
Channel Pruning-Based YOLOv7 Deep Learning Algorithm for Identifying Trolley Codes
Abstract
:1. Introduction
2. Development of the Algorithm
2.1. Dataset Creation
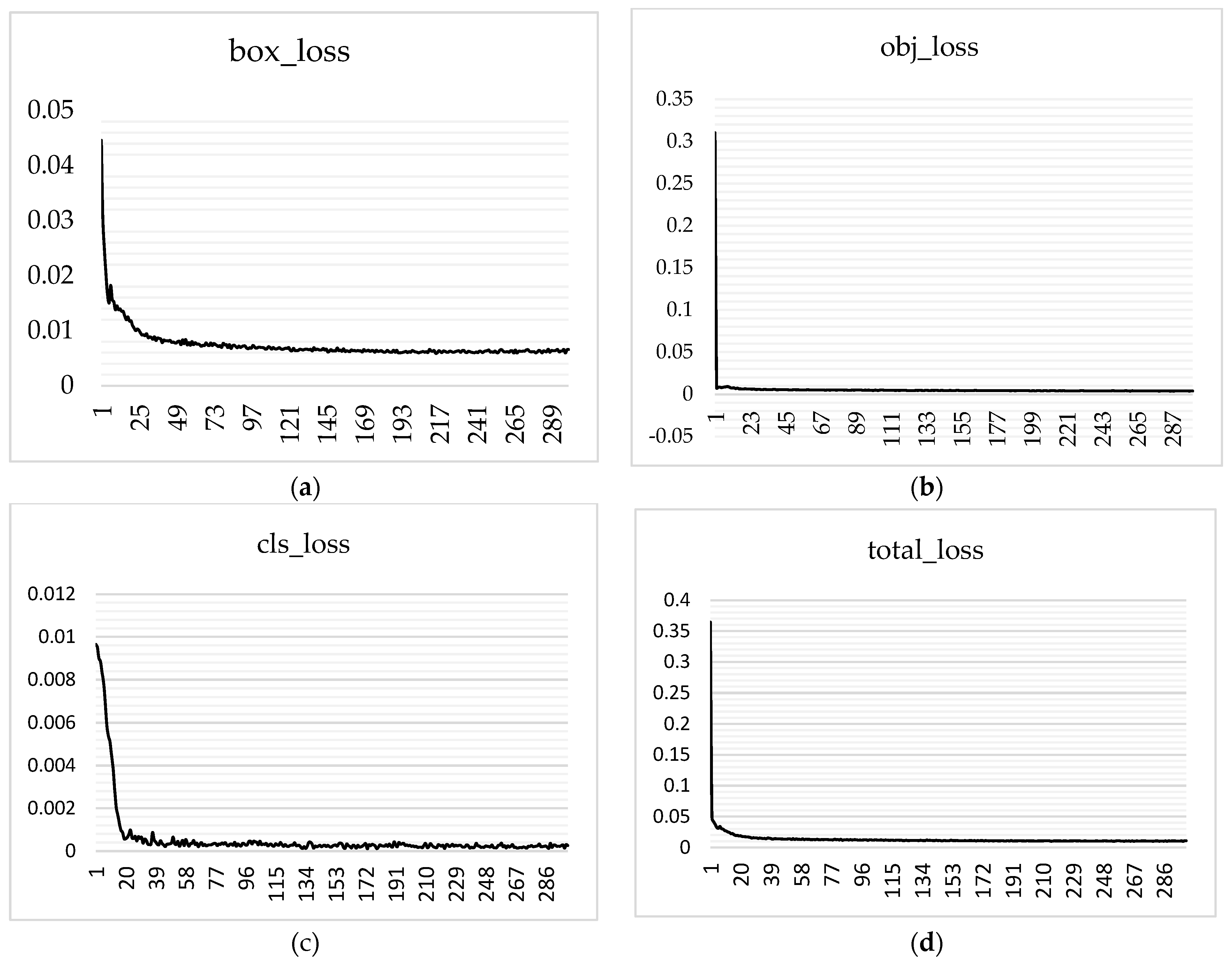
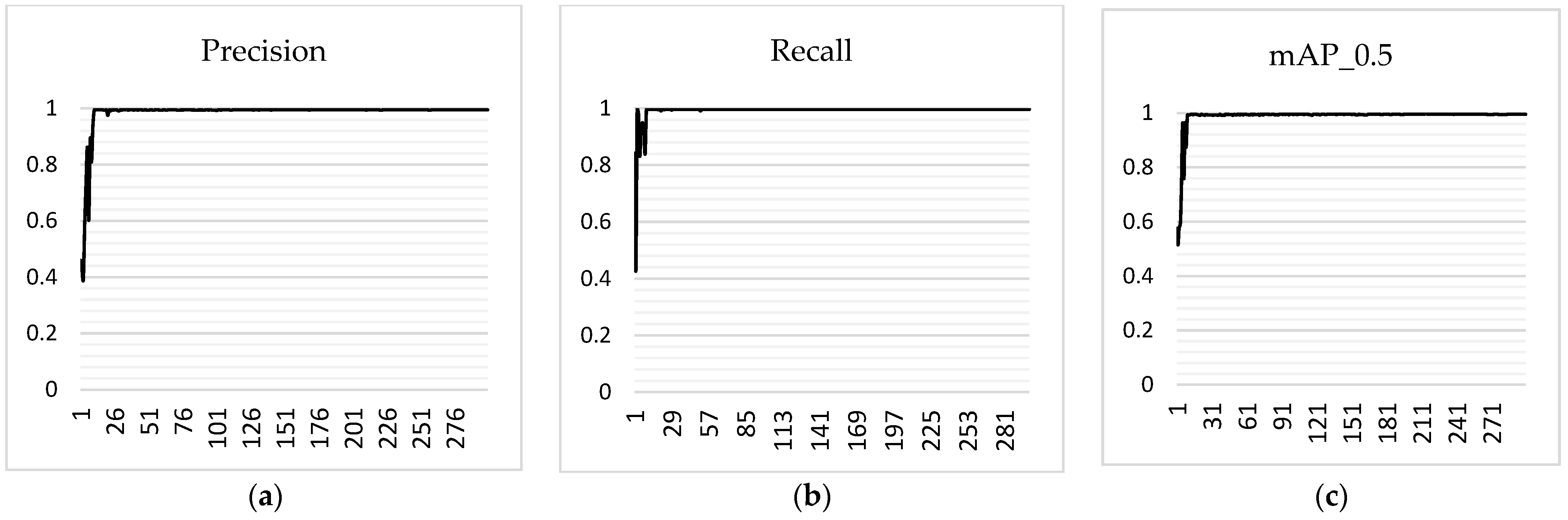
2.2. Training Environment and Evaluation Indicators
2.3. YOLOv7 Algorithm
2.3.1. Technical Details
2.3.2. Identifying Trolley Codes Based on YOLOv7
2.3.3. Pruning YOLOv7 Model
- In order to incorporate structural sparsity into the YOLOv7 model, the L1 regularization technique was utilized. Specifically, L1 regularization constraints were applied to the coefficients of the Batch Normalization (BN) layer within the YOLOv7 model. The objective of this phase was to fine-tune the model’s parameters by imposing L1 regularization.
- Following the initial training phase, we proceeded to implement channel pruning. This crucial procedure entailed the elimination of branches or channels within the YOLOv7 model, in accordance with a predetermined pruning ratio. The pruning ratio plays a crucial role in determining the proportion of channels that will be preserved, leading to a more streamlined and storage-efficient model. By selectively removing channels, we were able to substantially decrease the storage demands of the model, rendering it more manageable and appropriate for environments with limited resources. This particular step played a crucial role in optimizing the size of the model while simultaneously preserving its effectiveness.
- Following the process of channel pruning, our foremost objective was to mitigate any potential decrease in accuracy. We conducted a meticulous fine-tuning process to carefully adjust and retrain the pruned model. Throughout the fine-tuning phase, we diligently balanced the parameters of the model to guarantee that, while achieving a reduction in size, we did not compromise significantly on accuracy. This step was undertaken with the objective of optimizing the pruned model, with a focus on achieving both compactness and performance, as both factors are of utmost importance.
