

A Study of Reciprocal Job Recommendation for College Graduates Integrating Semantic Keyword Matching and Social Networking
Abstract
:1. Introduction
2. Related Works
2.1. Research on Job Recommendation Based on Keyword Matching
2.2. Research on Job Recommendations Based on Social Networks
2.3. Research on Job Recommendations Based on Reciprocity
2.4. The Application of Job Recommendation in the Field of Colleges
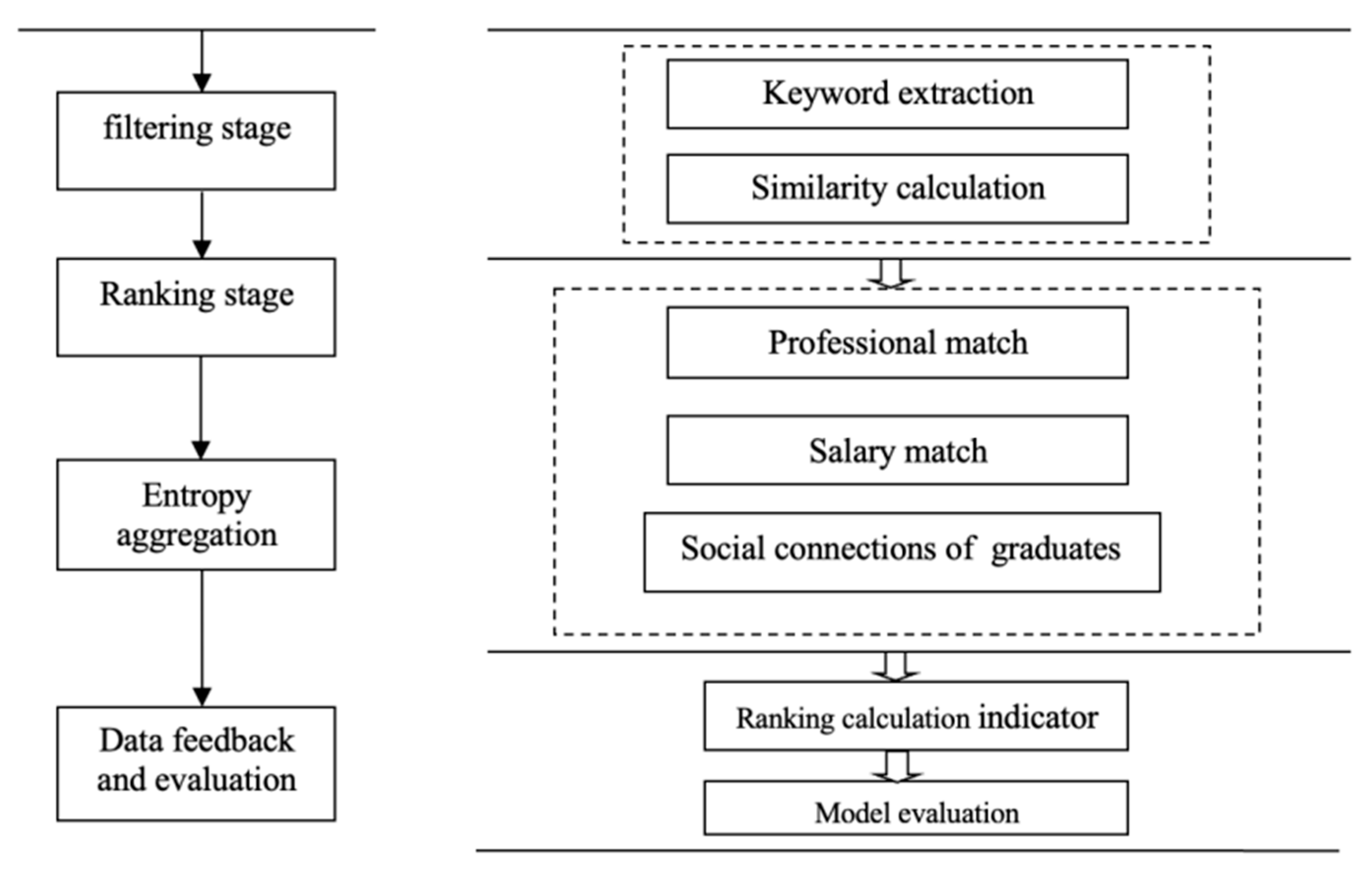
3. Proposed Job Recommendation Method
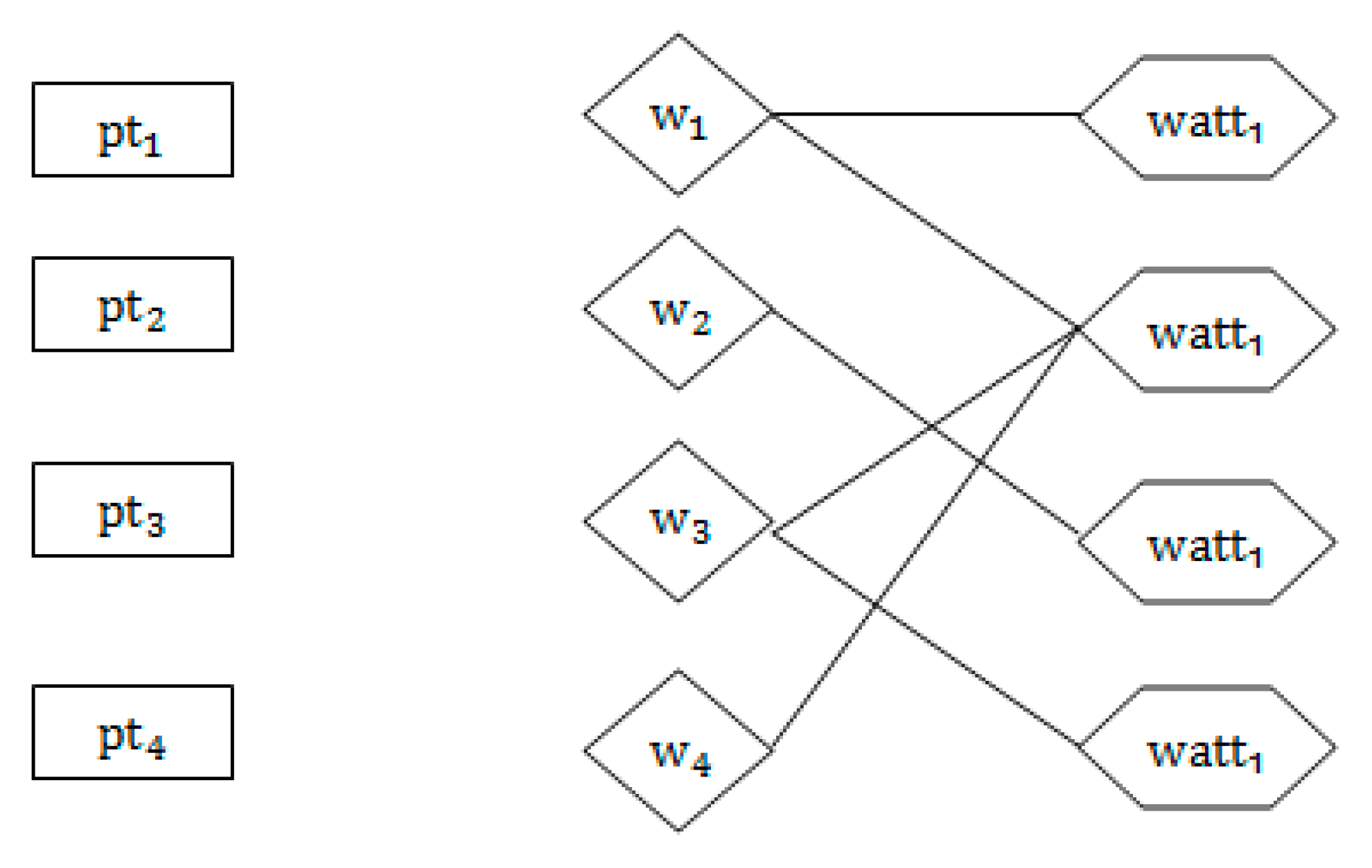
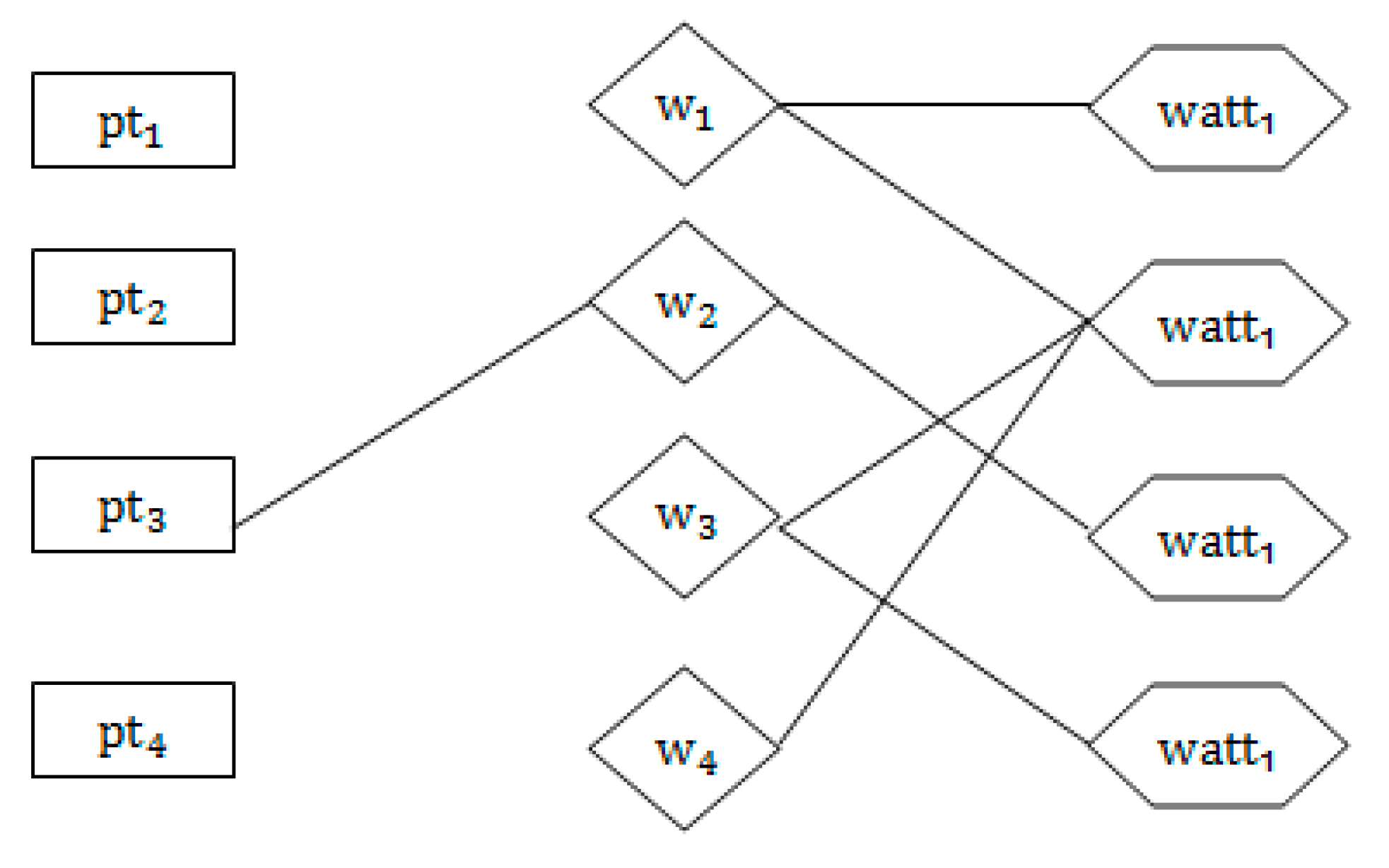
3.1. Screening Phase
3.1.1. Text Information Extraction and Processing Filtering Stage
3.1.2. The Semantic Keyword Iterative Algorithm
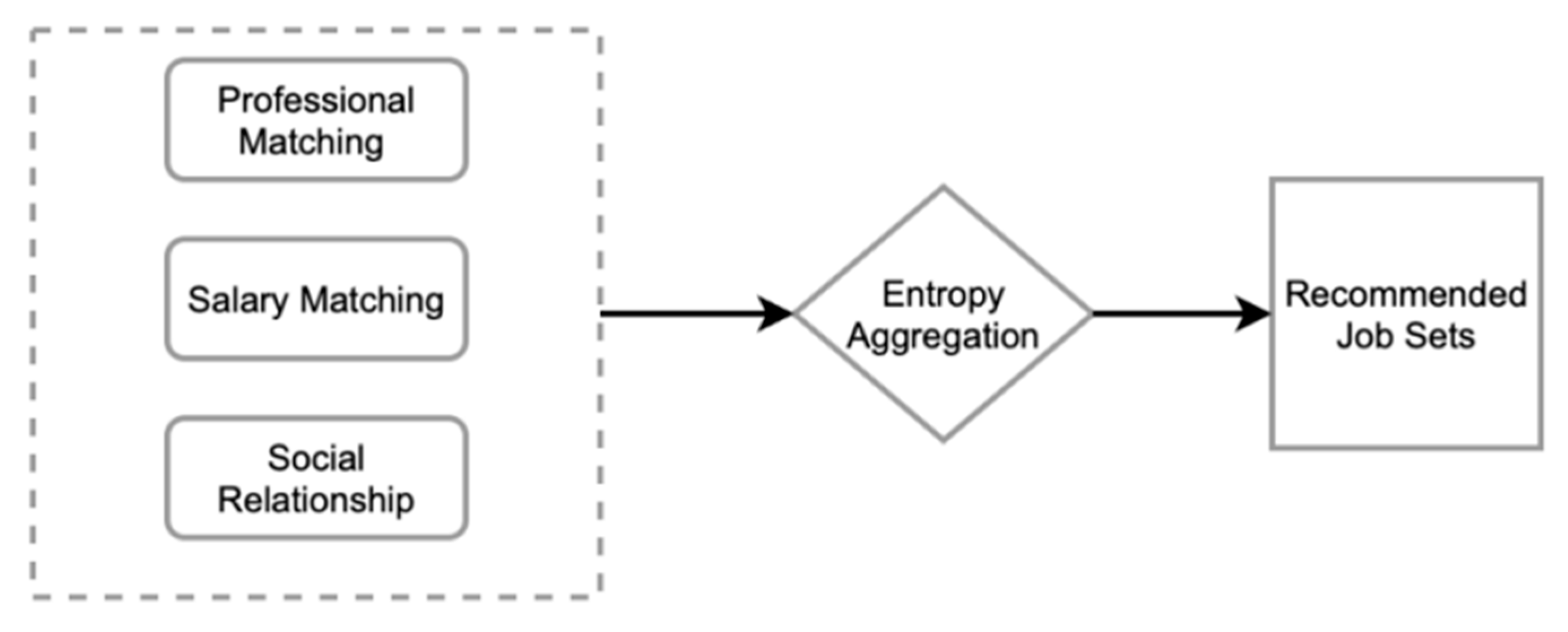
3.2. Ranking Stage
3.2.1. Professional Matching
3.2.2. Salary Matching
3.2.3. Social Relationship
3.2.4. Entropy Aggregation
3.3. Experimental Evaluation
3.3.1. Recommendation Method
3.3.2. Evaluation of Indicators
4. Analysis and Discussion of Experimental Results
4.1. Experimental Settings
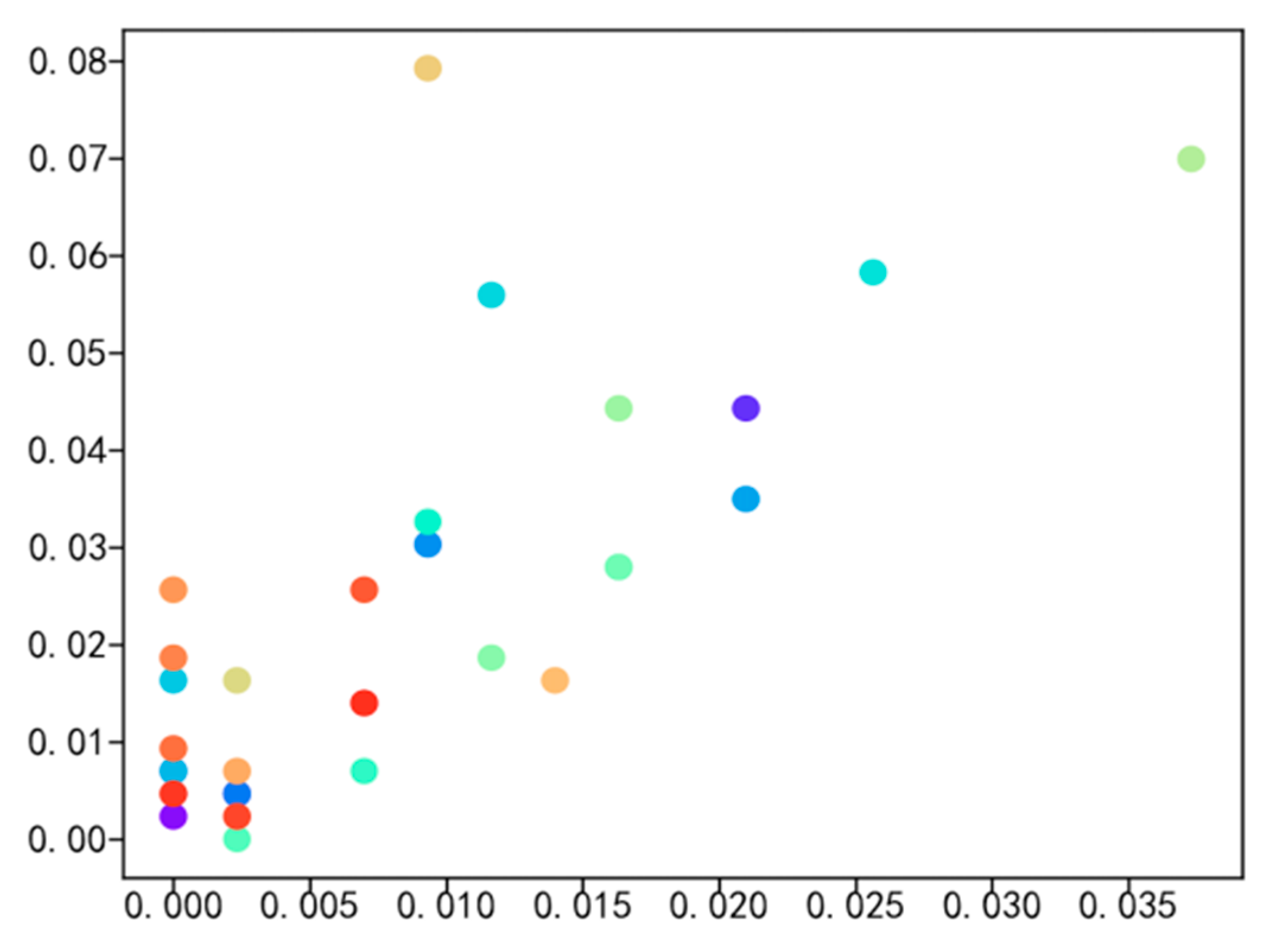
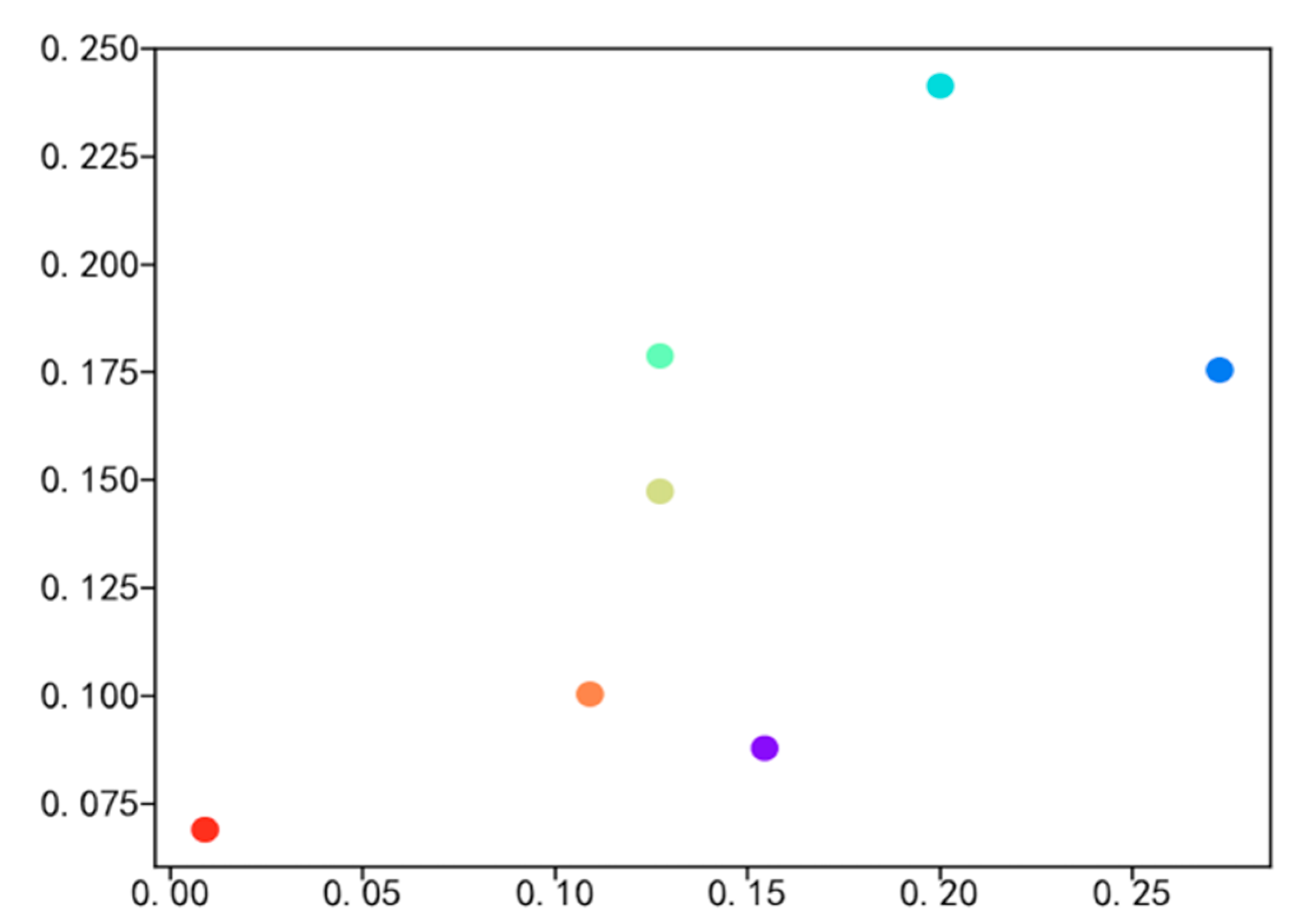
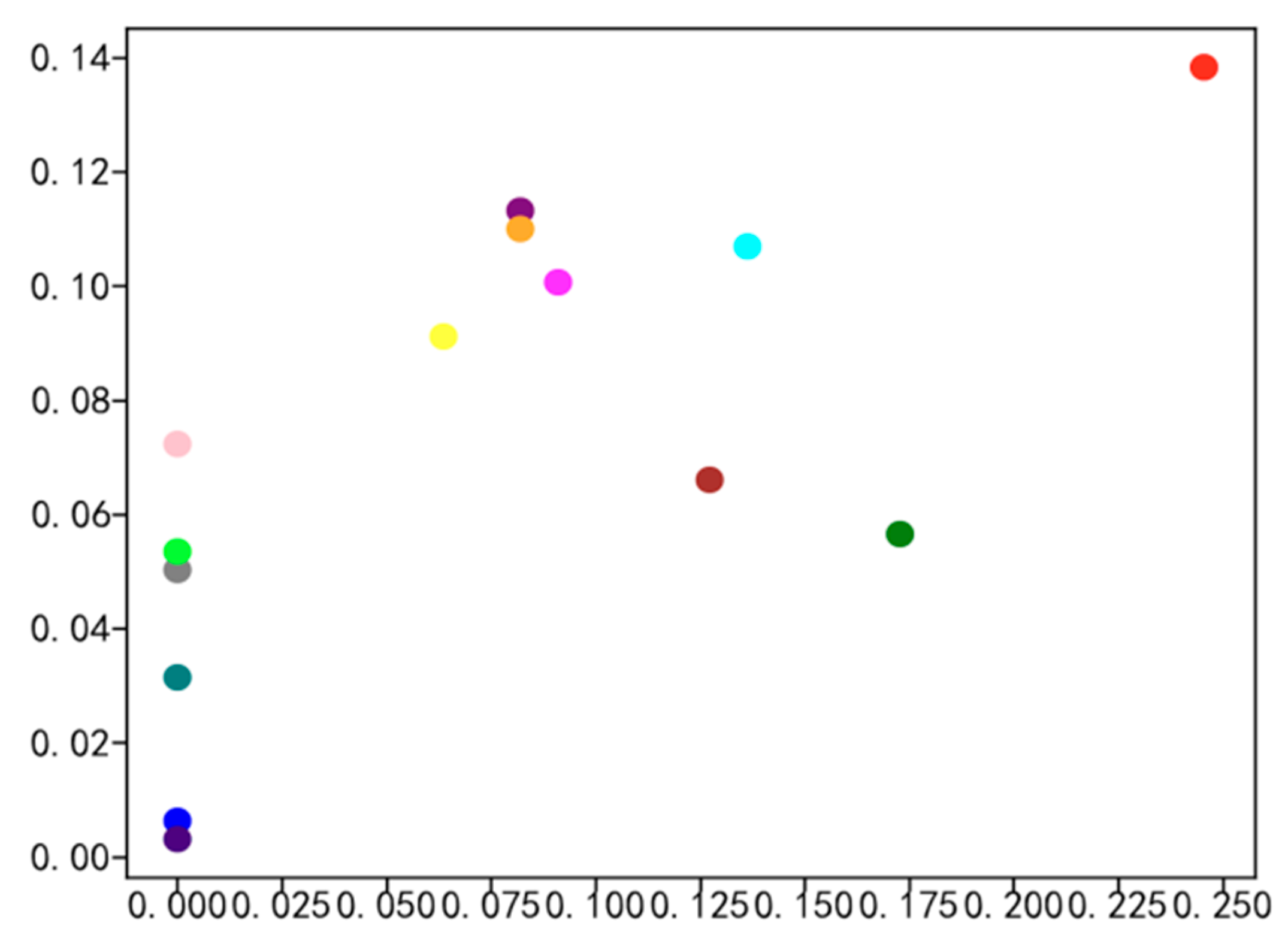
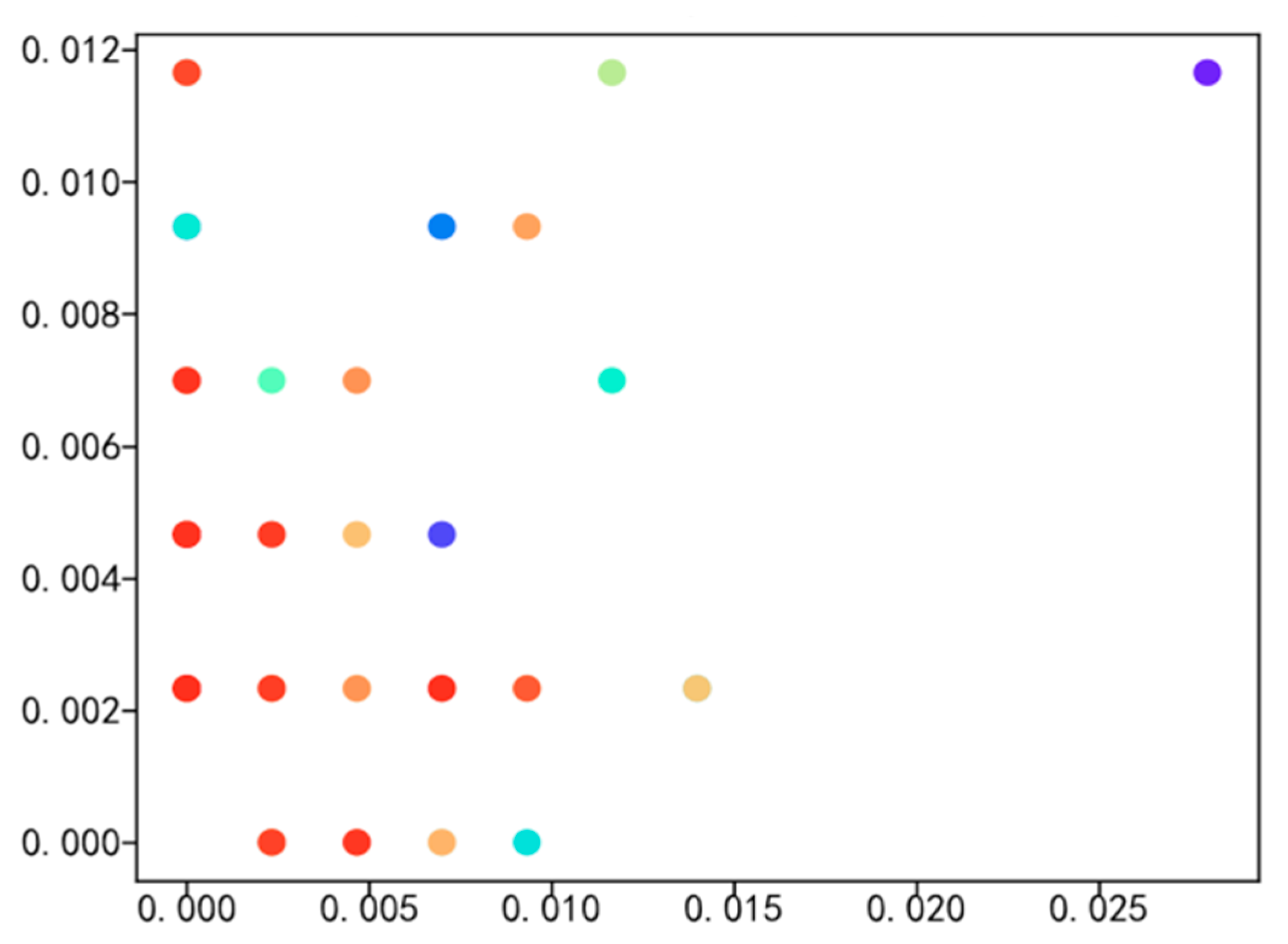
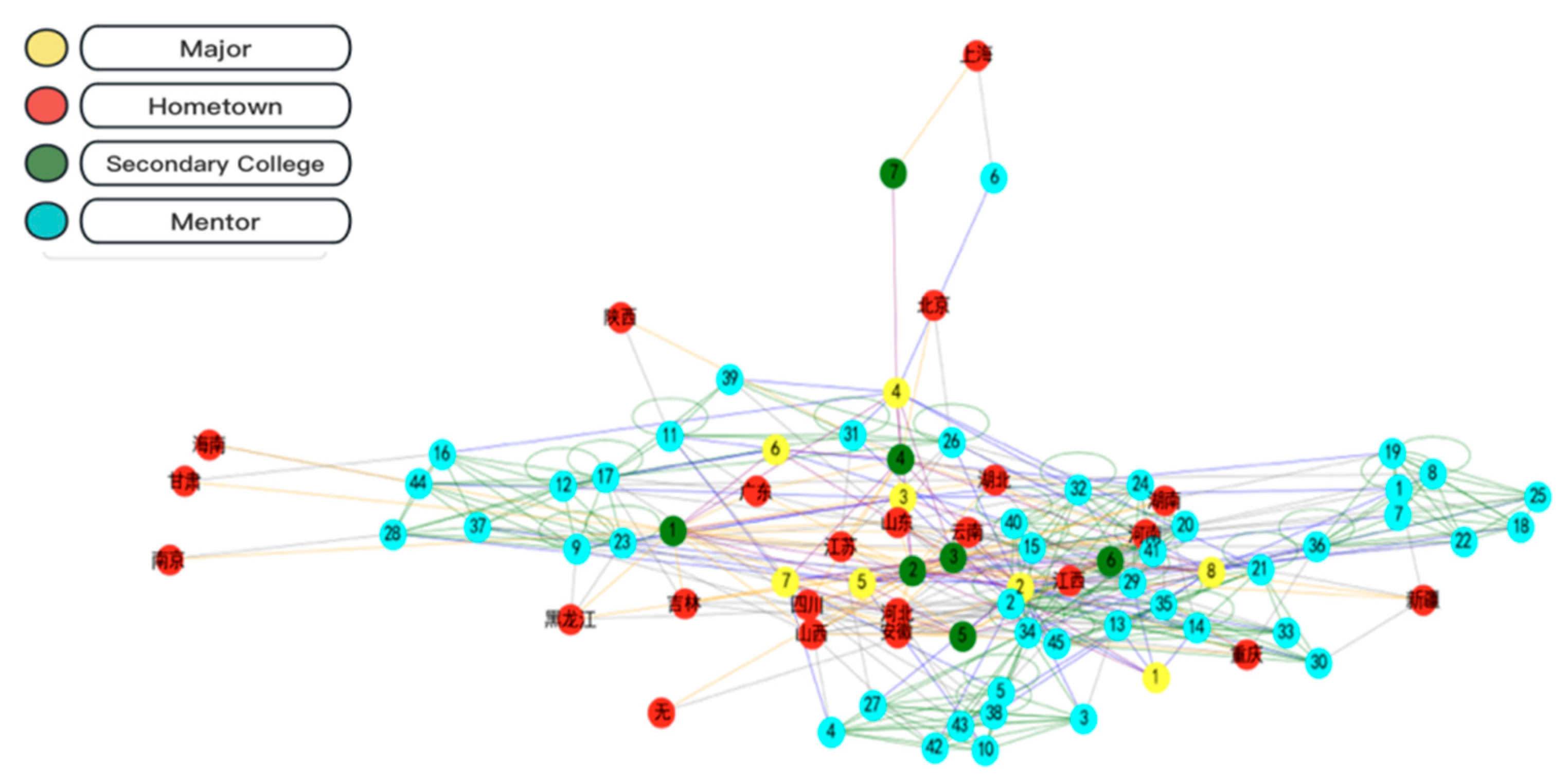
4.2. Social Network Visualization of Experimental Data
4.3. Result Analysis
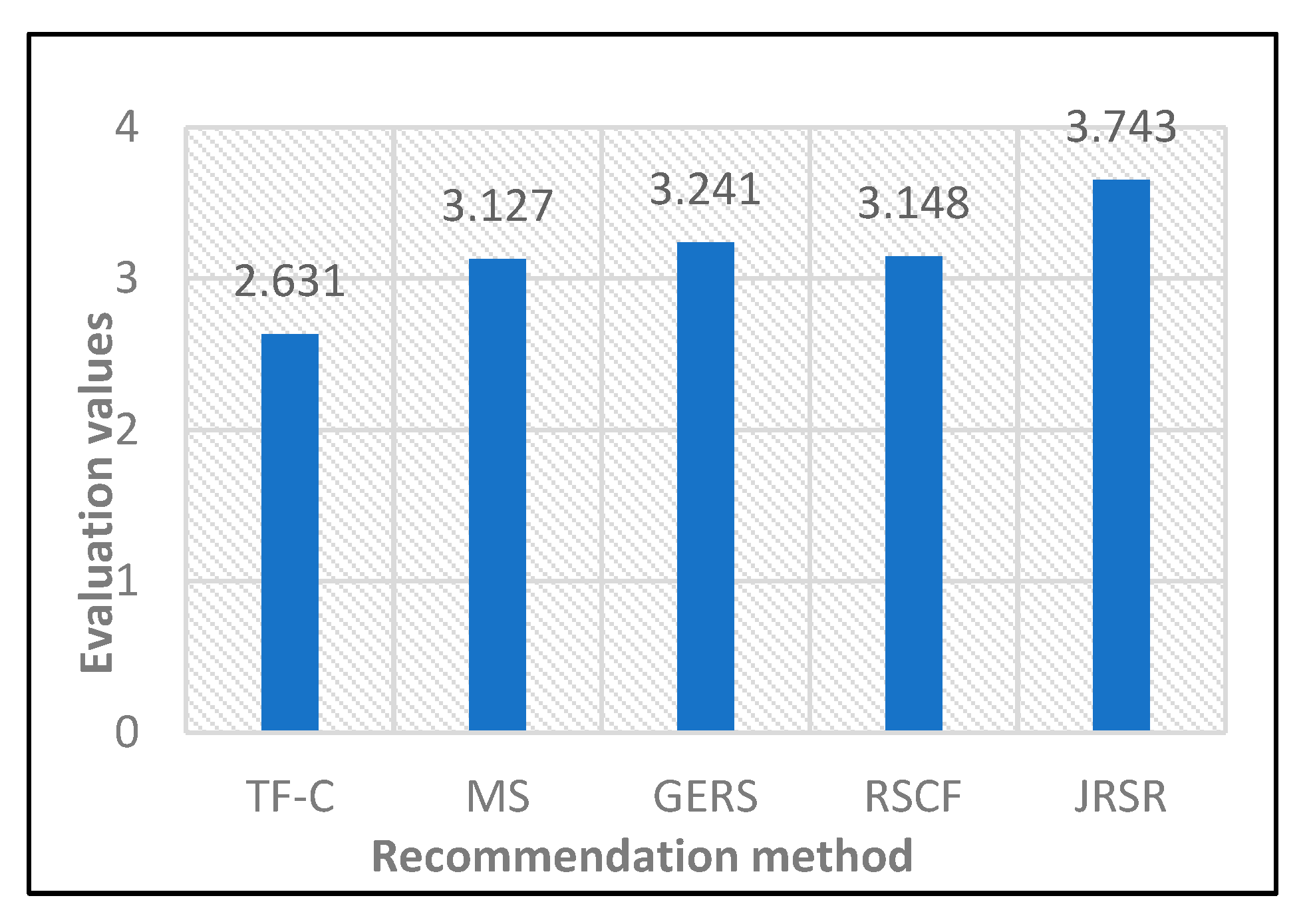
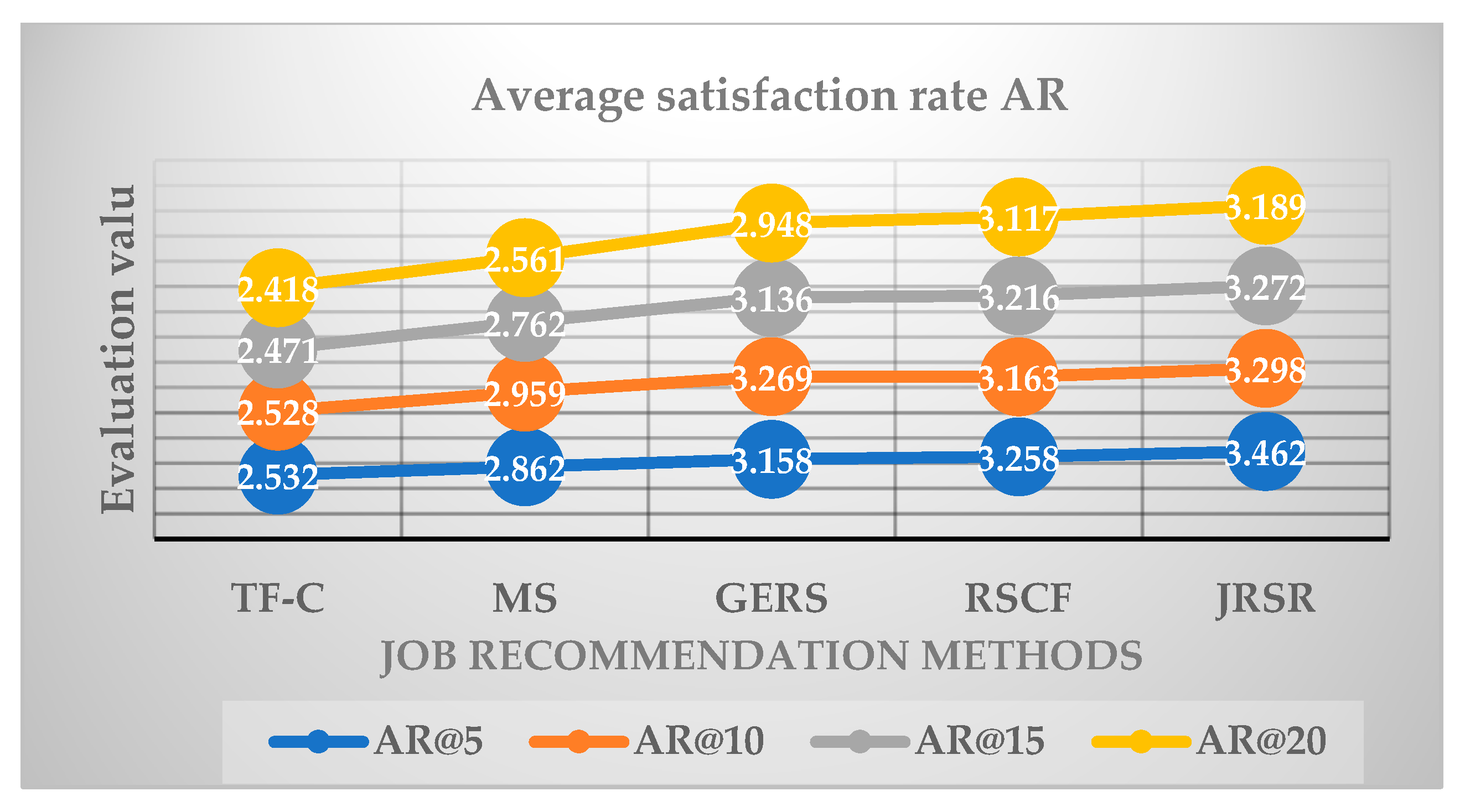
4.3.1. Evaluation Analysis of the Average Satisfaction Rate
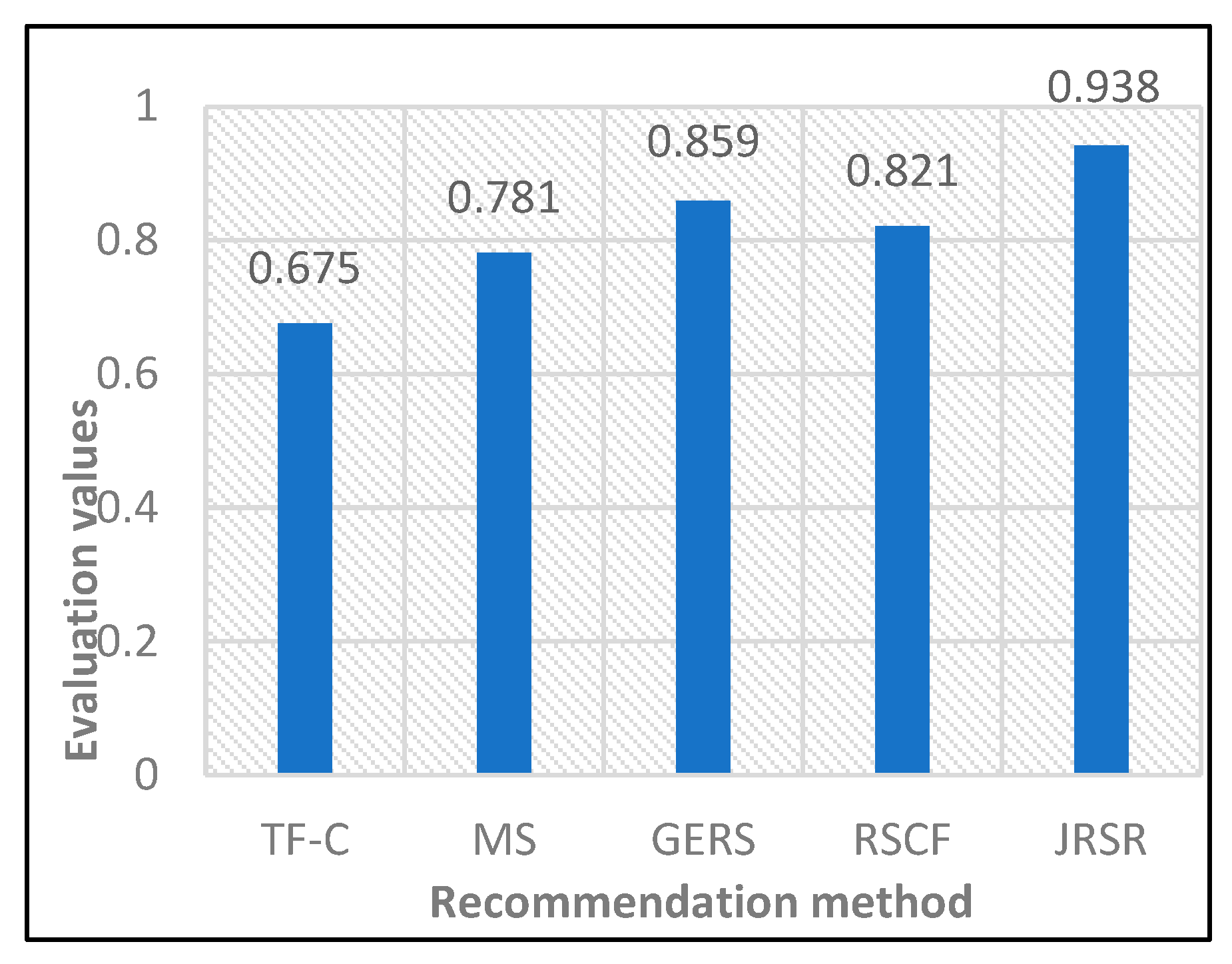
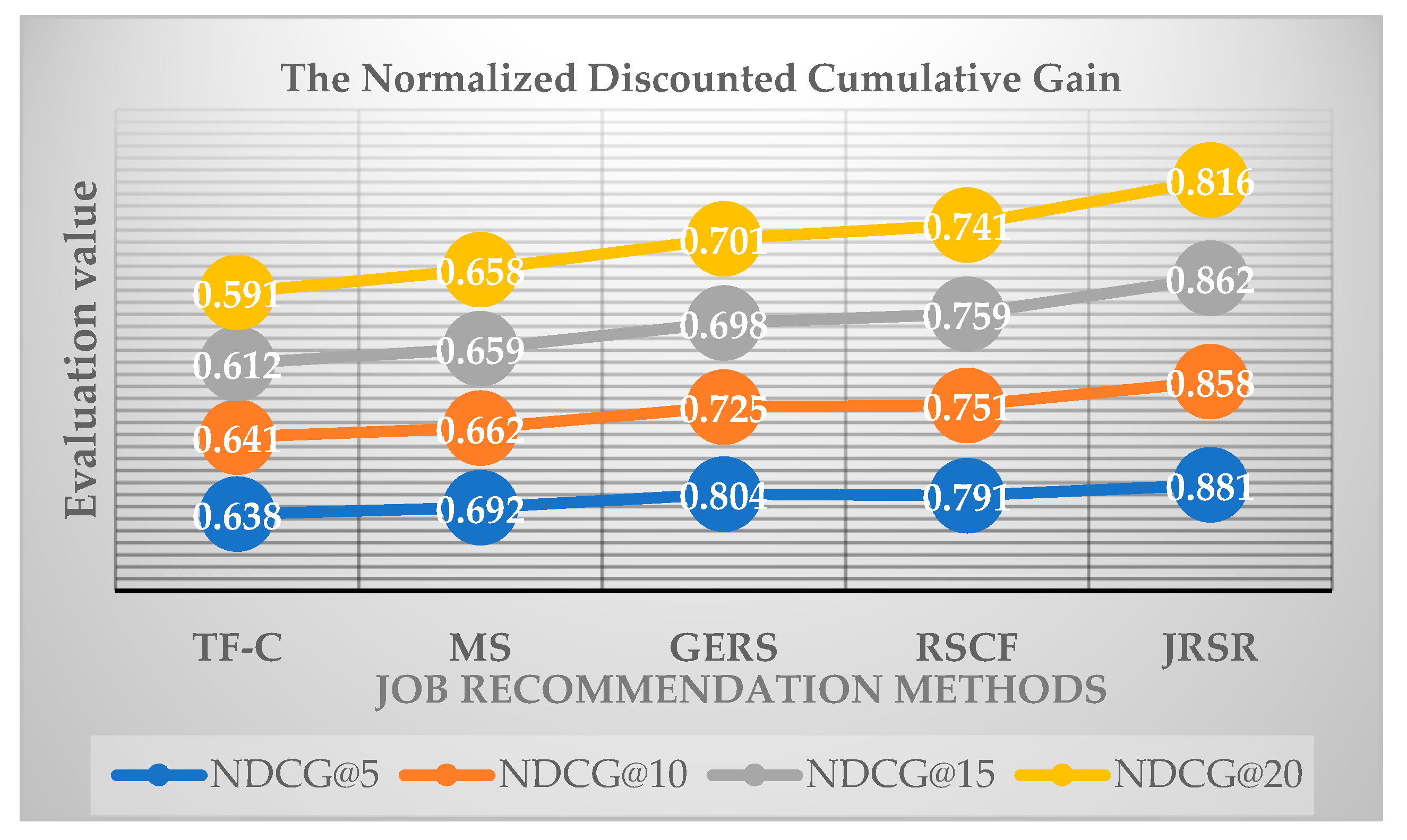
4.3.2. Evaluation Analysis of Normalized Discounted Cumulative Gain
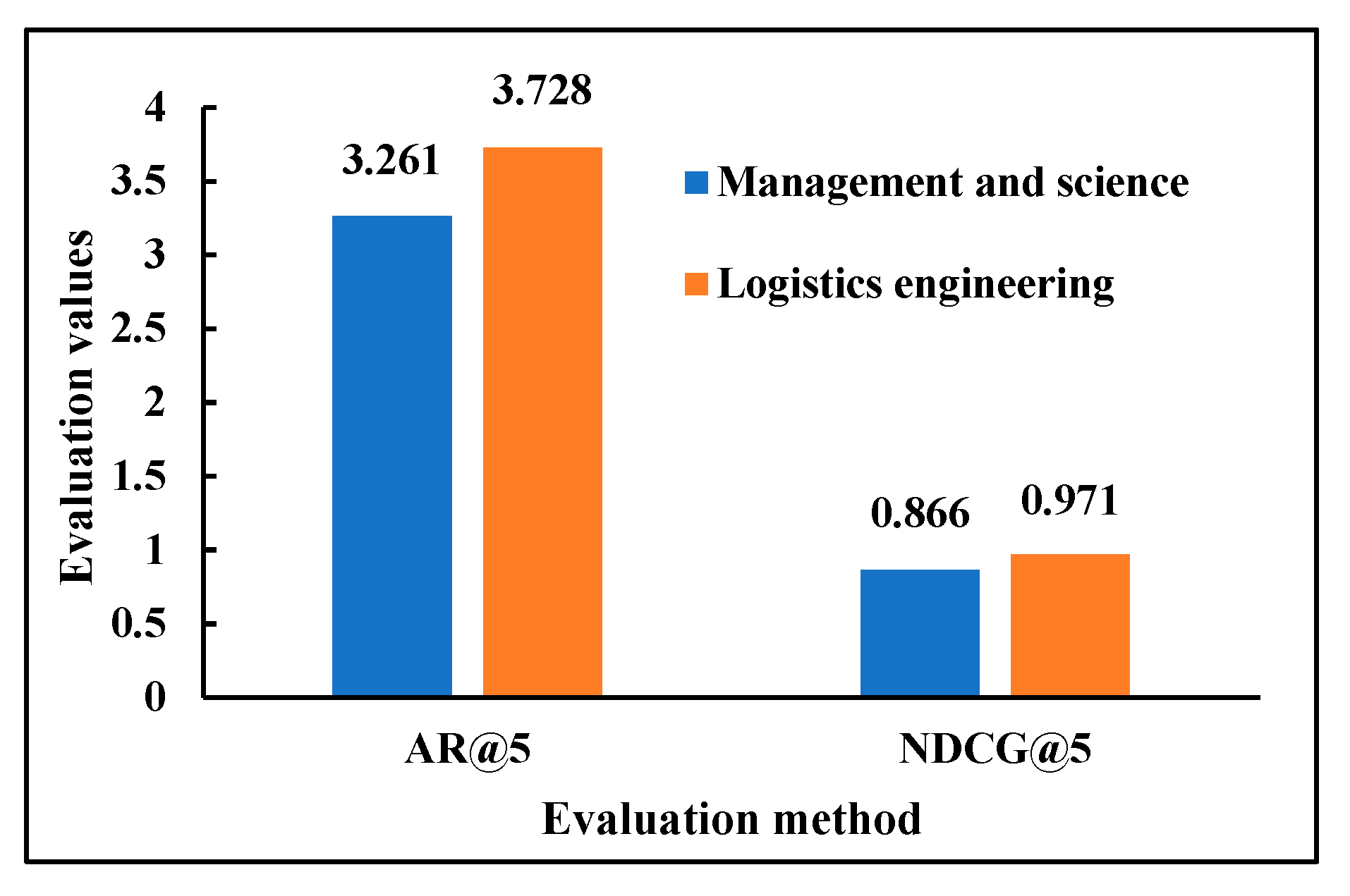
4.3.3. Comparative Analysis of the Recommendation Results under Different Job Sample Sets
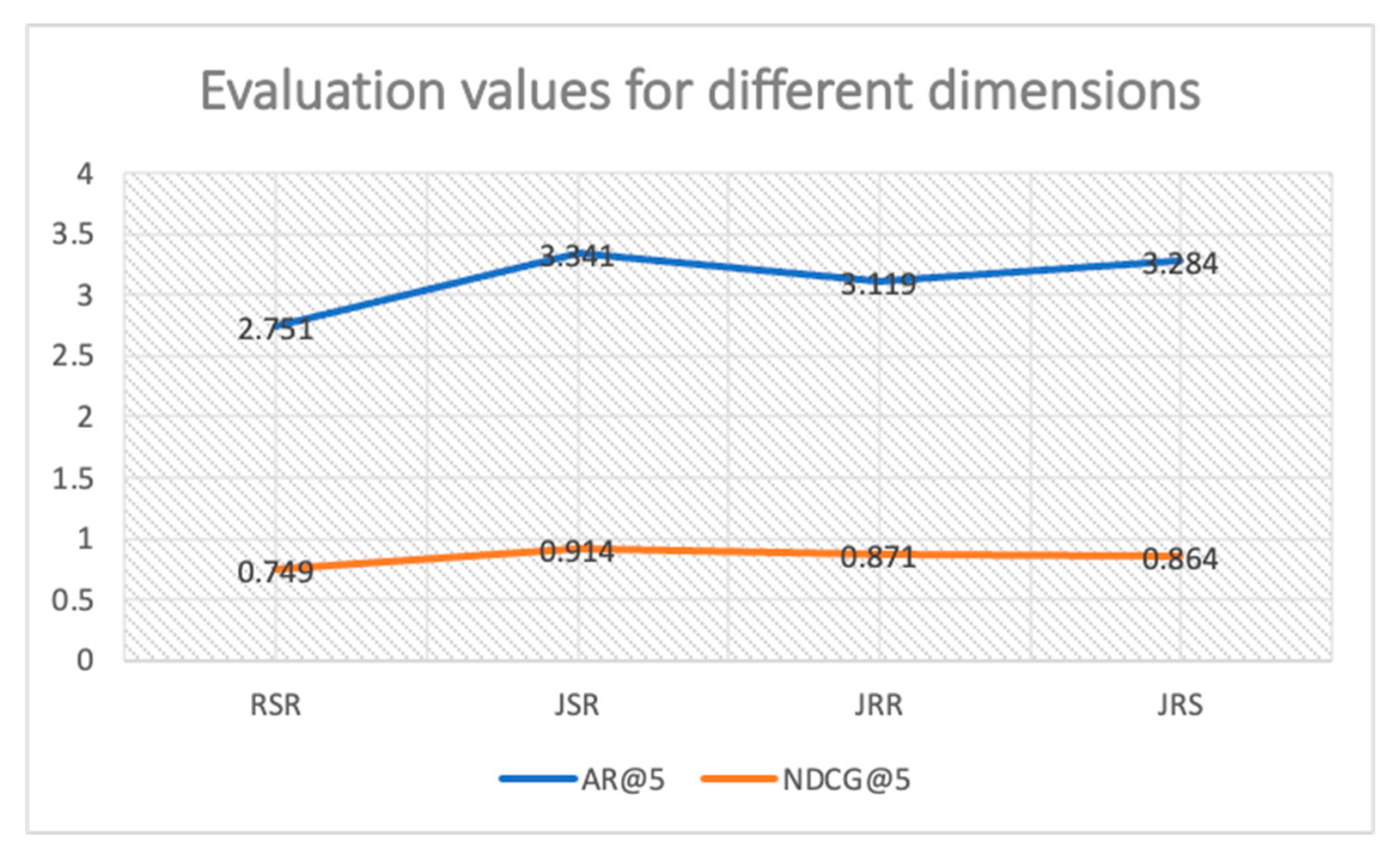
4.3.4. Comparative Analysis of Evaluation Values in Different Dimensions
4.3.5. Comparative Analysis of Evaluated Values for Different Recommendation List Lengths
4.4. Discussion
