
WIG-Net: Wavelet-Based Defocus Deblurring with IFA and GCN


Abstract
:1. Introduction
- (1)
- An end-to-end network for single-image de-defocusing is presented. Wavelet transforms are also incorporated into the encoding stage of the proposed network, reducing the feature map size while ensuring a wide receptive field.
- (2)
- IFA and GCN modules are introduced to increase the network’s depth, thereby enhancing the ability to reconstruct clear images.
- (3)
- A proprietary dataset is curated. In contrast to previous datasets, the proposed collection included a higher proportion of images with extensive defocus blur, alongside their corresponding all-in-focus images.
2. Related Works
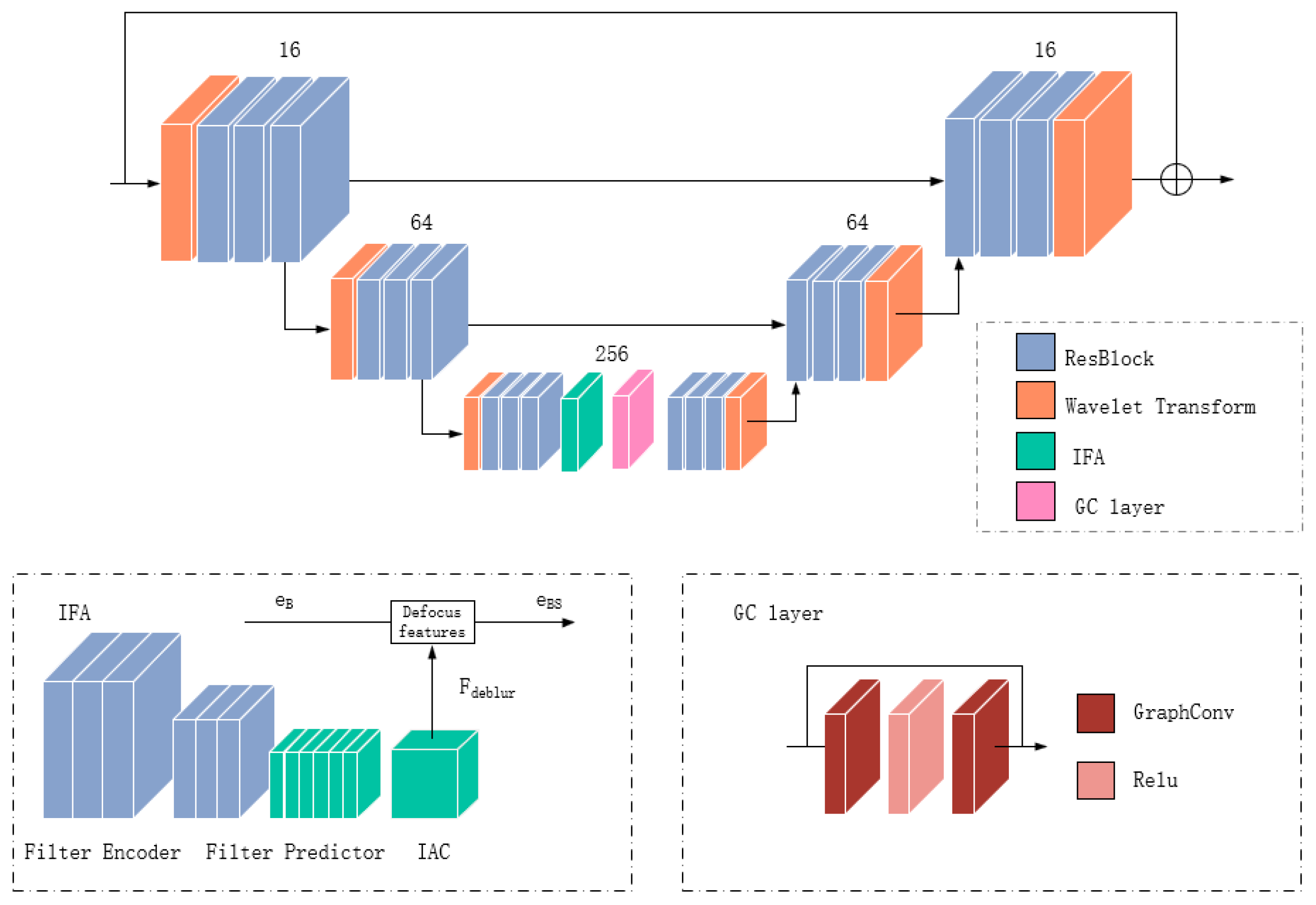
3. Methods
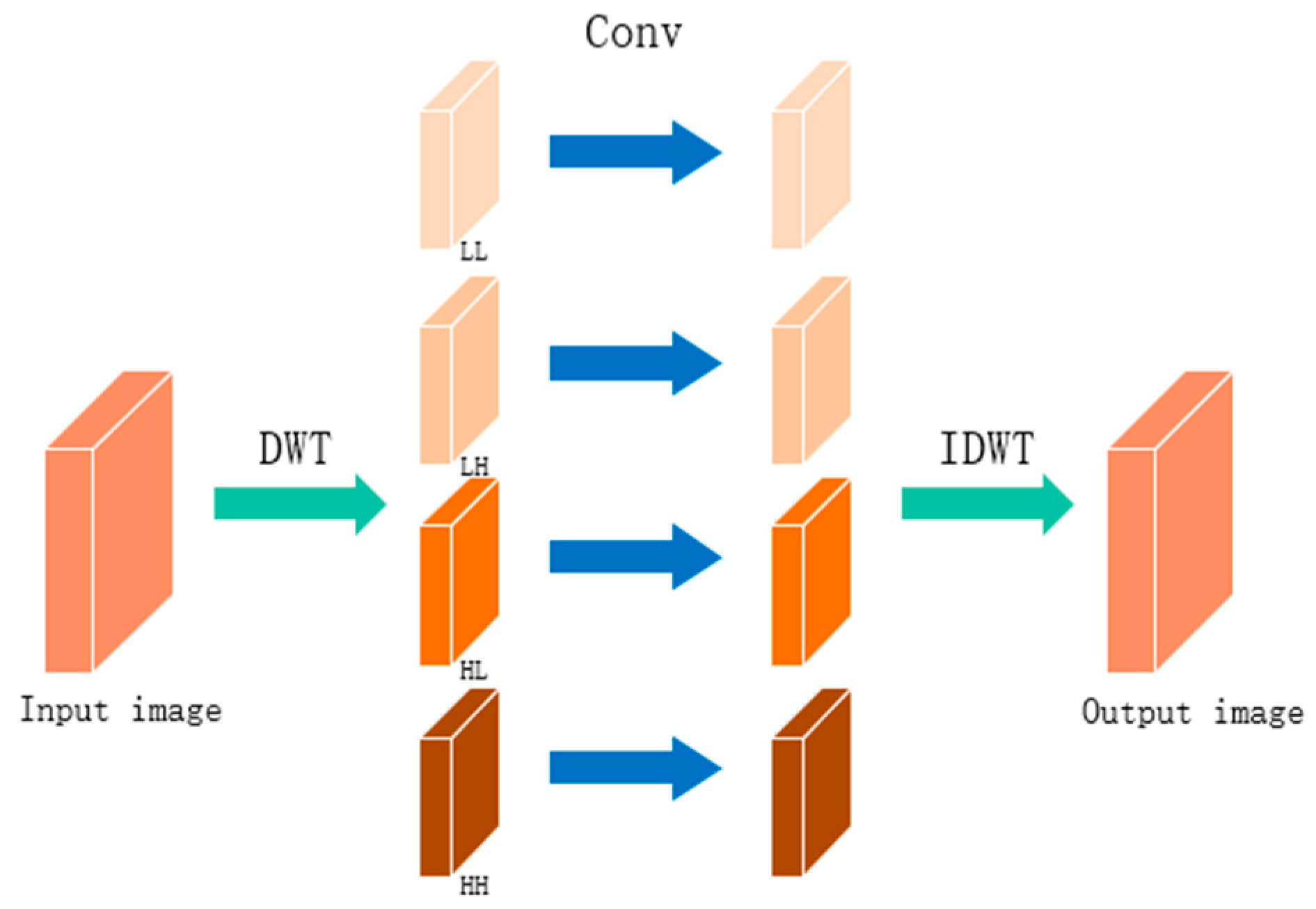
3.1. Wavelet Transform
- LL Subband: This subband contains low frequencies in both horizontal and vertical directions.
- LH Subband: This subband represents low frequency in the horizontal direction and high frequency in the vertical direction.
- HL Subband: This subband denotes high frequency in the horizontal direction and low frequency in the vertical direction.
- HH Subband: This subband represents high frequency in both horizontal and vertical directions.
