
Noise-to-Norm Reconstruction for Industrial Anomaly Detection and Localization

Abstract
:1. Introduction
- We introduce a novel unsupervised anomaly detection method based on the noise-to-norm paradigm.
- We propose a residual attention module that can be embedded in the encoder and decoder to achieve high-quality reconstruction of noisy images.
- Our method achieves state-of-the-art (SOTA) performance on the MPDD dataset.
2. Related Work
2.1. Feature Embedding-Based Methods
2.2. Reconstruction-Based Methods
3. Method
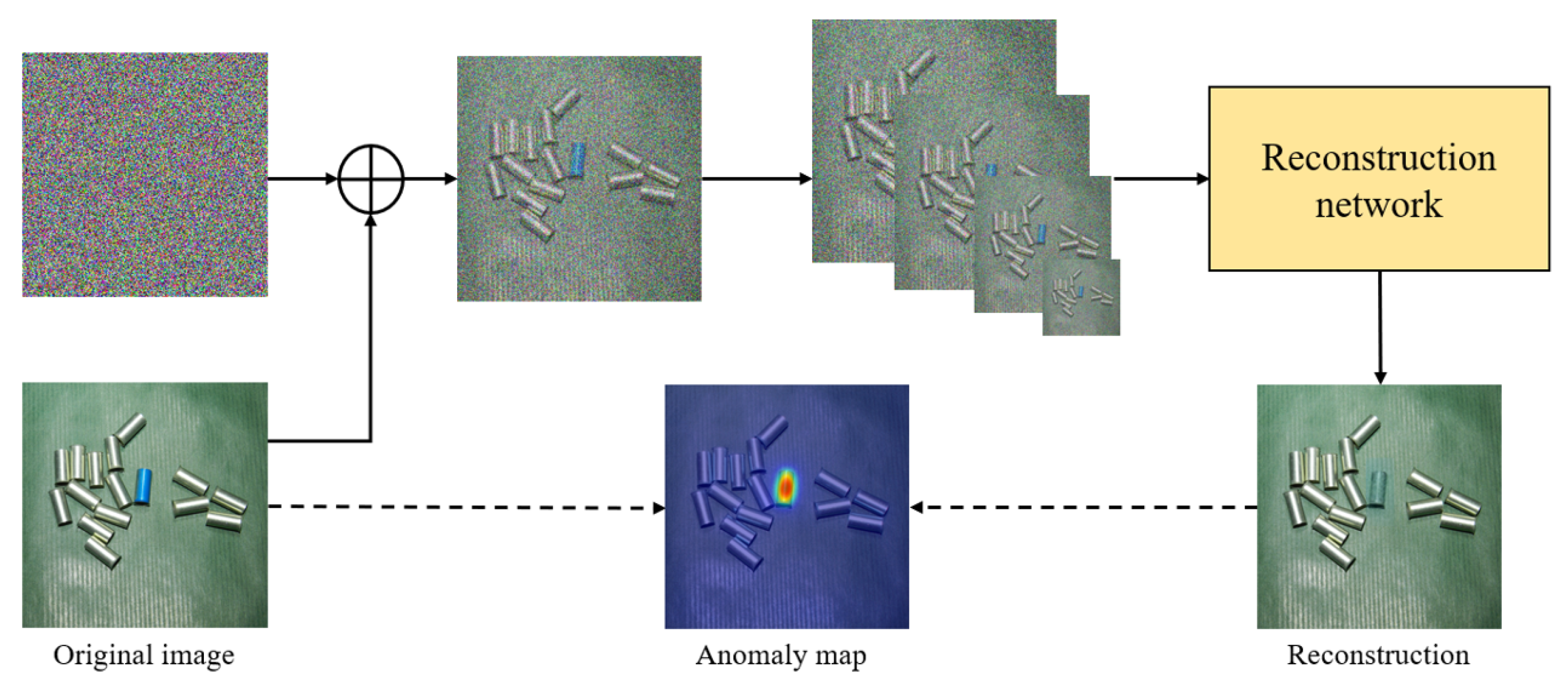
3.1. Overview
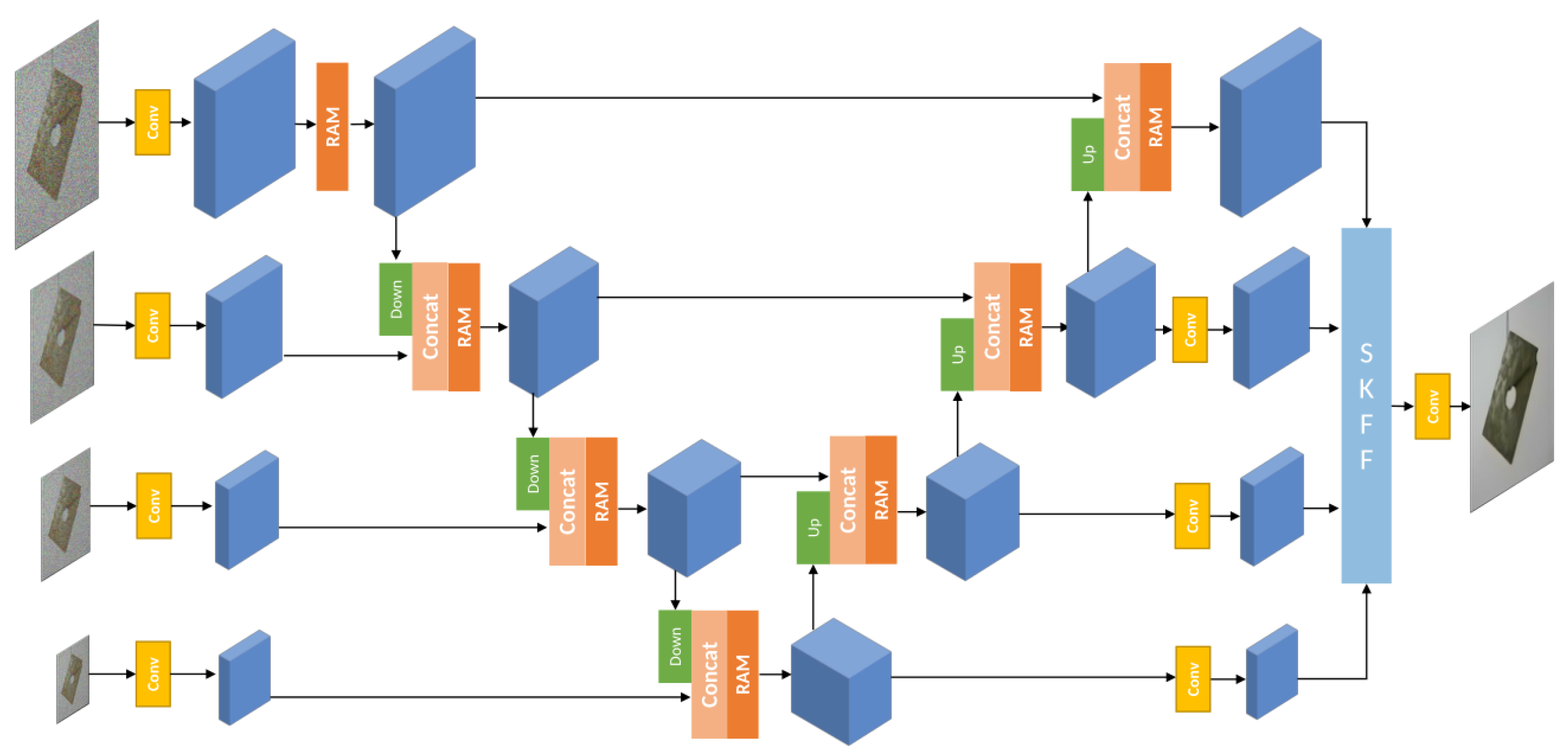
3.2. Reconstruction Network
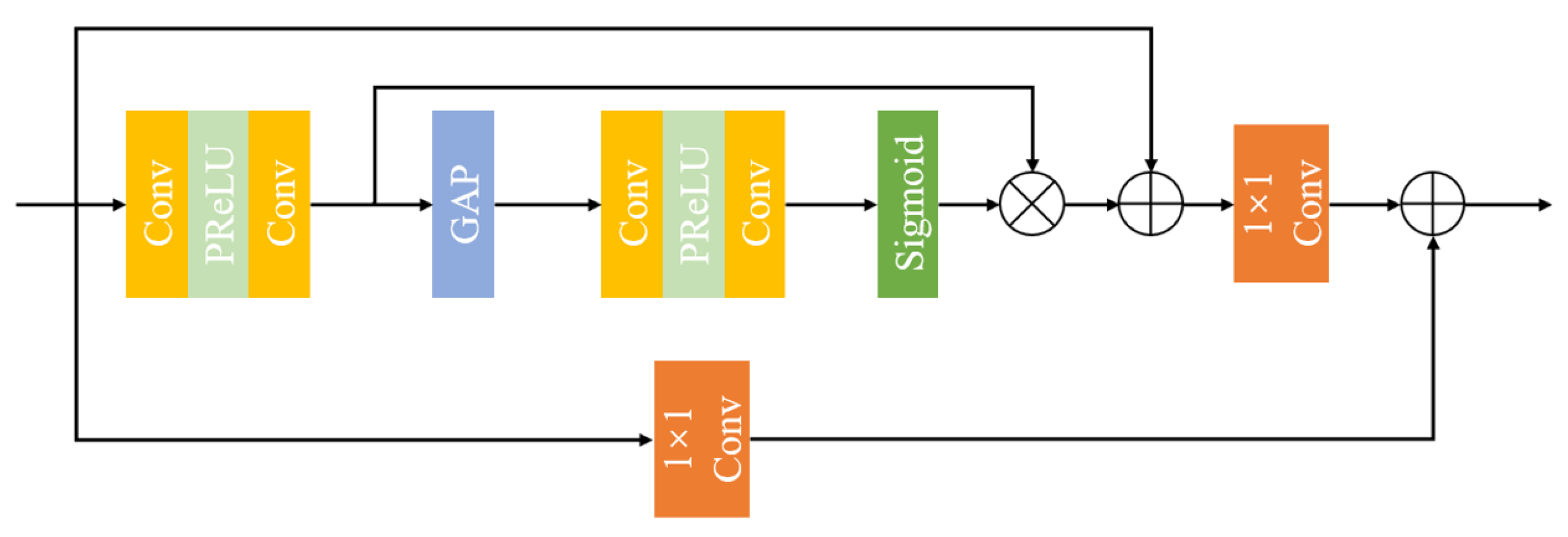
3.2.1. Residual Attention Module
3.2.2. Selective Kernel Feature Fusion (SKFF)
3.3. Metric Function
4. Experiments
4.1. Datasets
4.1.1. MPDD
4.1.2. VisA
4.2. Experimental Details
4.3. Comparative Experiments
4.3.1. MPDD
4.3.2. VisA
4.4. Ablation Studies
4.4.1. Effect of
4.4.2. Importance of Residual Attention Module
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bergmann, P.; Fauser, M.; Sattlegger, D.; Steger, C. MVTec AD—A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9584–9592. [Google Scholar] [CrossRef]
- Jezek, S.; Jonak, M.; Burget, R.; Dvorak, P.; Skotak, M. Deep learning-based defect detection of metal parts: Evaluating current methods in complex conditions. In Proceedings of the 2021 13th International Congress on Ultra Modern Telecommunications and Control Systems and Workshops (ICUMT), Brno, Czech Republic, 25–27 October 2021; pp. 66–71. [Google Scholar] [CrossRef]
- Zou, Y.; Jeong, J.; Pemula, L.; Zhang, D.; Dabeer, O. SPot-the-Difference Self-supervised Pre-training for Anomaly Detection and Segmentation. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 392–408. [Google Scholar]
- Menze, B.H.; Jakab, A.; Bauer, S.; Kalpathy-Cramer, J.; Farahani, K.; Kirby, J.; Burren, Y.; Porz, N.; Slotboom, J.; Wiest, R.; et al. The Multimodal Brain Tumor Image Segmentation Benchmark (BRATS). IEEE Trans. Med. Imaging 2015, 34, 1993–2024. [Google Scholar] [CrossRef] [PubMed]