5. Conclusions
- (a)
- In response to the issue of low accuracy resulting from the omission of low-frequency keywords during the keyword matching calculation, this study used a text similarity calculation method based on a semantic keyword iteration algorithm during the filtering phase. This method effectively mitigated the problem of discarding low-frequency keywords, thereby enhancing calculation accuracy. This study addressed the issues of major structure matching and salary matching between college graduates and jobs, leading to a significant improvement in job recommendation satisfaction.
- (b)
- For the first time, this study introduces graduate social networks and historical employment information of past graduates. Jobs held by previous graduates are recommended to recent graduates, serving as a strategy to address the cold-start problem of the system. With the augmentation of both the sample size in the experimental data and the length of the job recommendation list, there is a concurrent decrease in the average satisfaction rate (AR) and the normalized discounted cumulative gain (NDCG) of the job recommendation method.
- (c)
- Evaluation based on the average satisfaction rate (AR) and normalized discounted cumulative gain (NDCG) metrics demonstrated that the job recommendation method for college graduates proposed in this study outperforms baseline recommendation methods in terms of recommendation performance.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mok, K.H.; Montgomery, C. Remaking higher education for the post-COVID-19 era: Critical reflections on marketization, internationalization and graduate employment. High. Educ. Q. 2021, 75, 373–380. [Google Scholar] [CrossRef]
- Zhao, Y.; He, F.; Feng, Y. Research on the Industrial Structure Upgrading Effect of the Employment Mobility of Graduates from China’s “Double First-Class” Colleges and Universities. Sustainability 2022, 14, 2353. [Google Scholar] [CrossRef]
