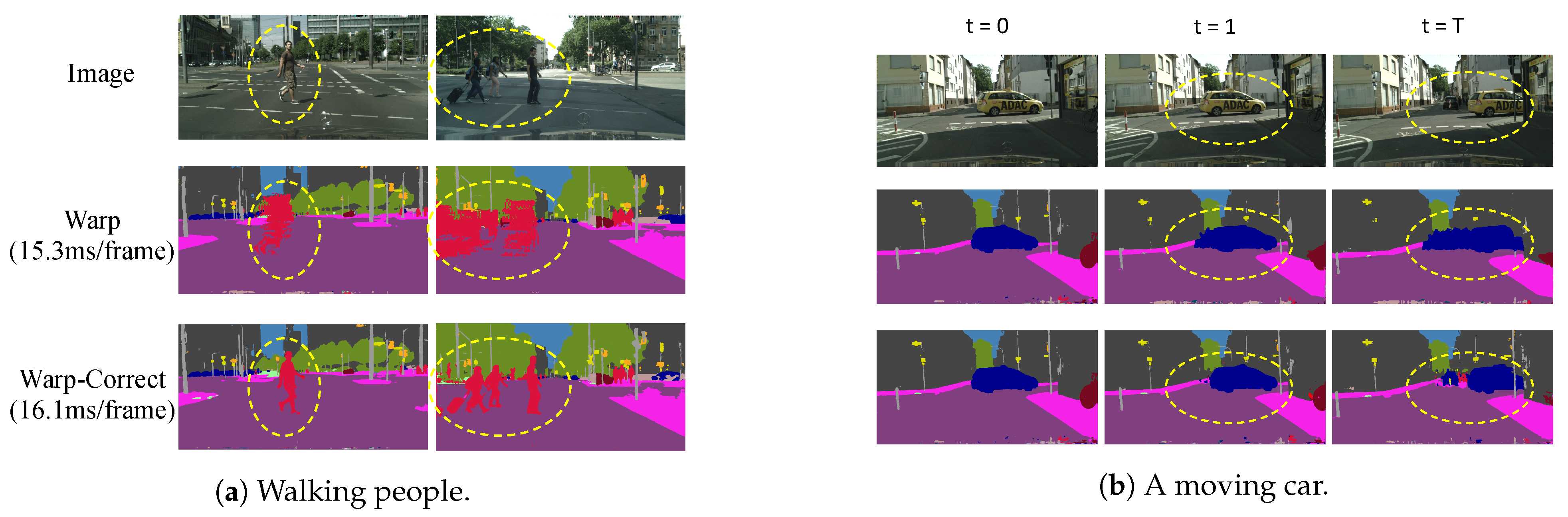
Figure 1.
Comparison between warping only and warping with correction. (a) The walking people’s limbs can be occluded by their own bodies a few frames prior but appear later, thus becoming severely deformed in later warped frames. (b) A moving car occludes distant objects that cannot be warped from previous frames. By adding a correction stage, errors can be significantly alleviated.
Figure 1.
Comparison between warping only and warping with correction. (a) The walking people’s limbs can be occluded by their own bodies a few frames prior but appear later, thus becoming severely deformed in later warped frames. (b) A moving car occludes distant