CMMTree was the main framework defining the structure and mechanism of operation of all the software we created. This solution allows building trees reflecting various relationships between the processed data.
To test our solution, we choose well-known protocols such as Andrew Secure RPC protocol [
36] (Andrew), Lowe modified BAN concrete Andrew Secure RPC protocol [
37] (Andrew
), Carlsen’s Secret Key Initiator protocol [
38], KaoChow v1 protocol [
10], Needham Schroeder Public Key protocol [
7] (NSPK), Needham Schroeder Symmetric Key protocol [
7], Wide-Mouthed Frog protocol [
39], Lowe modified Wide-Mouthed Frog protocol [
40], Woo Lam Pi protocol and its first, second, and third versions [
9], Yahalom protocol [
39], BAN simplified version of Yahalom protocol [
39], Lowe’s modified version of Yahalom Lowe’s protocol [
41], and Paulson’s strengthened version of Yahalom protocol [
42].
4.1. Properties and Functionalities of the CMMTree Model
In this section, we would like to present in the shortest possible way what CMMTree is, that is, an original solution; it has already been described in more detail in [
14]. Although we are aware that some of the information presented here will repeat what is written in [
14], we have decided that in the context of the entire work, a brief description of this solution is necessary. This is because CMMTree is a general tool designed to build and analyze multi-way conditional trees, and its key component is the predicate function, which can be formulated in many ways—better or worse—as we will try to show in the following sections. We deliberately decided to use many of the same symbols or phrases (as in [
14]) so that a person who wants more details about CMMTree can quickly find them in [
14].
In general, the CMMTree logic model is described by:
where:
is a collection of a unique input data values;
is the tree structure of relationships between input data;
is a predicate that defines the rules for joining nodes.
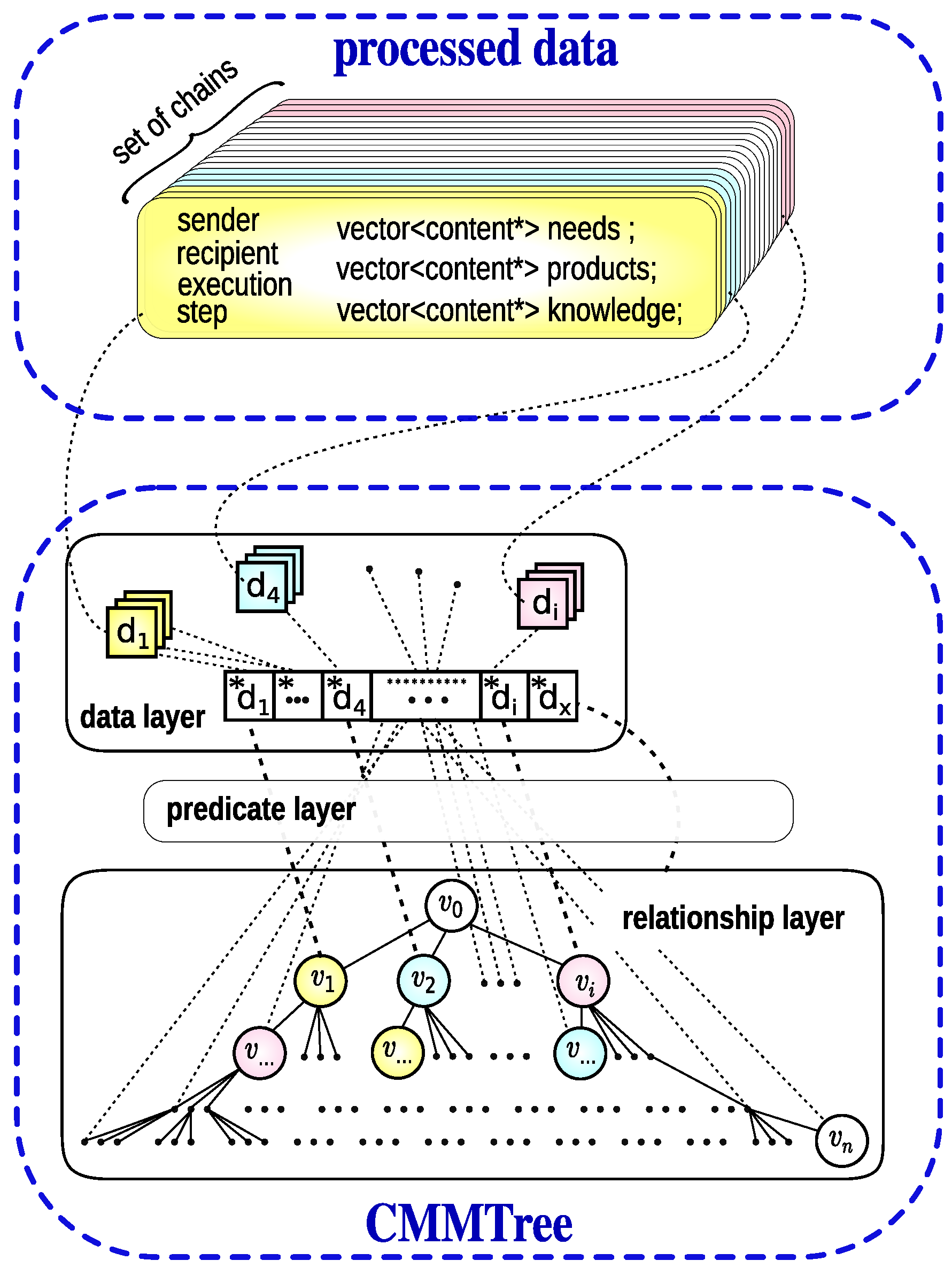
In this model, three layers are clearly distinguished (see
Figure 1): the data layer, predicate layer, and relationship layer. The elements of the input dataset
should be unique; however, their representations (references to individual values) may occur multiple times in the
structure. For example, in
Figure 1, node
represent the value
, node
the value
, and so on.
