

Mixed-Integer Linear Programming, Constraint Programming and a Novel Dedicated Heuristic for Production Scheduling in a Packaging Plant
Abstract
:1. Introduction
2. State of the Art
2.1. Constraints
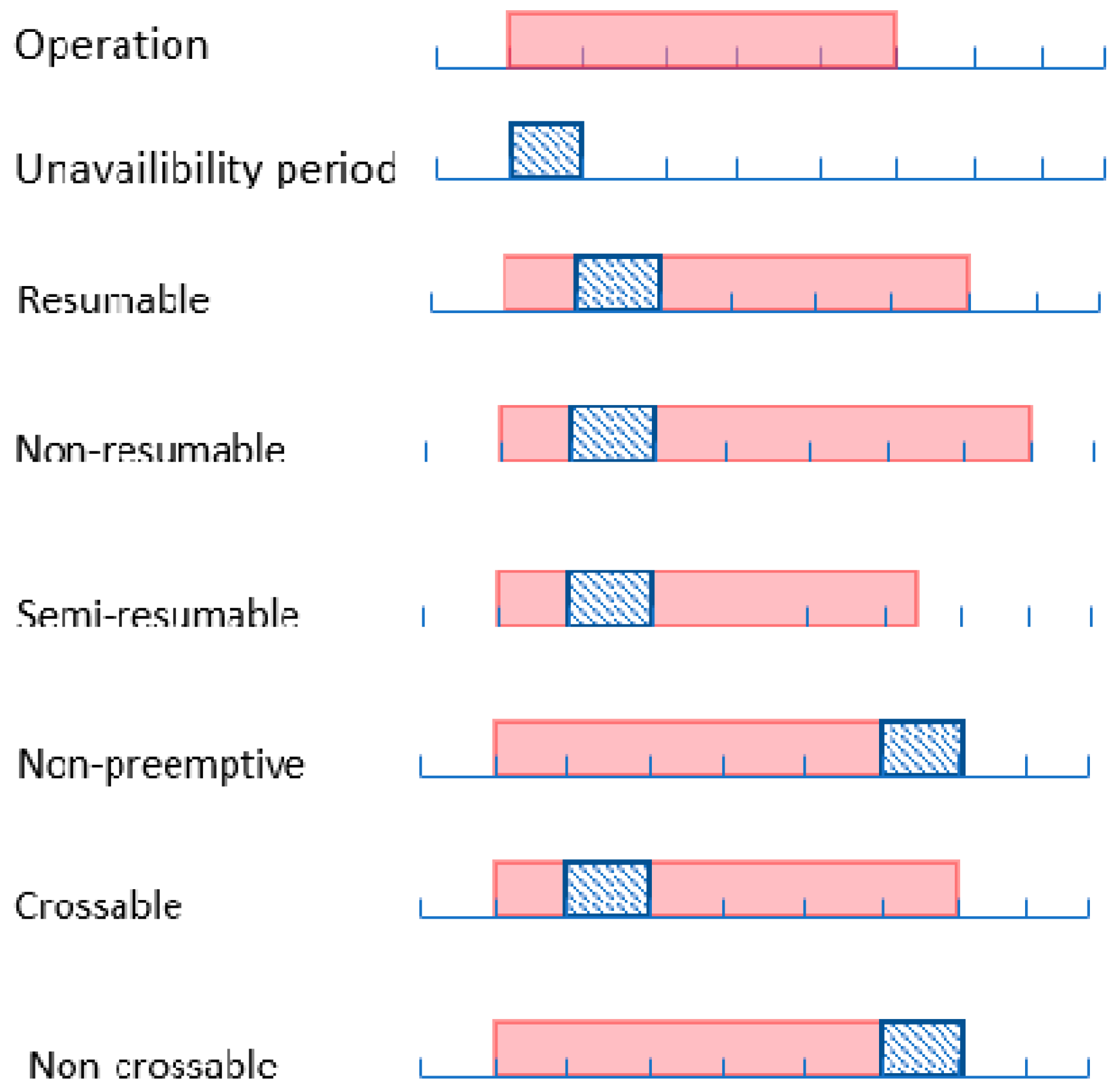
2.1.1. Setup Constraints
2.1.2. Resource Calendar Constraints
2.1.3. Machine Flexibility Constraints
2.2. Optimization Criteria
3. Problem Description
4. Model and Notations
4.1. Mixed-Integer Linear Programming
4.1.1. Start-Based Model
4.1.2. Modeling Calendar Constraints
4.2. Constraint Programming
4.2.1. Start-Based CP Model
4.2.2. Modeling Calendar Constraints
4.3. Dedicated Heuristic
- Step 1. Find earliest schedule
- Step 2. Check machine’s busyness
- Step 3. Setting operation’s schedule
5. Experimental Results
5.1. Performance of MILP and CP Models
5.1.1. Test Instances
5.1.2. Experimental Results
- -
- {5, 8, 10, 13, 15 to 20} for small-sized instances.
