1. Introduction
With the development of next-generation sequencing (NGS) technology, its massively parallel sequencing ability and high analytical sensitivity have made it an increasingly prevalent tool in diverse fields, such as population genomics, cancer or disease genetics, and DNA data storage [
1,
2,
3,
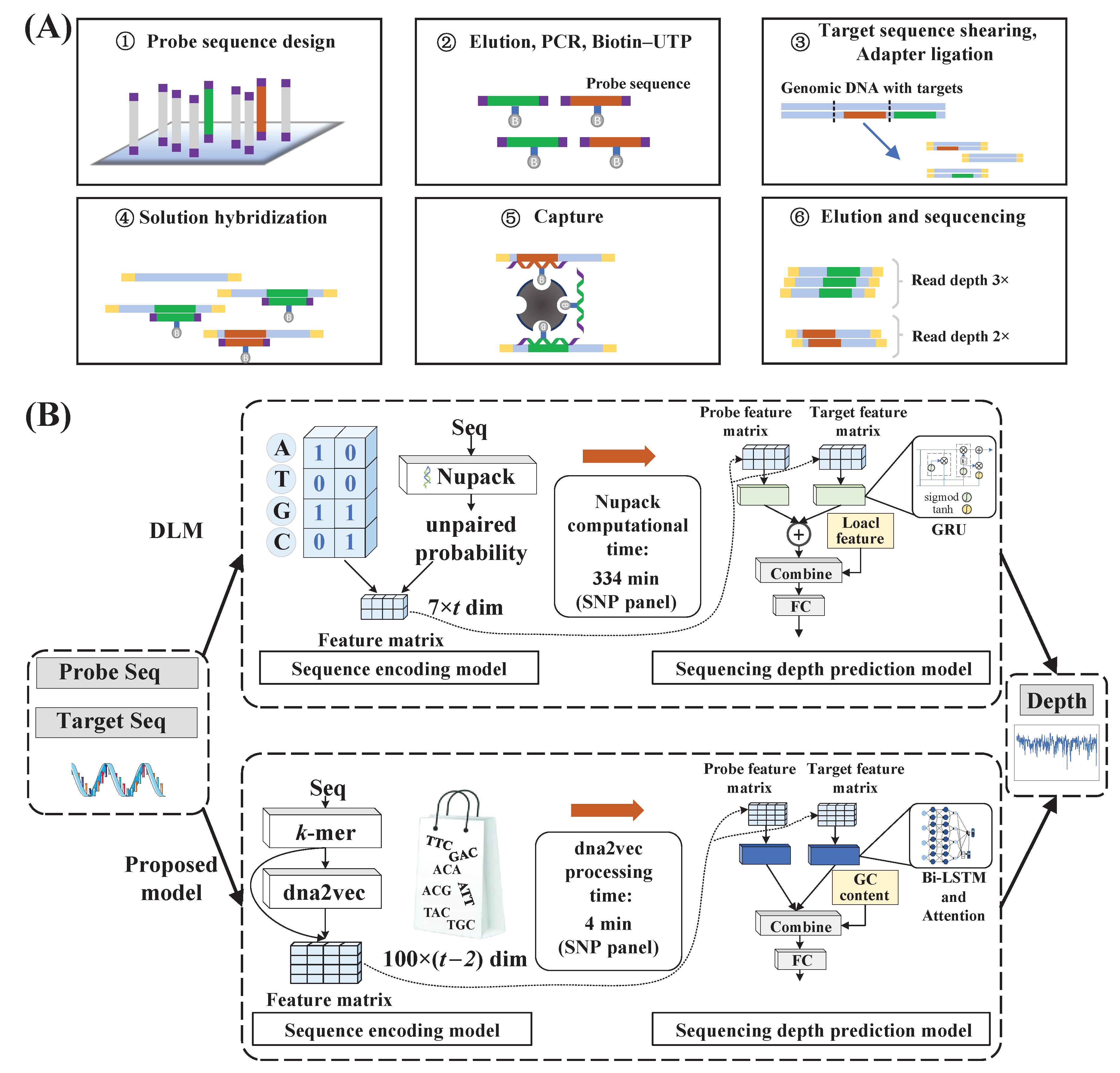
4]. In the realm of genome ecology, there are three main types of NGS sequencing, encompassing targeted sequencing, whole-exome sequencing, and whole-genome sequencing. Targeted sequencing uses probes to enable the process of enriching and sequencing specific regions of DNA [
5], with the work flow shown in
Figure 1A. In next-generation sequencing, probe sequences enable researchers to focus their sequencing efforts on areas of interest by targeting specific genomic regions [
6], thereby reducing the sequencing time and cost associated with analyzing the entire genome. However, the hybridization kinetic properties of the probe structure lead to uneven enrichment efficiency, which results in increased sequencing costs. Therefore, modeling the impact of probe character on enrichment efficiency can aid in the design of probe sequences that ensure a uniform coverage of sequencing depth.
