
Explainable Mortality Prediction Model for Congestive Heart Failure with Nature-Based Feature Selection Method

 ,
,  and
and 
Abstract
:1. Introduction
- This work broadens the field of mortality prediction in the ICU for heart failure patients by examining the impact of several nature-based feature selection methods on prediction;
- The role of features in the prediction process was analyzed using SHAP in this study, providing insight into the determinant features that decide mortality in the ICU.
2. Background Studies
2.1. Nature-Based Algorithms in Feature Selection Used in Different Studies
2.2. Scoring-Based Mortality Prediction
2.3. Machine-Learning-Based Mortality Prediction
2.4. Deep-Learning-Based Mortality Prediction
3. Materials and Methods
3.1. Workflow Diagram
3.2. Dataset Description
3.3. Data Preprocessing
3.4. Feature Selection Algorithm
3.4.1. Wrapper Feature Selection Method
3.4.2. Flower Pollination Algorithm
3.4.3. Genetic Algorithm
3.4.4. Particle Swarm Algorithm
3.5. Machine Learning Algorithm
3.5.1. Logistic Regression Algorithm
3.5.2. Decision Tree Algorithm
3.5.3. Random Forest Algorithm
3.5.4. Gradient Boosting Algorithm
4. Result Analysis
4.1. Comparison of Performance
4.2. AUROC Curve Analysis
4.3. Statistical Test Results
4.4. Proposed Model vs. Literature Studies
5. Interpretation of Results with SHAP
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Al Mamun, S.; Kaiser, M.S.; Mahmud, M. An Artificial Intelligence Based Approach towards Inclusive Healthcare Provisioning in Society 5.0: A Perspective on Brain Disorder. In Proceedings of the Brain Informatics: 14th International Conference, BI 2021, Virtual Event, 17–19 September 2021; Springer International Publishing: Cham, Switzerland, 2021. Available online: https://link.springer.com/chapter/10.1007/978-3-030-86993-9 (accessed on 12 February 2023).
- Heart Failure Projected to Increase Dramatically, According to New Statistics. 2021. Available online: https://www.heart.org/en/news/2018/05/01/heart-failure-projected-to-increase-dramatically-according-to-new-statistics (accessed on 23 November 2022).
- Safavi, K.C.; Dharmarajan, K.; Kim, N.; Strait, K.M.; Li, S.-X.; Chen, S.I.; Lagu, T.; Krumholz, H.M. Variation exists in rates of admission to intensive care units for heart failure patients across hospitals in the United States. Circulation 2013, 127, 923–929. [Google Scholar] [CrossRef] [PubMed]
- Johnson, A.; Pollard, T.; Mark, R. Mimic-III Clinical Database, MIMIC-III Clinical Database v1.4. 2016. Available online: https://physionet.org/content/mimiciii/1.4/ (accessed on 23 November 2022).
- Mohammadzadeh, H.; Gharehchopogh, F.S. A Novel Hybrid Whale Optimization Algorithm with Flower Pollination Algorithm for Feature Selection: Case Study Email Spam Detection. Comput. Intell. 2021, 37, 176–209. [Google Scholar] [CrossRef]
- Rajamohana, S.; Umamaheswari, K. A Hybrid Approach to Optimize Feature Selection Process Using IBPSO- BFPA for Review Spam Detection. Appl. Math. Inf. Sci. 2017, 11, 1443–1449. [Google Scholar] [CrossRef]
- Rodrigues, D.; de Rosa, G.H.; Passos, L.A.; Papa, J.P. Adaptive Improved Flower Pollination Algorithm for Global Optimization. In Nature-Inspired Computation in Data Mining and Machine Learning; Yang, X.-S., He, X.-S., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; Volume 855, pp. 1–21. [Google Scholar] [CrossRef]
- Khourdifi, Y.; Bahaj, M. Heart Disease Prediction and Classification Using Machine Learning Algorithms Optimized by Particle Swarm Optimization and Ant Colony Optimization. Int. J. Intell. Eng. Syst. 2019, 12, 242–252. [Google Scholar] [CrossRef]
- Guha, J.; Chouksey, A.; Khodwe, P.; Inje, B.V. Review Paper of Nature-Based Optimization Algorithms for Medicine Predictor. Int. J. Eng. Res. Technol. 2021, 10, 179–185. [Google Scholar]
- Yang, X.-S. Flower Pollination Algorithm for Global Optimization. In Unconventional Computation and Natural Computation; Durand-Lose, J., Jonoska, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 240–249. [Google Scholar] [CrossRef]
- Eberhart, R.; Kennedy, J. A new optimizer using particle swarm theory. In Proceedings of the Sixth International Symposium on Micro Machine and Human Science, Nagoya, Japan, 4–6 October 1995; pp. 39–43. [Google Scholar]
- Holland, J.H. Adaptation in Natural and Artificial Systems, 2nd ed.; University of Michigan Press: Ann Arbor, MI, USA, 1992. [Google Scholar]
- Menard, S. Applied Logistic Regression Analysis; No. 106; SAGE: Newbury Park, CA, USA, 2002. [Google Scholar]
- Gradient Boosting. Wikipedia. Wikimedia Foundation. 2022. Available online: https://en.wikipedia.org/wiki/Gradient-boosting (accessed on 24 January 2023).
