

SbMBR Tree—A Spatiotemporal Data Indexing and Compression Algorithm for Data Analysis and Mining

Abstract
:1. Introduction
- We introduce a hierarchical indexing structure, which takes full advantage of the feature that adjacent information in some spatiotemporal regions is similar. Building a tree based on local data similarity measurement allows us to control errors precisely for data compression and range query.
- For particular cross-domain data mining and analysis scenarios, the lossy effect on data utility is effectively estimated via a comparison of mutual information calculated before compression and after reconstruction.
- We evaluate the proposed algorithms based on actual datasets. To further demonstrate the advantages of our algorithms, we also compared them to some of the typical indexing and compression algorithms. The results provide reasonable shreds of evidence to support all the advantages we claimed.
2. Related Work
2.1. Data Compression Methods
2.2. Tree-Based Data Indexing Methods
3. Proposed Methodology
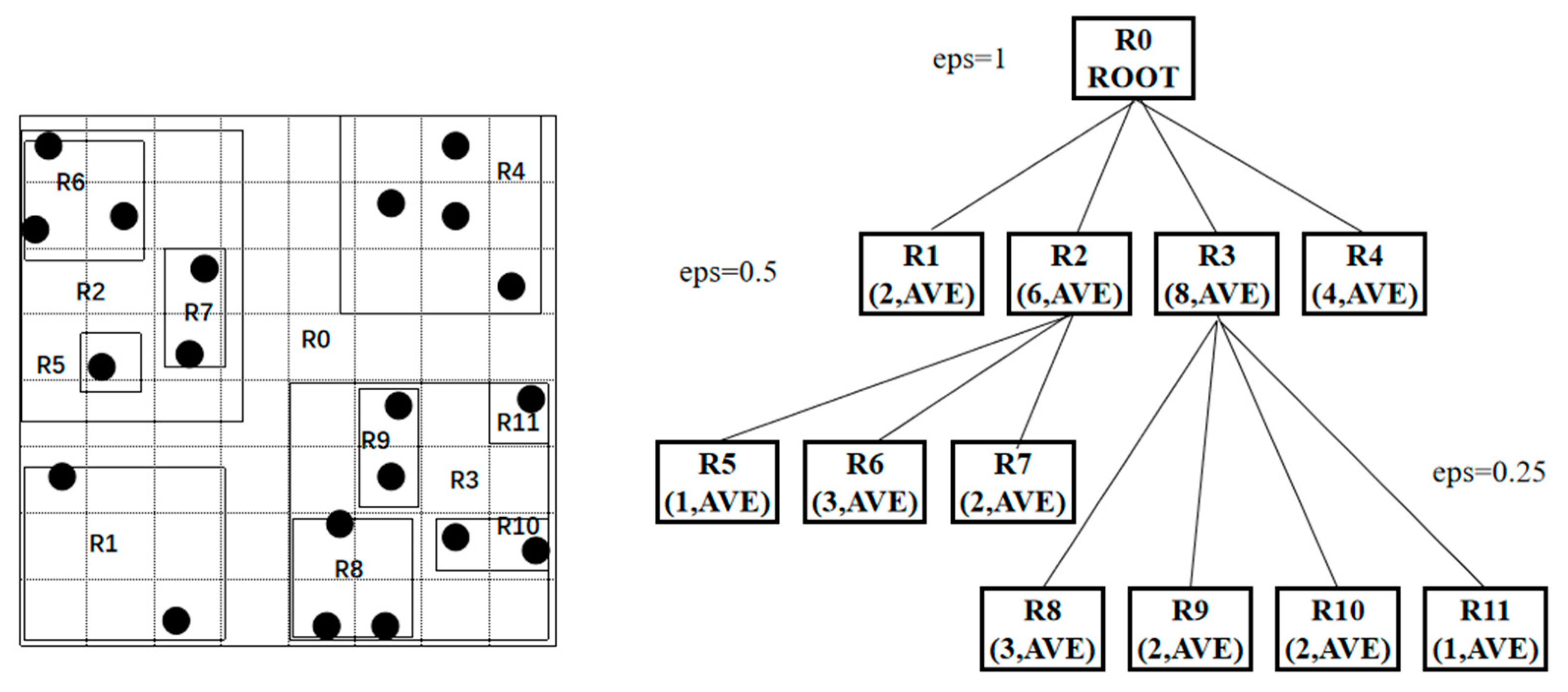
3.1. Structure of SbMBR Tree
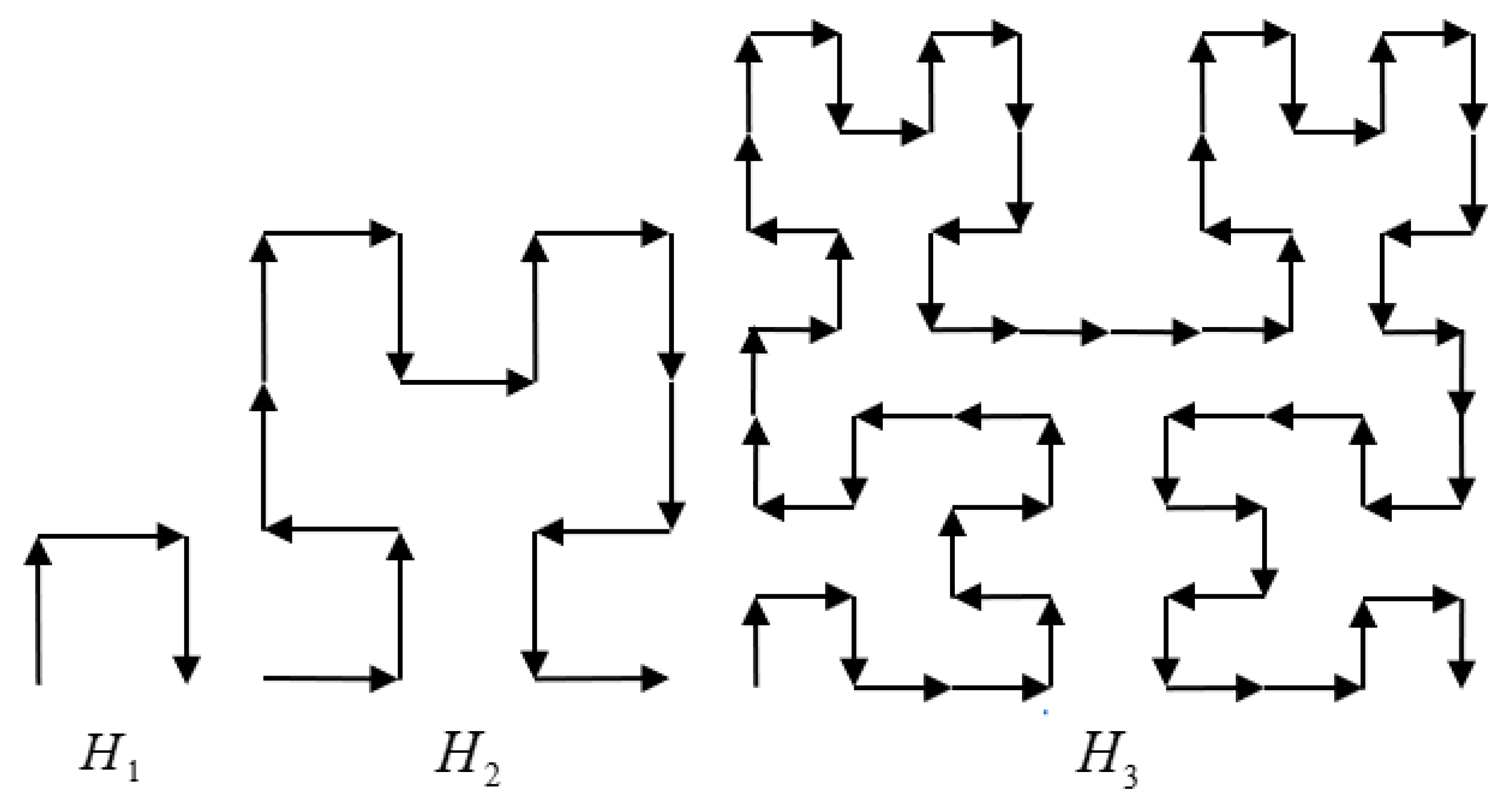
3.2. Construct MBRs with Hilbert Curve
| Algorithm 1: Merge MBRs with the Hilbert curve |
| Input: A set of MBRs with the same maximum error value p, the maximum error of new MBRs to be obtained x Output: A set of new MBRs with given maximum error value; inclusion relationship between new MBRs to be obtained and existing MBRs |
|
3.3. Indexing Algorithm
| Algorithm 2: Build SbMBR tree |
| Input: spatial data D, the maximum error of leaf nodes x Output: the SbMBR tree |