- Liu, H.; Wang, Z. Research on Causes and Countermeasures for the Difference between Employment Expectation and Actual Employment of College Graduates. In Proceedings of the 2016 International Conference on Education, Bangkok, Thailand, 21–22 April 2016. [Google Scholar]
- Ntale, P.D.; Ssempebwa, J. Designing Organizations for Collaborative Relationships: The Amenability of Social Capital to Inter-Agency Collaboration in the Graduate Employment Context in Uganda. Empl. Responsib. Rights J. 2022, 34, 291–318. [Google Scholar] [CrossRef]
- Evans, S.; Huxley, P. Factors associated with the recruitment and retention of social workers in Wales: Employer and employee perspectives. Health Soc. Care Community 2019, 17, 254–266. [Google Scholar] [CrossRef] [PubMed]
- Rafter, R.; Bradley, K.; Smyth, B. Personalised Retrieval for Online Recruitment Services. In Proceedings of the BCS/IRSG 22nd Annual Colloquium on Information Retrieval (IRSG 2000), Cambridge, UK, 5–7 April 2000. [Google Scholar]
- Bansal, S.; Srivastava, A.; Arora, A. Topic Modeling Driven Content Based Jobs Recommendation Engine for Recruitment Industry. Procedia Comput. Sci. 2017, 122, 865–872. [Google Scholar] [CrossRef]
- Lacic, E.; Reiter-Haas, M.; Kowald, D.; Dareddy, M.R.; Lex, E. Using autoencoders for session-based job recommendations. User Model. User-Adapt. Interact. 2020, 30, 617–658. [Google Scholar] [CrossRef]
- Mostafa, L.; Beshir, S. Job Candidate Rank Approach Using Machine Learning Techniques. In Advanced Machine Learning Technologies and Applications: Proceedings of AMLTA 2021; Springer International Publishing: Cham, Switzerland, 2021; pp. 225–233. [Google Scholar]
- Reusens, M.; Lemahieu, W.; Baesens, B.; Sels, L. A note on explicit versus implicit information for job recommendation. Decis. Support Syst. 2017, 98, 26–35. [Google Scholar] [CrossRef]