- -
- {30, 40, 50, 65, 70, 75, 80 to 100} for large-sized instances
Instances without Resource Calendar Constraints
- Small-Sized Instances
- 2.
- Large-Sized Problems
Instances with Resource Calendar Constraints
- Small-Sized Instances
- 2.
- Medium- and Large-Sized Instances
5.1.3. Discussion
5.2. Dedicated Heuristic
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
| Pseudo-Algorithm |
|---|
****************** SCHEDULING METHODS ****************** Determine an operation’s schedule --------------------------------- a. initialize - l = operation’s processing time (setup+execution) - ls = operation’s setup time - s = start - ss = None, the actual start, es = None, the start of the execution, r = None, the available time - ee = s, the end of the execution - A = machines’ availabilities (list of int couples representing each an availability window) b. iteration - b = 0, the availability bucket - While l>0 and b<|A| (we still processing time and availability buckets • B = A[b], B is the current availability bucket • si = B[0] (interval start), ei = B[1] (interval end) • if ei<=ee (if this intervals ends before the moving counter ee) ○ continue to next interval c. Set the availability time, r = ee + operation’s waiting time Find earliest schedule ---------------------- a. Try to schedule at time - determine a timing from time timing = determineTiming() - check if the machine is busy any time between timing.start and timing.end busy = checkBusy() - if not(busy) • return timing and end b. Else, try to schedule at each busyness interval’s end for [si,ei] in the machine’s busyness intervals - if ei<time => skip and continue to next interval - timing = determine a timing from ei - busy = check if machine is busy in that timing - if not(busy) • return timing and end Check machine’s busyness ------------------------ Setting operation’s schedule ---------------------------- a. Set the operation’s attribute (start,exec,end,available,machine) to (timing[1],timing[2],timing[3],timing[4],machine.id) b. Add the interval [timing[1],timing[3]] is the machine’s busyness and reorder the busyness intervals by increasing values c. Find the next operation nextOp in this operation’s parent job d. If nextOp exists, set its release time to timing[4] |
References
- Hoogeveen, J.A.; Lenstra, J.K.; Veltman, B. Preemptive Scheduling in a Two-Stage Multiprocessor Flow Shop Is NP-Hard. Eur. J. Oper. Res. 1996, 89, 172–175. [Google Scholar] [CrossRef]
- Gupta, J.N.D.; Hariri, A.M.A.; Potts, C.N. Scheduling a Two-Stage Hybrid Flow Shop with Parallel Machines at the First Stage. Ann. Oper. Res. 1997, 69, 171–191. [Google Scholar] [CrossRef]
- Oujana, S.; Yalaoui, F.; Amodeo, L. A Linear Programming Approach for Hybrid Flexible Flow Shop with Sequencedependent Setup Times to Minimise Total Tardiness. In Proceedings of the 17th IFAC Symposium on Information Control Problems in Manufacturing (INCOM 2021), Budapest, Hungary, 7–9 June 2021. [Google Scholar]