- Random Forest. Wikipedia. Wikimedia Foundation. 2023. Available online: https://en.wikipedia.org/wiki/Random-forest (accessed on 24 January 2023).
- Decision Tree. Wikipedia. Wikimedia Foundation. 2022. Available online: https://en.wikipedia.org/wiki/Decision-tree (accessed on 24 January 2023).
- Linardatos, P.; Papastefanopoulos, V.; Kotsianti, S. Explainable AI: A Review of Macine Learning Interpretability Methods. Entropy 2021, 23, 18. [Google Scholar] [CrossRef]
- Ghosh, M.; Guha, R.; Sarkar, R.; Abraham, A. A Wrapper-Filter Feature Selection Technique Based on Ant Colony Optimization. Neural Comput. Appl. 2020, 32, 7839–7857. [Google Scholar] [CrossRef]
- Sharma, M.; Kaur, P. A Comprehensive Analysis of Nature-Inspired Meta-Heuristic Techniques for Feature Selection Problem. Arch. Comput. Methods Eng. 2021, 28, 1103–1127. [Google Scholar] [CrossRef]
- Taradeh, M.; Mafarja, M.; Heidari, A.A.; Faris, H.; Aljarah, I.; Mirjalili, S.; Fujita, H. An Evolutionary Gravitational Search-Based Feature Selection. Inf. Sci. 2019, 497, 219–239. [Google Scholar] [CrossRef]
- Chen, R.-C.; Dewi, C.; Huang, S.-W.; Caraka, R.E. Selecting Critical Features for Data Classification Based on Machine Learning Methods. J. Big Data 2020, 7, 52. [Google Scholar] [CrossRef]
- Marcos-Zambrano, L.J.; Karaduzovic-Hadziabdic, K.; Loncar Turukalo, T.; Przymus, P.; Trajkovik, V.; Aasmets, O.; Berland, M.; Gruca, A.; Hasic, J.; Hron, K.; et al. Applications of Machine Learning in Human Microbiome Studies: A Review on Feature Selection, Biomarker Identification, Disease Prediction and Treatment. Front. Microbiol. 2021, 12, 313. [Google Scholar] [CrossRef] [PubMed]
- El-Hasnony, I.M.; Barakat, S.I.; Elhoseny, M.; Mostafa, R.R. Improved feature selection model for big data analytics. IEEE Access 2020, 8, 66989–67004. [Google Scholar] [CrossRef]
- Li, J.P.; Haq, A.; Swati, S.; Khan, J.; If, A.; Saboor, A. Heart Disease Identification Method Using Machine Learning Classification in E-Healthcare. IEEE Access 2020, 8, 107562–107582. [Google Scholar] [CrossRef]
- Mafarja, M.; Aljarah, I.; Faris, H.; Hammouri, A.I.; Al-Zoubi, A.M.; Mir-Jalili, S. Binary Grasshopper Optimisation Algorithm Approaches for Feature Selection Problems. Expert Syst. Appl. 2019, 117, 267–286. [Google Scholar] [CrossRef]
- Sayed, G.I.; Hassanien, A.E.; Azar, A.T. Feature Selection via a Novel Chaotic Crow Search Algorithm. Neural Comput. Appl. 2019, 31, 171–188. [Google Scholar] [CrossRef]
- Sahebi, G.; Movahedi, P.; Ebrahimi, M.; Pahikkala, T.; Plosila, J.; Tenhunen, H. GeFeS: A Generalized Wrapper Feature Selection Approach for Optimizing Classification Performance. Comput. Biol. Med. 2020, 125, 103974. [Google Scholar] [CrossRef]
- Shrivastava, P.; Shukla, A.; Vepakomma, P.; Bhansali, N.; Verma, K. A Survey of Nature-Inspired Algorithms for Feature Selection to Identify Parkinson’s Disease. Comput. Methods Programs Biomed. 2017, 139, 171–179. [Google Scholar] [CrossRef]
