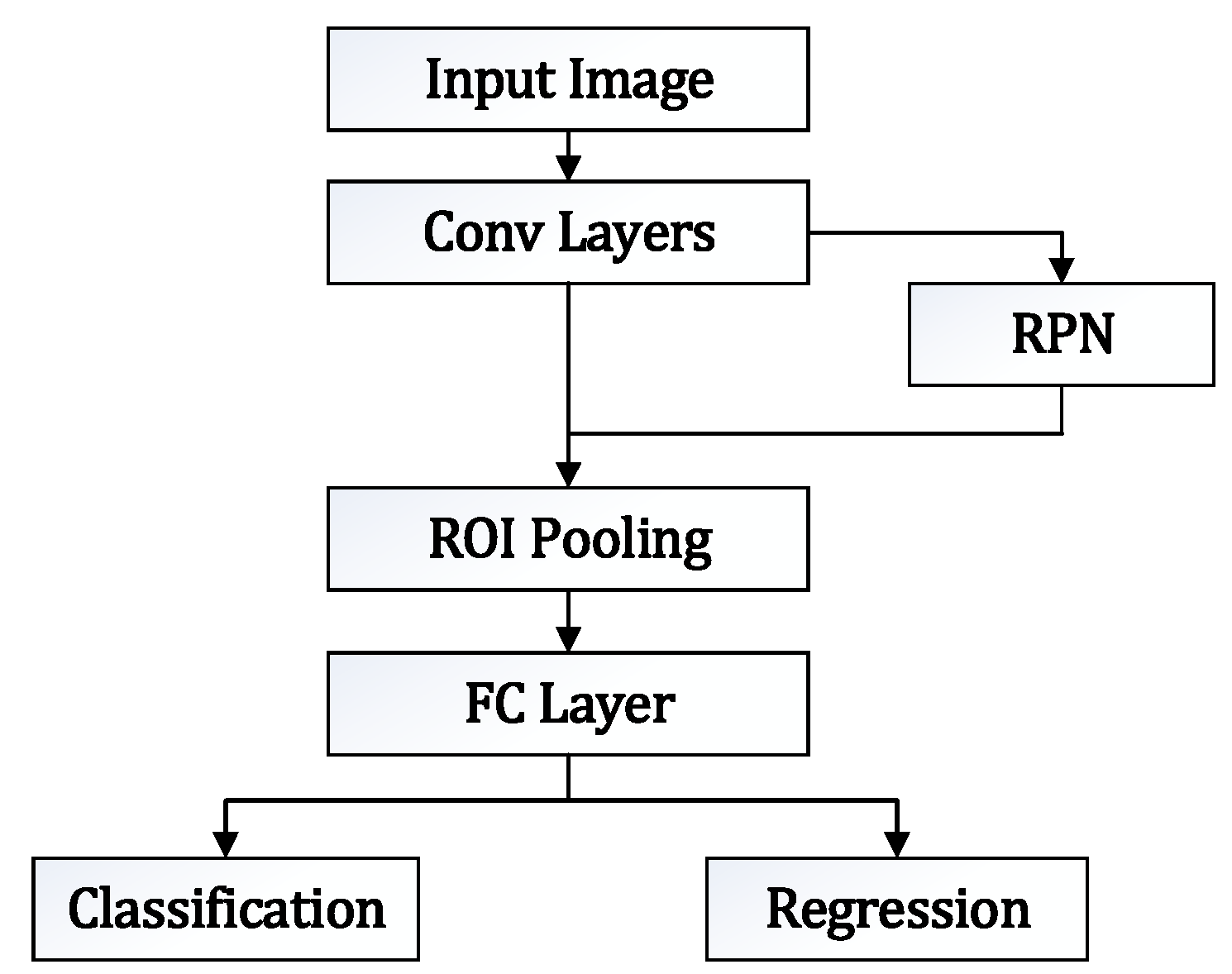
3.1. Faster RCNN Model Design
Faster RCNN is a classic network proposed by Girshick in 2015 [
18]. It consists of four modules, namely the feature extraction network module (Conv layers) [
19], Region Proposal Network (RPN) [
20,
21] module, ROI Pooling [
22] module, and Classification and Regression [
23] module. The frame diagram of Faster RCNN is shown in
Figure 1.
After the original image is input, the shared convolution layer computes it. The results can be shared with the RPN. RPN makes region suggestions (about 300) on the feature map after convolutional neural network (CNN) convolution, extracts feature maps according to the region suggestions generated by RPN, performs ROI pooling on the extracted features, then classifies and regresses the processed data through the full connection layer.