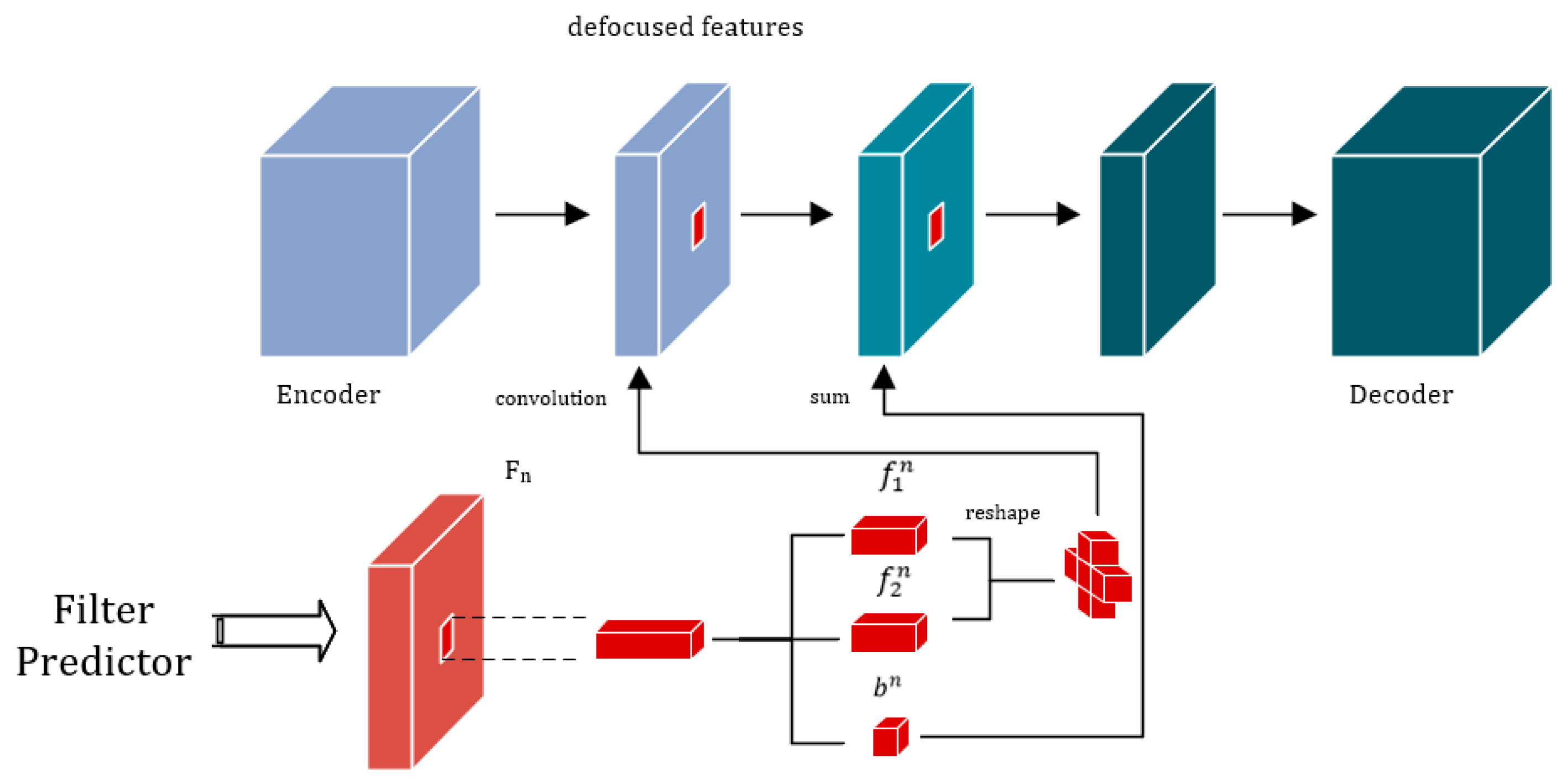
3.2. Iterative Filter Adaptive Module
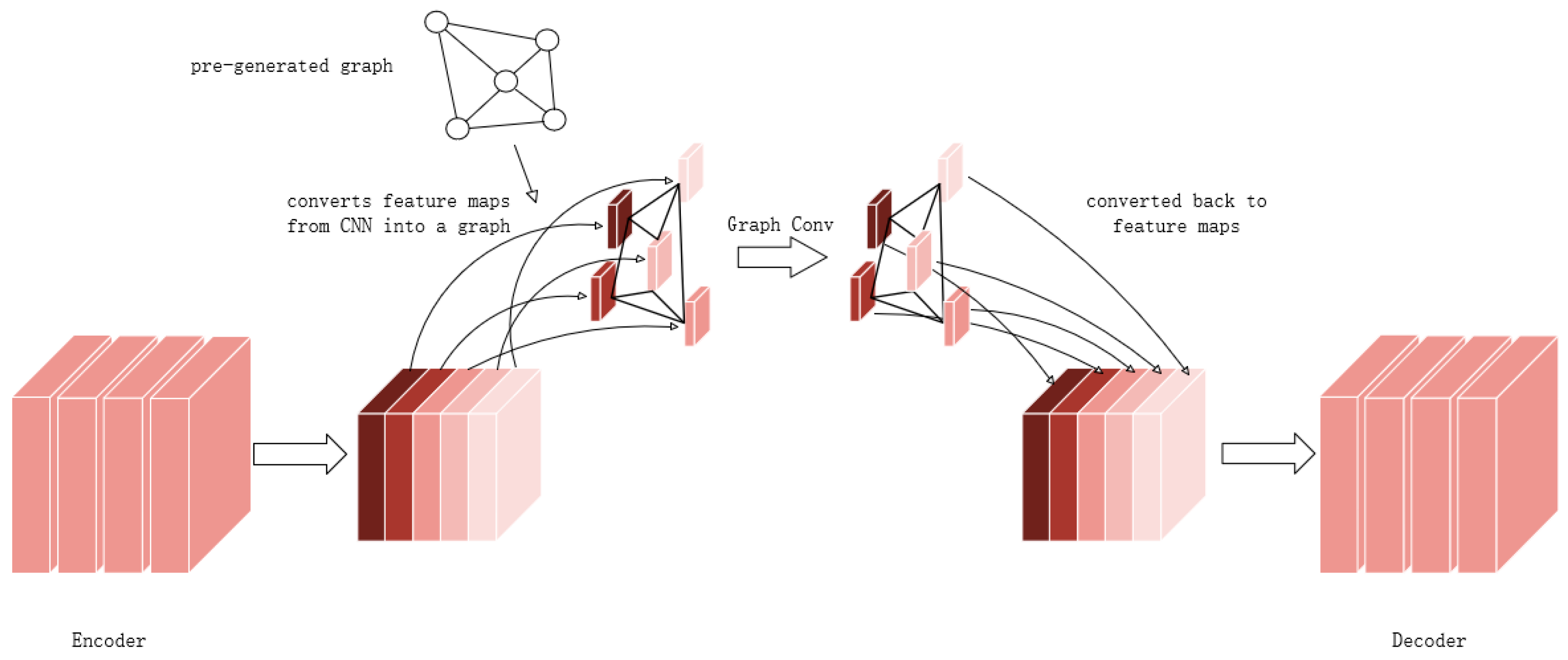
3.3. Graph Convolutional Network
3.4. Dataset
4. Experimental Section
4.1. Comparison with Previous Methods
4.2. Ablation Study
4.3. Generalization Ability
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Abuolaim, A.; Brown, M.S. Defocus deblurring using dual-pixel data. In Computer Vision—ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 111–126. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Guo, T.; Seyed Mousavi, H.; Huu, V.T.; Monga, V. Deep wavelet prediction for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 104–113. [Google Scholar]
- Lee, J.; Son, H.; Rim, J.; Cho, S.; Lee, S. Iterative filter adaptive network for single image defocus deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2034–2042. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Xu, L.; Zheng, S.; Jia, J. Unnatural l0 sparse representation for natural image deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1107–1114. [Google Scholar]
- Wang, R.; Zhang, C.; Zheng, X.; Lv, Y.; Zhao, Y. Joint Defocus deblurring and Superresolution Learning Network for Autonomous Driving. IEEE Intell. Transp. Syst. Mag. 2023. [Google Scholar] [CrossRef]
- Jiang, N.; Zhang, Y.; Yan, F.; Fu, X.; Kong, T. Image blind motion deblurring method with longitudinal channel and wavelet dynamic convolution. Comput. Graph. 2023, 116, 275–286. [Google Scholar] [CrossRef]
- Nah, S.; Hyun Kim, T.; Mu Lee, K. Deep multi-scale convolutional neural network for dynamic scene deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3883–3891. [Google Scholar]
- Chen, D.; He, M.; Fan, Q.; Liao, J.; Zhang, L.; Hou, D.; Yuan, L.; Hua, G. Gated context aggregation network for image dehazing and deraining. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2019; pp. 1375–1383. [Google Scholar]
