
GCARe: Mitigating Subgroup Unfairness in Graph Condensation through Adversarial Regularization


Abstract
:1. Introduction
- 1.
- We provide broad empirical evaluations, which reveal that performance disparities between advantaged and disadvantaged subgroups become more pronounced for GNNs that are trained on condensed graphs.
- 2.
- We introduce GCARe, an innovative paradigm that leverages adversarial learning to debias the condensation model, thereby achieving fair graph condensation. Notably, our proposed method maintains the same level of complexity as existing condensation techniques, and it can be implemented as a regularization term that is easy to plug and play.
- 3.
- Our comprehensive experiments demonstrate that GCARe not only mitigates fairness issues, but also enhances the overall performance of condensed graphs. For example, when applied to the Recidivism dataset, GCARe reduces the value from to , as well as the value from to , while simultaneously increasing the accuracy from to .
2. Related Work
2.1. Dataset Condensation
2.2. GNN Fairness
3. Background
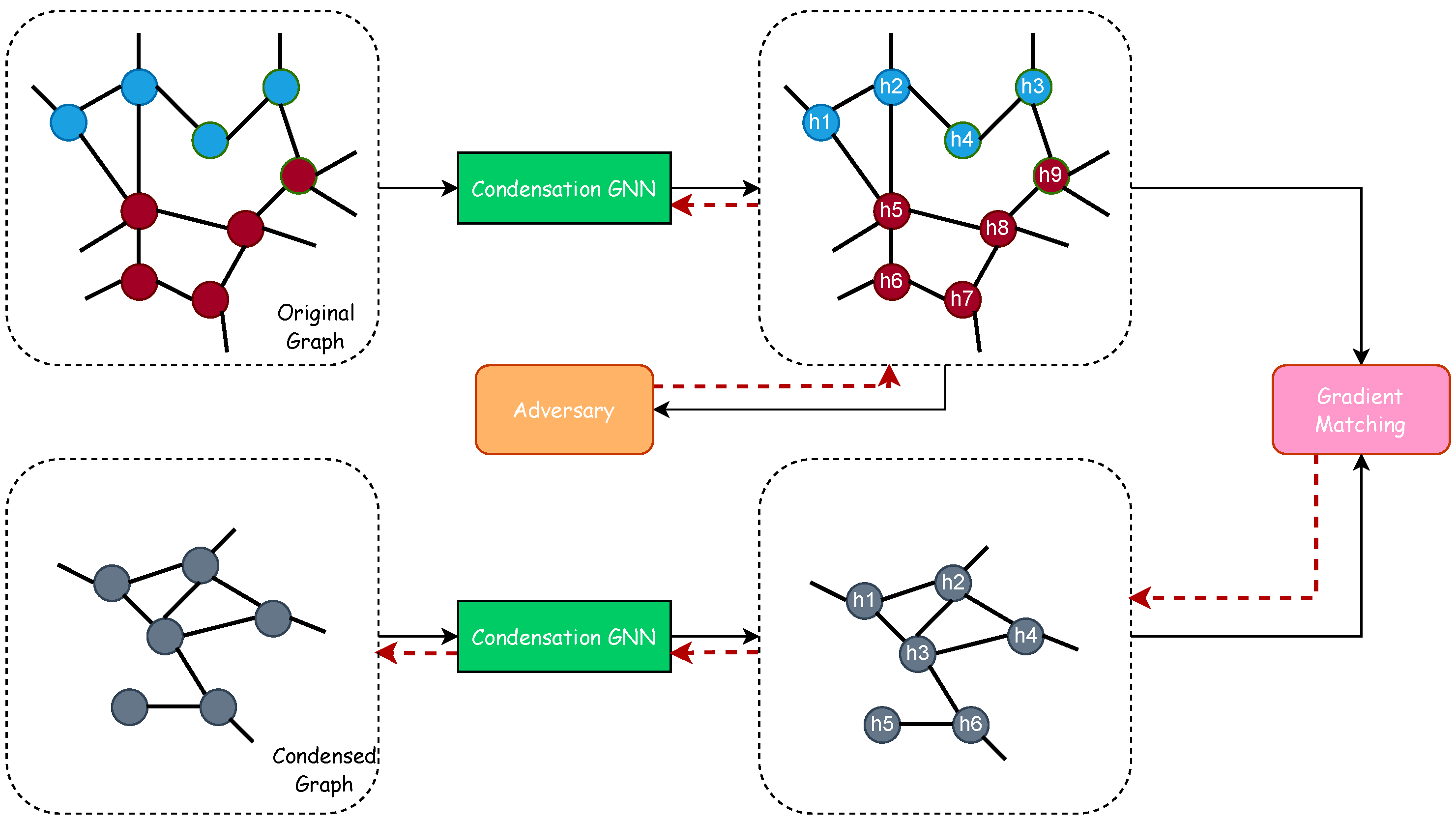
Graph Condensation via Gradient Matching
4. Graph Condensation with Adversarial Regularization
5. Experiments
5.1. Experiment Settings
5.1.1. Datasets
5.1.2. Subgroup Division Evaluation Metrics
5.1.3. Baselines
5.1.4. Hyperparameters
5.2. Main Results and Analysis
5.2.1. Fairness
5.2.2. Node Classification
5.3. Cross Architecture Generalization
6. Conclusions
Limitations and Broader Impact
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Duvenaud, D.K.; Maclaurin, D.; Iparraguirre, J.; Bombarell, R.; Hirzel, T.; Aspuru-Guzik, A.; Adams, R.P. Convolutional Networks on Graphs for Learning Molecular Fingerprints. In Proceedings of the 29th Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Fan, W.; Ma, Y.; Li, Q.; He, Y.; Zhao, E.; Tang, J.; Yin, D. Graph Neural Networks for Social Recommendation. In Proceedings of the World Wide Web Conference, Las Vegas, NV, USA, 29 July–1 August 2019; pp. 417–426. [Google Scholar]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A Comprehensive Survey on Graph Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4–24. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ying, R.; He, R.; Chen, K.; Eksombatchai, P.; Hamilton, W.L.; Leskovec, J. Graph Convolutional Neural Networks for Web-Scale Recommender Systems. In Proceedings of the 24th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Association for Computing Machinery, London, UK, 19–23 August 2018; pp. 974–983. [Google Scholar]
