1. Introduction
Image captioning is a hot topic involving several fields such as computer vision (CV) and natural language processing (NLP), known as image semantic description or “talking about pictures” [
1,
2,
3,
4,
5,
6]. Image captioning technology not only needs to recognize the entity object information in the image and the relationship between objects but also needs to learn how to integrate them into the ability to describe reasonable sentence descriptions. Traditional methods use models based on visual space search, sentence template usage, and the most matching sentence in the dataset to accomplish the tasks of image captioning. The disadvantage of these methods is the low efficiency of generating real and accurate sentences and the poor ability to generate structurally novel sentences. In recent research [
7,
8,
9,
10,
11], visual and language information has been embedded into a common space via recurrent neural networks (RNNs) initially. Convolutional neural networks (CNNs) were then embedded within the visual space and combined with long short-term memory (LSTM) to produce more effective results.
Most models extract image features by embedding the CNN into visual space. While this method can achieve good results, the extracted image features are not highly accurate and efficient, wasting a lot of time. Many models embed LSTM and Bi-LSTM into language space to generate sentences, but the results are not accurate enough. Therefore, it is challenging for subtitling models to perform novel subtitling tasks with accurate and efficient image-sentence retrieval.
To address these issues, we propose a model leveraging a bidirectional LSTM coupled with an attention mechanism (Bi-LS-AttM). This innovative model substitutes the region convolutional neural network (RCNN)—commonly used for feature extraction—with a more efficient fast region convolutional neural network (Fast RCNN). This adjustment enhances the identification and extraction of features within the image’s regions of interest (RoIs). The optimized model is then applied to refine the LSTM network’s performance. By juxtaposing forward and backward outcomes and incorporating the attention boost, the Bi-LS-AttM is able to predict word vectors with greater precision and generate more fitting image captions.