objects that cannot be warped from previous frames. By adding a correction stage, errors can be significantly alleviated.
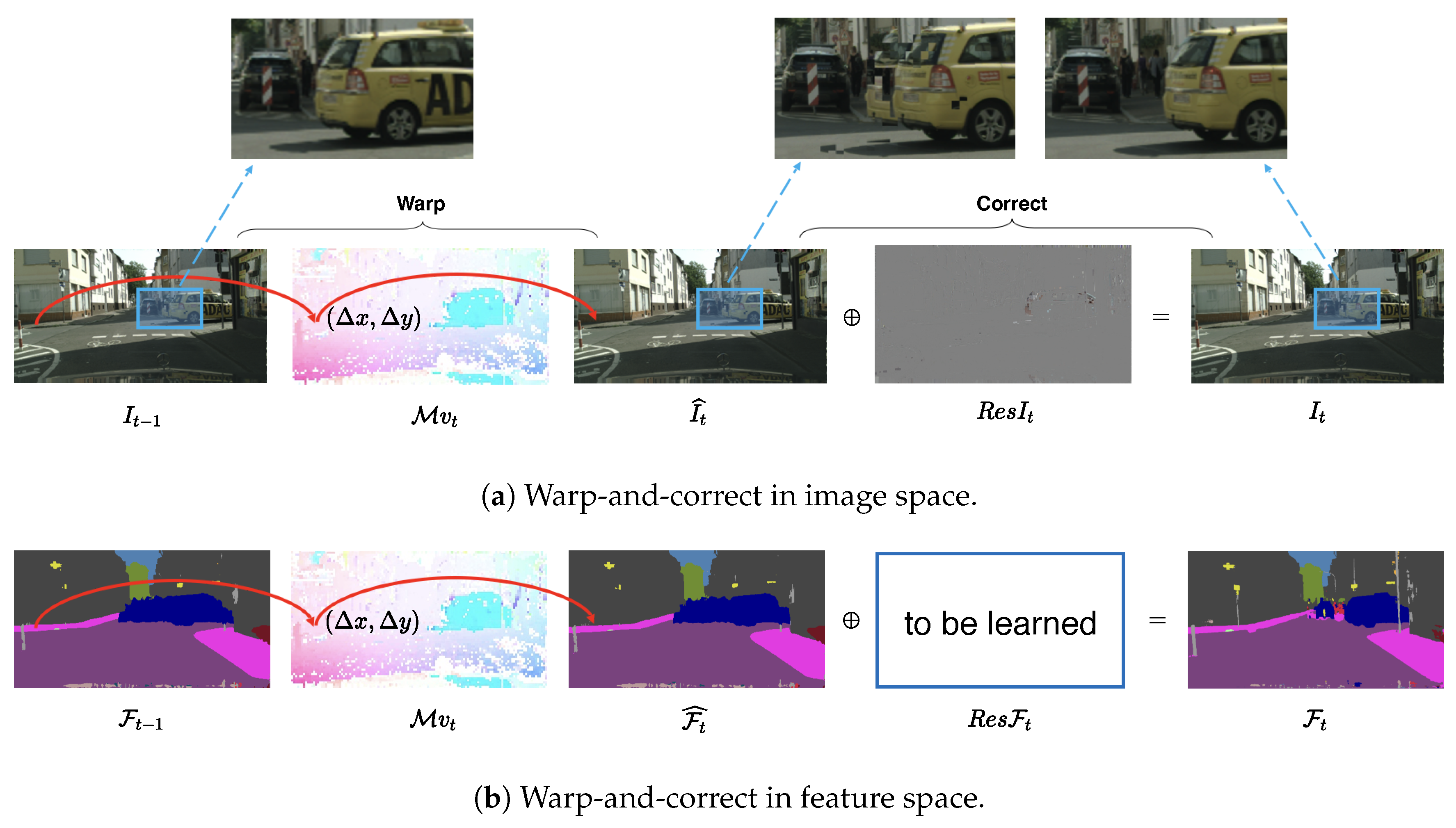
Figure 2.
Illustration of “warp-and-correct”. (a) Video codecs warp the preceding frame to the current one and then add the compressed-domain residuals. (b) We propose to learn the residuals in feature space to rectify the warped features.
Figure 2.
Illustration of “warp-and-correct”. (a) Video codecs warp the preceding frame to the current one and then add the compressed-domain residuals. (b) We propose to learn the residuals in feature space to rectify the warped features.
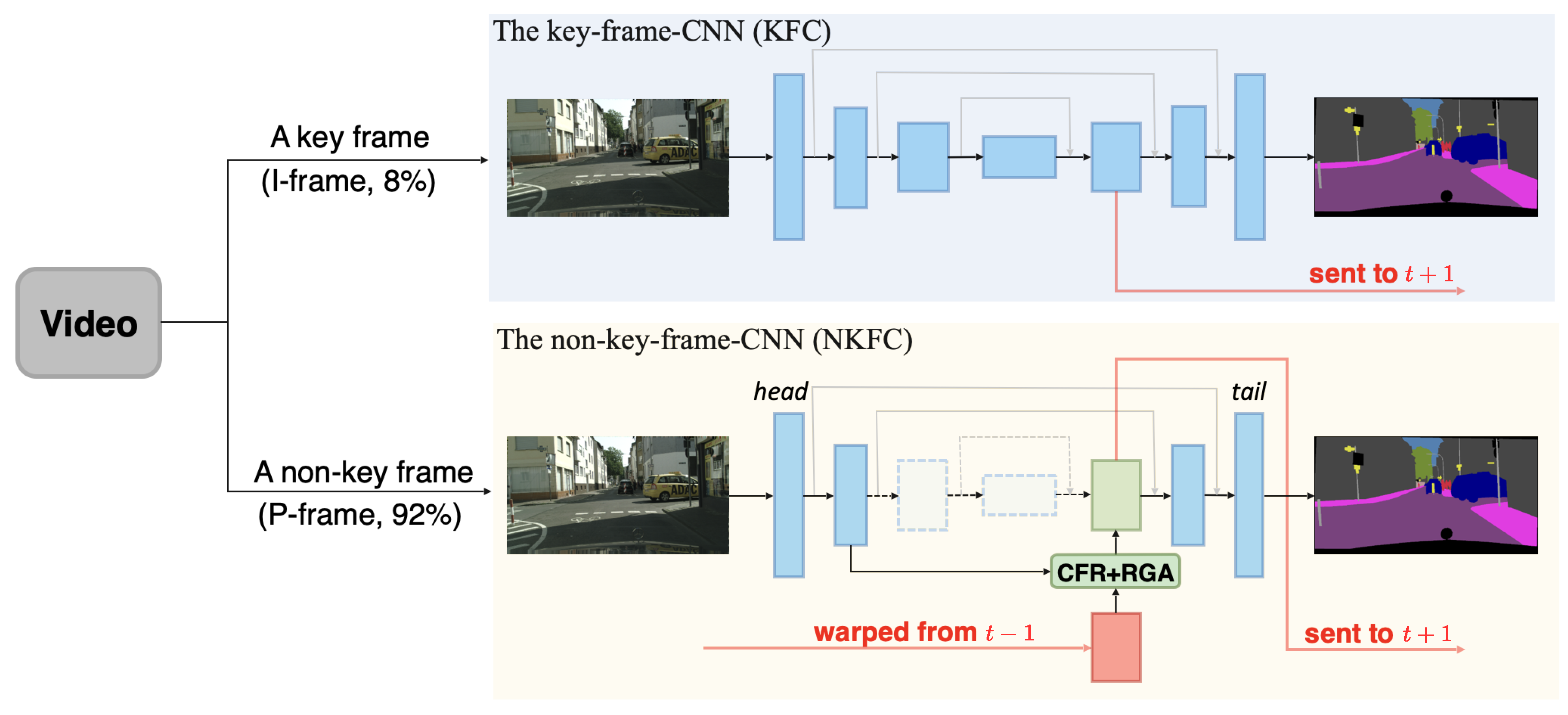
Figure 3.