The processed data are not required to be exactly the same type, and they can generally be of different types as long as they belong to a defined class hierarchy. A vector of pointers to them can easily represent such a set of data—see
Figure 1. In the present case of the study of cryptographic protocols, the input data were a set of chain objects, described in
Section 4.2.
The rules for joining subsequent nodes of the tree
are defined in a two-argument predicate function
p:
where:
Each decision on whether another node can be attached is made based on the information accumulated so far in tree and the information provided by candidate . The amount and scope of information taken from the tree can be varied. Data can be extracted from a single node, nodes on a path, as well as any other combination of nodes. Moreover, if the analyzed data form a class hierarchy, then information about the type of an object or group of objects can also be used by the predicate function p and (if necessary) will be able to operate polymorphically at run-time. The predicate function p (PF) must always be defined. As said before, the situation in which it returns a true value may depend on the required or already existing structure of the relationship between the data. In the simplest variant, p can always return false, but in this scenario, tree will consist of only the root node. Such an implementation of the p function, although not interesting from a practical point of view, is very helpful in the process of code development and testing.
There are many ways to implement multi-way trees, and some of the most commonly used include
left-child/right-sibling [
43,
44,
45,
46] (also known as
first_child/next_sibling [
47]),
array of pointers [
44], and
dynamic array-based list of child pointers [
45]. In CMMTree, however, a different solution was used. All nodes of tree
are free-stored objects, allocated on the heap. CMMTree does not use node linking specific to binary tree linking [
43,
44,
45,
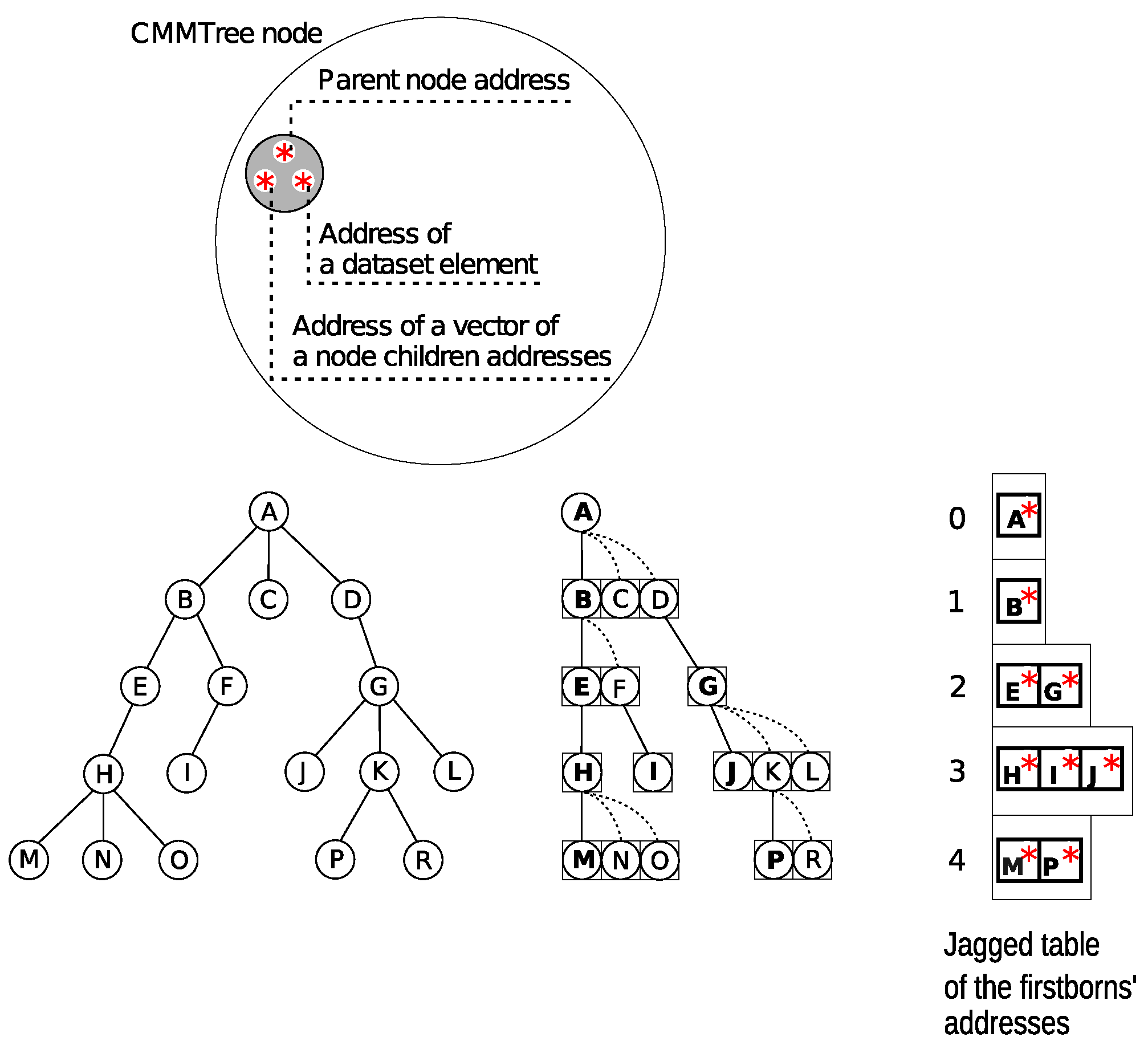
47]. Each node (except the root) stores the address of its parent and the address of a dynamic vector containing the addresses of its children—see
Figure 2.
Each node also stores the address to the appropriate element of the input dataset . In this way, data from the data layer are isolated from the structure created in the relationship layer. Since each node has the direct address of its parent, it is possible to directly determine paths (from a given node to the root) in O(i) time.