Why do we use the model? We employed the model to break through the boundaries of the traditional Bi-LSTM model, which is not focused enough on the comparison of historical and future word results. In the traditional LSTM cells, the prediction of the next word
using the visible context
and historical context
is performed by estimating
. However, in the Bi-LS-AttM, the prediction of the word
depends on the forward and backward results of separately maximizing
and
at time
. By combining the Bi-LSTM with the attention model, the model focuses increasingly on comparing historical and future word results and using their dependencies to predict and generate appropriate image captions.
Figure 1 shows the example image of the Bi-LS-AttM model generating a sentence that supports our hypothesis that the Bi-LS-AttM model can generate more complementary and focused captions.
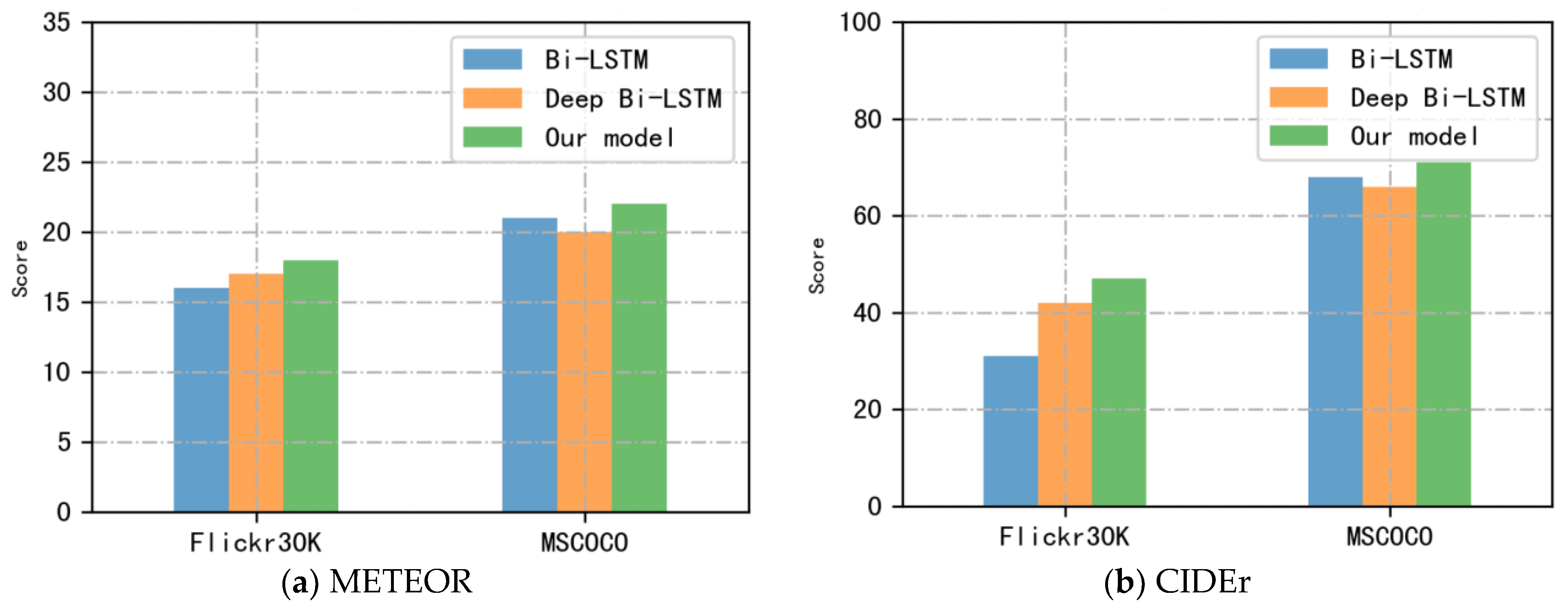
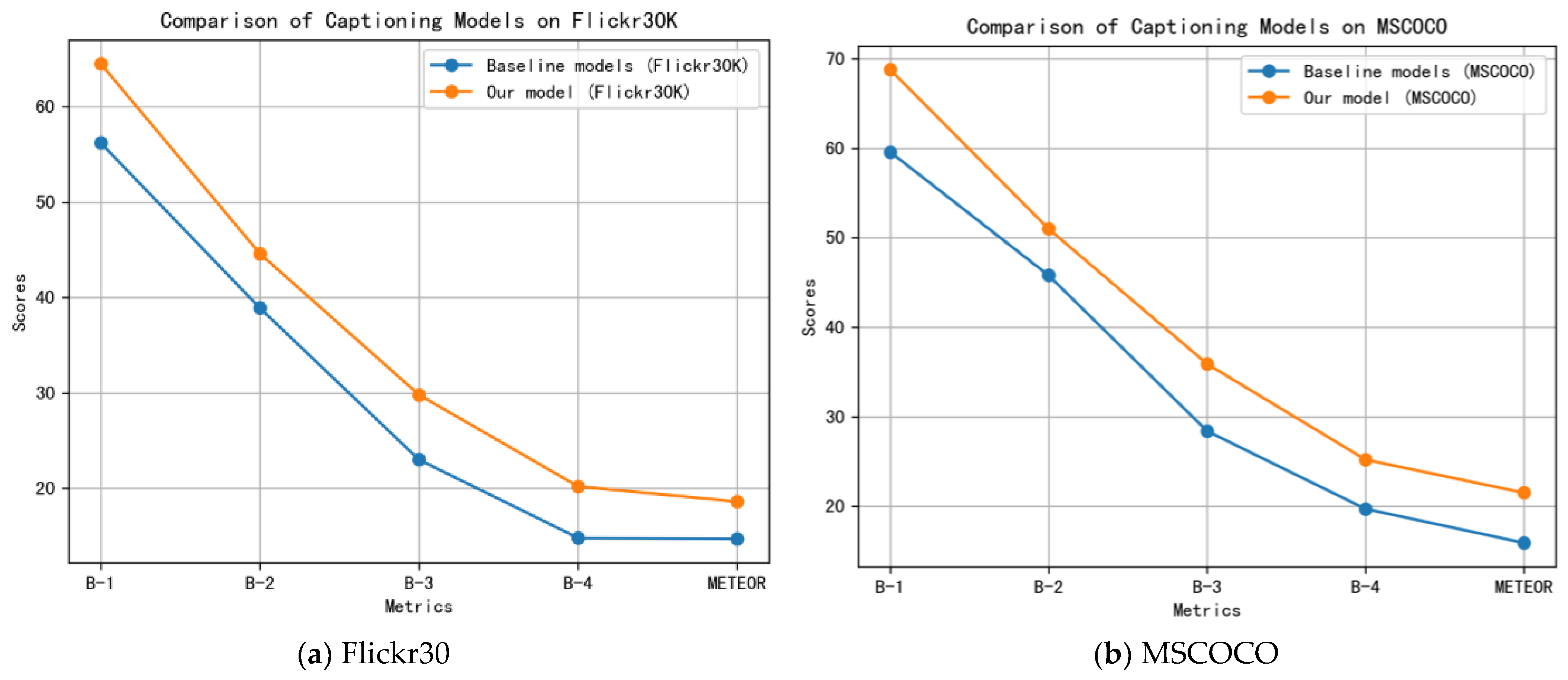
We tested the efficiency of our model on the datasets Flickr30K and MSCOCO and performed a qualitative analysis. The analysis showed that the method performs efficiently, and the proposed Bi-LS-AttM model outperforms other published models. The principal contributions of this paper are threefold:
We proposed a trainable model incorporating a bidirectional LSTM and attention mechanism. This model embeds image captions and scores into a region by capitalizing on the long-term forward and backward context.
We upgraded the feature extraction mechanism, replacing the conventional CNN and RCNN with a Fast RCNN. This improvement enhances the model’s ability to rapidly detect and extract features from items within an image’s regions of interest.
We verified the efficiency of the framework on two datasets Flickr30K and MSCOCO. The evaluation demonstrated that the Bi-LSTM and attention mechanism model achieved highly competitive performance results relative to current techniques in the tasks of generating captions and image sentence retrieval.
2. Related Works
Initially, researchers utilized computers to analyze identified content in image captioning, which was the original task for image recognition [
12,
13,