- Lu, C.; Shi, J.; Jia, J. Abnormal Event Detection at 150 FPS in MATLAB. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 2720–2727. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-Image Crowd Counting via Multi-Column Convolutional Neural Network. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Defard, T.; Setkov, A.; Loesch, A.; Audigier, R. PaDiM: A Patch Distribution Modeling Framework for Anomaly Detection and Localization. In Proceedings of the Pattern Recognition. ICPR International Workshops and Challenges, Virtual Event, 10–15 January 2021; Springer: Cham, Switzerland, 2021; pp. 475–489. [Google Scholar]
- Roth, K.; Pemula, L.; Zepeda, J.; Schölkopf, B.; Brox, T.; Gehler, P. Towards Total Recall in Industrial Anomaly Detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 14298–14308. [Google Scholar] [CrossRef]
- Sun, Z.; He, Y.; Gritsenko, A.; Lendasse, A.; Baek, S. Embedded spectral descriptors: Learning the point-wise correspondence metric via Siamese neural networks. J. Comput. Des. Eng. 2020, 7, 18–29. [Google Scholar] [CrossRef]
- Yu, J.; Zheng, Y.; Wang, X.; Li, W.; Wu, Y.; Zhao, R.; Wu, L. FastFlow: Unsupervised Anomaly Detection and Localization via 2D Normalizing Flows. arXiv 2021, arXiv:2111.07677. [Google Scholar]
- Gudovskiy, D.; Ishizaka, S.; Kozuka, K. CFLOW-AD: Real-Time Unsupervised Anomaly Detection with Localization via Conditional Normalizing Flows. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; pp. 1819–1828. [Google Scholar] [CrossRef]
- Akçay, S.; Atapour-Abarghouei, A.; Breckon, T.P. Skip-GANomaly: Skip Connected and Adversarially Trained Encoder-Decoder Anomaly Detection. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Liu, T.; Li, B.; Zhao, Z.; Du, X.; Jiang, B.; Geng, L. Reconstruction from edge image combined with color and gradient difference for industrial surface anomaly detection. arXiv 2022, arXiv:2210.14485. [Google Scholar]
