

Online Coal Identification Based on One-Dimensional Convolution and Its Industrial Applications

Abstract
:1. Introduction
2. The Profile of the Thermal Power Plant
3. Preliminaries
3.1. Maximum Information Coefficient (MIC)
- (1)
- Universality: applicable to all types of data, regardless of data distribution issues.
- (2)
- Autonomy: automatically mines the relationship among different features.
- (3)
- Robustness: strong anti-interference ability, not affected by outliers and missing values.
- (4)
- Interpretability: MIC results are in the range of [0, 1], allowing the strength of the correlation to be visualized.
| Algorithm 1 Feature Selection through Maximum Information Coefficient. |
Input: A data matrix Output: Selected k features , i = 1,2,…, k; // One of the random feature in 1:, k = 1,2,…, n; // Another random feature in 2:, l = 1,2,…, n; Step 1: Compute according to Equation (3) Step 2: Compute according to Equation (4) Step 3: Sort the result in descending order Step 4: Select the best k features as the output result. , i = 1,2,…, k; |
3.2. One-Dimensional Convolution Network
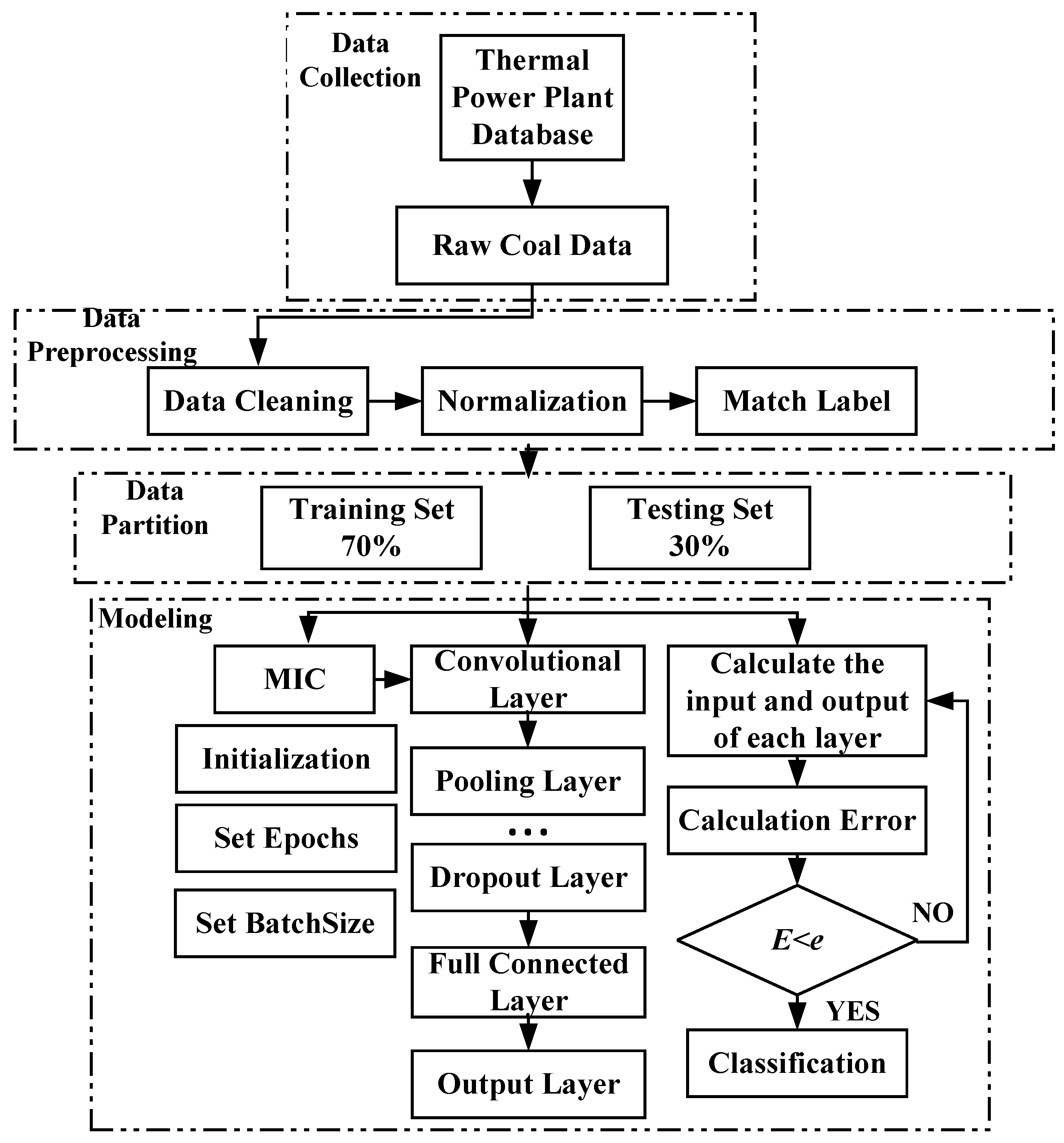
4. Methodology
4.1. Variable Selection Strategy
- (1)
- Calculation of MIC values: MIC values are computed to measure the correlation among different variables, which belong to a non-parametric method that can adjust data size and dimensionality adaptively. This method is highly adaptable to different data sets, and each pair of variables can be calculated to determine the correlation strength relationship.