In recent years, some traditional methods based on experience with DNA structure and biochemistry have been presented to optimize probe sequences for specific hybridization between probe and target sequences [
7,
8]. Several studies have shown that the traditional methods are labor-intensive and poorly generalized [
9]. In recent years, deep learning approaches have leveraged diverse neural network architectures to autonomously extract weakly correlated features from large datasets, leading to significant breakthroughs in various scientific domains, including natural language processing (NLP) and computer vision (CV) [
10,
11,
12,
13]. The latest research indicates that deep learning has been successfully applied in the field of bioinformatics for emerging tasks (e.g., protein structure prediction and medical image analysis) [
14,
15,
16,
17]. In the prediction of sequencing depth for targeted sequencing, the short-range and long-range interactions in the sequence can lead to the formation of different secondary structures, affecting the kinetic nature of the hybridization reaction and the efficiency of probe capture. This interaction phenomenon between different regions can be trapped by the recurrent neural network (RNN). The large NGS dataset also offers the possibility of using deep learning to solve this problem.
A deep learning model (DLM) was introduced to predict sequencing depth [
9]. The unpaired probability of each nucleotide in all possible secondary structures of the probe sequence was calculated using Nupack as the local feature [
18]; then, the standard free energy of the probe sequence, the target sequence, and the molecule after hybridization of the probe sequence were calculated as global features. The local feature of each nucleotide with the nucleotide chemical identity (NCP) was used to complete the process of encoding the sequence into the matrix. Four gate-recurrent units (GRUs) were utilized to process the probe and target sequences separately. The processing results were combined with global features and fed into the fully connected neural network to accomplish sequencing depth prediction.
Although the existing deep learning model is effective at predicting the sequencing depth of probe sequences, it suffers from several limitations. (1) The process of using Nupack to calculate the unpaired probability of each nucleotide is time-consuming. Therefore, it is possible to use only a few local features of the sequence, which are derived directly from the sequence itself, avoiding the need for a complex and uncertain thermodynamic calculation process. (2) NCP-based sequence encoding leads to less information input because it only describes the characteristics of the sequence without considering the dependence of nucleotides in the sequence. Thus, the representation of sequences can be achieved with higher-dimensional matrices. dna2vec enables the application of NLP techniques to DNA sequences by using sequence information to acquire the