The tree construction algorithm was implemented using the level-order strategy. However, unlike the traditional approach [
46,
47,
48], in which the set of nodes from the last level of the tree is remembered, a custom solution was used in which the set of addresses of only the firstborn nodes is stored [
14]—see
Figure 2. By using the address of any firstborn node, we gain access to its parent, the parent’s children, i.e., siblings of the firstborn, the parent’s parent, and so on. Gaining access to the selected node, we immediately know what the size of the vector of addresses of its children is, that is, how many children it has or that it is a leaf. If we have a set of addresses of all the firstborns of one level (
l) of the tree
, we can also determine the number of all nodes of this level and the number of leaves. Consequently, the set of firstborn addresses from all levels of the tree (see
Figure 2) maps the entire structure
. Thus, we can see that the single-node structure presented earlier as well as the implementation of interconnections between nodes makes it possible, with the help of firstborn node addresses, to “look deep” into any part of the tree. This eliminates the need for time-consuming traversing of the tree, which in traditional solutions would always have to begin from the root node.
The collection of addresses of all firstborn nodes (see
Figure 2, jagged table) is a kind of view of the whole tree
. The jagged table is indexed. Thus, it gives free access to the tree
of relationships existing between the input data. It directly provides information about the height
h of tree
:
as well as the number of firstborns (
) of the selected tree level
l:
By selecting any firstborn node address (from the jagged table), we can check the number of all the parent’s children
:
where
children_num() is a member function of the class
node. We can also gain direct access to the brother or sister
:
From the above, we can see that each address of the firstborn node (MTree[l][j]) maps a particular group of nodes, i.e., the parent and its children. This means that the set of addresses of all firstborn nodes maps the entire tree .
Using Formula (
3) allows us to determine the total number of nodes
of the selected tree level
l, and Equation (
4) can be used to determine the total number of leaves
at this level.
As a result, the shape of an entire tree
or forest
can be (parametrically) described using Formula (
5).
Thanks to the parametric form of the CMMTree shape description (
5), it is easy to identify nodes that have a significant impact on the shape of the tree. In this way, it is possible to selectively choose those places that should be analyzed first in order to obtain the relevant information. It is especially useful when the examined trees contain tens or hundreds of millions of nodes.
The research in [
14] also proposes other measures using
,
, and
parameters to facilitate the study of huge trees. In this study, these measures were used at the stage of PF optimization.
4.2. Primary Structures and Generalization of the Problem
The implementation of the CMMTree model is written in C++. Its main component is a two-parameter class template:
The first parameter (
X) is a
type parameter. It represents the type of data for which (as a result of source code compilation) a particular version of the CMMTree class will be created. The second (
pred_type) is a
template parameter, i.e., a template of the type parameter, that—in this particular case—is parameterized by the first parameter of the CMMTree class template. By the second parameter, a predicate is passed that specifies the conditions for connecting the tree’s nodes. More details on the implementation of the PF are provided in [
14].
Various types of so-called primitive structures are used to describe protocol specifications [
49,
50]. Each of these structures, to a greater or lesser extent, differs from the others regarding the scope of information stored and how to implement specific functionalities. For example, the decryption of messages encrypted with an asymmetric key and those encrypted with a symmetric key must be implemented differently. For this reason, at first glance, specifying only one type of parameter for a solution that is supposed to process many different types of data seems inconvenient. In practice, however, it is quite the opposite, because using the general programming technique allows the code developed in this way to operate on any data structure, provided that it meets certain syntactic and semantic requirements [
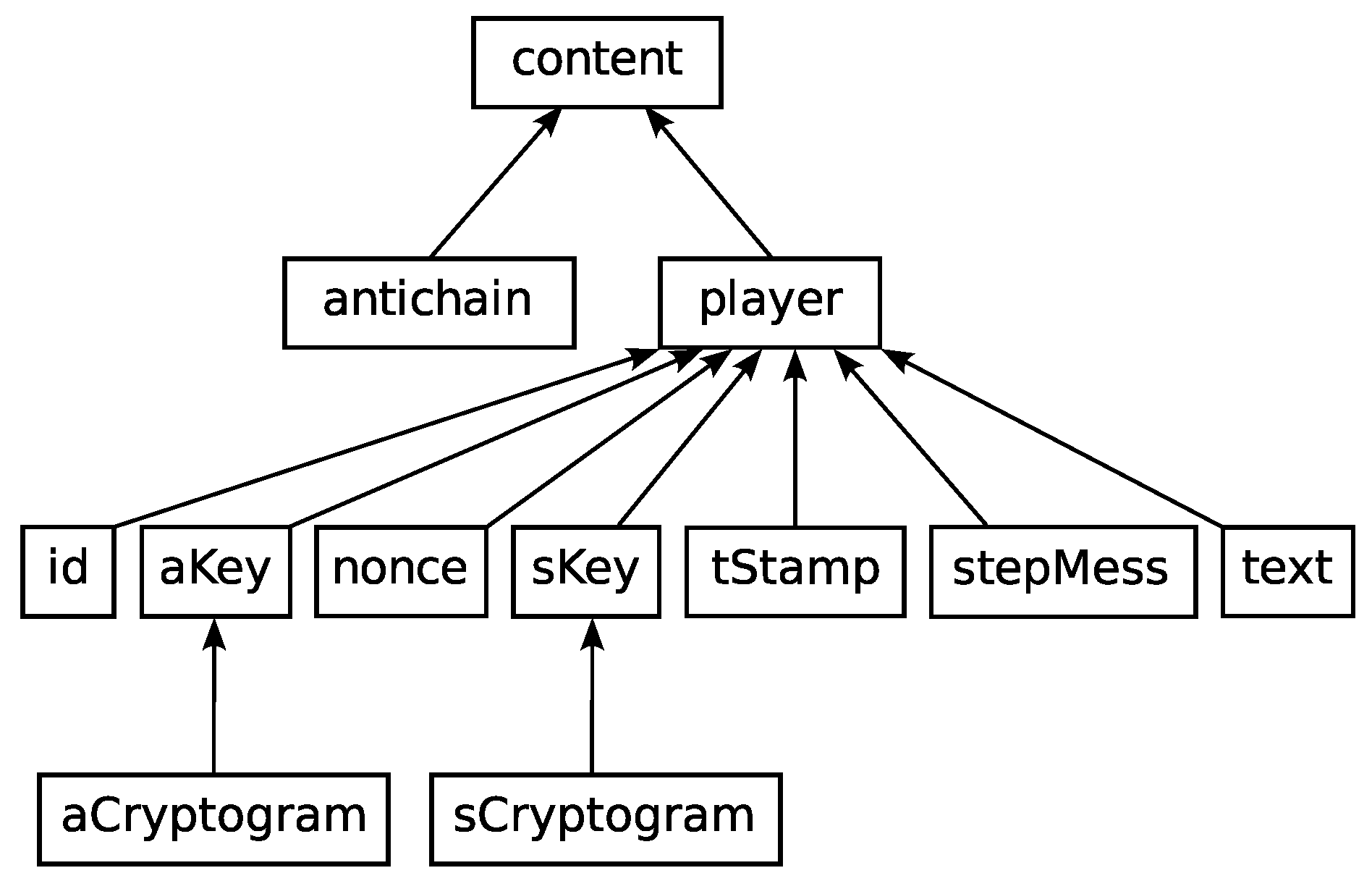
51]. Therefore, it was decided that the primitives used to record the input data would have to form a hierarchy of classes, shown in
Figure 3.