- You, J.; Liu, B.; Ying, R.; Pande, V.; Leskovec, J. Graph Convolutional Policy Network for Goal-Directed Molecular Graph Generation. In Proceedings of the 32nd Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 6412–6422. [Google Scholar]
- Patterson, D.; Gonzalez, J.; Hölzle, U.; Le, Q.; Liang, C.; Munguia, L.M.; Rothchild, D.; So, D.R.; Texier, M.; Dean, J. The Carbon Footprint of Machine Learning Training Will Plateau, Then Shrink. Computer 2022, 55, 18–28. [Google Scholar] [CrossRef]
- Zoph, B.; Le, Q. Neural Architecture Search with Reinforcement Learning. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- He, X.; Deng, K.; Wang, X.; Li, Y.; Zhang, Y.; Wang, M. LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 25–30 July 2020; pp. 639–648. [Google Scholar]
- Wu, F.; Souza, A.; Zhang, T.; Fifty, C.; Yu, T.; Weinberger, K. Simplifying Graph Convolutional Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 6861–6871. [Google Scholar]
- Jin, W.; Tang, X.; Jiang, H.; Li, Z.; Zhang, D.; Tang, J.; Yin, B. Condensing graphs via one-step gradient matching. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 720–730. [Google Scholar]
- Jin, W.; Zhao, L.; Zhang, S.; Liu, Y.; Tang, J.; Shah, N. Graph Condensation for Graph Neural Networks. In Proceedings of the 10th International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Hu, W.; Fey, M.; Zitnik, M.; Dong, Y.; Ren, H.; Liu, B.; Catasta, M.; Leskovec, J. Open Graph Benchmark: Datasets for Machine Learning on Graphs. In Proceedings of the 34th Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Rebuffi, S.A.; Kolesnikov, A.; Sperl, G.; Lampert, C.H. iCaRL: Incremental Classifier and Representation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5533–5542. [Google Scholar]
- Zhao, B.; Mopuri, K.R.; Bilen, H. Dataset Condensation with Gradient Matching. In Proceedings of the 9th International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Ling, H.; Jiang, Z.; Luo, Y.; Ji, S.; Zou, N. Learning Fair Graph Representations via Automated Data Augmentations. In Proceedings of the 11th International Conference on Learning Representations, Kobe, Japan, 2–7 April 2023. [Google Scholar]