- Oujana, S.; Amodeo, L.; Yalaoui, F.; Brodart, D. Solving a Realistic Hybrid and Flexible Flow Shop Scheduling Problem through Constraint Programming: Industrial Case in a Packaging Company. In Proceedings of the 2022 8th International Conference on Control, Decision and Information Technologies (CoDIT), Istanbul, Turkey, 17–20 May 2022; Volume 1, pp. 106–111. [Google Scholar]
- Naderi, B.; Gohari, S.; Yazdani, M. Hybrid Flexible Flowshop Problems: Models and Solution Methods. Appl. Math. Model. 2014, 38, 5767–5780. [Google Scholar] [CrossRef]
- Liu, C.-Y.; Chang, S.-C. Scheduling Flexible Flow Shops with Sequence-Dependent Setup Effects. IEEE Trans. Robot. Autom. 2000, 16, 408–419. [Google Scholar] [CrossRef]
- Kurz, M.E.; Askin, R.G. Comparing Scheduling Rules for Flexible Flow Lines. Int. J. Prod. Econ. 2003, 85, 371–388. [Google Scholar] [CrossRef]
- Salmasi, N.; Logendran, R.; Skandari, M.R. Total Flow Time Minimization in a Flowshop Sequence-Dependent Group Scheduling Problem. Comput. Oper. Res. 2010, 37, 199–212. [Google Scholar] [CrossRef]
- An, Y.-J.; Kim, Y.-D.; Choi, S.-W. Minimizing Makespan in a Two-Machine Flowshop with a Limited Waiting Time Constraint and Sequence-Dependent Setup Times. Comput. Oper. Res. 2016, 71, 127–136. [Google Scholar] [CrossRef]
- Cheng, C.-Y.; Ying, K.-C.; Li, S.-F.; Hsieh, Y.-C. Minimizing Makespan in Mixed No-Wait Flowshops with Sequence-Dependent Setup Times. Comput. Ind. Eng. 2019, 130, 338–347. [Google Scholar] [CrossRef]
- Rossi, F.L.; Nagano, M.S. Heuristics and Metaheuristics for the Mixed No-Idle Flowshop with Sequence-Dependent Setup Times and Total Tardiness Minimisation. Swarm Evol. Comput. 2020, 55, 100689. [Google Scholar] [CrossRef]
- Khare, A.; Agrawal, S. Scheduling Hybrid Flowshop with Sequence-Dependent Setup Times and Due Windows to Minimize Total Weighted Earliness and Tardiness. Comput. Ind. Eng. 2019, 135, 780–792. [Google Scholar] [CrossRef]
- Mati, Y. Minimizing the Makespan in the Non-Preemptive Job-Shop Scheduling with Limited Machine Availability. Comput. Ind. Eng. 2010, 59, 537–543. [Google Scholar] [CrossRef]
- Aggoune, R.; Portmann, M.-C. Flow Shop Scheduling Problem with Limited Machine Availability: A Heuristic Approach. Int. J. Prod. Econ. 2006, 99, 4–15. [Google Scholar] [CrossRef]
- Mauguière, P.; Billaut, J.-C.; Bouquard, J.-L. New Single Machine and Job-Shop Scheduling Problems with Availability Constraints. J. Sched. 2005, 8, 211–231. [Google Scholar] [CrossRef]
- Lee, C.-Y. Minimizing the Makespan in the Two-Machine Flowshop Scheduling Problem with an Availability Constraint. Oper. Res. Lett. 1997, 20, 129–139. [Google Scholar] [CrossRef]
- Benttaleb, M.; Hnaien, F.; Yalaoui, F. Two-Machine Job Shop Problem for Makespan Minimization under Availability Constraint. IFAC Pap. 2016, 49, 132–137. [Google Scholar] [CrossRef]
- Azem, S.; Aggoune, R.; Dauzère-Pérès, S. Heuristics for Job Shop Scheduling with Limited Machine Availability. IFAC Proc. Vol. 2012, 45, 1395–1400. [Google Scholar] [CrossRef]
