
A Multi-Fidelity Successive Response Surface Method for Crashworthiness Optimization Problems

Abstract
:1. Introduction
- We extended the SRSM to achieve qualitatively superior optima and potentially improve its computational efficiency. This is accomplished by leveraging GP, adaptive sampling techniques, and multi-fidelity metamodeling.
- Unlike conventional multi-fidelity methods (e.g., basic co-kriging), our approach is based on a method able to effectively handle complex non-linear correlations between different fidelities. We also quickly show how this method benefits from parallel job scheduling on a High-Performance Computer (HPC), enhancing its overall efficiency.
2. Crashworthiness Optimization: Problem Formulation
3. Successive Response Surface
4. Multi-Fidelity Metamodeling
4.1. Background on Gaussian Process
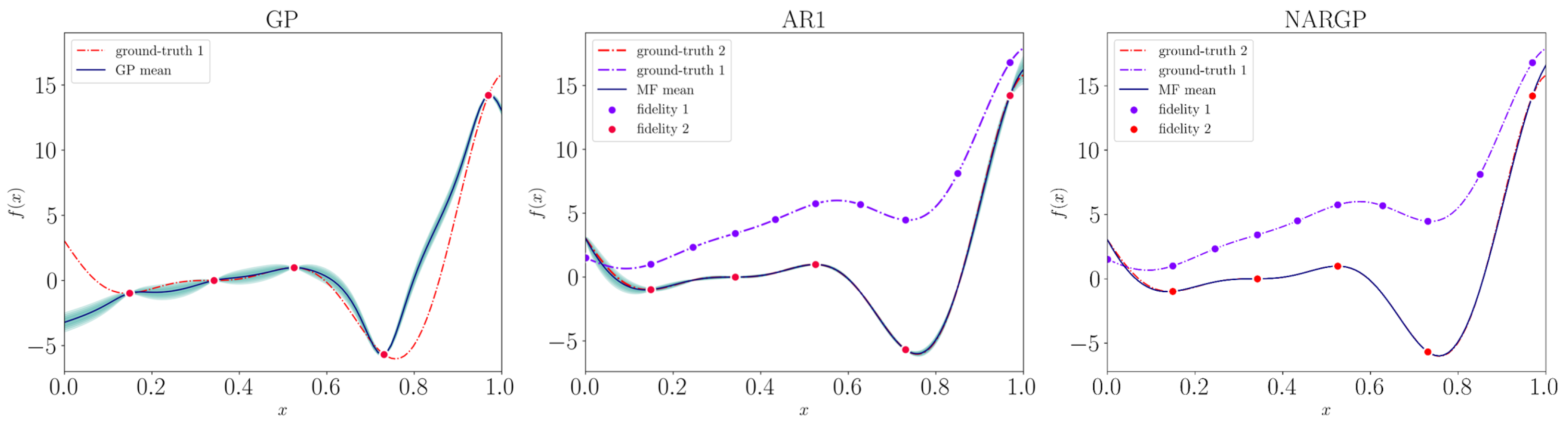
4.2. Linear Multi-Fidelity Metamodeling
4.3. Non-Linear Multi-Fidelity Metamodeling
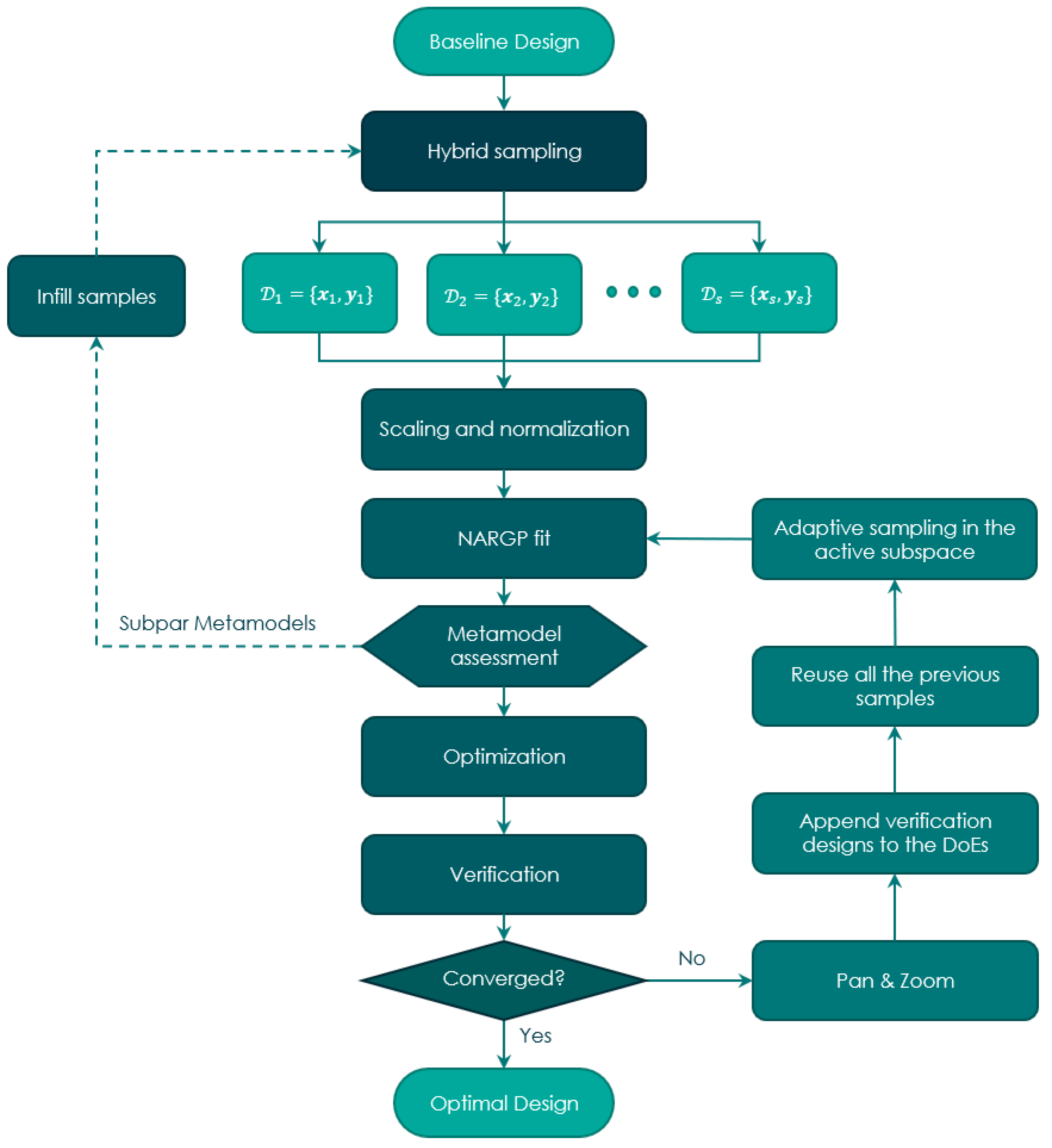
5. Multi-Fidelity Successive Response Surface
5.1. Adaptive Sampling: OLHD and MIPT
5.2. Multi-Fidelity Response Surface and Sample Reuse
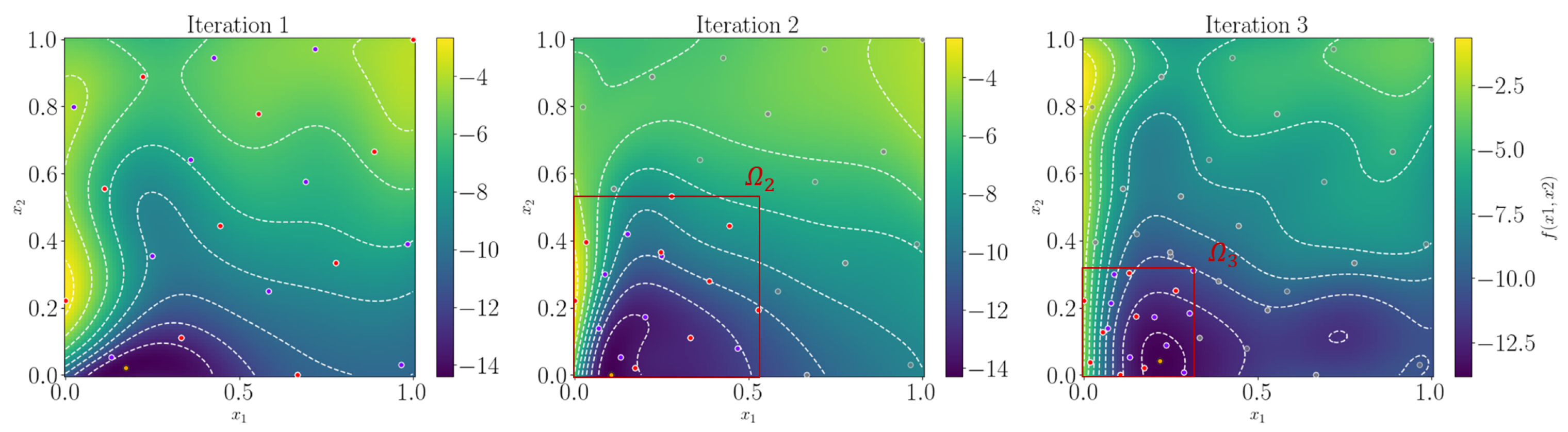
5.3. Adjustment of the RoI
5.4. Optimization Approach: Differential Evolution, Trust Region, and Verification Step
5.5. Convergence Criteria
6. Results and Discussion
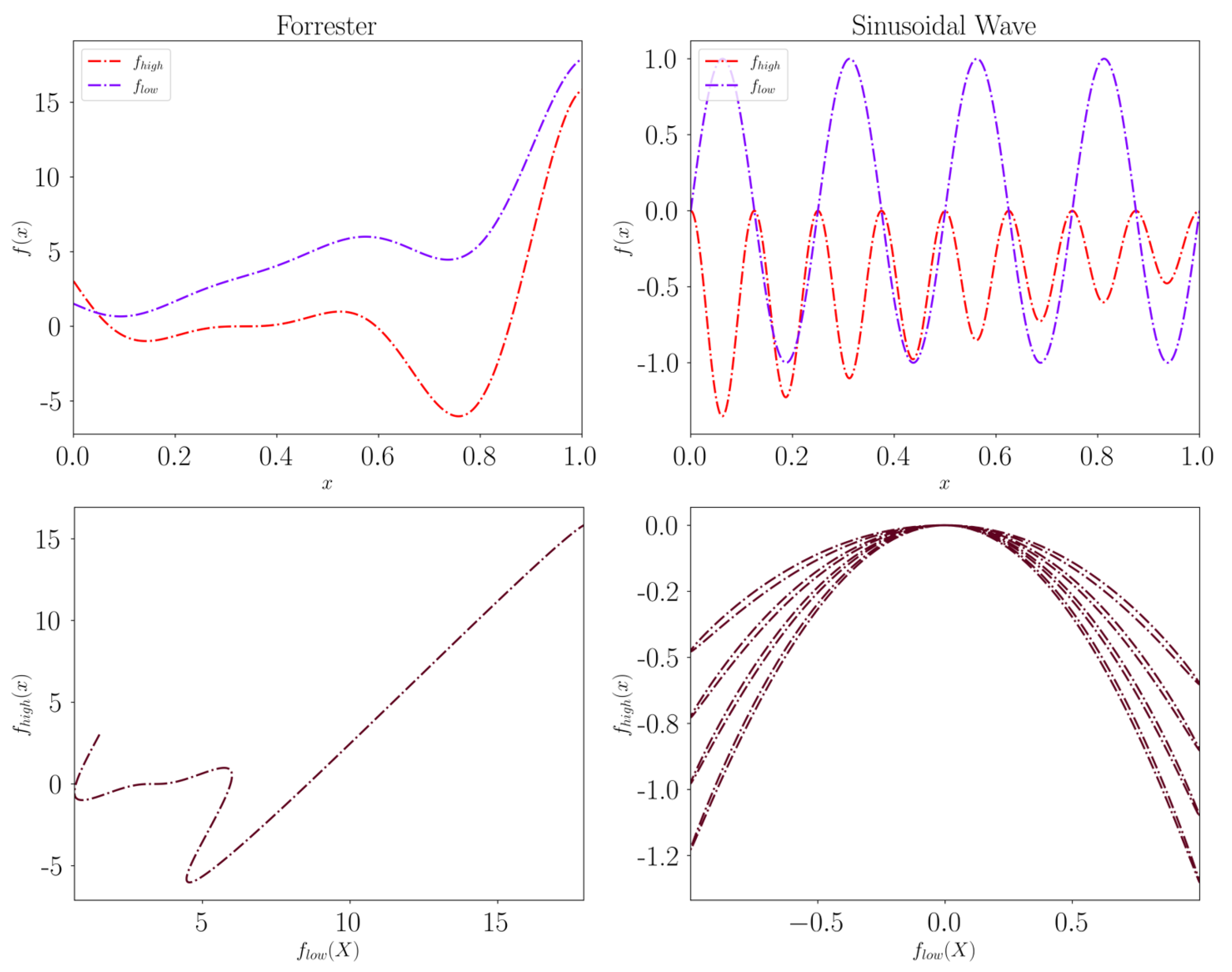
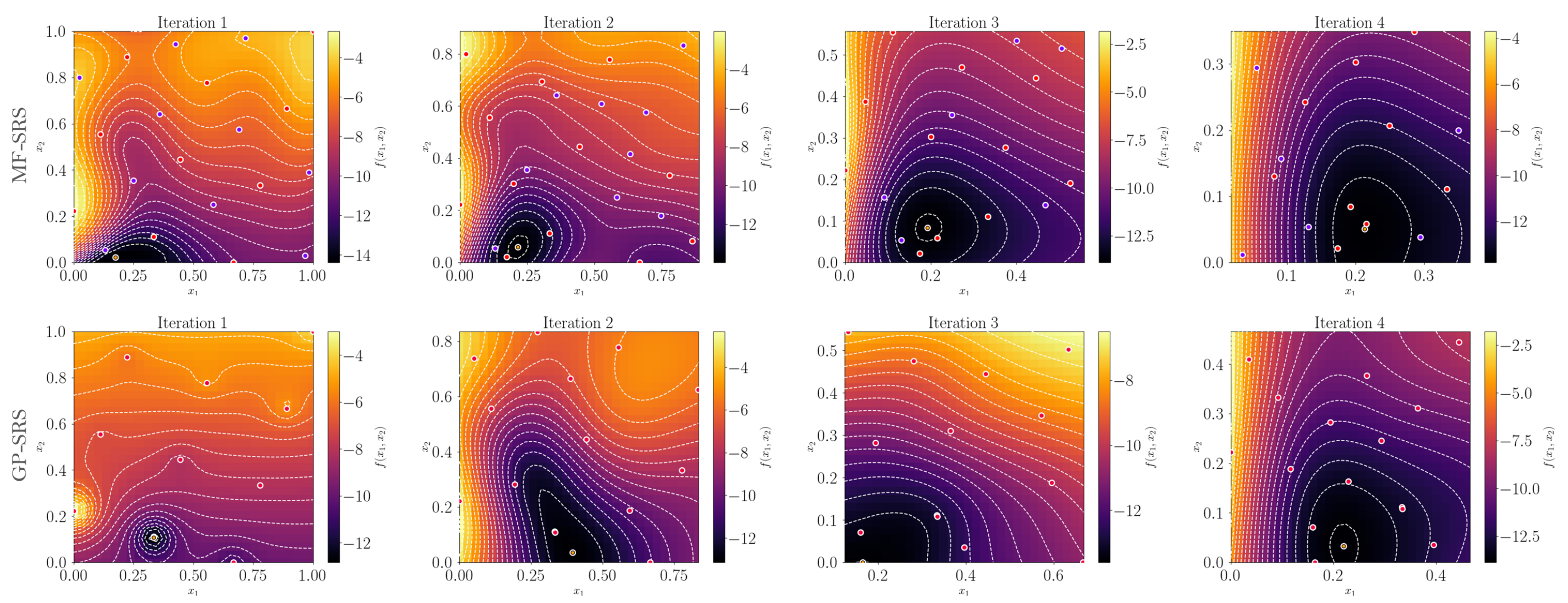
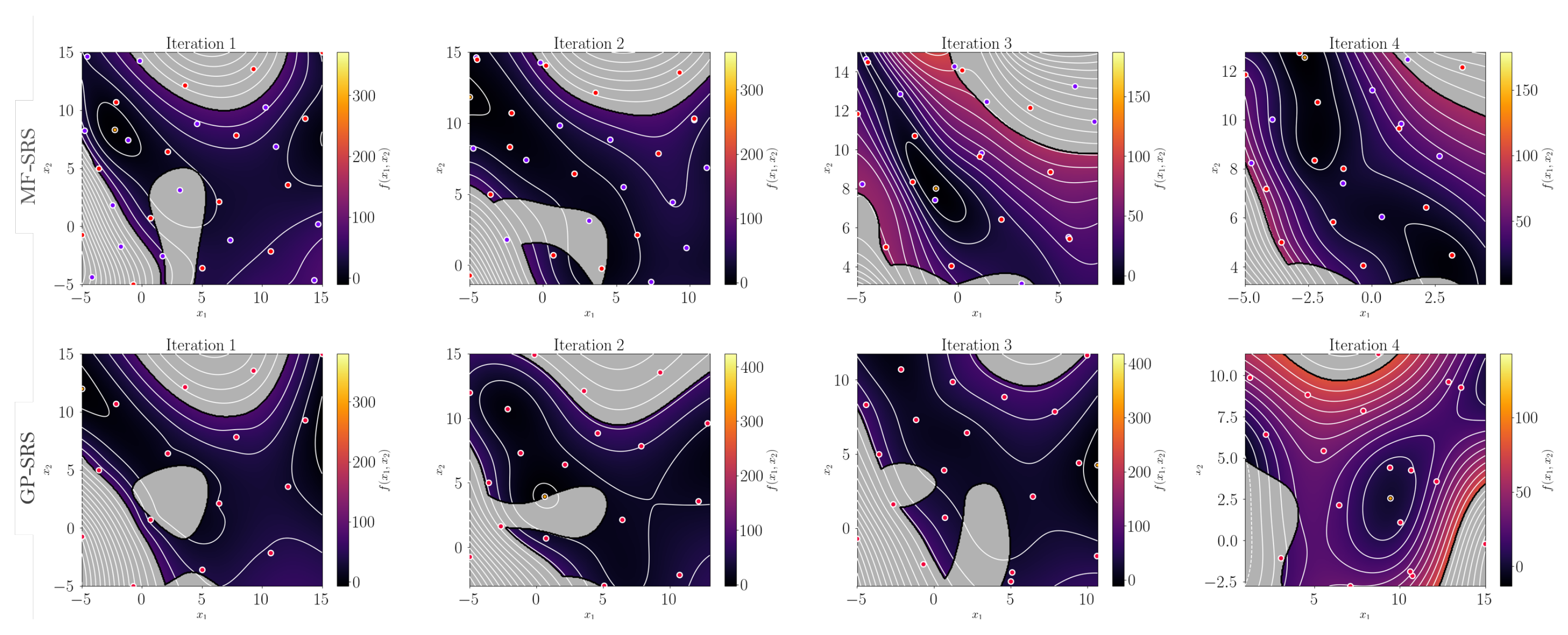
6.1. Synthetic Illustrative Problems
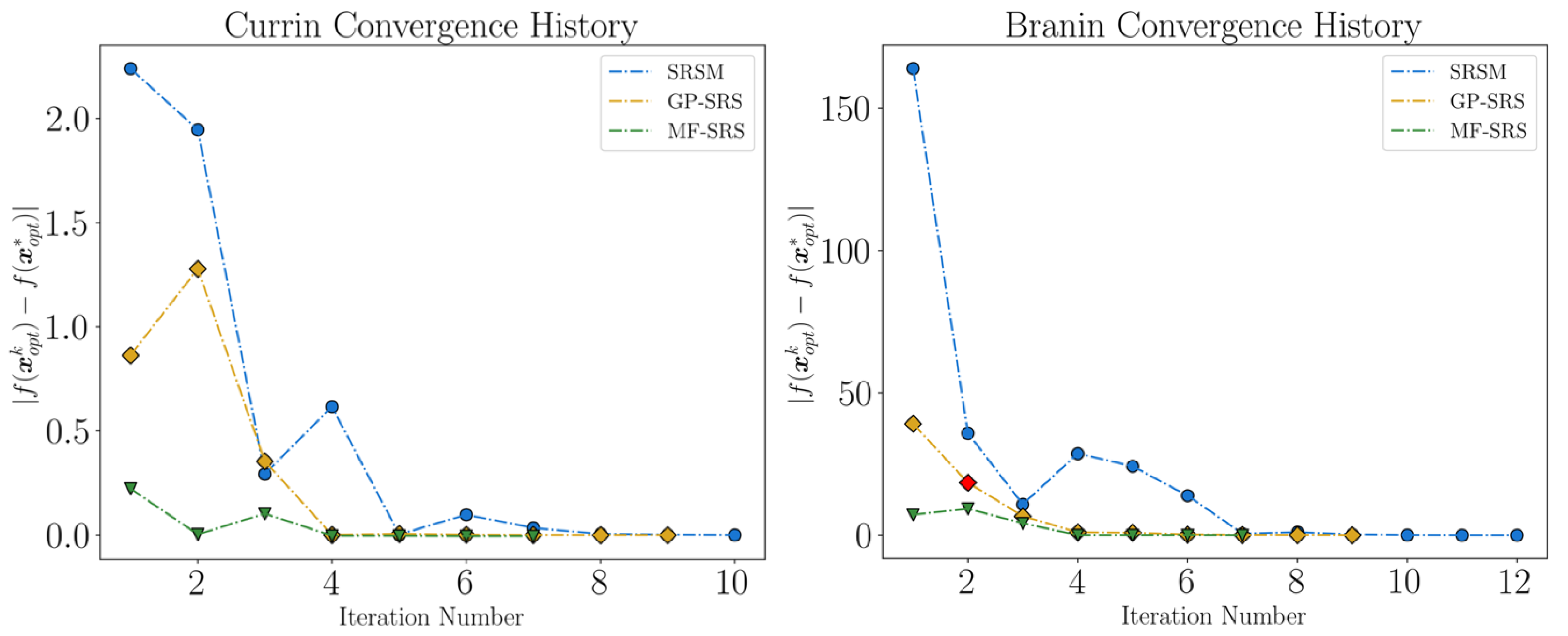
6.2. Results on Benchmark Functions
