
Manifolds-Based Low-Rank Dictionary Pair Learning for Efficient Set-Based Video Recognition

Abstract
:1. Introduction
2. Related Works
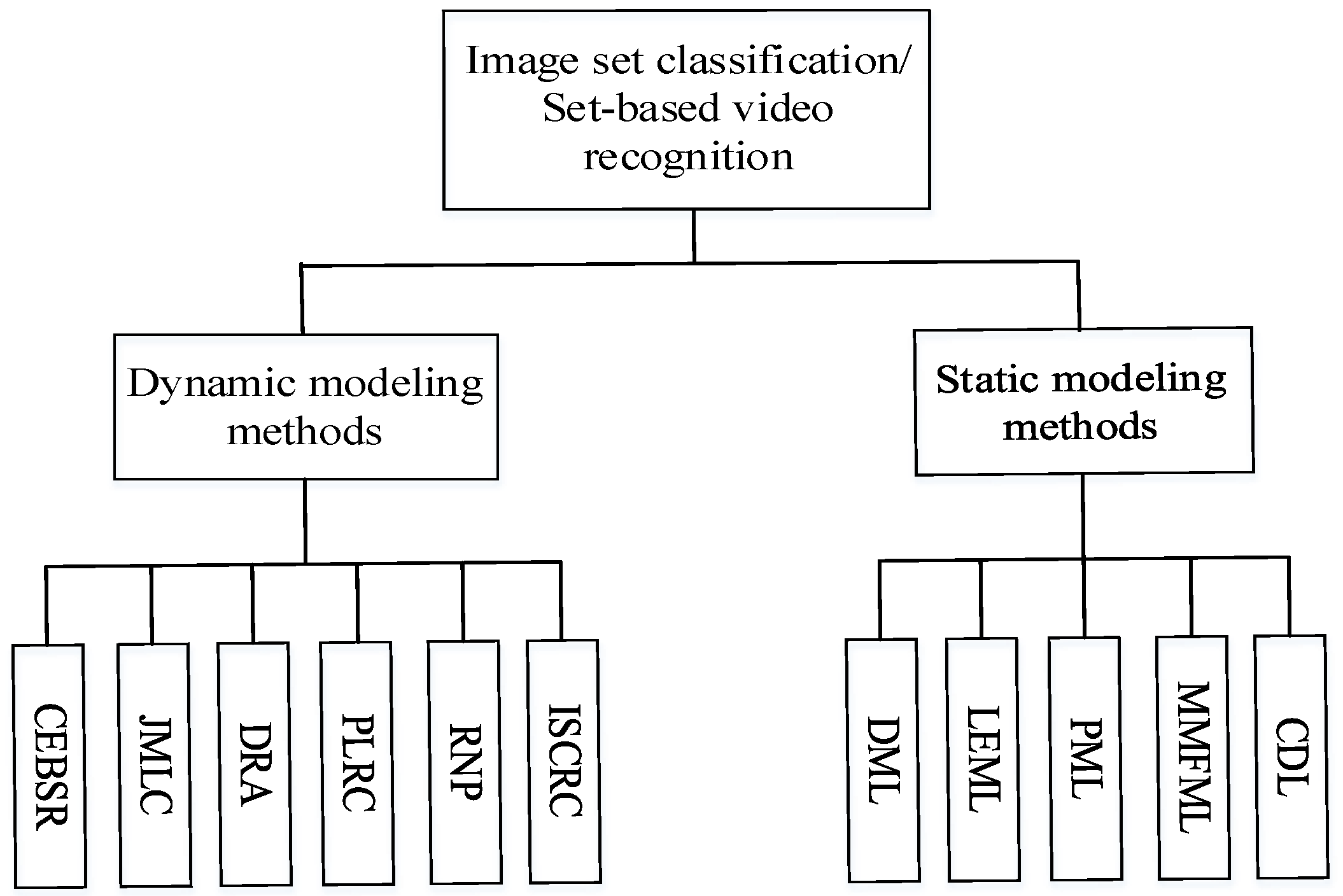
2.1. Image Set Classification
2.1.1. Static Modeling Methods
2.1.2. Dynamic Modeling Methods
2.2. Dictionary Learning
2.2.1. Unsupervised Dictionary Learning Methods
2.2.2. Discriminative Dictionary Learning Methods
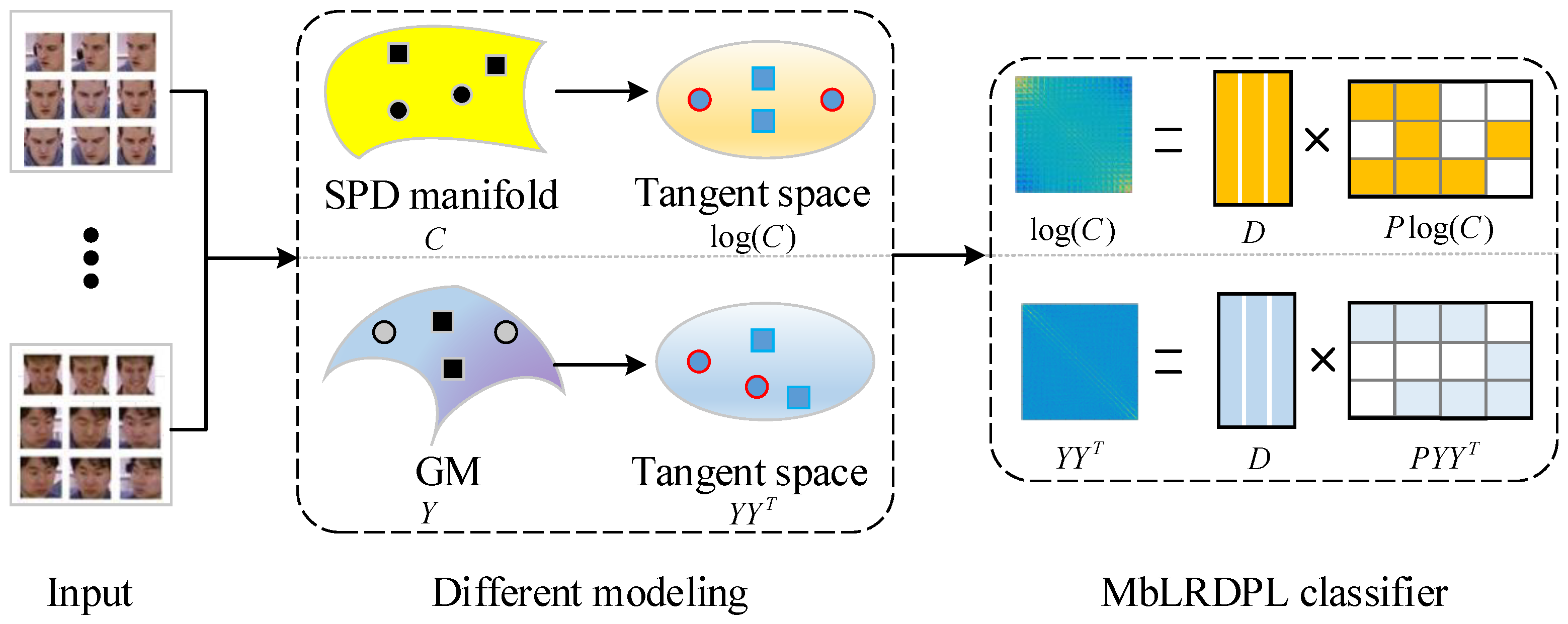
3. Manifolds-Based Low-Rank Dictionary Pair Learning
3.1. Problem Formulation
3.2. MbLRDPL-SPD
3.3. MbLRDPL-GM
3.4. Optimization
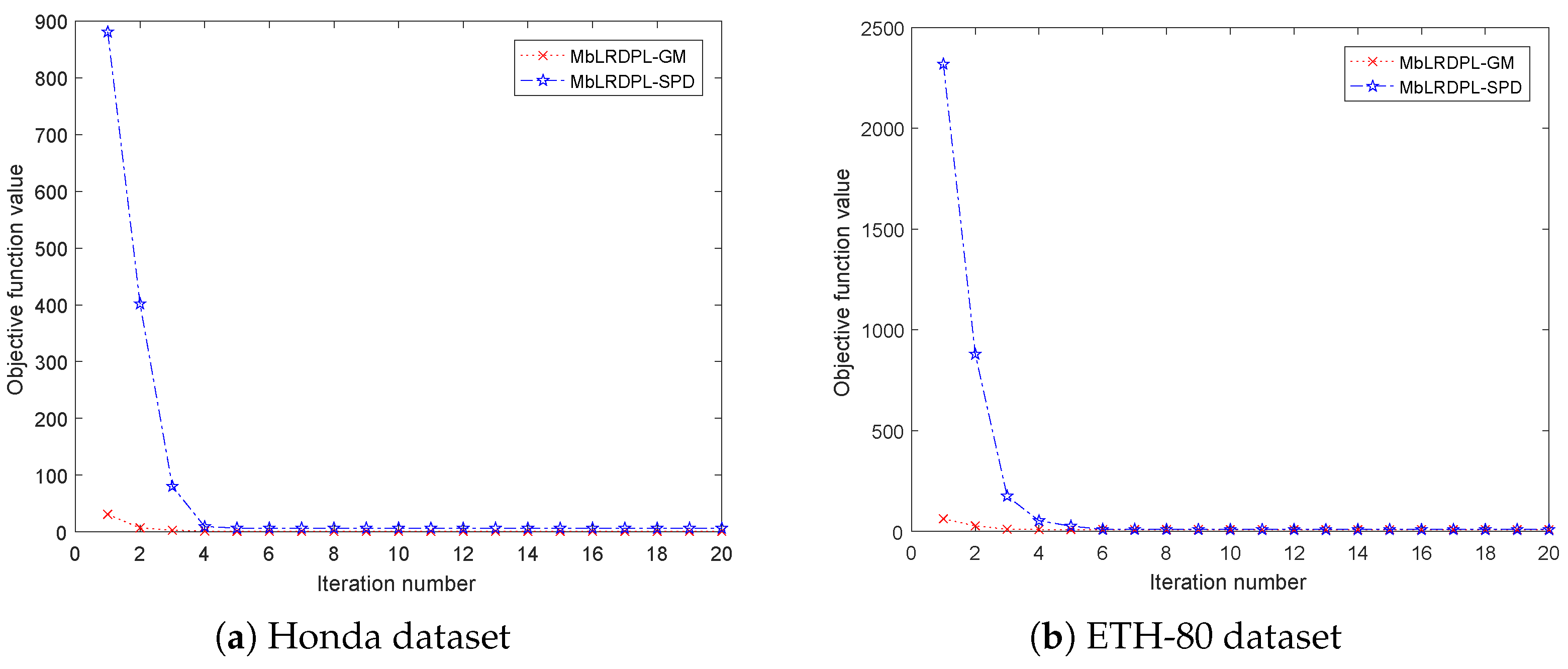
4. Experimental Results and Analysis
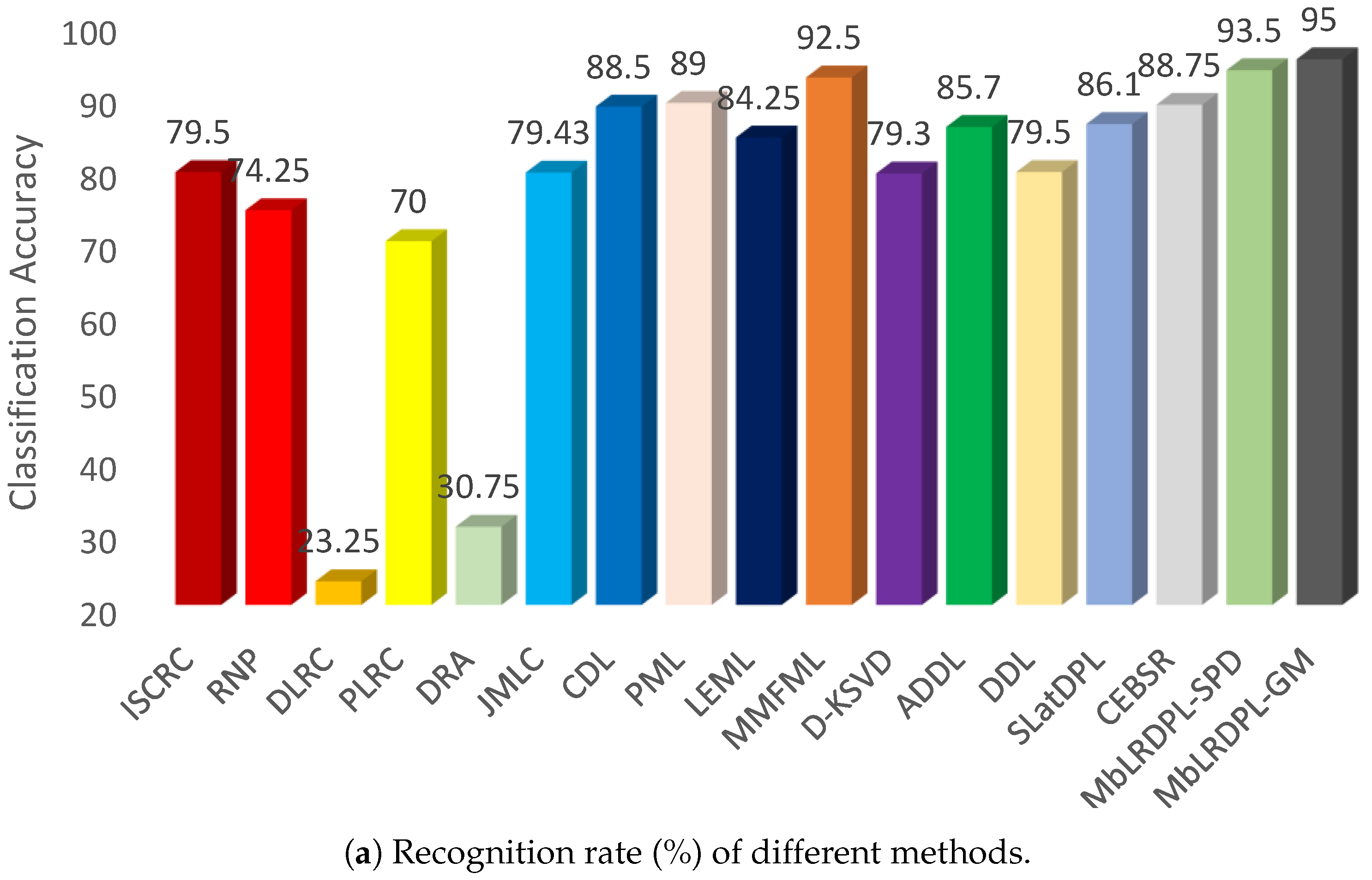
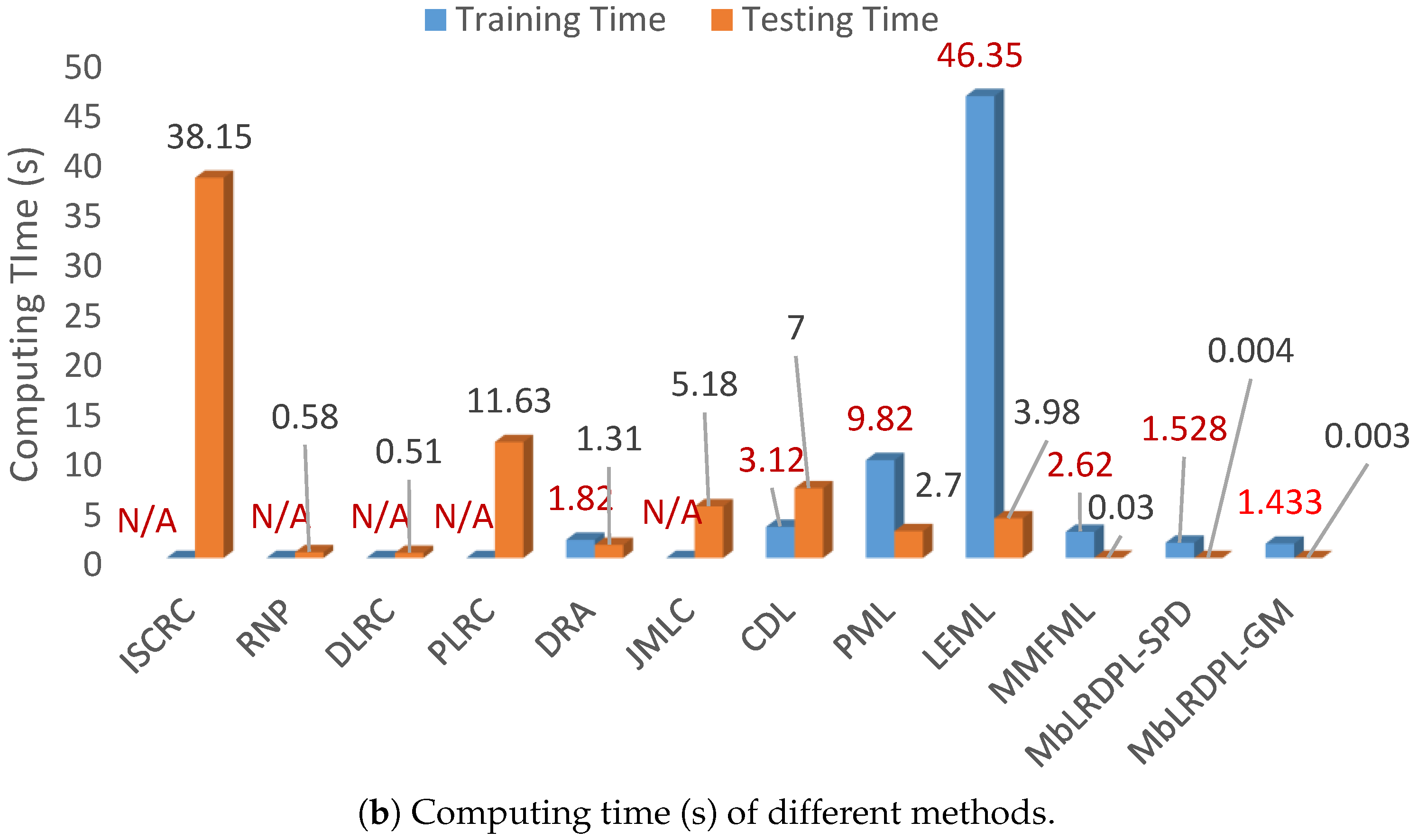
4.1. Experiments on Set-Based Video Face Recognition Task
4.2. Experiments on Set-Based Object Classification Task
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, R.; Guo, H.; Davis, L.S.; Dai, Q. Covariance Discriminative Learning: A Natural and Efficient Approach to Image Set Classification. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2496–2503. [Google Scholar]
- Gao, X.; Sun, Q.; Xu, H.; Wei, D.; Gao, J. Multi-model fusion metric learning for image set classification. Knowl. Based Syst. 2019, 164, 253–264. [Google Scholar] [CrossRef]