3. Results and Analysis
3.1. Comparison with Other Target Detection Algorithms
3.2. Comparison with Previous Studies
3.3. Discussion
3.3.1. Influence of Distance between Industrial Camera and Workpiece
3.3.2. Effect of Light Intensity on Detection
4. Conclusions
- The proposed method not only demonstrates a high level of accuracy, but also enables the efficient detection of trolley codes. By implementing the channel-pruning-based YOLOv7 deep learning algorithm, notable reductions in the number of parameters, model size, and forward inference time are achieved when compared to the unmodified model. Specifically, there is a decrease of 32.92% in the number of parameters, a reduction of 34.1% in model size, and a decrease of 48.8% in forward inference time. These enhancements have been implemented while ensuring accuracy is not compromised. Experiments have been conducted to demonstrate the method’s resistance to variations in factors such as the target camera distance and ambient lighting. These experiments aim to ensure consistent results under typical operating conditions. This demonstration of robustness further validates the practical viability of the proposed method.
- The method presented in this study generates a simplified model that demonstrates the ability to accurately identify tram codes in typical operational environments. The experimental results exhibit a remarkable average precision (mAP) value of 99.24%, surpassing YOLOv5x, YOLOv4, YOLOv5m, YOLOv5s, and YOLOv5n by 0.86%, 1.72%, 1.03%, 1.18%, and 1.51%, respectively. In relation to the time taken for forward inference, the enhanced model achieved a duration of 8.1ms, representing a reduction of 7.6 ms compared to YOLOv7. The objective of this study was to offer valuable technical insights into the implementation of tram code recognition models in compact terminals and the potential integration of automatic target detection models in engineering applications. The aforementioned contribution serves as a fundamental basis for future investigations within this particular field. In subsequent research, it is recommended to explore the development of algorithms aimed at enhancing feature extraction. This can be achieved through the implementation of attention mechanisms or other multi-scale fusion algorithms. By improving the feature extraction capabilities of the model, the performance of trolley coding detection can be significantly enhanced.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Papageorgiou, C.P.; Oren, M.; Poggio, T. A general framework for object detection. In Proceedings of the Sixth International Conference on Computer Vision 2002, Bombay, India, 7 January 1998; pp. 555–562. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; pp. 886–893. [Google Scholar] [CrossRef]
- Chen, A.; Xie, Y.; Wang, Y.; Li, L. Knowledge Graph-Based Image Recognition Transfer Learning Method for On-Orbit Service Manipulation. Space Sci. Technol. 2021, 2021, 165–172. [Google Scholar] [CrossRef]
- Lv, W. Research on Black and White Image Coloring Algorithm Based on Deep Neural Network. Master’s Thesis, Jiangxi University of Technology, Nanchang, China, 2019. Available online: https://kns.cnki.net/KCMS/detail/detail.aspx?dbname=CMFD202001&filename=1019188350.nh (accessed on 16 June 2023).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Wang, W.; Fu, Y.; Dong, F.; Li, F. Infrared Ship Target Detection Method Based on Deep Convolution Neural Network. Acta Opt. Sin. 2018, 38, 0712006. Available online: https://www.opticsjournal.net/Articles/OJae7dbefc1e5afa10/Abstract (accessed on 22 May 2023). [CrossRef]
- Kumar, D.; Kukreja, V. MRISVM: A Object Detection and Feature Vector Machine Based Network for Brown Mite Variation in Wheat Plant. In Proceedings of the 2022 International Conference on Data Analytics for Business and Industry (ICDABI), Sakhir, Bahrain, 25–26 October 2022; pp. 707–711. [Google Scholar] [CrossRef]
- Zhang, G.; He, J.; Gao, W. Research on face recognition based on deep learning. Wirel. Connect. Technol. 2019, 16, 133–135. Available online: https://www.cnki.com.cn/Article/CJFDTOTAL-WXHK201919061.htm (accessed on 28 July 2023).