k-mer distributed representation [
19]. (3) Although the attention mechanism has been widely applied in bioinformatics and possesses a better prediction ability, it has not yet been commonly applied in the field of sequencing depth prediction, so it can be introduced to improve the accuracy of the sequencing depth prediction.
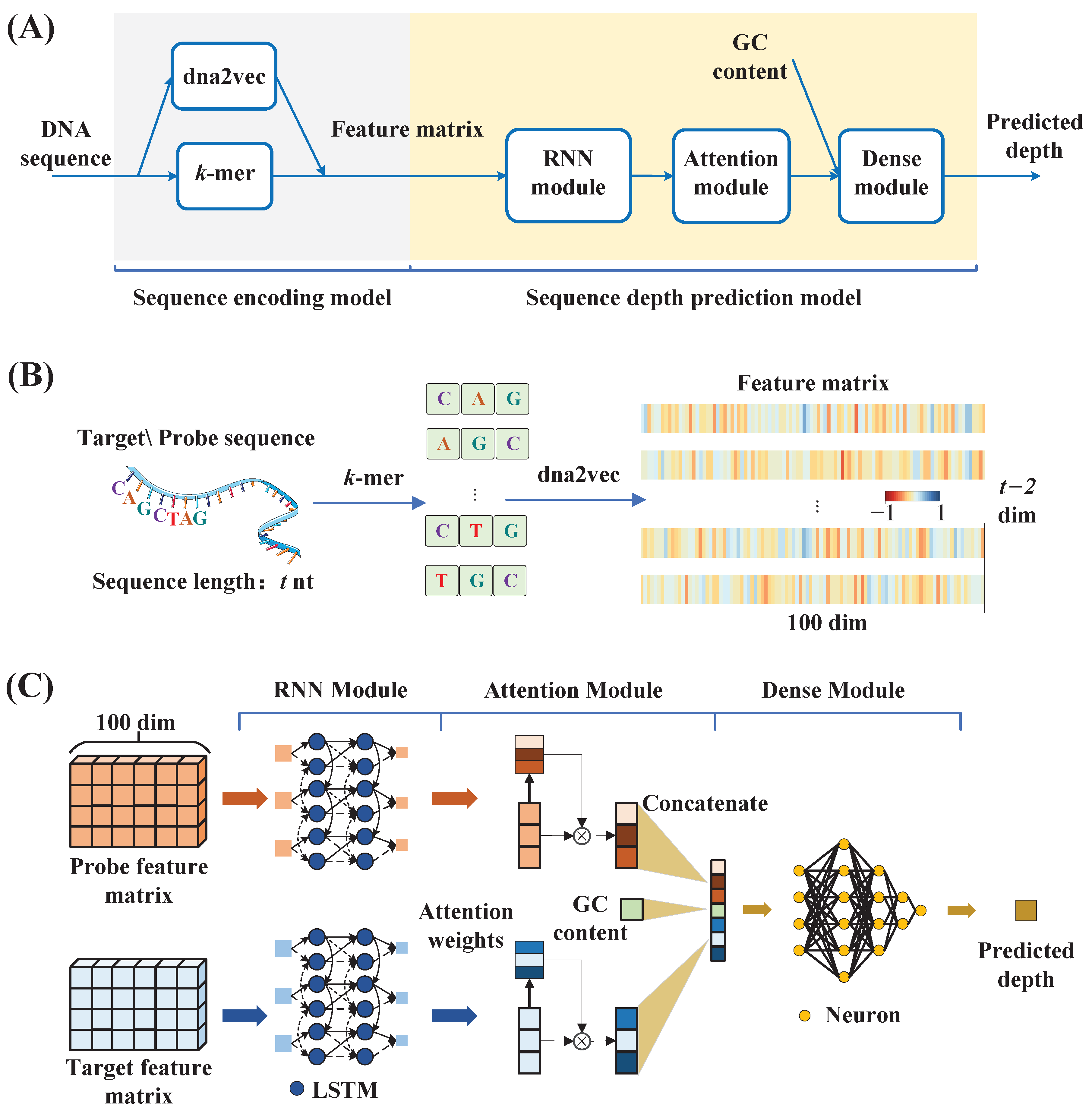
To overcome these limitations, we proposed a low-complexity deep learning model to predict the sequencing depth of probe sequences in targeted sequencing. Specifically, in this model, the target and probe sequences were first split into
k-mer word vector representations using
k-mer processing. Subsequently, the association information between different
k-mer word vectors was extracted from the probe sequences using the dna2vec model to obtain the high-dimensional vector representation of the
k-mer word vectors. The sequences were transformed into distributed representations based on the different high-dimensional vector representation combinations. Then, the Bi-LSTM was utilized to process the sequences sequentially according to base positions, and interactions between adjacent bases (short-range interactions), as well as interactions between bases that were far apart (long-range interactions), were captured as output for subsequent processing. Later, the attention mechanism was employed to process the output of the Bi-LSTM. Its ability to represent the different effects of nucleotides at different positions on sequencing depth by setting different weights allowed the model to selectively focus on positions that were more important for sequencing depth prediction. Finally, the predicted log sequencing depth was derived through a deep neural network.
Figure 1B provides an overview of the DLM and the proposed sequencing depth prediction model.
3. Results
In this section, the performance of the proposed model is discussed. Similar to previous work, the discussion is based on three benchmark datasets, lncRNA, and SynDNA, which contain different design and application directions. We relied on these datasets as the foundation of our research and aspired to offer guidance for future related studies.
3.1. Comparison of Sequence-Encoding Methods
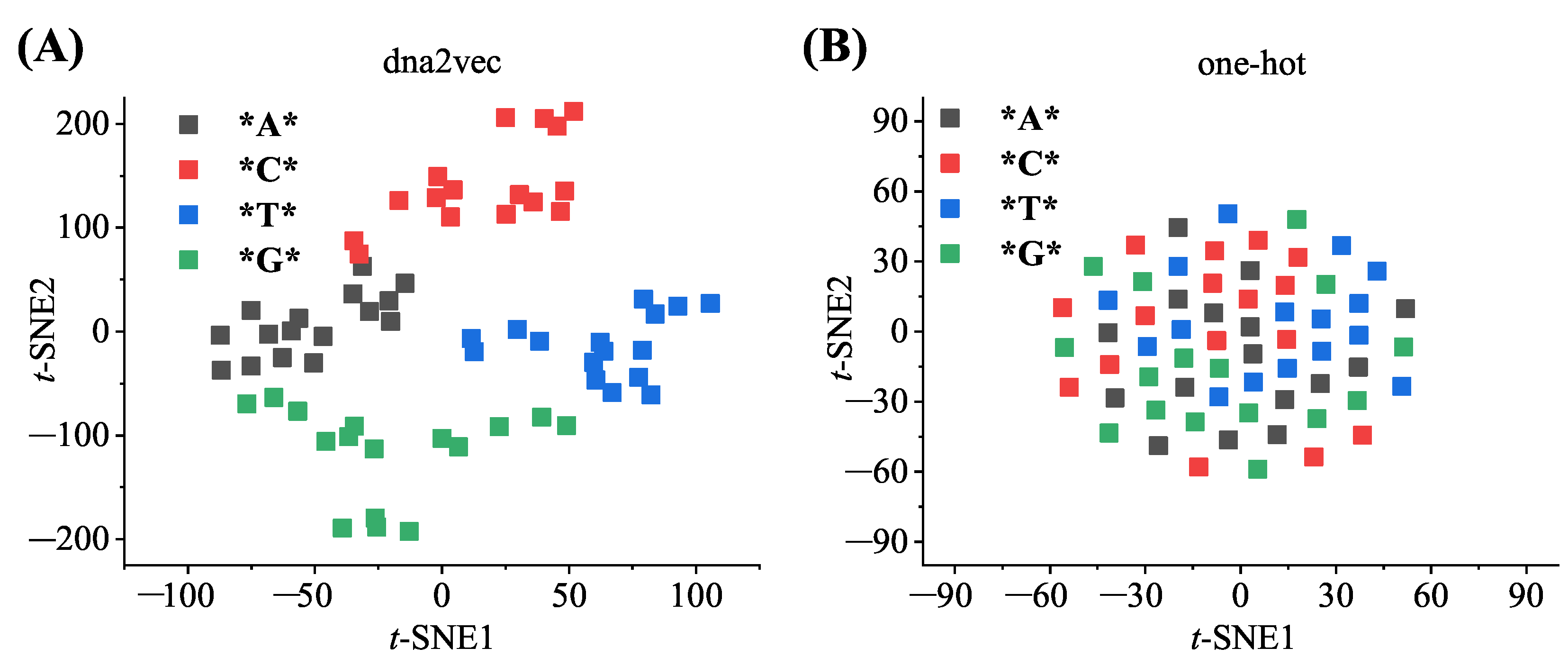
To verify the advantages of dna2vec in transforming DNA subsequences into a distributed representation, a commonly used one-hot encoding method [
32] was chosen for comparison with the dna2vec method. As one-hot encoding uses the sparse feature vector to represent each
k-mer word, each
k-mer word corresponds to a separate vector space, and each separate space is linearly independent. In contrast to the dna2vec method, the one-hot encoding method cannot infer the connections between
k-mer words for deeper association mining. The data visualization tool
t-SNE was used to cluster the word vectors obtained by different encoding methods.