The framework of TWNet. A group of frames consists of one key frame followed by many non-key frames. Key frames are sent to the key-frame CNN (KFC) and non-key frames to the non-key-frame CNN (NKFC), where the warped context features from the preceding frame are corrected by the CRF and RGA modules. Both CNNs output the result label maps and the interior context feature maps. Dashed arrows and boxes in NKFC indicate the operations to be skipped.
Figure 3.
The framework of TWNet. A group of frames consists of one key frame followed by many non-key frames. Key frames are sent to the key-frame CNN (KFC) and non-key frames to the non-key-frame CNN (NKFC), where the warped context features from the preceding frame are corrected by the CRF and RGA modules. Both CNNs output the result label maps and the interior context feature maps. Dashed arrows and boxes in NKFC indicate the operations to be skipped.
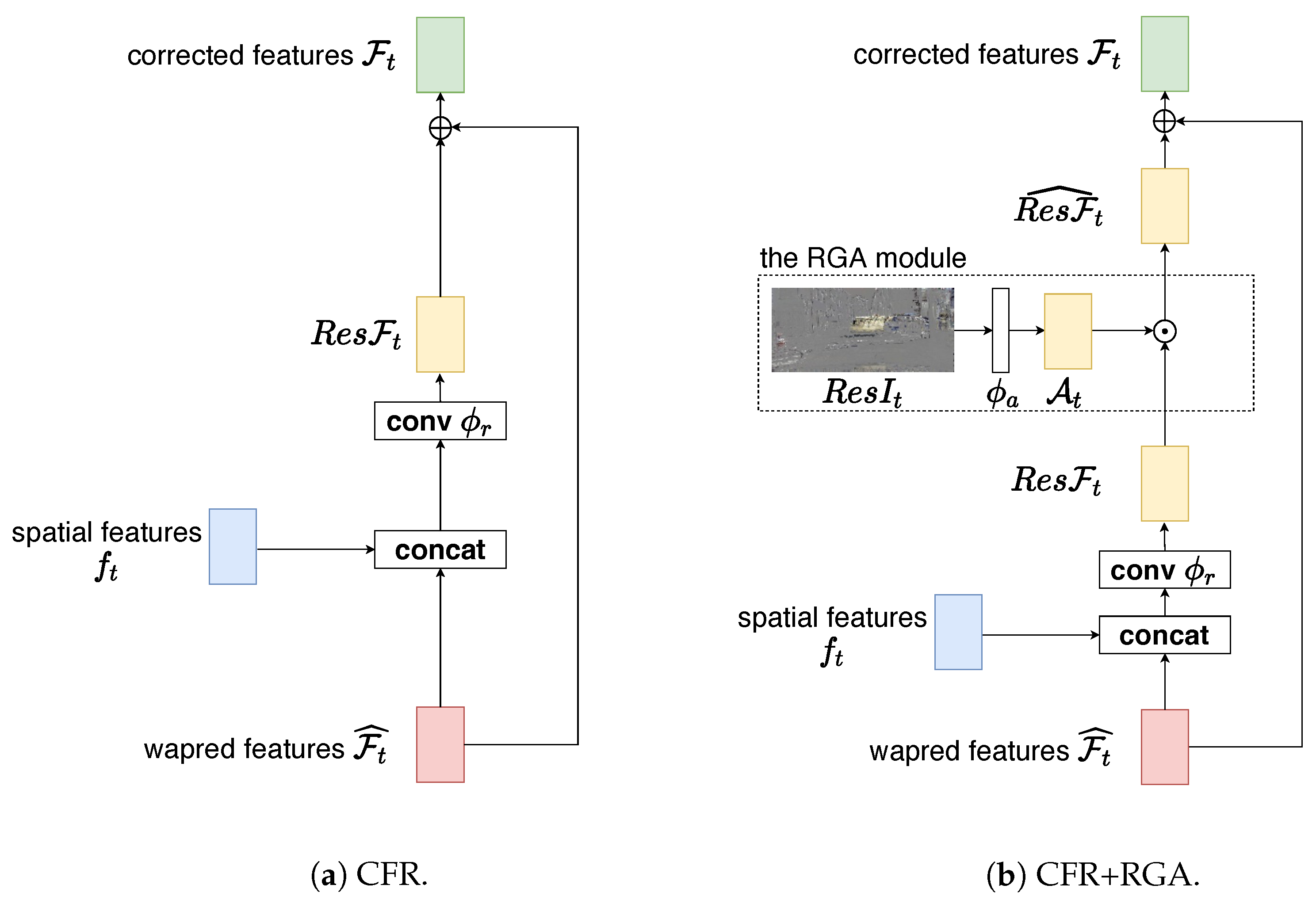
Figure 4.
