
Visual Exploration of Cycling Semantics with GPS Trajectory Data
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- We propose a new visualization system called VizCycSemantics for the exploration of underlying urban cycling semantics from both the cyclist and road segment’s perspectives, based on large-scale cycling GPS trajectories and road network data. The system could help to improve cycling services in cities.
- We textually convert the cycling trajectories into street name and moving feature corpora, then use a topic model to automatically extract the cyclists’ behavior semantics (i.e., cycling topics of cyclists) and moving semantics on roads (i.e., moving topics on roads), respectively. We further employ a clustering algorithm to capture the groups of similar cyclists and road segments in the city.
- We implement multiple interfaces to facilitate the understanding of cycling semantics for pervasive computing, including a cycling map, cycling groups and topics, the size of cycling groups, the street cloud of cycling topics, the temporal evolution of cycling topics, moving topics and moving topic distribution. A group of case studies in Beijing demonstrates the effectiveness of our system and also obtains various insightful findings and cycling advice.
2. Related Work
2.1. Visualization for Raw and Processed Trajectory Data
2.2. Visualization for Hidden Knowledge of Trajectory Data
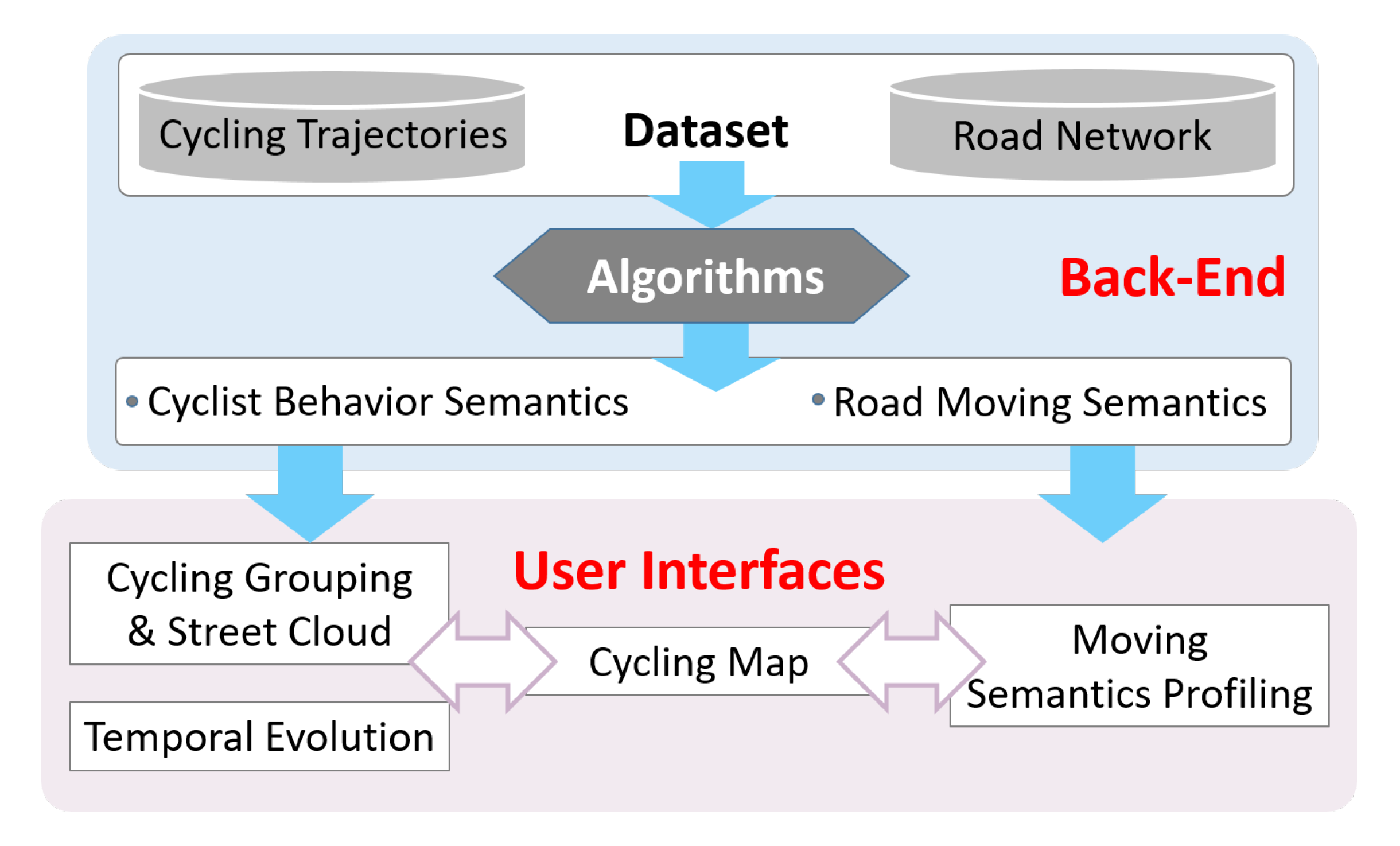
3. System Tasks and Framework of VizCycSemantics
- Task 1: Acquire cycling themes of cyclists in the city, i.e., behavior semantics. Based on the cycling trajectories and road network data, find out how many cycling themes of cyclists are in the city, which ones are more popular, how many groups of cyclists there are and how they distribute in time and space. This task could help cyclists to choose the desirable cycling routes and times according to their preferences.
