
Accurate Segmentation of Tilapia Fish Body Parts Based on Deeplabv3+ for Advancing Phenotyping Applications

Abstract
:1. Introduction
- For the first time, a tilapia part image sample dataset was established, which can be used for accurate part segmentation of tilapia and can provide an effective basis for phenotypic measurement of tilapia.
- According to the morphological characteristics of tilapia, the Deeplabv3+ network structure is improved accordingly to increase the segmentation accuracy of the network as a whole.
- Great improvements in the issues of unclear segmentation of tilapia boundary regions, mis-segmentation of small objects in the presence of overlapping fish, and segmentation errors in complex backgrounds on the Deeplabv3+ tilapia part segmentation dataset.
2. Materials and Methods
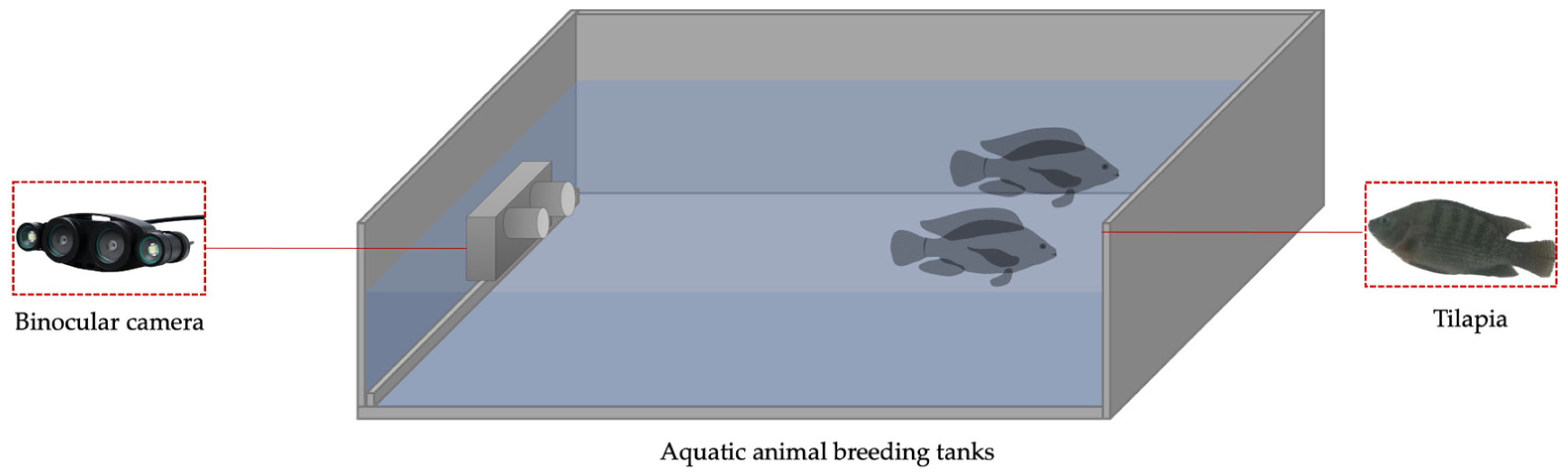
2.1. Data Acquisition
2.2. Research Program
2.2.1. Phenotype Classification-Oriented Segmentation Scheme
2.2.2. Experimental Process
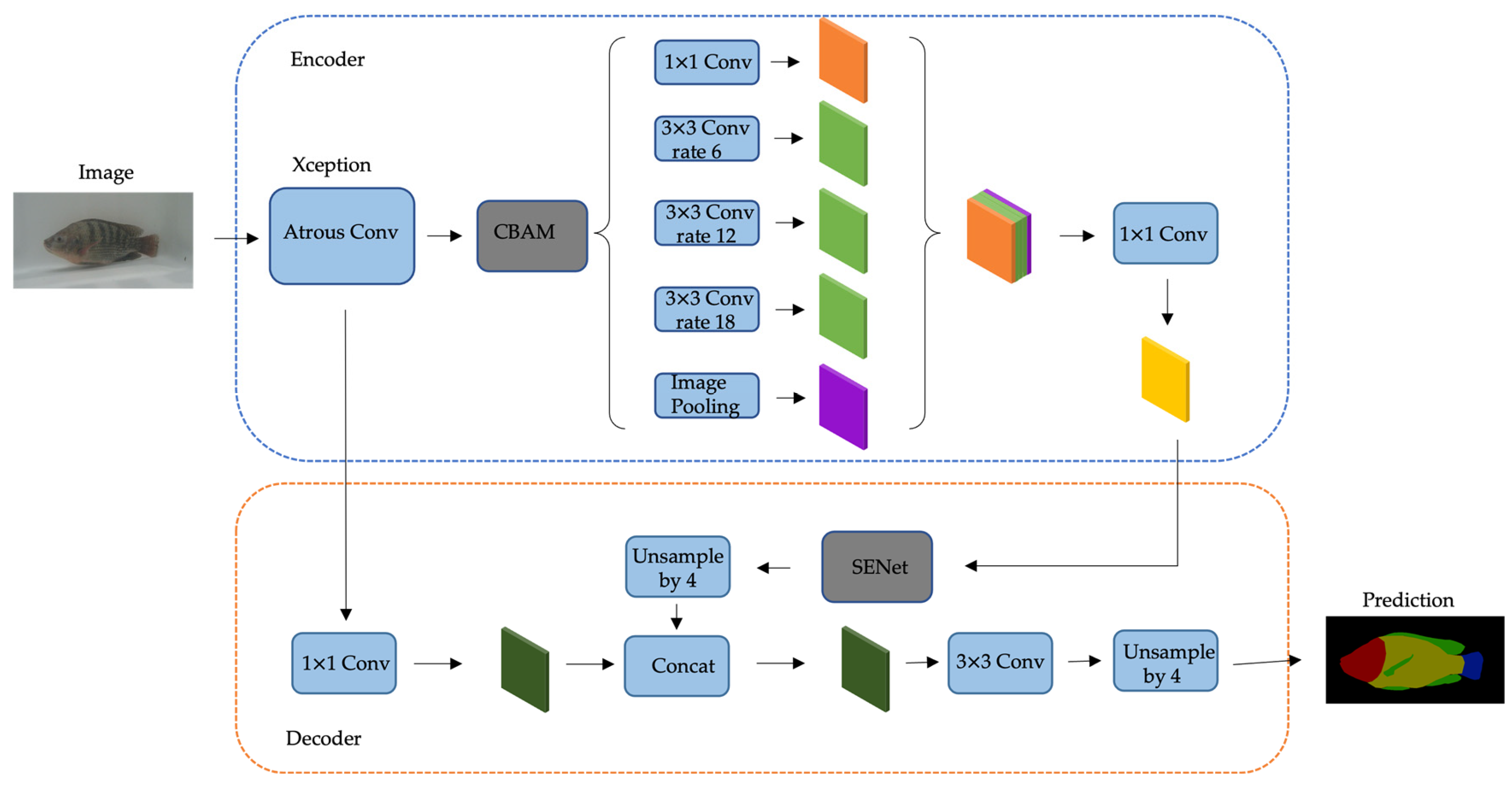
2.3. Improved Deeplabv3+ Network Architecture
2.3.1. CBAM Module
2.3.2. SENet Module
3. Experiment and Analysis
3.1. Experimental Environment
3.2. Evaluation Metrics
3.3. Experimental Parameter Setting
3.4. Network Training Results
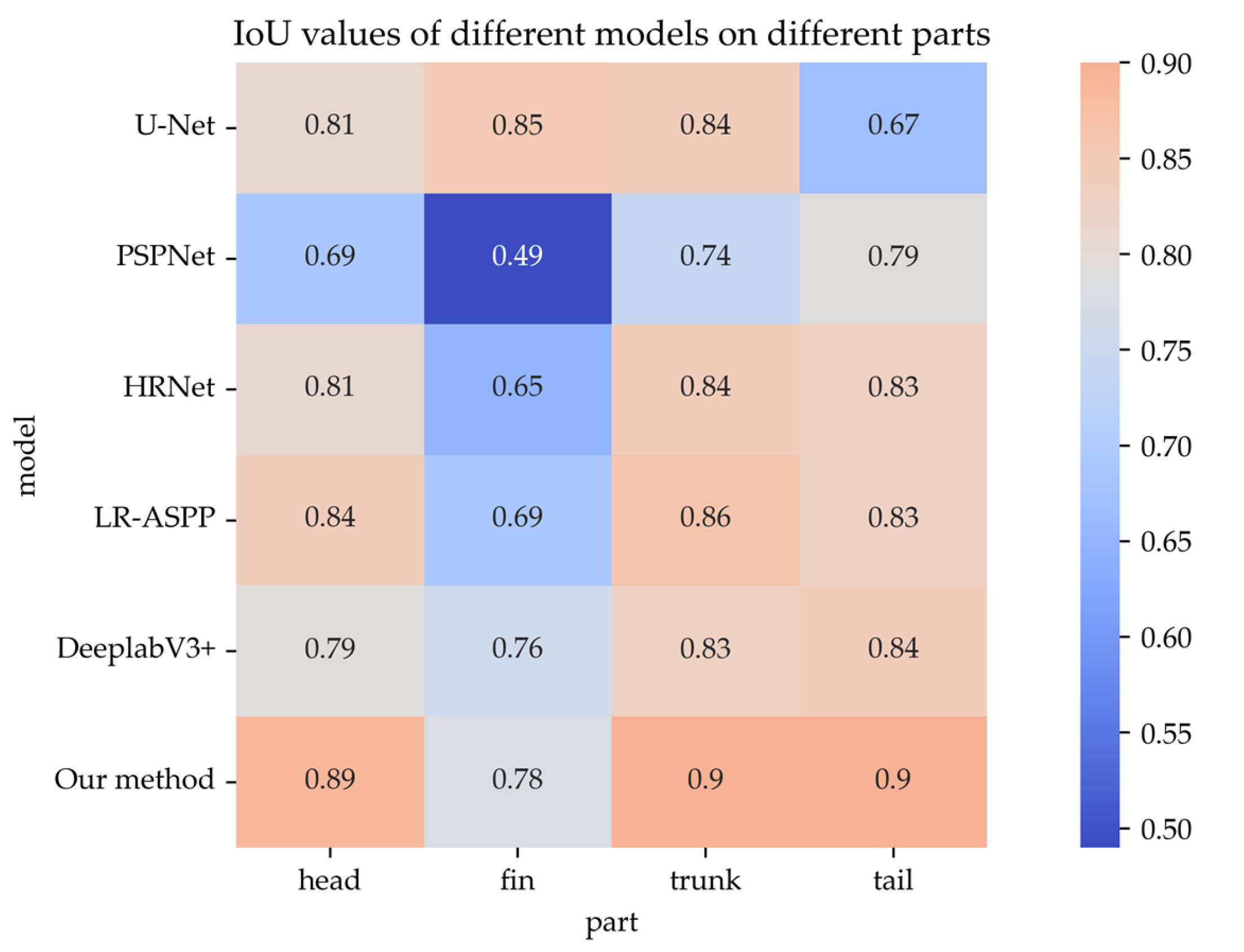
3.5. Comparative Analysis of Splitting Performance
3.6. Ablation Experiments
4. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xie, X.; Zhai, X.; Chen, M.; Li, Q.; Huang, Y.; Zhao, L.; Wang, Q.; Lin, L. Effects of Frozen Storage on Texture, Chemical Quality Indices and Sensory Properties of Crisp Nile Tilapia Fillets. Aquac. Fish. 2023, 8, 626–633. [Google Scholar] [CrossRef]
- Khammi, A.; Kutako, M.; Sangwichien, C.; Nootong, K. Development and Evaluation of Compact Aquaculture System for the Application of Zero Water-Exchange Inland Aquacultures. Eng. J. 2015, 19, 15–27. [Google Scholar] [CrossRef]
- Konovalov, D.A.; Saleh, A.; Domingos, J.A.; White, R.D.; Jerry, D.R. Estimating Mass of Harvested Asian Seabass Lates Calcarifer from Images. World J. Eng. Technol. 2018, 6, 15–23. [Google Scholar] [CrossRef]
- Deng, Y.; Tan, H.; Tong, M.; Zhou, D.; Li, Y.; Zhu, M. An Automatic Recognition Method for Fish Species and Length Using an Underwater Stereo Vision System. Fishes 2022, 7, 326. [Google Scholar] [CrossRef]
- Azarmdel, H.; Mohtasebi, S.S.; Jafari, A.; Rosado Muñoz, A. Developing an Orientation and Cutting Point Determination Algorithm for a Trout Fish Processing System Using Machine Vision. Comput. Electron. Agric. 2019, 162, 613–629. [Google Scholar] [CrossRef]
- Li, Y.; Huang, K.; Xiang, J. Measurement of Dynamic Fish Dimension Based on Stereoscopic Vision. Trans. CSAE 2020, 36, 220–226. [Google Scholar]
- Yu, C.; Fan, X.; Hu, Z.; Xia, X.; Zhao, Y.; Li, R.; Bai, Y. Segmentation and Measurement Scheme for Fish Morphological Features Based on Mask R-CNN. Inf. Process. Agric. 2020, 7, 523–534. [Google Scholar] [CrossRef]
