
Simultaneous Fault Diagnosis Based on Hierarchical Multi-Label Classification and Sparse Bayesian Extreme Learning Machine

Abstract
:1. Introduction
- (1)
- Simultaneous fault is not a simple combination of multiple single faults, so it is unfeasible to use a simple and traditional model of mechanism to recognize simultaneous faults.
- (2)
- In practice, due to the high number of species of all possible simultaneous failure modes, it is impractical to collect ample samples of all simultaneous failure modes to train a fault classification model focused on both single failure modes and simultaneous failure modes recognition.
- (3)
- There is no one-to-one correspondence between failure signs and failure cause, and the failure signs have the characteristics of large ambiguity, strong coupling, and uncertainty, which further increase the difficulty of recognition.
- (1)
- A simultaneous fault diagnosis framework based on a hierarchical multi-label classification strategy and a feed-forward neural network based on sparse Bayesian is proposed to effectively recognize single failures and simultaneous failures. Only single failure samples are participating in the training procedure of the model.
- (2)
- There is a certain correlation between each pair of single faults, to improve the classification accuracy, this paper introduces paired strategy into multi-label classification to create a hierarchical multi-label classification model.
- (3)
- The proposed diagnostic framework is utilized for the intelligent fault diagnosis of the main reducer. When simultaneous fault exists, it’s achievable to accurately identify multiple single faults that occur at the same time. The experimental results indicate that the framework performance is superior in recognition accuracy.
2. The Fundamental Theories
2.1. Extreme Learning Machine (ELM)
2.2. Sparse Bayesian Extreme Learning Machine (SBELM)