14]. Later, they introduced additional requirements such as processing and determining object properties, identifying object relationships, and describing image content in natural language. Since then, numerous image captioning techniques have been introduced, broadly categorized into three groups: template-based, retrieval-based, and deep-learning-based methods.
Template-based methods, which utilize fixed templates for sentence generation, identify image elements such as objects, actions, and scenes based on visual dependency grammar. For instance, Farhadi [
15] used a support vector machine (SVM) [
16,
17] to detect image items and pre-established templates for sentence descriptions. However, the limitations of datasets and template algorithms impeded their performance. Similarly, Li [
18] employed Web-scale N-grams for phrase extraction linked to objects, actions, and relationships in 2011. Later, Kulkarni [
19] used a conditional random field (CRF) [
20,
21] for data extraction from a large pool of visual descriptive text, thereby improving computer vision recognition and sentence generation. Despite these efforts, the performance of these methods was suboptimal due to the inherent restrictions of template-based approaches.
The retrieval-based method stores all image descriptions in a collection. The image to be described is then compared to the training set and filtered to find similar images. Using a similar image description to the one found, the candidate description is modified accordingly. Kuznetsova [
22] proposed to search for images with attached titles on the Internet and obtain expressive phrases as tree fragments from the test images. Then, new descriptions are composed by filtering and merging the fragments of the extraction tree. Mason [
23] proposed a nonparametric density estimation (NDE) technique that estimates the frequency of visual content words of the image to be detected and transforms caption generation into an extractive summarization problem. Sun [
24] proposed a concept automatic recognition method that uses parallel text and visual corpora. It can filter out text terms by matching the visual characteristics of similar images in the image library and the image to be described. Retrieval-based methods can be more natural language-like, although relying heavily on the capacity of the database makes it difficult to generate sentences for specific images.