- Rafter, R.; Bradley, K.; Smyth, B. Automated collaborative filtering applications for online recruitment services. In Proceedings of the Adaptive Hypermedia and Adaptive Web-Based Systems: International Conference, AH 2000, Trento, Italy, 28–30 August 2000; Proceedings 1. pp. 363–368. [Google Scholar]
- Reusens, M.; Lemahieu, W.; Baesens, B.; Sels, L. Evaluating recommendation and search in the labor market. Knowl.-Based Syst. 2018, 152, 62–69. [Google Scholar] [CrossRef]
- Zhang, Z.J.; Xu, G.W.; Zhang, P.F.; Wang, Y.K. Personalized recommendation algorithm for social networks based on comprehensive trust. Appl. Intell. 2017, 47, 659–669. [Google Scholar] [CrossRef]
- Liu, J.Q.; Fu, L.Y.; Wang, X.B.; Tang, F.L.; Chen, G.H. Joint Recommendations in Multilayer Mobile Social Networks. IEEE Trans. Mob. Comput. 2020, 19, 2358–2373. [Google Scholar] [CrossRef]
- Malherbe, E.; Diaby, M.; Cataldi, M.; Viennet, E.; Aufaure, M.A. Field Selection for Job Categorization and Recommendation to Social Network Users. In Proceedings of the IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Beijing, China, 17–20 August 2014; pp. 588–595. [Google Scholar]
- Chala, S.; Fathi, M. Job Seeker to Vacancy Matching using Social Network Analysis. In Proceedings of the IEEE International Conference on Industrial Technology (ICIT), Toronto, Canada, 22–25 March 2017; pp. 1250–1255. [Google Scholar]
- Urdaneta-Ponte, M.C.; Oleagordia-Ruiz, I.; Mendez-Zorrilla, A. Using LinkedIn Endorsements to Reinforce an Ontology and Machine Learning-Based Recommender System to Improve Professional Skills. Electronics 2022, 11, 1190. [Google Scholar] [CrossRef]
- Corbellini, A.; Mateos, C.; Godoy, D.; Zunino, A.; Schiaffino, S. An architecture and platform for developing distributed recommendation algorithms on large-scale social networks. J. Inf. Sci. Princ. Pract. 2015, 41, 686–704. [Google Scholar] [CrossRef]
- Zhao, R.; Shao, Z.; Zhang, W.; Zhang, J.; Wu, C. A multi-channel multi-tower GNN model for job transfer prediction based on academic social network. Appl. Soft Comput. 2023, 142, 110300. [Google Scholar] [CrossRef]