3. Proposed Methodology
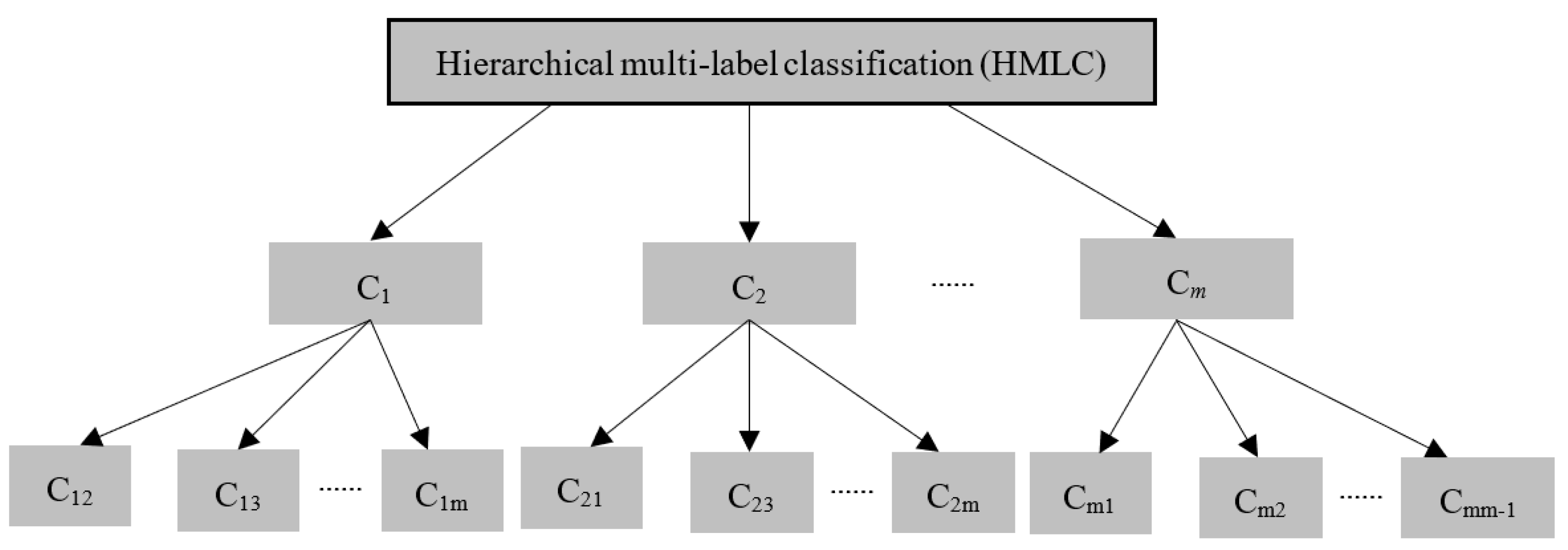
3.1. Design of Hierarchical Multi-Label Classification Strategy
- (1)
- Calculate the occurrence probability of all categories, and the category corresponding to the maximum value is chosen as the prediction category;
- (2)
- Based on binary classification, the classification problem with multiple classes can be skillfully converted into several sub-problems with two classes to be solved, and then the multiple binary classification results are effectively combined.
3.2. Design of Hierarchical Multi-Label Classification Strategy
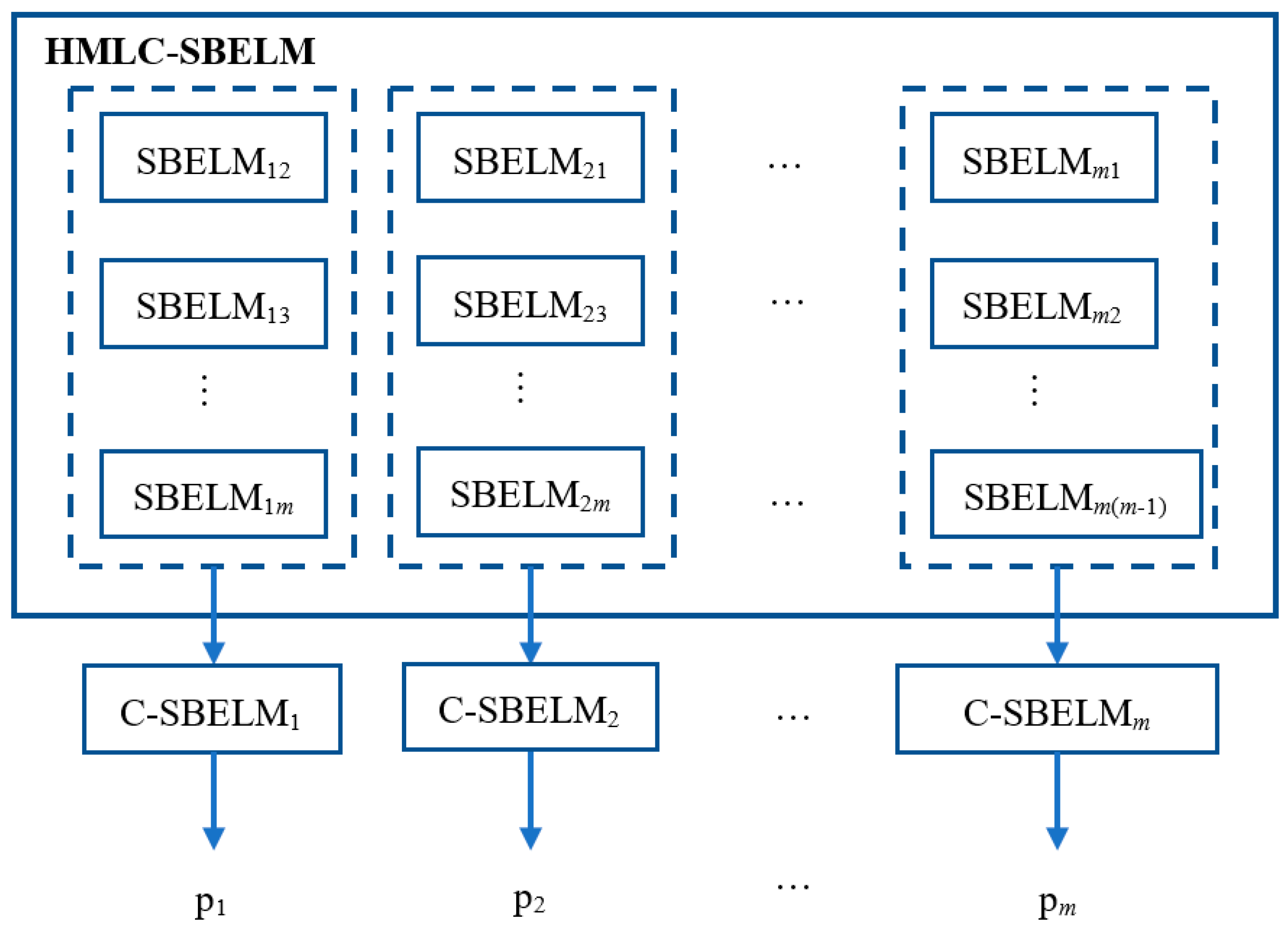
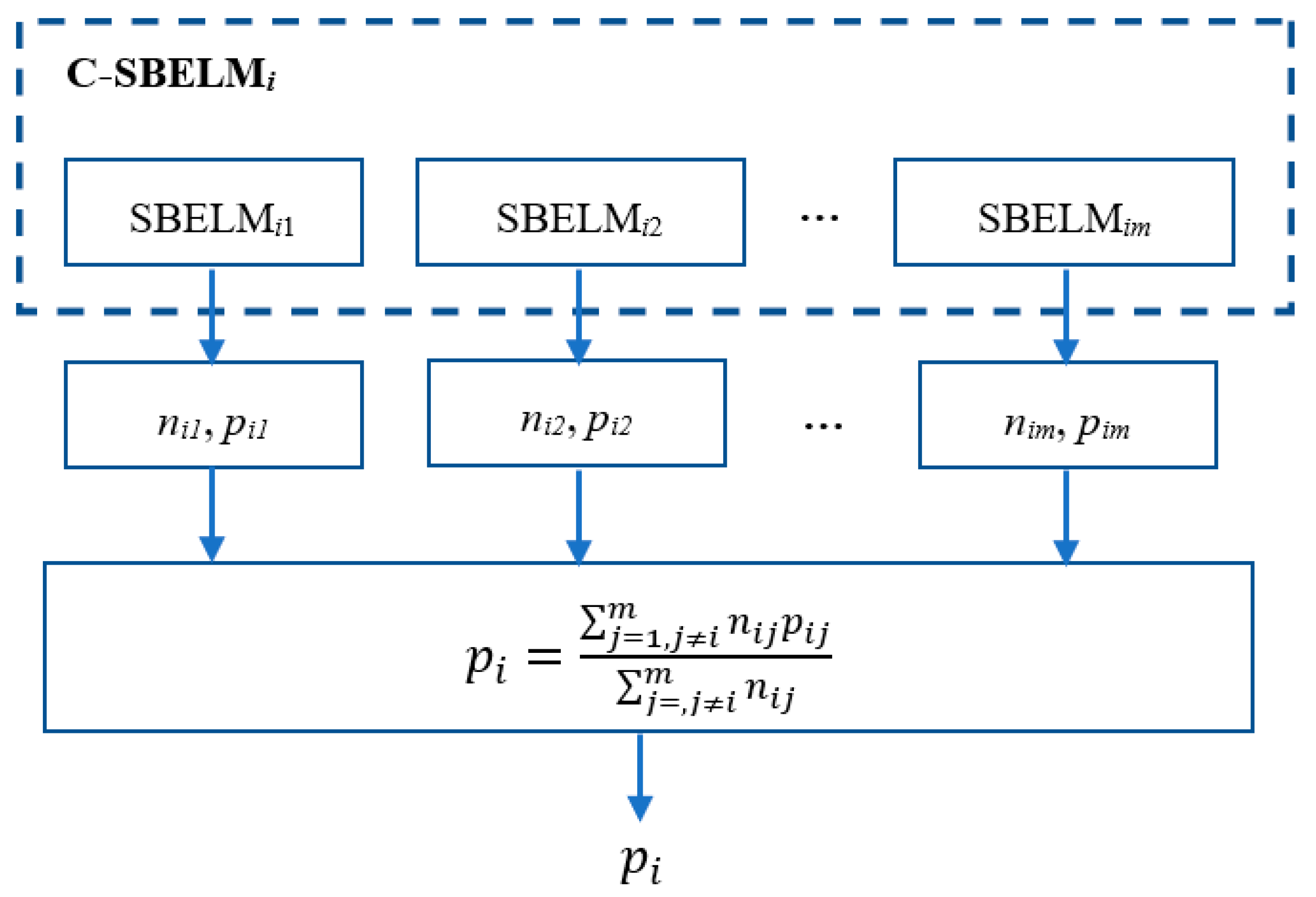
3.3. The Probability Output Fusion of Model Based on HMLC-SBELM
3.4. The Optimization of Threshold Value
3.5. The Architecture of the Framework Based on HMLC-SBELM
4. Experiment and Discuss
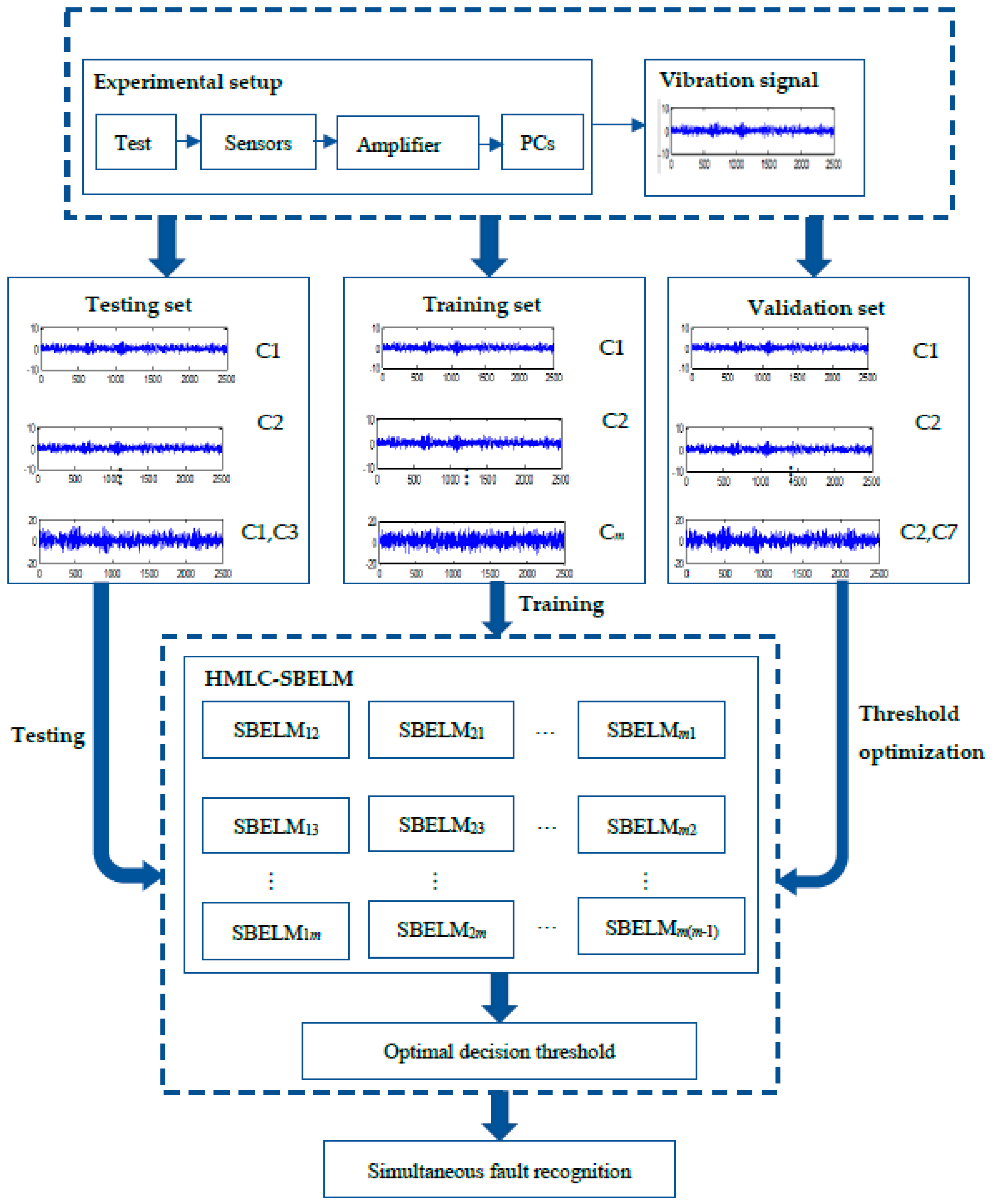
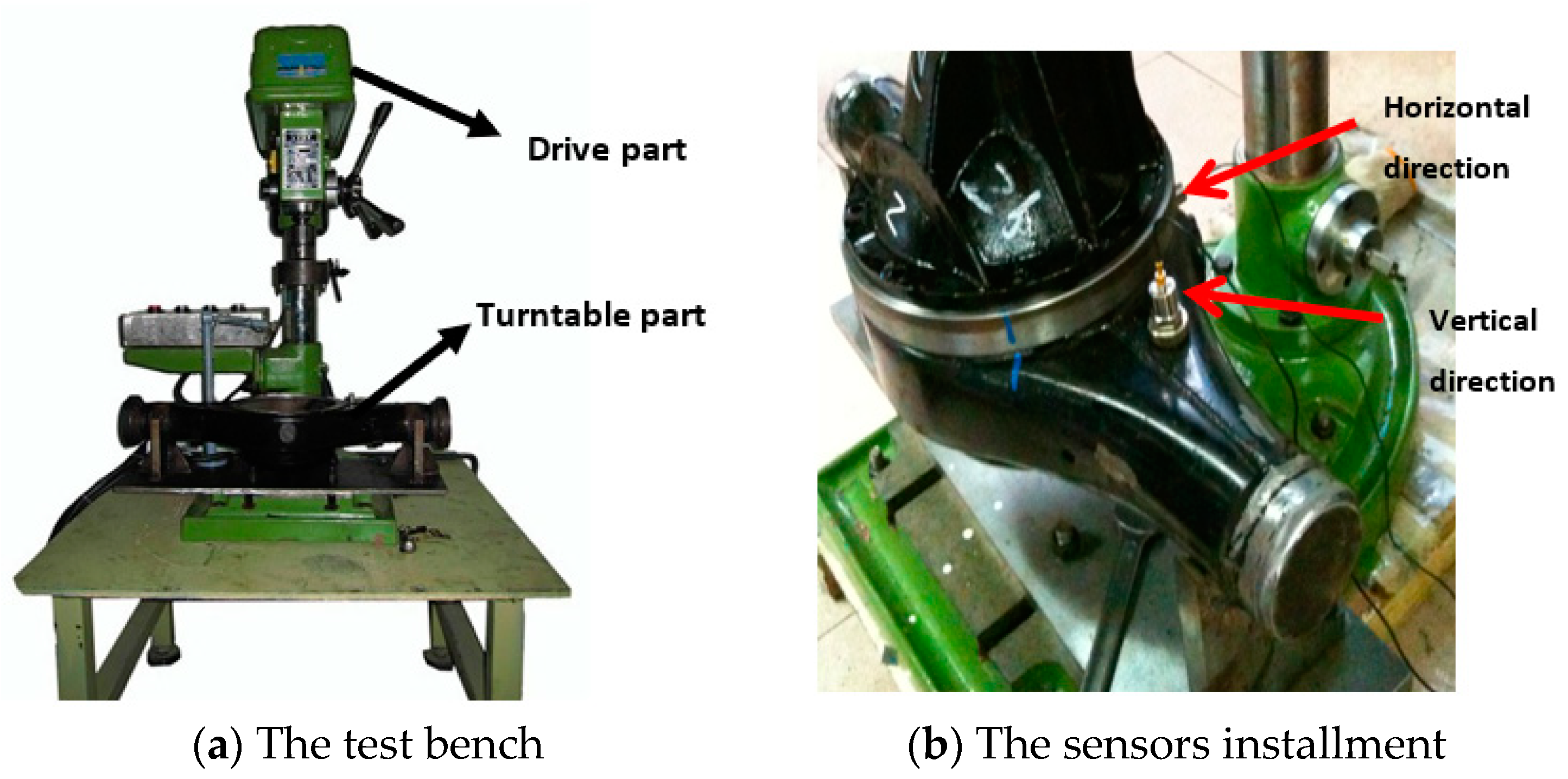
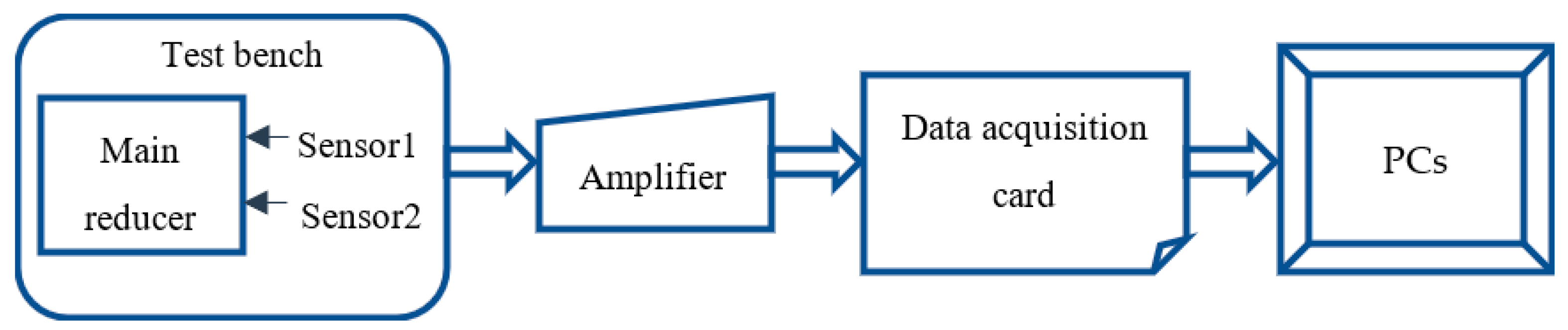
4.1. Experimental Environment and Setup
4.2. Model Parameter Setup
4.3. Comparative Analysis and Experimental Results
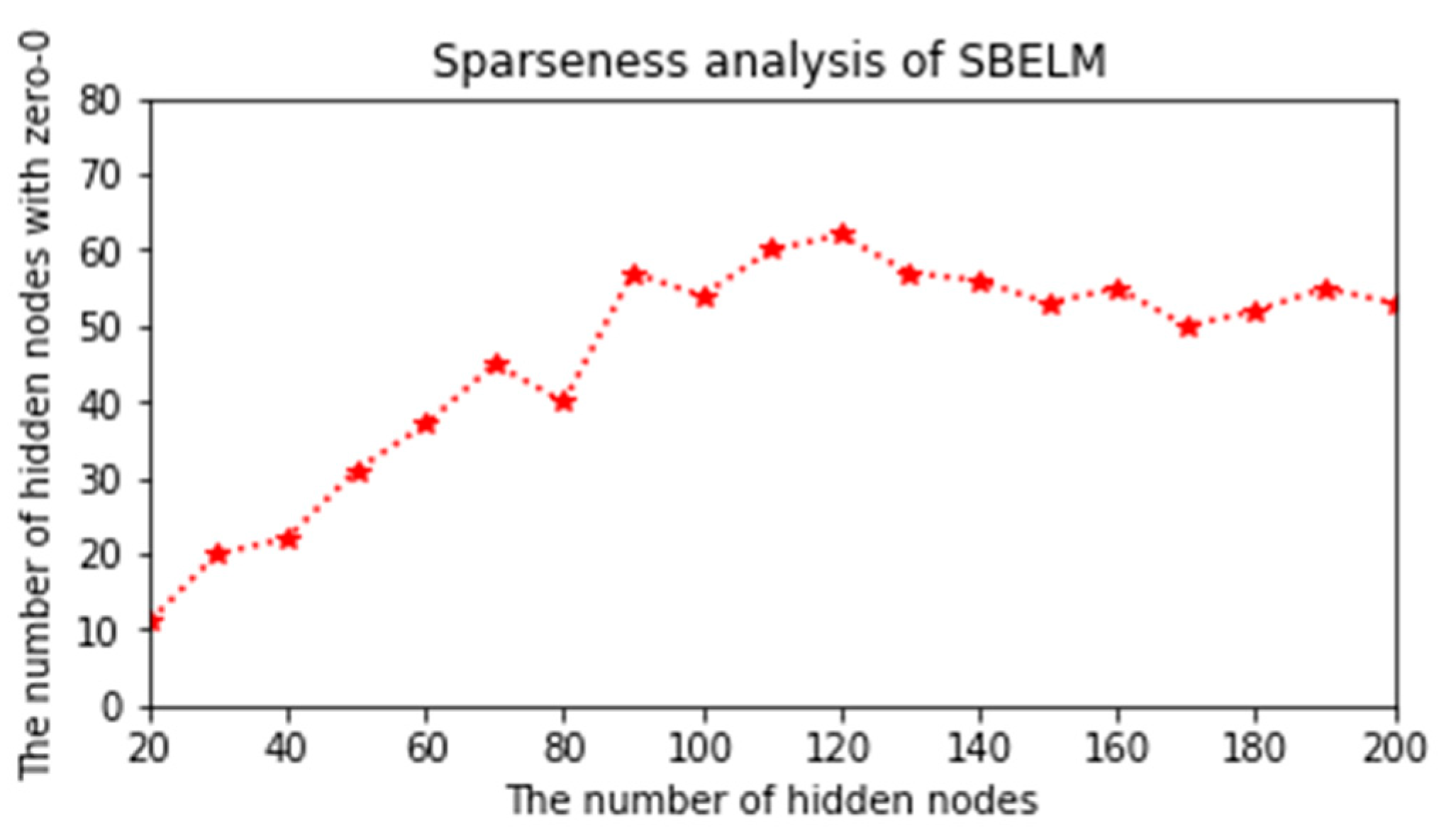
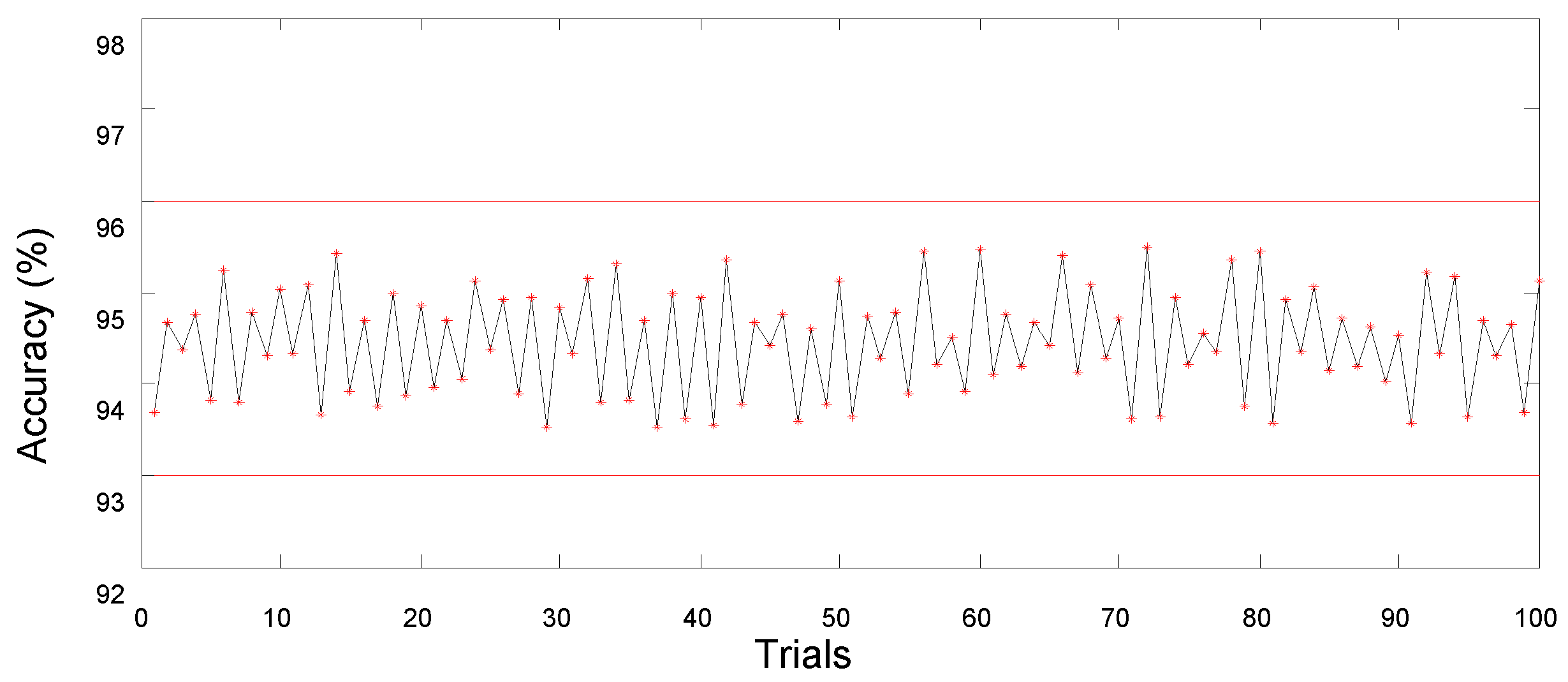
4.3.1. Sparseness Analysis of SBELM
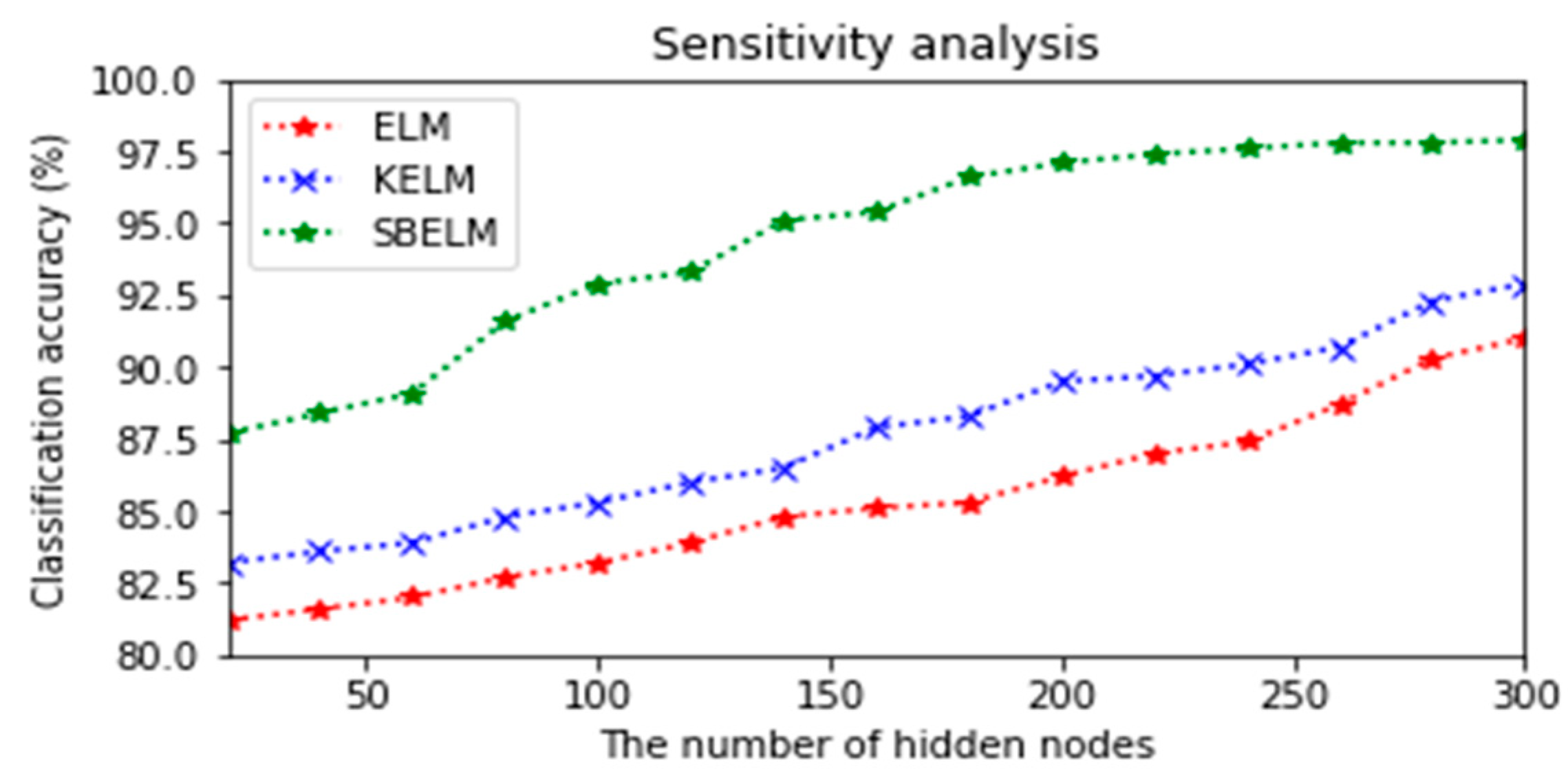
4.3.2. Sensitivity Analysis for the Hidden Layer Scale
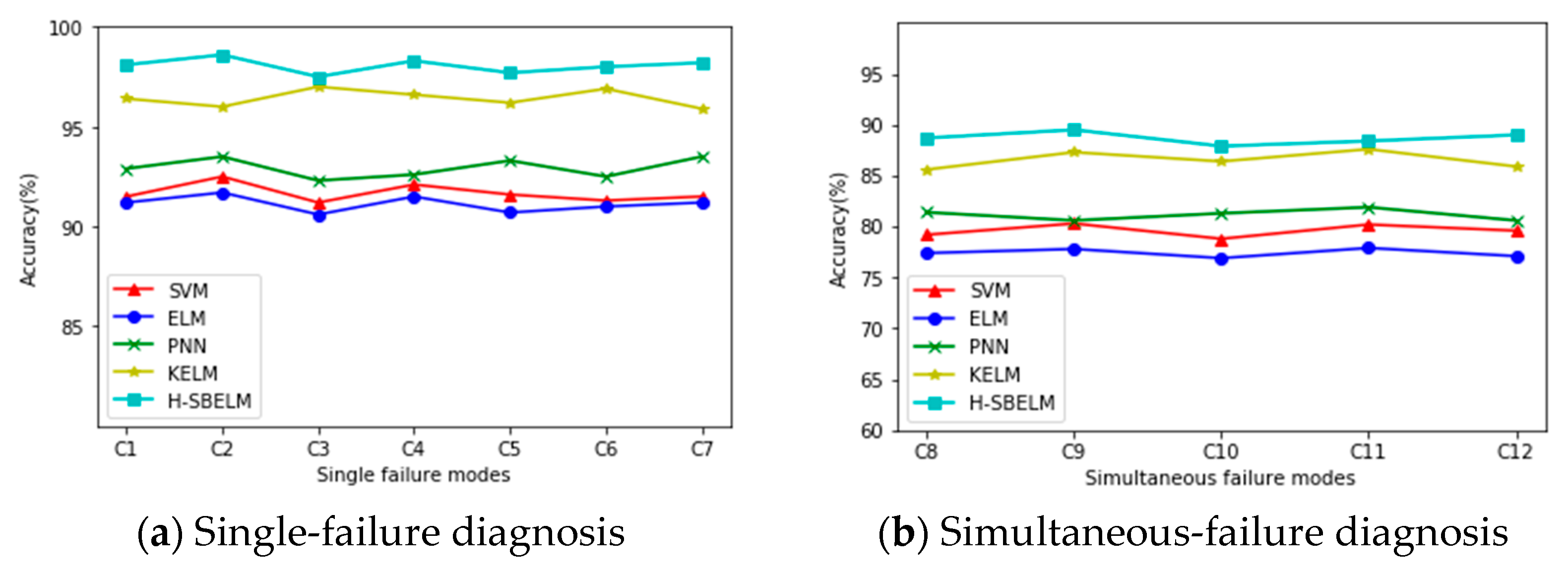
4.3.3. Performance Evaluation of the Diagnostic Framework
- (1)
- Training of HMLC-SBELM-based model
- (2)
- Determine the optimal decision threshold for the diagnostic model
- (3)
- Performance evaluation of the diagnostic model
- (4)
- Admissibility of simultaneous fault diagnosis results
- (5)
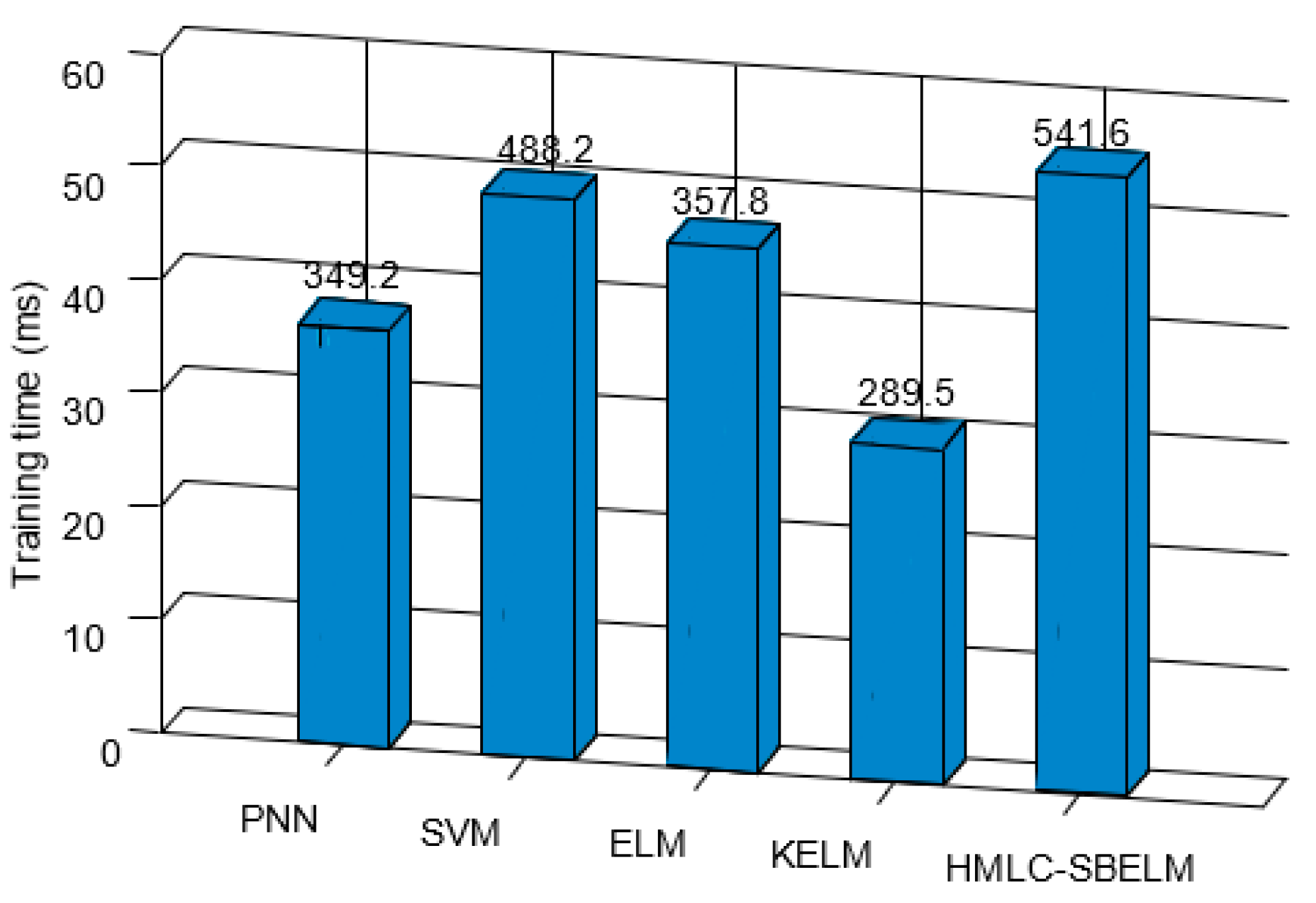
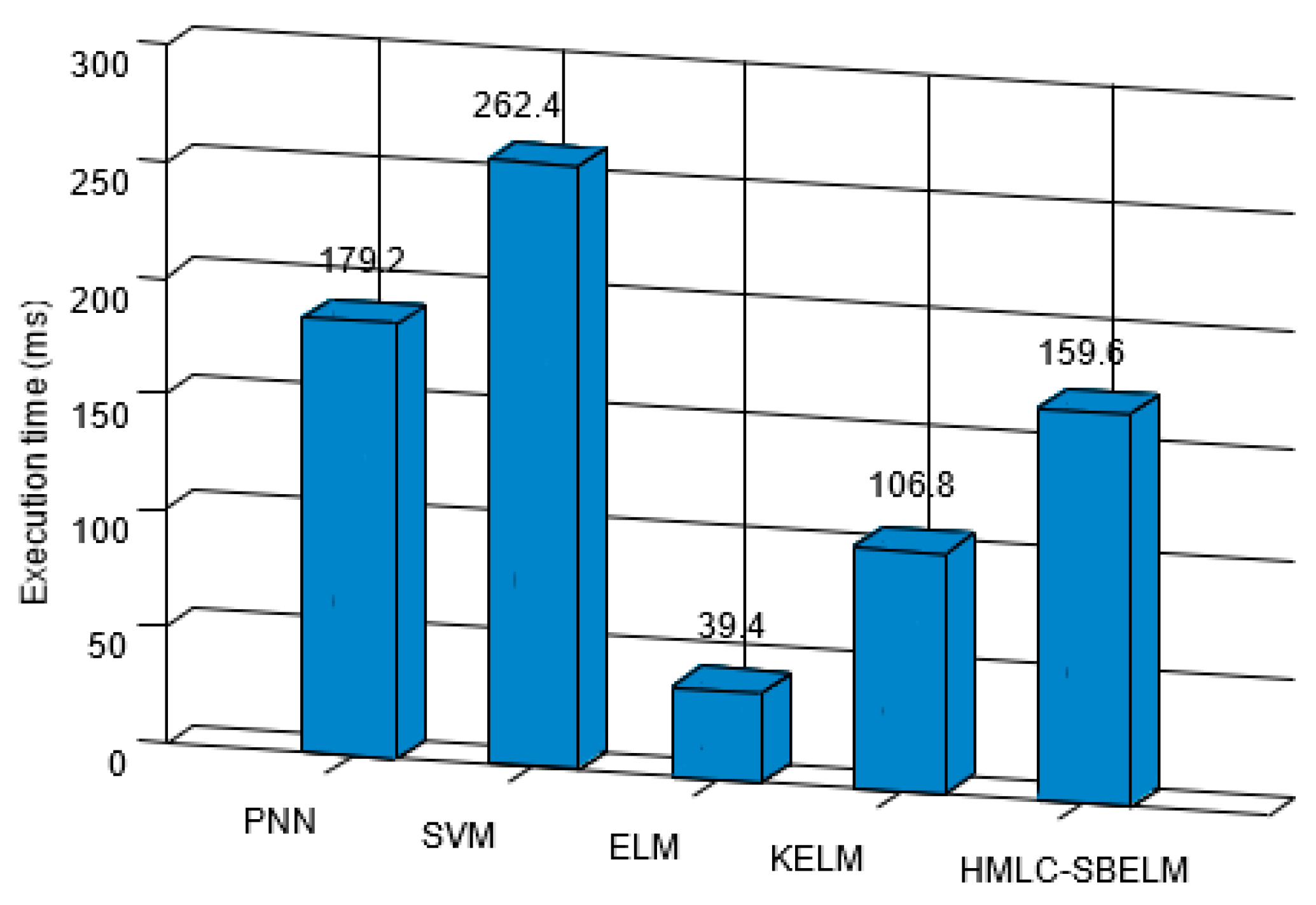
- Analysis of efficiency and stability
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yao, L.-J.; Ding, J.-X. An On-line Vibration Monitoring System for Final Drive of Automobile. Noise Vib. Control. 2007, 27, 54–57. [Google Scholar]