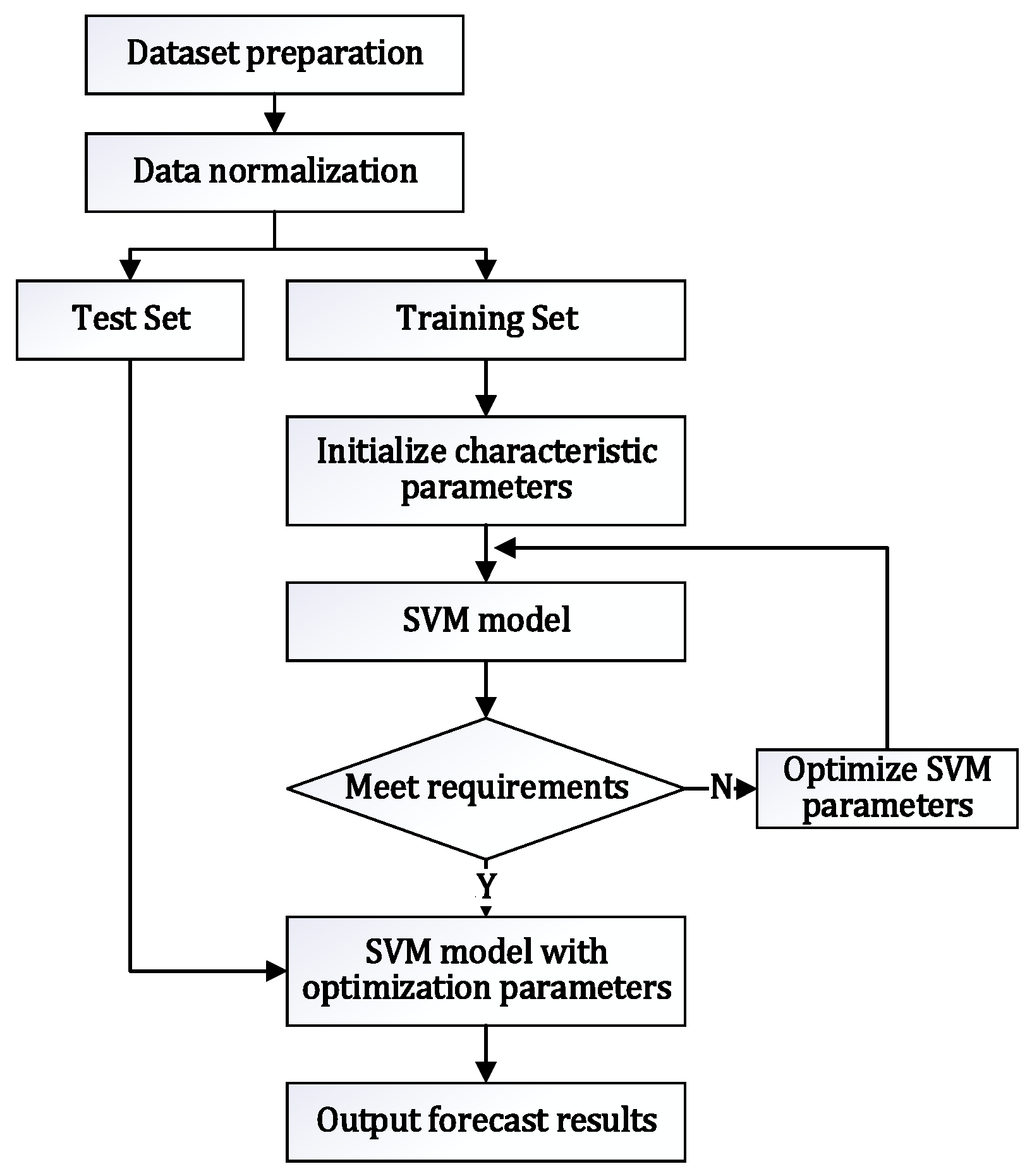
The feature extraction network module [
19] is an important part of the Fast RCNN algorithm. The flow of the feature extraction module is shown in
Figure 2.
After normalization, the prepared dataset is divided into the training set and the test set. When the training set is trained by the Support Vector Machine (SVM) [
24] model, better parameters are obtained by iteration, and finally, the SVM model meeting the requirements is obtained. The test dataset is input into the optimized SVM model, and the output result is finally obtained.
VGG16 is used as the feature extraction network in Faster RCNN. To break through the bottleneck of region selection in the predecessor target detection model, the new Fast RCNN algorithm model innovatively proposes the RPN algorithm, replacing the selective search (SS) [
25] algorithm model used in Fast RCNN and RCNN, that is, the Faster RCNN algorithm can be understood as RPN + Fast RCNN. The SS algorithm is a simple image processing without a training function. RPN is a fully convolutional network, and its first several convolutional layers are the same as the first five layers of Faster R-CNN, so RPN can share the calculation results of convolutional layers to reduce the time consumption of region suggestions. The RPN module is used to replace the candidate region selection mode of the original SS algorithm, thus greatly reducing the time cost. RPN selects candidate regions according to image color, shape, and size, and usually selects 2000 candidate boxes that may contain identification objects.
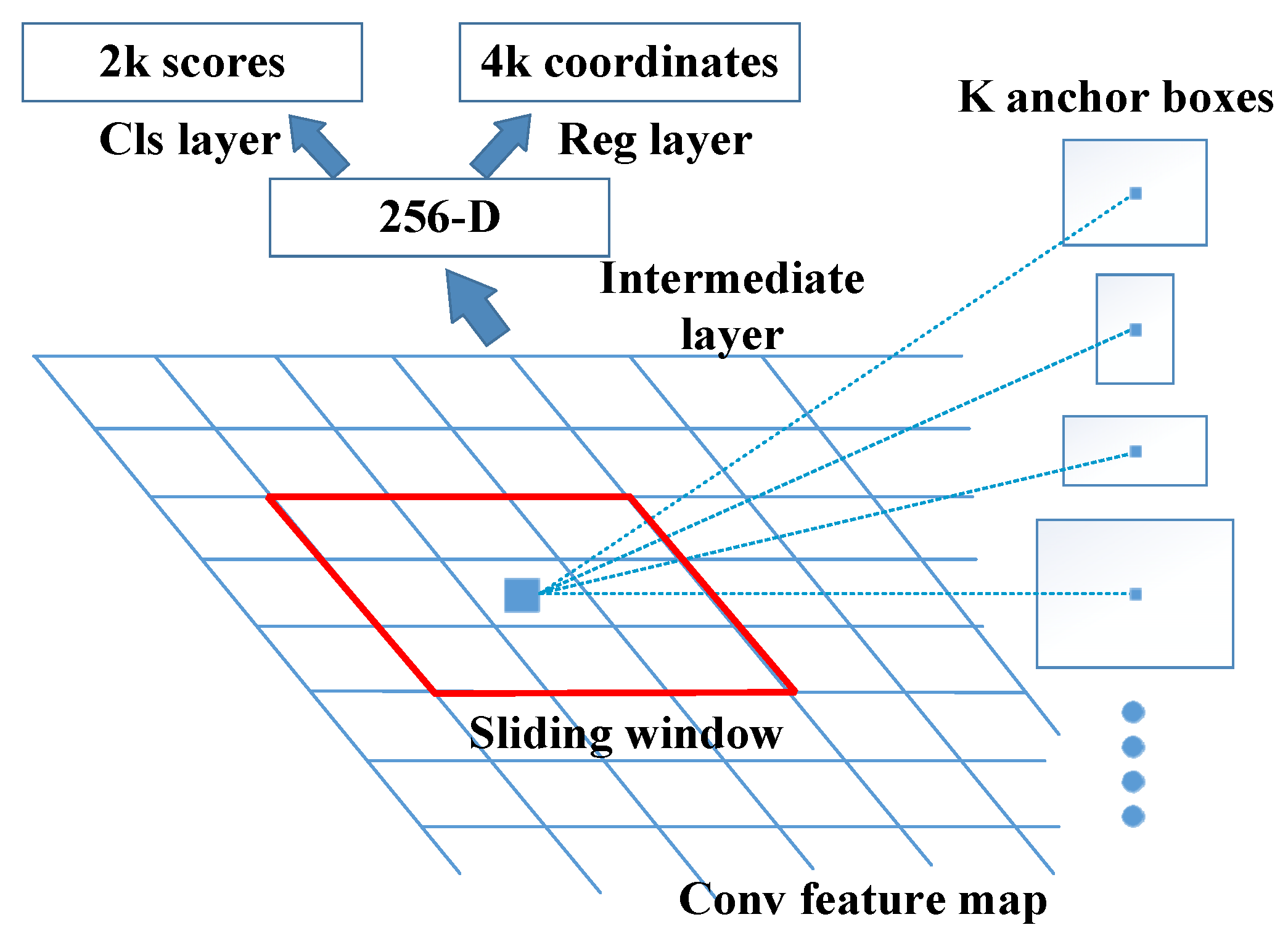