Illustration of the CFR and RGA modules. (a) The CFR module first concatenates , the spatial features of the current non-key frame, and , the warped features from the preceding frame. Then, the concatenated features are fed into a convolution layer to learn the feature space residuals . Finally, CFR adds the to to obtain the corrected features . (b) The RGA module is based on CFR. After obtaining , RGA uses compressed domain residuals , which are fed into a convolution layer to learn the attention map . Then, RGA multiplies with to focus on the error-prone regions and obtains . RGA adds to to obtain the corrected features . “⊙”: element-wise multiplication; “⊕”: element-wise addition.
Figure 4.
Illustration of the CFR and RGA modules. (a) The CFR module first concatenates , the spatial features of the current non-key frame, and , the warped features from the preceding frame. Then, the concatenated features are fed into a convolution layer to learn the feature space residuals . Finally, CFR adds the to to obtain the corrected features . (b) The RGA module is based on CFR. After obtaining , RGA uses compressed domain residuals , which are fed into a convolution layer to learn the attention map . Then, RGA multiplies with to focus on the error-prone regions and obtains . RGA adds to to obtain the corrected features . “⊙”: element-wise multiplication; “⊕”: element-wise addition.
Figure 5.
Choices of different layers for feature warping. The chosen layer is indicated with red color. The dotted arrows and boxes denote skipped operations.
Figure 5.
Choices of different layers for feature warping. The chosen layer is indicated with red color. The dotted arrows and boxes denote skipped operations.
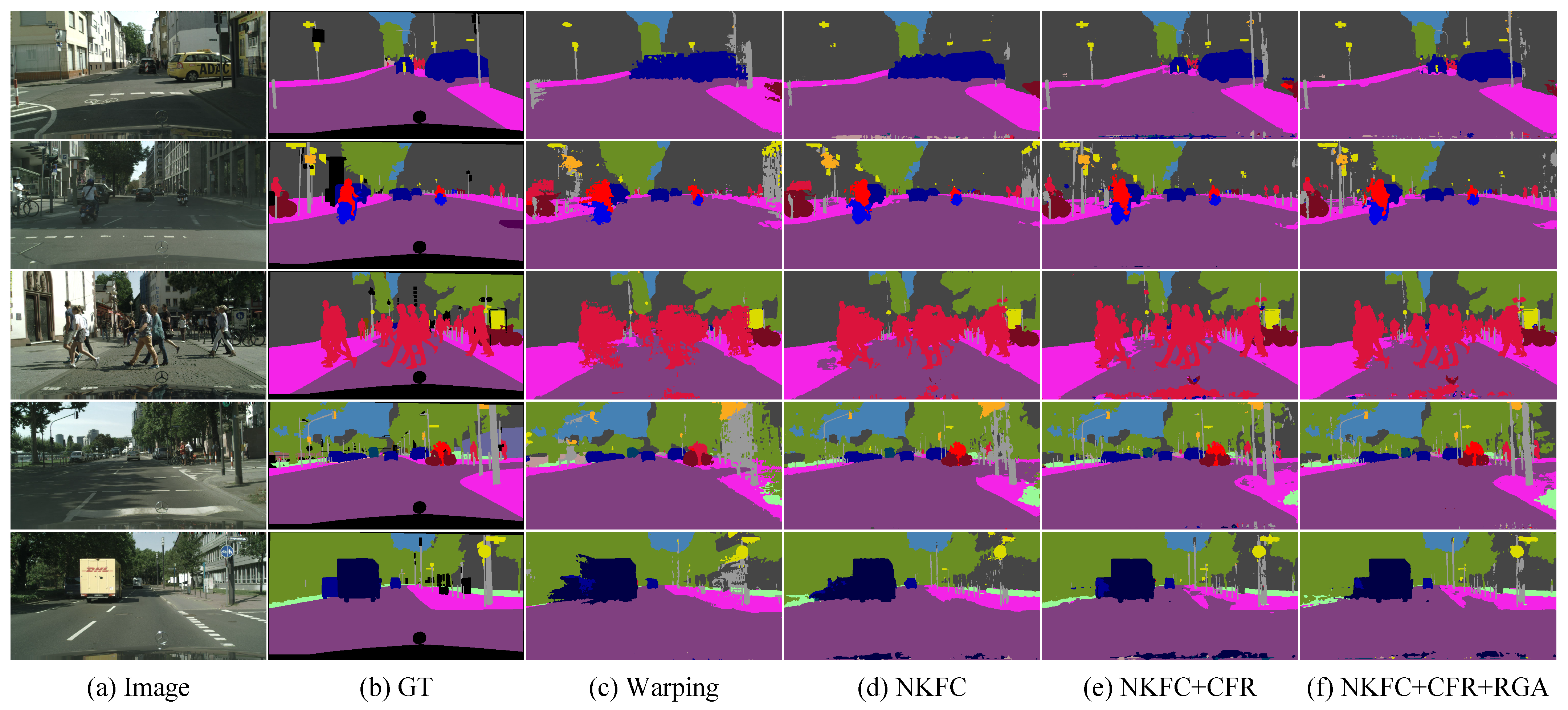
Figure 6.