From the perspective of generalizing the problem of cryptographic protocol processing, the content class plays the main role. It is an abstract base class whose main (and only) task is to provide a common interface for the other derived classes. Appropriate objects of derived classes store the real data.
Table 1 presents brief information on classes inheriting from the content class. If only because of the volume, their detailed description goes beyond the scope of this work. However, how objects of these types are used is important. Therefore, to be able to use the described solution for examining various protocols, the input data (steps of generated protocol executions) are converted into the
chain type—see
Figure 1.
class chain{
player sender, recipient;
int execution, step;
std::vector<content*> needs, products, knowledge;
/* … */
};
Table 1.
Class hierarchy prepared for protocol predicate.
Table 1.
Class hierarchy prepared for protocol predicate.
| Class | Description |
|---|
| player | information about honest and dishonest protocol participants |
| antichain | information about the ways of step execution by Intruder |
| id | information about the identifiers of protocol participants |
| aKey | information about users’ asymmetric keys |
| nonce | information about the random number that is used only once during the protocol execution |
| sKey | information about users’ symmetric keys |
| tStamp | information about the user timestamp that indicates the moment of the message creation |
| stepMess | information about messages sent during the step |
| text | information about the message part that will be sent as plain text |
| aCryptogram | information about cryptogram encrypted by asymmetric key |
| sCryptogram | information about cryptogram encrypted by symmetric key |
In this class, all information, the quantity, type, and scope of which are not known beforehand, is represented by the vectors of pointers to the
content type. Having the addresses of individual objects, the polymorphism of virtual functions and the RTTI (
Run-
Time
Type
Information—a mechanism that provides information about an object’s data type at run-time) mechanism [
51] can be employed to extract detailed information specific to the actual type of data being processed.
Vector needs represent (that is, contain the addresses of the relevant objects) a collection of objects that the sender needs to complete a step. For example, this vector may contain addresses of nonce, tStamp, aCryptogram, or sCryptogram class objects. However, it cannot contain addresses of objects that represent publicly known objects to protocol participants (public keys, identifiers).
Vector products represent objects that the sender must generate before the protocol step execution. These objects are also needed for the sender to complete the protocol step. Usually there are addresses of objects of type tStamp, nonce, or sKey.
The knowledge vector is intended for objects containing information the recipient learns during a given protocol step. For instance, these can be objects of classes nonce, tStamp, or aCryptogram.
The antichain class refers to objects representing how an Intruder can execute a protocol step depending on his knowledge. For example, if an Intruder should send the following message according to the execution structure, he has two possible ways to execute this step. Firstly, he can send the message if he knows the entire ciphertext. In a second method, he can send the message if he has in his knowledge each element forming a ciphertext (, , and ). Analogous to the chain class, vectors of pointers represent the primitives whose actual type can be known only during input processing to the content class.
At the predicate optimization stage, we used lexicographic sorting of protocol executions. The consistent use of a specific order of marking executions and steps definitely facilitates the analysis of both the tested protocol and the PF code under test. We compared the obtained ETs with trees built for randomized data to check the performance of the created PF.
Each analyzed chain is uniquely identified by a pair of . The key to sorting the execution of the protocol is information identifying players and information provided by sets of cryptographic objects that the Intruder can use during the execution of the protocol.
Also, it is worth mentioning that our methodology considers four Intruder models. The set of executions contains honest and dishonest (with Intruder) executions. Executions with Intruder are generated for the following Intruder models:
Dolev-Yao model—in which the Intruder controls the network, accesses transmitted messages, can intercept, block, and process messages against the protocol, but requires a decryption key for ciphertext information [
52].
Lazy Intruder—which can be considered a type of virus that can deliver complete messages, yet cannot alter or modify them [
53,
54].
Restricted Dolev-Yao—enabling a feature that the Dolev-Yao Intruder may only access messages specifically directed to them [
5].
Restricted Lazy Intruder—enabling a feature that the Lazy Intruder may only access messages specifically directed to them [
5].
For example, in the NSPK protocol, we have two players (
A and
B). We add an Intruder (
I) to the players’ set. The sorted player set has an Intruder on zero indexes. Next, based on the players’ set, we generate a set of all possible executions using variations without repetition. In this way, we obtained the following sorted set of executions (using sender → recipient designation):
Also, for each mentioned execution with the Intruder, we generate three parallel executions different from each other by cryptographic primitives used by the Intruder. For such an ordered set of possible protocol executions, one of the four paths containing an attack on the NSPK protocol will be represented by steps (10,1), (8,1), (8,2), (10,2), (10,3), and (8,3), i.e., step one of execution no. 10, step one of execution no. 8, and so on.