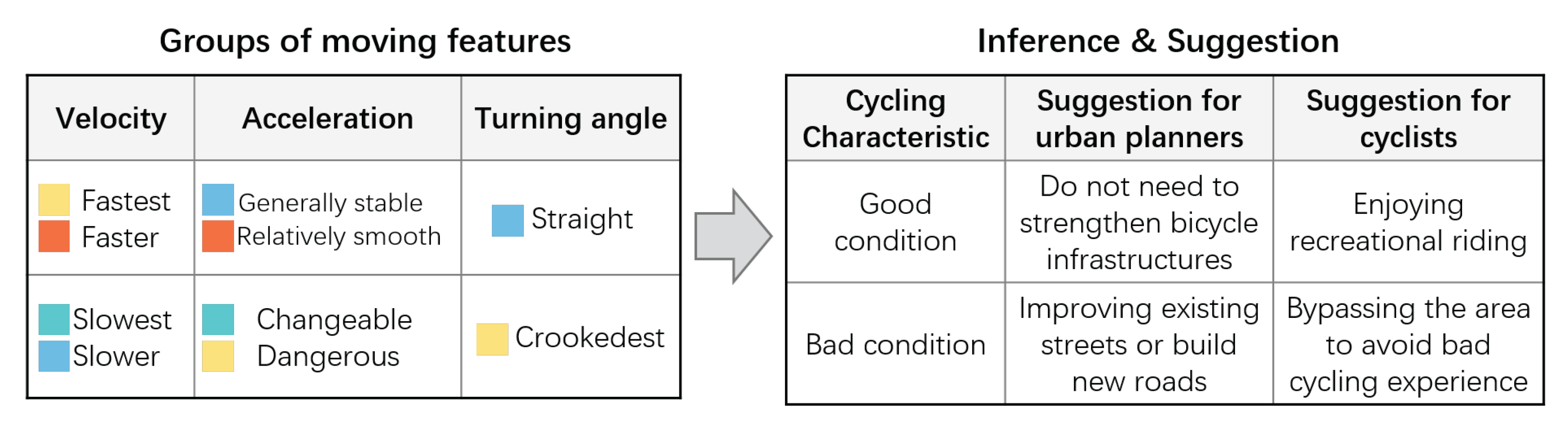
- Task 2: Identify different moving topics of cycling on the road network, i.e., moving semantics on roads. By investigating the fine-grained moving features on road segments, find out the moving topics of road segments in the city and determine where the road network is good for smooth or challenging cycling, where people need to ride with care and so on. This task can enable cyclists to choose appropriate road segments for their physical needs and can also help city planners to properly deploy cycling facilities.