Qualitative results on Cityscapes. GT: ground truth; warping: normal warping; NKFC: the non-key-frame CNN; CFR: context feature rectification; and RGA: residual-guided attention.
Figure 6.
Qualitative results on Cityscapes. GT: ground truth; warping: normal warping; NKFC: the non-key-frame CNN; CFR: context feature rectification; and RGA: residual-guided attention.
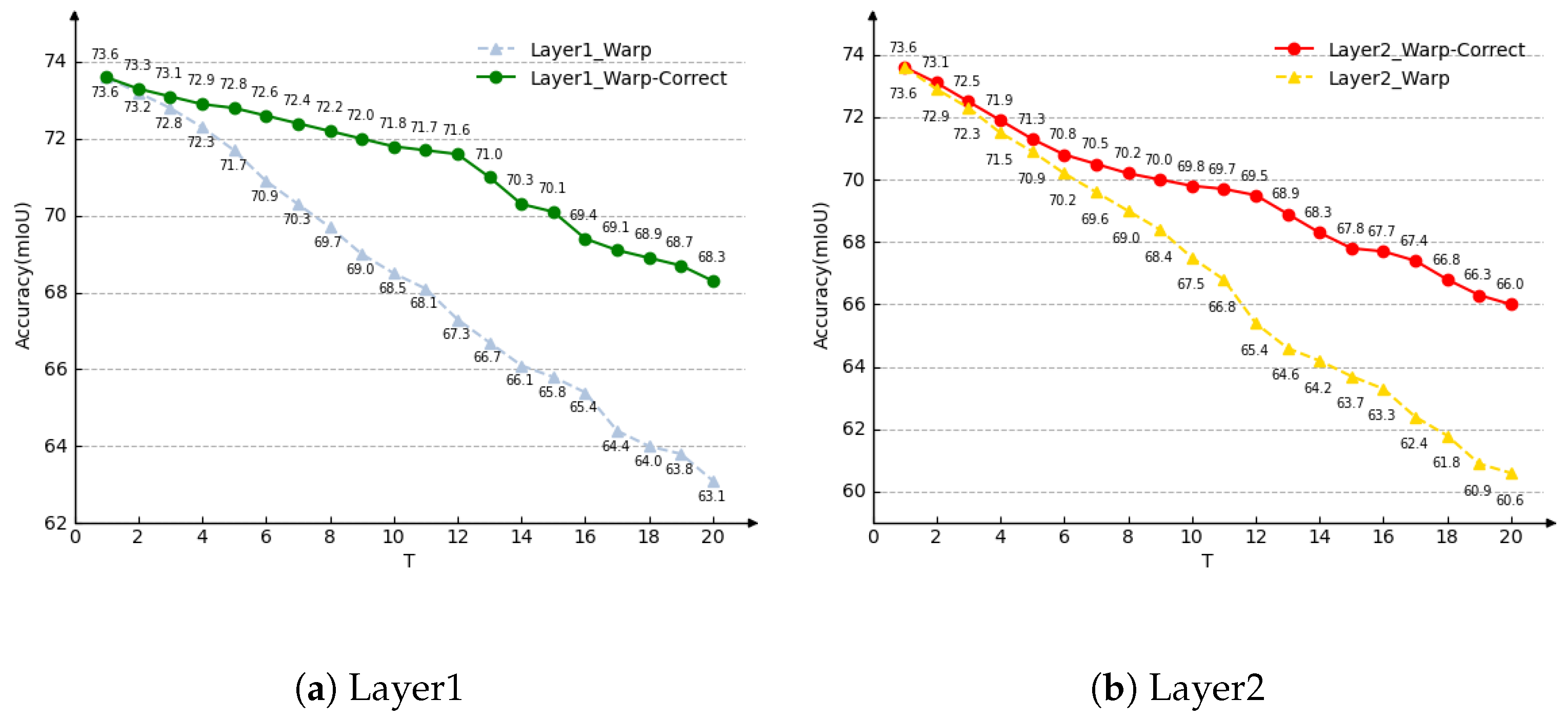
Figure 7.