- Ye, Q.; Liu, S.; Liu, C. A Deep Learning Model for Fault Diagnosis with a Deep Neural Network and Feature Fusion on Multi-Channel Sensory Signals. Sensors 2020, 20, 4300. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.; Wu, F.J.; Zhao, W.; Ghaffari, M.; Liao, L.X.; Siegel, D. Prognostics and health management design for rotary machinery systems: Reviews, methodology and applications. Mech. Syst. Signal Process. 2014, 42, 314–334. [Google Scholar] [CrossRef]
- Ye, Q.; Liu, C. A Multichannel Data Fusion Method Based on Multiple Deep Belief Networks for Intelligent Fault Diagnosis of Main Reducer. Symmetry 2020, 12, 483. [Google Scholar] [CrossRef]
- Qi, Y.; Shen, C.; Wang, D.; Shi, J.; Jiang, X.; Zhu, Z. Stacked sparse autoencoder-based deep network for fault diagnosis of rotating machinery. IEEE Access 2017, 5, 15066–15079. [Google Scholar] [CrossRef]
- Liu, G.; Bao, H.; Han, B. A stacked autoencoder-based deep neural network for achieving gearbox fault diagnosis. Math. Probl. Eng. 2018, 2018, 5105709. [Google Scholar] [CrossRef]
- Ye, Q.; Liu, C. An Unsupervised Deep Feature Learning Model Based on Parallel Convolutional Autoencoder for Intelligent Fault Diagnosis of Main Reducer. Comput. Intell. Neurosci. 2021, 2021, 8922656. [Google Scholar] [CrossRef]
- Liu, R.; Yang, B.; Zio, E.; Chen, X. Artificial intelligence for fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process. 2018, 108, 33–47. [Google Scholar] [CrossRef]
- Wu, Y.; Jin, W.; Li, Y.; Wang, D. A novel method for simultaneous-fault diagnosis based on between-class learning. Measurement 2021, 172, 108839. [Google Scholar] [CrossRef]
- Liang, P.; Deng, C. Single and simultaneous fault diagnosis of gearbox via a semi-supervised and high-accuracy adversarial learning framework. Knowl.-Based Syst. 2020, 198, 105895. [Google Scholar] [CrossRef]