In recent years, with the continued advancement of deep learning, neural networks have been extensively used in image caption tasks. Kiros [
25] first used deep neural networks and LSTM to construct two different multimodal neural network models in 2014, continuously integrating semantic information to generate words. For the encoding part, they applied an RNN to convert vocabulary into
-dimensional word vectors. The sentence described can be written as matrix
, where
is the number of words in a sentence, and
is the size of the word vector. Finally, they used a decoder consisting of LSTM cells to generate the final picture subtitle result word by word with the combination of image features and the language model sentence by sentence. In subsequent research, Xu et al. [
26] incorporated attention mechanisms into the encoder and decoder structural models to describe images. By establishing an attention matrix, they can automatically focus on different areas when predicting different words at different times to enhance the description effectiveness of the model. Bo [
27] used generative adversarial networks to generate diversified descriptions by controlling random noise vectors.
In contemporary research, Ayoub [
28] deployed the Bahdanau attention mechanism and transfer learning techniques for image caption generation. They incorporated a pre-trained image feature extractor alongside the attention mechanism, thus improving captioning quality and precision. Muhammad [
29] proposed a model blending the attention mechanism and object features for image captioning, enhancing the model’s ability to leverage extracted object features from images. Chun [
30] demonstrated an advanced deep learning approach for image captioning that combined CNN for image feature extraction and RNN for caption generation, enhanced by the attention mechanism. This innovative method facilitated the automated creation of comprehensive bridge damage descriptions. Lastly, Wu [
31] addressed the challenge of describing novel objects through a switchable attention mechanism and multimodal fusion approach, resulting in the generation of accurate and meaningful descriptions.
Wang [
8] used a Bi-LSTM model to perform image caption. Wang has developed a deep Bi-LSTM model based on this and has achieved good results. Fazin [
9] simplified Wang’s model by reducing many parameters and improving the efficiency of the model. Unlike the above models, the mapping relationship between vision and language in our Bi-LS-AttM model is reverse-crossed, and the forward and backward attention of visual language are dynamically learned. As shown in
Section 4, this has been demonstrated to be extremely beneficial for picture caption and image sentence retrieval.
3. Methodology
This section outlines our proposed model, an enhanced version of the deep Bi-LSTM model for image captioning as proposed by Wang [
8] and Fazin [
9]. In our design, we replace the RCNN used in Wang and Vahid’s model with Fast RCNN to expedite the feature extraction process. Furthermore, we substitute the Bi-LSTM with the Bi-LS-AttM, representing our unique contribution to this study.
Our model framework comprises three components: a Fast RCNN for detecting objects within images; a Bi-LSTM paired with an attention mechanism to provide attentional representation for each word; and a common space to compile all sentences and their respective final scores. The specifics of each module will be elaborated in the subsequent sections.
3.1. Detect Object by Fast RCNN
In this section, we adopt the method proposed by Girshick [
32] for feature extraction and recognition. The selective search algorithm is utilized to extract candidate regions from the input image. These regions are then mapped to the final convolutional feature layer based on their spatial positional relationship.
For each candidate region on the convolutional feature layer, RoI pooling is performed to secure fixed-dimensional features. These extracted features are then fed into the fully connected layer for subsequent classification and regression tasks.
Fast RCNN outputs the probability of each category for each candidate region, as well as the calculated position of each candidate box through regression. For each candidate region, the following loss function is calculated:
where
is the probability of each category belonging to the candidate region and
is the ground truth category.
is the predicted position for each category, and
is the ground truth position for the candidate field. Compared with the previous version of RCNN, Fast RCNN improves the calculation speed, saving the time and cost of object detection.
Fast RCNN combines classification and regression into a common network, enabling consistent training. In particular, its main enhancement on RCNN is that it eliminates the practice of using separate SVM classifiers and bounding regressors, which greatly improves speed.