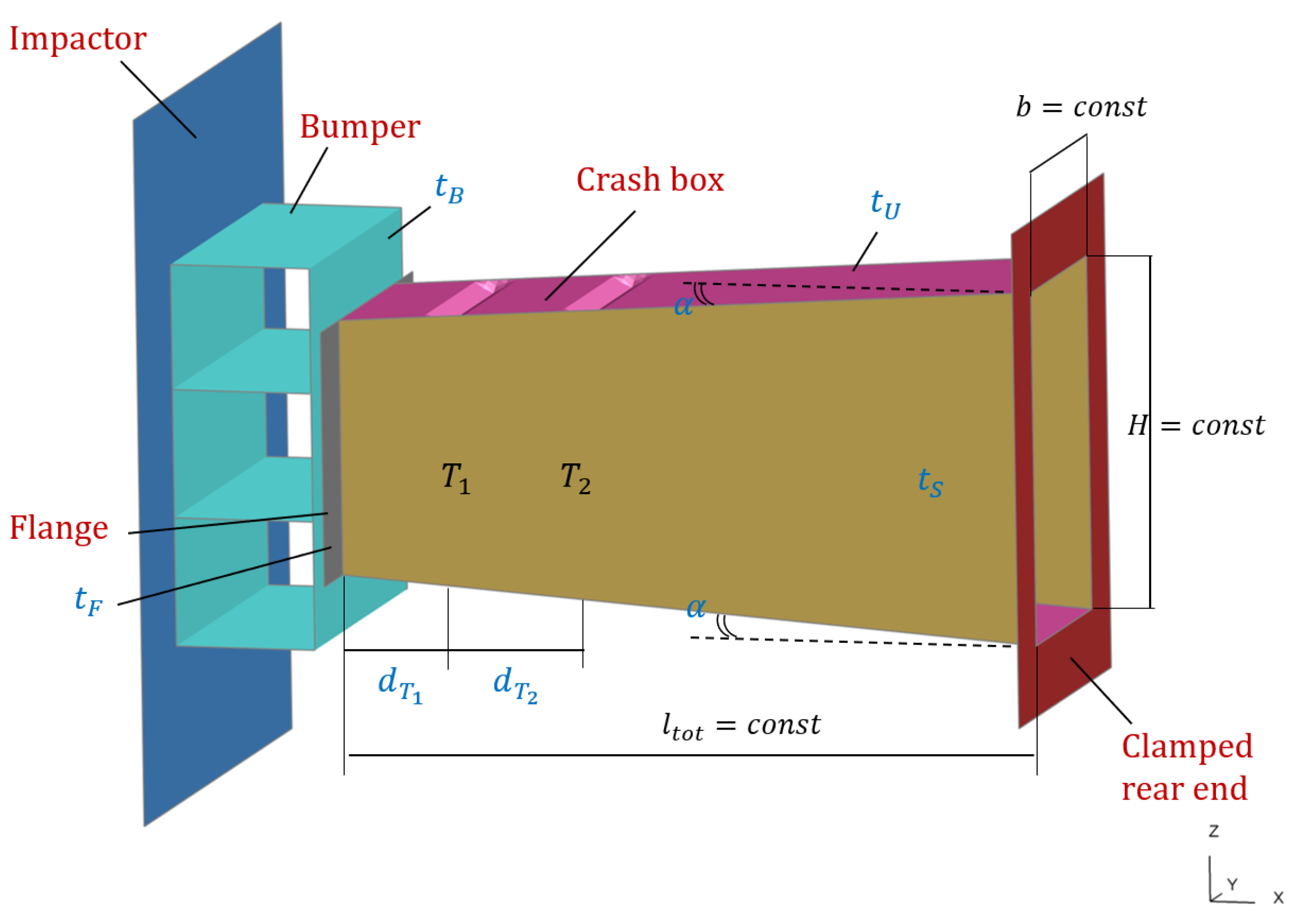
6.3. Engineering Use Case: Crash Box Design
6.3.1. Key Performance Indicators (KPIs)
6.3.2. Problem Formulation
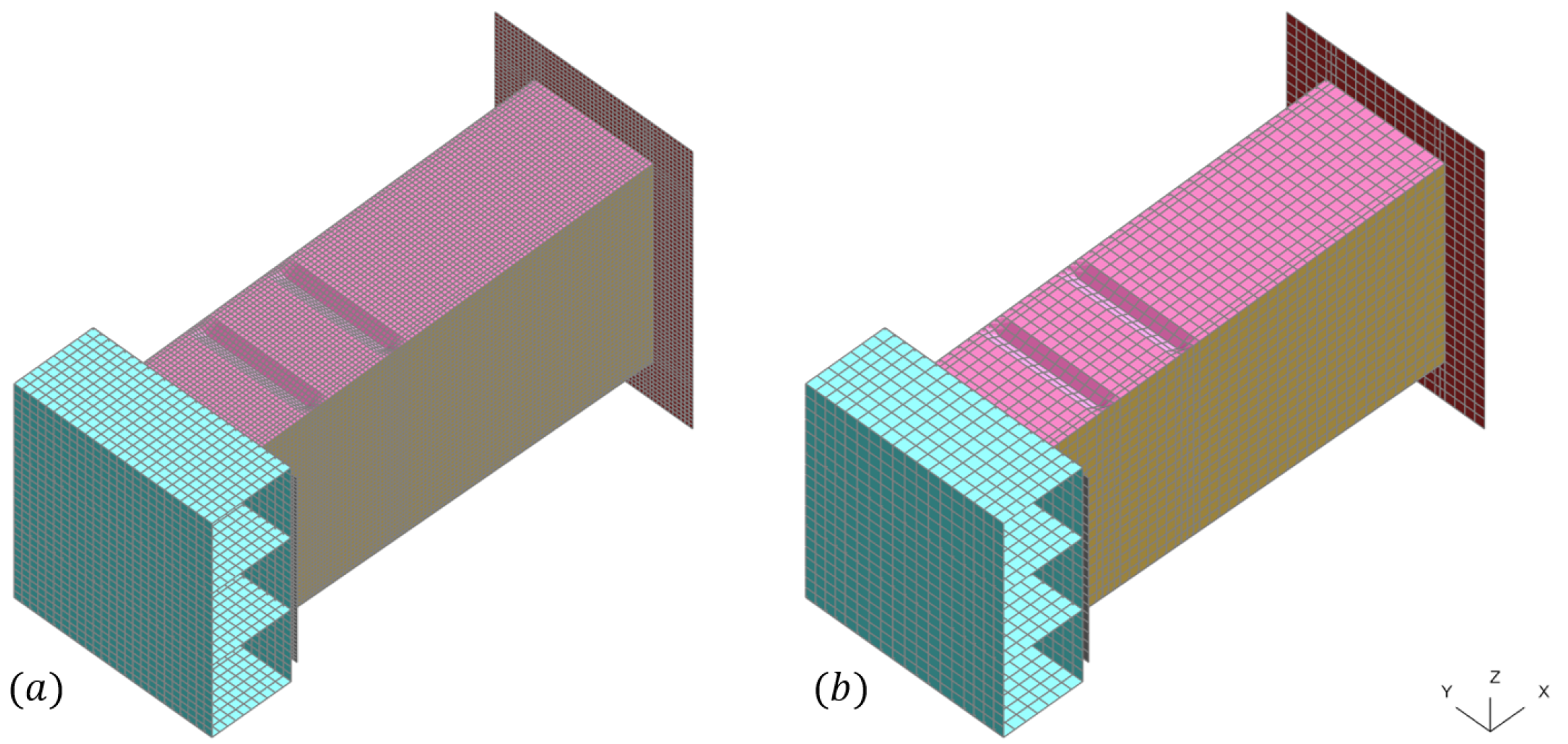
6.3.3. High- and Low-Fidelity Models
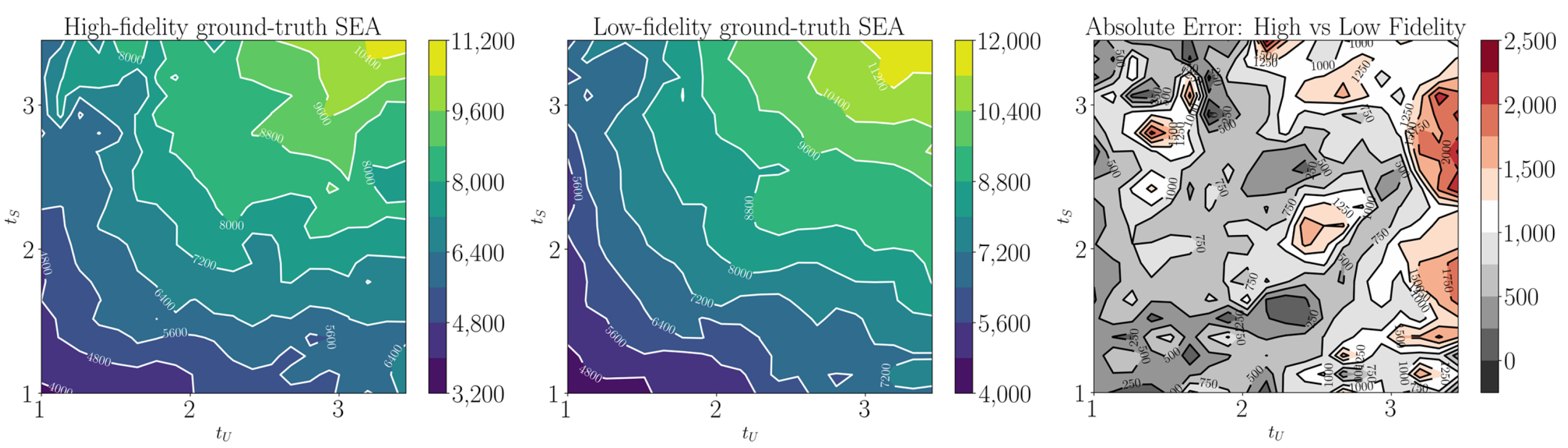
6.4. Results of the Engineering Use Case
6.5. Parallel Job Submission on an HPC
- We use a cluster of with 2 × 32 cores each (AMD EPYC 7601 processors);
- Only one job is submitted on each node at a time. Parallel job submissions across different nodes are allowed, but splitting a single node among multiple jobs is not;
- We use a greedy job scheduler that ideally distributes jobs across nodes once the optimization problem is defined. We assume that the availability of nodes at any given time does not affect the formulation of the optimization problem;
- We assume that the computational cost of low-fidelity jobs is equivalent to a unit cost. Therefore, given the cost ratio, we know that a high-fidelity job has a cost of 6.25 units for this particular problem.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AR1 | Auto-Regressive Order 1 |
| GP | Gaussian Process |
| GP-SRS | Gaussian Process Successive Response Surface |
| MF-SRS | Multi-Fidelity Successive Response Surface |
| NARGP | Non-Linear Auto-Regressive Gaussian Process |
| PRS | Polynomial Response Surface |
| SRSM | Successive Response Surface Method |
Appendix A
Appendix B
Appendix C
Appendix C.1
Appendix C.2

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | High-Fidelity Model | Low-Fidelity Model |
|---|---|---|
