
Lightweight Facial Expression Recognition Based on Class-Rebalancing Fusion Cumulative Learning
Abstract
:1. Introduction
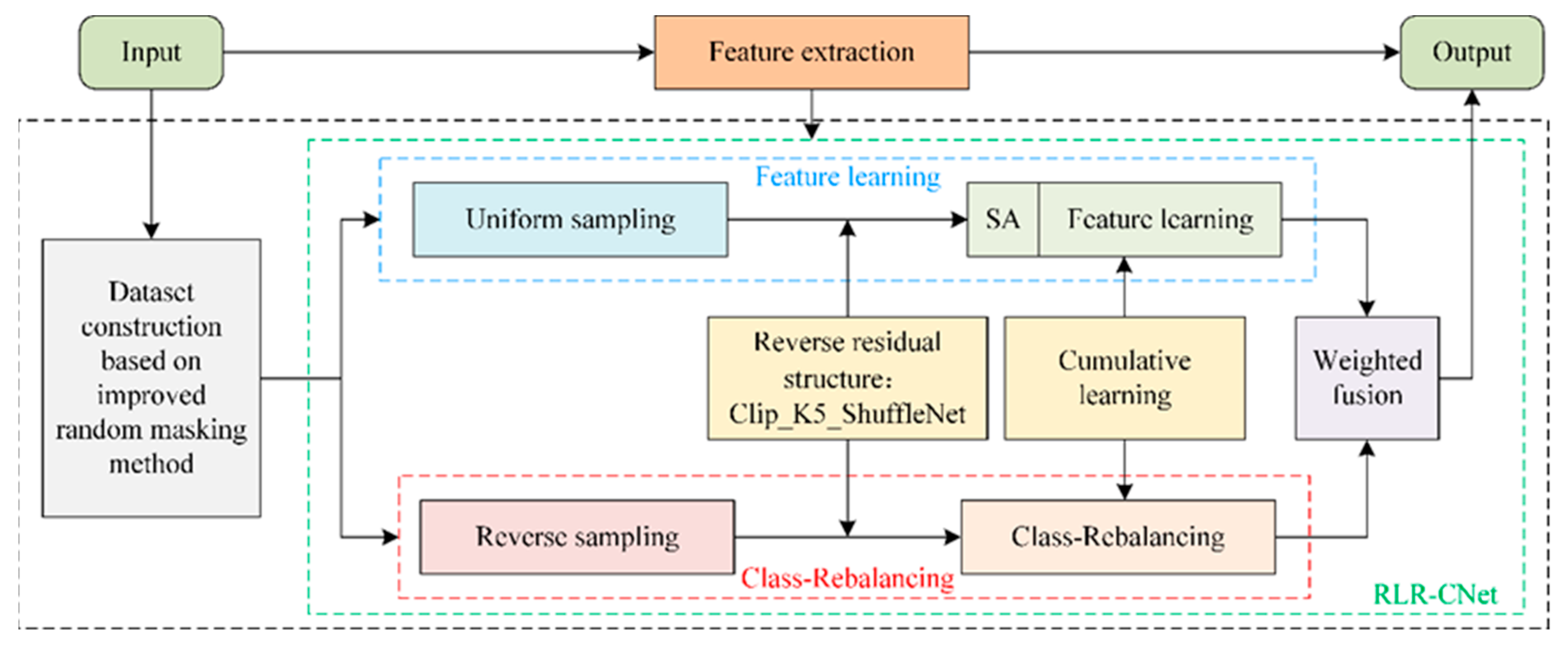
- To resolve the issue of the uneven inter-class distribution of facial expression data, a dual-branch network (RLR-CNet) is designed in our paper.
- To alleviate the issue of easily losing feature information and to cut down on the number of parameters of the RLR-CNet, a lighter Clip_K5_ShuffleNet inverted residual structure is proposed in the RLR-CNet.
- To facilitate the transfer of facial expression feature information and promote the generalization ability of the RLR-CNet, the β-Mish activation function and the improved random masking method are used in the RLR-CNet, respectively.
- To extract facial expressions’ local key features and further enhance the accuracy of FER without significantly increasing computational complexity, a shuffle attention (SA) module is embedded into the RLR-CNet, which integrates spatial and channel attention.
