1. Introduction
Wire rope is widely used in many fields, such as coal mine hoists, bridge construction, escalators, cranes, and ocean platforms for natural gas extraction [
1]. Due to the harsh working conditions in these fields, various defects inevitably occur during its whole life cycle [
2]. Furthermore, the condition of wire rope is of great importance for the stable operation of machines and the safety of human lives [
3]. Magnetic flux leakage (MFL) [
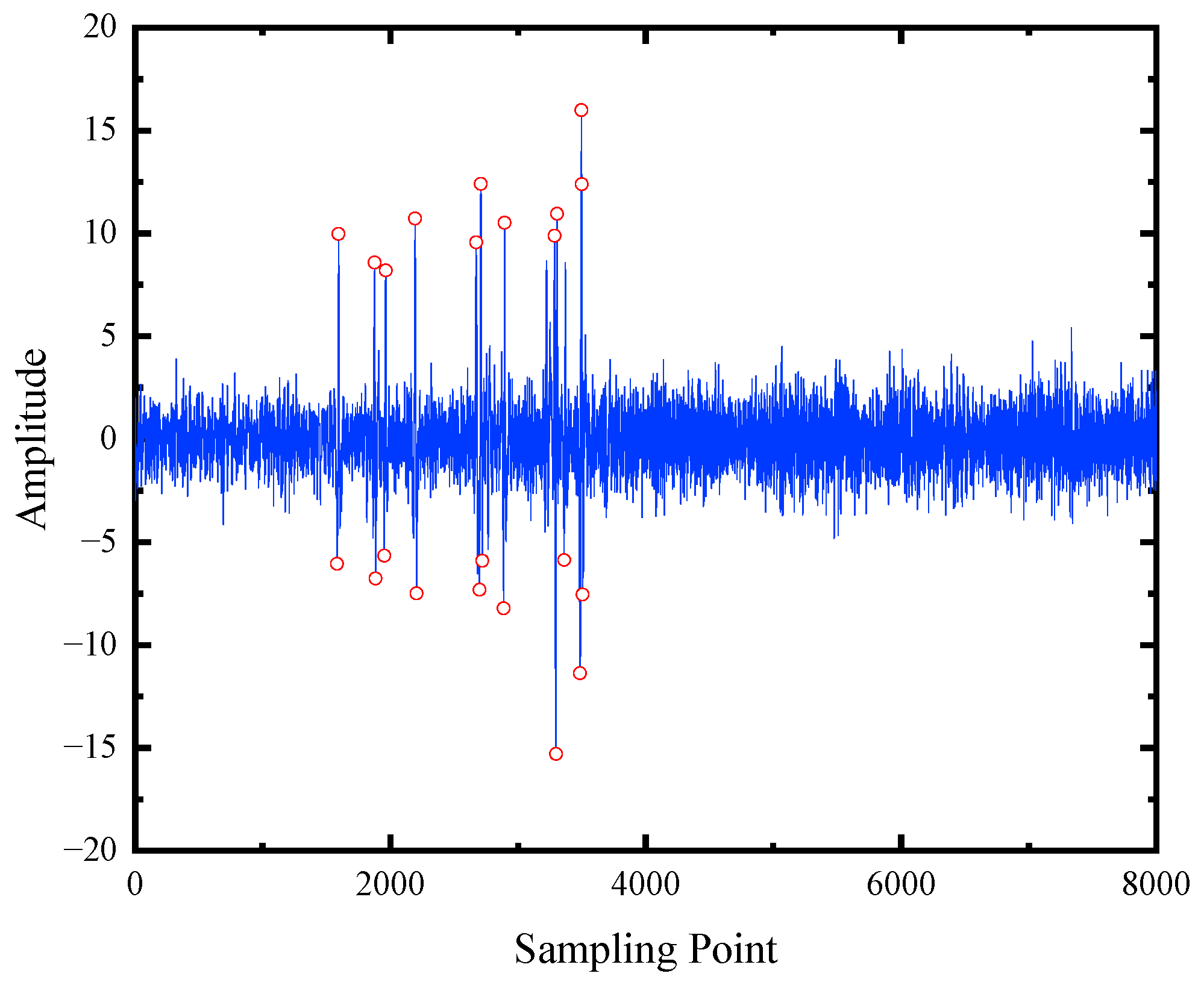
4] is one of the most prevalent non-destructive electromagnetic testing methods used in practical applications, where the loss of metallic cross-sectional area (LMA) defects can be detected both effectively and rapidly. However, the analysis of this method is difficult when LMA signals are combined with different noises that are generated by electromagnetic interference, detection speeds, the pole tip effect, or movement friction [
5]. Hence, the accurate defect diagnosis of wire rope is necessary and meaningful for machines to present greater reliability. In addition, reducing maintenance costs is another benefit that arises from wire rope defect diagnosis research.
In recent years, breakthroughs in image processing methods have provided increased directions for wire rope signal processing and feature extraction techniques. Based on the matrix reconstruction method and the fact that two-dimensional (2D) imaging provides a better platform for feature extraction in comparison to standard one-dimensional (1D) signals, numerous detection algorithms have been proposed and demonstrated in the literature [
6,
7,
8]. To improve the robustness and accuracy outcomes of wire rope defect inspections, Liu et al. proposed some novel methods to complete quantitative defect recognition practices, including a reshaped sine function, wavelet function, and grid entropy. Finally, the feasibility of the presented methods is verified through case studies that are conducted under different working conditions [
9]. In a recent study, Li et al. presented the establishment of MFL gray images and combined a kernel extreme learning machine with a compressed sensing wavelet to inhibit noise interference and improve the accuracy of wire rope defect recognition results [
10]. From the perspective of solving noise interference issues, Liu et al. designed a new signal processing method based on notch filtering and wavelet denoising for successfully detecting defect signals in the MFL data, which was demonstrated by a series of experiments and processing results [
11].
It is well known that deep learning and neural networks have achieved great success in numerous fields, such as image classification [
12,
13], object detection [
14,
15], and natural language processing [
16]. These new approaches can automatically extract features instead of depending on prior knowledge. Furthermore, the advantage of deep learning networks is their better generalization and robustness. Based on machine learning techniques, some methods were proposed in the literature and demonstrated to be effective for various defect diagnosis tasks in mechanical industries, such as drag machines, gearbox diagnosis, motor fault detection, and rotor-bearing systems [
17]. Eren et al. used raw sensor signal as an input to establish a compact, adaptive, 1D convolution neural network (CNN) classifier for bearing fault diagnosis without any pre-determined feature extraction or feature selection methods, and the effectiveness and feasibility of the proposed method were validated by comparing the results with other competing intelligent fault diagnosis algorithms [
18]. Based on an artificial neural network, Sahu et al. applied a multilayer perceptron in a drag system to improve the sensitivity of their fault symptom identification and demonstrated the effectiveness of minimizing the failure frequency and maintenance costs [
19]. To address the difficulties of acquiring labeled samples, He et al. proposed a new framework based on small-labeled infrared thermal images and an enhanced CNN for monitoring the vibration of a rotor-bearing system fault diagnosis, which was demonstrated to be superior to the mainstream methods used to date [
20]. Some studies also focused on transfer learning (TL) methods to minimize the discrepancy between two datasets of working conditions, which aimed to avoid long time-consuming training and insufficiently labeled data. Wang et al. designed a novel fault diagnosis network that was constructed by a deformable CNN, deep long short-term memory, and dense layers based on transfer learning strategies, and their cross-domain experiments demonstrated its effectiveness in identifying the fault types of bearings in new conditions [
21]. Ma et al. proposed a transfer diagnosis framework based on an improved domain adaptation algorithm, and their related comparison of the experimental results demonstrated the applicability and practicability of the proposed method compared with other existing state-of-the-art (SOTA) algorithms [
22]. Some studies also used machine learning methods to detect wire rope defects, such as neural networks, support vector machine (SVM) [
23], and multi-channel signal fusion, to improve the performance of defect detection activities under conditions of vigorous movement and strand noise [
24]. Undoubtedly, the mentioned studies yielded positive effects from different aspects; however, for cross-domain working conditions and those with noise interference, further improvements and increased robustness can be achieved in wire rope defect diagnosis.