- Tan, Y.; Zhang, J.; Tian, H.; Jiang, D.; Guo, L.; Wang, G.; Lin, Y. Multi-label classification for simultaneous fault diagnosis of marine machinery: A comparative study. Ocean. Eng. 2021, 239, 109723. [Google Scholar] [CrossRef]
- Zare, S.; Ayati, M. Simultaneous fault diagnosis of wind turbine using multichannel convolutional neural networks. ISA Trans. 2021, 108, 230–239. [Google Scholar] [CrossRef] [PubMed]
- Guangbin, H.; Zhu, Q.; Siew, C.K. Extreme learning machine theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar]
- Cambria, E. Extreme Learning Machines. IEEE Trans. Cybern. 2013, 28, 30–59. [Google Scholar]
- Zhang, Y.; Wang, Y.; Zhou, G.; Jin, J.; Wang, B.; Wang, X.; Cichocki, A. Multi-kernel extreme learning machine for EEG classification in brain-computer interfaces. Expert Syst. Appl. 2018, 96, 302–310. [Google Scholar] [CrossRef]
- Huang, G.; Ding, X.; Zhou, H. Optimization method based extreme learning machine for classification. Neurocomputing 2010, 74, 155–163. [Google Scholar] [CrossRef]
- Wong, P.K.; Yang, Z.; Vong, C.M.; Zhong, J. Real-time diagnosis fault diagnosis for gas turbine generator systems using extreme learning machine. Neurocomputing 2014, 128, 249–257. [Google Scholar] [CrossRef]
- Tian, Y.; Ma, J.; Lu, C.; Wang, Z. Rolling bearing fault diagnosis under variable conditions using LMD-SVD and extreme learning machine. Mech. Mach. Theory 2015, 90, 175–186. [Google Scholar] [CrossRef]
- Song, Y.; Crowcroft, J.; Zhang, J. Automatic epileptic seizure detection in EEGs based on optimized sample entropy and extreme learning machine. J. Neurosci. Methods 2012, 210, 132–146. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhou, H.; Ding, X.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. B: Cybern. 2012, 42, 513–529. [Google Scholar] [CrossRef]
- Emilio, S.O.; Juan, G.S.; Martin, J.D.; Vila-Frances, J.; Martinez, M.; Magdalena, J.R.; Serrano, A.J. BELM: Bayesian extreme learning machine. IEEE Trans. Neural Netw. 2011, 22, 505–509. [Google Scholar]
