectures, etc.), with the focus shifting from session to session. It is is also consistent with [
39] research on study patterns, where it was discovered that a sizeable portion of learners in the MOOC focus their time on a specific task, such as viewing videos or submitting an assignment, and with [
5,
21], which recognizes that the most common interaction patterns are associated with the use of a single type of resource (video-lecture only and assessment-summative only, respectively). Additionally, this is in line with the most common learning tactics reported in [
4,
6], where content-only and assessment-only tactics account for a considerable portion of the presented sample. Our research builds on these findings by distinguishing between first-time and re-engagement with content and assessments.
Excluding students who dropped out of the course from the analysis allowed for the description of behaviors that successful students commonly display. From the five clusters obtained, four types of sessions were identified: Short sessions with a specific goal (Cluster 1), long sessions in which the student moves through the course sequence in an orderly fashion (Cluster 4), sessions associated with Retaking-Skimming dynamics (Cluster 3), and sessions with content search and repetition (Cluster 2). The clusters obtained are akin to those reported in [
8], except for the two associated with No activity and Drop out, which are not present in our analysis. Furthermore, the patterns reported here are aligned with the activity patterns outlined in [
34] for successful students and in [
19] for the cluster researchers named
“Achievers”.
One of the unexpected findings in this study was that the Skimming dynamic was the most common variant, accounting for 26.7% of the high-level log. This could indicate the need to refine this dynamic because the review of an unfinished assessment could be the result of several factors, including: reviewing the difficulty of the content to be assessed in preparation for a serious attempt to complete it; reviewing mistakes made in previous attempts; and using the questions as learning examples, among others. Particularly in a programming course, this could be related to the necessity to check the code’s syntax or to better understand some control flow structure or data type. It is worth looking into the possibilities of obtaining more precise information from MOOCs in order to determine the actual objectives behind these unfinished assessment attempts. One method could be to investigate how the variants that incorporate Skimming connect to the content being viewed. Another approach is to contrast with external data, such as questionnaires, to uncover patterns underlying the skimming activities in order to describe more precise dynamics.
This research illustrates how a domain knowledge-based abstraction enables the description of student–MOOC interactions that would not be possible without this transition from low to high level. However, because our research cannot exist in a vacuum, it is necessary to enhance the findings of this work with advancements from other researchers. First, the framework aims to determine students’ intentions from the available data (for instance, progressing versus exploring). However, similar to what has been done in other MOOC studies such as [
8], such extrapolations could be improved if the framework were supplemented with certain additional instruments, for example, surveys and interviews. Second, dealing with fine- and mixed-grained events is a challenging task, as stated in [
22]. This work serves as an example of how this issue is not unrelated to data from educational systems. It also emphasizes how crucial it is to establish specific methods for this domain and evaluate the effectiveness of techniques provided in other domains on this sort of data. In this regard, rather than competing approaches, domain-driven event abstractions and data-driven event abstractions should be considered as complementary tools that can support each other. With this in mind, our framework could be supplemented with some of the data-driven event abstraction techniques described in [
13], creating a hybrid method that combines the two approaches with the aim of improving the dynamics suggested here and delivering a high-level event log consistent with both the source data and prior knowledge of the process. Finally, to validate the framework’s universality and utility, it must be evaluated using data from various MOOCs and platforms. Similarly, different courses would allow assessing their extensibility in relation to interactions not covered in this case study, such as forums or projects.
6. Conclusions
This study proposes a domain-driven event abstraction framework for creating a high-level event log to analyze learning dynamics in MOOC sessions. The framework, in specific, is divided into three stages: (1) the minimal data model required; (2) the creation of a low-level event log; and (3) the classification into seven high-level activities that can be utilized to construct an abstracted high-level event log.
A case study that examined the learning dynamics of the sessions of students who completed the course successfully validated the application of the framework in a real-world setting. The examination of the dynamics of the resources that are reviewed again lets us identify problems in the course and reveals that most students start a study session with a certain goal in mind (advance in the course, complete assessments, clear up questions, etc.). Similar distinctions were made between student behaviors at the start of the course and those at the end, since early on, students prioritized content consumption over working on assessments. However, when involvement to the course increases, students begin to actively participate in evaluation activities as their interest in the subject grows. Finally, the sessions could be divided into 4 different clusters, highlighting that while the development of relatively short sessions with a specific goal is the most common behavior of students in MOOCs, there are also sessions of extended duration in which students invest more time in the course by either progressing through it, attempting to improve their assessment results, or navigating through the course and revisiting content and assessments.
Among the limitations of this study is the use of sessions as the unit of analysis in our proposed event abstraction; thus, reviewing lower-level behavior patterns, such as behavior within an assessment, or higher-level ones, such as behavior during a course week or an overview of the entire course, requires their own domain-driven abstractions, while the framework was intended to be expanded and modified, as previously said, it begins with a separation between two basic categories of resources: content and assessment. This means that applying similar learning dynamics to courses that do not follow this order, such as project-based courses, may not make sense. However, the proposed abstraction approach would still be a valuable alternative for carrying out process analysis without having to deal with the complexities of data generated by students with total freedom of navigation through MOOC resources. Similarly, while the concepts explored in this research might be useful in synchronous and hybrid courses, such as b-learning courses hosted in LMS systems like MOODLE, our approach does not take into account the possibility of activities that might exist outside the system and that are not recorded in the database. This restriction must be taken into consideration by any application in a setting where there is interaction with parties outside the system, such as in a classroom.
This research demonstrates that utilizing event abstraction techniques on educational data enables the discovery of outcomes that would not be obvious when using data mining or process discovery techniques directly. One potential route for expanding on this research would be to identify behaviors that necessitate student interactions, such as forums, group projects, or peer assessments, as their own learning dynamics. Another alternative is to compare how the top-down learning dynamics described are correlated with a bottom-up abstraction output. This might allow for the detection of previously unknown learning dynamics or indicate the necessity for intermediate abstraction layers between the low-level of resources viewed and the activities conducted by a student during a MOOC session. In a related vein, given that all interactions are mediated by a MOOC system, it would be interesting to study how cultural [
40], usability [
41], or other factors, such as users’ special needs (e.g., autism [
42]), affect study session behavior. Finally, emphasizing the usefulness of event abstractions in an educational context opens up the possibility of using this type of technique in other contexts and educational problems where digital traces exist and process mining has previously been used, such as dropout detection [
17], curriculum analytics [
43,
44], quiz taking behavior [
45], and so on.
In recent years, the interest in understanding the behaviors, actions, tactics, strategies, and dynamics of MOOC users has been increasing, so there is a compelling need to systematically consolidate and organize the findings on the subject obtained so far. This is emphasized by the fact that techniques from a variety of disciplines, such as epistemic networks [
46,
47], ordered network analysis [
6], process discovery [
7,
15,
16], sequence mining [
17,
48], n-gram analysis [
32], and traditional machine learning [
19,
20], are currently being employed to describe these phenomena. This highlights the importance of using a common framework and taxonomy to help to refine the scope of future research proposals on this topic.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}