When the detected image is input to the feature extraction network module, the feature image is generated after the module convolution operation, and it is input to the RPN module to select candidate regions. This module uses the center point of the sliding window as the anchor. All the pixels in the feature picture correspond to k anchor points, generating 128-, 256-, 512-pixel areas and 1:1, 1:2, and 2:1 scale windows, respectively. The combined result is a total of 9 windows, as shown in
Figure 3.
The generated candidate area and convolution layer feature map are input to the ROI Pooling module. ROI Pooling pools feature maps of different sizes into a uniform size, which facilitates their input to the next layer. Following the ROI Pooling module, the target classification and position regression module processes the data output from the ROI Pooling layer to obtain the object category of the candidate area and the modified image block diagram, and its processing formula can be expressed by Formula (1).
where
,
,
, and
are the horizontal and vertical coordinates and the width and height values of the candidate box center pixel, respectively;
,
,
, and
are the regression parameters of
N + 1 categories of candidate boxes, with a total of 4 × (
N + 1) nodes; exp is an exponential function with the natural number
e as the base.
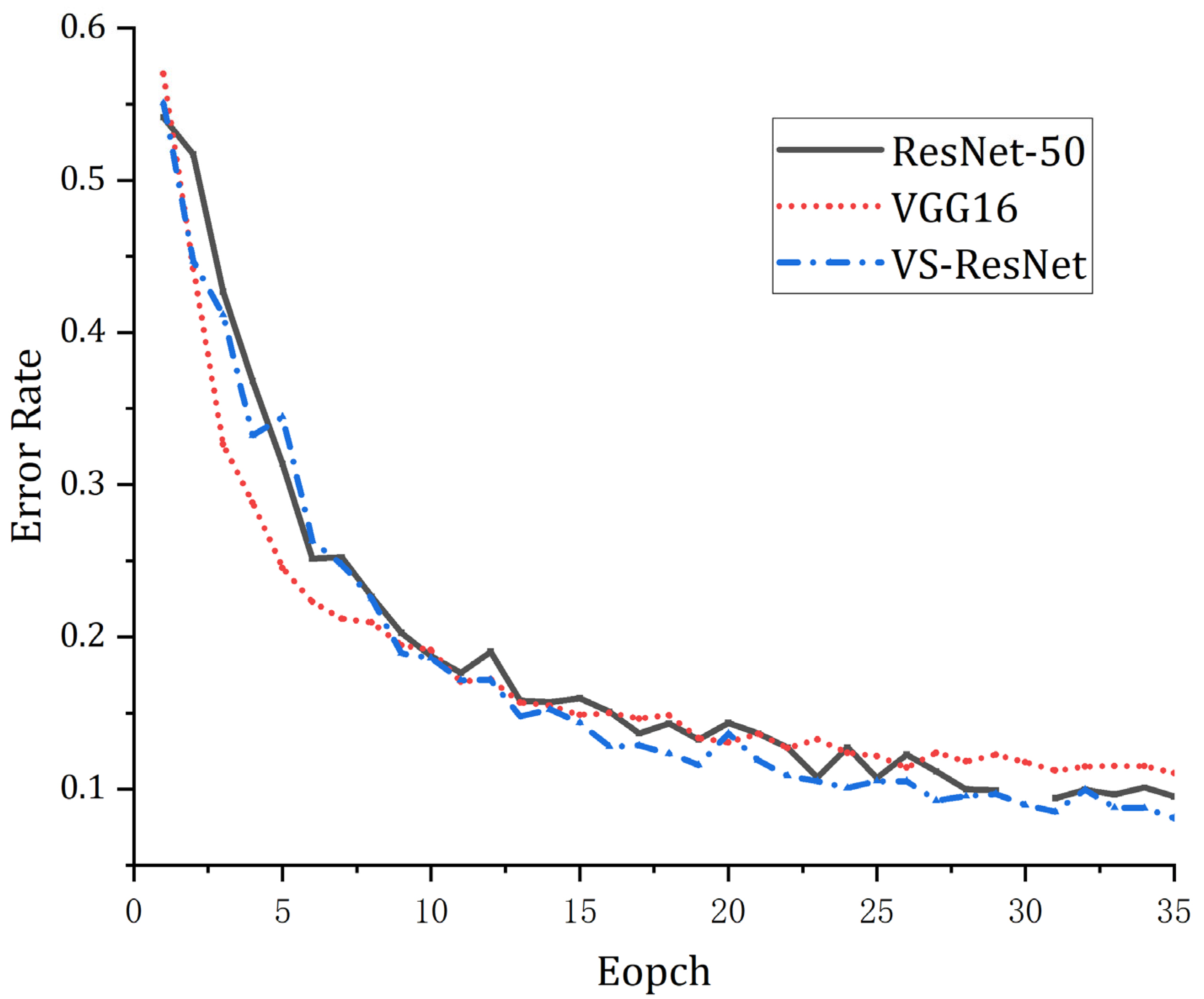
To solve the problem of weak expression ability of the VGG16 network due to its small number of layers, the VS-ResNet network is used to replace the VGG16 network. The VS-ResNet network is based on the ResNet-50 network improvement. In the original Faster RCNN, the CBAM attention mechanism and FPN feature pyramid structure are integrated to enhance the detection capability for small truncated or occluded objects. The specific improvement process is as follows.