| Number of Nodes | 23,826 | 6082 |
| Number of Elements | 23,548 | 5940 |
| Material Model | * MAT_024 | |
| Element Type | Shell Belytschko-Tsay | |
| Contact Type | AUTOMATIC_SURFACE_TO_SURFACE | |
| Erosion | Active | Inactive |
Appendix C.3


Appendix C.4
| Method | (mm) | (mm) | (mm) | (mm) | (mm) | (mm) | (deg) |
|---|---|---|---|---|---|---|---|
| SRSM | 2.1 | 2.6 | 1.0 | 1.0 | 30.1 | 40.0 | 1.0 |
| GP-SRS | 2.3 | 2.5 | 1.2 | 1.7 | 33.2 | 31.1 | 2.8 |
| MF-SRS | 2.4 | 2.7 | 1.0 | 1.5 | 36.2 | 30.0 | 2.7 |
References
- O’Neill, B. Preventing passenger vehicle occupant injuries by vehicle design—A historical perspective from IIHS. Traffic Inj. Prev. 2009, 10, 113–126. [Google Scholar] [CrossRef]
- Sacks, J.; Welch, W.J.; Mitchell, T.J.; Wynn, H.P. Design and Analysis of Computer Experiments. Stat. Sci. 1989, 4, 409–423. [Google Scholar] [CrossRef]
- Bartz-Beielstein, T.; Zaefferer, M. Model-based methods for continuous and discrete global optimization. Appl. Soft Comput. 2017, 55, 154–167. [Google Scholar] [CrossRef]
- Khatouri, H.; Benamara, T.; Breitkopf, P.; Demange, J. Metamodeling techniques for CPU-intensive simulation-based design optimization: A survey. Adv. Model. Simul. Eng. Sci. 2022, 9, 1. [Google Scholar] [CrossRef]
- Kleijnen, J.P.C. A Comment on Blanning’s “Metamodel for Sensitivity Analysis: The Regression Metamodel in Simulation”. Interfaces 1975, 5, 21–23. [Google Scholar] [CrossRef]