Performance degradation of warp and warp-correct. (a): Layer 1 used for feature warping. (b): Layer 2 used for warping. T: frame interval between the key frame and the frame to be evaluated. The correction module effectively alleviates the long-term error accumulation problem.
Figure 7.
Performance degradation of warp and warp-correct. (a): Layer 1 used for feature warping. (b): Layer 2 used for warping. T: frame interval between the key frame and the frame to be evaluated. The correction module effectively alleviates the long-term error accumulation problem.
Table 1.
Performance comparison of different layers used for feature warping. “Fine-tuned” indicates whether the second training step is performed to fine-tune NKFC. If not fin-tuned, the parameters of the head and tail layers keep the same as those in KFC. If Layer 3 is chosen, no trainable parameters exist and hence there is no fine-tuning. ↑: higher is better. ✓ indicates the fine-tuning is used. The best results are shown in bold.
Table 1.
Performance comparison of different layers used for feature warping. “Fine-tuned” indicates whether the second training step is performed to fine-tune NKFC. If not fin-tuned, the parameters of the head and tail layers keep the same as those in KFC. If Layer 3 is chosen, no trainable parameters exist and hence there is no fine-tuning. ↑: higher is better. ✓ indicates the fine-tuning is used. The best results are shown in bold.
| Warping Layer | Fine-Tuned | mIoU ↑ | FPS ↑ |
|---|
| Layer 1 | | 67.3 | 65.5 |
| ✓ | 69.6 | 65.5 |
| Layer 2 | | 65.4 | 89.8 |
| ✓ | 67.8 | 89.8 |
| Layer 3 | - | 63.2 | 119.7 |
Table 2.
Validation of . : the weight of . We achieve the bests results when setting to 10. ↑: higher is better. The best results are shown in bold.
Table 2.
Validation of . : the weight of . We achieve the bests results when setting to 10. ↑: higher is better. The best results are shown in bold.
| Warping Layer | | mIoU ↑ | FPS ↑ |
|---|
| Layer 1 | 0 | 69.9 | 63.1 |
| 1 | 70.2 | 63.1 |
| 10 | 70.6 | 63.1 |
| 20 | 70.3 | 63.1 |
| Layer 2 | 0 | 67.6 | 86.3 |
| 1 | 68.1 | 86.3 |
| 10 | 68.6 | 86.3 |
| 20 | 68.3 | 86.3 |
Table 3.
Effect of each module of TWNet. FT: the fine-tuning of the non-key CNN (the second training step); CFR: context feature rectification; and RGA: residual-guided attention. “✓” means the model utilizes the corresponding module. We also show the extra cost of adding our modules. ↑: higher is better; ↓: lower is better. The best results are shown in bold.
Table 3.
Effect of each module of TWNet. FT: the fine-tuning of the non-key CNN (the second training step); CFR: context feature rectification; and RGA: residual-guided attention. “✓” means the model utilizes the corresponding module. We also show the extra cost of adding our modules. ↑: higher is better; ↓: lower is better. The best results are shown in bold.
| Warping Layer | FT | CFR | RGA | mIoU ↑ | FPS ↑ | GFLOPs ↓ |
|---|
| Layer 1. | | | | 67.3 | 65.5 | 113.28 |
| ✓ | | | 69.6 | 65.5 | +0 |
| ✓ | ✓ | | 70.6 | 63.1 | +2.42 |
| ✓ | ✓ | ✓ | 71.6 | 61.8 | +0.0012 |
| Layer 2. | | | | 65.4 | 89.8 | 73.00 |
| ✓ | | | 67.8 | 89.8 | +0 |
| ✓ | ✓ | | 68.6 | 86.3 | +2.42 |
| ✓ | ✓ | ✓ | 69.5 | 84.9 | +0.0029 |
Table 4.
IoU improvements of different categories. We choose Layer 1 here. The accuracy of non-rigid objects improves significantly. The improvements over five percentage points are shown in bold.
Table 4.
IoU improvements of different categories. We choose Layer 1 here. The accuracy of non-rigid objects improves significantly. The improvements over five percentage points are shown in bold.
| Method | Object | Human | Vehicle | Nature | Construction | Sky | Flat |
|---|
| Warping | 43.8 | 56.7 | 82.2 | 86.6 | 87.1 | 91.6 | 96.6 |
| NKFC | 51.2 (+7.4) | 65.5 (+8.8) | 84.6 (+2.4) | 89.6 (+3.0) | 89.1 (+2.0) | 94.0 (+2.4) | 97.3 (+0.7) |
| NKFC + CFR | 62.2 (+18.4) | 75.2 (+18.5) | 89.7 (+7.5) | 91.3 (+4.7) | 90.8 (+3.7) | 94.2 (+2.6) | 97.9 (+1.3) |
| NKFC + CFR + RGA | 62.2 (+18.4) | 76.1 (+19.4) | 90.1 (+7.9) | 91.1 (4.5) | 91.0 (+3.9) | 94.2 (+2.6) | 98.0 (+1.4) |
Table 5.