Figure 4 shows the clustering effect of the three-mer word vectors based on dna2vec and one-hot encoding, and different three-mer vectors according to the nucleotide species at the central position are plotted. In the figure, the dna2vec-based encoding method better clustered similar word vectors, and their local clusters were clustered into larger clustering groups based on the same central nucleotides.
3.2. Parameter Optimization
The model parameters were trained using a 20-fold cross-validation method to comprehensively assess the proposed model. The dataset was divided into 20 folds, with 19 folds serving as the training set and 1 fold serving as the prediction set. This process was repeated 20 times, and the results were aggregated after 20 rounds of cross-validated predictions to obtain the prediction accuracy of our network.
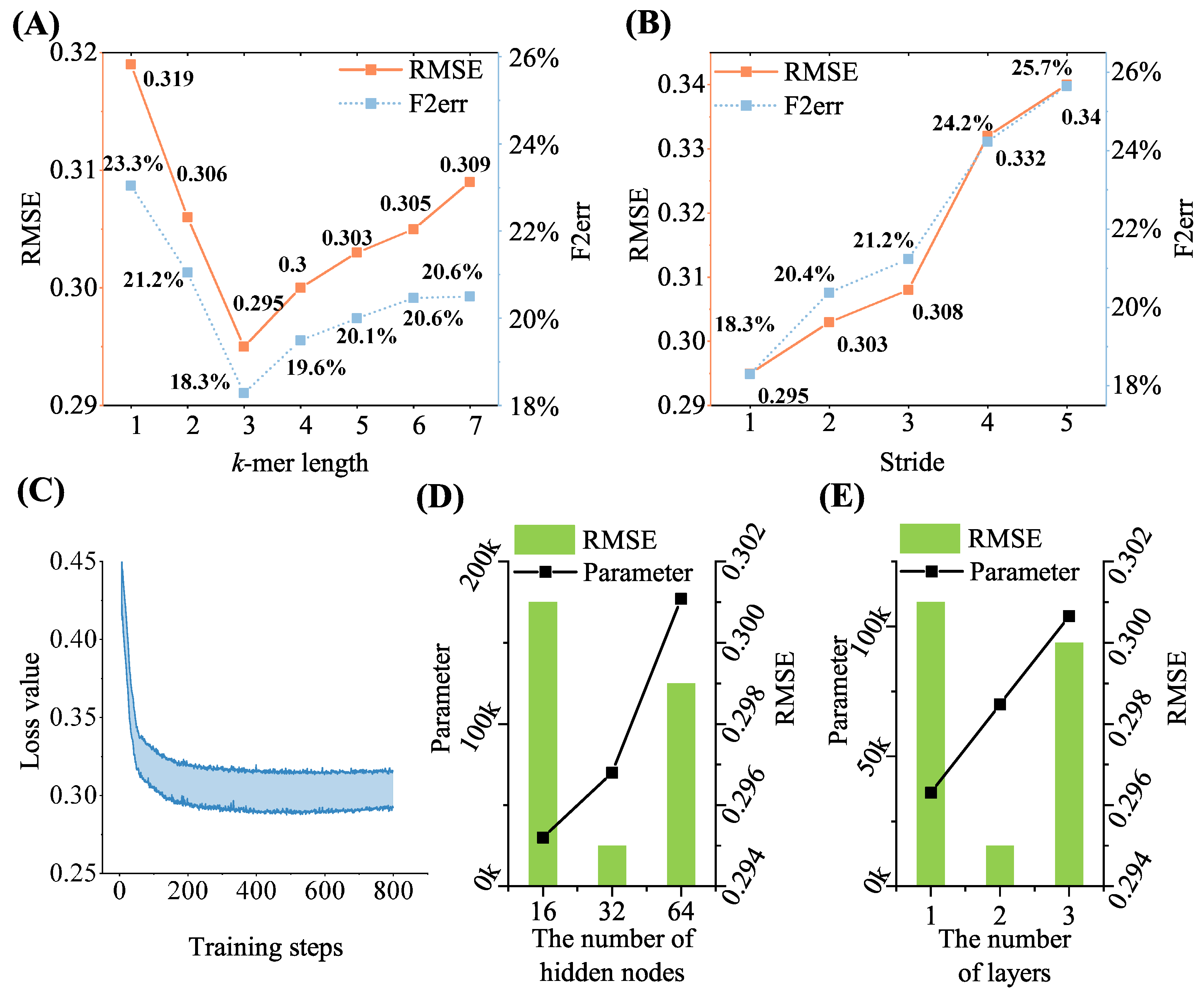
To acquire the best-distributed representation of the sequences, the performance of the proposed model was tested with different step size (
s) and
k values. As depicted in
Figure 5A, the performance of the model was the best when
k was 3. This result can be attributed to the fact that in biology, an amino acid comprises three bases, and the process of segmenting a sequence into word vectors with
shares a similar characteristic with this phenomenon. Then,
k was set to 3, and the effect of different values of
s on performance was tested. As
Figure 5B indicates, the model’s performance deteriorated as the step size increased. Longer step lengths could lead to a loss of sequence information. This might result in a degradation of prediction performance. Therefore, the values of
k and
s were set to 3 and 1, respectively, during the following experiments on model performance calculation. On an Intel(R) Xeon Gold 5220R CPU with a maximum frequency of 2.2 GHz, the CPU times required to generate sequence representation using DLM and the proposed model were compared. Based on the SNP dataset, the process of generating three-mer sequence representation took only 4 min of CPU time, significantly reducing the transformation processing time from sequence to distributed representation compared to the DLM (334 min of CPU time).