|
| Algorithm 3: Range query |
| Input: the root node of a subtree root, rectangle range R, maximum error eps Output: A set of MBRs contained in range R |
|
3.4. Error Estimation Method for Data Analysis
3.4.1. Mutual Information
3.4.2. Normalization
3.5. Complexity Analysis
4. Experimentation and Results
4.1. Experimental Setup
- Processor: Intel© Core© i7-10875H CPU @ 2.30 GHz
- RAM: 16 GB
- OS: Ubuntu 22.04
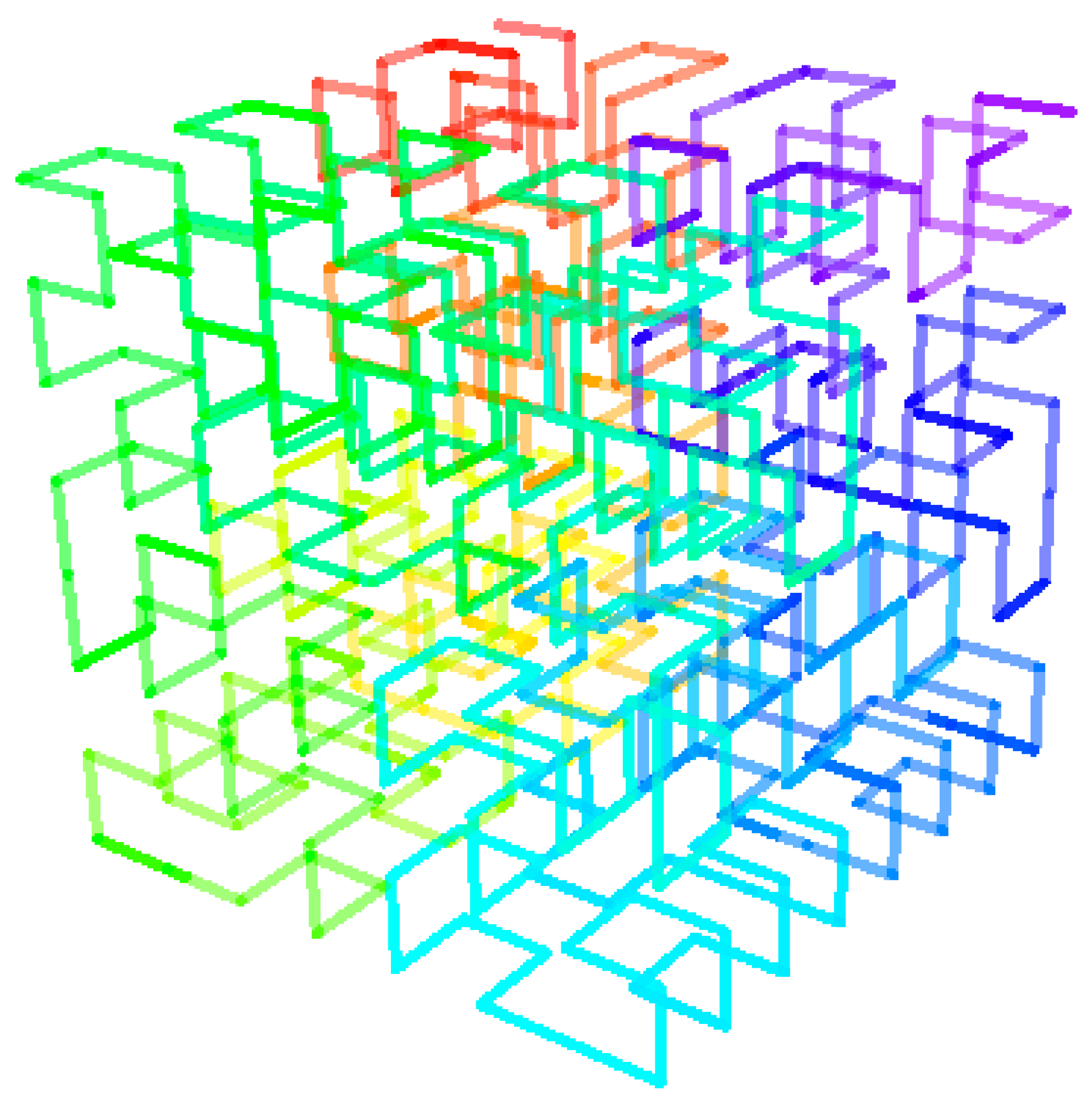
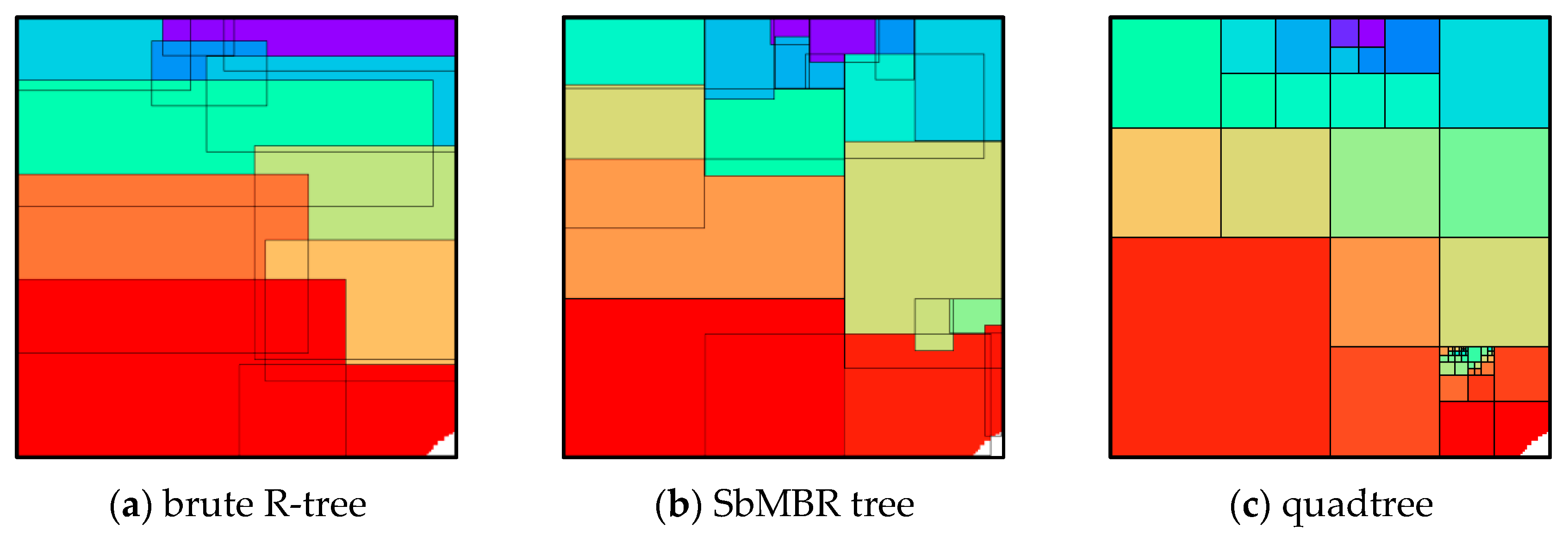
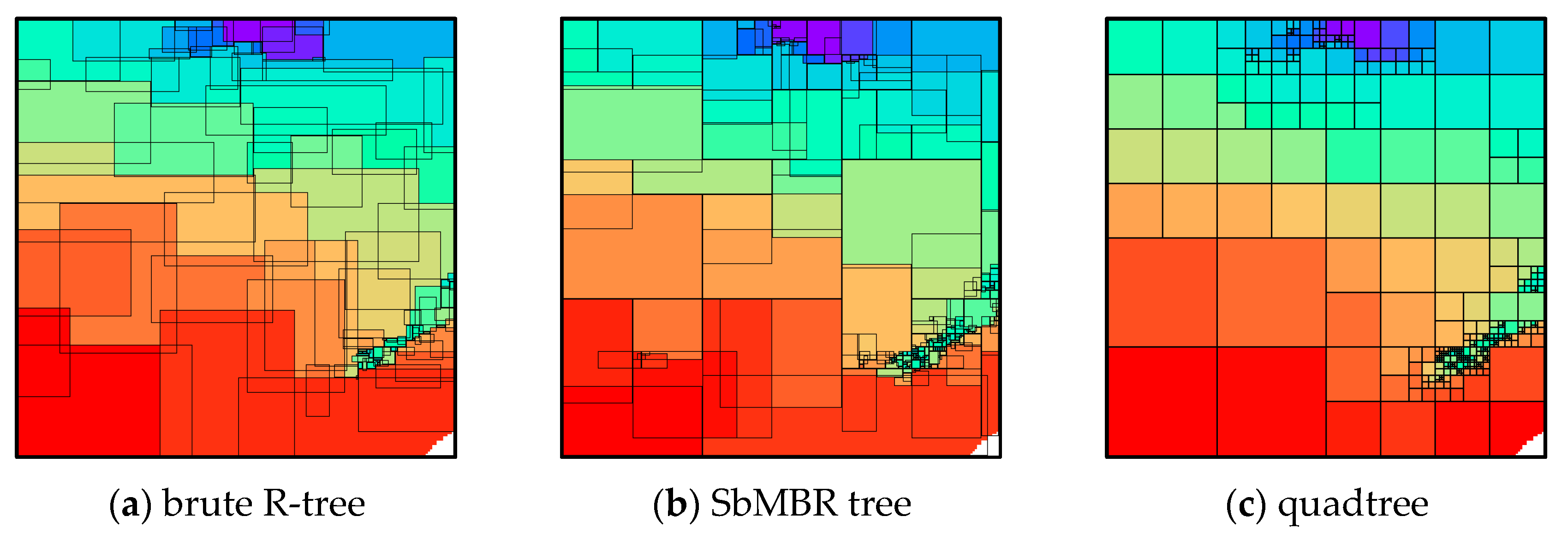
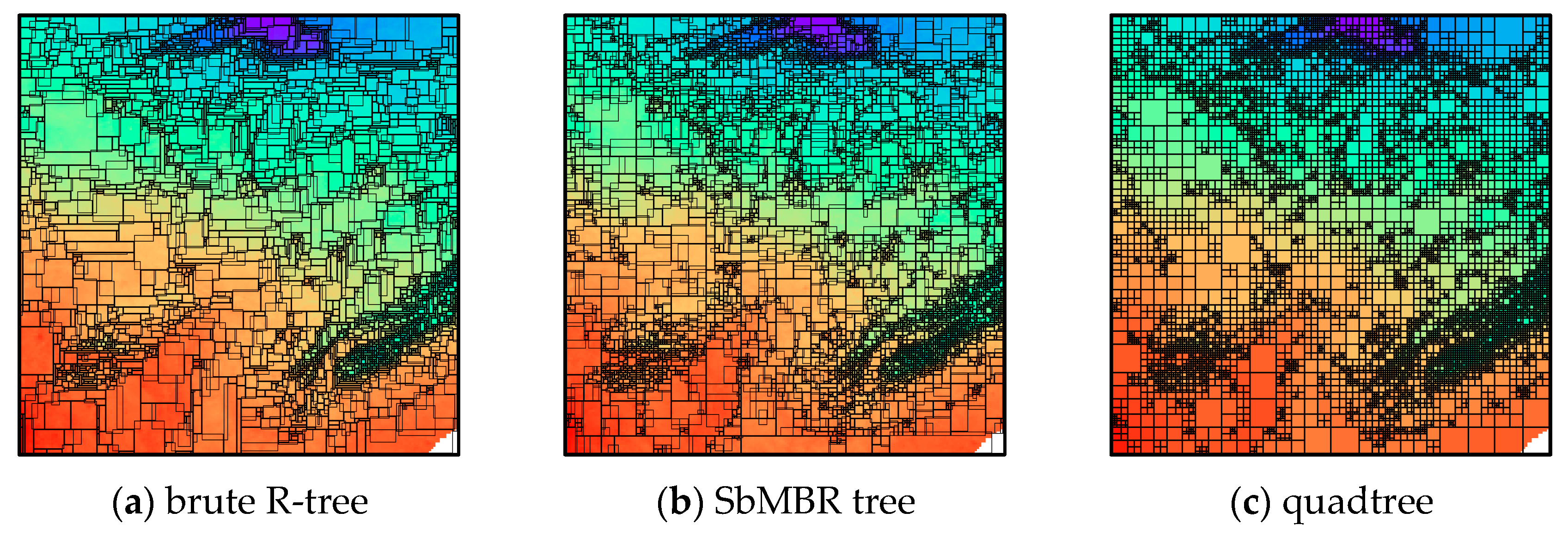
4.2. Visualization of Compression Results
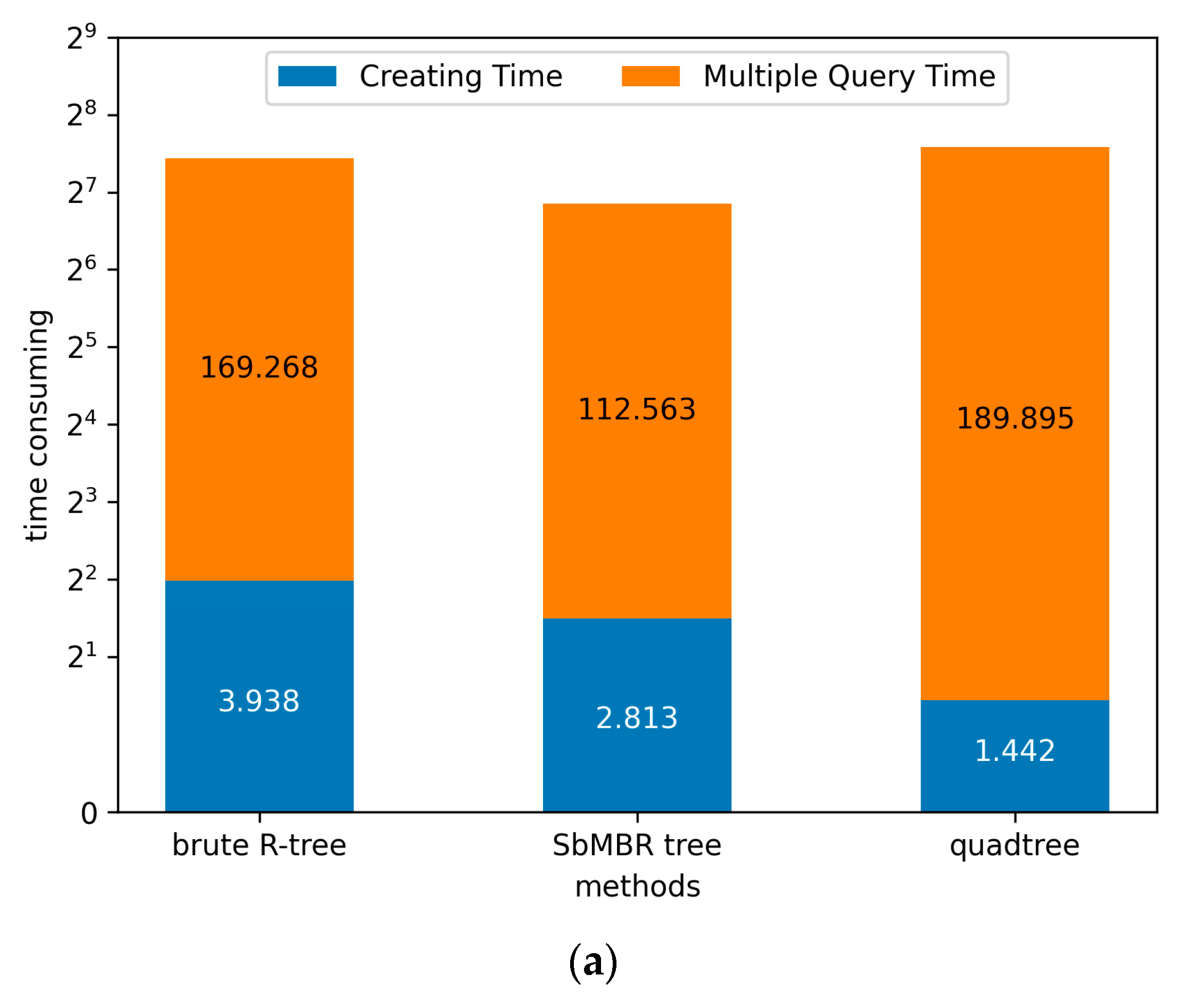
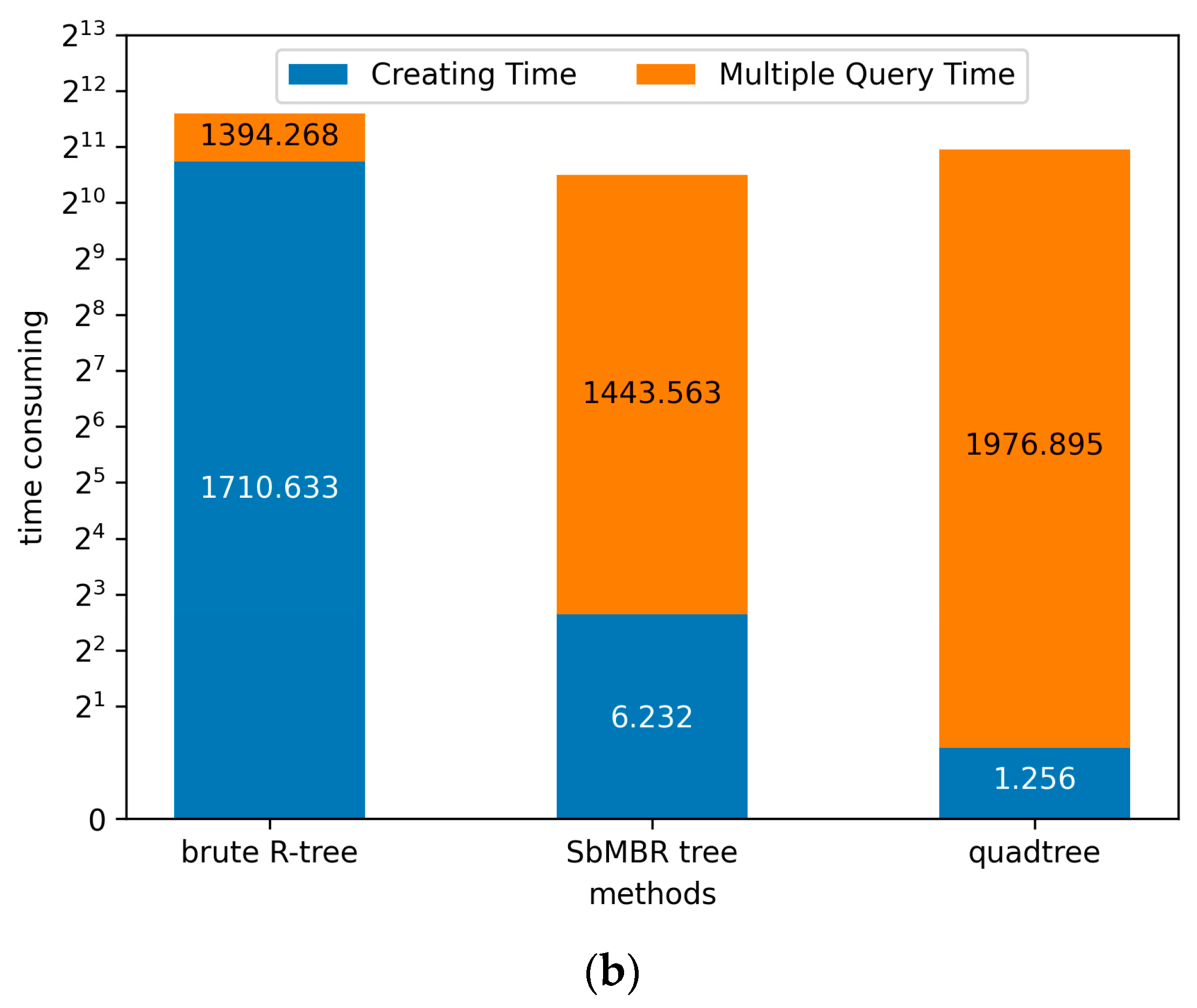
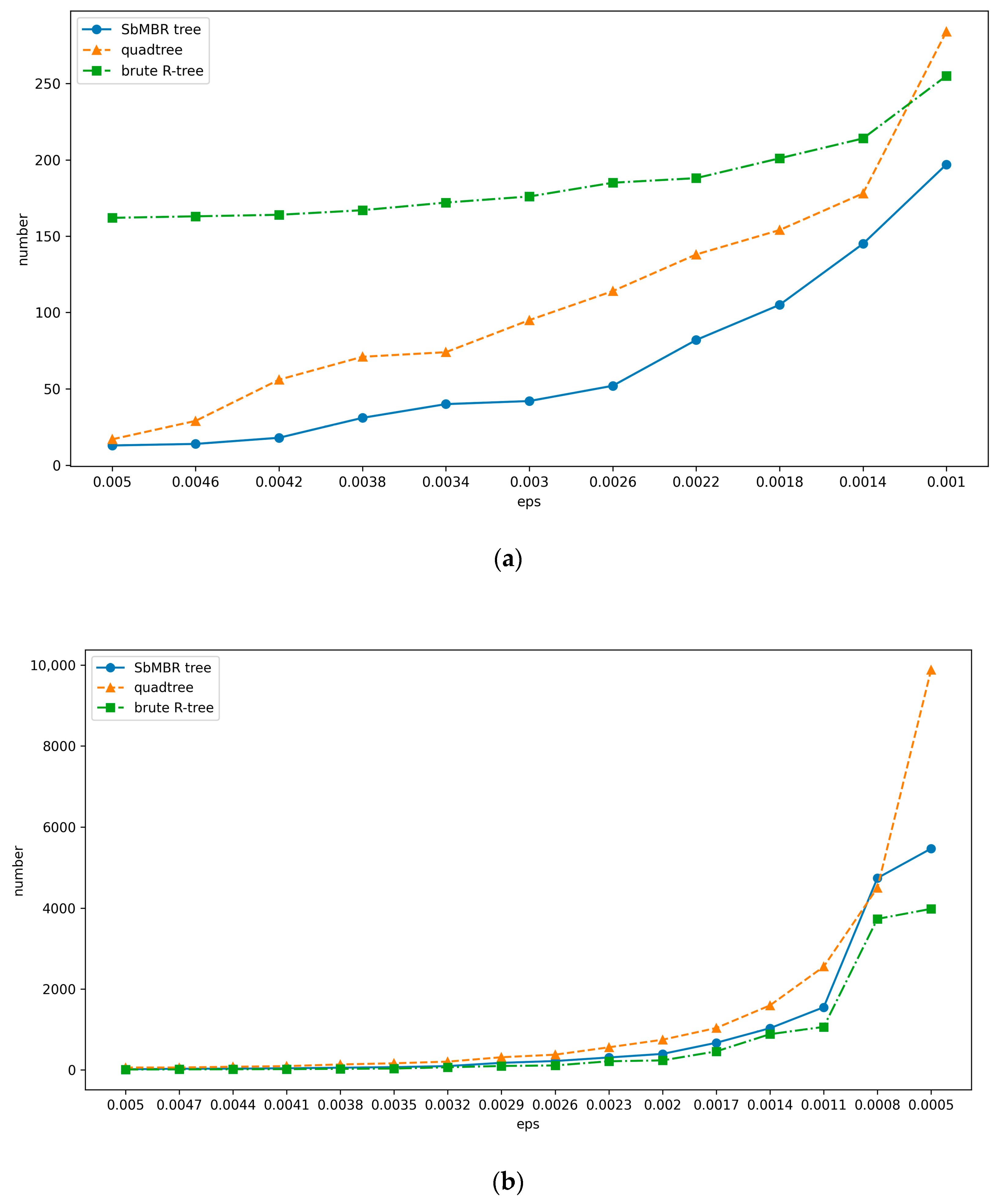
