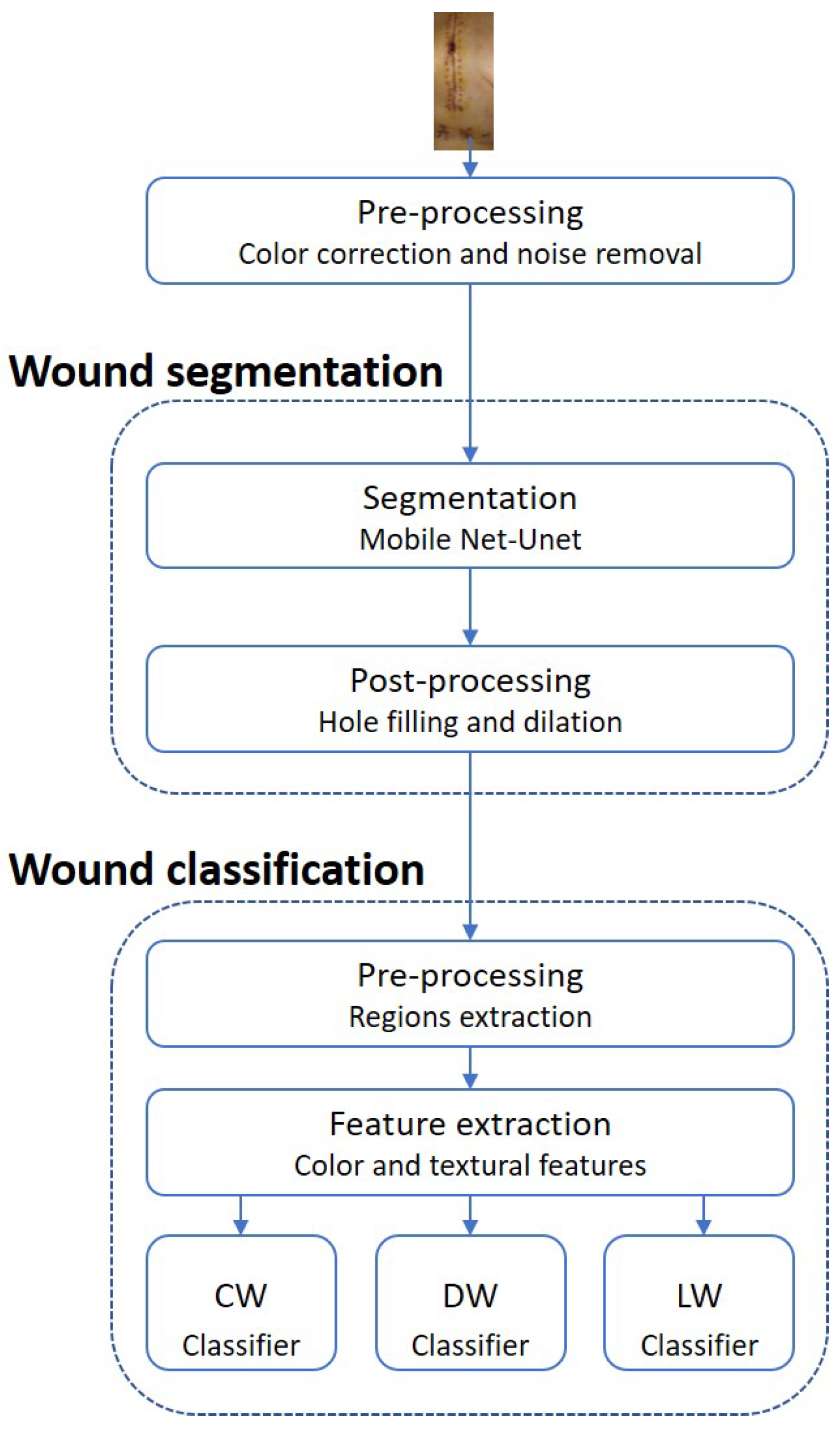
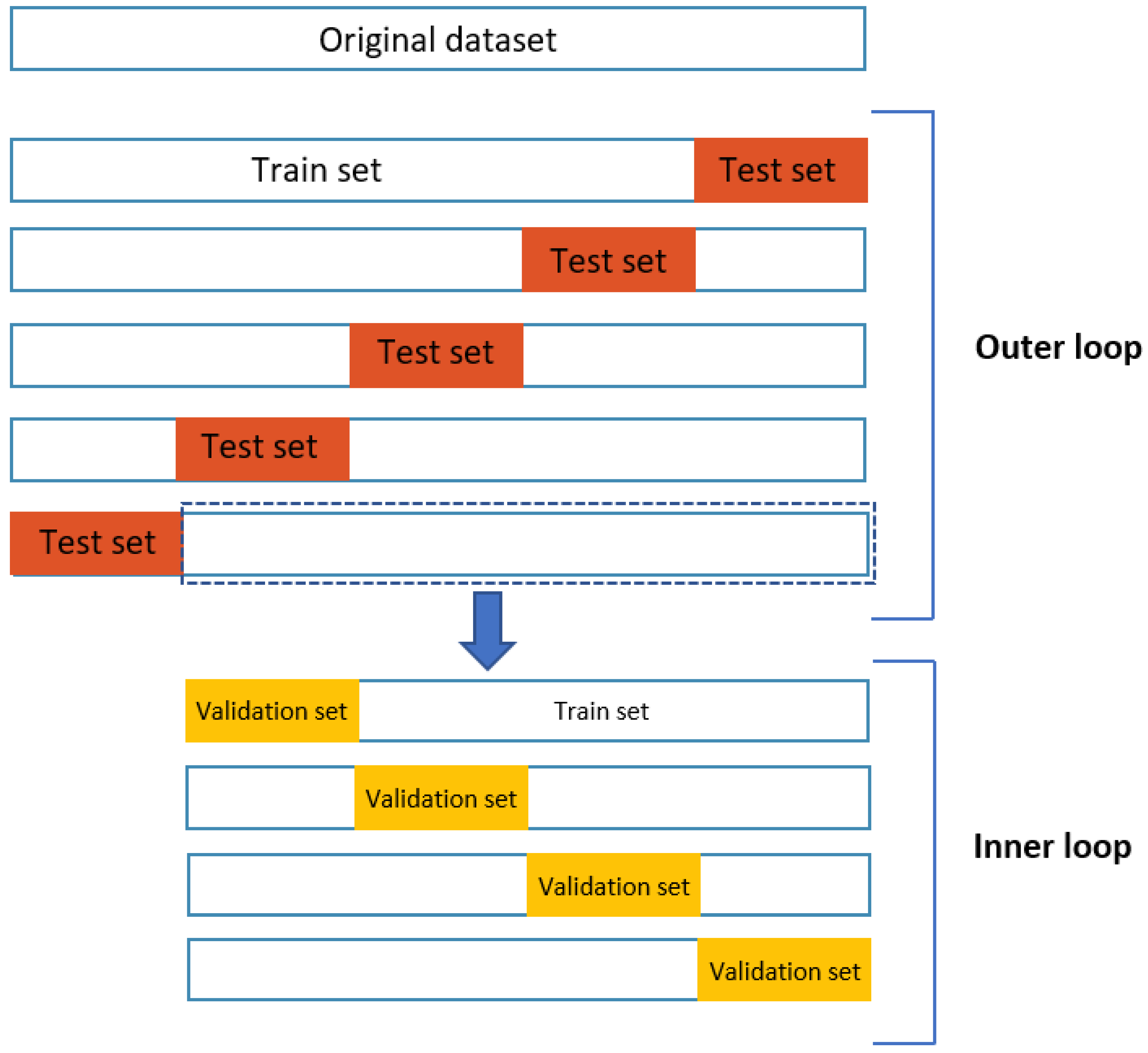
5.1. Wound Segmentation
MobileNet-Unet was the selected architecture for the wound segmentation model due to its good performance and advantageous characteristics. It achieved 82.06% ± 0.55% mean IoU when tested on the five test folds. MobileNet is a widely used structure with low memory requirements, high processing speed, and fewer parameters than other networks, which can be highly beneficial for this specific type of problem and for the future applications of this work. In terms of the decoder’s frameworks, there is no way to distinguish the best network because SegNet had a significantly better score than Unet for ResNet50 but worse for MobileNet, in which there is only a slight variance between both.
The reported results demonstrate that the Adam optimizer’s best batch size is 32, which is corroborated by [
38], who suggested a 32 batch size was a reasonable default value. Commonly, larger batch sizes lead to poor generalization and can take a long to reach the optimal minimum. On the other hand, smaller batch sizes have shown faster convergence because they allow the model to start learning before seeing all data. Nevertheless, the model may never reach the optimal minimum. The presented outcomes on smaller batch sizes agree with several authors [
39,
40], which stated that a smaller batch size should be used. In addition, there is a high correlation between the learning rate and the batch size, where larger batch sizes perform better with high learning rates. In the present segmentation model, there was no optimization regarding the learning rate; the default values were 0.001 and 0.01 for Adam and SGD, respectively. Hence, these low learning rates demonstrated their better performance with the experimented small batch sizes. Regarding the optimizer’s choice, Adam is already an upgrade of SGD, which was proven for this dataset with the exhibited mean IoU. Regarding the reported results, the MobileNet-Unet architecture achieved its best performance with the Adam optimizer, a 32 batch size, and 50 epochs.