- Liang, Y.; Zhang, J.; Zhao, S.; Wu, R.C.; Liu, Y.; Pan, S. Omni-frequency Channel-selection Representations for Unsupervised Anomaly Detection. arXiv 2022, arXiv:2203.00259. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Zhao, Z.; Zhang, X.; Sun, C.; Chen, X. Industrial Anomaly Detection with Domain Shift: A Real-world Dataset and Masked Multi-scale Reconstruction. arXiv 2023, arXiv:2304.02216. [Google Scholar] [CrossRef]
- Mehta, R.; Sivaswamy, J. M-net: A Convolutional Neural Network for deep brain structure segmentation. In Proceedings of the 2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017), Melbourne, VIC, Australia, 18–21 April 2017; pp. 437–440. [Google Scholar] [CrossRef]
- Zheng, Y.; Wang, X.; Deng, R.; Bao, T.; Zhao, R.; Wu, L. Focus Your Distribution: Coarse-to-Fine Non-Contrastive Learning for Anomaly Detection and Localization. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Rudolph, M.; Wehrbein, T.; Rosenhahn, B.; Wandt, B. Fully Convolutional Cross-Scale-Flows for Image-based Defect Detection. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; pp. 1829–1838. [Google Scholar] [CrossRef]
- Shi, Y.; Yang, J.; Qi, Z. Unsupervised anomaly segmentation via deep feature reconstruction. Neurocomputing 2021, 424, 9–22. [Google Scholar] [CrossRef]
- Zavrtanik, V.; Kristan, M.; Skočaj, D. DRÆM – A discriminatively trained reconstruction embedding for surface anomaly detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 8310–8319. [Google Scholar] [CrossRef]
- Tang, T.W.; Kuo, W.H.; Lan, J.H.; Ding, C.F.; Hsu, H.; Young, H.T. Anomaly Detection Neural Network with Dual Auto-Encoders GAN and Its Industrial Inspection Applications. Sensors 2020, 20, 3336. [Google Scholar] [CrossRef] [PubMed]
- Zavrtanik, V.; Kristan, M.; Skočaj, D. Reconstruction by inpainting for visual anomaly detection. Pattern Recognit. 2021, 112, 107706. [Google Scholar] [CrossRef]