4.3. Comparison of Index Construction and Data Query Efficiency
4.4. Comparison of Compression Ratio and Nodes Number
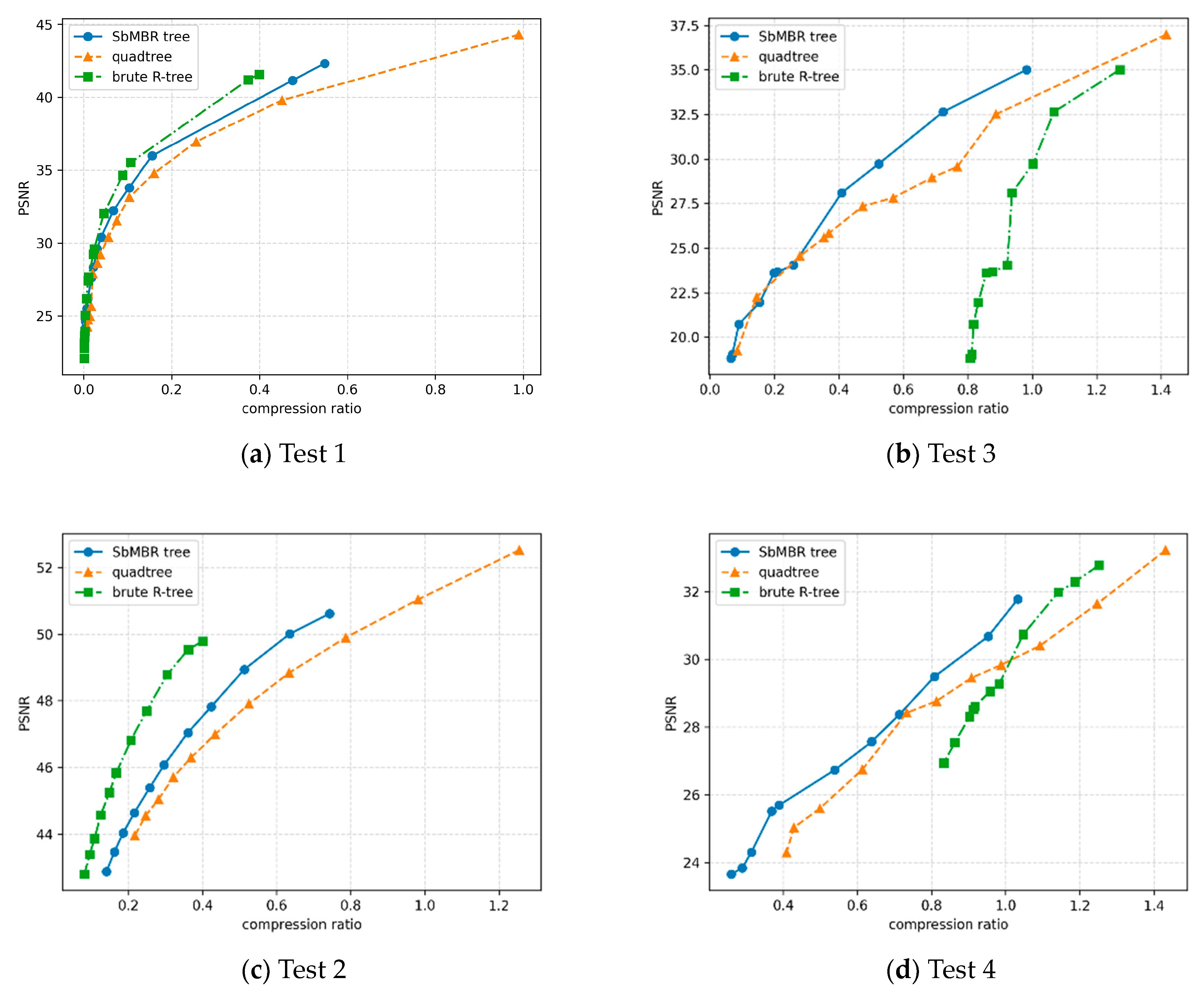
4.5. Comparison of Peak Signal-to-Noise Ratio (PSNR) under the Same Compression Ratio
4.6. Case Study of Using SbMBR Tree in Data Analysis
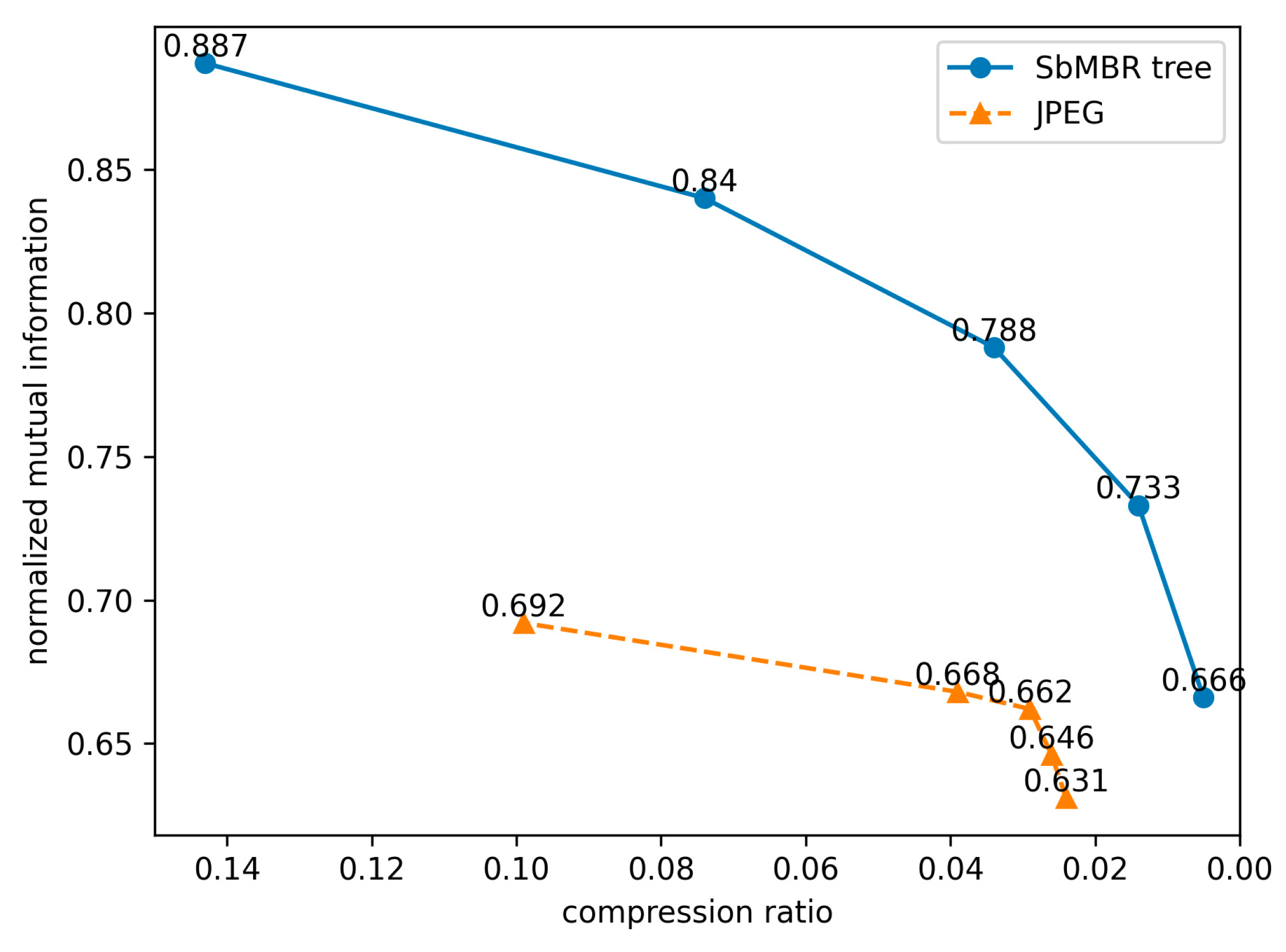
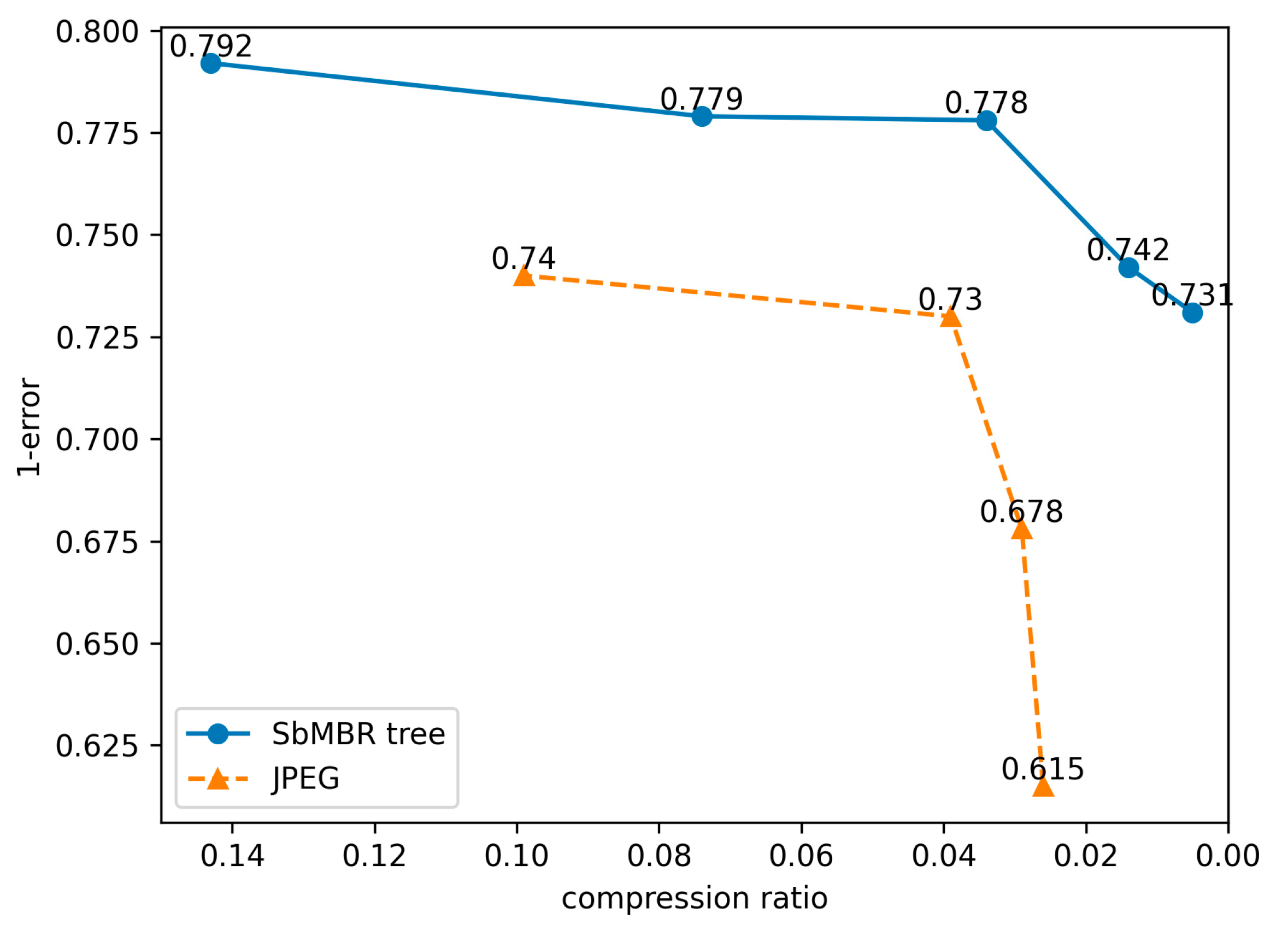
4.6.1. Results of Error Estimations
4.6.2. Validation of Error Estimation Method
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Foster, I.; Ainsworth, M.; Allen, B.; Bessac, J.; Cappello, F.; Choi, J.Y.; Constantinescu, E.; Davis, P.E.; Di, S.; Di, W.; et al. Computing Just What You Need: Online Data Analysis and Reduction at Extreme Scales. In Proceedings of the European Conference on Parallel Processing (Euro-Par 2017), Jaipur, India, 23 June 2017; pp. 3–19. [Google Scholar]