- Zhu, P.; Zuo, W.; Zhang, L.; Shiu, S.C.K.; Zhang, D. Image Set-Based Collaborative Representation for Face Recognition. IEEE Trans. Inf. Forensics Secur. 2014, 9, 1120–1132. [Google Scholar] [CrossRef]
- Yang, M.; Zhu, P.; Van Gool, L.; Zhang, L. Face recognition based on regularized nearest points between image sets. In Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013; pp. 1–7. [Google Scholar]
- Liu, D.; Liang, C.; Chen, S.; Tie, Y.; Qi, L. Auto-encoder based structured dictionary learning for visual classification. Neurocomputing 2021, 438, 34–43. [Google Scholar] [CrossRef]
- Gu, S.; Zhang, L.; Zuo, W.; Feng, X.; Claims, A.I. Projective dictionary pair learning for pattern classification. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014; pp. 793–801. [Google Scholar]
- Zhu, F.; Gao, J.; Yang, J.; Ye, N. Neighborhood linear discriminant analysis. Pattern Recognit. 2022, 123, 108422. [Google Scholar] [CrossRef]
- Abdulrahman, A.A.; Tahir, F.S. Face recognition using enhancement discrete wavelet transform based on MATLAB. Indones. J. Electr. Eng. Comput. Sci. 2021, 23, 1128–1136. [Google Scholar] [CrossRef]
- Zhu, F.; Zhang, W.; Chen, X.; Gao, X.; Ye, N. Large margin distribution multi-class supervised novelty detection. Expert Syst. Appl. 2023, 224, 119937. [Google Scholar] [CrossRef]