- Lualdi, P.; Sturm, R.; Siefkes, T. Exploration-oriented sampling strategies for global surrogate modeling: A comparison between one-stage and adaptive methods. J. Comput. Sci. 2022, 60, 101603. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; Adaptive Computation and Machine Learning; MIT: Cambridge, MA, USA; London, UK, 2006. [Google Scholar]
- Myers, R.H.; Montgomery, D.C.; Anderson-Cook, C.M. Response Surface Methodology: Process and Product Optimization Using Designed Experiments, 4th ed.; Wiley Series in Probability and Statistics; Wiley: Hoboken, NJ, USA, 2016. [Google Scholar]
- Montgomery, D.C. Design and Analysis of Experiments, 10th ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2021. [Google Scholar]
- Gunn, S.R. Support Vector Machines for Classification and Regression; University of Southampton Institutional Repository: Southampton, UK, 1998. [Google Scholar]
- Wang, T.; Li, M.; Qin, D.; Chen, J.; Wu, H. Crashworthiness Analysis and Multi-Objective Optimization for Concave I-Shaped Honeycomb Structure. Appl. Sci. 2022, 12, 420. [Google Scholar] [CrossRef]
- Pawlus, W.; Robbersmyr, K.G.; Karimi, H.R. Performance Evaluation of Feed Forward Neural Networks for Modeling a Vehicle to Pole Central Collision; World Scientific and Engineering Academy and Society (WSEAS): Stevens Point, WI, USA, 2011. [Google Scholar]
- Omar, T.; Eskandarian, A.; Bedewi, N. Vehicle crash modelling using recurrent neural networks. Math. Comput. Model. 1998, 28, 31–42. [Google Scholar] [CrossRef]
- Fang, J.; Sun, G.; Qiu, N.; Kim, N.H.; Li, Q. On design optimization for structural crashworthiness and its state of the art. Struct. Multidiscip. Optim. 2017, 55, 1091–1119. [Google Scholar] [CrossRef]