- Lee, J.-G.; Kang, M. Geospatial big data: Challenges and opportunities. Big Data Res. 2015, 2, 74–81. [Google Scholar] [CrossRef]
- Huo, H.; Long, P.; Vitter, J.S. Practical High-Order Entropy-Compressed Text Self-Indexing. IEEE Trans. Knowl. Data Eng. 2023, 35, 2943–2960. [Google Scholar] [CrossRef]
- Ghosh, S.; Eldawy, A. AID*: A Spatial Index for Visual Exploration of Geo-Spatial Data. IEEE Trans. Knowl. Data Eng. 2022, 34, 3569–3582. [Google Scholar] [CrossRef]
- Kim, M.; Liu, L.; Choi, W. Multi-GPU Efficient Indexing for Maximizing Parallelism of High Dimensional Range Query Services. IEEE Trans. Serv. Comput. 2022, 15, 2910–2924. [Google Scholar] [CrossRef]
- Andrés, F.-R.; Eduardo, R.-M.; Carlos, A.-C.; Fidel, L.-S. Image Retrieval System based on a Binary Auto-Encoder and a Convolutional Neural Network. IEEE Lat. Am. Trans. 2020, 18, 1925–1932. [Google Scholar] [CrossRef]
- Moon, A.; Kim, J.; Zhang, J.; Son, S.W. Lossy compression on IoT big data by exploiting spatiotemporal correlation. In Proceedings of the 2017 IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA USA, 12–14 September 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Jo, B.; Jung, S. Quadrant-based minimum bounding rectangle-tree indexing method for similarity queries over big spatial data in HBase. Sensors 2018, 18, 3032. [Google Scholar] [CrossRef] [PubMed]
- Error-controlled lossy compression optimized for high compression ratios of scientific datasets. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; IEEE: Piscataway, NJ, USA, 2018.