- Task 3: Facilitate the understanding of the cycling semantics for analysts. Through implementing an interactive visualization system, the cycling semantics derived from task 1 and task 2 could be presented more intuitively. The user interfaces should satisfy the criterion of a user-friendly interaction.
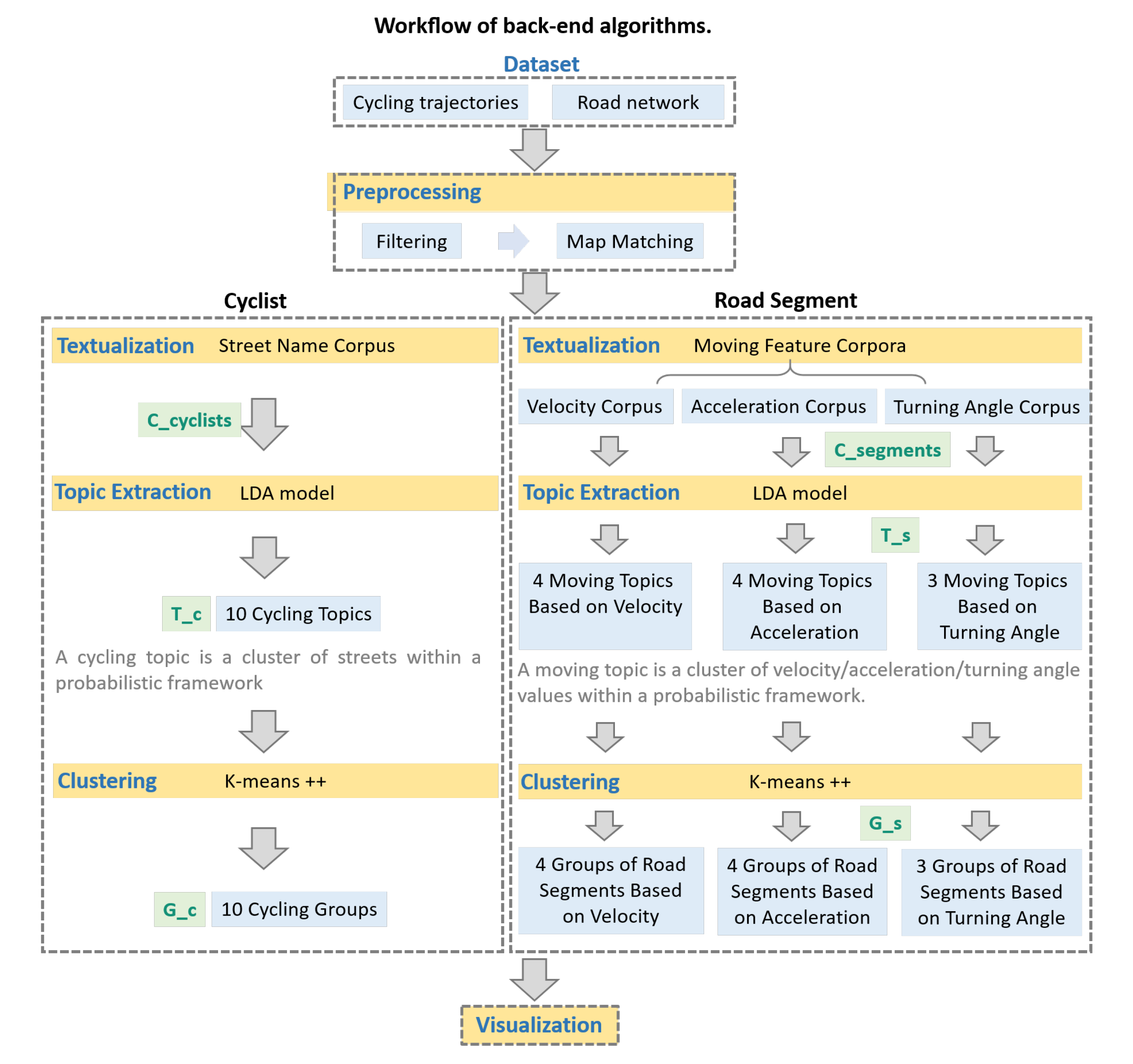
4. Backend Algorithms of VizCycSemantics
4.1. Preprocessing
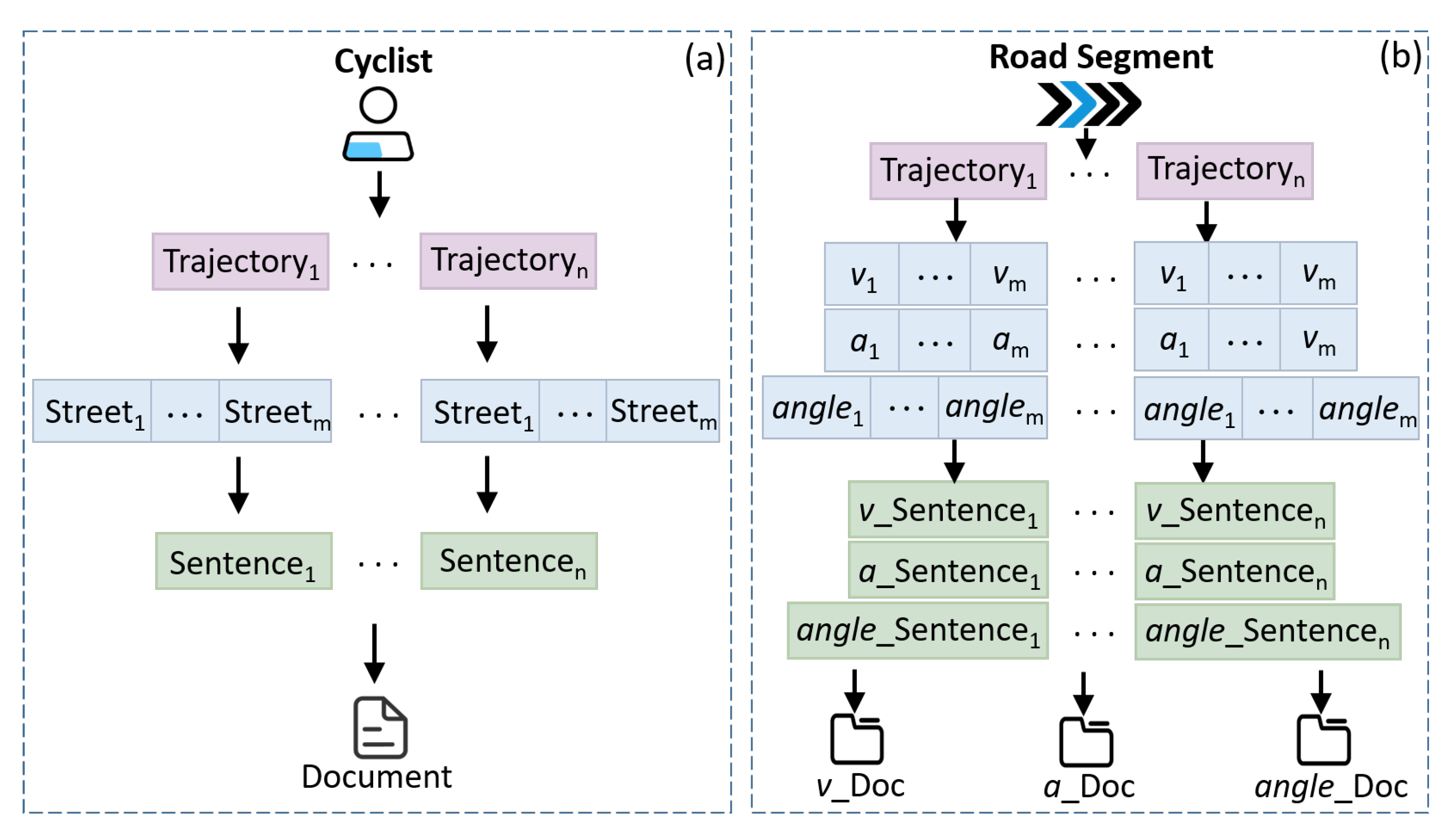
4.2. Textualization
4.2.1. Trajectory–Streets Textualization
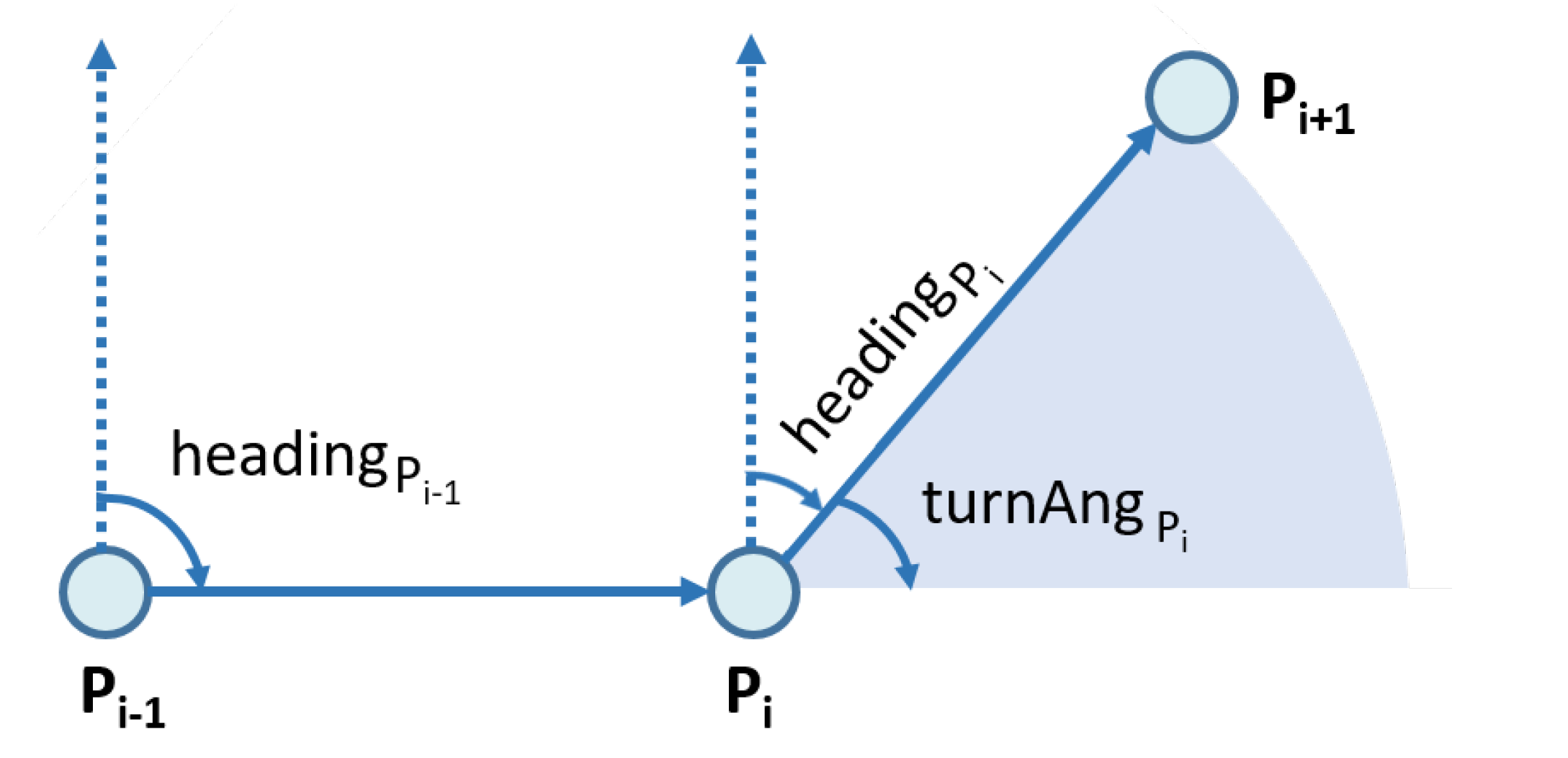