Data augmentation aims to improve the generalization of a model by artificially inflating the training dataset size with transformed data, introducing more information for the model to learn. However, the results remained the same with and without augmentation, concluding that the augmentation had no significant effect on the dataset. There are two possible explanations for this occurrence: a large number of data samples and the misrepresenting image transformations. Other combinations of geometrical and color modifications can be tried in the future to see if the model improves beyond its achieved performance.
Regarding the wound segmentation model, since the IoU metric penalizes the badly classified instances harder, it is the best metric to evaluate the proposed system along with the final mean average precision. It is vital not to have bad segmentation results since these can penalize and lead to wrong final classifications, such as FN, which can cause a wound with actual alterations to be overlooked by clinicians. Hence, it can be concluded that the segmentation system achieved a good score and performed well on the proposed task. The final average precision of the segmentation, 90.1%, shows promising results in the pixel-wise classification made by the segmentation model, which is extremely important for dividing the several wounds along the three classifiers. In addition, it indicates that the system seems suitable for our purpose.
5.2. Wound Classification
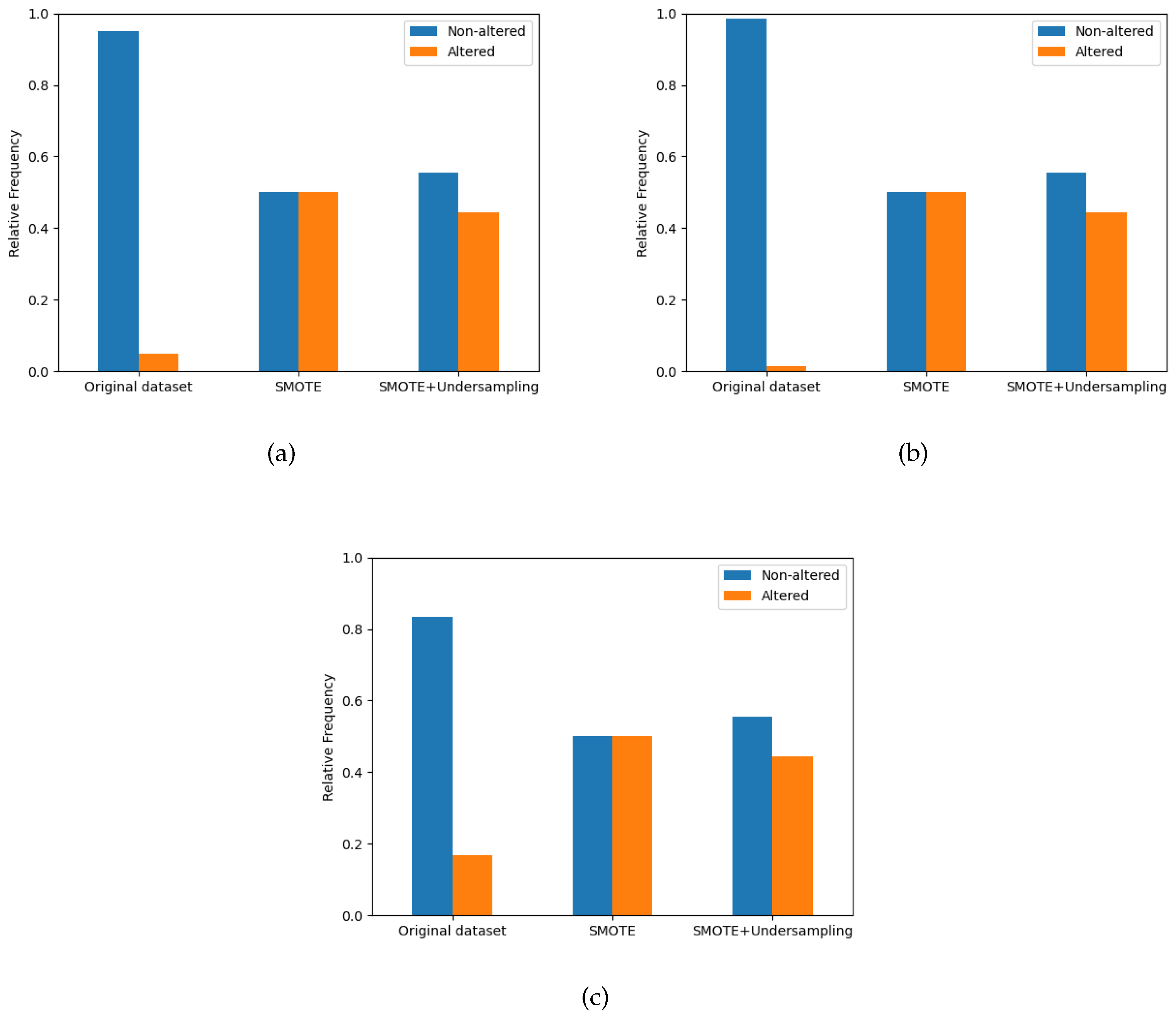
Applying methods that address class imbalance improves the performance of the models. In terms of the two trials conducted to balance the class distribution, the SMOTE technique combined with undersampling achieved better overall results than the single SMOTE method. However, the best type of technique to balance data is not equal for every classifier. The SMOTE technique had better scores for the LW classifier, while for CW and DW, the SMOTE + Undersampling was better. As the number of LW samples and the ratio between classes are smaller than in other wound types, the undersampling may eliminate important information regarding the negative class. Thus, the performance is slightly lower when compared to the use of SMOTE alone.