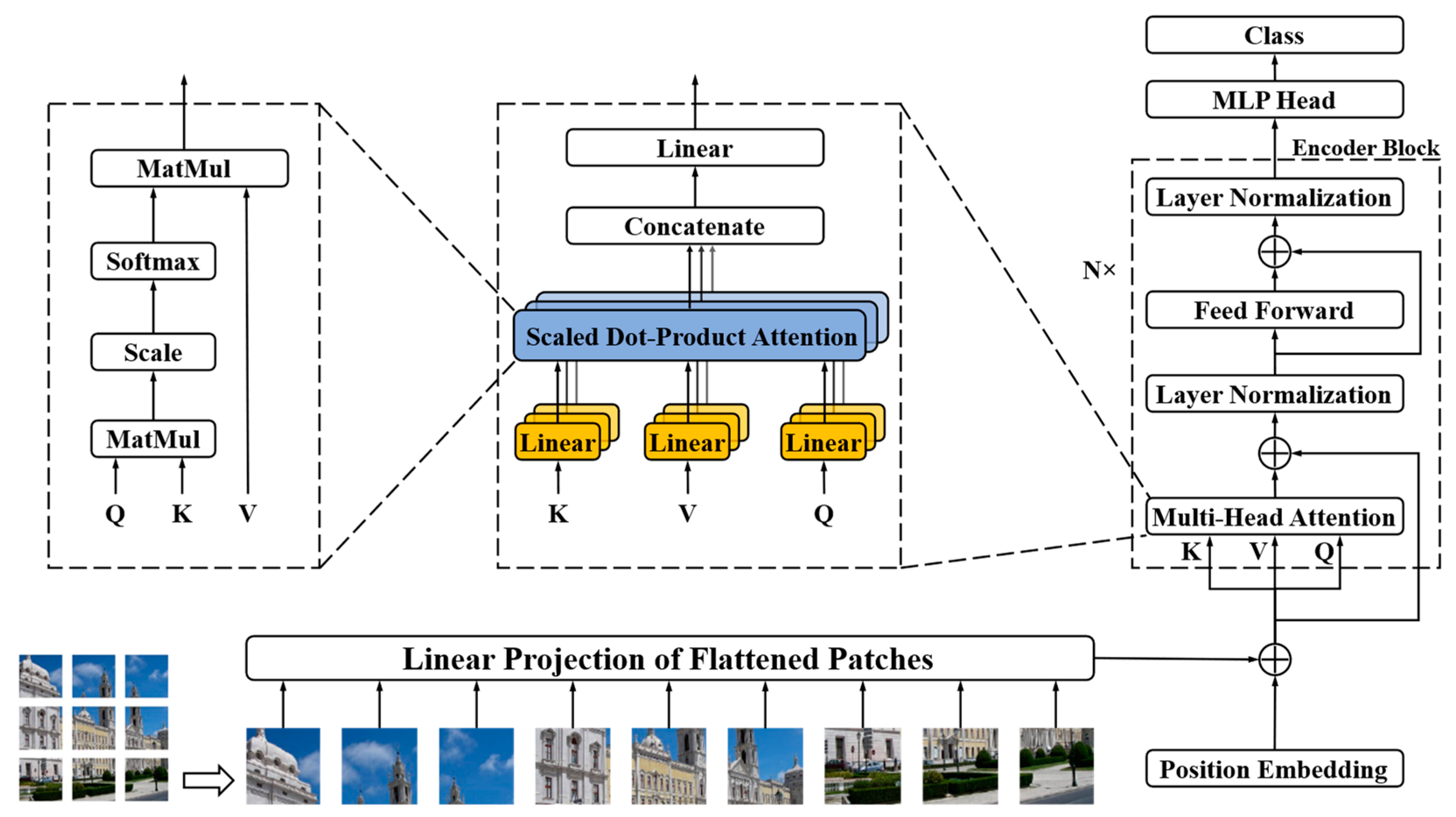
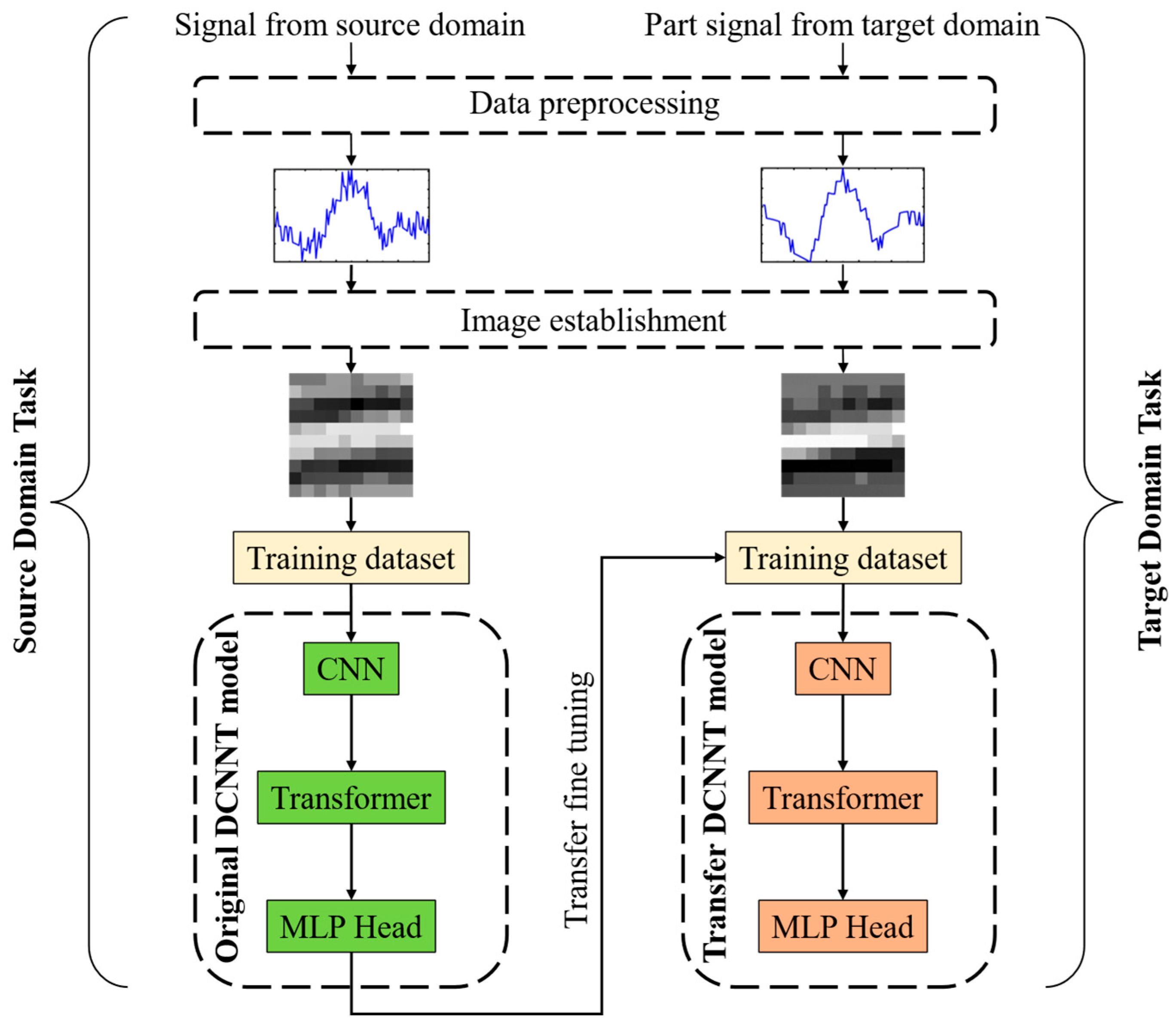
Aiming to improve wire rope defect diagnosis performance under diverse working conditions from LMA signals, a new CNN-transformer network and TL architecture are proposed in this paper to improve the defect