We prepare the set of chains (SoC) for all possible protocol executions. Each chain has this same structure as described earlier. The content of each vector may be complex, and everything depends on the protocol structure.
Table 2 and
Table 3 present two fragments of the SoC for protocol execution involving an Intruder. Both tables have the same structure. Column
Send. → Rec. contains information about the sender and receiver in the current protocol step. Column
Execution & step includes execution and step number information. The rest of the columns (
Needs,
Products, and
Knowledge) contain information about the content of corresponding vectors.
Table 2 contains the chains for execution no. 1 generated for the NSPK protocol in Alice–Bob notation. Each chain from this execution consists of each part described earlier in this section, separated by semicolons. The Intruder is a sender in the first and third steps, so he can execute each of these steps in two ways (sending the entire ciphertext or the ciphertext composed using his knowledge).
Table 3 contains the chains for execution no. 9, generated for the KaoChow protocol in Alice–Bob notation. The KaoChow protocol has a different and more complex structure than the NSPK protocol, so this chain contains more entries and objects in individual vectors. The Intruder is a sender in the third step only, but he can execute this step in four ways when his knowledge contains the following objects:
two entire ciphertexts;
the objects from the first ciphertext and the entire second ciphertext;
the entire first ciphertext and objects from the second ciphertext;
the objects from both ciphertexts.
In our opinion, the above-described method of combining many different data types into a hierarchy of classes that inherit from a very general base class is a very flexible solution. If a new data type appears, it is enough to “put” it in the right place in such a hierarchy to be able to study the impact of the new data on the overall structure of the relationship between all data. However, in each case of the use of any particular non-abstract type of data, we assume that it is provided with the right set of functionalities—that is, functions which, if necessary, can “cooperate” with other types of that hierarchy.
4.3. Predicate Function: Searching for the Best Possible Solution
The predicate function
p (
2) (PF) plays a key role in the CMMTree model (
1). The rules for connecting successive tree nodes written there will directly impact the correctness of the obtained results and the data analysis time. It will depend on these rules whether analyzing a given problem at all with specific computing resources will be possible.
For such special data as chains of protocol executions, the use of only rules “for yes”—according to the general principle (if the conditions are met, the node can be attached)—is clearly insufficient. This is due to the fact that the ETs will grow to gigantic sizes, and very often, they will grow indefinitely. Therefore, rules “for not” are also necessary for the PF, to allow effective pruning of “non-perspective” branches during the construction of the ET.
One of the main goals of this work was to develop and test a tool that would allow the study of various cryptographic protocols. Therefore, it was necessary to find a compromise between a solution specialized for a specific protocol and a generalized solution allowing processing and analyzing a broader spectrum of protocols.
We used an approach in which our solution (and related protocol analysis) was tested in four main stages.
The text-encoded protocol (in the ProToc language [
35]) was loaded into the program at stage one. There, its validation was carried out for the correctness of the writing. Then the protocol was converted into object (binary) form, according to the class hierarchy described in
Section 4.2. From this point on, all subsequent protocol processing was carried out using objects of this class hierarchy.
In the second step, the original form of the protocol was processed into a set of protocol executions. These executions were ordered lexicographically (at the stage of searching for the best possible form of the PF) or shuffled when a given form of the PF was evaluated.
In the third step, the input data were transformed into a set of chains, according to the methodology described in [
15,
16].
In the last—fourth—stage of our research, different variants of the protocol ETs were created and evaluated.
It was at this stage that the general CMMTree model—along with its functionalities (see
Section 4.1)—was concretized for the chain type containing primitives (see
Section 4.2) defining individual protocols.
We tested various conditions that decide the attachment of subsequent tree nodes. These conditions were evaluated for their impact on tree construction time and the time to find possible attacks, as well as their impact on the overall size of the ET.
We tried to prune the branches of each tree as much as possible (during its construction), ensuring that no important data were unnecessarily omitted at any stage of data processing.
As already mentioned, the executions of each tested protocol were first sorted lexicographically. Thanks to this, we were able to ensure the repeatability of testing conditions for both the protocol and the PF. Then, the tested version of the PF was run several times on randomized data. We used the std::mersenne_twister_engine algorithm [
55] to shuffle the set of chains of all possible protocol executions.
We considered a tested rule to be valuable (in the context of the entire predicate) if the use of a given version of the PF allowed us to:
We have also implemented mechanisms to prevent the tree from growing indefinitely, i.e., time safeguard and protection that controls the total number of nodes in the tree. The program stopped its work after saving all current results when 3 h of operation elapsed (for one protocol) or the tree reached one billion nodes. The values of these protections were determined experimentally for the computer we used. It was a desktop computer with an AMD Ryzen 9 3900X processor (12 cores, 24 threads) and 64 GB RAM, with the Linux Mint 20.3 operating system. The CMMTree construction algorithm has been implemented as a single separate thread of the program. Separate threads responsible for implementing the protections mentioned above did not block the processed data.