On the other hand, the CW and DW datasets are more extensive, so removing data points is less critical because there is more information regarding the majority class. Even though the oversampling techniques improved the model’s performance, some flaws must be considered. SMOTE generates a lot of noisy artificial samples in the feature space, which can increase the number of data points in the boundaries between the two classes, confusing the classification algorithm. In addition, the increase in samples may result in overfitting the model.
The number of features varies within each wound type classifier, suggesting that every wound type could have different representative features. Certain features may be more appropriate to characterize a specific wound type than another. However, the variance in the feature number is visible within the same type of classifier.
Table 6, shows that the CW algorithm needs less number of components, 20 and 30, compared with the other types, indicating that the boundaries between the two classes are well-defined and that the alterations in the wounds are visually notorious.In contrast, DW needs more features to predict changes in the wound correctly and reports a lower performance when compared with the other classifiers. This can be interpreted as the substantial portion of the features extracted sharing similar values between the positive and negative classes, which can be explained by the few DW alterations being very hard to differentiate. Lastly, the LW algorithm varies the number of needed components from 50 to 60. It shows the best performance among the three classifiers, suggesting that the variations in the images between both classes are considerable and well-categorized.
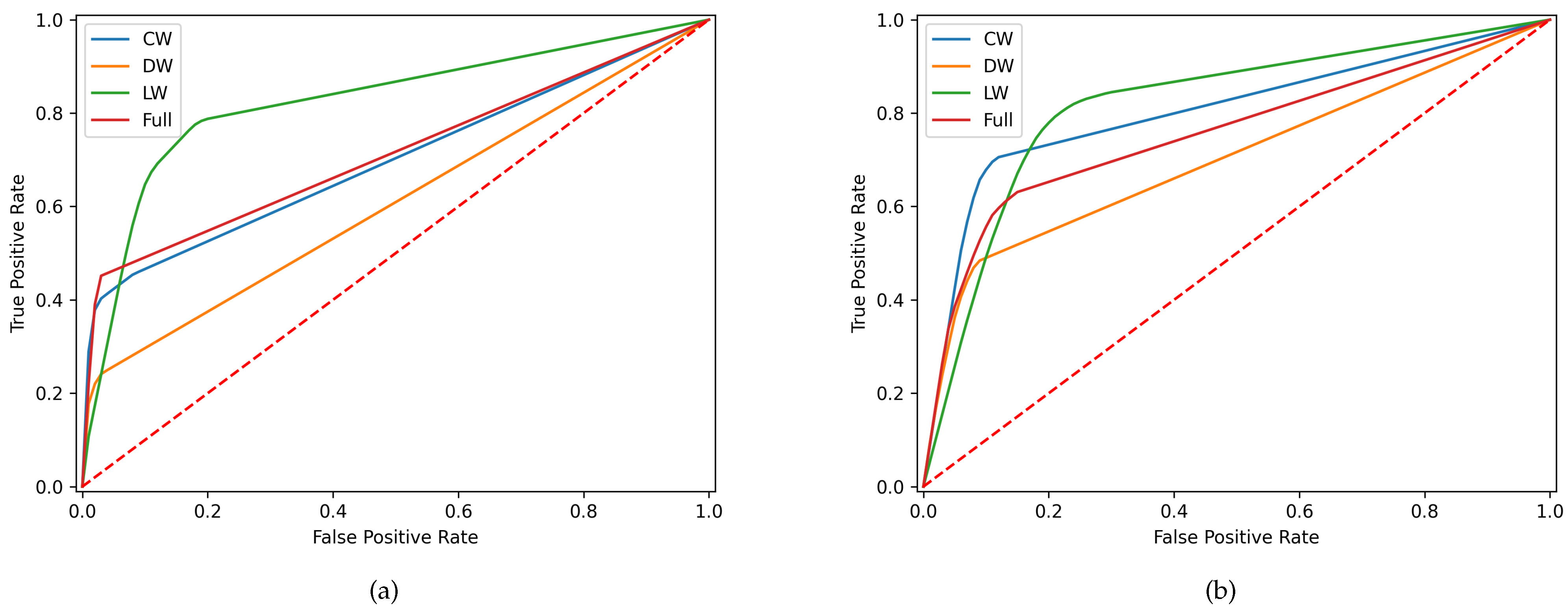
The reported metrics of the wound alteration classifier show a high standard deviation, except for accuracy, due to the high number of obtained folds for validation and testing. Hence, the selection bias is minimal, but the evaluation performance variance is considerable. As expected, the models optimized with the F1 score have more balance between precision and recall, while the optimization with the F2 score compromises the precision to obtain a higher recall. All models achieved a good accuracy, but as mentioned, it is a biased metric even after the application of oversampling because the test data is unaltered; so, there is still a superior number of samples for the negative class.
From all model types, the DW classifiers had the worst performance for both metrics, while LW achieved the best scores. Regarding the F1-optimization, DW obtained poor results, below 50%, for precision, recall, F1, and F2. The performance slightly improved for the F2-score, reaching a recall of 68.4%; however, the remaining metrics, except accuracy, still showed bad results. The poor results for the DW classifier can have two possible explanations: the significant discrepancy in the number of data samples between classes in the test set and the few differences presented between characteristics of positive and negative classes. The quantity of DW that has an alteration is low, meaning there are few examples of DW alterations. In CW, the scores already surpass the 50% barrier, except for the precision for the F2-optimization. The differences between F1 and F2 scores for both optimizers are low, while precision and recall are higher. Ultimately, the LW showed a higher overall score for all metrics and a recall of 87.6% for the F2-optimizer. However, it has the worst accuracy, which may be because LW has the lowest ratio between positive and negative classes; as such, the accuracy metric is less biased and corresponds more to reality.