detection accuracy. The main contributions and novelties of this paper are the following:
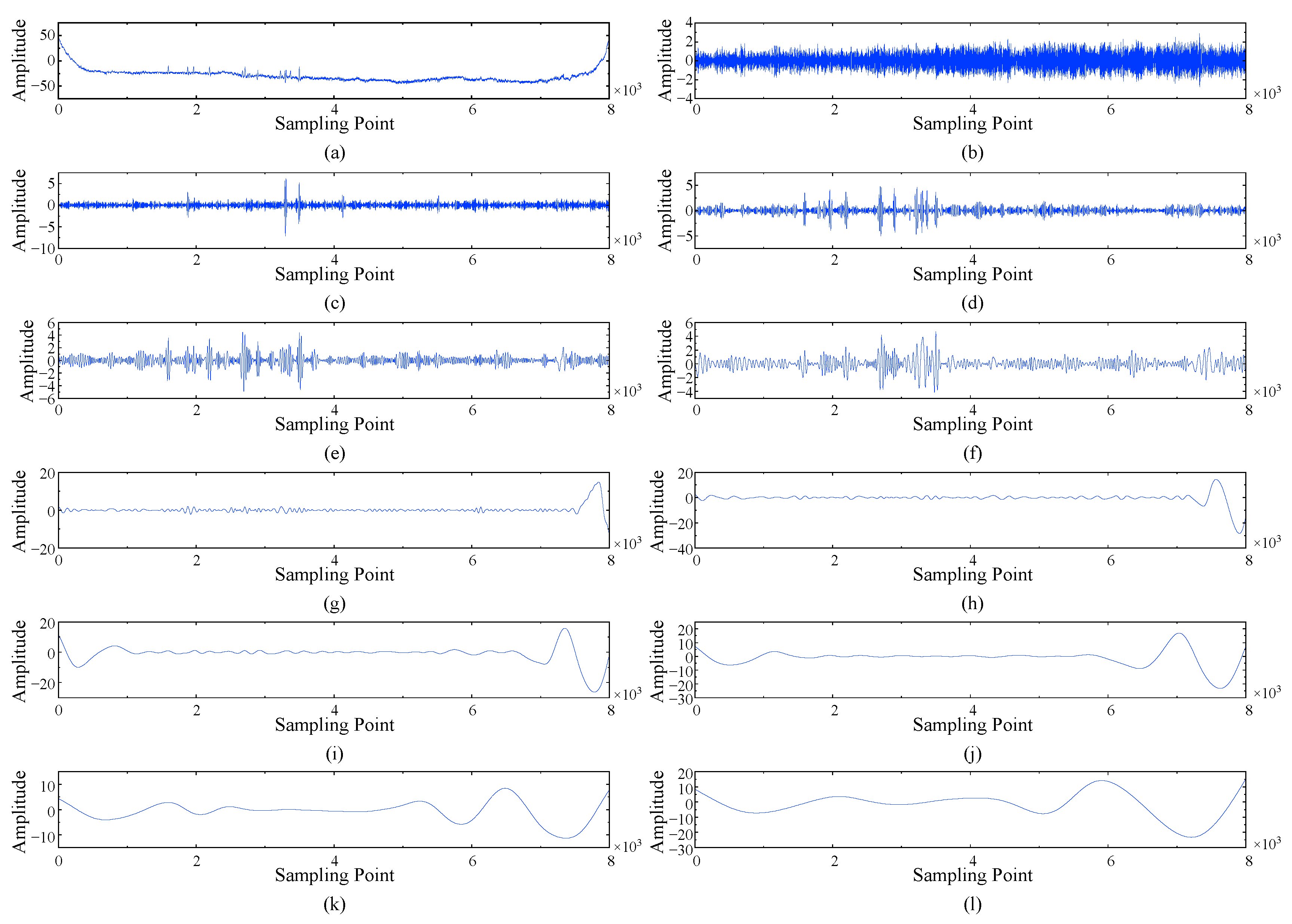
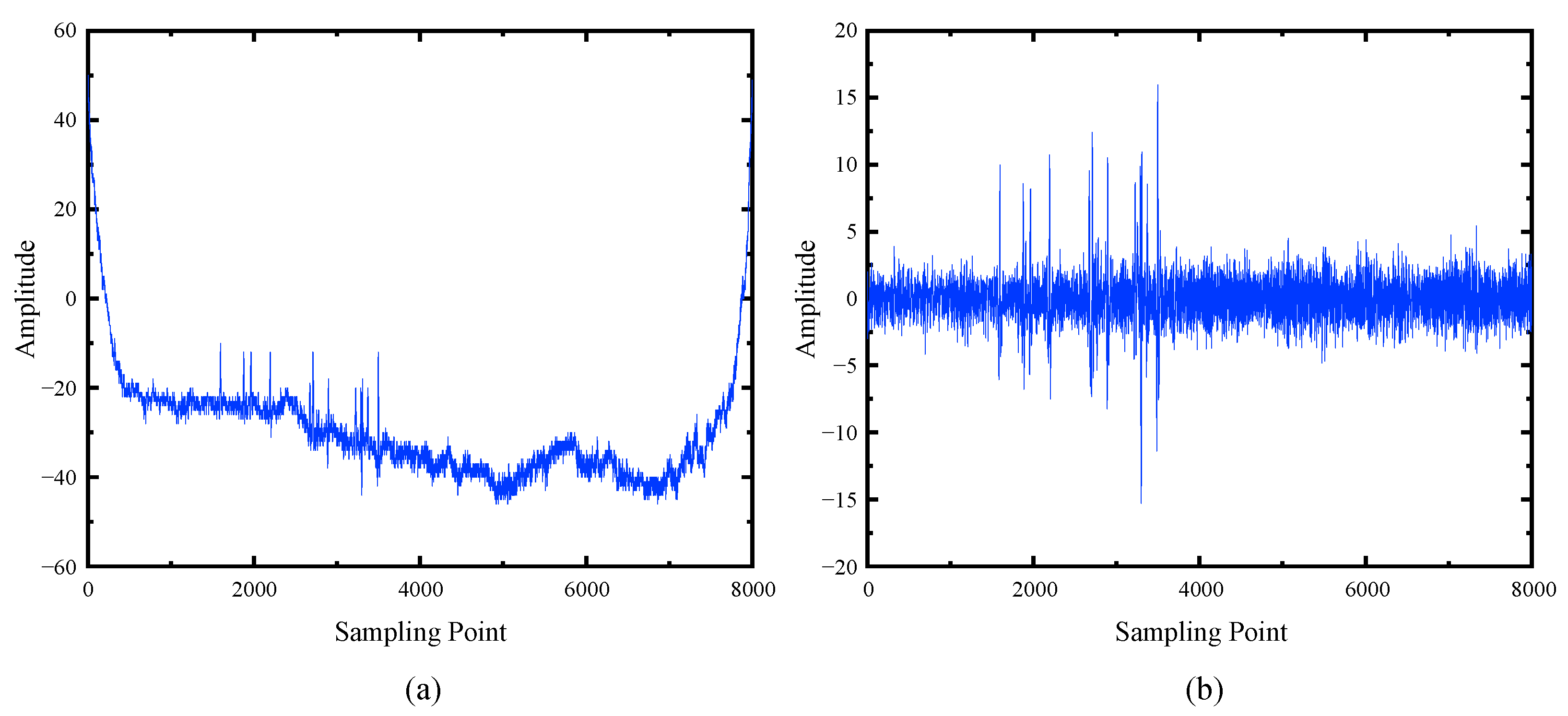
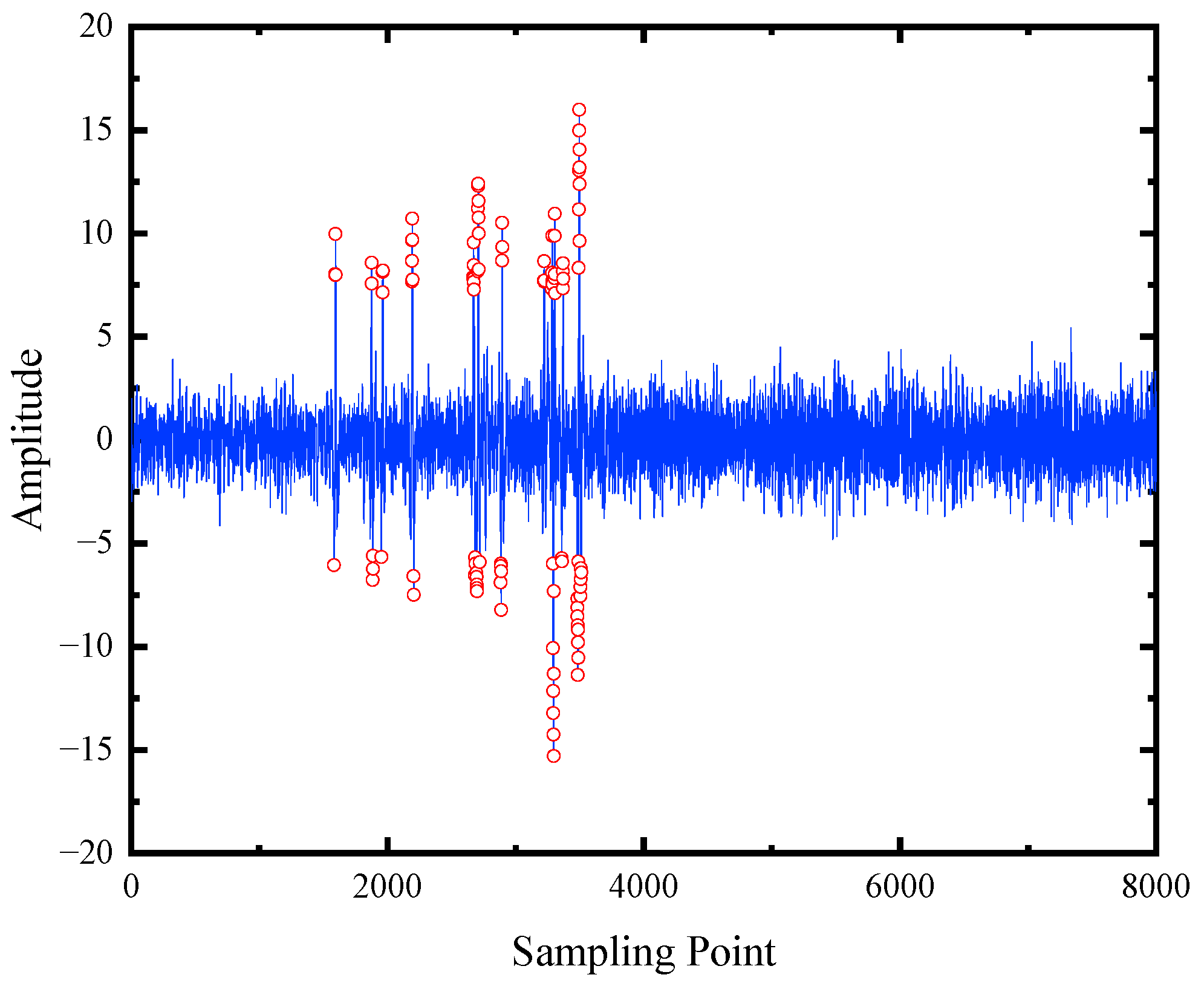
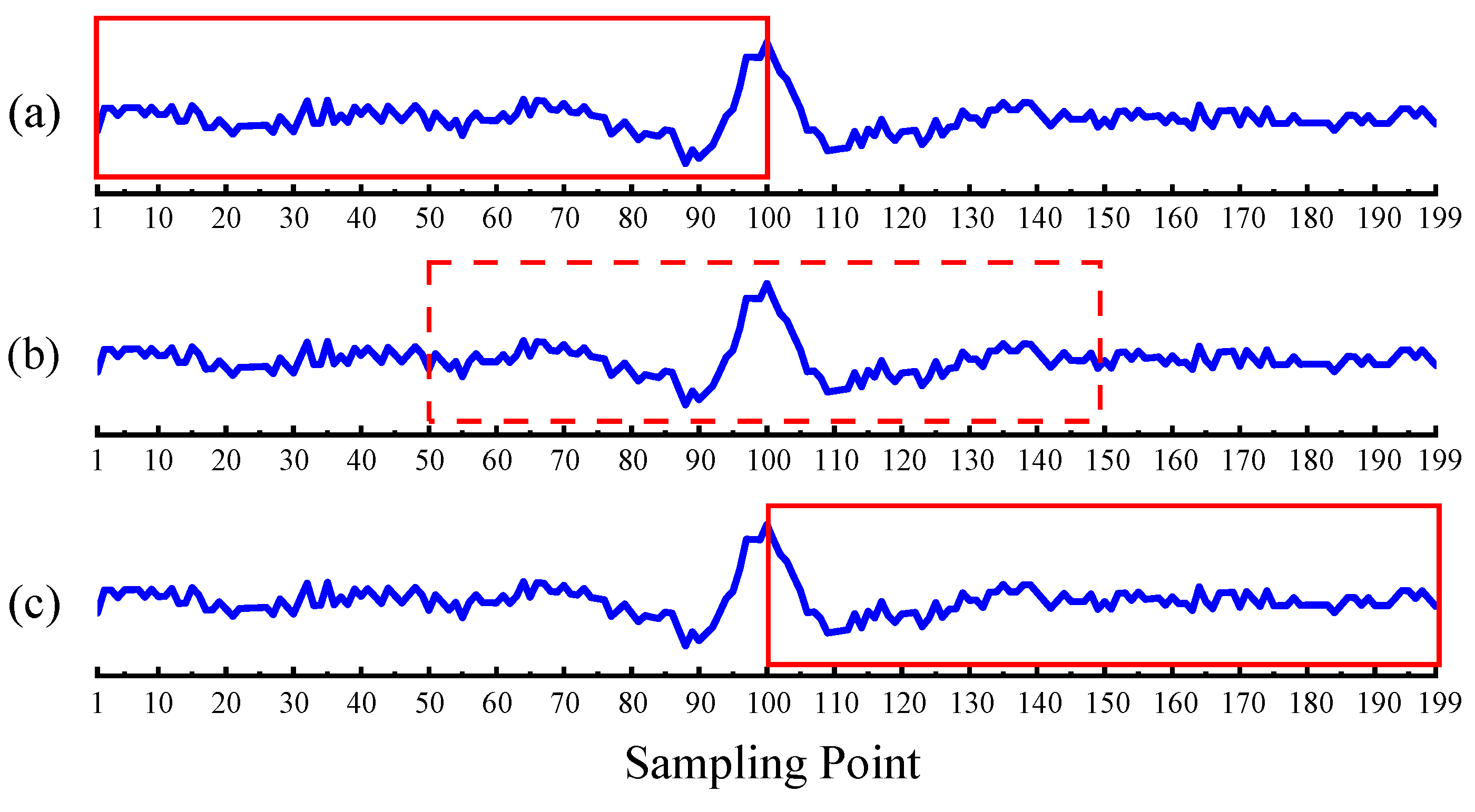