3.2. Design of Group Convolution and Inverse Residual Structure
The structure of the packet convolution network refers to the multi-dimensional convolution [
26] combination principle of Inception, which changes the single path convolution kernel convolution operation of the characteristic graph into a multi-channel convolution kernel convolution stack, reducing the parameters in the network and effectively reducing the complexity of the algorithm model, but its accuracy will not be greatly affected. VS-ResNet refers to the ResNeXt network [
27] and uses 32 groups of 8-dimensional convolutional cores.
When a deep convolution network is used for convolution, the convolution parameter of the partial convolution kernel is 0, which results in partial parameter redundancy. The experiment proves that when the dimension is too low, too much image feature information of the Re
LU activation function is lost. The Re
LU function is shown in Formula (2).
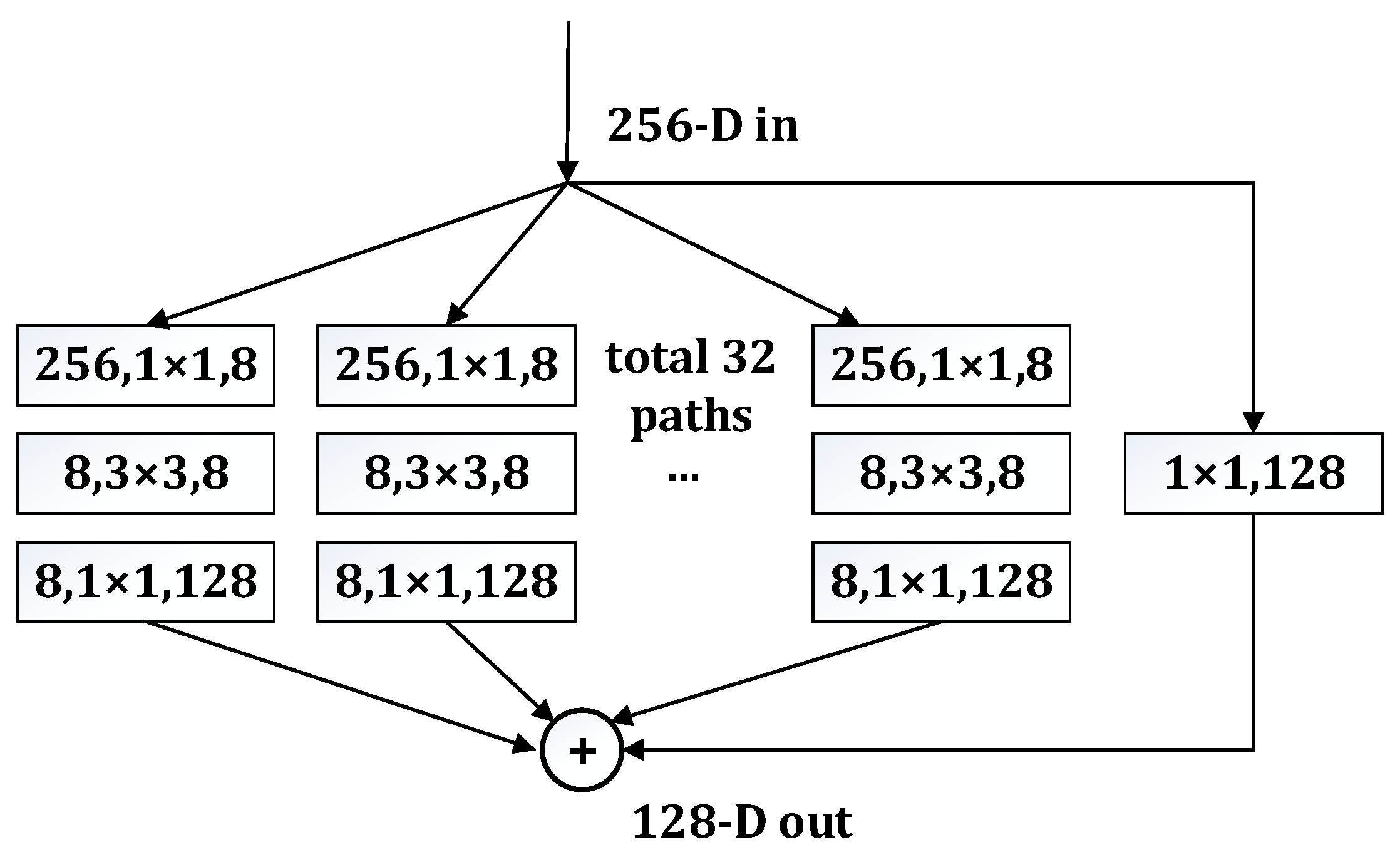
To solve this problem, the VS-ResNet network uses a reciprocal residual structure, with convolution kernel sizes of 1 × 1, 3 × 3, and 1 × 1, as shown in
Figure 4.