- Rivas, A.; Channoso, P.; Gonzalez-Briones, A.; Casado-Vara, R.; Manuel Corchado, J. Hybrid job offer recommender system in a social network. Expert Syst. 2019, 36, e12416. [Google Scholar] [CrossRef]
- Van Hoye, G.; Van Hooft, E.A.; Lievens, F. Networking as a job search behaviour: A social network perspective. J. Occup. Organ. Psychol. 2009, 82, 661–682. [Google Scholar] [CrossRef]
- Skeels, M.M.; Grudin, J. When social networks cross boundaries: A case study of workplace use of facebook and linkedin. In Proceedings of the ACM International Conference on Supporting Group Work, Sanibel, FL, USA, 10–13 May 2009; pp. 95–104. [Google Scholar]
- Zhitomirsky-Geffet, M.; Bratspiess, Y. Perceived Effectiveness of Social Networks for Job Search. Libri 2015, 65, 105–118. [Google Scholar] [CrossRef]
- Palank, J. Face it:’Book’no secret to employers. The Washington Times, 17 July 2006; pp. 1–2. [Google Scholar]
- Xia, P.; Liu, B.; Sun, Y.; Chen, C. Reciprocal Recommendation System for Online Dating. In Proceedings of the 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Paris, France, 25–28 August 2015; pp. 234–241. [Google Scholar]
- Liu, J.; Li, C.; Huang, Y.; Han, J. An intelligent medical guidance and recommendation model driven by patient-physician communication data. Front. Public Health 2023, 11, 1098206. [Google Scholar] [CrossRef]
- Ullah, Z.; Jamjoom, M. A smart secured framework for detecting and averting online recruitment fraud using ensemble machine learning techniques. PeerJ Comput. Sci. 2023, 9, e1234. [Google Scholar] [CrossRef]
- Jochen, M. Matching people and jobs: A bilateral recommendation approach. In Proceedings of the 39th Annual Hawaii International Conference on System Sciences (HICSS’06), IEEE Computer Society, Kauai, HI, USA, 4–7 January 2006. [Google Scholar]
- Huang, L. The Establishment of College Student Employment Guidance System Integrating Artificial Intelligence and Civic Education. Math. Probl. Eng. 2022, 2022, 3934381. [Google Scholar] [CrossRef]