2. Related Work
2.1. FER in Real-World
2.2. FER Based on Lightweight Network
3. Models and Methods
3.1. Dataset Construction Based on Improved Random Masking Method
3.2. Design a Clip_K5_ ShuffleNet Inverted Residual Structure
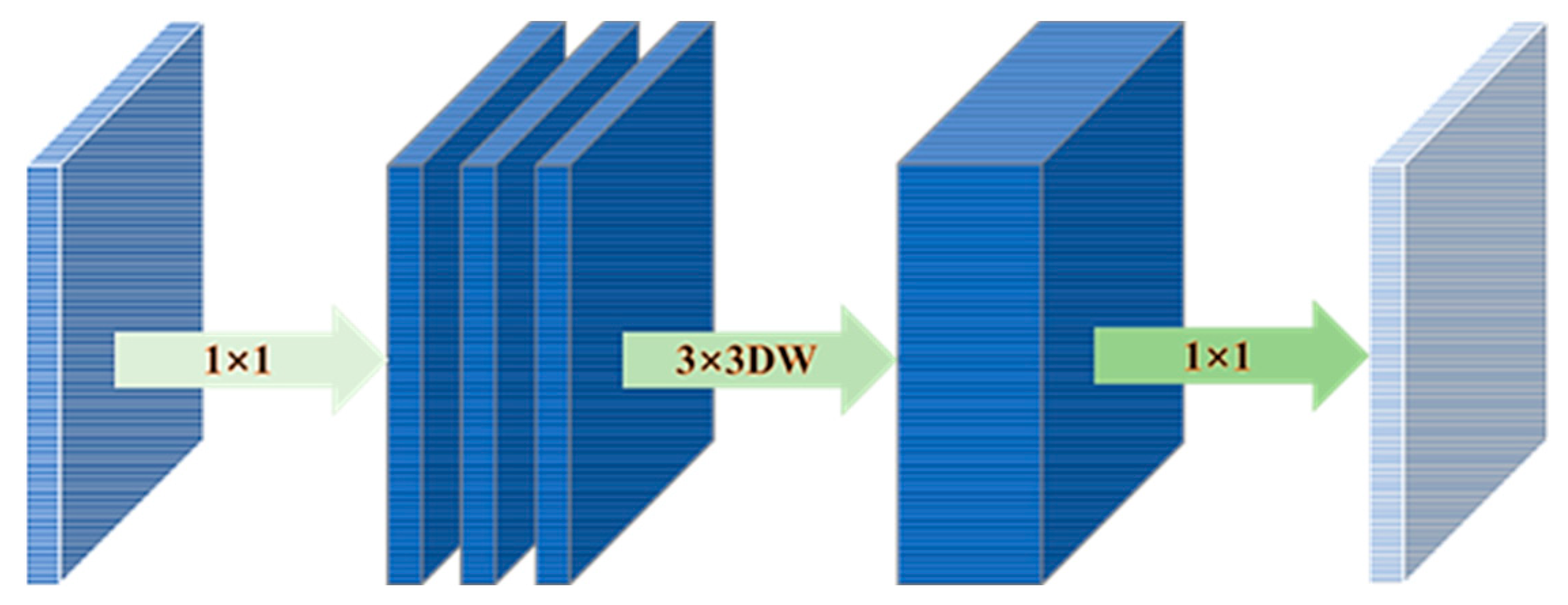
3.2.1. Inverted Residual Structure
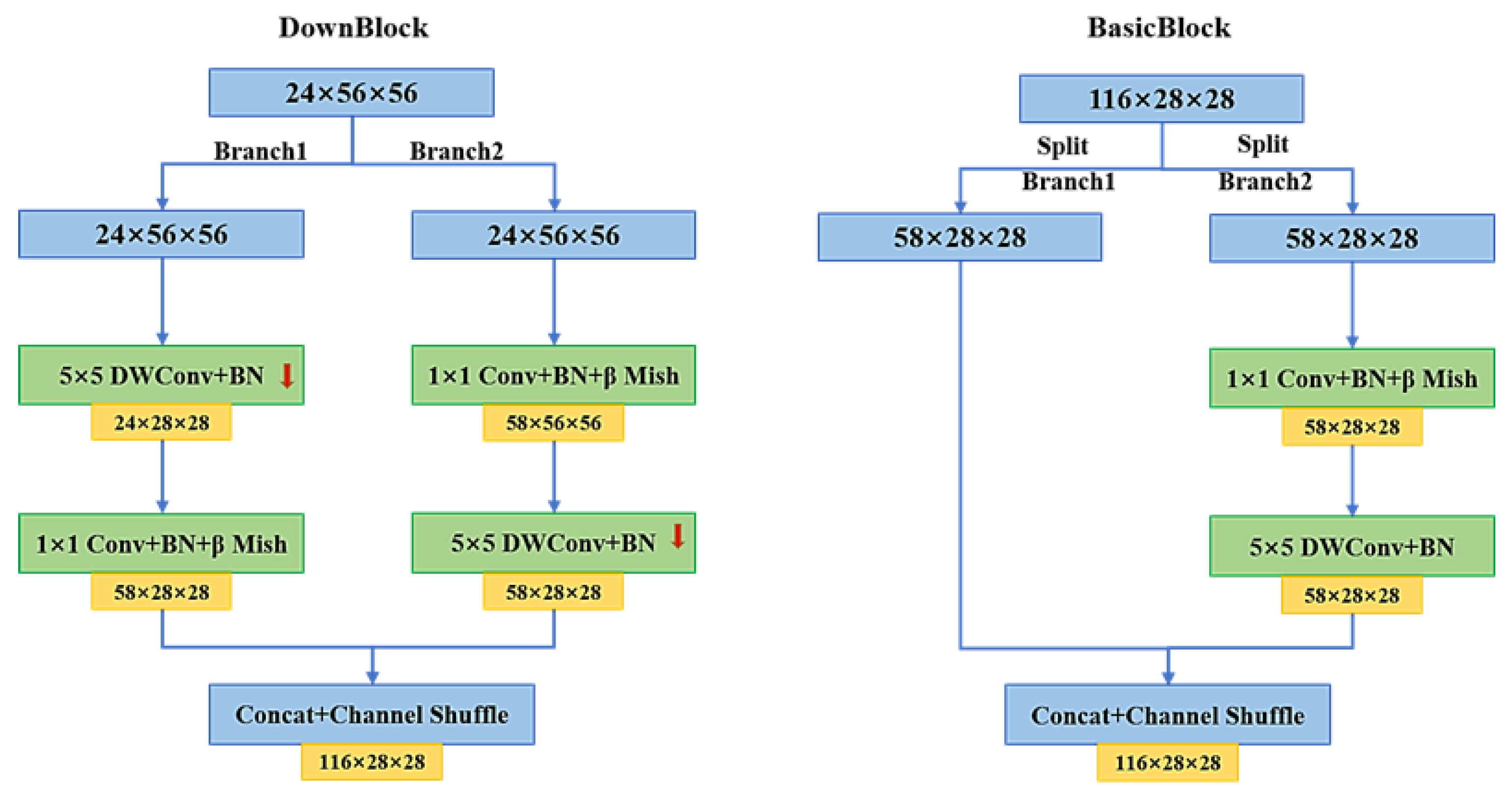
3.2.2. Improved ShuffleNet_Block
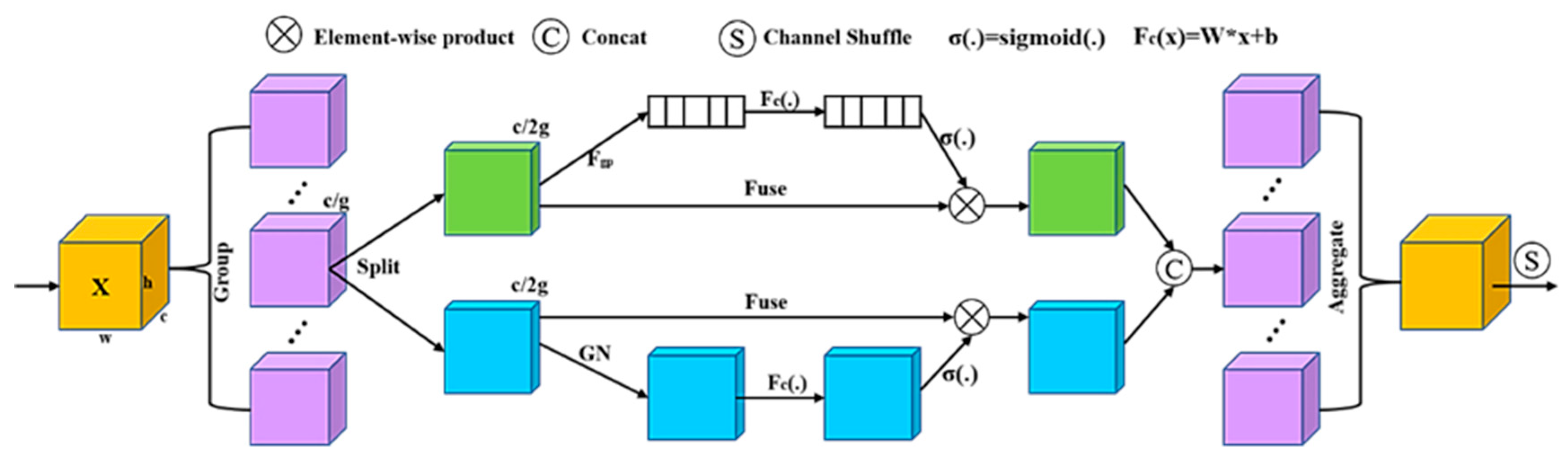
3.3. Shuffle Attention Module (SA)
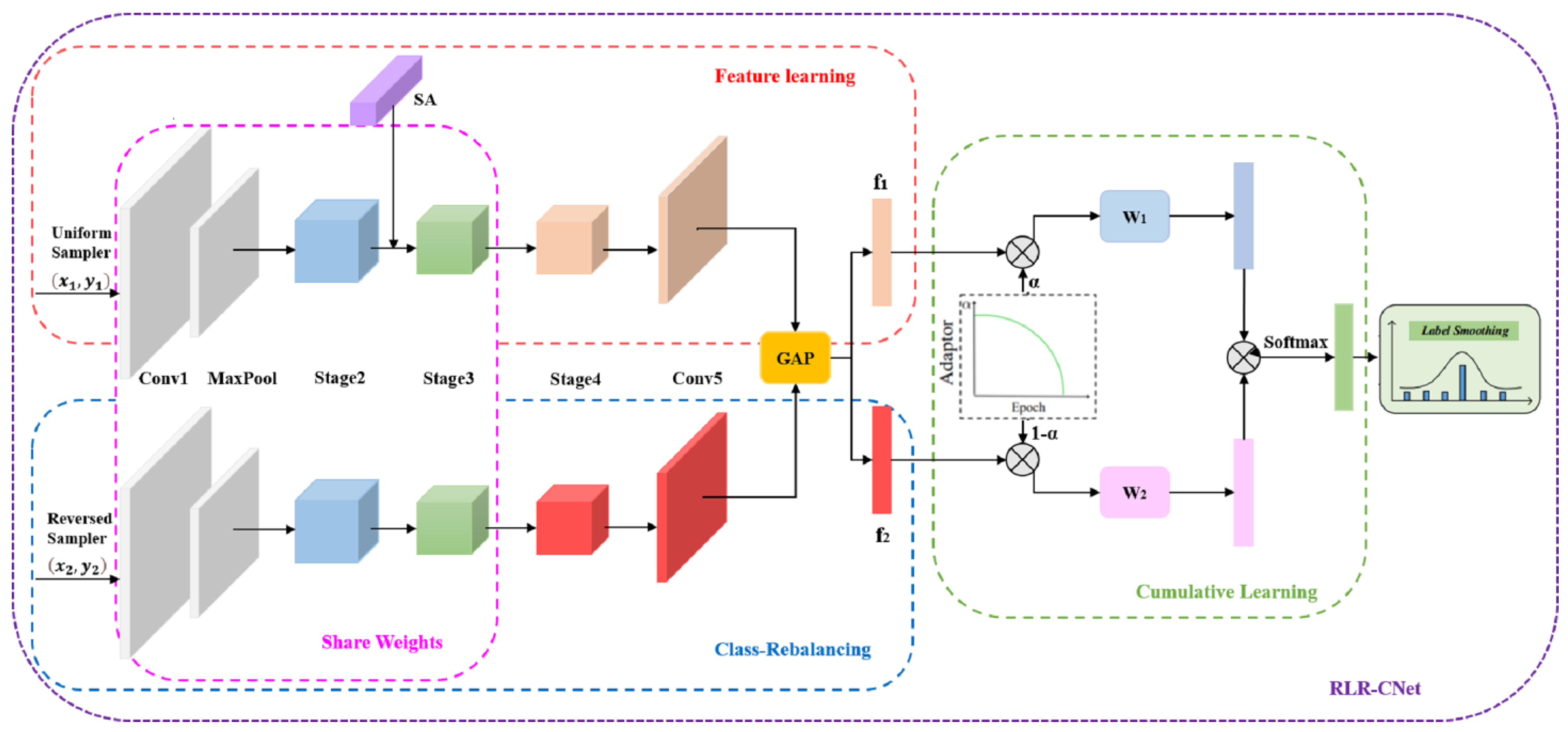
3.4. The Dual-Branch Network (RLR-CNet)
- The improved Clip_K5_ShuffleNet module is used in the whole of the dual-branch in this paper. Among them, the clipping of the 1 × 1 convolution reduces the model’s parameters, and the use of 5 × 5 DW convolution is beneficial for extracting global features. Pairing the β-Mish activation function in each block enhances the flow of feature information. Moreover, in order to obtain the expressions’ key features to ensure the validity of feature information, this paper incorporates the lightweight SA module in the feature learning branch but, in order not to add too many additional parameters as much as possible, only embeds the SA module between Stage 2 and Stage 3. These designs enable the model to promote the accuracy of recognition and classification while ensuring light weight.
- Weight sharing in the dual-branch network: The two branches share the weights of the network before Stage 4. On the one hand, the good learning of the feature learning branch is conducive to the learning of the class-rebalancing branch; on the other hand, the shared weights greatly reduce the computational complexity of the network and the speed of the model training, which in turn improves the recognition efficiency of the network.