(1) A data preprocessing method based on empirical mode decomposition (EMD) is presented to eliminate the adverse interference of various noises. Two-dimensional gray images are processed through matrix reconstruction and data augmentation methods for the preparation of a wire rope training dataset.
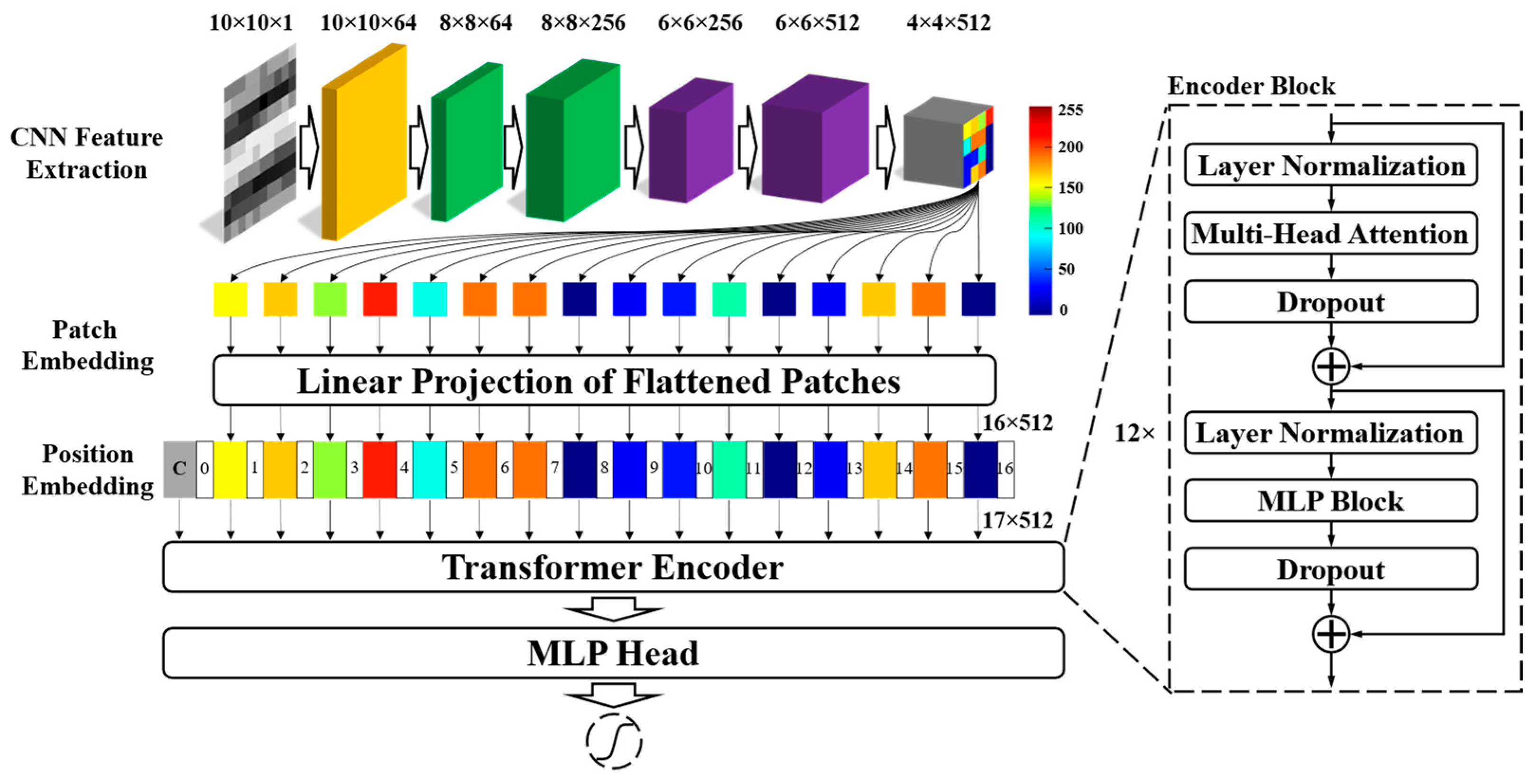
(2) Through the combination of CNN and a transformer, a novel wire rope defect diagnosis network is proposed and named DCNNT, where the defect information can be effectively extracted, computational complexities are reduced, and forward efficiency is improved.