The proposed model was completed with the PyTorch framework on an NVIDIA A6000 GPU server [
33]. The model was trained with a batch size of 2560, and the initial learning rate was set to 0.0001. During the training process, RMSE was utilized to calculate the loss value between the predicted results and actual labels, and the adaptive moment estimation (Adam) algorithm was used to optimize the gradient descent [
34]. The training process of this model is illustrated in
Figure 5C. By observing the change in the loss value with the number of iterations, it was found that the loss value of the validation set started to increase at 450 rounds or more, indicating that the overfitting phenomenon had started to occur; therefore, the number of iterations was set to 450.
Figure 5D,E illustrates the process of setting the number of hidden nodes and layers in a Bi-LSTM network, and the two-layer Bi-LSTM network with 32 hidden nodes is the optimal model. Setting more hidden nodes and deeper layers in the Bi-LSTM could lead to overfitting of the model, while a one-layer network or a smaller number of hidden nodes could lead to a lack of information acquisition. Compared to the four three-layer GRU networks with 128 hidden nodes used in the DLM, the number of parameters was reduced in the proposed sequencing depth prediction model because the sequence representation obtained through the
k-mer and dna2vec in the sequence-encoding module contained more sequence information.
3.3. Predicted Results
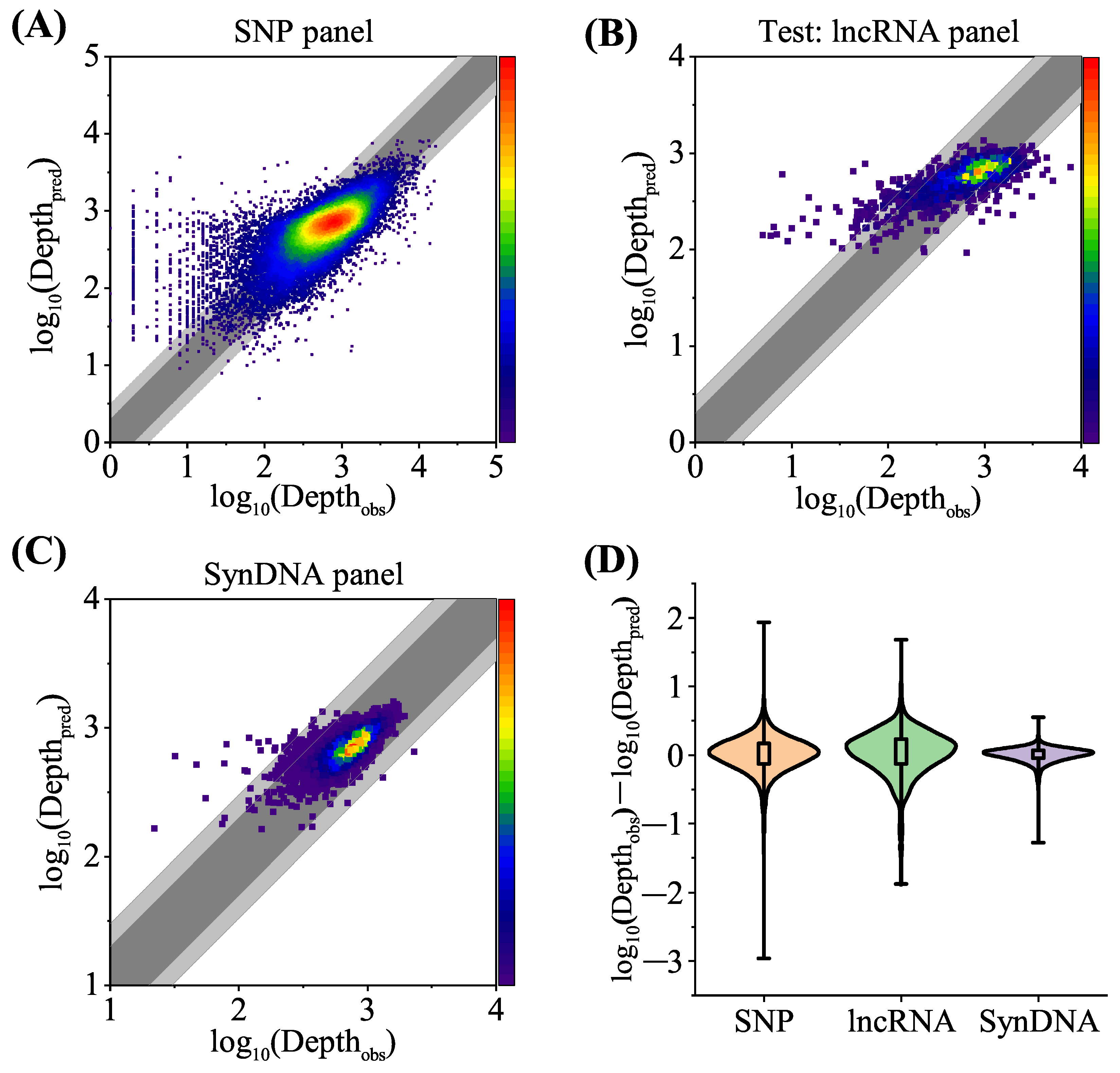
Figure 6A–C depict a comparison of the predicted and observed sequencing depth for the different datasets. The dark gray shading marks areas where the difference between the predicted sequencing depth and observed actual read depth was within a multiple of two, and the light gray indicates where the difference was within a multiple of three.