- Garcia, R.; Prados, R.; Quintana, J.; Tempelaar, A.; Gracias, N.; Rosen, S.; Vågstøl, H.; Løvall, K. Automatic Segmentation of Fish Using Deep Learning with Application to Fish Size Measurement. ICES J. Mar. Sci. 2020, 77, 1354–1366. [Google Scholar] [CrossRef]
- Yu, X.; Wang, Y.; Liu, J.; Wang, J.; An, D.; Wei, Y. Non-Contact Weight Estimation System for Fish Based on Instance Segmentation. Expert Syst. Appl. 2022, 210, 118403. [Google Scholar] [CrossRef]
- Liu, B.; Wang, K.; Li, X.; Hu, C. Motion Posture Parsing of Chiloscyllium Plagiosum Fish Body Based on Semantic Part Segmentation. Trans. CSAE 2021, 37, 179–187. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Liu, F.; Fang, M. Semantic Segmentation of Underwater Images Based on Improved Deeplab. J. Mar. Sci. Eng. 2020, 8, 188. [Google Scholar] [CrossRef]
- Zeng, H.; Peng, S.; Li, D. Deeplabv3+ Semantic Segmentation Model Based on Feature Cross Attention Mechanism. J. Phys. Conf. Ser. 2020, 1678, 012106. [Google Scholar] [CrossRef]
- Peng, H.; Xue, C.; Shao, Y.; Chen, K.; Xiong, J.; Xie, Z.; Zhang, L. Semantic Segmentation of Litchi Branches Using DeepLabV3+ Model. IEEE Access 2020, 8, 164546–164555. [Google Scholar] [CrossRef]
- Atik, S.O.; Atik, M.E.; Ipbuker, C. Comparative research on different backbone architectures of DeepLabV3+ for building segmentation. J. Appl. Remote Sens. 2022, 16, 024510. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. ISBN 978-3-319-24573-7. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Qian, Y.