(3) Unlike the existing approaches in the literature, this paper focuses on solving the issues of domain adaptation and wire rope defect data that are insufficient. A new TL architecture is established based on TL techniques and the proposed DCNNT.
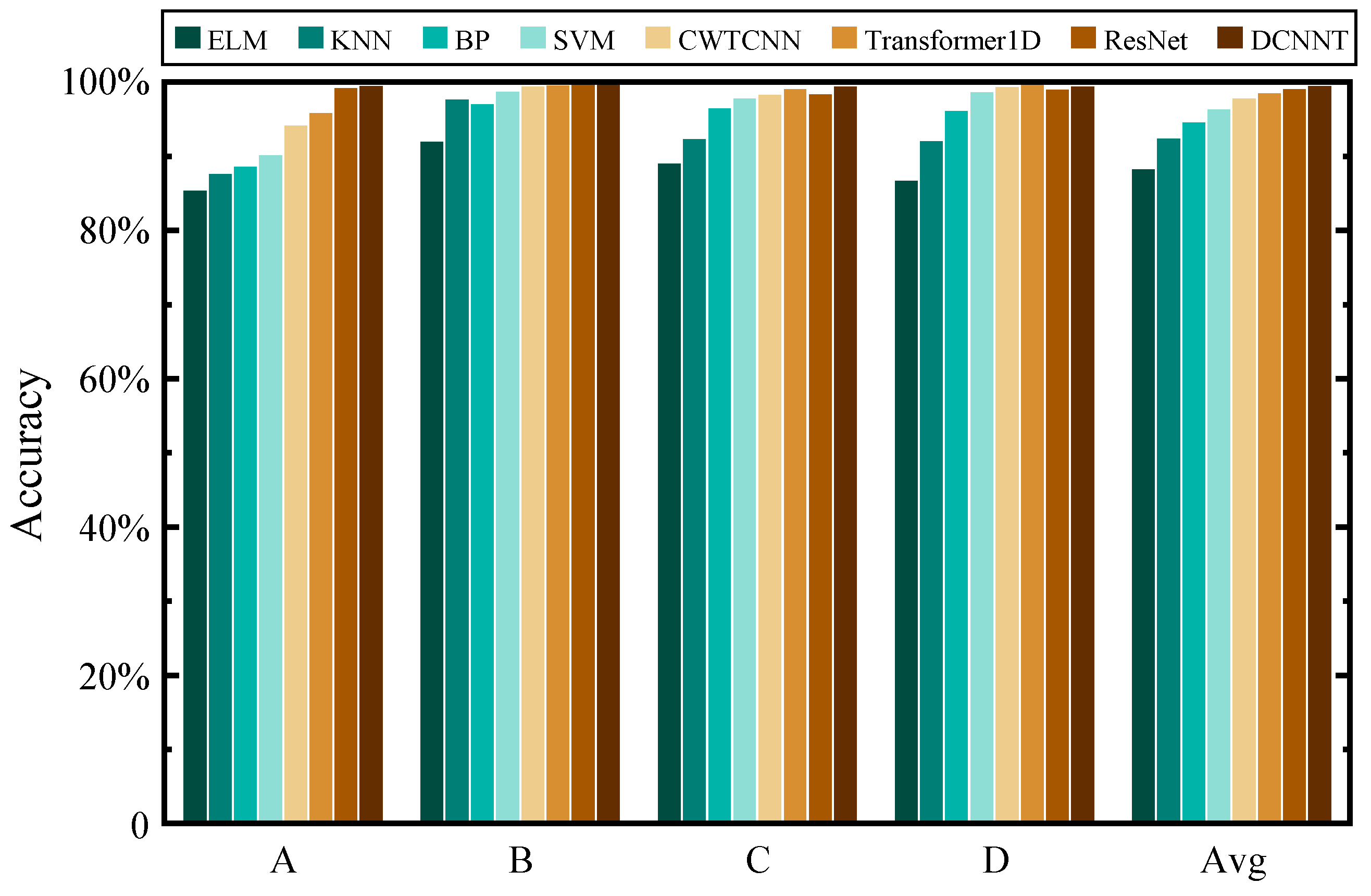
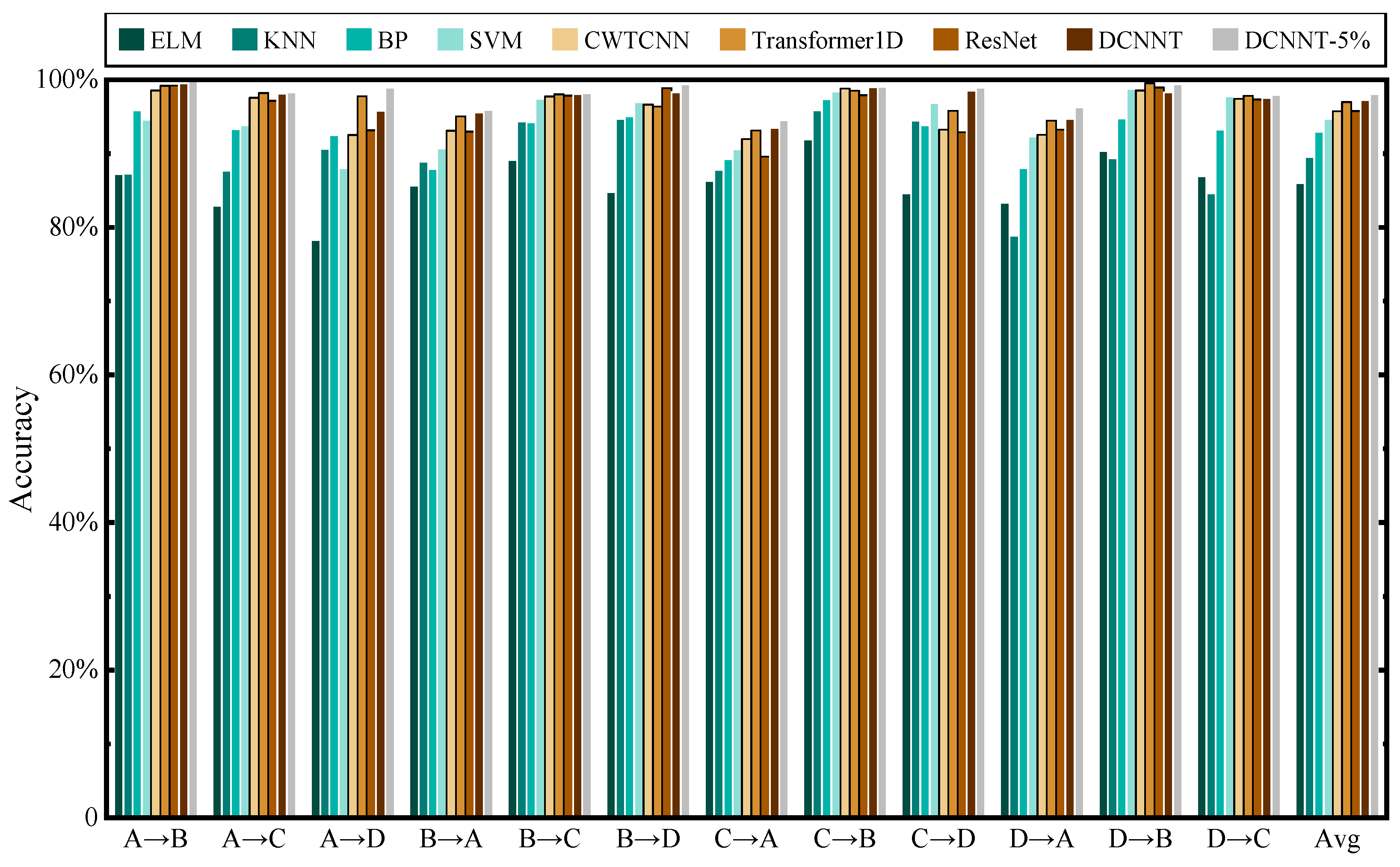
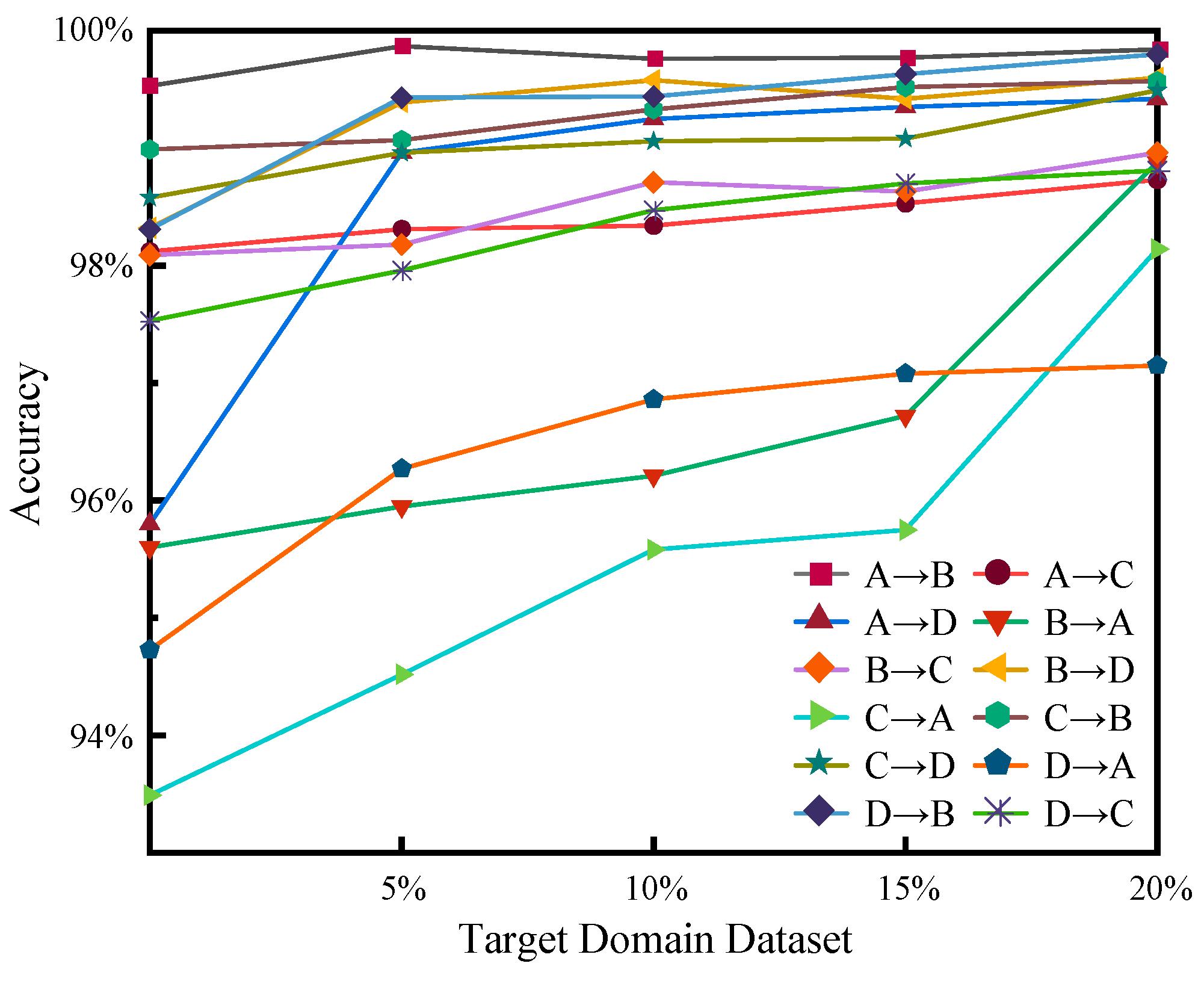
(4) The effectiveness of the proposed DCNNT and domain adaptation ability of the TL architecture are verified through different comparison experiments with several general and SOTA methods, where the proposed model can balance detection accuracy, forward latency, and network parameters.
This paper is organized as follows: The related study is reviewed in
Section 2.
Section 3 is the methodology of the proposed methods, including original data preprocessing based on EMD, feature image processing based on matrix reconstruction, TL architecture establishment, and DCNNT network structure. In
Section 4, case studies are conducted through comparison experiments and visualization analysis. Conclusions are presented in
Section 5.