3.2. Long Short-Term Memory
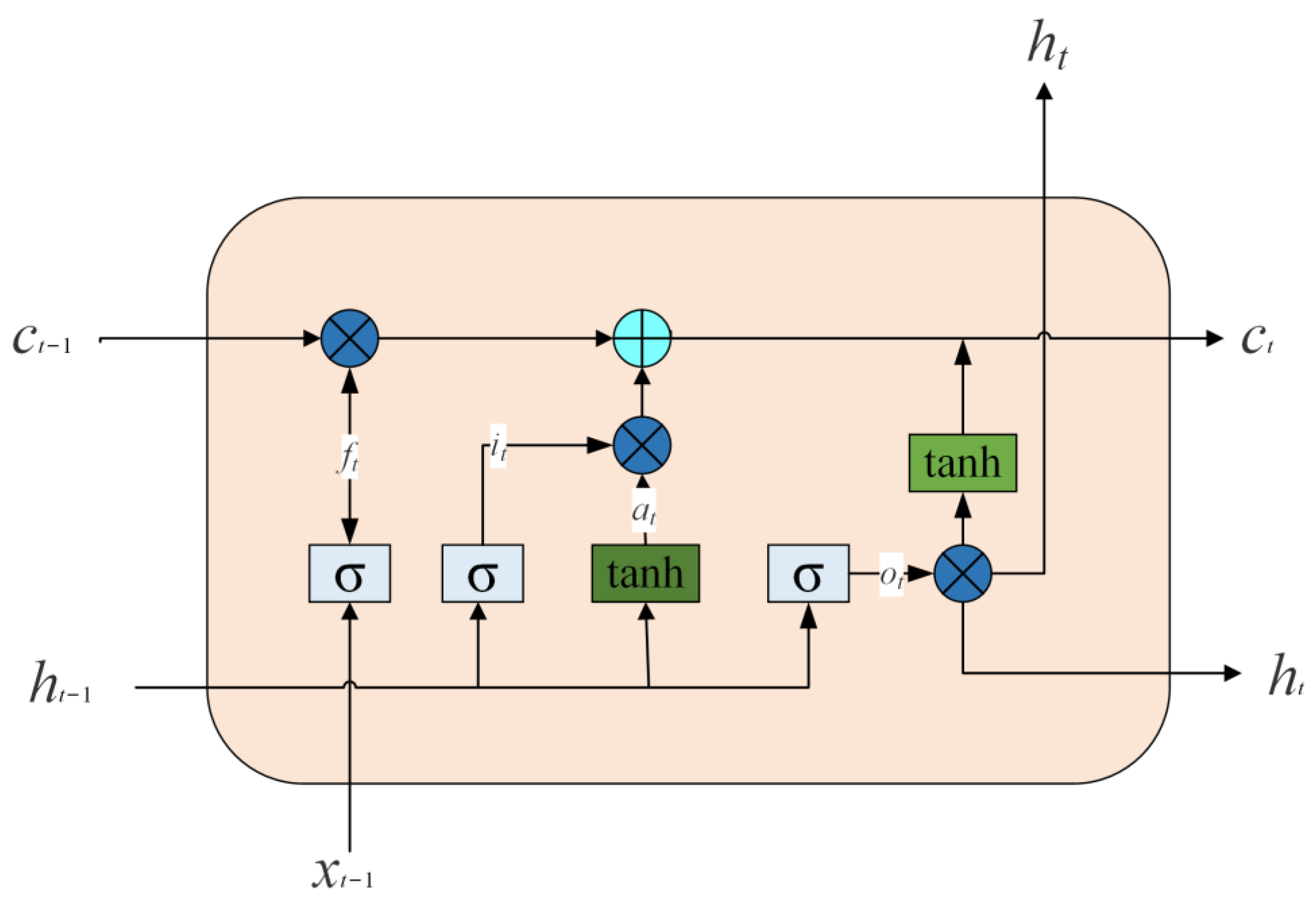
The LSTM cells form the basis of this work. They are a unique form of RNN able to memorize long-term associations.
Figure 2 shows that an LSTM cell is made up of four important components: a memory cell
and three gate circuits (
is the gate of the input,
is the gate of forget, and
is the gate of the output) [
9].