- Jochen, M.; Weitzel, T.; Keim, T. Decision support for team staffing: An automated relational recommendation approach. Decis. Support Syst. 2008, 45, 429–447. [Google Scholar]
- Hong, W.; Zheng, S.; Wang, H.; Shi, J. A job recommender system based on user clustering. J. Comput. 2013, 8, 1960–1967. [Google Scholar] [CrossRef]
- Özcan, G.; Ögüdücü, S.G. Applying different classification techniques in reciprocal job recommender system for considering job candidate preferences. In Proceedings of the 2016 11th International Conference for Internet Technology and Secured Transactions (ICITST), Barcelona, Spain, 5–7 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 235–240. [Google Scholar]
- Zhou, Q.; Liao, F.L.; Chen, C.; Ge, L. Job recommendation algorithm for graduates based on personalized preference. CCF Trans. Pervasive Comput. Interact. 2019, 1, 260–274. [Google Scholar] [CrossRef]
- Li, S.; Chuancheng, Y.; Hongguo, W.; Yanhui, D. An Employment Recommendation Algorithm Based on Historical Information of College Graduates. In Proceedings of the 2018 9th International Conference on Information Technology in Medicine and Education (ITME), Hangzhou, China, 19–21 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 708–711. [Google Scholar]
- Shi, S.; Lv, H. A Framework of Graduate Employment Recommendation System and Key Technologies. In Proceedings of the 6th International Conference on Information Engineering for Mechanics & Materials, Huhhot, China, 30–31 July 2016; Atlantis Press: Amsterdam, Netherlands, 2016; pp. 169–174. [Google Scholar]
- Li, W. Research on personalised recommendation algorithm for college students’ employment. Appl. Math. Nonlinear Sci. 2022. [Google Scholar] [CrossRef]
- Assudani, P.J.; Kadu, R.K.; Sheikh, R.; Khanna, T. Smart College Campus Recruitment System. Int. J. Next-Gener. Comput. 2022, 13, 1280–1285. [Google Scholar]