-C.; Wang, X.; Ren, J.; Wang, J.; Limbu, S.M.; Li, R.-X.; Zhou, W.-H.; Qiao, F.; Zhang, M.-L.; Du, Z.-Y. Different Effects of Two Dietary Levels of Tea Polyphenols on the Lipid Deposition, Immunity and Antioxidant Capacity of Juvenile GIFT Tilapia (Oreochromis Niloticus) Fed a High-Fat Diet. Aquaculture 2021, 542, 736896. [Google Scholar] [CrossRef]
- Fernandes, A.F.A.; Turra, E.M.; De Alvarenga, É.R.; Passafaro, T.L.; Lopes, F.B.; Alves, G.F.O.; Singh, V.; Rosa, G.J.M. Deep Learning Image Segmentation for Extraction of Fish Body Measurements and Prediction of Body Weight and Carcass Traits in Nile Tilapia. Comput. Electron. Agric. 2020, 170, 105274. [Google Scholar] [CrossRef]
- Zhu, J.; Shen, X.; Zhou, Y.; Tan, Y.; Gan, X. Growth Performance Evaluation and Correlation Analysis on Phenotypic Traits of GIFT Tilapia. J. Northwest A F Univ. Nat. Sci. Ed. 2014, 42, 24–28. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Li, X.; Sun, X.; Meng, Y.; Liang, J.; Wu, F.; Li, J. Dice Loss for Data-Imbalanced NLP Tasks. arXiv 2019, arXiv:1911.02855. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | IoU (%) | ||||
|---|---|---|---|---|---|
| Background | Head | Fin | Trunk | Tail | |
| PSPNet | 98.14 | 68.89 | 49.26 | 79.19 | 74.45 |
| U-Net | 98.90 | 80.67 | 84.70 | 65.63 | 83.65 |
| HRNet | 98.98 | 81.04 | 65.27 | 84.12 | 82.77 |
| LR-ASPP | 98.82 | 84.00 | 69.37 | 86.39 | 83.39 |
| Deeplabv3+ | 99.18 | 79.05 | 75.70 | 83.59 | 83.48 |
| Our method | 99.09 | 88.83 | 77.97 | 89.66 | 90.06 |