- Knaus, W.A.; Draper, E.A.; Wagner, D.P.; Zimmerman, J.E. APACHE II: A Severity of Disease Classification System. Crit. Care Med. 1985, 13, 818. [Google Scholar] [CrossRef]
- Vincent, J.L.; Moreno, R.; Takala, J.; Willatts, S.; De Mendonça, A.; Bruining, H.; Reinhart, C.K.; Suter, P.M.; Thijs, L.G. The SOFA (Sepsis-Related Organ Failure Assessment) Score to Describe Organ Dysfunction/Failure. On Behalf of the Working Group on Sepsis-Related Problems of the European Society of Intensive Care Medicine. Intensive Care Med. 1996, 22, 707–710. [Google Scholar] [CrossRef]
- Le Gall, J.-R. A New Simplified Acute Physiology Score (SAPS II) Based on a European/North American Multicenter Study. JAMA J. Am. Med. Assoc. 1993, 270, 2957. [Google Scholar] [CrossRef]
- Aperstein, Y.; Cohen, L.; Bendavid, I.; Cohen, J.; Grozovsky, E.; Rotem, T.; Singer, P. Improved ICU Mortality Prediction Based on SOFA Scores and Gastrointestinal Parameters. PLoS ONE 2019, 14, e0222599. [Google Scholar] [CrossRef] [PubMed]
- Jentzer, J.C.; Diepen, S.; Murphree, D.; Ismail, A.; Keegan, M.; Morrow, D.; Barsness, G.; Anaveka, N. Admission Diagnosis and Mortality Risk Prediction in a Contemporary Cardiac Intensive Care Unit Population. Am. Heart J. 2020, 224, 57–64. [Google Scholar] [CrossRef] [PubMed]
- Lin, K.; Hu, Y.; Kong, G. Predicting In-Hospital Mortality of Patients with Acute Kidney Injury in the ICU Using Random Forest Model. Int. J. Med. Inform. 2019, 125, 55–61. [Google Scholar] [CrossRef] [PubMed]
- Li, F.; Xin, H.; Zhang, J.; Fu, M.; Zhou, J.; Lian, Z. Prediction Model of In-Hospital Mortality in Intensive Care Unit Patients with Heart Failure: Machine Learning-Based, Retrospective Analysis of the MIMIC-III Database. BMJ Open 2021, 11, e044779. [Google Scholar] [CrossRef]
- Guo, C.; Liu, M.; Lu, M. A Dynamic Ensemble Learning Algorithm Based on K-Means for ICU Mortality Prediction. Appl. Soft Comput. 2021, 103, 107166. [Google Scholar] [CrossRef]
- El-Rashidy, N.; El-Sappagh, S.; Abuhmed, T.; Abdelrazek, S.; El-Bakry, H.M. Intensive Care Unit Mortality Prediction: An Improved Patient-Specific Stacking Ensemble Model. IEEE Access 2020, 8, 133541–133564. [Google Scholar] [CrossRef]
- Ghorbani, R.; Ghousi, R.; Makui, A.; Atashi, A. A New Hybrid Predictive Model to Predict the Early Mortality Risk in Intensive Care Units on a Highly Imbalanced Dataset. IEEE Access 2020, 8, 141066–141079. [Google Scholar] [CrossRef]
- Allenbach, Y.; Saadoun, D.; Maalouf, G.; Vieira, M.; Hellio, A.; Boddaert, J.; Gros, H.; Salem, J.E.; Resche Rigon, M.; Menyssa, C.; et al. Development of a Multivariate Prediction Model of Intensive Care Unit Transfer or Death: A French Prospective Cohort Study of Hospitalized COVID-19 Patients. PLoS ONE 2020, 15, e0240711. [Google Scholar] [CrossRef]
- Chiew, C.J.; Liu, N.; Wong, T.H.; Sim, Y.E.; Abdullah, H.R. Utilizing Machine Learning Methods for Preoperative Prediction of Postsurgical Mortality and Intensive Care Unit Admission. Ann. Surg. 2020, 272, 1133–1139. [Google Scholar] [CrossRef]