- Kumar, D.; Kukreja, V. Early Recognition of Wheat Powdery Mildew Disease Based on Mask RCNN. In Proceedings of the 2022 International Conference on Data Analytics for Business and Industry (ICDABI), Sakhir, Bahrain, 25–26 October 2022; pp. 542–546. [Google Scholar] [CrossRef]
- Sanguansub, N.; Kamolrungwarakul, P.; Poopair, S.; Techaphonprasit, K.; Siriborvornratanakul, T. Song lyrics recommendation for social media captions using image captioning, image emotion, and caption-lyric matching via universal sentence embedding. Soc. Netw. Anal. Min. 2023, 13, 95. [Google Scholar] [CrossRef]
- Ji, Z.; Wu, Y.; Zeng, X.; An, Y.; Zhao, L.; Wang, Z.; Ganchev, I. Lung Nodule Detection in Medical Images Based on Improved YOLOv5s. IEEE Access 2023, 11, 76371–76387. [Google Scholar] [CrossRef]
- Hu, H.; Zhu, Z. Sim-YOLOv5s: A method for detecting defects on the end face of lithium battery steel shells. Adv. Eng. Inform. 2023, 55, 101824. [Google Scholar] [CrossRef]
- Hu, H.; Peng, R.; Tai, Y.W.; Tang, C.K. Network Trimming:A Data-Driven Neuron Pruning Approach towards Efficient Deep Architectures. arXiv 2016, arXiv:1607.03250. [Google Scholar] [CrossRef]
- Wang, Y.; Li, Y.; Duan, Y.; Wu, H. Infrared image recognition of substation equipment based on lightweight backbone network and attention structure. Power Grid Technol. 2023, 1–12. [Google Scholar] [CrossRef]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. arXiv 2018, arXiv:1809.02165. [Google Scholar] [CrossRef]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.-T.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Rathore, D.; Divyanth, L.G.; Reddy, K.L.S.; Chawla, Y.; Buragohain, M.; Soni, P.; Machavaram, R.; Hussain, S.Z.; Ray, H.; Ghosh, A. A Two-Stage Deep-Learning Model for Detection and Occlusion-Based Classification of Kashmiri Orchard Apples for Robotic Harvesting. J. Biosyst. Eng. 2023, 48, 242–256. [Google Scholar] [CrossRef]
- Chen, J.; Liu, H.; Zhang, Y.; Zhang, D.; Ouyang, H.; Chen, X. A Multiscale Lightweight and Efficient Model Based on YOLOv7: Applied to Citrus Orchard. Plants 2022, 11, 3260. [Google Scholar] [CrossRef] [PubMed]
- Puri, P.; Kumar, D.; Kukreja, V. Enhanced Detection of Wheat Mosaic Virus Using YOLOV5 Model with Adaptive Thresholding. In Proceedings of the 2023 4th International Conference for Emerging Technology (INCET), Belgaum, India, 26–28 May 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Li, Z.; Yan, J.; Zhou, J.; Fan, X.; Tang, J. An efficient SMD-PCBA detection based on YOLOv7 network model. Eng. Appl. Artif. Intell. 2023, 124, 106492. [Google Scholar] [CrossRef]
- Singhi, V.; Kumar, D.; Kukreja, V. Integrated YOLOv4 Deep Learning Pretrained Model for Accurate Estimation of Wheat Rust Disease Severity. In Proceedings of the 2023 2nd International Conference on Applied Artificial Intelligence and Computing (ICAAIC), Salem, India, 4–6 May 2023; pp. 489–494. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar] [CrossRef]
- Prasetyo, E.; Suciati, N.; Fatichah, C. Yolov4-tiny and Spatial Pyramid Pooling for Detecting Head and Tail of Fish. In Proceedings of the 2021 International Conference on Artificial Intelligence and Computer Science Technology (ICAICST), Yogyakarta, Indonesia, 29–30 June 2021; pp. 157–161. [Google Scholar] [CrossRef]
- Cai, Y.; Li, H.; Yuan, G.; Niu, W.; Li, Y.; Tang, X.; Ren, B.; Wang, Y. YOLObile: Real-Time Object Detection on Mobile Devices via Compression-Compilation Co-Design. Proc. Conf. AAAI Artif. Intell. 2021, 35, 955–963. [Google Scholar] [CrossRef]
- Luo, J. Research on Model Pruning Algorithms for Deep Convolutional Neural Networks. Ph.D. Thesis, Nanjing University, Nanjing, China, 2020. [Google Scholar] [CrossRef]
- Ju, M.; Luo, H.; Wang, Z.; He, M.; Chang, Z.; Hui, B. Improved YOLO V3 algorithm and its application in small target detection. J. Opt. 2019, 39, 253–260. Available online: https://kns.cnki.net/kcms/detail/detail.aspx?FileName=GXXB201907028&DbName=CJFQ2019 (accessed on 23 July 2023).