5. Conclusions
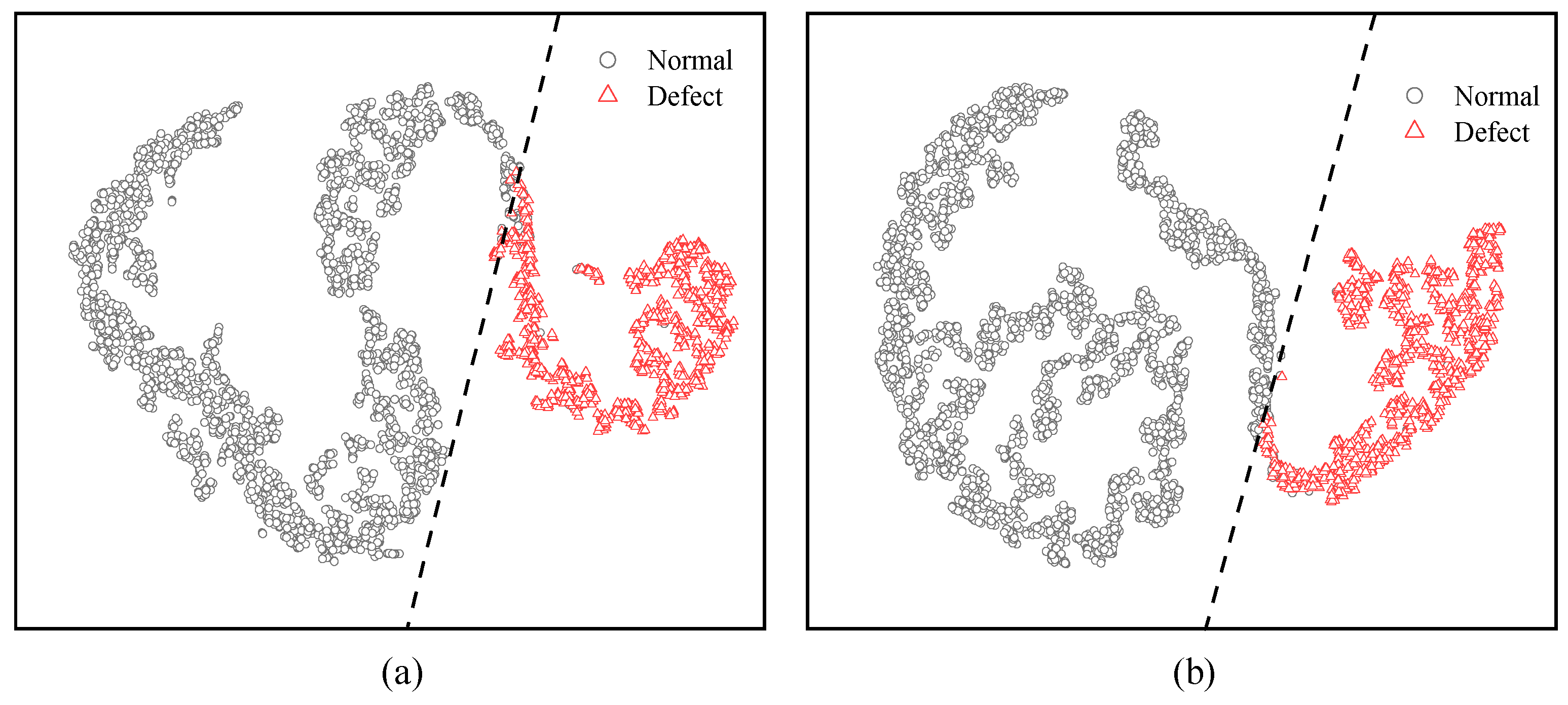
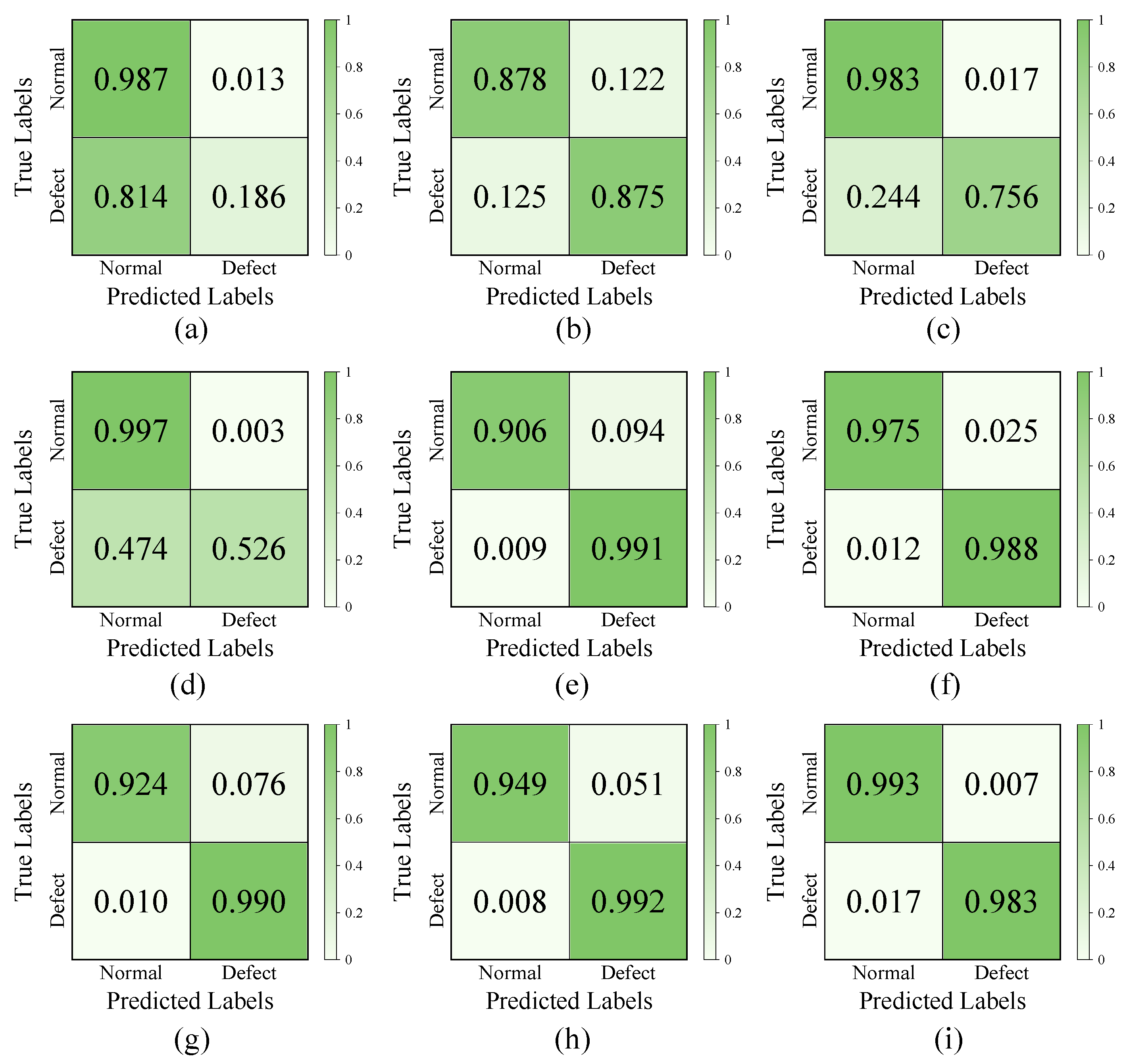
In this study, we solved the concerns of wire rope defect diagnosis issues under various working conditions. Based on the LMA signal, this paper proposed a new CNN-transformer network to improve the overall diagnosis performance. The combination of a CNN and transformer was used for the first time in the wire rope defect diagnosis application field. In addition, the EMD data processing method was introduced to reduce the adverse impact of diverse noise signals. The image processing method was presented for the preparation of the wire rope dataset. TL architecture was proposed as the solution to improve the ability of domain adaptation. Consequently, through comparison experiments, the robustness and effectiveness of the DCNNT model and TL architecture were proven. The results indicate that the proposed method performs well and can balance detection accuracy, diagnosis speed, and computational cost factors. Then, visualization was conducted to understand why the proposed DCNNT model and TL architecture worked well in classification tasks. Finally, the MMD algorithm was used to analyze the transfer feasibility between different groups. In summary, DCNNT can achieve a better performance compared with other diagnostic methods in wire rope defect diagnosis activity, whilst being relatively acceptable to complete model training by a common GPU. TL architecture can avoid the time-consuming retraining procedure and solve the challenges of lacking labeled defect data.
Although the results are encouraging, numerous limitations and challenges remain. Firstly, one of the challenges is how to apply the trained DCNNT model to another mechanical component that presents a considerable discrepancy in MMD, such as gearboxes and pumps. Second, generating a healthy degree, according to the diagnosis results, is difficult because this is the foundation for evaluating the entire mechanical system. In the future, some weighted-based and quantitative methods are recommended to realize the interaction between diagnosis and health evaluation models, such as the introduction of an analytic hierarchy process or the entropy weight method.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}