- Zhang, Y.; Jin, J.; Wang, X.; Wang, Y. Motor imagery EEG classification via Bayesian extreme learning machine. In Proceedings of the IEEE Sixth International Conference on Information Science and Technology (ICIST 2016), Dalian, China, 6–8 May 2016; pp. 27–30. [Google Scholar]
- Udmale, S.S.; Singh, S.K. Application of spectral kurtosis and improved extreme learning machine for bearing fault classification. IEEE Trans. Instrum. Meas. 2019, 68, 4222–4233. [Google Scholar] [CrossRef]
- Luo, J.; Vong, C.M.; Wong, P.K. Sparse Bayesian extreme learning machine for multi- classification. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 836–842. [Google Scholar] [PubMed]
- Suresh, S.; Saraswathi, S.; Sundararajan, N. Performance enhancement of extreme learning machine for multi-category sparse data classification problems. Eng. Appl. Artif. Intell. 2010, 23, 1149–1157. [Google Scholar] [CrossRef]
- Chen, S.; Gao, L.; Liao, G. MBAN-MLC: A multi-label classification method and its application in automating fault diagnosis. Int. J. Internet Manuf. Serv. 2018, 5, 350–364. [Google Scholar] [CrossRef]
- Chen, W.-J.; Shao, Y.-H.; Li, C.-N.; Deng, N.-Y. MLTSVM: A novel twin support vector machine to multi-label learning. Pattern Recogn. 2016, 52, 61–74. [Google Scholar] [CrossRef]
- Boutell, M.R.; Luo, J.; Shen, X.; Brown, C.M. Learning multi-label scene classification. Pattern Recogn. 2004, 37, 1757–1771. [Google Scholar] [CrossRef]
- Ning, K.; Liu, M.; Dong, M.; Wu, C.; Wu, Z. Two efficient twin ELM methods with prediction interval. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 2058–2071. [Google Scholar] [CrossRef]
- Zhao, R.; Mao, K. Semi-random projection for dimensionality reduction and extreme learning machine in high-dimensional space. IEEE Comput. Intell. Mag. 2015, 10, 30–41. [Google Scholar] [CrossRef]