In the formula below,
,
, and
are the values of forget, input, and output at time
, respectively.
is the intermediate feature extract result of
and
at time
:
where
is the entrance, and
is the hidden state value at time
. The results calculated by forgetting and inputting operate on the cell state, expressed as the formula below:
where
represents the Hadamard product. Finally, the hidden state is at
.
is obtained by multiplying the gate output
and the current cell state
using the Hadamard product:
The following equation uses the parameters
and
to predict the next word:
where
is the tipping probability of the forecast value.
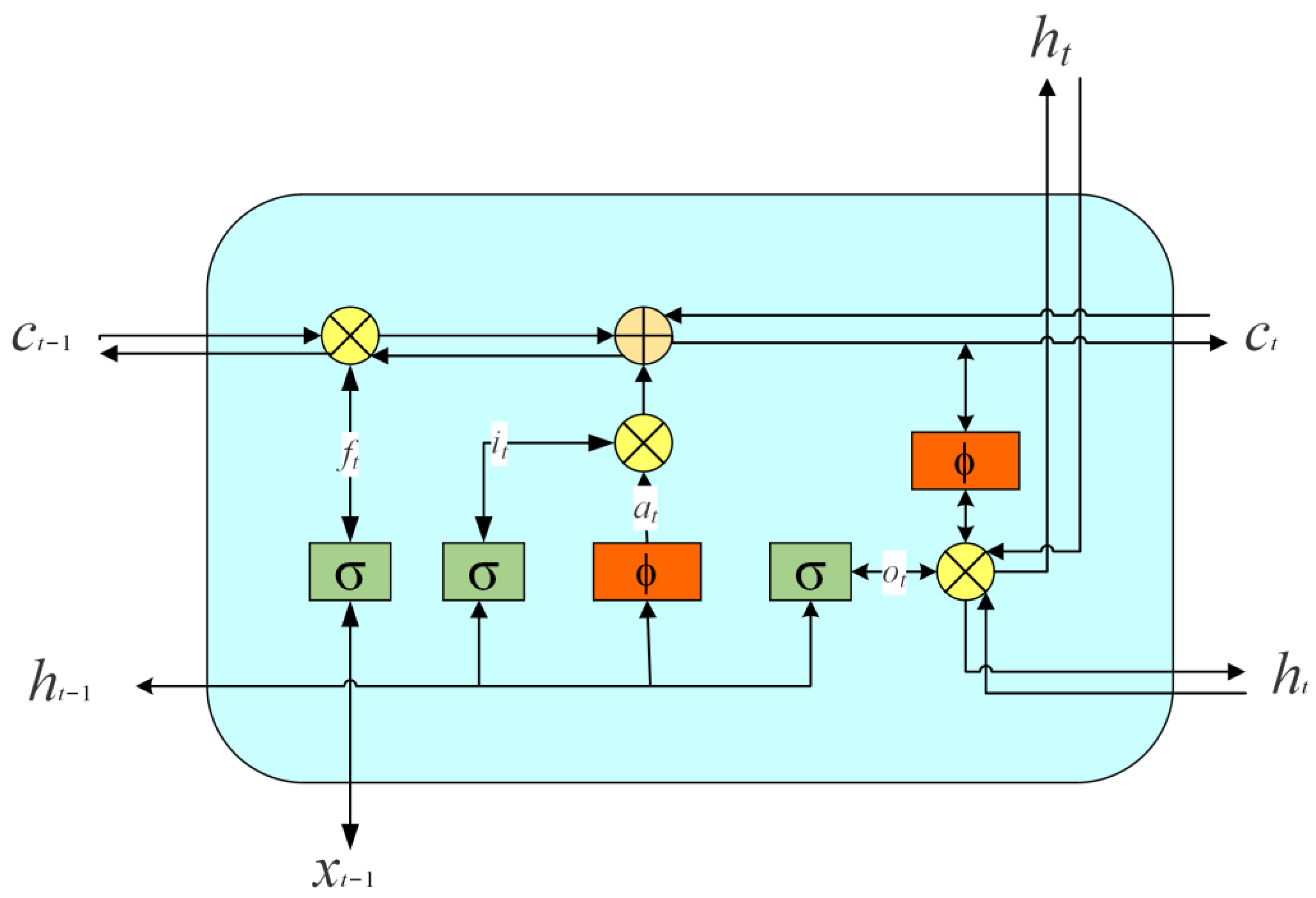
3.3. Bi-LSTM
Both RNN and LSTM units leverage past temporal information to predict forthcoming outputs. However, in some instances, the desired output is associated with not just the previous state but also the future state. For instance, predicting a missing word within a textual context requires comprehension of both the preceding and succeeding context. This dual-directional context analysis provides a more comprehensive and accurate interpretation, thereby achieving a genuine contextual understanding and decision-making process.