The common residual structure is first based on the output basis of the previous layer, using 1 × 1 convolution-kernel-size dimension reduction. Convolution kernels of 3 × 3 size are passed again to extract image features; lastly, dimension elevation of convolution size 1 × 1 is used. Unlike the ordinary residual structure, the inverted residual structure has exactly the opposite order of dimension increase and dimension reduction, that is, 1 × 1-size convolution is first used to increase the dimension. Additionally, you have a 3 × 3 convolution. Finally, a 1 × 1 convolution kernel is used to reduce the dimension to the original feature map size. When the ReLU function is activated linearly in the
region, it may cause the function value to be too large after activation, thus affecting the stability of the model. The ReLU function does not limit output, allowing very high values on the positive side. However, ReLU6 limits the value of the positive side to 6, which can eliminate most of the value, so VS-RCNN uses the RELU6 function instead of the ReLU function, as shown in Formula (3).
3.3. Reference to Auxiliary Classifier
With the deepening of the network, the convergence of the feature extraction network becomes more difficult. It is necessary to retain a certain degree of the front-end network propagation gradient to alleviate the gradient disappearance. VS-ResNet adds an auxiliary classifier [
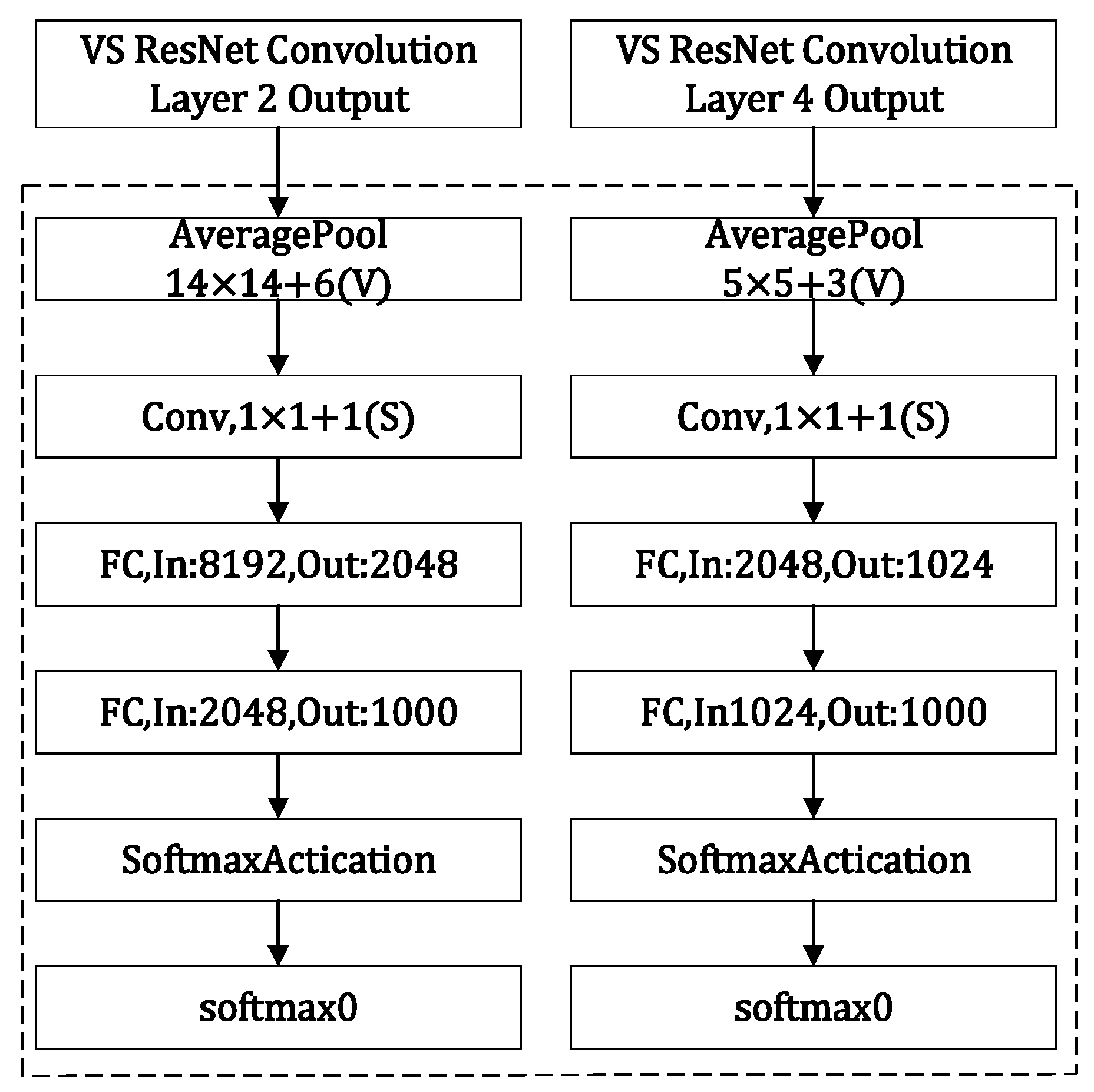
28] after convolution layer 2 and convolution layer 4 of the ResNet-50 network, respectively to retain the low-dimensional output information of convolution layer 2 and convolution layer 4. In the final classification task, combined with the actual application, a fixed utility value is set and shallow feature reuse is used for auxiliary classification. The utility value of the auxiliary classifier in the VS-ResNet network is set to 0.1. The auxiliary classifier consists of an average pooling layer, a convolution layer, and two full connection layers, as shown in
Figure 5. After the image is extracted by convolution layer 2 in ResNet-50, a feature map is generated and input to the first auxiliary classifier. Firstly, the number of network parameters is reduced by an average pooling downsampling layer, which uses a pool size of 14 × 14 with a step distance of 6. Then, the convolution layer is entered, which uses 128 convolution kernels of 1 × 1 with a sliding step of 1. The results are then flattened and fed into the fully connected layer that follows this layer.