- Lian, Z.; Wang, H.; Zhang, Q. An Image Deblurring Method Using Improved U-Net Model. Mob. Inf. Syst. 2022, 2022, 6394788. [Google Scholar] [CrossRef]
- Ye, Q.; Suganuma, M.; Okatani, T. Accurate Single-Image Defocus deblurring Based on Improved Integration with Defocus Map Estimation. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Kuala Lumpur, Malaysia, 8–11 October 2023. [Google Scholar]
- Li, Z.; Yang, M.; Cheng, L.; Jia, X. Blind Text Image Deblurring Algorithm Based on Multi-Scale Fusion and Sparse Priors. IEEE Access 2023, 11, 16042–16055. [Google Scholar] [CrossRef]
- Bruna, J.; Mallat, S. Invariant scattering convolution networks. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1872–1886. [Google Scholar] [CrossRef] [PubMed]
- Bae, W.; Yoo, J.; Chul Ye, J. Beyond deep residual learning for image restoration: Persistent homology-guided manifold simplification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 145–153. [Google Scholar]
- Wu, Y.; Qian, P.; Zhang, X. Two-level wavelet-based convolutional neural network for image deblurring. IEEE Access 2021, 9, 45853–45863. [Google Scholar] [CrossRef]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. Proc. ICML 2013, 30, 3. [Google Scholar]
- Xu, B.; Yin, H. Graph convolutional networks in feature space for image deblurring and super-resolution. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ‘small-world’networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef] [PubMed]