4.2.2. Moving Feature Textualization
4.3. Topic Extraction via LDA
4.3.1. Keyword–Topic Distribution
4.3.2. Topic–Document Distribution
4.4. Topic-Based Clustering
5. Visualization Implementation
5.1. Study Area and Data Source
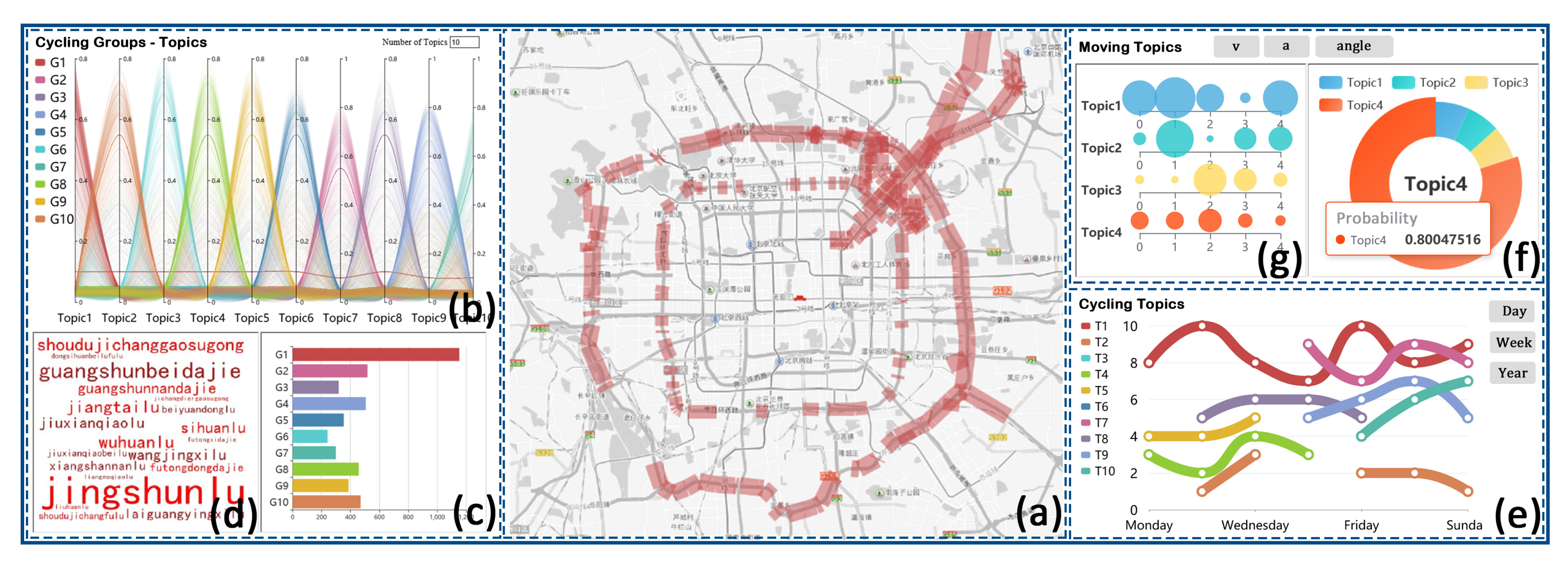
5.2. Visual Design
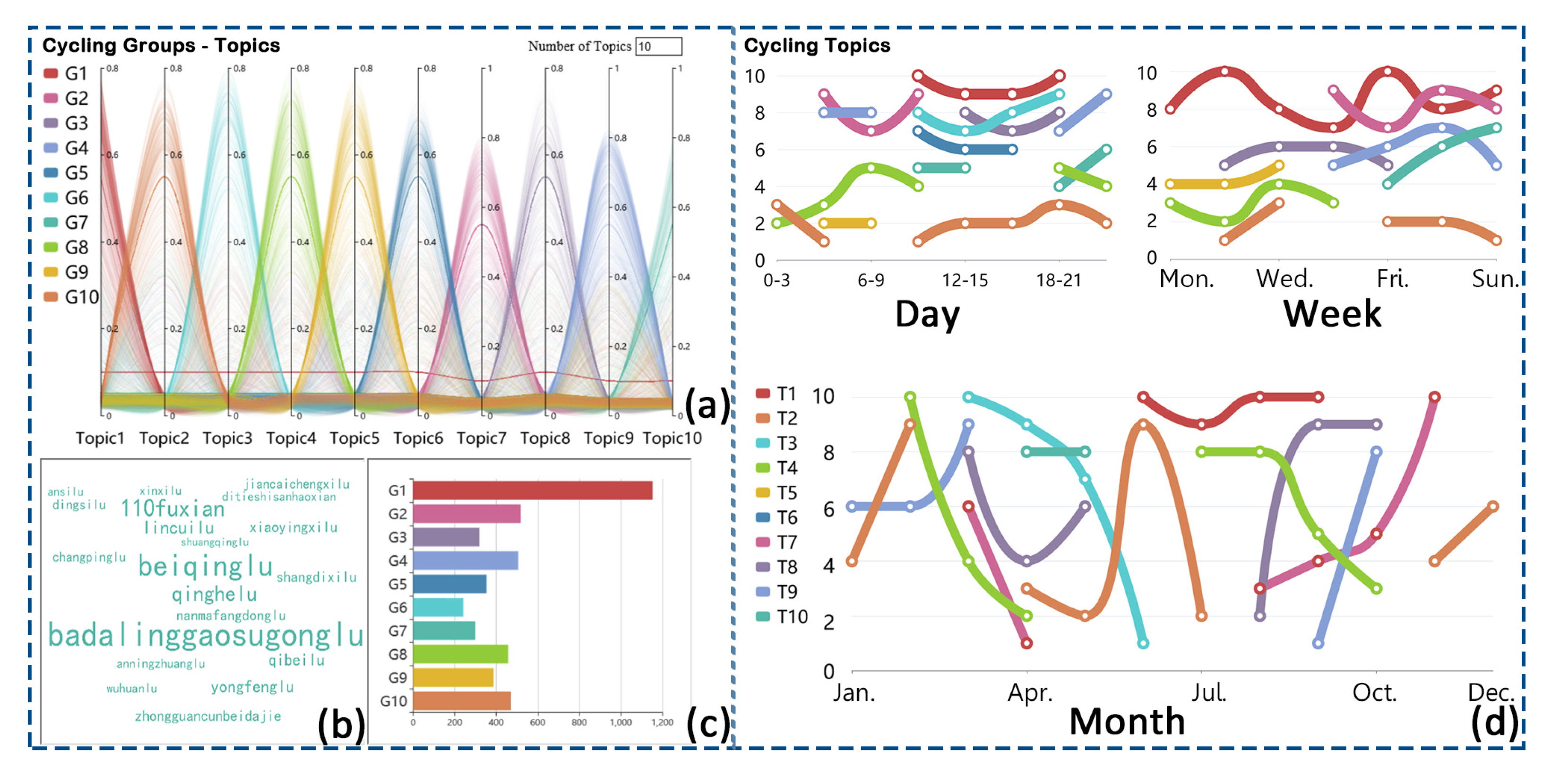
5.2.1. Cycling Grouping and Street Cloud of Cycling Topics
5.2.2. Temporal Evolution of Cycling Topics
5.2.3. Moving Semantics Profiling
5.2.4. Cycling Map
6. Case Study
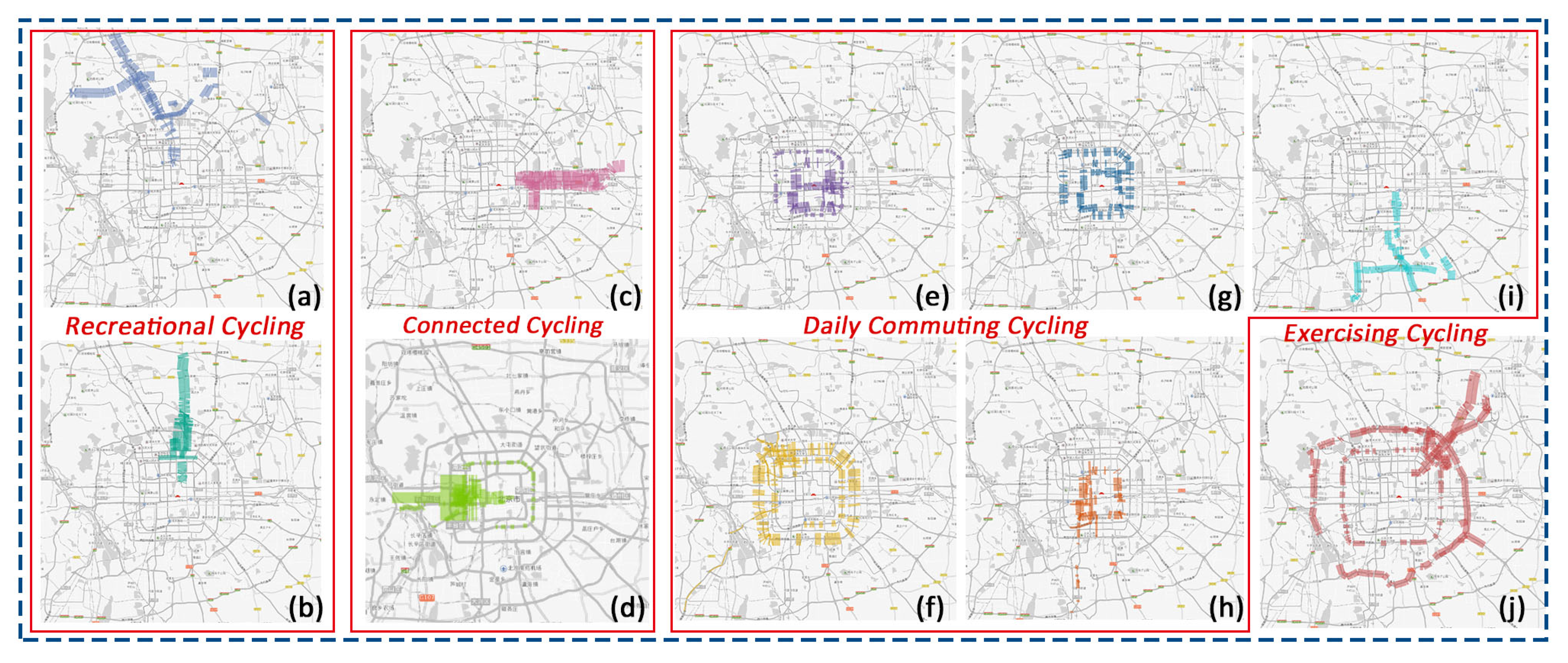