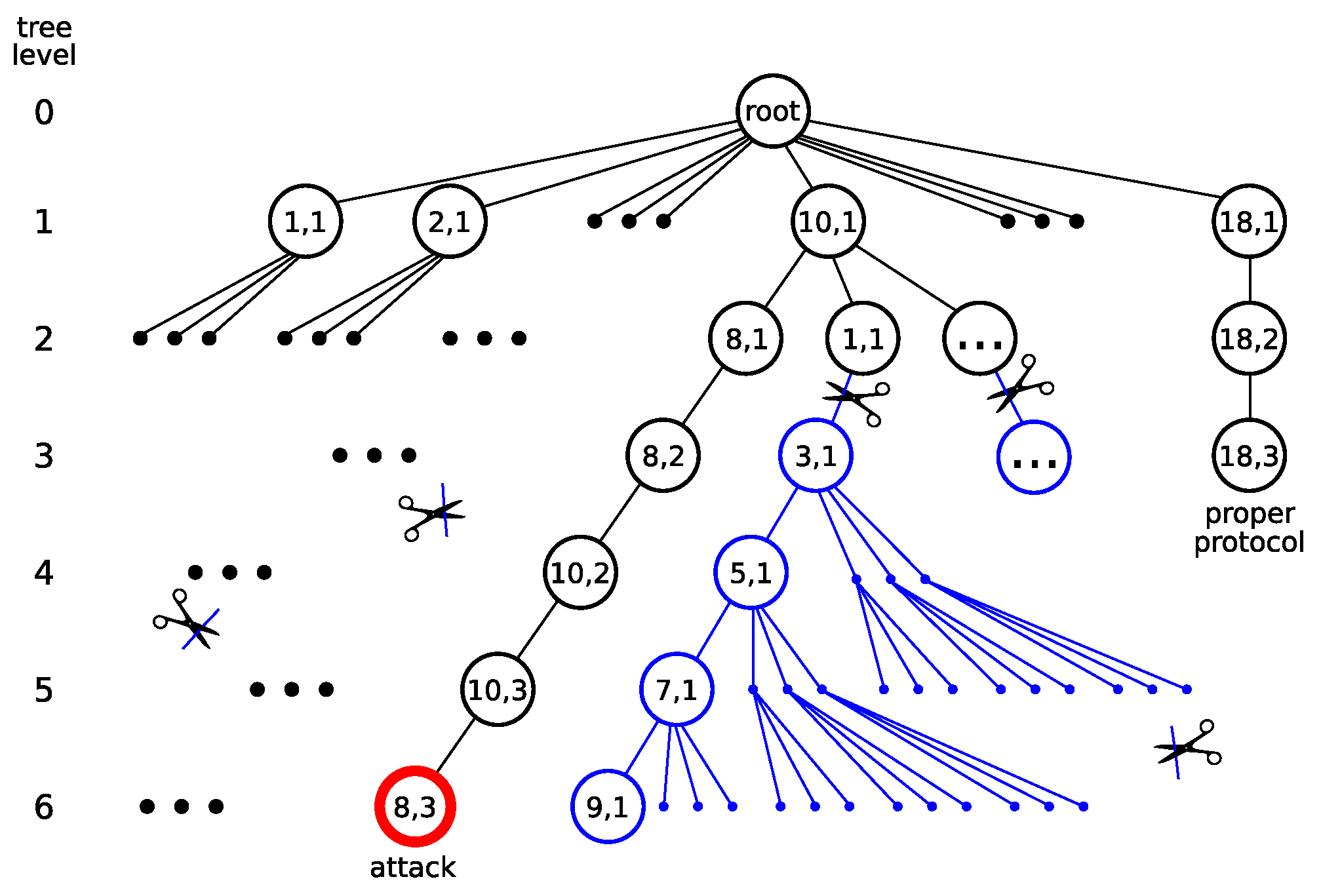
Figure 4 illustrates the main idea behind the pruning process of the protocol ET. An example is the ET (a small fragment of it, to be precise) of the NSPK protocol. Here we can see that the CMMTree is actually a forest, that is, a collection of the root node subtrees. This is a case where the CMMTree root node does not represent any element from the input dataset. The nodes corresponding to the possible executions of the first step of the protocol are the roots of these subtrees. CMMTree takes the form of a forest with other protocols as well. We also see two exemplary protocol paths, resulting in the execution of its last step, and one path that can be considered “non-perspective” and suitable for pruning. The path of steps (18,1), (18,2), and (18,3) is the proper realization of the protocol. The path of (10,1), (8,1), (8,2), (10,2), (10,3), and (8,3) is the realization of the protocol with the participation of the Intruder, which ends with a successful attack. The path of (10,1), (1,1), (3,1), and so on is not prospective because it does not guarantee the expected progress in the execution of the protocol. Furthermore, each of these nodes could be treated as the root of another subtree, and thus, the forest would grow to infinity.
Direct analysis of trees containing millions or tens of millions of nodes is beyond human perceptual capabilities—certainly beyond our abilities. Therefore, to evaluate the effects of our experiments, we used quantitative and qualitative measures describing the shape of created trees, as discussed in [
14]. These measures are based on the parametric form of the CMMTree description expressed by Formula (
5). Among other things, they allow us to immediately identify places where—in general—something happened, or something started to happen. Since CMMTree is a mapped structure, such a place can be reached in
O(1) time without traversing the entire tree, which would always have to start at the root.