- Mohammed, S.A.; Abdulrahman, A.A.; Tahir, F.S. Emotions Students Faces Recognition using Hybrid Deep Learning and Discrete Chebyshev Wavelet Transformations. Int. J. Math. Comput. Sci. 2022, 17, 1405–1417. [Google Scholar]
- Tahir, F.S.; Abdulrahman, A.A.; Thanon, Z.H. Novel face detection algorithm with a mask on neural network training. Int. J. Nonlinear Anal. Appl. 2022, 13, 209–215. [Google Scholar]
- Huang, Z.; Wang, R.; Shan, S.; Chen, X. Projection Metric Learning on Grassmann Manifold with Application to Video based Face Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 140–149. [Google Scholar]
- Huang, Z.; Wang, R.; Shan, S.; Li, X.; Chen, X. Log-Euclidean Metric Learning on Symmetric Positive Definite Manifold with Application to Image Set Classification. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 720–729. [Google Scholar]
- Wei, D.; Shen, X.; Sun, Q.; Gao, X. Discrete Metric Learning for Fast Image Set Classification. IEEE Trans. Image Process. 2022, 31, 6471–6486. [Google Scholar] [CrossRef] [PubMed]
- Gao, X.; Niu, S.; Wei, D.; Liu, X.; Wang, T.; Zhu, F.; Dong, J.; Sun, Q. Joint Metric Learning-Based Class-Specific Representation for Image Set Classification. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Chen, L. Dual linear regression based classification for face cluster recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 2673–2680. [Google Scholar]