Effect of different flow models. ↑: higher is better. The best results are shown in bold.
Table 5.
Effect of different flow models. ↑: higher is better. The best results are shown in bold.
| Flow Model | mIoU ↑ | FPS ↑ |
|---|
| Motion vectors | 67.3 | 65.5 |
| FlowNet2 | 67.5 | 13.2 |
| FlowNet2-s | 66.3 | 26.6 |
| FlowNet2-c | 66.6 | 22.7 |
| PWC-Net | 67.0 | 29.4 |
Table 6.
The required head layers for different versions of TWNet. head n: the nth head layer of the encoder. ✓ indicates the specific layer is required.
Table 6.
The required head layers for different versions of TWNet. head n: the nth head layer of the encoder. ✓ indicates the specific layer is required.
| Model Name | Head1 | Head2 | Head3 |
|---|
| Per-frame | ✓ | ✓ | ✓ |
| TWNet-Layer1 | ✓ | ✓ | |
| TWNet-Layer2 | ✓ | | |
| TWNet-Layer3 | | | |
Table 7.
Head layers for different backbones. We quote the notations from the TensorFlow Slim package.
Table 7.
Head layers for different backbones. We quote the notations from the TensorFlow Slim package.
| Backbone | Head1 | Head2 | Head3 |
|---|
| MobileNetV1 | | | |
| MobileNetV2 | | | |
| ResNet-18 | | | |
Table 8.
Performance of TWNet based on different backbone networks. Warp: the layer where feature warping is performed. “None” means no feature warping. ↑: higher is better. × indicates the speed-up times. The best results are shown in bold.
Table 8.
Performance of TWNet based on different backbone networks. Warp: the layer where feature warping is performed. “None” means no feature warping. ↑: higher is better. × indicates the speed-up times. The best results are shown in bold.
| Backbone | Warp | mIoU ↑ | FPS ↑ | Speed-Up (×) |
|---|
| MobileNetV1 | None | 73.6 | 35.5 | - |
| Layer1 | 71.6 | 61.8 | 1.74 |
| Layer2 | 69.5 | 84.9 | 2.39 |
| Layer3 | 63.2 | 119.7 | 3.37 |
| MobileNetV2 | None | 73.2 | 32.3 | - |
| Layer1 | 71.3 | 59.6 | 1.85 |
| Layer2 | 69.4 | 82.5 | 2.55 |
| Layer3 | 62.4 | 115.8 | 3.59 |
| ResNet-18 | None | 71.6 | 36.9 | - |
| Layer1 | 69.4 | 63.6 | 1.72 |
| Layer2 | 67.7 | 86.8 | 2.35 |
| Layer3 | 61.9 | 120.4 | 3.26 |
Table 9.
Comparison of SOTA models on Cityscapes. Terms with “-pf”: mIoU/FPS for per-frame model; “FPS norm” is calculated based on the ability of the GPU. All the results only use train as the training set. All of the TWNet models run at a resolution of . ↑: higher is better; ↓: lower is better. The best results are shown in bold.
Table 9.
Comparison of SOTA models on Cityscapes. Terms with “-pf”: mIoU/FPS for per-frame model; “FPS norm” is calculated based on the ability of the GPU. All the results only use train as the training set. All of the TWNet models run at a resolution of . ↑: higher is better; ↓: lower is better. The best results are shown in bold.
| Model | Eval Set | Resolution | mIoU-pf ↑ | mIoU ↑ | FPS-pf ↑ | FPS ↑ | FPS Norm ↑ | Params (M) ↓ | GPU |
|---|
| Per-frame Models |
| ICNet [22] | val | | 67.7 | - | 30.3 | - | 49.7 | 25.17 | TITAN X(M) |
| ERFNet [27] | test | | 69.7 | - | 11.2 | - | 18.4 | 2.08 | TITAN X(M) |
| SwiftNetRN-18 [19] | val | | 74.4 | - | 34.0 | - | 34.0 | 12.9 | 1080 Ti |
| CAS [21] | val | | 74.0 | - | 34.2 | - | 48.9 | 1070 | |
| Liu et al. [23] | val | | 73.9 | - | 20.8 | - | 20.8 | 3.2 | 1080 Ti |
| TD-PSP18 [25] | val | | 76.8 | - | 11.8 | - | 10.5 | 12.77 | Titan Xp |