- The dual-branch network that combines cumulative learning: Parameter is set to control the weights and loss functions for the two branches, and realize the transfer of learning “attention” between two branches. In this way, the influence of class-rebalancing on feature learning is eliminated, the recognition accuracy of small sample size classes is enhanced, and the recognition accuracy of the network is comprehensively improved. Where parameter is adaptively adjusted according to the number of iterations for training, indirectly determined by the total training time of the network and the current training time , the formula is as follows:
4. Experiment and Analysis
4.1. Experimental Preparation and Evaluation Indicators
4.1.1. Experimental Preparation
4.1.2. Evaluation Indicators
4.1.3. Experimental Datasets
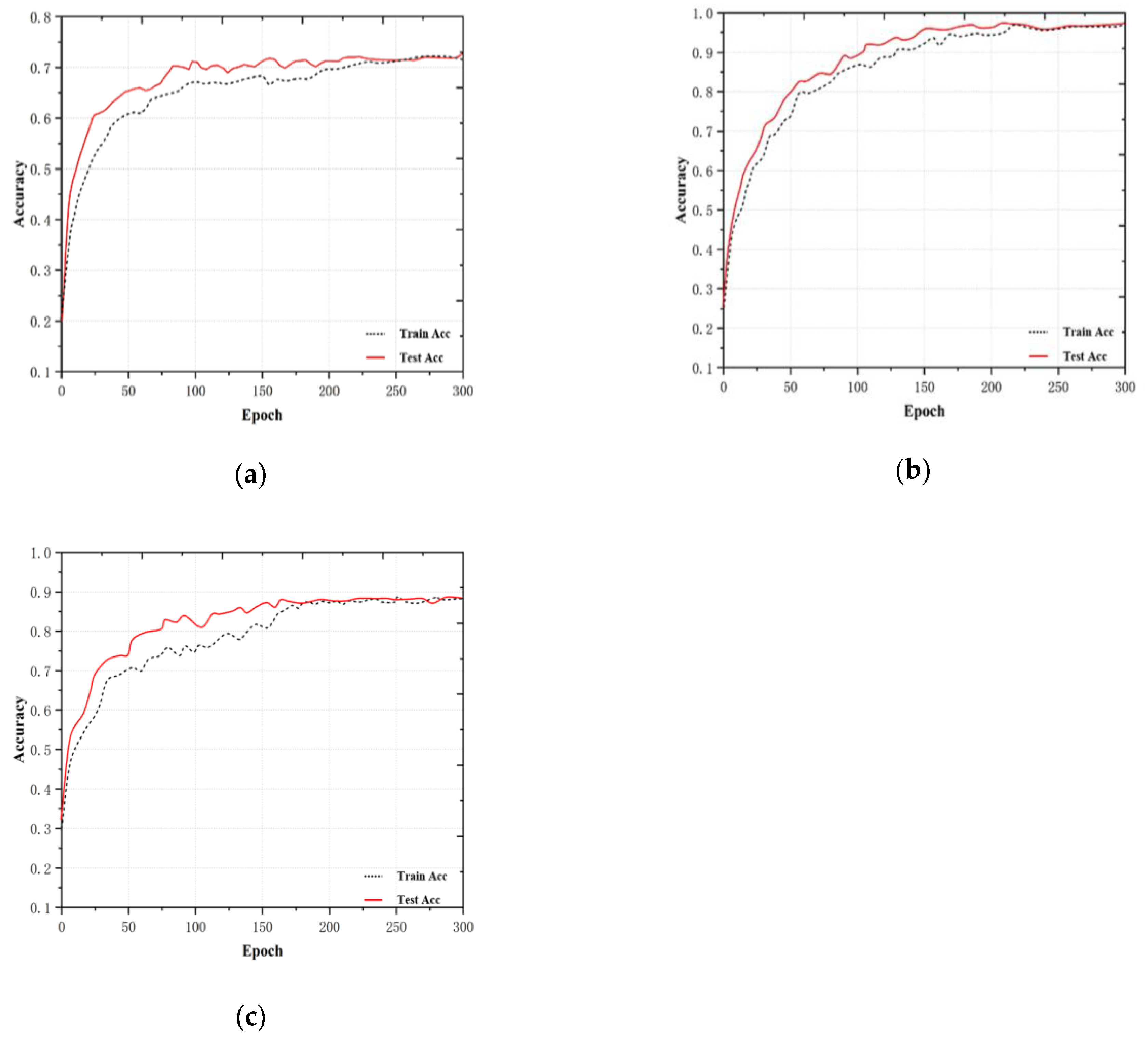
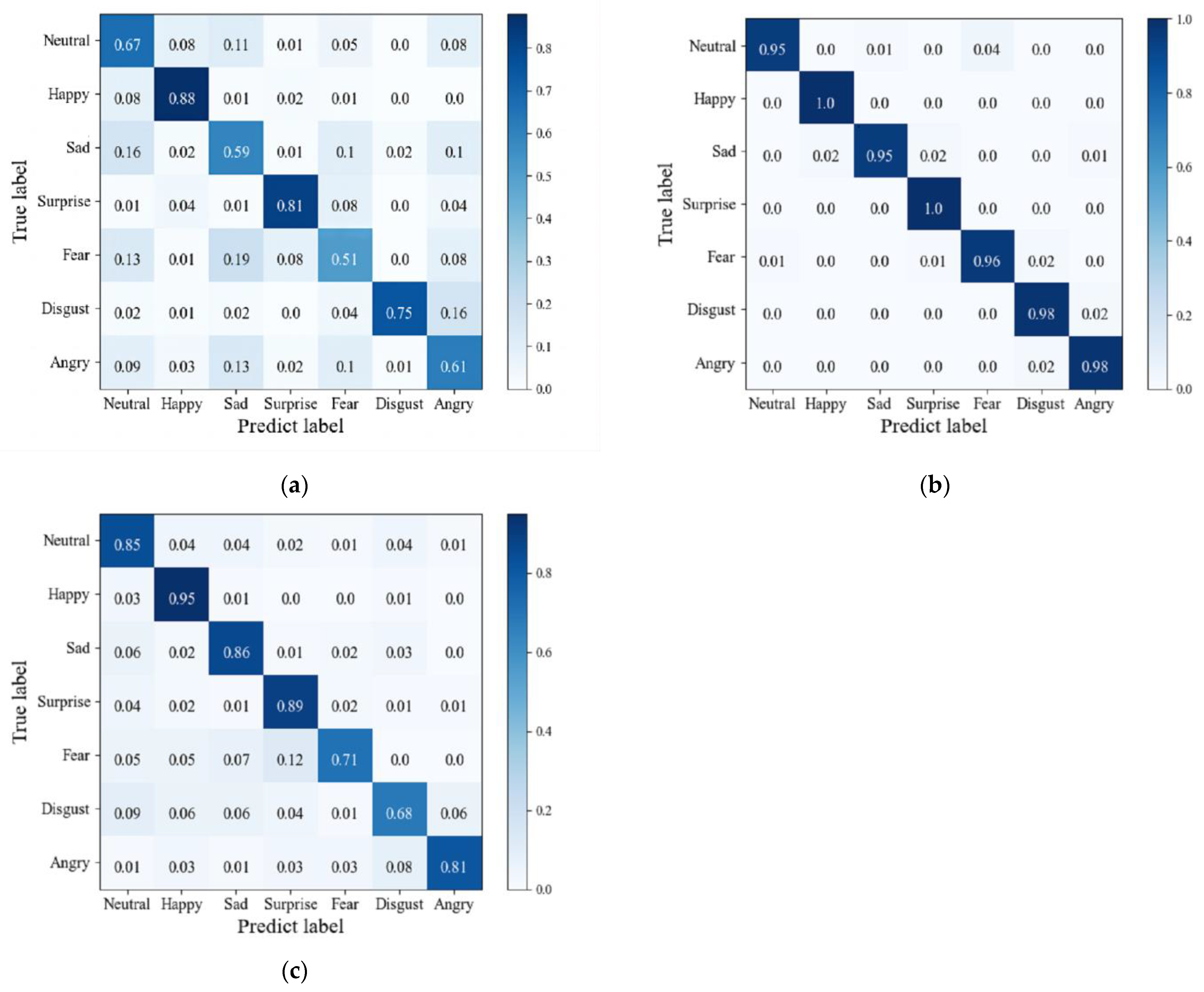
4.2. Ablation Experiments
4.3. Comparative Experiment of Mainstream Algorithms
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, S.; Deng, W. Deep facial expression recognition: A survey. IEEE Trans. Affect. Comput. 2020, 13, 1195–1215. [Google Scholar] [CrossRef] [Green Version]
- Canedo, D.; Neves, A.J.R. Facial Expression Recognition Using Computer Vision: A Systematic Review. Appl. Sci. 2019, 9, 4678. [Google Scholar] [CrossRef] [Green Version]
- Shahzad, H.M.; Bhatti, S.M.; Jaffar, A.; Akram, S.; Alhajlah, M.; Mahmood, A. Hybrid Facial Emotion Recognition Using CNN-Based Features. Appl. Sci. 2023, 13, 5572. [Google Scholar] [CrossRef]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The Extended Cohn-Kanade Dataset (CK+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Lyons, M.; Akamatsu, S.; Kamachi, M.; Gyoba, J. Coding facial expressions with gabor wavelets. In Proceedings of the Third IEEE International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998. [Google Scholar]
- Goodfellow, I.J.; Erhan, D.; Carrier, P.L.; Courville, A.; Mirza, M.; Hamner, B.; Cukierski, W.; Tang, Y.; Thaler, D.; Lee, D.H.; et al. Challenges in representation learning: A report on three machine learning contests. In Proceedings of the 20th International Conference on Neural Information Processing (ICONIP), Daegu, Republic of Korea, 3–7 November 2013. [Google Scholar]
- Li, S.; Deng, W.; Du, J.P. Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, K.; Peng, X.; Yang, J.; Meng, D.; Qiao, Y. Region Attention Networks for Pose and Occlusion Robust Facial Expression Recognition. IEEE Trans. Image Process. 2020, 29, 4057–4069. [Google Scholar] [CrossRef] [Green Version]
- Sadeghi, H.; Raie, A.A. HistNet: Histogram-based convolutional neural network with Chi-squared deep metric learning for facial expression recognition. Inf. Sci. 2022, 608, 472–488. [Google Scholar] [CrossRef]