- Wang, R.; Wang, X.; Shi, C.; Song, L. Uncovering the Structural Fairness in Graph Contrastive Learning. In Proceedings of the 36th Conference on Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Wang, X.; Wu, Z.; Lian, L.; Yu, S.X. Debiased Learning From Naturally Imbalanced Pseudo-Labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 14647–14657. [Google Scholar]
- Wang, T.; Zhu, J.; Torralba, A.; Efros, A.A. Dataset Distillation. arXiv 2018, arXiv:1811.10959. [Google Scholar]
- Esipova, M.S.; Ghomi, A.A.; Luo, Y.; Cresswell, J.C. Disparate Impact in Differential Privacy from Gradient Misalignment. In Proceedings of the 11th International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Koh, P.W.; Sagawa, S.; Marklund, H.; Xie, S.M.; Zhang, M.; Balsubramani, A.; Hu, W.; Yasunaga, M.; Phillips, R.L.; Gao, I.; et al. WILDS: A Benchmark of in-the-Wild Distribution Shifts. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; Volume 139, pp. 5637–5664. [Google Scholar]
- Zhu, Z.; Luo, T.; Liu, Y. The Rich Get Richer: Disparate Impact of Semi-Supervised Learning. In Proceedings of the 10th International Conference on Learning Representations, Virtually, 25–29 April 2022. [Google Scholar]
- Piratla, V.; Netrapalli, P.; Sarawagi, S. Focus on the Common Good: Group Distributional Robustness Follows. In Proceedings of the 10th International Conference on Learning Representations, Virtually, 25–29 April 2022. [Google Scholar]
- Tang, X.; Yao, H.; Sun, Y.; Wang, Y.; Tang, J.; Aggarwal, C.; Mitra, P.; Wang, S. Investigating and Mitigating Degree-Related Biases in Graph Convoltuional Networks. In Proceedings of the 29th ACM International Conference on Information and Knowledge Management, Online, 23 October 2020; pp. 1435–1444. [Google Scholar]
- Dai, E.; Wang, S. Say No to the Discrimination: Learning Fair Graph Neural Networks with Limited Sensitive Attribute Information. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, Virtual, 8–12 March 2021; pp. 680–688. [Google Scholar]
- Spinelli, I.; Scardapane, S.; Hussain, A.; Uncini, A. FairDrop: Biased Edge Dropout for Enhancing Fairness in Graph Representation Learning. IEEE Trans. Artif. Intell. 2021, 3, 344–354. [Google Scholar] [CrossRef]
- Dai, E.; Zhao, T.; Zhu, H.; Xu, J.; Guo, Z.; Liu, H.; Tang, J.; Wang, S. A Comprehensive Survey on Trustworthy Graph Neural Networks: Privacy, Robustness, Fairness, and Explainability. arXiv 2022, arXiv:2204.08570. [Google Scholar]