- Quattrone, G.; Capra, L.; De Meo, P.; Ferrara, E.; Ursino, D. Effective retrieval of resources in folksonomies using a new tag similarity measure. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management, Glasgow, UK, 24–28 October 2011; pp. 545–550. [Google Scholar]
- Zhang, M.; Ma, J.; Liu, Z.; Sun, J.; Silva, T. A research analytics framework-supported recommendation approach for supervisor selection. Br. J. Educ. Technol. 2016, 47, 403–420. [Google Scholar] [CrossRef]
- Scott, A.J. The Cultural Economy of Cities. Int. J. Urban Reg. Res. 2010, 21, 323–339. [Google Scholar] [CrossRef]
- Jung, Y.; Suh, Y. Mining the voice of employees: A text mining approach to identifying and analyzing job satisfaction factors from online employee reviews. Decis. Support Syst. 2019, 123, 113074. [Google Scholar] [CrossRef]
- Lou, T.; Tang, J.; Hopcroft, J.; Fang, Z.; Ding, X. Learning to predict reciprocity and triadic closure in social networks. ACM Trans. Knowl. Discov. Data (TKDD) 2013, 7, 1–25. [Google Scholar] [CrossRef]
- Ishitani, Y. Model-based information extraction method tolerant of OCR errors for document images. Int. J. Comput. Process. Orient. Lang. 2012, 15, 165–186. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, C.; Niu, Z. A Research of job recommendation system based on collaborative filtering. In Proceedings of the 2014 Seventh International Symposium on Computational Intelligence and Design, Rome, Italy, 16–18 October 2014; Volume 1, pp. 533–538. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Logistics Graduate Resume Information | |
|---|---|
| Name: Zhang Gender: Female Graduate school: xx university, logistics engineering Research direction: supply chain management supervisor: Li xx Address: Kunming, Yunnan Province | Expected salary CNY: 3000–5000 Expected work location: Southwest Desired position: engaged in logistics-related work Expected working environment: office environment; corporate culture; work prospects; and so on |
| Job Recruitment Information | |