- (2)
- Sorting of MIC values: The MIC values calculated for each variable are sorted from largest to smallest, with the ranking indicating the strength of the correlation between the characteristic variables and the response variables. A value closer to 1 indicates a stronger correlation, whereas a value closer to 0 indicates a weaker correlation.
- (3)
- Variable selection: The variables with a strong correlation with the remaining variables are selected from the ranked MIC values for elimination, and the remaining variables are retained as feature variables for subsequent modeling.
4.2. Construction of the Model for Coal Identification
- (1)
- Data acquisition: The experimental data used in this study are related to the actual application of coal in a coal-fired boiler in a TPP, consisting of a total of 288,000 data.
- (2)
- Data pre-processing: Directly collected data from TPPs often contain missing and duplicated data caused by the industrial environment and process flow, making them unsuitable for direct use. Therefore, data cleaning is performed to remove or correct missing data, normalize data to reduce the computational load, and improve data labeling to meet the supervised learning conditions of 1D-CNN.
- (3)
- Data set partitioning: The processed data are divided into training and test sets.
- (4)
- MIC-CNN model construction: The input data are fed into the model for training and testing, and model accuracy is validated using the validation set. In addition, the model is compared with back propagation (BP) neural network and 1D-CNN methods.
| Algorithm 2 Coal identification algorithm based on MIC-CNN. |
Input: A data matrix = () Output: An array R; // Classification Result // Complete data preprocessing Step 1:Def function (data preprocessing): Return Data cleaning, Normalization, Match Label; // Complete data partition Step 2: Def function (data partition): Training Set: 70%, Testing Set: 30% Return Training Set, Testing Set; // Complete modeling Step 3: Def function (MIC): // feature selection Select best k features ), i = 1,2,…, k; Return ); // New data Step 4: Def function (CNN): Pooling Layer, Dropout Layer, Full Connected Layer, Output Layer Initialization, Set Epochs, Set BatchSize Calculation Error E If E < e: Return R; Else: Calculate again; |
4.3. Performance Measurement Criteria
5. Case Study
5.1. Data Description
5.2. Data Pre-Processing
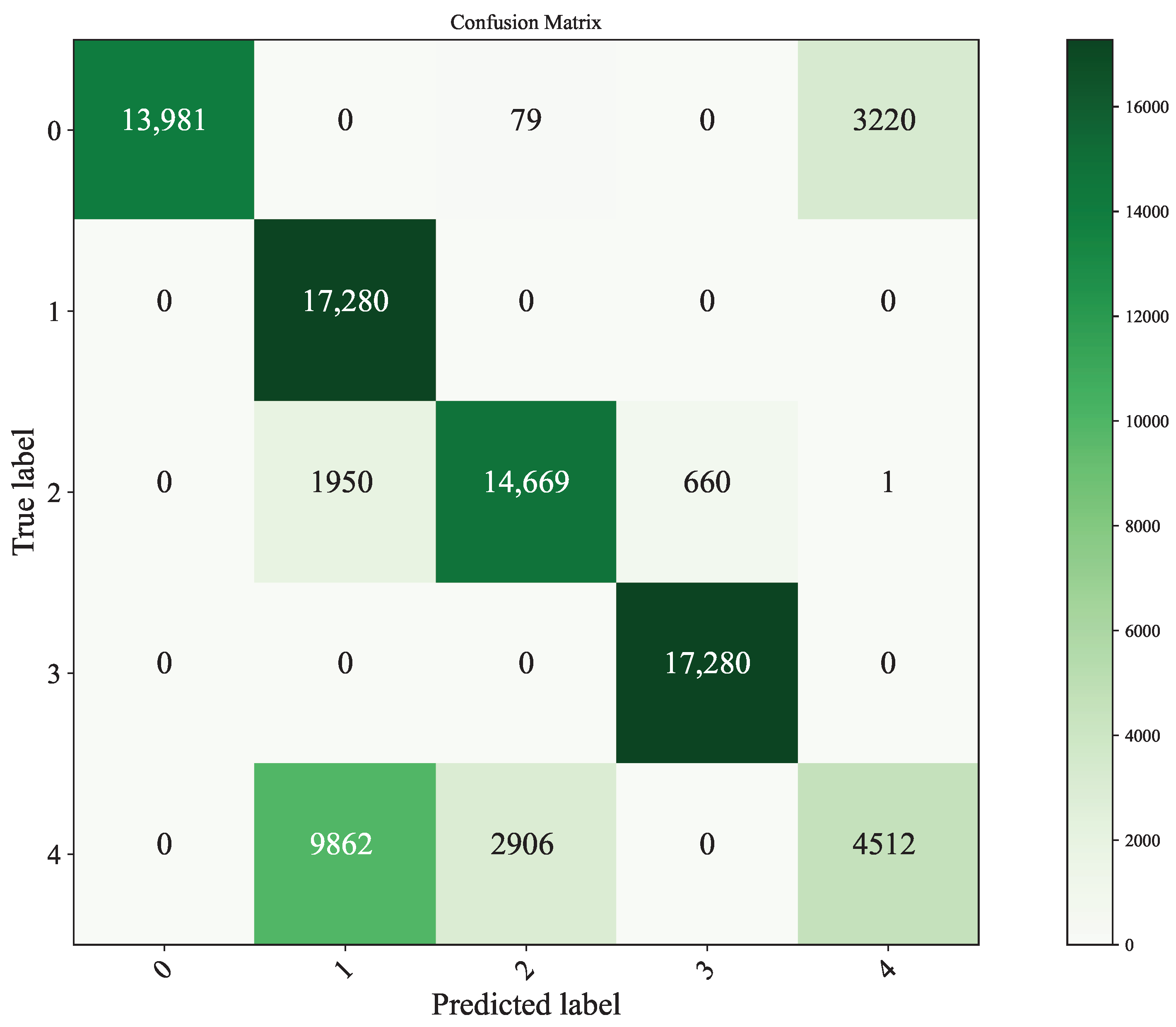
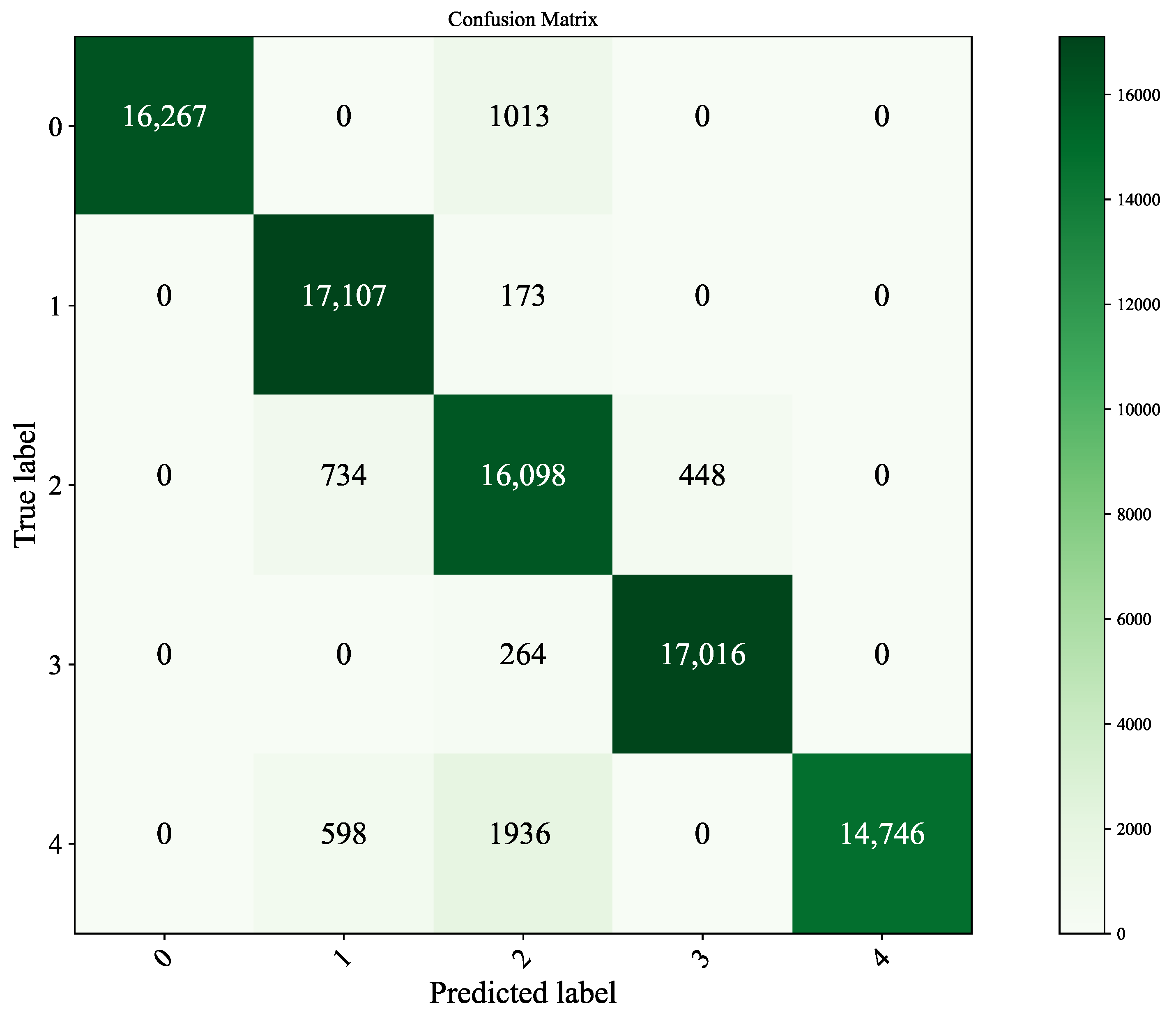
5.3. Model Performance Analysis
- (1)
- 1D-CNN model: 1D-CNN encompasses a convolutional layer, pooling layer, fully connected layer, and classification output layer. In this experiment, three convolutional layers are used, and each convolutional layer executes two convolutional calculations. The pooling layer adopts maximum pooling after each convolutional layer. Dropout is implemented before the fully connected layer, with a value of , . The optimizer used in this study is Adam, with a learning rate set at . The original power plant data are preprocessed and split into training and test sets in a 7:3 ratio. Following this step, the features are non-linearly combined using the fully connected layer, and the coal categories are obtained through the classification output layer. The results of model training and testing are recorded.
- (2)
- MIC-CNN model: During the establishment of the MIC-CNN coal identification model, the data are initially subjected to feature selection using MIC, followed by data pre-processing and division into a training set and a test set at a ratio of 7:3. Subsequently, the 1D-CNN model is trained to accomplish the coal identification task and evaluated for accuracy and generalization ability on the test set. The resulting training and test results of the model are documented.
- (3)
- BP neural network model: In building a multilayer perceptron for coal classification, an input layer with 47 nodes, an output layer with five nodes, 32 hidden layers, Relu as the activation function, and Softmax classifier as the output layer are used to output the classification results. The accuracy and training test results of the model are recorded.