Figure 6A shows the combined results of the SNP dataset after 20-fold cross validation. At a sequencing depth of 100 and above (i.e.,
Depth
, the points combining predicted and observed depth were densely distributed in the gray area. Sequences with a lower observed sequencing depth in the SNP dataset had a
Depth
) of between 1 and 3.5, while the majority of these probes had a lower GC content (average GC content of 0.31 for sequencing depth less than 100 and 0.45 for sequences depth greater than 100). An explanation for this phenomenon is that probes with a lower observed sequencing depth (such as a lower GC content) were more affected by random fluctuations in the experimental procedure, which could also affect the sequencing depth [
9]. This also illustrates the importance of using GC content as an input to the dense module in the neural network.
To prove the effectiveness of the model in practical application scenarios, such as using the existing model to optimize the new probe design, the lncRNA dataset was taken as a prediction set from the SNP dataset, and the read depth of lncRNA was predicted through the model trained on the SNP dataset. It should be noted that although the lncRNA dataset and the SNP dataset had similar library preparation methods in terms of experimental work flow, hybridization temperature, and other relevant aspects, they differed in terms of the experimental operator, instrumentation, and reagents. In this study, the model obtained from a single fold of the 20-fold cross-validation process on the SNP dataset was employed to directly predict the probe log sequencing depth for the lncRNA dataset.
Figure 6B displays the results of the lncRNA dataset generated from the proposed model trained on the SNP dataset. The proportion of points within the light gray region was marginally lower in the lncRNA compared to the SNP, and this decline might have been caused by the experimental changes associated with library preparation methods and other factors. However, because the proposed model only used the model trained in one fold of the SNP training process to predict the lncRNA log sequencing depth, this significantly reduced the cost of the sequencing probe design and prediction. The results of the lncRNA dataset show that the proposed model can predict the sequencing depth of probes obtained by similar library preparation methods to enable the generalization of method availability.
Figure 6C shows the SynDNA dataset prediction results of probes applied in DNA information storage. The points in the figure are mostly concentrated within the gray area. The generation of these sequences by the program led to a reduction in the probability of high or low GC content, hairpin structures, and homopolymers, which resulted in a more focused distribution of sequencing depth and enhanced prediction performance.
Figure 6D shows the deviation between the predicted and observed log sequencing depth in different datasets. On each box whisker plot, the bottom of the box represents the 75th percentile, the top edge represents the 25th percentile, and the whisker length refers to the maximum and minimum values of the difference between the observed and predicted depths.
3.4. Performance Comparison with Other Methods
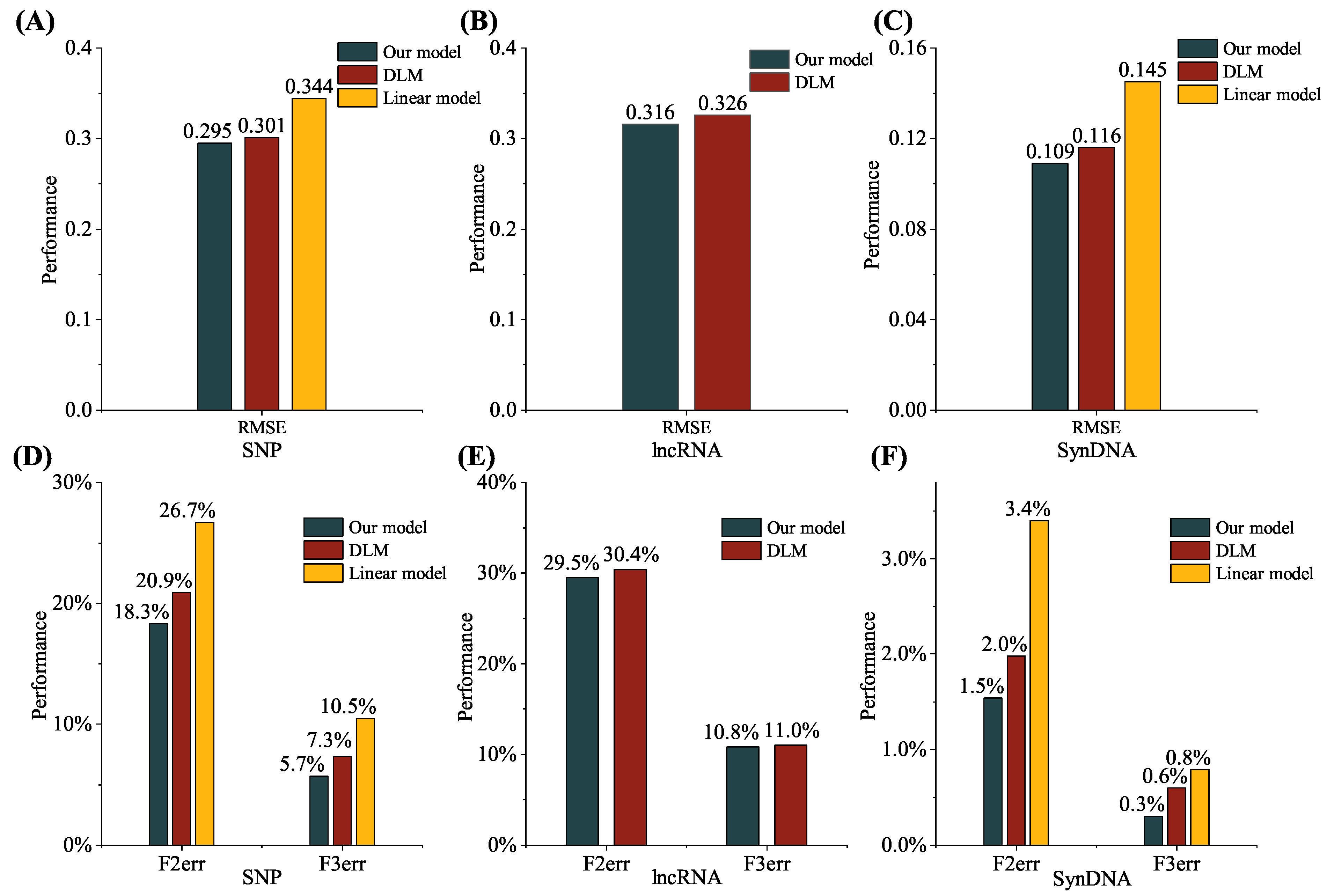