- Fan, W.; Zhao, X.; Chen, X.; Su, J.; Gao, J.; Wang, L.; Liu, Q.; Wang, Y.; Xu, H.; Chen, L.; et al. A Comprehensive Survey on Trustworthy Recommender Systems. arXiv 2022, arXiv:2209.10117. [Google Scholar]
- Qiu, J.; Chen, Q.; Dong, Y.; Zhang, J.; Yang, H.; Ding, M.; Wang, K.; Tang, J. GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training. In Proceedings of the 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual, 6–10 July 2020; pp. 1150–1160. [Google Scholar]
- Kojaku, S.; Yoon, J.; Constantino, I.; Ahn, Y.Y. Residual2Vec: Debiasing graph embedding with random graphs. In Proceedings of the 35th Conference on Neural Information Processing Systems, Online, 6–14 December 2021. [Google Scholar]
- Ma, J.; Guo, R.; Wan, M.; Yang, L.; Zhang, A.; Li, J. Learning Fair Node Representations with Graph Counterfactual Fairness. In Proceedings of the 15th ACM International Conference on Web Search and Data Mining, Virtual, 21–25 February 2022; pp. 695–703. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the 28th Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; March, M.; Lempitsky, V. Domain-Adversarial Training of Neural Networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Agarwal, C.; Lakkaraju, H.; Zitnik, M. Towards a Unified Framework for Fair and Stable Graph Representation Learning. In Proceedings of the 37th Conference on Uncertainty in Artificial Intelligence, Online, 27–30 July 2021. [Google Scholar]
- Menon, A.K.; Williamson, R.C. The Cost of Fairness in Binary Classification. In Proceedings of the 1st Conference on Fairness, Accountability and Transparency, New York, NY, USA, 23–24 February 2018; pp. 107–118. [Google Scholar]
- Dutta, S.; Wei, D.; Yueksel, H.; Chen, P.Y.; Liu, S.; Varshney, K. Is There a Trade-Off between Fairness and Accuracy? A Perspective Using Mismatched Hypothesis Testing. In Proceedings of the 37th International Conference on Machine Learning, Virtual, 13–18 July 2020; Volume 119, pp. 2803–2813. [Google Scholar]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive Representation Learning on Large Graphs. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Gasteiger, J.; Bojchevski, A.; Günnemann, S. Combining Neural Networks with Personalized PageRank for Classification on Graphs. In Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering. In Proceedings of the 30th Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]