- Kim, J.C.; Kim, M.H.; Suh, H.E.; Naseem, M.T.; Lee, C.S. Hybrid Approach for Facial Expression Recognition Using Convolutional Neural Networks and SVM. Appl. Sci. 2022, 12, 5493. [Google Scholar] [CrossRef]
- Gong, W.; Wang, C.; Jia, J.; Qian, Y.; Fan, Y. Multi-feature Fusion Network for Facial Expression Recognition in the Wild. J. Intell. Fuzzy Syst. 2022, 42, 4999–5011. [Google Scholar] [CrossRef]
- Ge, H.; Zhu, Z.; Dai, Y.; Wang, B.; Wu, X. Facial expression recognition based on deep learning. Comput. Methods Programs Biomed. 2022, 215, 106621. [Google Scholar] [CrossRef] [PubMed]
- Bian, J.; Mei, X.; Xue, Y.; Wu, L.; Ding, Y. Efficient hierarchical temporal segmentation method for facial expression sequences. Turk. J. Electr. Eng. Comput. Sci. 2019, 27, 1680–1695. [Google Scholar] [CrossRef]
- Hassaballah, M.; Aly, S. Face recognition: Challenges, achievements and future directions. IET Comput. Vis. 2015, 9, 614–626. [Google Scholar] [CrossRef]
- Ng, H.W.; Nguyen, V.D.; Vonikakis, V.; Winkler, S. Deep learning for emotion recognition on small datasets using transfer learning. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9 November 2015. [Google Scholar]
- Chun, C.; Ryu, S.K. Road Surface Damage Detection Based on Semi-supervised Learning Using Pseudo Labels. J. Korea Inst. Intell. Transp. Syst. 2019, 18, 71–79. [Google Scholar] [CrossRef]
- Yao, L.; He, S.; Su, K.; Shao, Q. Facial expression recognition based on spatial and channel attention mechanisms. Wirel. Pers. Commun. 2022, 125, 1483–1500. [Google Scholar] [CrossRef]
- Siqueira, H.; Magg, S.; Wermter, S. Efficient facial feature learning with wide ensemble-based convolutional neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New York Hilton Midtown, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Li, S.; Deng, W. A deeper look at facial expression dataset bias. IEEE Trans. Affect. Comput. 2020, 13, 881–893. [Google Scholar] [CrossRef] [Green Version]
- Pan, B.; Wang, S.; Xia, B. Occluded facial expression recognition enhanced through privileged information. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 15 October 2019. [Google Scholar]
- Xia, B.; Wang, S. Occluded Facial Expression Recognition with Step-Wise Assistance from Unpaired Non-Occluded Images. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12 October 2020. [Google Scholar]
- Mahmoudi, M.A.; Chetouani, A.; Boufera, F.; Tabia, H. Kernel-based convolution expansion for facial expression recognition. Pattern Recognit. Lett. 2022, 160, 128–134. [Google Scholar] [CrossRef]
- Kong, Y.; Ren, Z.; Zhang, K.; Zhang, S.; Ni, Q.; Han, J. Lightweight facial expression recognition method based on attention mechanism and key region fusion. J. Electron. Imaging 2021, 30, 063002. [Google Scholar] [CrossRef]