- Kong, G.; Lin, K.; Hu, Y. Using Machine Learning Methods to Predict In-Hospital Mortality of Sepsis Patients in the ICU. BMC Med. Inform. Decis. Mak. 2020, 20, 251. [Google Scholar] [CrossRef]
- Subudhi, S.; Verma, A.; Patel, A.; Hardin, C.; Khandekar, M.J.; Lee, H.; Stylianopoulos, T.; Munn, L.; Dutta, S.; Jain, R. Comparing Machine Learning Algorithms for Predicting ICU Admission and Mortality in COVID-19. NPJ Digit. Med. 2021, 4, 87. [Google Scholar] [CrossRef] [PubMed]
- Banoei, M.M.; Dinparastisaleh, R.; Zadeh, A.V.; Mirsaeidi, M. Machine-Learning-Based COVID-19 Mortality Prediction Model and Identification of Patients at Low and High Risk of Dying. Crit. Care 2021, 25, 328. [Google Scholar] [CrossRef] [PubMed]
- Raj, R.; Luostarinen, T.; Pursiainen, E.; Posti, J.; Takala, R.; Bendel, S.; Konttila, T.; Korja, M. Machine Learning-Based Dynamic Mortality Prediction after Traumatic Brain Injury. Sci. Rep. 2019, 9, 17672. [Google Scholar] [CrossRef] [PubMed]
- Tabassum, T.; Tasnim, N.; Nizam, N. Anonymous Person Tracking Across Multiple Camera Using Color Histogram and Body Pose Estimation. In Proceedings of the International Conference on Trends in Computational and Cognitive Engineering, Online, 21–22 October 2021; Kaiser, M.S., Ed.; Springer: Singapore, 2021; Volume 1309, pp. 639–648. [Google Scholar] [CrossRef]
- Thorsen-Meyer, H.-C.; Nielsen, A.B.; Nielsen, A.P.; Kaas-Hansen, B.; Toft, P.; Schierbeck, J.; Strøm, T.; Chmura, P.; Heimann, M.; Dybdahl, L.; et al. Dynamic and Explainable Machine Learning Prediction of Mortality in Patients in the Intensive Care Unit: A Retrospective Study of High-Frequency Data in Electronic Patient Records. Lancet Digit. Health 2020, 2, e179–e191. [Google Scholar] [CrossRef]
- Yu, K.; Zhang, M.; Cui, T.; Hauskrech, M. Monitoring ICU Mortality Risk with A Long Short-Term Memory Recurrent Neural Network. Pac. Symp. Biocomput. Pac. Symp. Biocomput. 2020, 25, 103–114. [Google Scholar]
- Kim, S.Y.; Kim, S.; Cho, J.; Kim, Y.S.; Sol, I.S.; Sung, Y.; Cho, I.; Park, M.; Jang, H.; Kim, Y.H.; et al. A Deep Learning Model for Real-Time Mortality Prediction in Critically Ill Children. Crit. Care 2019, 23, 279. [Google Scholar] [CrossRef]
- Caicedo-Torres, W.; Gutierrez, J. ISeeU: Visually Interpretable Deep Learning for Mortality Prediction inside the ICU. J. Biomed. Inform. 2019, 98, 103269. [Google Scholar] [CrossRef]
- Li, X.; Ge, P.; Zhu, J.; Li, H.; Graham, J.; Singer, A.; Richman, P.S.; Duong, T.Q. Deep Learning Prediction of Likelihood of ICU Admission and Mortality in COVID-19 Patients Using Clinical Variables. PeerJ 2020, 8, e10337. [Google Scholar] [CrossRef]
- Kumawat, D. Introduction to Logistic Regression-Sigmoid Function, Code Explanation, Analytics Steps. Available online: https://www.analyticssteps.com/blogs/introduction-logistic-regression-sigmoid-function-code-explanation (accessed on 31 January 2023).