- Feng, Q.; Zhou, Y.; Lan, R. Pairwise Linear Regression Classification for Image Set Retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4865–4872. [Google Scholar]
- Ren, C.; Luo, Y.; Xu, X.; Dai, D.; Yan, H. Discriminative Residual Analysis for Image Set Classification With Posture and Age Variations. IEEE Trans. Image Process. 2019, 29, 2875–2888. [Google Scholar] [CrossRef] [PubMed]
- Aharon, M.; Elad, M.; Bruckstein, A. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, B. Discriminative K-SVD for dictionary learning in face recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2691–2698. [Google Scholar]
- Zhang, Z.; Jiang, W.; Qin, J.; Zhang, L.; Li, F.; Zhang, M.; Yan, S. Jointly Learning Structured Analysis Discriminative Dictionary and Analysis Multiclass Classifier. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 3798–3814. [Google Scholar] [CrossRef] [PubMed]
- Mahdizadehaghdam, S.; Panahi, A.; Krim, H.; Dai, L. Deep Dictionary Learning: A PARametric NETwork Approach. IEEE Trans. Image Process. 2019, 28, 4790–4802. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Sun, Y.; Wang, Y.; Zhang, Z.; Zhang, H.; Liu, G.; Wang, M. Twin-Incoherent Self-Expressive Locality-Adaptive Latent Dictionary Pair Learning for Classification. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 947–961. [Google Scholar] [CrossRef] [PubMed]
- Cai, J.F.; Candès, E.J.; Shen, Z. A Singular Value Thresholding Algorithm for Matrix Completion. SIAM J. Optim. 2010, 20, 1956–1982. [Google Scholar] [CrossRef]
- Martinez, A.M.; Kak, A.C. PCA versus LDA. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 228–233. [Google Scholar] [CrossRef]
- Lee, K.C.; Ho, J.; Yang, M.H.; Kriegman, D. Videobased face recognition using probabilistic appearance manifolds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 18–20 June 2003; pp. 313–320. [Google Scholar]
- Kim, M.; Kumar, S.; Pavlovic, V.; Rowley, H. Face tracking and recognition with visual constraints in real-world videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Leibe, B.; Schiele, B. Analyzing appearance and contour based methods for object categorization. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 18–20 June 2003; pp. 409–415. [Google Scholar]
- ur Rehman, A.; Belhaouari, S.B.; Kabir, M.A.; Khan, A. On the Use of Deep Learning for Video Classification. Appl. Sci. 2023, 13, 2007. [Google Scholar] [CrossRef]