In the traditional LSTM, the forecast of the word using the optical context and historical context is performed by estimating . However, in the Bi-LSTM with attention, the prediction of the word depends on the forward and backward results of separately maximizing and at time .
In the Bi-LSTM cell structure, the input sequence is processed in both forward and backward directions by two distinct LSTM cells to extract features. As illustrated in
Figure 3, the output vectors generated are amalgamated to form the final word representation. The core concept behind the Bi-LSTM cell is to facilitate the capture of features at any given time point, encompassing information from both preceding and succeeding time steps. It is worth noting that the two LSTM units within the Bi-LSTM cell operate with independent parameters while sharing a common word-embedding vector space.
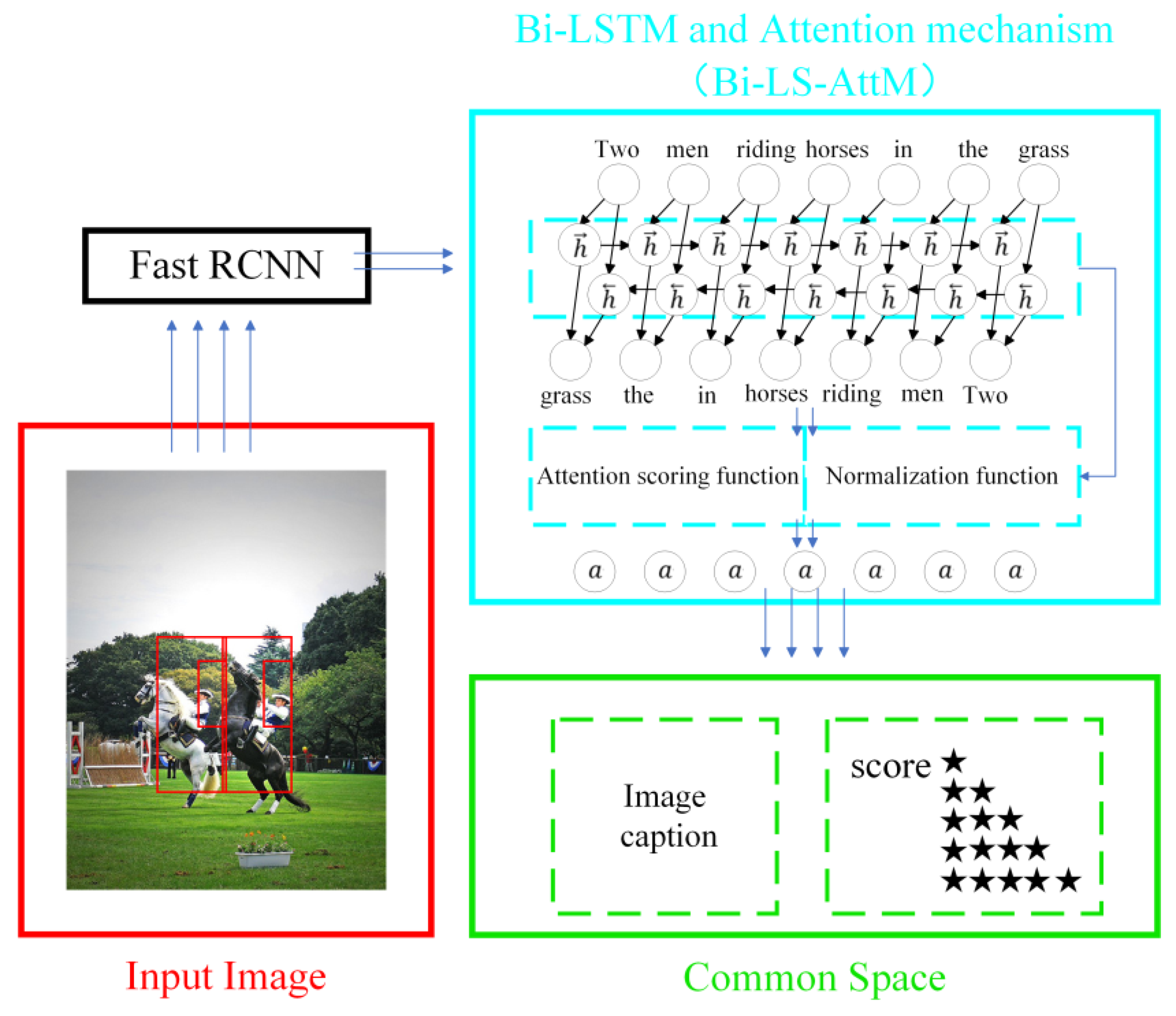
3.4. Architecture Model
The general layout of the model is illustrated in
Figure 4. It is mainly composed of three modules: Fast RCNN for encoding image input, Bi-LS-AttM for encoding sentence input, and embedding picture and caption into common space and decoding it into image captions and evaluation scores.
The Bi-LS-AttM generates word vectors by comparing similarity using the context information from the frontend and the backend. More accurate words are selected after passing by attention. In our work, the model calculates the front hidden vector
and the back hidden vector
. The front cell starts at
, while the back cell starts at
. Our framework works such that for an initial input frame I, the encoding is performed as follows:
where
and
represent Fast RCNN and Bi-LSTM, respectively.
and
are their corresponding weight coefficients.
and
are forward and backward vectors learned from the neural network, respectively. Afterward, the obtained vectors
and
are input into attention. The bilinear scoring procedure is applied to calculate the correlation between the query
and
and
. Next, a SoftMax is applied to these scores to normalize them and obtain the attention distribution