To better evaluate the performance of our model,
Figure 7 demonstrates a performance comparison of different networks on three different datasets. F2err and F3err were applied to determine the proportion of sequences for which the error between the predicted and observed sequencing depth exceeded twofold and threefold, respectively, where RMSE represents the root mean square error across the dataset. The DLM and the linear model were employed for comparison with the proposed model. The DLM used the GRU network were used to process the target and probe sequences for sequencing depth prediction. The linear model used four biochemical features calculated by Nupack as input to predict the sequencing depth. The sequencing depth prediction performance for all competing methods was obtained from their respective papers.
As demonstrated in
Figure 7, our model outperformed the DLM and the linear model in terms of RMSE, F2err, and F3err metrics on both the SNP and SynDNA datasets (F2err of 18.3%, F3err of 5.7%, and RMSE of 0.295 on the SNP dataset and F2err of 1.5%, F3err of 0.3%, and RMSE of 0.109 on the SynDNA dataset), indicating that better predictions were achieved for different types of probes. Our model also performed slightly better than DLM in predicting the sequencing depth of the lncRNA dataset using a onefold model trained on the SNP dataset (F2err of 29.5%, F3err of 10.8%, and RMSE of 0.316 on the lncRNA dataset). This suggests that it could achieve a better prediction performance for probes that use similar library preparation methods to predict their sequencing depth. The performance improvement can be attributed to the distributed representation of the sequence, as well as the utilization of Bi-LSTM and attention modules, to capture the long-range and short-range interactions in the sequences.
3.5. Ablation Experiments and Reliability Analysis
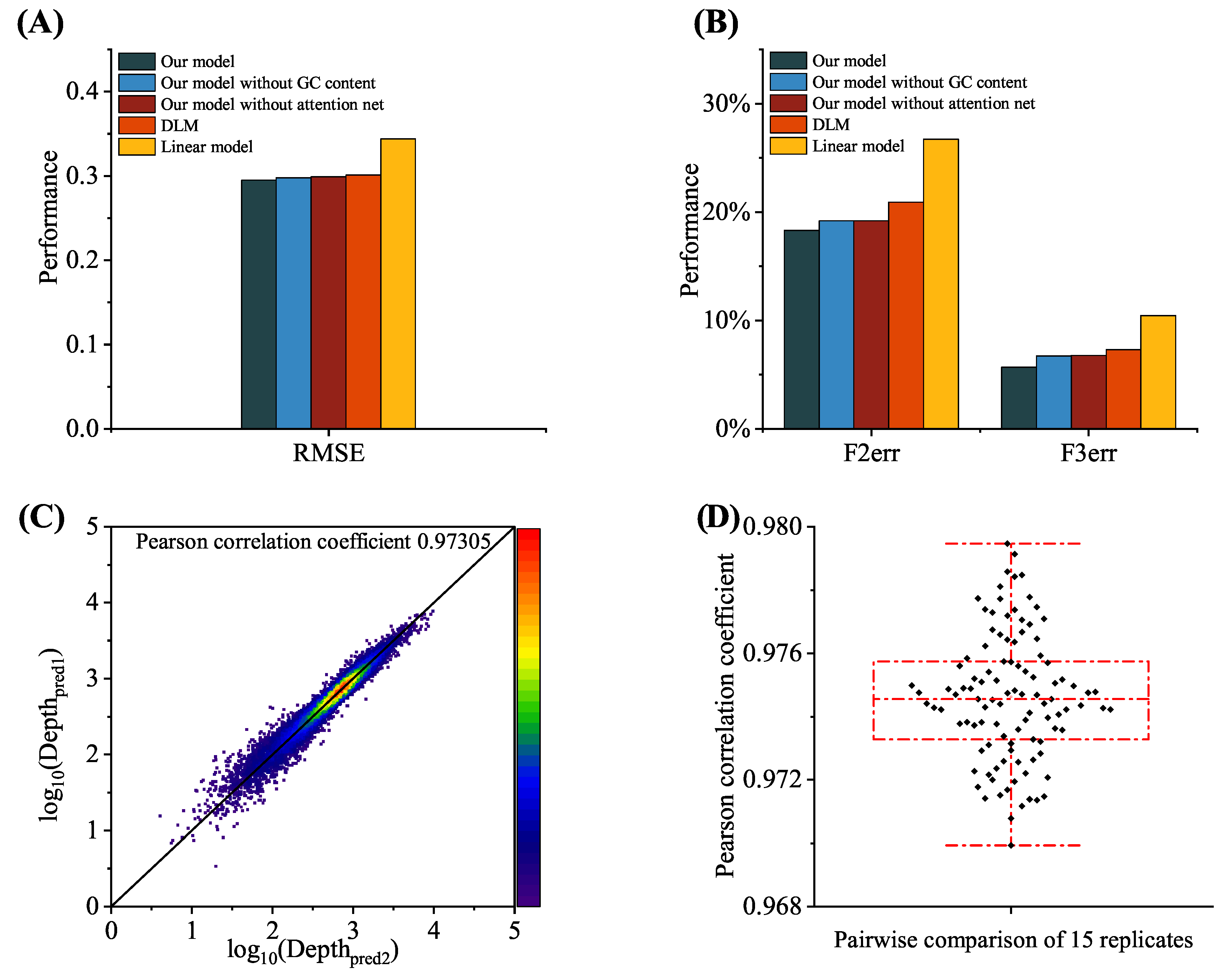
To verify the design superiority of the proposed model, two simplified models were compared with the proposed model using ablation experiments: our model (no GC feature) and our model (no attention).
Figure 8A,B and
Table 1 present the performance results on the SNP dataset. Further analysis showed that the use of different modules resulted in different performance improvements. The GC content increased the amount of input information for the existing model and was related to the sequencing depth. The attention mechanism extracted the effect of different regions of the input sequence on the sequencing depth. Based on performance comparisons, the model using the attention mechanism with GC content achieved the best prediction performance.
As shown in
Table 1, there are 70 k trainable parameters in the proposed sequencing depth prediction model, which is significantly less than the DLM (300 k in total), with the reduction in parameters mainly stemming from optimization of the number of hidden nodes and the number of network layers in the RNN module. The reduction in the number of parameters did not have a negative impact on prediction accuracy. Experiments conducted on publicly available data illustrate that the proposed model outperformed the DLM, as described in