- Duddeck, F. Multidisciplinary optimization of car bodies. Struct. Multidiscip. Optim. 2008, 35, 375–389. [Google Scholar] [CrossRef]
- Holland, J.H. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence, 1st ed.; The MIT Press: Cambridge, UK, 1992. [Google Scholar]
- Bäck, T. Evolutionary Algorithms in Theory and Practice: Evolution Strategies, Evolutionary Programming, Genetic Algorithms; Thomas Bäck; Oxford University Press: Oxford, UK; New York, NY, USA, 1996. [Google Scholar]
- Slowik, A.; Kwasnicka, H. Evolutionary algorithms and their applications to engineering problems. Neural Comput. Appl. 2020, 32, 12363–12379. [Google Scholar] [CrossRef]
- Kirkpatrick, S.; Gelatt, C.D.; Vecchi, M.P. Optimization by simulated annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef]
- Kurtaran, H.; Eskandarian, A.; Marzougui, D.; Bedewi, N.E. Crashworthiness design optimization using successive response surface approximations. Comput. Mech. 2002, 29, 409–421. [Google Scholar] [CrossRef]
- Stander, N.; Craig, K.J. On the robustness of a simple domain reduction scheme for simulation–based optimization. Eng. Comput. 2002, 19, 431–450. [Google Scholar] [CrossRef]
- Liu, S.T.; Tong, Z.Q.; Tang, Z.L.; Zhang, Z.H. Design optimization of the S-frame to improve crashworthiness. Acta Mech. Sin. 2014, 30, 589–599. [Google Scholar] [CrossRef]
- Naceur, H.; Guo, Y.Q.; Ben-Elechi, S. Response surface methodology for design of sheet forming parameters to control springback effects. Comput. Struct. 2006, 84, 1651–1663. [Google Scholar] [CrossRef]