. The bilinear scoring function and SoftMax are defined as follows:
where
is a trainable parameter matrix.
is a bilinear function.
After training the model, it can predict the word
with a given image context
and forward word context
, predicted either in a forward direction using
or in a backward direction using
. For both forward and backward directions,
is set at the starting point. Finally, for sentences generated from both directions, the last sentence of the given image
is determined by the sum of all words’ probabilities in the caption:
The Bi-LSTM module and its training parameters are similar to those presented in Wang [
8]. The difference is that an attention mechanism is added to it. It can focus more on comparing the forward and backward context information to obtain the attention distribution. When extracting features, the Fast RCNN is more efficient and saves time.
5. Conclusions
In this study, we have introduced a model that leverages the capabilities of the Bi-LS-AttM approach to generate captions that are precise, inventive, and context-sensitive. This was accomplished by incorporating bidirectional information and an attention mechanism. For the dual purposes of feature extraction and time optimization, we utilized the Fast RCNN. Additionally, to provide a comprehensive understanding of the proposed model’s structure, we generated a detailed visualization outlining the word generation process at consecutive timesteps. The model’s robustness and stability were thoroughly assessed across various datasets pertinent to image captioning and image-sentence retrieval tasks.
In terms of future work, we intend to delve into more intricate domains of image captioning, including those related to remote sensing and medical imaging. We anticipate broadening the application scope of our model to encapsulate other forms of captioning tasks such as video captioning. Furthermore, we plan to explore the integration of multi-task learning methodologies with an aim to enhance the model’s general applicability.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}