In further explanations, we will also use:
Figure 5 and
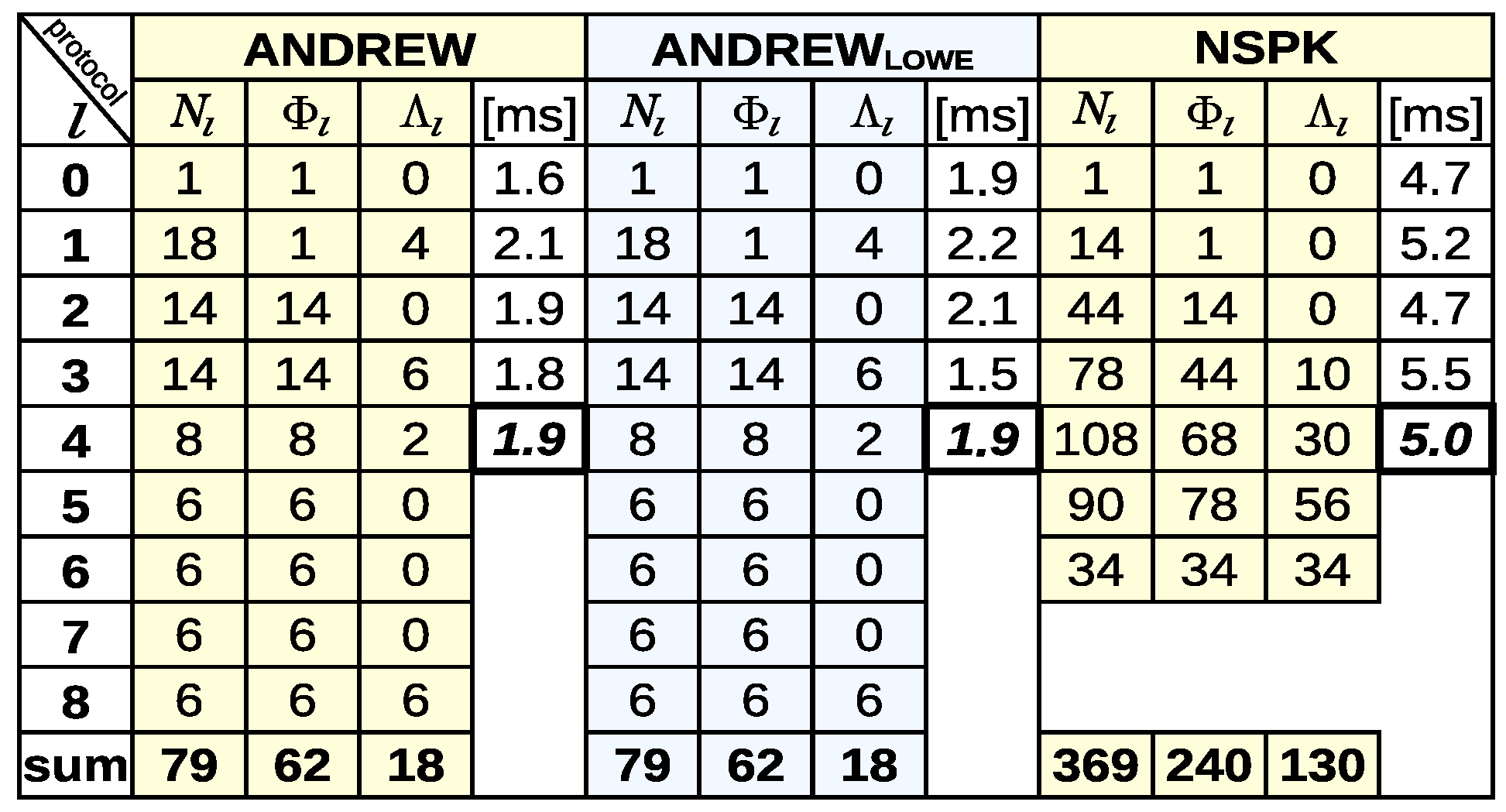
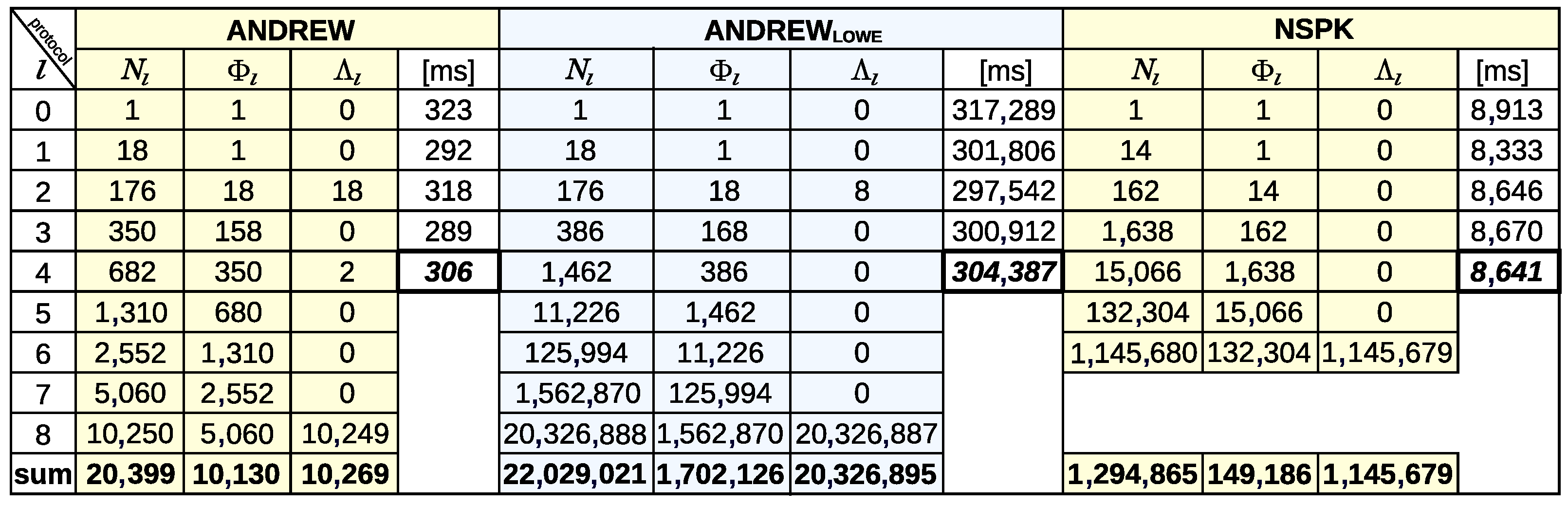
Table 4 portray three examples of CMMTree shape descriptions of the execution tree (ET) of the NSPK protocol obtained during the development of the predicate function (PF).