- Zhu, Y.; Zhang, J.; Wang, G.; Yao, R.; Ren, C.; Chen, G.; Jin, X.; Guo, J.; Liu, S.; Zheng, H.; et al. Machine Learning Prediction Models for Mechanically Ventilated Patients: Analyses of the MIMIC-III Database. Front. Med. 2021, 8, 662340. [Google Scholar] [CrossRef]
- Chiu, C.-C.; Wu, C.-M.; Chien, T.-N.; Kao, L.-J.; Li, C.; Jiang, H.-L. Applying an Improved Stacking Ensemble Model to Predict the Mortality of ICU Patients with Heart Failure. J. Clin. Med. 2022, 11, 6460. [Google Scholar] [CrossRef]
- Barrett, L.A.; Payrovnaziri, S.N.; Bian, J.; He, Z. Building Computational Models to Predict One-Year Mortality in ICU Patients with Acute Myocardial Infarction and Post Myocardial Infarction Syndrome. AMIA Summits Transl. Sci. Proc. 2019, 2019, 407–416. [Google Scholar] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Algorithm | Feature Selection | Interpretation | Dataset | Outcome |
|---|---|---|---|---|---|
| [34] | RF | No | No | MIMIC-III | Accuracy: 0.73 |
| [35] | LR | XGBoosting | No | MIMIC-III | AUROC: 0.8416 |
| [36] | Ensemble Method | No | No | MIMIC-III | AUROC: 83.91 |
| [38] | Ensemble Method | GA | No | MIMIC-III | Accuracy: 82.5% |
| [41] | GBM | No | No | MIMIC-III | AUROC: 0.845 |
| Ref. | Algorithm | Feature Selection | Interpretation | Dataset | Outcome |
|---|---|---|---|---|---|
| [46] | LSTM | No | Yes | Collected | AUROC: 0.88 |
| [47] | LSTM | No | No | MIMIC-III | AUROC: 0.8854 |
| [49] | CNN | No | Yes | MIMIC-III | AUROC: 0.8735 |
| [50] | Deep Learning | No | No | Collected | AUROC: 0.84 |
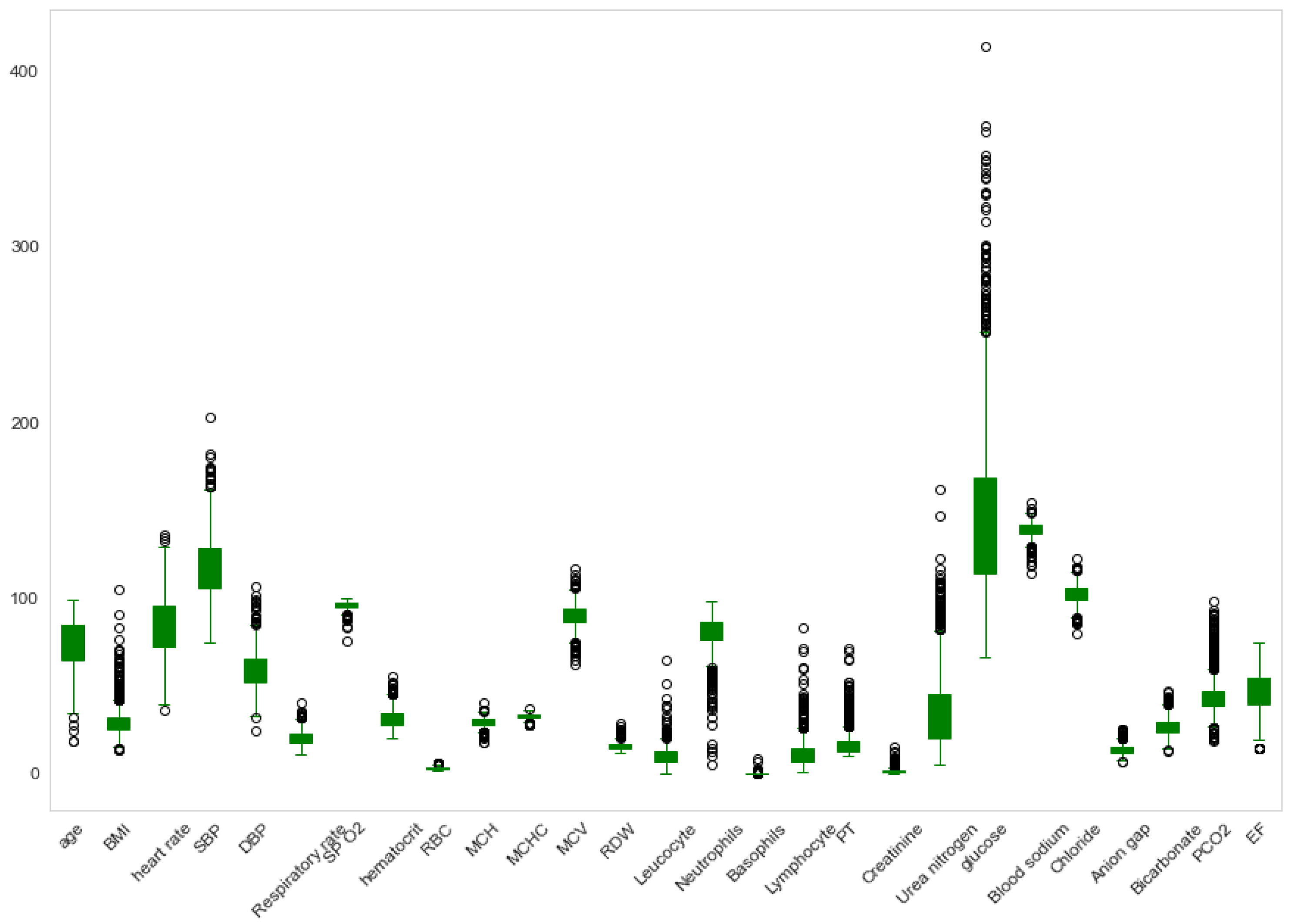
| Feature | Mean | Standard Deviation | Min | 25% | 50% | 75% | Max |
|---|---|---|---|---|---|---|---|
| Age | 74.05 | 13.43 | 19.00 | 65.00 | 77.00 | 85.00 | 99.00 |
| BMI | 30.19 | 9.33 | 13.35 | 24.33 | 28.31 | 33.63 | 104.97 |
| Hypertensive | 0.72 | 0.45 | 0.00 | 0.00 | 1.00 | 1.00 | 1.00 |
| Atrial fibrillation | 0.45 | 0.49 | 0.00 | 0.00 | 0.00 | 1.00 | 1.00 |