- Nan, Y.; Ju, J.; Hua, Q.; Zhang, H.; Wang, B. A-MobileNet: An approach of facial expression recognition. Alex. Eng. J. 2022, 61, 4435–4444. [Google Scholar] [CrossRef]
- Zhou, N.; Liang, R.; Shi, W. A lightweight convolutional neural network for real-time facial expression detection. IEEE Access 2020, 9, 5573–5584. [Google Scholar] [CrossRef]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random erasing data augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York Hilton Midtown, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hilton New Orleans Riverside, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet V2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, J.; Sun, J. Large kernel matters–improve semantic segmentation by global convolutional network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Misra, D. Mish: A self regularized non-monotonic activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Zhang, Q.L.; Yang, Y.B. SA-Net: Shuffle attention for deep convolutional neural networks. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021. [Google Scholar]
- Horn, G.V.; Perona, P. The devil is in the tails: Fine-grained classification in the wild. arXiv 2017, arXiv:1709.01450. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Zhou, B.; Cui, Q.; Wei, X.S.; Chen, Z.M. BBN: Bilateral-branch network with cumulative learning for long-tailed visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Gan, Y.; Chen, J.; Yang, Z.; Xu, L. Multiple attention network for facial expression recognition. IEEE Access 2020, 8, 7383–7393. [Google Scholar] [CrossRef]
- Momeny, M.; Neshat, A.A.; Jahanbakhshi, A.; Mahmoudi, M.; Ampatzidis, Y.; Radeva, P. Grading and fraud detection of saffron via learning-to-augment incorporated Inception-v4 CNN. Food Control 2023, 147, 109554. [Google Scholar] [CrossRef]
- Mollahosseini, A.; Chan, D.; Mahoor, M.H. Going deeper in facial expression recognition using deep neural networks. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016. [Google Scholar]
- Minaee, S.; Minaei, M.; Abdolrashidi, A. Deep-emotion: Facial expression recognition using attentional convolutional network. Sensors 2021, 21, 3046. [Google Scholar] [CrossRef] [PubMed]
- Yang, H.; Ciftci, U.; Yin, L. Facial expression recognition by de-expression residue learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Chen, J.; Xu, Y. Expression recognition based on the convolution residual network of attention pyramid. Comput. Eng. Appl. 2022, 58, 123–131. [Google Scholar]
- Pham, L.; Vu, T.H.; Tran, T.A. Facial Expression Recognition Using Residual Masking Network. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021. [Google Scholar]