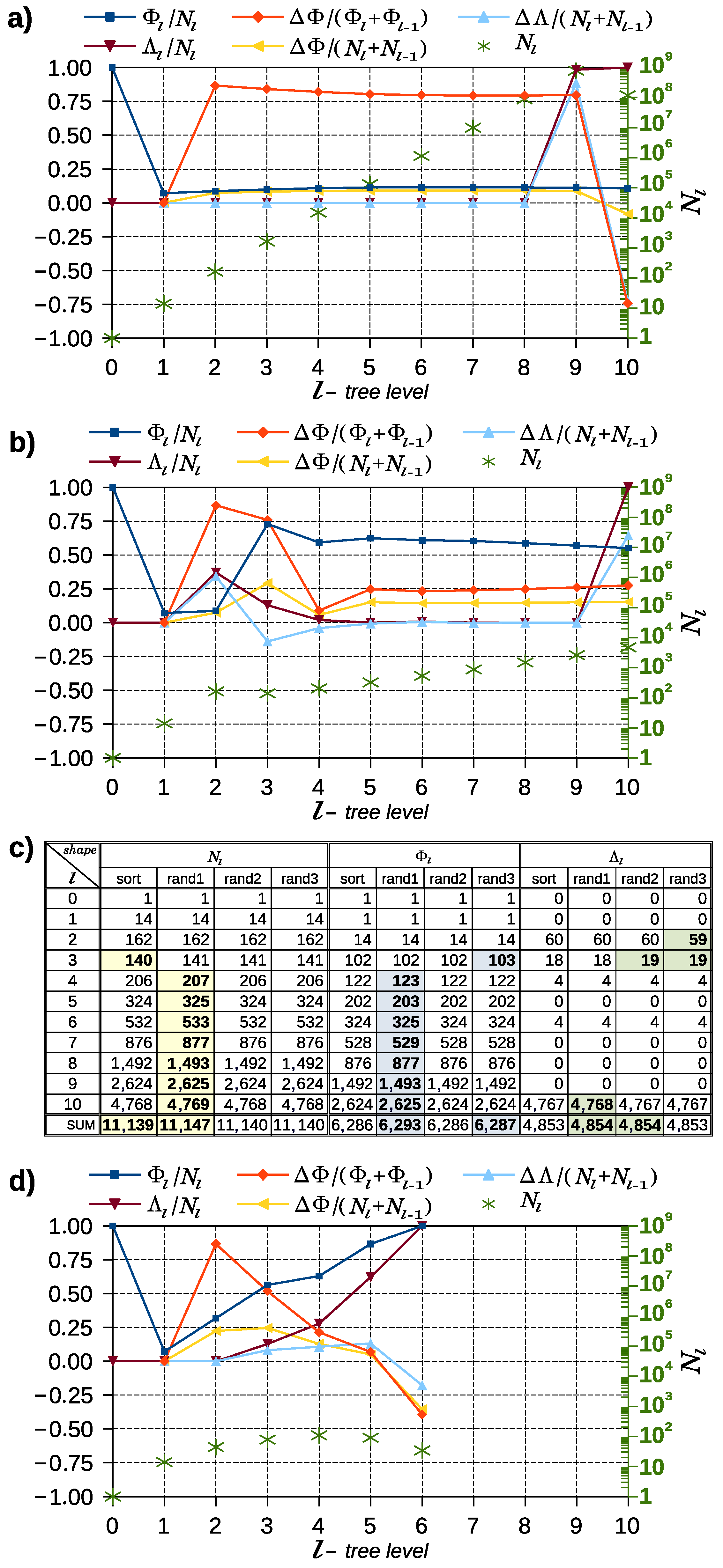
Figure 5a is an image of the ET constructed using the PF without conditions that cause the pruning of branches—without “for not” conditions. Tree construction was terminated (on tree level
) after exceeding the 1 billion node limit. The tree building time was almost 1005 s, and the entire CMMTree structure took 50.7 GB of RAM.
This graph clearly shows the exponential increase in the number of nodes at each tree level. Each level has an average of 10 times more nodes than the previous level. The tree grows almost symmetrically. Up to level 5, each node has descendants. This is obvious because the
, and consequently
measures (see
Table 4, part 1), have values equal to zero. As can be seen, the measure
runs nearby values of 0.1, so each node has an average of 10 children. A careful analysis of the
and
measures shows a slight decrease in the tree’s growth dynamics, but this tendency is practically insignificant. Most of the leaves appeared on level 9. This is directly due to the activation of the safety mechanism against the unlimited growth of the tree.
Figure 5b presents a tree image obtained during the evaluation of one of the variants of the PF using a lexicographically sorted set of input data. As in the previous case, the tree construction was terminated at level 10. This time, however, it resulted from activating one of the “for not” conditions, one of the applied pruning conditions (PCs). The tree contains 11,139 nodes. It was built in 65 milliseconds. Four expected attack paths were found in this tree.
Comparing
Figure 5a,b, we can immediately see that the use of a few other PCs significantly changes the size and shape of the ET that is created. If we look at the measure
, we can see that from level 3, its value is greater than 0.5, meaning that from level 2, the average parent node has no more than two children. By analyzing the
measure, it can be seen that pruning at levels 2 and 3 proved to be the most important. Thirty-seven percent of level 2 nodes and almost thirteen percent of level 3 nodes are leaves. The identified four leaves at level 6 (see
Table 4, part 2) correspond to the four executions of the protocol with a successful attack.
Despite finding attack paths (also for shuffled data) and a huge reduction in the number of tree nodes and their construction time, the examined PF could not be considered satisfactory by us for two main reasons. First, if the condition interrupting the tree’s construction at level had not been applied, it could have continued to grow. No leaf was identified for the next three levels of the tree; the and measures have values equal to zero. This means that none of the tree’s other branches have been pruned, i.e., none of the remaining paths have been terminated. The second reason was the change in the parameters of the tree shape description after applying the input data shuffle operation.
Figure 5c shows a table of the parameters of the CMMTree shape description for sorted data and three samples of shuffled data. We can see that changing the processing order of chains of the protocol executions caused (small, but noticeable) changes in parameters
,
, and
. Nevertheless, this should not be the case when processing the same data.
Figure 5d presents the description of the CMMTree shape obtained using the final form of PF. This tree contains 369 nodes. It was built in about 5 milliseconds, and the parametric description of its shape does not depend on the order in which the input data are processed. Its construction was completed at level
after exhausting the possibilities of connecting further nodes without using any additional PCs that would be conditions of a safeguard nature. This graph shows that parameter
reaches its maximum value at level
and then decreases. From level
, measure
takes on increasing values, meaning that more nodes of a given level become leaves. At level
, measures
and
take the value 1. This means that each node of this level is a firstborn node and has no more descendants.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