| CHD with no MI | 0.09 | 0.28 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 |
| Diabetes | 0.42 | 0.49 | 0.00 | 0.00 | 0.00 | 1.00 | 1.00 |
| Deficiency anemias | 0.34 | 0.47 | 0.00 | 0.00 | 0.00 | 1.00 | 1.00 |
| Depression | 0.12 | 0.32 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 |
| Hyperlipidemia | 0.38 | 0.48 | 0.00 | 0.00 | 0.00 | 1.00 | 1.00 |
| Renal failure | 0.37 | 0.48 | 0.00 | 0.00 | 0.00 | 1.00 | 1.00 |
| COPD | 0.08 | 0.26 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 |
| Heart rate | 84.58 | 16.01 | 36.00 | 72.37 | 83.61 | 95.90 | 135.70 |
| Systolic BP | 118.00 | 17.37 | 75.00 | 105.38 | 116.15 | 128.63 | 203.00 |
| Diastolic BP | 1161.00 | 10.68 | 24.73 | 52.17 | 58.46 | 65.46 | 107.00 |
| Respiratory rate | 1164.00 | 4.00 | 11.13 | 17.92 | 20.37 | 23.39 | 40.90 |
| Temperature | 1158.00 | 0.60 | 33.25 | 36.28 | 36.65 | 37.02 | 39.13 |
| SP O2 | 1164.00 | 2.29 | 75.91 | 95.00 | 96.45 | 97.91 | 100.00 |
| Urine output | 1899.28 | 1272.36 | 0.00 | 980.00 | 1675.00 | 2500.00 | 8820.00 |
| Hematocrit | 31.91 | 5.20 | 20.31 | 28.16 | 30.80 | 35.01 | 55.42 |
| RBC | 3.57 | 0.62 | 2.03 | 3.12 | 3.49 | 3.90 | 6.57 |
| MCH | 29.54 | 2.61 | 18.12 | 28.25 | 29.75 | 31.24 | 40.31 |
| MCHC | 32.86 | 1.40 | 27.82 | 32.01 | 32.98 | 33.82 | 37.01 |
| MCV | 89.90 | 6.53 | 62.60 | 86.25 | 90.00 | 93.85 | 116.71 |
| RDW | 15.95 | 2.13 | 12.08 | 14.46 | 15.51 | 16.93 | 29.05 |
| Leucocyte | 10.71 | 5.22 | 0.10 | 7.44 | 9.68 | 12.74 | 64.75 |
| Platelets | 241.50 | 113.12 | 9.57 | 168.90 | 222.66 | 304.25 | 1028.20 |
| Neutrophils | 80.11 | 11.13 | 5.00 | 74.77 | 82.46 | 87.45 | 98.00 |
| Basophils | 0.41 | 0.46 | 0.10 | 0.20 | 0.30 | 0.50 | 8.80 |
| Lymphocyte | 12.23 | 8.63 | 0.96 | 6.65 | 10.47 | 15.46 | 83.50 |
| PT | 17.48 | 7.38 | 10.10 | 13.16 | 14.63 | 18.80 | 71.27 |
| INR | 1.62 | 0.83 | 0.87 | 1.14 | 1.30 | 1.73 | 8.34 |
| NT-proBNP | 11,014.13 | 13,148.66 | 50.00 | 2251.00 | 5840.00 | 14,968.00 | 118,928.00 |