The better performances by the LW and CW can be interpreted by the more considerable visual variances between the positive and negative classes, where the alterations of the wounds are more visible than in DW. It also corroborates that characteristics that indicate wound alterations can differ for each wound type, confirming the need to separate the wound classification problem into three classifiers.
Lastly, by comparing the performance between a single classifier and the three proposed, it can be concluded that the single classifier achieves a worse performance. Thus, it cannot be considered the final classification model.
The reported results and the discussion have some essential points of information that need to be addressed. As previously mentioned, a high number of FNs can be highly prejudicial to the proposed system, causing worrying alterations to be overlooked by the clinicians. For this reason, the best ML algorithms were selected based on the F2 optimization since it gives a higher weight to the recall metric. Hence, for the CW classifier, the RF algorithm with 50 feature components had the best performance with the following hyperparameters, entropy criterion, 1000 number of estimators, and with auto maximization of features. The SVM algorithm with regularization parameter (C) of 1, with rbf kernel type and an auto kernel coefficient (gamma), gave the best scores for the DW classifier with a total of 70 features. Lastly, the LW classifier utilized 60 features and elected the KNN algorithm with 5 nearest neighbors. The distance between them was measured by the minkowski metric, and the uniform weight function was used to make the predictions.
In summary, the LW clearly had the best performance, while the CW and DW need some improvements to obtain good predictions. As such, the LW classifier is acceptable for being implemented in the system, but overall, the classification needs improvement to be integrated into a real context. The use of oversampling techniques addresses the class imbalance problem by creating synthetic samples. However, the application of the SMOTE algorithm has to be cautious because artificially synthesized data may create unrealistic data samples that diverge from the actual dataset. Another essential consideration to consider is the lack of generalization present in the classification dataset. Besides the low amount of wounds belonging to the positive class, this reduced number is very biased because the same wound alteration is repeated for the same individual in the following images until a proposed treatment starts to have effects.
To the best of our knowledge, this is the first research work that applies artificial intelligent methods to assess surgical site infection in cardiac surgery based on images collected by patients themselves in a remote patient monitoring service. Related works were not trained with our type of wounds; most of them are related to burns or ulcers, which is the reason for not being able to present a fair comparison of our results with other related work.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