- Pirnay, J.; Chai, K. Inpainting Transformer for Anomaly Detection. In Proceedings of the Image Analysis and Processing—ICIAP 2022, Lecce, Italy, 23–27 May 2022; Springer: Cham, Switzerland, 2022; pp. 394–406. [Google Scholar]
- Jiang, J.; Zhu, J.; Bilal, M.; Cui, Y.; Kumar, N.; Dou, R.; Su, F.; Xu, X. Masked Swin Transformer Unet for Industrial Anomaly Detection. IEEE Trans. Ind. Inform. 2023, 19, 2200–2209. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Li, C.; Tan, Y.; Chen, W.; Luo, X.; Gao, Y.; Jia, X.; Wang, Z. Attention Unet++: A Nested Attention-Aware U-Net for Liver CT Image Segmentation. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 345–349. [Google Scholar] [CrossRef]
- Li, H.; He, Y.; Xu, Q.; Deng, J.; le Li, W.; Wei, Y.; Zhou, J. Sematic segmentation of loess landslides with STAPLE mask and fully connected conditional random field. Landslides 2022, 20, 367–380. [Google Scholar] [CrossRef]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-Unet: Unet-Like Pure Transformer for Medical Image Segmentation. In Proceedings of the Computer Vision—ECCV 2022 Workshops, Tel Aviv, Israel, 23–27 October 2022; Karlinsky, L., Michaeli, T., Nishino, K., Eds.; Springer: Cham, Switzerland, 2023; pp. 205–218. [Google Scholar]
- Sun, Z.; Rooke, E.; Charton, J.; He, Y.; Lu, J.; Baek, S. ZerNet: Convolutional Neural Networks on Arbitrary Surfaces Via Zernike Local Tangent Space Estimation. Comput. Graph. Forum 2020, 39, 204–216. [Google Scholar] [CrossRef]
- Fan, C.M.; Liu, T.J.; Liu, K.H.; Chiu, C.H. Selective Residual M-Net for Real Image Denoising. In Proceedings of the 2022 30th European Signal Processing Conference (EUSIPCO), Belgrade, Serbia, 29 August–2 September 2022; pp. 469–473. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Learning Enriched Features for Real Image Restoration and Enhancement. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 492–511. [Google Scholar]