- Jung, H.; Lee, S.; Yim, J.; Park, S.; Kim, J. Joint fine-tuning in deep neural networks for facial expression recognition. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Arriaga, O.; Valdenegro, T.M.; Plöger, P. Real-time convolutional neural networks for emotion and gender classification. arXiv 2017, arXiv:1710.07557. [Google Scholar]
- Tang, H.; Xiang, J.; Chen, H.; Lu, R.; Xia, Z. Lightweight facial expression recognition method based on multi-region fusion. Laser Optoelectron. Prog. 2023, 60, 0610006. [Google Scholar]
- Wang, K.; Peng, X.; Yang, J.; Lu, S.; Qiao, Y. Suppressing uncertainties for large-scale facial expression recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Ma, H.; Celik, T.; Li, H.C. Lightweight attention convolutional neural network through network slimming for robust facial expression recognition. Signal Image Video Process. 2021, 15, 1507–1515. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| sl | 0.04 |
| sh | 0.3 |
| p | 0.5 |
| rc | 0.3 |
| Parameter | FER2013 | CK+ | RAF-DB |
|---|---|---|---|
| Loss function | Cross Entropy | Cross Entropy | Cross Entropy |
| Learning rate | 0.01 | 0.01 | 0.01 |
| Optimizer | SGD | SGD | SGD |
| Batch size | 16 | 16 | 16 |
| Momentum | 0.9 | 0.9 | 0.9 |
| Learning rate decay | 0.5/50 | 0.5/50 | 0.5/50 |
| Epochs | 300 | 300 | 300 |
| Model | FER2013 | CK+ | RAF-DB | Parameter |
|---|---|---|---|---|
| ShuffleNet | 65.71% | 95.23% | 84.31% | 1.24 MB |
| ShuffleNet + RM | 67.87% | 95.91% | 85.11% | 1.24 MB |
| ShuffleNet + RM + Clip_K5 | 67.84% | 95.87% | 84.98% | 0.94 MB |
| ShuffleNet + RM + Clip_K5 + SA | 69.35% | 96.35% | 86.44% | 0.96 MB |
| RLR-CNet (ours) | 71.14% | 98.04% | 87.93% | 1.02 MB |
| Model | FER2013 (%) | CK+ (%) | RAF-DB (%) | Parameter (MB) |
|---|---|---|---|---|
| ResNet18 | 70.09 | 89.39 | 84.10 | 11.69 |
| ResNet50 | 71.26 | 92.46 | 86.01 | 25.56 |
| VGG16 | 68.89 | 95.46 | 81.68 | 14.75 |
| VGG19 | 68.53 | 92.18 | 81.17 | 20.06 |
| AlexNet | 67.51 | 87.59 | 55.60 | 60.92 |
| ours | 71.14 | 98.04 | 87.93 | 1.02 |
| Model | Accuracy (%) |
|---|---|
| MANet [35] | 69.46 |
| Inception V4 [36] | 66.80 |
| DCN [37] | 69.30 |
| Minace [38] | 70.20 |
| ours | 71.14 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mou, X.; Song, Y.; Wang, R.; Tang, Y.; Xin, Y. Lightweight Facial Expression Recognition Based on Class-Rebalancing Fusion Cumulative Learning. Appl. Sci. 2023, 13, 9029. https://doi.org/10.3390/app13159029
Mou X, Song Y, Wang R, Tang Y, Xin Y. Lightweight Facial Expression Recognition Based on Class-Rebalancing Fusion Cumulative Learning. Applied Sciences. 2023; 13(15):9029. https://doi.org/10.3390/app13159029
Chicago/Turabian StyleMou, Xiangwei, Yongfu Song, Rijun Wang, Yuanbin Tang, and Yu Xin. 2023. "Lightweight Facial Expression Recognition Based on Class-Rebalancing Fusion Cumulative Learning" Applied Sciences 13, no. 15: 9029. https://doi.org/10.3390/app13159029