| DABNet [29] | test | | 70.1 | - | 104.0 | - | 104.0 | 0.76 | 1080 Ti |
| LRNNet [58] | test | | 72.2 | - | 71.0 | - | 71.0 | 0.68 | 1080 Ti |
| LEANet [14] | test | | 71.9 | - | 77.3 | - | 77.3 | 0.74 | 1080 Ti |
| LAANet [13] | test | | 73.6 | - | 95.8 | - | 95.8 | 0.67 | 1080 Ti |
| DDRNet-23-slim [46] | test | | 77.4 | - | 101.6 | - | 79.37 | 5.7 | 2080 Ti |
| Video-based Models |
| DFF [34] | val | | 71.1 | 69.2 | 1.52 | 5.6 | 12.8 | N/A | Tesla K40 |
| DVSNet1 [33] | val | | 73.5 | 63.2 | 5.6 | 30.4 | 30.4 | 42.73 | 1080 Ti |
| DVSNet2 [33] | val | | 73.5 | 70.4 | 5.6 | 19.8 | 19.8 | 62.9 | 1080 Ti |
| Prop-mv [31] | val | | 75.2 | 61.7 | 1.3 | 7.6 | 9.6 | 8.7 | Tesla K80 |
| Interp-mv [31] | val | | 75.2 | 66.6 | 1.3 | 7.2 | 9.1 | 8.7 | Tesla K80 |
| Low-Latency [32] | val | | 80.2 | 75.9 | 2.8 | 8.4 | - | 50.1 | N/A |
| LMA [59] | val | | 72.1 | 73.7 | 99.0 | 86.2 | 67.2 | N/A | 2080 Ti |
| Ours |
| TWNet-Layer1 | val | | 73.6 | 71.6 | 35.5 | 61.8 | 61.8 | 12.35 | 1080 Ti |
| TWNet-Layer1 | test | | 73.1 | 71.2 | 35.5 | 61.8 | 61.8 | 12.35 |
| TWNet-Layer2 | val | | 73.6 | 69.5 | 35.5 | 84.9 | 84.9 | 12.14 |
| TWNet-Layer2 | test | | 73.1 | 69.0 | 35.5 | 84.9 | 84.9 | 12.14 |
Table 10.
Effect of each module on the CamVid test set. ↑: higher is better. The best results are shown in bold. ✓ indicates the module is used.
Table 10.
Effect of each module on the CamVid test set. ↑: higher is better. The best results are shown in bold. ✓ indicates the module is used.
| Warping Layer | FT | CFR | RGA | mIoU ↑ | FPS ↑ |
|---|
| Layer 1 | | | | 68.8 | 183.1 |
| ✓ | | | 69.9 | 183.1 |
| ✓ | ✓ | | 71.0 | 179.8 |
| ✓ | ✓ | ✓ | 71.5 | 175.2 |
| Layer 2 | | | | 66.7 | 252.6 |
| ✓ | | | 68.1 | 252.6 |
| ✓ | ✓ | | 69.3 | 245.8 |
| ✓ | ✓ | ✓ | 70.0 | 240.7 |
Table 11.
Comparison with others on the CamVid test set. ↑: higher is better; ↓: lower is better. The best results are shown in bold.
Table 11.
Comparison with others on the CamVid test set. ↑: higher is better; ↓: lower is better. The best results are shown in bold.
| Model | Resolution | mIoU-pf ↑ | mIoU ↑ | FPS-pf ↑ | FPS ↑ | FPS Norm ↑ | Params (M) ↓ | GPU |
|---|
| Per-frame Models |
| DFANet A [9] | | 64.7 | - | 120 | - | 196.8 | 7.8 | TITAN X |
| ICNet [22] | | 67.1 | - | 27.8 | - | 45.6 | 25.17 | TITAN X (M) |
| BiSeNet [10] | | 68.7 | - | 116.2 | - | 103.4 | 13.43 | Titan Xp |
| BiSeNet V2 [43] | | 73.2 | - | 32.7 | - | 32.7 | 49 | 1080 Ti |
| Liu et al. [23] | | 78.2 | - | 27.8 | - | 27.8 | 3.2 | 1080 Ti |
| TD-PSP18 [25] | | 72.6 | - | 25 | - | 22.3 | 12.77 | Ttian Xp |
| DABNet [29] | | 66.7 | - | 124.4 | - | 124.4 | 0.76 | 1080 Ti |
| LRNNet [58] | | 67.6 | - | 83.0 | - | 83.0 | 0.67 | 1080 Ti |
| LEANet [14] | | 67.5 | - | 98.6 | - | 98.6 | 0.74 | 1080 Ti |
| LAANet [13] | | 67.9 | - | 112.5 | - | 112.5 | 0.67 | 1080 Ti |
| DRRNet-23-slim [46] | | 74.3 | - | 230 | - | 179.7 | 5.7 | 2080 Ti |
| Video-based Models |
| Prov-mv [31] | | 68.6 | 63.4 | 3.6 | 21.4 | 27.0 | 8.7 | Tesla K80 |
| Interp-mv [31] | | 68.6 | 67.3 | 3.6 | 19.1 | 24.1 | 8.7 | Tesla K80 |
| Ours |
| TWNet-Layer1 | | 73.5 | 71.5 | 103.5 | 175.2 | 175.2 | 12.35 | 1080 Ti |
| TWNet-Layer2 | | 73.5 | 70.0 | 103.5 | 240.7 | 240.7 | 12.14 | 1080 Ti |













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}