- Zhao, H.; Gallo, O.; Frosio, I.; Kautz, J. Loss Functions for Image Restoration With Neural Networks. IEEE Trans. Comput. Imaging 2017, 3, 47–57. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Deng, H.; Li, X. Anomaly Detection via Reverse Distillation from One-Class Embedding. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 9727–9736. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | DAGAN | Skip-GANomaly | PaDiM | CFLOW | PatchCore | Ours |
|---|---|---|---|---|---|---|
| Bracket Black | 68.55 | 61.30 | 75.60 | 72.67 | 81.88 | 93.42 |
| Bracket Brown | 77.07 | 62.14 | 85.40 | 88.84 | 78.43 | 93.14 |
| Bracket White | 72.11 | 73.33 | 82.22 | 87.78 | 76.00 | 89.33 |
| Connector | 99.76 | 73.62 | 91.67 | 94.76 | 96.67 | 100.00 |
| Metal Plate | 85.43 | 73.24 | 56.30 | 99.51 | 100.00 | 99.57 |
| Tubes | 31.93 | 46.42 | 57.51 | 73.14 | 59.73 | 94.16 |
| Avg. | 72.48 | 64.84 | 74.78 | 86.12 | 82.12 | 94.94 |
| Method | DAGAN | Skip-GANomaly | PaDiM | CFLOW | PatchCore | Ours |
|---|---|---|---|---|---|---|
| Bracket Black | 89.73 | 88.96 | 94.23 | 96.88 | 98.41 | 98.97 |
| Bracket Brown | 81.50 | 78.07 | 92.44 | 97.78 | 91.46 | 93.10 |
| Bracket White | 70.63 | 78.81 | 98.11 | 98.61 | 97.44 | 97.82 |
| Connector | 85.73 | 80.20 | 97.89 | 98.39 | 95.00 | 98.95 |
| Metal Plate | 89.95 | 89.72 | 92.93 | 98.21 | 96.57 | 98.78 |
| Tubes | 82.31 | 77.30 | 93.94 | 96.43 | 95.05 | 99.17 |
| Avg. | 83.31 | 82.19 | 96.74 | 97.72 | 95.66 | 97.80 |
| Method | DRAEM | RD4AD | PaDiM | CFLOW | FastFlow | PatchCore | Ours |
|---|---|---|---|---|---|---|---|
| Candle | 94.4 | 92.2 | 91.6 | 97.0 | 92.8 | 98.6 | 83.7 |
| Capsules | 76.3 | 90.1 | 70.7 | 93.0 | 71.2 | 81.6 | 93.3 |
| Cashew | 90.7 | 99.6 | 93.0 | 90.9 | 91.0 | 97.3 | 93.4 |
| Chewing gum | 94.2 | 99.7 | 98.8 | 98.3 | 91.4 | 99.1 | 97.7 |
| Fryum | 97.4 | 96.6 | 88.6 | 91.1 | 88.6 | 96.2 | 97.3 |
| Macaroni1 | 95.0 | 98.4 | 87.0 | 69.6 | 98.3 | 97.5 | 91.6 |
| Macaroni2 | 96.2 | 97.6 | 70.5 | 77.2 | 86.3 | 78.1 | 91.5 |