6.1. Case 1: Exploring the Spatiotemporal Patterns of Cycling Themes for Cyclists
6.1.1. Recreational Cycling
6.1.2. Connected Cycling
6.1.3. Daily Commuting Cycling
6.1.4. Exercising Cycling
6.1.5. Temporal Evolution of Cycling Topics
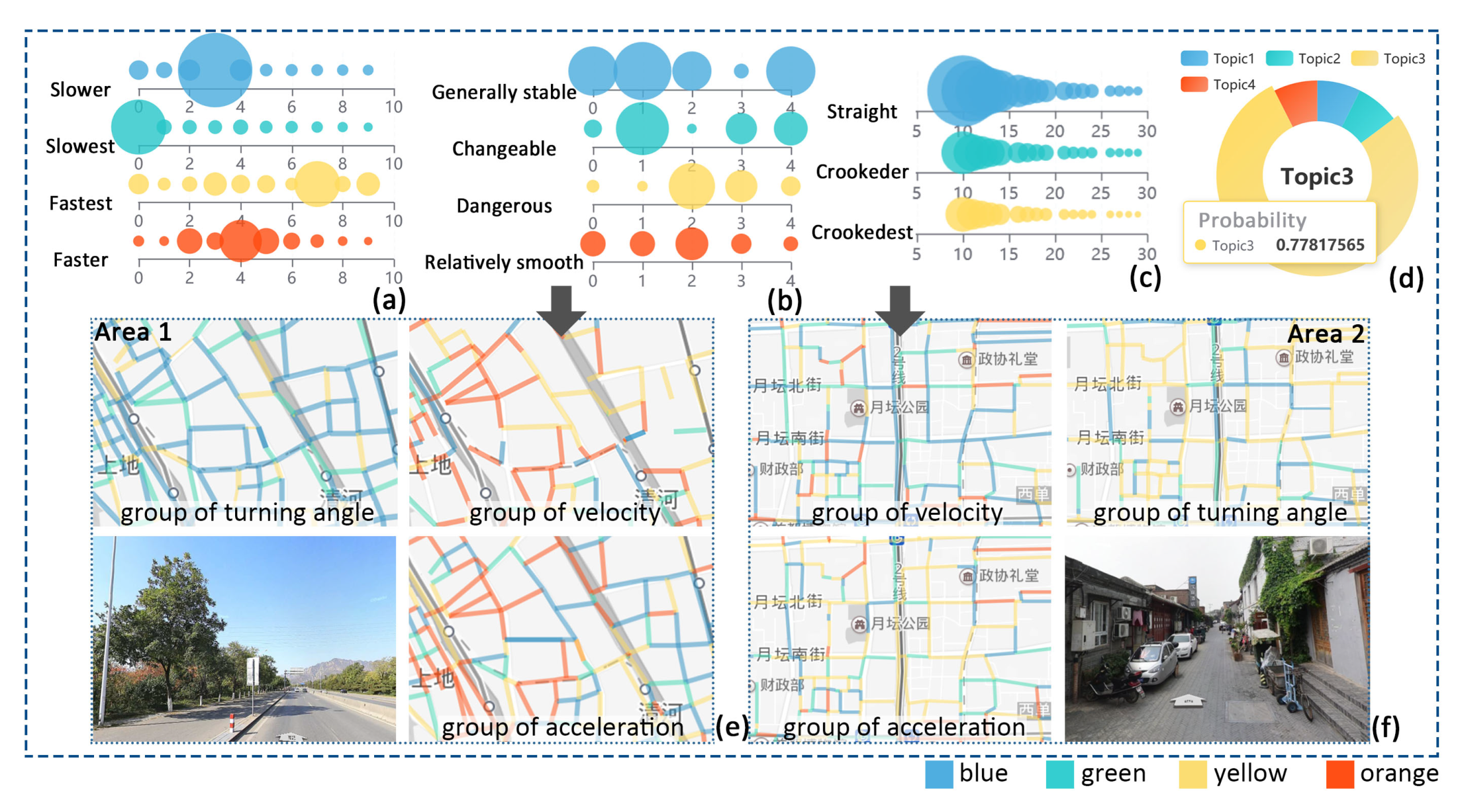
6.2. Case 2: Exploring the Moving Semantics of Road Segments
6.2.1. Topics Extracted by Velocity
6.2.2. Topics Extracted by Acceleration
6.2.3. Topics Extracted by Turning Angle
6.2.4. Regional Comparison
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Boss, D.; Nelson, T.; Winters, M.; Ferster, C.J. Using crowdsourced data to monitor change in spatial patterns of bicycle ridership. J. Transp. Health 2018, 9, 226–233. [Google Scholar] [CrossRef]
- Brauer, A.; Mäkinen, V.; Oksanen, J. Characterizing cycling traffic fluency using big mobile activity tracking data. Comput. Environ. Urban Syst. 2021, 85, 101553. [Google Scholar] [CrossRef]
- Commonwealth of Australia. National Road Safety Action Plan 2021–30. 2021. Available online: https://www.roadsafety.gov.au/sites/default/files/documents/National-Road-Safety-Strategy-2021-30.pdf (accessed on 15 September 2020).