| Creatine kinase | 246.77 | 1484.52 | 8.00 | 46.00 | 89.25 | 185.18 | 42,987.50 |
| Creatinine | 1.64 | 1.27 | 0.26 | 0.94 | 1.28 | 1.90 | 15.53 |
| Urea nitrogen | 36.29 | 21.85 | 5.35 | 20.83 | 30.66 | 45.25 | 161.75 |
| Glucose | 148.79 | 51.49 | 66.66 | 113.93 | 136.40 | 169.50 | 414.10 |
| Blood potassium | 4.17 | 0.41 | 3.00 | 3.90 | 4.11 | 4.40 | 6.56 |
| Blood sodium | 138.89 | 4.15 | 114.66 | 136.66 | 139.25 | 141.60 | 154.73 |
| Blood calcium | 8.50 | 0.57 | 6.70 | 8.14 | 8.50 | 8.86 | 10.95 |
| Chloride | 102.28 | 5.34 | 80.26 | 99.00 | 102.50 | 105.57 | 122.52 |
| Anion gap | 13.92 | 2.65 | 6.63 | 12.25 | 13.66 | 15.41 | 25.50 |
| Magnesium ion | 2.12 | 0.25 | 1.40 | 1.95 | 2.09 | 2.24 | 4.07 |
| PH | 7.37 | 0.06 | 7.09 | 7.33 | 7.38 | 7.43 | 7.58 |
| Bicarbonate | 26.91 | 5.16 | 12.85 | 23.45 | 26.50 | 29.87 | 47.66 |
| Lactic acid | 1.85 | 0.98 | 0.50 | 1.20 | 1.60 | 2.20 | 8.33 |
| PCO2 | 45.53 | 12.71 | 18.75 | 37.04 | 43.00 | 50.58 | 98.60 |
| EH | 48.71 | 12.86 | 15.00 | 40.00 | 55.00 | 55.00 | 75.0 |
| Model Name | No Feature Selection | With Feature Selection | ||
|---|---|---|---|---|
| FPA | PSO | GA | ||
| LR | 69.9% | 71.6% | 57.3% | 69.0% |
| DT | 82.50% | 84.8% | 81.8% | 75.1% |
| RF | 90.9% | 92.8% | 90.6% | 92.4% |
| GB | 91.0% | 91.1% | 83.9% | 81.3% |
| Algorithm | Number of Selected Features | Feature Names |
|---|---|---|
| FPA | 21 | Age, BMI, hypertensive, atrial fibrillation, depression, Renal failure, COPD, heart rate, SP O2, hematocrit, RBC, MCV, MCHC, platelets, blood sodium, creatine kinase, creatinine, urea nitrogen, blood calcium, chloride, and magnesium ion |
| PSO | 17 | Hypertensive, atrial fibrillation, depression, COPD, heart rate, systolic blood pressure, temperature, hematocrit, MCH, RDW, lymphocyte, urea nitrogen, anion gap, PH, bicarbonate, lactic acid, and PCO2 |
| GA | 12 | Age, BMI, systolic blood pressure, diastolic blood pressure, respiratory rate, hematocrit, MCH, MCHC, neutrophils, PT, blood sodium, and lactic acid. |