- Acar, E.; Yilmaz, B.; Güler, M.A.; Altin, M. Multi-fidelity crashworthiness optimization of a bus bumper system under frontal impact. J. Braz. Soc. Mech. Sci. Eng. 2020, 42, 493. [Google Scholar] [CrossRef]
- Lönn, D.; Bergman, G.; Nilsson, L.; Simonsson, K. Experimental and finite element robustness studies of a bumper system subjected to an offset impact loading. Int. J. Crashworthiness 2011, 16, 155–168. [Google Scholar] [CrossRef]
- Aspenberg, D.; Jergeus, J.; Nilsson, L. Robust optimization of front members in a full frontal car impact. Eng. Optim. 2013, 45, 245–264. [Google Scholar] [CrossRef]
- Nilsson, L.; Redhe, M. (Eds.) An Investigation of Structural Optimization in Crashworthiness Design Using a Stochastic Approach; Livermore Software Corporation: Dearborn, MI, USA, 2004. [Google Scholar]
- Redhe, M.; Giger, M.; Nilsson, L. An investigation of structural optimization in crashworthiness design using a stochastic approach. Struct. Multidiscip. Optim. 2004, 27, 446–459. [Google Scholar] [CrossRef]
- Stander, N.; Reichert, R.; Frank, T. Optimization of nonlinear dynamical problems using successive linear approximations. In Proceedings of the 8th Symposium on Multidisciplinary Analysis and Optimization, Long Beach, CA, USA, 6 September 2000. [Google Scholar] [CrossRef]
- Kennedy, M.C.; O’Hagan, A. Predicting the Output from a Complex Computer Code When Fast Approximations Are Available. Biometrika 2000, 87, 1–13. [Google Scholar] [CrossRef]
- Le Gratiet, L.; Garnier, J. Recursive co-kriging model for design of computer experiments with multiple levels of fidelity. Int. J. Uncertain. Quantif. 2014, 4, 365–386. [Google Scholar] [CrossRef]