- Feng, S.Y.; Mei, W.; Hu, D.S. Airborne target detection based on impr-oved Faster R-CNN. J. Opt. 2018, 38, 250–258. Available online: https://kns.cnki.net/kcms/detail/detail.aspx?FileName=GXXB201806034&DbName=CJFQ2018 (accessed on 12 July 2023).
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Proc. Adv. Neural Inf. Process. Syst. 2015, 91, 99. [Google Scholar] [CrossRef]
- Zhou, K.; Wang, W.; Hu, T.; Deng, K. Time Series Forecasting and Classification Models Based on Recurrent with Attention Mechanism and Generative Adversarial Networks. Sensors 2020, 20, 7211. [Google Scholar] [CrossRef] [PubMed]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample Model Coding | Number of Samples |
|---|---|
| 01111N | 423 |
| 01111L | 426 |
| 01111S | 302 |
| 01111 | 408 |
| Parameter | Value |
|---|---|
| Image size | 640 × 640 |
| Learning rate | 0.001 |
| Batch | 32 |
| Number of categories | 2 |
| Number of iterations | 300 |
| Step | Phase Parameter | Value |
|---|---|---|
| Sparse training | Sparse training batch size | 32 |
| Learning rate | 0.001 | |
| Number of iterations | 300 | |
| Channel pruning | Access pruning; pruning rate | 0.8 |
| Fine-tuning | Model fine-tuning batch size | 32 |
| Number of iterations | 100 |
| Parameter | Original Network | Pruned Network | Fine-Tuned Network |
|---|---|---|---|
| Number of parameters | 37,201,950 | 25,289,954 | 24,813,245 |
| mAP (%) | 99.58 | 99.15 | 99.24 |
| Model size (MB) | 73.0 | 48.6 | 47.63 |
| Forward extrapolation time (ms) | 15.7 | 9.75 | 8.1 |
| Algorithm | Number of Parameters | Model Size (MB) | mAP (%) | Forward Propagation Time (ms) |
|---|---|---|---|---|
| YOLOv5x | 88,922,205 | 166 | 98.38 | 114 |
| YOLOv4 | 62,941,672 | 237.83 | 97.52 | 163 |
| YOLOv5m | 21,172,173 | 40.8 | 98.21 | 33.9 |
| YOLOv5s | 7,025,023 | 14.1 | 98.06 | 18.8 |
| YOLOv5n | 1,867,405 | 3.87 | 97.73 | 8.6 |
| Ours | 24,813,245 | 47.63 | 99.24 | 8.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Zhang, R.; Shu, X.; Yu, L.; Xu, X. Channel Pruning-Based YOLOv7 Deep Learning Algorithm for Identifying Trolley Codes. Appl. Sci. 2023, 13, 10202. https://doi.org/10.3390/app131810202
Zhang J, Zhang R, Shu X, Yu L, Xu X. Channel Pruning-Based YOLOv7 Deep Learning Algorithm for Identifying Trolley Codes. Applied Sciences. 2023; 13(18):10202. https://doi.org/10.3390/app131810202
Chicago/Turabian StyleZhang, Jun, Rongxi Zhang, Xinming Shu, Lulu Yu, and Xuanning Xu. 2023. "Channel Pruning-Based YOLOv7 Deep Learning Algorithm for Identifying Trolley Codes" Applied Sciences 13, no. 18: 10202. https://doi.org/10.3390/app131810202