- Yu, H.; Mu, C.; Sun, C.; Yang, W.; Yang, X.; Zuo, X. Support vector machine-based optimized decision threshold adjustment strategy for classifying imbalanced data. Knowl.-Based Syst. 2015, 76, 67–78. [Google Scholar] [CrossRef]
- Lipton, Z.C.; Elkan, C.; Naryanaswamy, B. Optimal thresholding of classifiers to maximize F1 measure. Mach. Learn. Knowl. Discov. Databases 2014, 8725, 225–239. [Google Scholar] [PubMed]
- Haas, D.; Painter, F.D.; Wilkinson, M. Root-cause analysis of simultaneous faults on an offshore FPSO vessel. IEEE Trans. Ind. Appl. 2014, 50, 1543–1551. [Google Scholar] [CrossRef]
- Barbieri, R.; Barbieri, N.; De Lima, K.F. Some applications of PSO for optimization of acoustic filters. Appl. Acoust. 2015, 89, 62–70. [Google Scholar] [CrossRef]
- Ali, J.B.; Saidi, L.; Mouelhi, A.; Chebel-Morello, B.; Fnaiech, F. Linear feature selection and classification using PNN and SFAM neural networks for a nearly online diagnosis of bearing naturally progressing degradations. Eng. Appl. Artif. Intell. 2015, 42, 67–81. [Google Scholar]
- Chen, X.; Zhou, J.; Xiao, H.; Wang, E.; Xiao, J.; Zhang, H. Fault diagnosis based on comprehensive geometric characteristic and probability neural network. Appl. Math. Comput. 2014, 230, 542–554. [Google Scholar] [CrossRef]
- Huang, G.B. An insight into extreme learning machines: Random neurons, random features and kernels. Cogn. Comput. 2014, 6, 376–390. [Google Scholar] [CrossRef]
- Iosifidis, A.; Tefas, A.; Pitas, I. On the kernel extreme learning machine classifier. Pattern Recognit. Lett. 2015, 54, 11–17. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, Y.; Jin, J.; Wang, X. Sparse Bayesian learning for obtaining sparsity of EEG frequency bands based feature vectors in motor imagery classification. Int. J. Neural Syst. 2017, 27, 1650032. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, L. A review of failure modes, condition monitoring and fault diagnosis methods for large-scale wind turbine bearings. Measurement 2020, 149, 107002. [Google Scholar] [CrossRef]