- Duvenaud, D. Automatic Model Construction with Gaussian Processes. Ph.D. Thesis, Apollo—University of Cambridge Repository, Cambridge, UK, 2014. [Google Scholar] [CrossRef]
- Hagan, A.O. A Markov Property for Covariance Structures; University of Nottingham: Nottingham, UK, 1998. [Google Scholar]
- Forrester, A.I.J.; Sóbester, A.; Keane, A.J. Engineering Design via Surrogate Modelling: A Practical Guide; J. Wiley: Chichester West Sussex, UK; Hoboken, NJ, USA, 2008. [Google Scholar]
- Perdikaris, P.; Karniadakis, G.E. Model inversion via multi-fidelity Bayesian optimization: A new paradigm for parameter estimation in haemodynamics, and beyond. J. R. Soc. Interface 2016, 13. [Google Scholar] [CrossRef]
- Perdikaris, P.; Raissi, M.; Damianou, A.; Lawrence, N.D.; Karniadakis, G.E. Nonlinear information fusion algorithms for data-efficient multi-fidelity modelling. Proc. R. Soc. Math. Phys. Eng. Sci. 2017, 473, 20160751. [Google Scholar] [CrossRef]
- Van Dam, E.R.; Husslage, B.; den Hertog, D.; Melissen, H. Maximin Latin Hypercube Designs in Two Dimensions. Oper. Res. 2007, 55, 158–169. [Google Scholar] [CrossRef]
- Crombecq, K.; Laermans, E.; Dhaene, T. Efficient space-filling and non-collapsing sequential design strategies for simulation-based modeling. Eur. J. Oper. Res. 2011, 214, 683–696. [Google Scholar] [CrossRef]
- Van Dam, E.; den Hertog, D.; Husslage, B.; Rennen, G. Space-Filling Designs. 2015. Available online: https://www.spacefillingdesigns.nl/ (accessed on 15 July 2023).