Dropout [
29] at 50% is performed in two fully connected layers to prevent overfitting. Some parameters of the second auxiliary classifier are different from those of the first auxiliary classifier. The size of the pool is 5 × 5 instead of 14 × 14, and the step distance is changed from 6 to 3, which is based on the position of the auxiliary classifier in the convolutional neural network. The input of the two fully connected layers is 2048 and 1024 neurons, respectively. The output results of the two auxiliary classifiers are multiplied by the utility ratio set in VS-ResNet and then added to the final classification result. The addition of the auxiliary classifiers increases the gradient of network backpropagation and alleviates the phenomenon of gradient disappearance.
3.4. Detailed Structure of VS-ResNet Network
For the feature extraction network module, VS-ResNet changes the residual block structure from a funnel model to a bottleneck model, so that the activation function information can be better preserved, as shown in
Table 2. Referring to the structural parameters of ResNet-50, the number of convolution channels of the first residual structure is changed from the original [64,64,256] to [256,256], and the last three residual structures are also modified successively from [128,128,512] to [512,512,256]. [256,256,1024] is [1024,1024,512] and [512,512,2048] is [2048,2048,1024]. The group convolution method is referenced in the inverted residual structure, and the number of groups is set to 32. By referring to the model of the Swin Transformer algorithm [
30], the original hierarchical structure [3,4,6,3] is modified to [3,3,9,3], and auxiliary classifiers are added after the second and fourth layers to accelerate the convergence speed of the network to a certain extent and alleviate the phenomenon of gradient disappearance.
3.5. Incorporate the CBAM Attention Mechanism
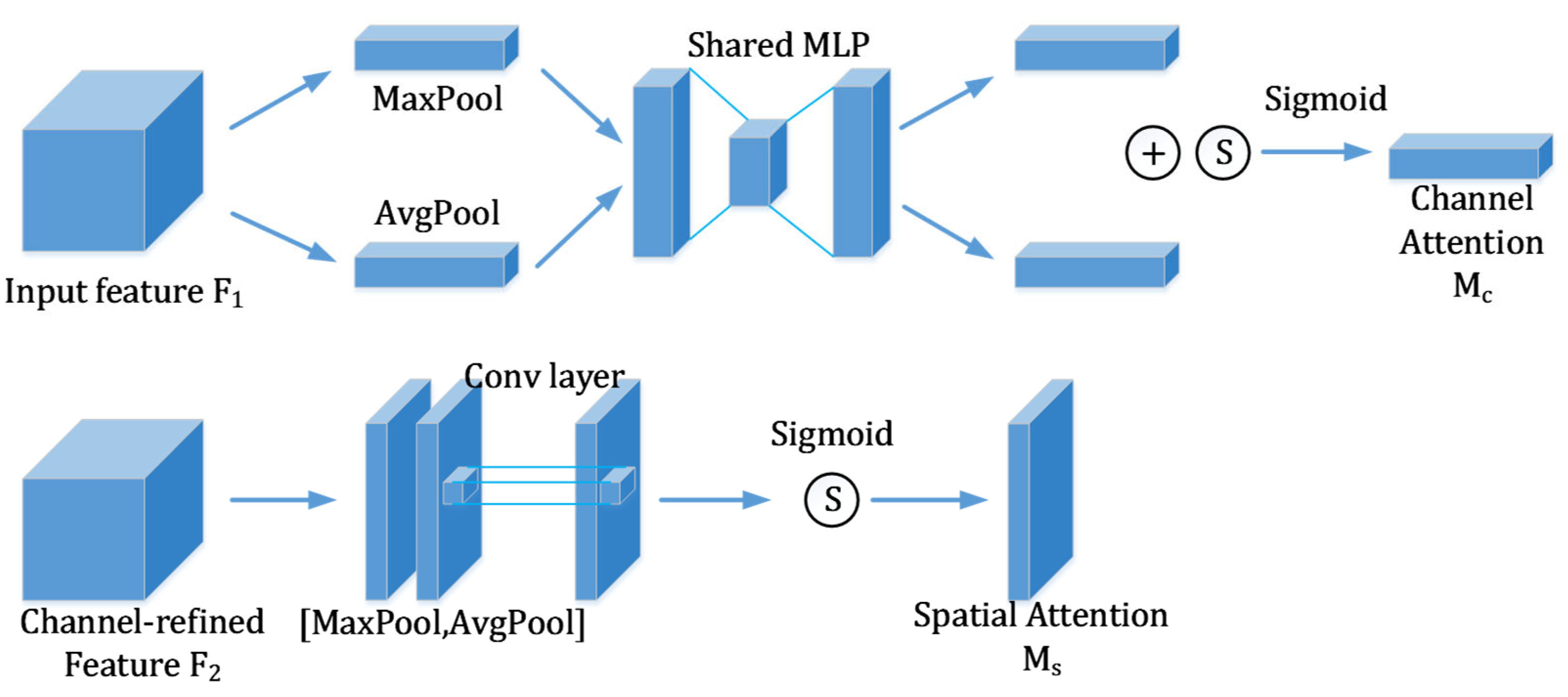
The attention mechanism can selectively ignore some inefficient information in the image, focus on the efficient information, reduce the resource consumption of the inefficient part, improve the network utilization, and enhance the ability of object detection. Therefore, the CBAM attention mechanism is integrated into the feature extraction network, and the channel attention mechanism and spatial attention mechanism are connected [
31] to form a simple but effective attention module, whose structure is shown in
Figure 6.
In the channel attention module, the global average pooling and maximum pooling of the same input feature space are performed to obtain the spatial information of the feature map, and then the obtained feature space information is input into the multi-layer awareness mechanism module of the next layer for dimension reduction and dimension-increase processing. The weight of the two shared convolution layers in the multi-layer awareness network is shared. Then, the characteristics of the perceptual network output are added and then processed with the sigmoid activation function to obtain channel attention. The calculation formula is shown in Formula (4).
Among them, is the channel attention module calculation factor, is the sigmoid activation function, is the multi-layer perceptron, and represents the feature vector.