- Wang, Z.; Guan, R.; Pan, X.; Song, B.; Zhang, X.; Tian, Y. Efficient Spatiotemporal Big Data Indexing Algorithm with Loss Control. In Proceedings of the International Conference on Big Data and Security, Osaka, Japan, 17–20 December 2022; Springer Nature: Singapore, 2022; pp. 524–533. [Google Scholar]
- Ainsworth, M.; Tugluk, O.; Whitney, B.; Klasky, S. Multilevel techniques for compression and reduction of scientific data—The univariate case. Comput. Vis. Sci. 2018, 19, 65–76. [Google Scholar] [CrossRef]
- Lindstrom, P. Fixed-Rate Compressed Floating-Point Arrays. IEEE Trans. Vis. Comput. Graph. 2014, 20, 2674–2683. [Google Scholar] [CrossRef] [PubMed]
- Jain, A.K. Image data compression: A review. Proc. IEEE 1981, 69, 349–389. [Google Scholar] [CrossRef]
- Huffman, D.A. A method for the construction of minimum-redundancy codes. Proc. IRE 1952, 40, 1098–1101. [Google Scholar] [CrossRef]
- Al-Ani, M.S.; Awad, F.H. The JPEG image compression algorithm. Int. J. Adv. Eng. Technol. 2013, 6, 1055–1062. [Google Scholar]
- Li, J.; Takala, J.; Gabbouj, M.; Chen, H. A detection algorithm for zero-quantized DCT coefficients in JPEG. In Proceedings of the 2008 IEEE International Conference on Acoustics, Speech and Signal Processing, Las Vegas, NV, USA, 31 March–4 April 2008; IEEE: Piscataway, NJ, USA, 2008. [Google Scholar]
- Kumar, B.; Thakur, K.; Sinha, G.R. Performance evaluation of JPEG image compression using symbol reduction technique. In Proceedings of the First International Conference on Information Technology Convergence and Services (ITCS 2012), Bangalore, India, 3–4 January 2012. [Google Scholar]
- Ziv, J.; Lempel, A. A universal algorithm for sequential data compression. IEEE Trans. Inf. Theory 1977, 23, 337–343. [Google Scholar] [CrossRef]
- Oswal, S.; Singh, A.; Kumari, K. Deflate compression algorithm. Int. J. Eng. Res. Gen. Sci. 2016, 4, 430–436. [Google Scholar]
- Gailly, J.L. GNU Gzip. Available online: https://www.gnu.org/software/gzip/gzip.html (accessed on 2 July 2023).
- Oberhumer, M.F.X.J. LZO-a Real-Time Data Compression Library. 2008. Available online: http://www.oberhumer.com/opensource/lzo/ (accessed on 2 July 2023).
- Lee, K. LZ4 Compression and Improving Boot Time; LinuxCon: Tokyo, Japan, 2013. [Google Scholar]
- Mogul, J.C.; Douglis, F.; Feldmann, A.; Krishnamurthy, B. Potential benefits of delta encoding and data compression for HTTP. In Proceedings of the ACM SIGCOMM’97 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication, New York, NY, USA, 14–18 September 1997; pp. 181–194. [Google Scholar]
- Guttman, A. R-trees: A dynamic index structure for spatial searching. In Proceedings of the 1984 ACM SIGMOD International Conference on Management of Data, Boston, MA, USA, 18–21 June 1984. [Google Scholar]
- Beckmann, N.; Kriegel, H.P.; Schneider, R.; Seeger, B. The R*-tree: An efficient and robust access method for points and rectangles. In Proceedings of the 1990 ACM SIGMOD International Conference on Management of Data, Atlantic City, NJ, USA, 23–25 May 1990. [Google Scholar]
- Kamel, I.; Faloutsos, C. Parallel R-trees. ACM SIGMOD Rec. 1992, 21, 195–204. [Google Scholar] [CrossRef]
- Kamel, I.; Faloutsos, C. Hilbert R-tree: An improved R-tree using fractals. In Proceedings of the VLDB Conference, Santiago, Chile, 12–15 September 1994. [Google Scholar]
- White, D.A.; Jain, R. Similarity indexing with the SS-tree. In Proceedings of the Twelfth International Conference on Data Engineering, New Orleans, LO, USA, 26 February–1 March 1996; IEEE: Piscataway, NJ, USA, 1996. [Google Scholar]
- Kumar, A.A.; Makur, A. Lossy compression of encrypted image by compressive sensing technique. In Proceedings of the TENCON 2009-2009 IEEE Region 10 Conference, Singapore, 23–26 November 2009; IEEE: Piscataway, NJ, USA, 2009. [Google Scholar]
- Xia, J.; Huang, S.; Zhang, S.; Li, X.; Lyu, J.; Xiu, W.; Tu, W. DAPR-tree: A distributed spatial data indexing scheme with data access patterns to support Digital Earth initiatives. Int. J. Digit. Earth 2020, 13, 1656–1671. [Google Scholar] [CrossRef]
- Griffiths, J.G. An algorithm for displaying a class of space-filling curves. Softw.-Pract. Exp. 1986, 16, 403–411. [Google Scholar] [CrossRef]
- Moon, B.; Jagadish, H.V.; Faloutsos, C.; Saltz, J.H. Analysis of the clustering properties of the Hilbert space-filling curve. IEEE Trans. Knowl. Data Eng. 2001, 13, 124–141. [Google Scholar] [CrossRef]
- Baker, A.H.; Xu, H.; Dennis, J.M.; Levy, N.; Nychka, D.; Mickelson, S.A.; Edwards, J.; Vertenstein, M.; Wegener, A. A methodology for evaluating the impact of data compression on climate simulation data. In Proceedings of the 23rd International Symposium on High-Performance Parallel and Distributed Computing HPDC’14, Vancouver, BC, Canada, 23–27 June 2014; pp. 203–214. [Google Scholar]
- Fick, S.E.; Hijmans, R.J. WorldClim 2: New 1km spatial resolution climate surfaces for global land areas. Int. J. Climatol. 2017, 37, 4302–4315. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Adv. Neural Inf. Process. Syst. 2015, 28, 802–810. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name of the Data | Types of the Data | Location of the Data | Density of the Data | Scale of the Data |
|---|---|---|---|---|