- Liu, X.; Liu, S.; Ma, Z. A Framework for Short Video Recognition Based on Motion Estimation and Feature Curves on SPD Manifolds. Appl. Sci. 2022, 12, 4669. [Google Scholar] [CrossRef]
- Guo, Z.; Ying, S. Whole-Body Keypoint and Skeleton Augmented RGB Networks for Video Action Recognition. Appl. Sci. 2022, 12, 6215. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Description |
|---|---|
| a matrix | |
| a vector | |
| scalar | |
| the gallery image set from class | |
| the image coming from gallery video | |
| ⊖ | the manifold replacements for subtraction |
| ⊗ | the manifold replacements for multiplication |
| the geodesic distance metric | |
| the Frobenius norm | |
| the norm | |
| the nuclear norm |
| Method | Honda | YTC | ||||
|---|---|---|---|---|---|---|
| Accuracy | Tra. Time | Tes. Time | Accuracy | Tra. Time | Tes. Time | |
| ISCRC | 96.41 ± 2.24 | N/A | 9.36 | 69.31 ± 2.02 | N/A | 1171 |
| RNP | 96.41 ± 2.16 | N/A | 2.49 | 70.35 ± 2.44 | N/A | 47.12 |
| DLRC | 34.36 ± 2.15 | N/A | 10.15 | 38.37 ± 6.70 | N/A | 183.2 |
| PLRC | 67.53 ± 6.64 | N/A | 33.84 | 49.26 ± 2.24 | N/A | 3102 |
| DRA | 70.12 ± 9.22 | 41.23 | 38.33 | 30.19 ± 0.35 | 2238 | 2482 |
| JMLC | 100.0 ± 0.00 | N/A | 1.81 | 71.89 ± 3.13 | N/A | 986 |
| CDL | 100.0 ± 0.00 | 3.56 | 8.58 | 69.18 ± 2.65 | 12.58 | 15.69 |