| Model | mIoU (%) | mPA (%) | mRecall (%) |
|---|---|---|---|
| PSPNet | 73.99 | 83.88 | 84.60 |
| U-Net | 82.71 | 90.31 | 89.68 |
| HRNet | 82.44 | 89.83 | 89.34 |
| LR-ASPP | 84.39 | 91.23 | 91.22 |
| Deeplabv3+ | 88.46 | 93.98 | 89.67 |
| Our method | 91.69 | 95.94 | 94.21 |
| Model | mIoU (%) | mPA (%) |
|---|---|---|
| Deeplabv3+ + ResNet-50 | 67.54 | 84.11 |
| Deeplabv3+ + MobileNetv3 | 72.26 | 86.07 |
| Deeplabv3+ + Swin Transformer | 75.71 | 84.99 |
| Deeplabv3+ + Xception | 88.46 | 93.98 |
| Deeplabv3+ + Xception+ CBAM+ SENet | 91.69 | 95.94 |
| Model | SENet | CBAM | mIoU (%) | mPA (%) |
|---|---|---|---|---|
| Deeplabv3+ | 88.46 | 93.98 | ||
| ✓ | 89.08 | 94.21 | ||
| ✓ | 89.11 | 94.08 | ||
| ✓ | ✓ | 91.69 | 95.94 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, G.; Wang, H.; Chen, M.; Liu, Z. Accurate Segmentation of Tilapia Fish Body Parts Based on Deeplabv3+ for Advancing Phenotyping Applications. Appl. Sci. 2023, 13, 9635. https://doi.org/10.3390/app13179635
Feng G, Wang H, Chen M, Liu Z. Accurate Segmentation of Tilapia Fish Body Parts Based on Deeplabv3+ for Advancing Phenotyping Applications. Applied Sciences. 2023; 13(17):9635. https://doi.org/10.3390/app13179635
Chicago/Turabian StyleFeng, Guofu, Hao Wang, Ming Chen, and Zhixiang Liu. 2023. "Accurate Segmentation of Tilapia Fish Body Parts Based on Deeplabv3+ for Advancing Phenotyping Applications" Applied Sciences 13, no. 17: 9635. https://doi.org/10.3390/app13179635