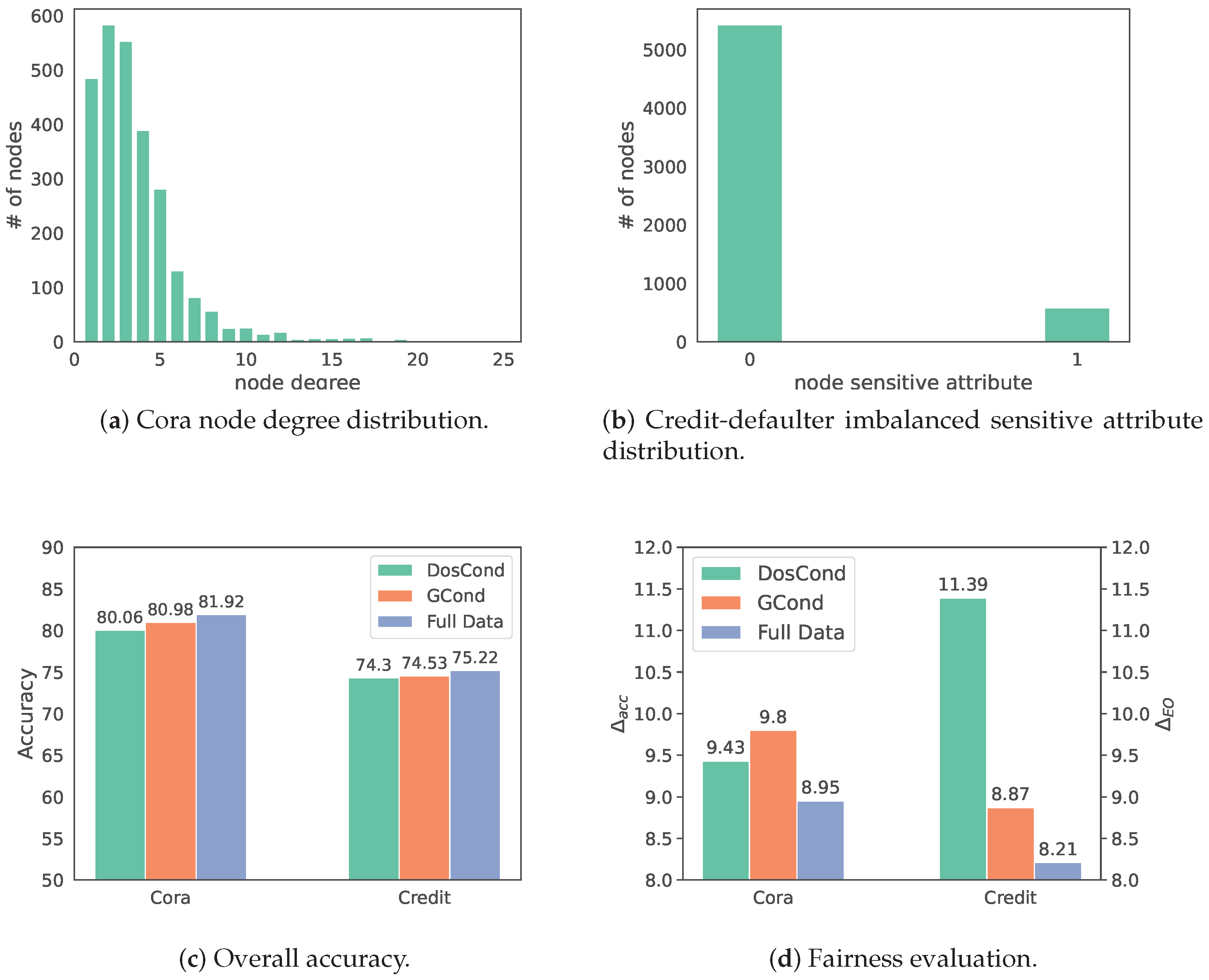{kind=link}
{kind=link}
| Dataset | #Nodes | #Edges | #Classes | #Features | Train/Valid/Test |
|---|---|---|---|---|---|
| Cora | 2708 | 5429 | 7 | 1433 | 140/500/1000 |
| Ogbn-arxiv | 169,343 | 1,166,243 | 40 | 128 | 90,941/29,799/48,603 |
| Credit-defaulter | 30,000 | 2,873,716 | 2 | 13 | 6000/7500/7500 |
| Recidivism | 18,876 | 642,616 | 2 | 18 | 1000/4719/4719 |
| Dataset | Metric | GCond | +SP | +Ours | DosCond | +SP | +Ours | Whole Dataset |
|---|---|---|---|---|---|---|---|---|
| Cora | 80.98 | 80.80 | 81.03 | 80.06 | 80.25 | 80.32 | 81.92 | |
| 9.80 | 9.83 | 9.56 | 9.43 | 9.31 | 9.07 | 8.95 | ||
| 4.50 | 4.41 | 4.28 | 4.18 | 4.14 | 4.15 | 3.96 | ||
| Ogbn-arxiv | 59.23 | 58.89 | 59.37 | 58.61 | 58.08 | 57.81 | 71.21 | |
| 31.36 | 30.75 | 30.22 | 31.79 | 30.53 | 29.85 | 22.04 | ||
| 10.98 | 10.75 | 10.71 | 11.15 | 10.63 | 10.35 | 7.57 | ||
| Credit-defaulter | 74.53 | 74.60 | 74.37 | 74.30 | 74.66 | 74.96 | 75.22 | |
| 11.21 | 11.20 | 10.98 | 13.99 | 10.10 | 10.90 | 10.23 | ||
| 8.87 | 8.91 | 8.74 | 11.39 | 8.15 | 8.82 | 8.21 | ||
| Recidivism | 80.04 | 82.43 | 81.97 | 80.08 | 80.88 | 81.16 | 81.01 | |
| 4.47 | 4.46 | 3.98 | 4.76 | 4.90 | 4.68 | 3.59 | ||
| 3.40 | 2.76 | 2.52 | 3.45 | 3.61 | 3.43 | 1.21 |
| Method | Metric | GCN | GraphSage | SGC | MLP | APPNP | Cheby |
|---|---|---|---|---|---|---|---|
| DosCond | 74.30 | 74.73 | 74.63 | 74.64 | 75.11 | 77.77 | |
| 13.99 | 10.35 | 14.69 | 11.65 | 15.11 | 11.60 | ||
| 11.39 | 8.34 | 12.00 | 9.61 | 12.65 | 8.51 | ||
| GCARe | 74.96 | 73.97 | 75.82 | 75.01 | 75.56 | 78.12 | |
| 10.90 | 7.47 | 14.76 | 8.70 | 13.11 | 6.54 | ||
| 8.82 | 5.99 | 11.83 | 6.79 | 10.48 | 4.37 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mao, R.; Fan, W.; Li, Q. GCARe: Mitigating Subgroup Unfairness in Graph Condensation through Adversarial Regularization. Appl. Sci. 2023, 13, 9166. https://doi.org/10.3390/app13169166
Mao R, Fan W, Li Q. GCARe: Mitigating Subgroup Unfairness in Graph Condensation through Adversarial Regularization. Applied Sciences. 2023; 13(16):9166. https://doi.org/10.3390/app13169166
Chicago/Turabian StyleMao, Runze, Wenqi Fan, and Qing Li. 2023. "GCARe: Mitigating Subgroup Unfairness in Graph Condensation through Adversarial Regularization" Applied Sciences 13, no. 16: 9166. https://doi.org/10.3390/app13169166