Spatial attention features are complementary to channel attention and reflect the importance of input values in spatial dimensions. The calculation formula is shown in Formula (5). First, global average pooling and global maximum pooling of one channel dimension are performed on the feature map, then the two features are spliced, and finally the dimension is reduced to one by 7 × 7 convolution post-channel processing using the sigmoid function [
32] to generate spatial attention feature maps.
Among them, is the space attention module calculation factor, is the sigmoid activation function, is the multi-layer perceptron, represents the feature vector, is the channel combination, and is the convolution operation.
In order to facilitate the use of pre-trained models during the experiment, CBAM is not embedded in all convolutional residual blocks, but only acts after different convolutional layers.
3.6. Introduce FPN Feature Pyramid Structure
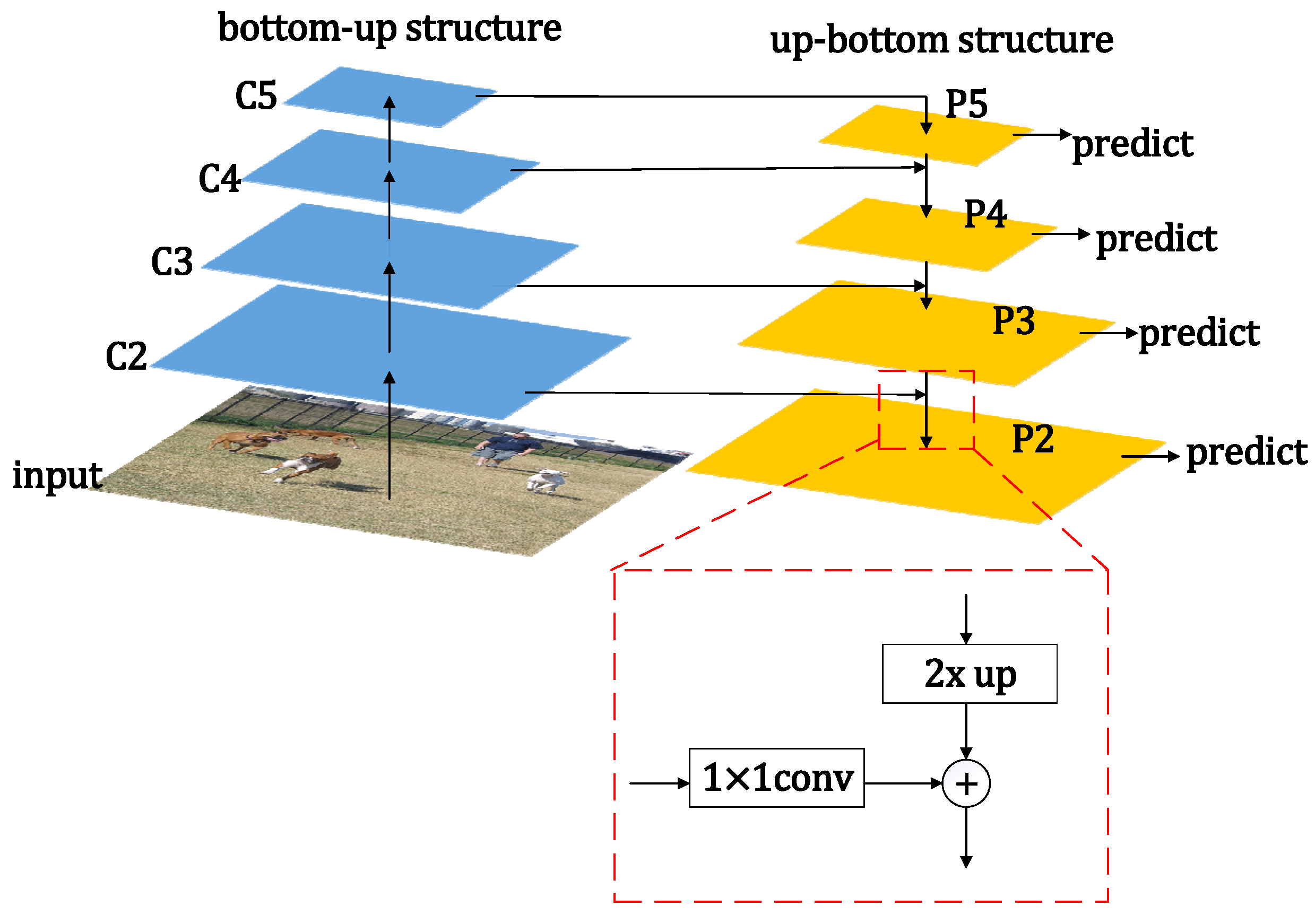
In order to alleviate the unsatisfactory detection ability of the Faster RCNN algorithm for small-sized targets, the FPN feature pyramid network model is introduced into the Faster RCNN target detection algorithm. The FPN network model is divided into two network routes. One of the network routes produces multi-scale features from bottom to top, connecting the high-level features with high semantics and low resolution and the low-level features with high resolution and low semantics [
33]. Another network route is from top to bottom; after some layer changes, the rich semantic information contained in the upper layer is transferred layer by layer to the low-layer features for fusion [
34]. Compared with the SSD algorithm, FPN also uses multi-level features and multi-scale anchor frames. SSD predicts the low-level data alone, where it is difficult to ensure strong semantic features, and the detection effect is not ideal for small targets.
Figure 7 is a schematic diagram of the FPN feature pyramid structure. In the figure, the bottom-up feature map with computed order on the left is {C2, C3, C4, C5}, and the top-down feature pyramid structure on the right is {P2,P3,P4,P5}. The CF-RCNN algorithm uses the above VS-ResNet as the backbone extraction network of the FPN feature pyramid structure. The image part on the left side of
Figure 7 is a downsampling model. During the feature extraction operation of this model, the value of the step size is set as {4,8,16,32}. In the upsampling model of the right image, the upper feature map is convolved with a convolution kernel of 1 × 1 size, the step size is set to 1, and the number of channels is 256, to adjust the dimension to be consistent so that it can be fused with the lower feature. Then, after 3 × 3 size convolution, the aliasing situation in the 2-fold upsampling process is eliminated to obtain the feature map. {P2, P3, P4, P5} share the weight of RPN and Fast RCNN, and use a different anchor size of {32
2, 64
2, 128
2, 256
2} and the anchor ratio of {1:2, 1:1, 2:1} on the {P2, P3, P4, P5} feature map to select candidate boxes.