- Lei, Y.; Yang, B.; Jiang, X.; Jia, F.; Li, N.; Nandi, A.K. Applications of machine learning to machine fault diagnosis: A review and roadmap. Mech. Syst. Signal Process. 2020, 138, 106587. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Failure Type | Failure No. | Description |
|---|---|---|
| Single fault | C1 | Normal state |
| C2 | Gear hard point | |
| C3 | Gear crack | |
| C4 | Gear tooth broken | |
| C5 | Gear burr | |
| C6 | Gear error | |
| C7 | Misalignment | |
| Simultaneous fault | C2, C3 | Gear hard point and gear crack |
| C3, C6 | Gear crack and gear error | |
| C5, C7 | Gear burr and misalignment | |
| C2, C3, C6 | Gear hard point, gear crack and gear error | |
| C3, C5, C7 | Gear crack, gear burr and misalignment |
| Single Failure Samples | Simultaneous Failure Samples | Total | |
|---|---|---|---|
| Training set | 350 × 7 | None | 2450 |
| Validation set | 100 × 7 | 400 × 5 | 2700 |
| Testing set | 50 × 7 | 100 × 5 | 850 |
| Total | 3500 | 2500 | 6000 |
| No. | Actual Category | Predicted Result | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 0.7218 | 0.0256 | 0.0672 | 0.1005 | 0.1026 | 0.0052 | 0.2735 | 1 |
| 2 | 1 | 0.7237 | 0.2096 | 0.0034 | 0.1128 | 0.0007 | 0.1265 | 0.1542 | 1 |
| 3 | 1 | 0.7623 | 0.0028 | 0.1205 | 0.0005 | 0.1037 | 0.0039 | 0.0126 | 1 |
| 4 | 1 | 0.8906 | 0.2118 | 0.0087 | 0.0132 | 0.0005 | 0.0458 | 0.0001 | 1 |
| 5 | 1 | 0.7314 | 0.0075 | 0.3008 | 0.0009 | 0.0386 | 0.0012 | 0.0006 | 1 |
| 6 | 1 | 0.7209 | 0.1022 | 0.1102 | 0.0026 | 0.0065 | 0.0725 | 0.0214 | 1 |
| … | |||||||||
| 2447 | 7 | 0.1115 | 0.0009 | 0.0077 | 0.1026 | 0.0059 | 0.0437 | 0.7601 | 7 |
| 2448 | 7 | 0.0021 | 0.0097 | 0.0382 | 0.0815 | 0.1027 | 0.0829 | 0.7268 | 7 |