|---|---|
| Recruitment company: xxx Salary level CNY: 5000–6000 Job responsibilities: manage supply chain; cost control Working environment: office environment; corporate culture; employment prospects… Working location: Kunming, Yunnan | Education requirements: graduate degree or above English level: College English Level 6 Job requirements: applicants are logistics-related majors, supply chain research direction is preferred, candidates should be skilled in using matlab software, and so on |
| Recommendation Model | TF-C | MS | GERS | RSCF |
|---|---|---|---|---|
| JRSR | 0.000 | 0.000 | 0.000 | 0.000 |
| Recommendation Model | TF-C | MS | GERS | RSCF |
|---|---|---|---|---|
| JRSR | 0.002 | 0.001 | 0.000 | 0.001 |
| AR@5 | AR@10 | AR@15 | AR@20 | |
| TF-C | 2.532 | 2.528 | 2.471 | 2.418 |
| MS | 2.862 | 2.959 | 2.762 | 2.561 |
| GERS | 3.158 | 3.269 | 3.136 | 2.948 |
| RSCF | 3.258 | 3.163 | 3.216 | 3.117 |
| JRSR | 3.462 | 3.298 | 3.272 | 3.189 |
| NDCG@5 | NDCG@10 | NDCG@15 | NDCG@20 | |
| TF-C | 0.638 | 0.641 | 0.612 | 0.591 |
| MS | 0.692 | 0.662 | 0.659 | 0.658 |
| GERS | 0.804 | 0.725 | 0.698 | 0.701 |
| RSCF | 0.791 | 0.751 | 0.759 | 0.741 |
| JRSR | 0.881 | 0.858 | 0.862 | 0.816 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, J.; Xu, Y.; Gao, J. A Study of Reciprocal Job Recommendation for College Graduates Integrating Semantic Keyword Matching and Social Networking. Appl. Sci. 2023, 13, 12305. https://doi.org/10.3390/app132212305
Yao J, Xu Y, Gao J. A Study of Reciprocal Job Recommendation for College Graduates Integrating Semantic Keyword Matching and Social Networking. Applied Sciences. 2023; 13(22):12305. https://doi.org/10.3390/app132212305
Chicago/Turabian StyleYao, Jinping, Yunhong Xu, and Jiaojiao Gao. 2023. "A Study of Reciprocal Job Recommendation for College Graduates Integrating Semantic Keyword Matching and Social Networking" Applied Sciences 13, no. 22: 12305. https://doi.org/10.3390/app132212305