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| TPP | Thermal power plants |
| CNN | Convolutional neural network |
| 1D-CNN | One-dimensional convolution network |
| SVM | Support vector machine |
| VGG | Visual geometry group |
| ADARTS | Attention for differentiable neural architecture search |
| MOEA-PS | Multi-objective evolutionary algorithm with a probability stack |
| EPC-DARTS | Efficient partial channel connection for differentiable architecture search |
| MIC | Maximum information coefficient |
| SWUP | Spiral Wound Universal Pressure Boiler |
| DCS | Distributed Control System |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Variables | Units |
|---|---|---|
| 1 | 2 AB phase voltage of generator stator | KV |
| 2 | 2A The temperature of the lower bearing of the coal mill’s rotary separator | DEG C |
| 3 | A Motor speed of coal feeder | rpm/mi |
| 4 | A Instantaneous coal feeding rate for coal feeder | t/h |
| 5 | A Three-selection output of primary air temperature at the outlet of air preheater | DEG C |
| 6–11 | A Coal mill motor stator coil temperature 1–6 | DEG C |
| 12–15 | A Coal mill motor bearing temperature 1–4 | DEG C |
| 16 | A Current of coal mill | A |
| 17–19 | A Coal mill air-powder mixture temperature1–3 | DEG C |
| 20–21 | A Coal mill planetary gearbox input bearing temperature 1–2 | DEG C |
| 22–25 | A Coal mill planetary gearbox bearing temperature 1–4 | DEG C |
| 26 | A Feedback on the position of the cold primary air electric adjustment damper of the coal mill | % |
| 27 | A Differential pressure between the sealing air of the coal mill and the lower part of the grinding bowl | kPa |
| 28 | A Differential pressure above and below the grinding bowl of the coal mill | kPa |
| 29 | A Position feedback of electric regulating damper for hot primary air of coal mill | % |
| 30 | A Lubricating oil return temperature of coal mill | DEG C |
| 31 | A Coal mill lubricating oil temperature 1 | DEG C |
| 32 | A Temperature of lubricating oil tank of coal mill | DEG C |
| 33 | A Lubricating oil pressure of coal mill | MPa |
| 34 | A Coal mill rotary separator current | A |
| 35 | A Bearing temperature on the rotary separator of the coal mill | DEG C |
| 36 | A Coal mill rotary separator speed output | rpm/mi |
| 37 | A Lower bearing temperature of rotary separator of coal mill | DEG C |
| 38 | A Primary air pressure of coal mill | kPa |
| 39 | A Inlet air temperature of forced draft fan | DEG C |
| 40 | BTU correction command feedback | |
| 41 | B Three-selection output of primary air temperature at the outlet of air preheater | DEG C |
| 42 | Generator active power three-selection output | MW |
| 43 | Three-selection output of primary air volume of coal mill | t/h |
| 44 | Primary Air Temperature Dual Selection Output of Coal Mill | DEG C |
| 45–47 | Hot primary air header pressure 1–3 | MPa |
References
- Rushdi, A.; Sharma, A.; Gupta, R. An experimental study of the effect of coal blending on ash deposition. Fuel 2004, 83, 495–506. [Google Scholar] [CrossRef]
- Chen, G.; Xia, J.; Peng, P.; Yang, T.; Gao, W.; Yan, Z.; Jiang, J. Development and Application of the Intelligent Decision System for Entire Process of Coal Blending. ASME Power Conf. 2011, 44595, 215–220. [Google Scholar]
- Nomura, S.; Arima, T.; Kato, K. Coal blending theory for dry coal charging process. Fuel 2004, 83, 1771–1776. [Google Scholar] [CrossRef]
- Dai, C.; Cai, X.H.; Cai, Y.P.; Huang, G.H. A simulation-based fuzzy possibilistic programming model for coal blending management with consideration of human health risk under uncertainty. Appl. Energy 2014, 133, 1–13. [Google Scholar] [CrossRef]
- Hu, L.; Zhang, Y.; Chen, D.; Fang, J.; Zhang, M.; Wu, Y.; Zhang, H. Experimental study on the combustion and NOx emission characteristics of a bituminous coal blended with semi-coke. Appl. Therm. Eng. 2019, 160, 113993. [Google Scholar] [CrossRef]
- Liu, C.; Li, M.; Zhang, Y.; Han, S.; Zhu, Y. An enhanced rock mineral recognition method integrating a deep learning model and clustering algorithm. Miner 2019, 9, 516. [Google Scholar] [CrossRef]
- Hui-ling, M.; Man, L. Characteristic analysis and recognition of coal-rock interface based on visual technology. Int. J. Signal Process. Image Process. Pattern Recognit. 2016, 9, 61–68. [Google Scholar]