| PCB1 | 54.8 | 97.6 | 94.7 | 91.4 | 77.4 | 98.5 | 94.7 |
| PCB2 | 77.8 | 91.1 | 88.5 | 96.7 | 61.9 | 97.3 | 95.6 |
| PCB3 | 94.5 | 95.5 | 91.0 | 99.6 | 74.3 | 97.9 | 98.7 |
| PCB4 | 93.4 | 96.5 | 97.5 | 94.2 | 80.9 | 99.6 | 98.2 |
| Pipe fryum | 99.4 | 97.0 | 97.0 | 99.0 | 72.0 | 99.8 | 92.6 |
| Avg. | 88.7 | 96.0 | 89.1 | 91.5 | 82.2 | 95.1 | 94.0 |
| Noise Coefficient | ||||
|---|---|---|---|---|
| Bracket Black | 47.61/77.21 | 83.71/98.16 | 93.42/98.97 | 90.56/99.02 |
| Bracket Brown | 82.50/83.93 | 90.57/91.84 | 93.14/93.10 | 84.09/92.86 |
| Bracket White | 74.89/89.82 | 92.78/98.35 | 89.33/97.82 | 83.22/96.74 |
| Connector | 96.67/93.70 | 100.00/98.78 | 100.00/98.95 | 100.00/98.80 |
| Metal Plate | 97.83/97.88 | 98.92/98.96 | 99.57/98.78 | 99.30/98.40 |
| Tubes | 39.45/85.88 | 97.06/98.61 | 94.16/99.17 | 93.75/99.44 |
| Avg. | 73.16/88.07 | 93.84/97.45 | 94.94/97.80 | 91.82/97.54 |
| Image-Level | Pixel-Level | |||
|---|---|---|---|---|
| Residual Attention module | ✔ | ✖ | ✔ | ✖ |
| Bracket Black | 93.42 | 50.47 | 98.97 | 89.36 |
| Bracket Brown | 93.14 | 75.32 | 93.10 | 80.36 |
| Bracket White | 92.33 | 65.92 | 96.75 | 85.74 |
| Connector | 100.00 | 62.38 | 98.95 | 94.99 |
| Metal Plate | 99.57 | 88.61 | 98.78 | 96.69 |
| Tubes | 94.16 | 57.87 | 99.17 | 84.93 |
| Avg. | 95.44 | 66.76 | 97.62 | 88.68 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, S.; Sun, Z.; Zhuang, R.; Gong, J. Noise-to-Norm Reconstruction for Industrial Anomaly Detection and Localization. Appl. Sci. 2023, 13, 12436. https://doi.org/10.3390/app132212436
Deng S, Sun Z, Zhuang R, Gong J. Noise-to-Norm Reconstruction for Industrial Anomaly Detection and Localization. Applied Sciences. 2023; 13(22):12436. https://doi.org/10.3390/app132212436
Chicago/Turabian StyleDeng, Shiqi, Zhiyu Sun, Ruiyan Zhuang, and Jun Gong. 2023. "Noise-to-Norm Reconstruction for Industrial Anomaly Detection and Localization" Applied Sciences 13, no. 22: 12436. https://doi.org/10.3390/app132212436