- Ministry of Transport in China. Guidelines of the Ministry of Transport and Other 10 Departments on Encouraging and Regulating the Development of Internet Bike Rental. 2017. Available online: https://www.mot.gov.cn/yijianzhengji/201705/P020170521640994522102.doc (accessed on 15 September 2020).
- U.S. Department of Transportation. Encourage and Promote Safe Bicycling and Walking.; 2019. Available online: https://www.transportation.gov/mission/health/Encourage-and-Promote-Safe-Bicycling-and-Walking (accessed on 16 September 2020).
- Chu, D.; Sheets, D.A.; Zhao, Y.; Wu, Y.; Yang, J.; Zheng, M.; Chen, G. Visualizing hidden themes of taxi movement with semantic transformation. In Proceedings of the 2014 IEEE Pacific Visualization Symposium, Yokohama, Japan, 4–7 March 2014; pp. 137–144. [Google Scholar]
- Beecham, R.; Wood, J. Characterising group-cycling journeys using interactive graphics. Transp. Res. Part C Emerg. Technol. 2014, 47, 194–206. [Google Scholar] [CrossRef] [Green Version]
- Kassim, A.; Tayyeb, H.; Al-Falahi, M. Critical review of cyclist speed measuring techniques. J. Traffic Transp. Eng. (Engl. Ed.) 2020, 7, 98–110. [Google Scholar] [CrossRef]
- Al-Kodmany, K. Bridging the gap between technical and local knowledge: Tools for promoting community-based planning and design. J. Archit. Plan. Res. 2001, 18, 110–130. [Google Scholar]
- Chen, W.; Huang, Z.; Wu, F.; Zhu, M.; Guan, H.; Maciejewski, R. Vaud: A visual analysis approach for exploring spatio-temporal urban data. IEEE Trans. Vis. Comput. Graph. 2018, 24, 2636–2648. [Google Scholar] [CrossRef]
- Liao, C.; Chen, C.; Zhang, Z.; Xie, H. Understanding and visualizing passengers’ travel behaviours: A device-free sensing way leveraging taxi trajectory data. Pers. Ubiquitous Comput. 2019, 26, 491–503. [Google Scholar] [CrossRef]
- He, J.; Chen, H.; Chen, Y.; Tang, X.; Zou, Y. Diverse visualization techniques and methods of moving-object-trajectory data: A review. ISPRS Int. J. Geo-Inf. 2019, 8, 63. [Google Scholar] [CrossRef] [Green Version]
- Kreso, I.; Kapo, A.; Turulja, L. Data mining privacy preserving: Research agenda. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2021, 11, e1392. [Google Scholar] [CrossRef]
- Chen, C.; Zhang, D.; Castro, P.S.; Li, N.; Sun, L.; Li, S.; Wang, Z. iBOAT: Isolation-based online anomalous trajectory detection. IEEE Trans. Intell. Transp. Syst. 2013, 14, 806–818. [Google Scholar] [CrossRef]
- Chen, C.; Zhang, D.; Ma, X.; Guo, B.; Wang, L.; Wang, Y.; Sha, E. Crowddeliver: Planning city-wide package delivery paths leveraging the crowd of taxis. IEEE Trans. Intell. Transp. Syst. 2016, 18, 1478–1496. [Google Scholar] [CrossRef]
- Chen, C.; Jiao, S.; Zhang, S.; Liu, W.; Feng, L.; Wang, Y. TripImputor: Real-time imputing taxi trip purpose leveraging multi-sourced urban data. IEEE Trans. Intell. Transp. Syst. 2018, 19, 3292–3304. [Google Scholar] [CrossRef]
- Chen, C.; Ding, Y.; Xie, X.; Zhang, S.; Wang, Z.; Feng, L. TrajCompressor: An online map-matching-based trajectory compression framework leveraging vehicle heading direction and change. IEEE Trans. Intell. Transp. Syst. 2019, 21, 2012–2028. [Google Scholar] [CrossRef]
- Chen, C.; Yang, S.; Wang, Y.; Guo, B.; Zhang, D. CrowdExpress: A probabilistic framework for on-time crowdsourced package deliveries. IEEE Trans. Big Data 2020, 8, 827–842. [Google Scholar] [CrossRef]
- Chen, C.; Liu, Q.; Wang, X.; Liao, C.; Zhang, D. semi-Traj2Graph Identifying Fine-Grained Driving Style With GPS Trajectory Data via Multi-Task Learning. IEEE Trans. Big Data 2021, 8, 1550–1565. [Google Scholar] [CrossRef]
- Andrienko, G.; Andrienko, N.; Chen, W.; Maciejewski, R.; Zhao, Y. Visual analytics of mobility and transportation: State of the art and further research directions. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2232–2249. [Google Scholar] [CrossRef]
- Chen, W.; Guo, F.; Wang, F.Y. A survey of traffic data visualization. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2970–2984. [Google Scholar] [CrossRef]
- Kraak, M.J. The space-time cube revisited from a geovisualization perspective. In Proceedings of the 21st International Cartographic Conference, Citeseer, Durban, South Africa, 10–16 August 2003; pp. 1988–1996. [Google Scholar]
- Bach, B.; Dragicevic, P.; Archambault, D.; Hurter, C.; Carpendale, S. A descriptive framework for temporal data visualizations based on generalized space-time cubes. Comput. Graph. Forum 2017, 36, 36–61. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Ye, T.; Lu, M.; Yuan, X.; Qu, H.; Yuan, J.; Wu, Q. Visual exploration of sparse traffic trajectory data. IEEE Trans. Vis. Comput. Graph. 2014, 20, 1813–1822. [Google Scholar] [CrossRef]