| 2449 | 7 | 0.2091 | 0.0038 | 0.0006 | 0.1081 | 0.0077 | 0.0021 | 0.7523 | 7 |
| 2450 | 7 | 0.1518 | 0.0009 | 0.0738 | 0.0021 | 0.1703 | 0.0977 | 0.7139 | 7 |
| Contrastive Models | PNN | SVM | ELM | KELM | HMLC-SBELM | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| ε* | ε* | ε* | ε* | ε* | ||||||
| ε*, | 0.71 | 0.863 | 0.68 | 0.829 | 0.69 | 0.857 | 0.69 | 0.903 | 0.71 | 0.923 |
| Various Models | Multi-Label Classification Strategy | Accuracy (%) | ||
|---|---|---|---|---|
| Single Failures | Simultaneous Failures | Overall Results | ||
| PNN | One-to-all | 88.45 (±1.52) | 78.15 (±1.63) | 82.79 (±1.49) |
| HMLC strategy | 92.88 (±1.31) | 81.26 (±1.49) | 86.37 (±1.72) | |
| SVM | One-to-all | 90.12 (±1.25) | 76.23 (±1.75) | 81.94 (±1.44) |
| HMLC strategy | 91.69 (±1.18) | 79.81 (±1.52) | 84.52 (±1.29) | |
| ELM | One-to-all | 85.61 (±1.46) | 74.08 (±1.91) | 82.91 (±1.55) |
| HMLC strategy | 91.19 (±1.37) | 77.35 (±1.68) | 85.44 (±1.59) | |
| KELM | One-to-all | 93.26 (±1.54) | 83.62 (±1.62) | 89.17 (±1.77) |
| HMLC strategy | 96.38 (±1.71) | 86.31 (±1.43) | 91.93 (±1.65) | |
| HMLC-SBELM | One-to-all | 93.62 (±1.05) | 85.38 (±1.45) | 88.24 (±1.23) |
| HMLC strategy | 98.03 (±0.96) | 88.71 (±1.01) | 94.43 (±1.14) | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, Q.; Liu, C. Simultaneous Fault Diagnosis Based on Hierarchical Multi-Label Classification and Sparse Bayesian Extreme Learning Machine. Appl. Sci. 2023, 13, 2376. https://doi.org/10.3390/app13042376
Ye Q, Liu C. Simultaneous Fault Diagnosis Based on Hierarchical Multi-Label Classification and Sparse Bayesian Extreme Learning Machine. Applied Sciences. 2023; 13(4):2376. https://doi.org/10.3390/app13042376
Chicago/Turabian StyleYe, Qing, and Changhua Liu. 2023. "Simultaneous Fault Diagnosis Based on Hierarchical Multi-Label Classification and Sparse Bayesian Extreme Learning Machine" Applied Sciences 13, no. 4: 2376. https://doi.org/10.3390/app13042376