Figure 7. However, due to the large number of model parameters, to verify the robustness of the model and avoid overfitting phenomena or non-reproducibility being caused by too many parameters, several rounds of independent experiments were set up, verifying that the prediction results were highly consistent. The proposed model training process was repeated 15 times on the SNP dataset. Each round of training started with random parameters and stopped after 450 rounds.
Figure 8C shows the comparison results of the log sequencing depth predictions from two independent prediction rounds. As presented in
Figure 8D, Pearson’s
r values for all 105 pairwise comparisons exceeded 0.970, which demonstrates that despite the difference in parameter initialization across independent experiments, the proposed model still generated relatively consistent prediction results.
4. Discussion and Conclusions
Targeted high-throughput sequencing of DNA has emerged as a superior technique in biomedical research. Although the cost of NGS has decreased exponentially over the years, the problem of poor sequencing uniformity remains a significant issue. Inefficient sequencing of high-depth targets and insufficient coverage of low-depth targets can result in a wasteful use of reads. Therefore, a low-complexity targeted sequencing depth prediction model was proposed in this paper to provide guidance for probe sequence analysis work. In this study, we implemented the prediction function of sequencing depth prediction using probe sequences. Our innovation can be summarized as follows. (1) A distributed representation of k-mer was trained using the word-embedding model, and a sequence-encoding model was constructed to realize the representation process from sequences to feature matrices. (2) The sequencing depth prediction model based on Bi-LSTM with ab attention mechanism was proposed to realize the sequencing depth prediction result of generating sequences from the feature matrix representation of probe sequences. Our model used a new sequence-encoding process that only took 4 min of CPU time for the SNP dataset. Compared with the complex biochemical calculations in DLM, our process was more efficient and convenient. The network architecture was optimized, and the parameters were reduced from 300 k to 70 k, which reduced the risk of overfitting. The prediction accuracy was improved based on the different datasets compared with the linear model and the DLM. The proposed model predicted the difference between predicted and observed sequencing depths with an F3err of 5.7% for SNP and 0.3% for SynDNA.
In conclusion, our model provides a practical solution for prediction of the sequencing depth of the probe sequence. In future work, the proposed model can be transferred and extended to other bioinformatics tasks. For example, the proposed model can be extended by constructing corresponding datasets and combining other types of features. The intermolecular interactions that occur between a large number of sequences in solution during target capture are modeled and analyzed to assess their impact on sequencing depth. Meanwhile, we can attempt to introduce a transformer [
35] to optimize the existing sequencing depth prediction model to address the potential vanishing gradient problem of existing RNN models when sequentially processing long sequence information.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}