- Shamal, A.D.; Zhao, Y.; Kamw, F.; Yang, J.; Ye, X.; Chen, W. QuteVis: Visually studying transportation patterns using multisketch query of joint traffic situations. IEEE Comput. Graph. Appl. 2019, 41, 35–48. [Google Scholar]
- Krüger, R.; Simeonov, G.; Beck, F.; Ertl, T. Visual interactive map matching. IEEE Trans. Vis. Comput. Graph. 2018, 24, 1881–1892. [Google Scholar] [CrossRef]
- Lu, M.; Lai, C.; Ye, T.; Liang, J.; Yuan, X. Visual analysis of multiple route choices based on general gps trajectories. IEEE Trans. Big Data 2017, 3, 234–247. [Google Scholar] [CrossRef]
- Kamw, F.; Al-Dohuki, S.; Zhao, Y.; Eynon, T.; Sheets, D.; Yang, J.; Ye, X.; Chen, W. Urban structure accessibility modeling and visualization for joint spatiotemporal constraints. IEEE Trans. Intell. Transp. Syst. 2019, 21, 104–116. [Google Scholar] [CrossRef]
- Itoh, M.; Yokoyama, D.; Toyoda, M.; Tomita, Y.; Kawamura, S.; Kitsuregawa, M. Visual exploration of changes in passenger flows and tweets on mega-city metro network. IEEE Trans. Big Data 2016, 2, 85–99. [Google Scholar] [CrossRef]
- Zeng, W.; Fu, C.W.; Arisona, S.M.; Schubiger, S.; Burkhard, R.; Ma, K.L. Visualizing the relationship between human mobility and points of interest. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2271–2284. [Google Scholar] [CrossRef]
- Zhao, X.; Zhang, Y.; Hu, Y.; Wang, S.; Li, Y.; Qian, S.; Yin, B. Interactive visual exploration of human mobility correlation based on smart card data. IEEE Trans. Intell. Transp. Syst. 2020, 22, 4825–4837. [Google Scholar] [CrossRef]
- Shi, Y.; Liu, Y.; Tong, H.; He, J.; Yan, G.; Cao, N. Visual analytics of anomalous user behaviors: A survey. IEEE Trans. Big Data 2020, 8, 377–396. [Google Scholar] [CrossRef] [Green Version]
- Feng, Z.; Li, H.; Zeng, W.; Yang, S.H.; Qu, H. Topology density map for urban data visualization and analysis. IEEE Trans. Vis. Comput. Graph. 2020, 27, 828–838. [Google Scholar] [CrossRef]
- Al-Dohuki, S.; Wu, Y.; Kamw, F.; Yang, J.; Li, X.; Zhao, Y.; Ye, X.; Chen, W.; Ma, C.; Wang, F. Semantictraj: A new approach to interacting with massive taxi trajectories. IEEE Trans. Vis. Comput. Graph. 2016, 23, 11–20. [Google Scholar] [CrossRef]
- Bahmani, B.; Moseley, B.; Vattani, A.; Kumar, R.; Vassilvitskii, S. Scalable k-means++. arXiv 2012, arXiv:1203.6402. [Google Scholar] [CrossRef]
- Lou, Y.; Zhang, C.; Zheng, Y.; Xie, X.; Wang, W.; Huang, Y. Map-matching for low-sampling-rate GPS trajectories. In Proceedings of the 17th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 4–6 November 2009; pp. 352–361. [Google Scholar]
- Jiang, L.; Chen, C.X.; Chen, C. L2MM: Learning to Map Matching with Deep Models for Low-Quality GPS Trajectory Data. ACM Trans. Knowl. Discov. Data (TKDD) 2022, 17, 39. [Google Scholar] [CrossRef]
- Newson, P.; Krumm, J. Hidden Markov map matching through noise and sparseness. In Proceedings of the 17th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 4–6 November 2009; pp. 336–343. [Google Scholar]
- Ryan, M.S.; Nudd, G.R. The Viterbi Algorithm; University of Warwick: Coventry, UK, 1993. [Google Scholar]
- Zheng, Y.; Li, Q.; Chen, Y.; Xie, X.; Ma, W.Y. Understanding mobility based on GPS data. In Proceedings of the 10th International Conference on Ubiquitous Computing, Seoul, Republic of Korea, 21–24 September 2008; pp. 312–321. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Yuan, C.; Yang, H. Research on K-value selection method of K-means clustering algorithm. J 2019, 2, 226–235. [Google Scholar] [CrossRef] [Green Version]
- Dou, W.; Wang, X.; Chang, R.; Ribarsky, W. Paralleltopics: A probabilistic approach to exploring document collections. In Proceedings of the 2011 IEEE Conference on Visual Analytics Science and Technology (VAST), Providence, RI, USA, 23–28 October 2011; pp. 231–240. [Google Scholar]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, X.; Liao, C.; Chen, C.; Li, R. Visual Exploration of Cycling Semantics with GPS Trajectory Data. Appl. Sci. 2023, 13, 2748. https://doi.org/10.3390/app13042748
Gao X, Liao C, Chen C, Li R. Visual Exploration of Cycling Semantics with GPS Trajectory Data. Applied Sciences. 2023; 13(4):2748. https://doi.org/10.3390/app13042748
Chicago/Turabian StyleGao, Xuansu, Chengwu Liao, Chao Chen, and Ruiyuan Li. 2023. "Visual Exploration of Cycling Semantics with GPS Trajectory Data" Applied Sciences 13, no. 4: 2748. https://doi.org/10.3390/app13042748