3.7. Improvement of Non-Maximum Suppression NMS Algorithm
Non-Maximum Suppression (NMS) is an important part of the target detection algorithm, and its main function is to eliminate redundant candidate boxes generated in the RPN network. The elimination criterion is shown in Formula (6).
where
is the score of the
th candidate box;
indicates the candidate box with the largest score;
is the candidate box to be scored;
is the combined ratio of
; and
Nt is the threshold value of
set in NMS.
When the ratio between the candidate box to be scored and the candidate box with the largest score exceeds the threshold, the NMS deletes the candidate box to be scored. As a result, NMS mistakenly deletes overlapping candidate boxes in partially crowded and truncated complex scenarios. To solve this problem, CF-RCNN uses the Soft-NMS algorithm. The Soft-NMS score function is shown in Formula (7).
If the combined ratio is less than the threshold, the score remains unchanged. If it is greater than or equal to the threshold, is the difference between multiplied by 1 and the combined ratio. Compared with NMS, Soft-NMS does not directly overlap candidate boxes, but resets to a smaller score.
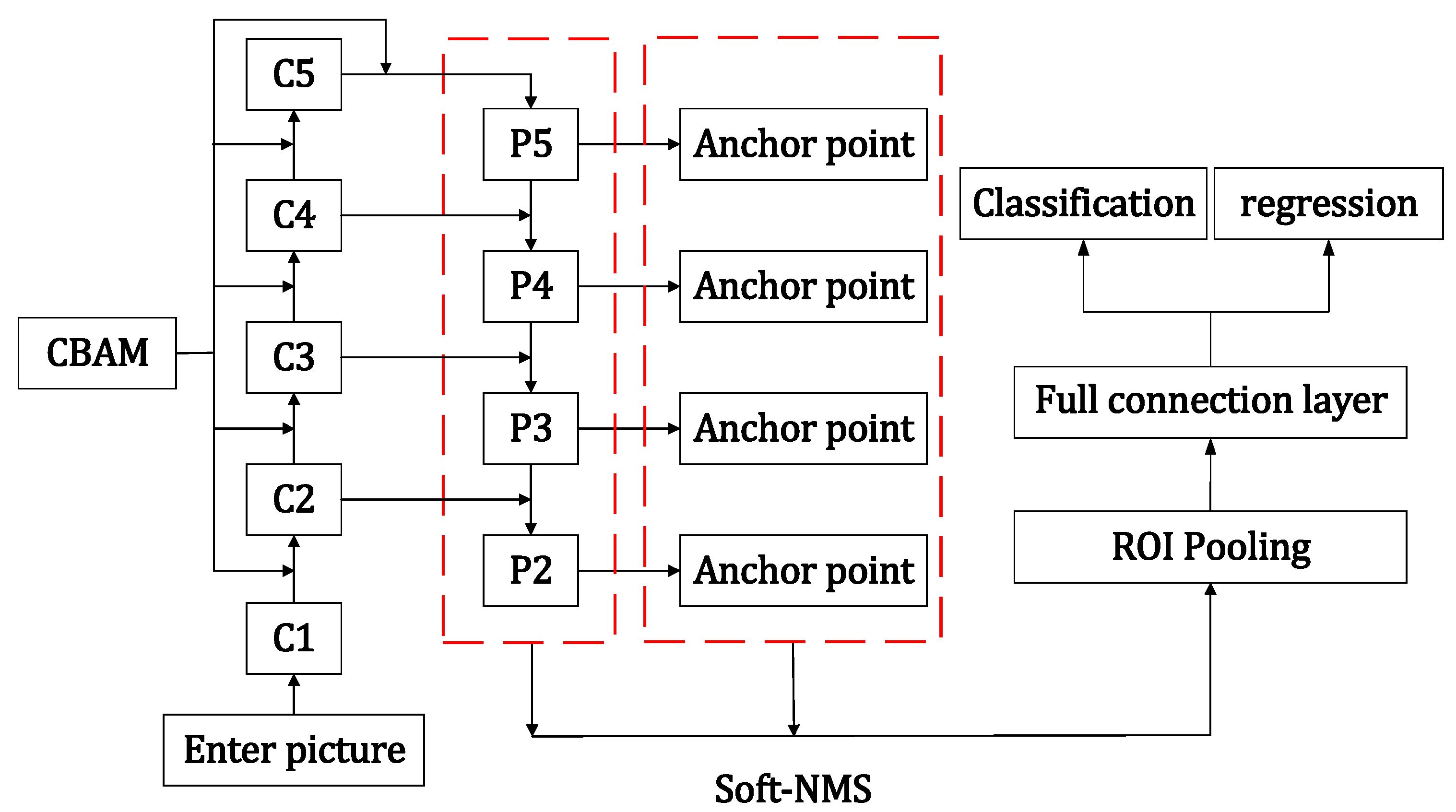
3.8. Overall Structure of CF-RCNN
Combined with the above improvement measures, the detailed structure of the CF-RCNN algorithm is shown in
Figure 8.
Firstly, CF-RCNN takes the image stream as input, extracts image features based on the inverted residual ResNet-50 model, and obtains intermediate feature vector graphics. Secondly, the CBAM attention mechanism is used to calculate the attention weight in the two dimensions of space and channel, and adjusts the parameters of the intermediate feature map. Third, based on the FPN feature pyramid structure, the feature map is multi-scaled. Fourth, on each feature map, the RPN network uses a single scale to select regions that may contain objects and balances the positive and negative sample ratios through Soft-NMS. Finally, the classification and position regression operations are performed on the objects in the selected area.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}