- Pu, Y.; Apel, D.B.; Szmigiel, A.; Chen, J. Image recognition of coal and coal gangue using a convolutional neural network and transfer learning. Energies 2019, 12, 1735. [Google Scholar] [CrossRef]
- Pontil, M.; Verri, A. Properties of support vector machines. Neural Comput. 1998, 10, 955–974. [Google Scholar] [CrossRef]
- Joachims, T. Text categorization with support vector machines: Learning with many relevant features. In Proceedings of the 10th European Conference on Machine Learning, Chemnitz, Germany, 21–23 April 1998; pp. 137–142. [Google Scholar]
- Ng, A.; Jordan, M. On discriminative vs. generative classifiers: A comparison of logistic regression and naive bayes. In Proceedings of the Advances in Neural Information Processing Systems 14 (NIPS 2001), Vancouver, BC, Canada, 3–8 December 2001; Volume 14. [Google Scholar]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef]
- Xu, S. Bayesian Naïve Bayes classifiers to text classification. J. Inf. Sci. 2018, 44, 48–59. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Quinlan, J.R. Improved use of continuous attributes in C4.5. J. Artif. Intel. Res. 1996, 4, 77–90. [Google Scholar]
- Banfield, R.E.; Hall, L.O.; Bowyer, K.W.; Kegelmeyer, W.P. A comparison of decision tree ensemble creation techniques. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 29, 173–180. [Google Scholar] [CrossRef] [PubMed]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM. 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Zhang, X.; Zou, J.; He, K.; Sun, J. Accelerating very deep convolutional networks for classification and detection. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 1943–1955. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Xue, Y.; Qin, J. Partial connection based on channel attention for differentiable neural architecture search. IEEE Trans. Industr. Inform. 2023, 19, 6804–6813. [Google Scholar] [CrossRef]
- Xue, Y.; Chen, C.; Słowik, A. Neural Architecture Search Based on A Multi-objective Evolutionary Algorithm with Probability Stack. IEEE Trans. Evol. Comput. 2023, 27, 778–786. [Google Scholar] [CrossRef]
- Cai, Z.; Chen, L.; Liu, H.L. EPC-DARTS: Efficient partial channel connection for differentiable architecture search. Neural Netw. 2023, 166, 344–353. [Google Scholar] [CrossRef]
- Li, D.; Zhang, Z.; Xu, Z.; Xu, L.; Meng, G.; Li, Z.; Chen, S. An image-based hierarchical deep learning framework for coal and gangue detection. IEEE Access 2019, 7, 184686–184699. [Google Scholar] [CrossRef]
- Liu, Q.; Li, J.; Li, Y.; Gao, M. Recognition methods for coal and coal gangue based on deep learning. IEEE Access 2021, 9, 77599–77610. [Google Scholar] [CrossRef]
- Lv, Z.; Wang, W.; Xu, Z.; Zhang, K.; Lv, H. Cascade network for detection of coal and gangue in the production context. Powder Technol. 2021, 377, 361–371. [Google Scholar] [CrossRef]
- Reshef, D.N.; Reshef, Y.A.; Finucane, H.K.; Grossman, S.R.; Mcvean, G.; Turnbaugh, P.J.; Lander, E.S.; Mitzenmacher, M.; Sabeti, P.C. Detecting novel associations in large data sets. Science 2011, 334, 1518–1524. [Google Scholar] [CrossRef]
- Chen, H.; Chen, A.; Xu, L.; Xie, H.; Qiao, H.; Lin, Q.; Cai, K. A deep learning CNN architecture applied in smart near-infrared analysis of water pollution for agricultural irrigation resources. Agric. Water Manag. 2020, 240, 106303. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]









| Number of Samples Training Set/Test Set | Coal Type | Label |
|---|---|---|
| 40,320/17,280 | Coal type1 | 0 |
| 40,320/17,280 | Coal type2 | 1 |
| 40,320/17,280 | Coal type3 | 2 |
| 40,320/17,280 | Coal type4 | 3 |
| 40,320/17,280 | Coal type5 | 4 |
| Accuracy | BP | 1D-CNN | MIC-CNN |
|---|---|---|---|
| Training set | 78.17% | 88.54% | 98.23% |
| Test set | 68.65% | 78.38% | 94.02% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, S.; He, K.; Peng, X. Online Coal Identification Based on One-Dimensional Convolution and Its Industrial Applications. Appl. Sci. 2023, 13, 9867. https://doi.org/10.3390/app13179867
Ma S, He K, Peng X. Online Coal Identification Based on One-Dimensional Convolution and Its Industrial Applications. Applied Sciences. 2023; 13(17):9867. https://doi.org/10.3390/app13179867
Chicago/Turabian StyleMa, Shaochen, Kaixun He, and Xin Peng. 2023. "Online Coal Identification Based on One-Dimensional Convolution and Its Industrial Applications" Applied Sciences 13, no. 17: 9867. https://doi.org/10.3390/app13179867