| Test 1 | Average temperature in July | 31°40′ N–48°20′ N, 96°40′ W–80°00′ W | Dense | 400 × 400 |
| Test 2 | Average temperature in July | 30°00′ S–6°40′ N, 180°00′–138°20′ W | Sparse | 880 × 1000 |
| Test 3 | Solar radiation in April | 33°45′ N–50°25′ N, 100°50′ W–75°50′ W | Dense | 600 × 400 |
| Test 4 | Solar radiation in April | 30°00′ S–6°40′ N, 180°00′–138°20′ W | Sparse | 880 × 1000 |
| Method | Param Name | Explanation | Value Range or Requirement |
|---|---|---|---|
| SbMBR tree | eps array | eps of different layers when building the SbMBR tree | , incremental |
| query eps | eps of query area | ||
| query area | a rectangle area needed to query, containing the coordinate of the bottom left corner and top right corner | Coordinates of two real number points | |
| brute R-tree | eps array | eps of different layers when building the tree | , incremental |
| query eps | eps of query area | ||
| query area | a rectangle area needed to query, containing the coordinate of the bottom left corner and top right corner | Coordinates of two real number points | |
| quadtree | query eps | eps of query area | |
| query area | a rectangle area needed to query, containing the coordinate of the bottom left corner and top right corner | Coordinates of two real number points | |
| JPEG | ratio | compression ratio |
| Method | Relative Time of Creating Tree | Relative Time of Multiple Querying | Relative Total Time |
|---|---|---|---|
| quadtree | 100.0% | 100.0% | 100.0% |
| SbMBR tree | 195.1% | 59.2% | 60.2% |
| brute R-tree | 273.1% | 89.1% | 90.5% |
| Method | Relative Time of Creating Tree | Relative Time of Multiple Querying | Relative Total Time |
|---|---|---|---|
| quadtree | 100.0% | 100.0% | 100.0% |
| SbMBR tree | 496.1% | 73.0% | 73.2% |
| brute R-tree | 136,196.9% | 70.5% | 156.9% |
| eps | Method | Volume Reduction Ratio |
|---|---|---|
| 0.005 | SbMBR tree | 0.000236 |
| brute R-tree | 0.002945 | |
| quadtree | 0.000309 | |
| 0.0046 | SbMBR tree | 0.000254 |
| brute R-tree | 0.002963 | |
| quadtree | 0.000527 | |
| 0.0042 | SbMBR tree | 0.000327 |
| brute R-tree | 0.002981 | |
| quadtree | 0.001018 | |
| 0.0038 | SbMBR tree | 0.000563 |
| brute R-tree | 0.003036 | |
| quadtree | 0.001290 | |
| 0.0034 | SbMBR tree | 0.000727 |
| brute R-tree | 0.003127 | |
| quadtree | 0.001345 | |
| 0.003 | SbMBR tree | 0.000763 |
| brute R-tree | 0.003200 | |
| quadtree | 0.001727 | |
| 0.0026 | SbMBR tree | 0.000945 |
| brute R-tree | 0.003363 | |
| quadtree | 0.002072 | |
| 0.0022 | SbMBR tree | 0.001490 |
| brute R-tree | 0.003418 | |
| quadtree | 0.002509 | |
| 0.0018 | SbMBR tree | 0.001909 |
| brute R-tree | 0.003654 | |
| quadtree | 0.002800 | |
| 0.0014 | SbMBR tree | 0.002636 |
| brute R-tree | 0.003890 | |
| quadtree | 0.003236 | |
| 0.001 | SbMBR tree | 0.003581 |
| brute R-tree | 0.004636 | |
| quadtree | 0.005163 |
| eps | Method | Volume Reduction Ratio |
|---|---|---|
| 0.005 | SbMBR tree | 0.0018 |
| brute R-tree | 0.0011 | |
| quadtree | 0.0060 | |
| 0.0047 | SbMBR tree | 0.0030 |
| brute R-tree | 0.0015 | |
| quadtree | 0.0060 | |
| 0.0044 | SbMBR tree | 0.0032 |
| brute R-tree | 0.0017 | |
| quadtree | 0.0080 | |
| 0.0041 | SbMBR tree | 0.0042 |
| brute R-tree | 0.0021 | |
| quadtree | 0.0100 | |
| 0.0038 | SbMBR tree | 0.0056 |
| brute R-tree | 0.0028 | |
| quadtree | 0.0140 | |
| 0.0035 | SbMBR tree | 0.0071 |
| brute R-tree | 0.0035 | |
| quadtree | 0.0170 | |
| 0.0032 | SbMBR tree | 0.0096 |
| brute R-tree | 0.0067 | |
| quadtree | 0.0210 | |
| 0.0029 | SbMBR tree | 0.0176 |
| brute R-tree | 0.0099 | |
| quadtree | 0.0320 | |
| 0.0026 | SbMBR tree | 0.0221 |
| brute R-tree | 0.0112 | |
| quadtree | 0.0380 | |
| 0.0023 | SbMBR tree | 0.0309 |
| brute R-tree | 0.0215 | |
| quadtree | 0.0560 | |
| 0.002 | SbMBR tree | 0.0397 |
| brute R-tree | 0.0237 | |
| quadtree | 0.0750 | |
| 0.0017 | SbMBR tree | 0.0672 |
| brute R-tree | 0.0459 | |
| quadtree | 0.1040 | |
| 0.0014 | SbMBR tree | 0.1032 |
| brute R-tree | 0.0885 | |
| quadtree | 0.1600 | |
| 0.0011 | SbMBR tree | 0.1550 |
| brute R-tree | 0.1064 | |
| quadtree | 0.2550 | |
| 0.0008 | SbMBR tree | 0.4742 |
| brute R-tree | 0.3733 | |
| quadtree | 0.4500 | |
| 0.0005 | SbMBR tree | 0.5471 |
| brute R-tree | 0.3982 | |
| quadtree | 0.9880 |
| Param Name | Value |
|---|---|
| Convolution kernel | 3 × 3 |
| Number of Convolutional layers | 4 |
| Number of nodes per layer | {1,16,32,64} |
| Optimizer | AdamW |
| Loss Function | L1Loss |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guan, R.; Wang, Z.; Pan, X.; Zhu, R.; Song, B.; Zhang, X. SbMBR Tree—A Spatiotemporal Data Indexing and Compression Algorithm for Data Analysis and Mining. Appl. Sci. 2023, 13, 10562. https://doi.org/10.3390/app131910562
Guan R, Wang Z, Pan X, Zhu R, Song B, Zhang X. SbMBR Tree—A Spatiotemporal Data Indexing and Compression Algorithm for Data Analysis and Mining. Applied Sciences. 2023; 13(19):10562. https://doi.org/10.3390/app131910562
Chicago/Turabian StyleGuan, Runda, Ziyu Wang, Xiaokang Pan, Rongjie Zhu, Biao Song, and Xinchang Zhang. 2023. "SbMBR Tree—A Spatiotemporal Data Indexing and Compression Algorithm for Data Analysis and Mining" Applied Sciences 13, no. 19: 10562. https://doi.org/10.3390/app131910562