- Viana, F.A.C.; Venter, G.; Balabanov, V. An algorithm for fast optimal Latin hypercube design of experiments. Int. J. Numer. Methods Eng. 2010, 82, 135–156. [Google Scholar] [CrossRef]
- Hao, P.; Feng, S.; Li, Y.; Wang, B.; Chen, H. Adaptive infill sampling criterion for multi-fidelity gradient-enhanced kriging model. Struct. Multidiscip. Optim. 2020, 62, 353–373. [Google Scholar] [CrossRef]
- Loeppky, J.L.; Sacks, J.; Welch, W.J. Choosing the Sample Size of a Computer Experiment: A Practical Guide. Technometrics 2009, 51, 366–376. [Google Scholar] [CrossRef]
- Nguyen, V.; Rana, S.; Gupta, S.K.; Li, C.; Venkatesh, S. Budgeted Batch Bayesian Optimization. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 1107–1112. [Google Scholar] [CrossRef]
- Gao, B.; Ren, Y.; Jiang, H.; Xiang, J. Sensitivity analysis-based variable screening and reliability optimisation for composite fuselage frame crashworthiness design. Int. J. Crashworthiness 2019, 24, 380–388. [Google Scholar] [CrossRef]
- Fiore, A.; Marano, G.C.; Greco, R.; Mastromarino, E. Structural optimization of hollow-section steel trusses by differential evolution algorithm. Int. J. Steel Struct. 2016, 16, 411–423. [Google Scholar] [CrossRef]
- Loja, M.; Mota Soares, C.M.; Barbosa, J.I. Optimization of magneto-electro-elastic composite structures using differential evolution. Compos. Struct. 2014, 107, 276–287. [Google Scholar] [CrossRef]
- Storn, R. On the usage of differential evolution for function optimization. In Proceedings of the 1996 Biennial conference of the North American Fuzzy Information Processing Society, Berkeley, CA, USA, 19–22 June 1996; Smith, M.H.E., Ed.; IEEE: New York, NY, USA, 1996; pp. 519–523. [Google Scholar] [CrossRef]
- Storn, R.; Price, K. Differential Evolution—A Simple and Efficient Heuristic for global Optimization over Continuous Spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Hansen, N.; Auger, A.; Ros, R.; Mersmann, O.; Tušar, T.; Brockhoff, D. COCO: A platform for comparing continuous optimizers in a black-box setting. Optim. Methods Softw. 2021, 36, 114–144. [Google Scholar] [CrossRef]
- Conn, A.R.; Gould, N.I.M.; Toint, P.L. Trust-Region Methods; MPS-SIAM Series on Optimization; SIAM: Philadelphia, PA, USA, 2000. [Google Scholar] [CrossRef]
- Querin, O.M.; Victoria, M.; Alonso, C.; Ansola, R.; Martí, P. Chapter 3—Discrete Method of Structural Optimization. In Topology Design Methods for Structural Optimization [Electronic Resource]; Querin, O.M., Ed.; Academic Press: London, UK, 2017; pp. 27–46. [Google Scholar] [CrossRef]
- Forrester, A.I.; Sóbester, A.; Keane, A.J. Multi-fidelity optimization via surrogate modelling. Proc. R. Soc. Math. Phys. Eng. Sci. 2007, 463, 3251–3269. [Google Scholar] [CrossRef]
- Van Rijn, S.; Schmitt, S. MF2: A Collection of Multi-Fidelity Benchmark Functions in Python. J. Open Source Softw. 2020, 5, 2049. [Google Scholar] [CrossRef]
- Xiong, S.; Qian, P.Z.G.; Wu, C.F.J. Sequential Design and Analysis of High-Accuracy and Low-Accuracy Computer Codes. Technometrics 2013, 55, 37–46. [Google Scholar] [CrossRef]
- Dong, H.; Song, B.; Wang, P.; Huang, S. Multi-fidelity information fusion based on prediction of kriging. Struct. Multidiscip. Optim. 2015, 51, 1267–1280. [Google Scholar] [CrossRef]
- Mortazavi Moghaddam, A.; Kheradpisheh, A.; Asgari, M. A basic design for automotive crash boxes using an efficient corrugated conical tube. Proc. Inst. Mech. Eng. Part J. Automob. Eng. 2021, 235, 1835–1848. [Google Scholar] [CrossRef]
- Xiang, Y.; Wang, M.; Yu, T.; Yang, L. Key Performance Indicators of Tubes and Foam-Filled Tubes Used as Energy Absorbers. Int. J. Appl. Mech. 2015, 07, 1550060. [Google Scholar] [CrossRef]
- Kröger, M. Methodische Auslegung und Erprobung von Fahrzeug-Crashstrukturen. Ph.D. Thesis, Hannover Universität, Hannover, Germany, 2002. [Google Scholar] [CrossRef]



















| Variable Design | Label | Unit | Lower Bound | Upper Bound |
|---|---|---|---|---|
| Upper crash box thickness | (mm) | 1.0 | 3.5 | |
| Side crash box thickness | (mm) | 1.0 | 3.5 | |
| Bumper cross member thickness | (mm) | 1.0 | 3.0 | |
| Flange thickness | (mm) | 1.0 | 4.0 | |
| Flange to distance | (mm) | 20.0 | 70.0 | |
| to distance | (mm) | 30.0 | 100.0 | |
| Angle to horizontal plane | 1.0 | 3.5 |
| Method | (J/kg) | (kN) | (kN) | (J) | |||
|---|---|---|---|---|---|---|---|
| SRSM | 19 | 8159.8 | 51.9 | 26.9 | 271.9 | 0.52 | 0.48 |
| GP-SRS | 17 | 8233.2 | 59.0 | 28.5 | 260.8 | 0.51 | 0.48 |
| MF-SRS | 15 | 9313.5 | 61.5 | 31.9 | 244.2 | 0.51 | 0.49 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lualdi, P.; Sturm, R.; Siefkes, T. A Multi-Fidelity Successive Response Surface Method for Crashworthiness Optimization Problems. Appl. Sci. 2023, 13, 11452. https://doi.org/10.3390/app132011452
Lualdi P, Sturm R, Siefkes T. A Multi-Fidelity Successive Response Surface Method for Crashworthiness Optimization Problems. Applied Sciences. 2023; 13(20):11452. https://doi.org/10.3390/app132011452
Chicago/Turabian StyleLualdi, Pietro, Ralf Sturm, and Tjark Siefkes. 2023. "A Multi-Fidelity Successive Response Surface Method for Crashworthiness Optimization Problems" Applied Sciences 13, no. 20: 11452. https://doi.org/10.3390/app132011452