- Li, G.; Müller, M.; Thabet, A.; Ghanem, B. Deepgcns: Can gcns go as deep as cnns? In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9267–9276. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems 32; MIT Press: Cambridge, MA, USA, 2019. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Shi, J.; Xu, L.; Jia, J. Just noticeable defocus blur detection and estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 657–665. [Google Scholar]
- Karaali, A.; Jung, C.R. Edge-based defocus blur estimation with adaptive scale selection. IEEE Trans. Image Process. 2017, 27, 1126–1137. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | PSNR | SSIM | MAE |
|---|---|---|---|
| Input | 22.31 | 0.614 | 0.502 |
| Shi et al. [23] | 22.39 | 0.620 | 0.504 |
| Karaali et al. [24] | 22.45 | 0.632 | 0.487 |
| Abuolaim et al. [1] | 22.73 | 0.687 | 0.464 |
| Ye et al. [12] | 23.54 | 0.715 | 0.428 |
| Lee et al. [4] | 23.64 | 0.723 | 0.419 |
| Ours | 23.71 | 0.742 | 0.412 |
| WtT | IFA | GCN | PSNR | SSIM | MAE |
|---|---|---|---|---|---|
| 23.67 | 0.705 | 0.436 | |||
| √ | 24.65 | 0.757 | 0.409 | ||
| √ | 24.56 | 0.751 | 0.414 | ||
| √ | 24.03 | 0.736 | 0.423 | ||
| √ | √ | 25.12 | 0.765 | 0.399 | |
| √ | √ | 25.04 | 0.763 | 0.401 | |
| √ | √ | 24.77 | 0.749 | 0.411 | |
| √ | √ | √ | 25.37 | 0.774 | 0.394 |
| PSNR | SSIM | MAE | |
|---|---|---|---|
| Blurry image | 21.05 | 0.632 | 0.513 |
| Ours | 23.46 | 0.708 | 0.435 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Wang, N.; Li, J.; Zhang, Y. WIG-Net: Wavelet-Based Defocus Deblurring with IFA and GCN. Appl. Sci. 2023, 13, 12513. https://doi.org/10.3390/app132212513
Li Y, Wang N, Li J, Zhang Y. WIG-Net: Wavelet-Based Defocus Deblurring with IFA and GCN. Applied Sciences. 2023; 13(22):12513. https://doi.org/10.3390/app132212513
Chicago/Turabian StyleLi, Yi, Nan Wang, Jinlong Li, and Yu Zhang. 2023. "WIG-Net: Wavelet-Based Defocus Deblurring with IFA and GCN" Applied Sciences 13, no. 22: 12513. https://doi.org/10.3390/app132212513