| PML | 96.67 ± 2.01 | 5.55 | 3.51 | 66.13 ± 3.16 | 65.58 | 18.37 |
| LEML | 97.18 ± 3.32 | 22.34 | 3.90 | 50.60 ± 3.01 | 400.6 | 39.96 |
| MMFML | 100.0 ± 0.00 | 2.53 | 0.02 | 71.32 ± 4.36 | 18.32 | 0.56 |
| DML | – | – | – | 70.89 ± 9.75 | 10.38 | 0.30 |
| MbLRDPL-SPD | 100.0 ± 0.00 | 0.89 | 0.003 | 72.16 ± 2.44 | 9.73 | 0.47 |
| MbLRDPL-GM | 100.0 ± 0.00 | 0.78 | 0.002 | 71.85 ± 2.53 | 9.16 | 0.51 |
| Method | Accuracy |
|---|---|
| D-KSVD | 59.20 |
| ADDL | 62.30 |
| DDL | 60.10 |
| SLatDPL | 61.90 |
| CEBSR | 66.31 |
| MbLRDPL-SPD | 72.16 |
| MbLRDPL-GM | 71.85 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, X.; Wei, K.; Li, J.; Shi, Z.; Zhao, H.; Niu, S. Manifolds-Based Low-Rank Dictionary Pair Learning for Efficient Set-Based Video Recognition. Appl. Sci. 2023, 13, 6383. https://doi.org/10.3390/app13116383
Gao X, Wei K, Li J, Shi Z, Zhao H, Niu S. Manifolds-Based Low-Rank Dictionary Pair Learning for Efficient Set-Based Video Recognition. Applied Sciences. 2023; 13(11):6383. https://doi.org/10.3390/app13116383
Chicago/Turabian StyleGao, Xizhan, Kang Wei, Jia Li, Ziyu Shi, Hui Zhao, and Sijie Niu. 2023. "Manifolds-Based Low-Rank Dictionary Pair Learning for Efficient Set-Based Video Recognition" Applied Sciences 13, no. 11: 6383. https://doi.org/10.3390/app13116383