| Friedman Test | Degrees of Freedom | Chi-Square | p-Value |
|---|---|---|---|
| 3 | 11.1 | 0.0112 |
| Rank | Feature Selection with the Classifiers | Rank Sum |
|---|---|---|
| 1 | FPA | 16 |
| 2 | No feature selection | 11 |
| 3 | GA | 7 |
| 4 | PSO | 6 |
| Study | Year | Dataset | Sample | Algorithm | Number of Features | AUROC Score |
|---|---|---|---|---|---|---|
| [52] | 2021 | MIMIC-III | 25,659 | XGBoost | 66 | 82% |
| [53] | 2022 | MIMIC-III | 6699 | Ensemble | 20 | 82.55% |
| [36] | 2021 | MIMIC-III | 58,976 | Dynamic Ensemble | 28 | 83.91% |
| [41] | 2020 | MIMIC-III | 16,688 | GB | 86 | 84% |
| RF + PSO | 2023 | MIMIC-III | 1177 | RF + FPA | 21 | 83.0% |
| Study | Year | Dataset | Sample | Algorithm | Number of Features | Accuracy |
|---|---|---|---|---|---|---|
| [54] | 2019 | MIMIC-III | 5037 | Logistic Model Trees | 79 | 85.12% |
| [35] | 2021 | MIMIC-III | 1177 | XGBoost | 20 | 76% |
| [34] | 2019 | MIMIC-III | 19,044 | RF | 15 | 72.8% |
| LR + FPA | 2023 | MIMIC-III | 1177 | RF + FPA | 21 | 92.80% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tasnim, N.; Al Mamun, S.; Shahidul Islam, M.; Kaiser, M.S.; Mahmud, M. Explainable Mortality Prediction Model for Congestive Heart Failure with Nature-Based Feature Selection Method. Appl. Sci. 2023, 13, 6138. https://doi.org/10.3390/app13106138
Tasnim N, Al Mamun S, Shahidul Islam M, Kaiser MS, Mahmud M. Explainable Mortality Prediction Model for Congestive Heart Failure with Nature-Based Feature Selection Method. Applied Sciences. 2023; 13(10):6138. https://doi.org/10.3390/app13106138
Chicago/Turabian StyleTasnim, Nusrat, Shamim Al Mamun, Mohammad Shahidul Islam, M. Shamim Kaiser, and Mufti Mahmud. 2023. "Explainable Mortality Prediction Model for Congestive Heart Failure with Nature-Based Feature Selection Method" Applied Sciences 13, no. 10: 6138. https://doi.org/10.3390/app13106138