- Figielska, E. Heuristic algorithms for scheduling in a flowshop with resource constraints. IFAC Proc. Vol. 2007, 40, 325–330. [Google Scholar] [CrossRef]
- Laribi, I.; Yalaoui, F.; Belkaid, F.; Sari, Z. Heuristics for Solving Flow Shop Scheduling Problem under Resources Constraints. IFAC Pap. 2016, 49, 1478–1483. [Google Scholar] [CrossRef]
- Pan, Q.-K.; Wang, L.; Mao, K.; Zhao, J.-H.; Zhang, M. An Effective Artificial Bee Colony Algorithm for a Real-World Hybrid Flowshop Problem in Steelmaking Process. IEEE Trans. Autom. Sci. Eng. 2013, 10, 307–322. [Google Scholar] [CrossRef]
- Long, J.; Zheng, Z.; Gao, X.; Pardalos, P.M. Scheduling a Realistic Hybrid Flow Shop with Stage Skipping and Adjustable Processing Time in Steel Plants. Appl. Soft Comput. 2018, 64, 536–549. [Google Scholar] [CrossRef]
- Koch, C.; Arbaoui, T.; Ouazene, Y.; Yalaoui, F.; De Brunier, H.; Jaunet, N.; De Wulf, A. A Matheuristic Approach for Solving a Simultaneous Lot Sizing and Scheduling Problem with Client Prioritization in Tire Industry. Comput. Ind. Eng. 2022, 165, 107932. [Google Scholar] [CrossRef]
- Quadt, D.; Kuhn*, H. Conceptual Framework for Lot-Sizing and Scheduling of Flexible Flow Lines. Int. J. Prod. Res. 2005, 43, 2291–2308. [Google Scholar] [CrossRef]
- Quadt, D.; Kuhn, H. Capacitated Lot-Sizing and Scheduling with Parallel Machines, Back-Orders, and Setup Carry-Over. Nav. Res. Logist. NRL 2009, 56, 366–384. [Google Scholar] [CrossRef]
- Oduguwa, V.; Tiwari, A.; Roy, R. Evolutionary Computing in Manufacturing Industry: An Overview of Recent Applications. Appl. Soft Comput. J. 2005, 5, 281–299. [Google Scholar] [CrossRef]
- Kochhar, S.; Morris, R.J.T.; Wong, W.S. The Local Search Approach to Flexible Flow Line Scheduling. Eng. Costs Prod. Econ. 1988, 14, 25–37. [Google Scholar] [CrossRef]
- Botta-Genoulaz, V. Hybrid Flow Shop Scheduling with Precedence Constraints and Time Lags to Minimize Maximum Lateness. Int. J. Prod. Econ. 2000, 64, 101–111. [Google Scholar] [CrossRef]
- Ruiz, R.; Maroto, C. A Genetic Algorithm for Hybrid Flowshops with Sequence Dependent Setup Times and Machine Eligibility. Eur. J. Oper. Res. 2006, 169, 781–800. [Google Scholar] [CrossRef]
- Naderi, B.; Ruiz, R.; Zandieh, M. Algorithms for a Realistic Variant of Flowshop Scheduling. Comput. Oper. Res. 2010, 37, 236–246. [Google Scholar] [CrossRef]
- Chen, J.-F. Scheduling on Unrelated Parallel Machines with Sequence- and Machine-Dependent Setup Times and Due-Date Constraints. Int. J. Adv. Manuf. Technol. 2009, 44, 1204–1212. [Google Scholar] [CrossRef]
- Sen, T.; Gupta, S.K. A State-of-Art Survey of Static Scheduling Research Involving Due Dates. Omega 1984, 12, 63–76. [Google Scholar] [CrossRef]
- Lee, Y.H.; Pinedo, M. Scheduling Jobs on Parallel Machines with Sequence-Dependent Setup Times. Eur. J. Oper. Res. 1997, 100, 464–474. [Google Scholar] [CrossRef]
- Park, Y.; Kim, S.; Lee, Y. Scheduling Jobs on Parallel Machines Applying Neural Network and Heuristic Rules. Comput. Ind. Eng. 2000, 38, 189–202. [Google Scholar] [CrossRef]
- Naderi, B.; Zandieh, M.; Shirazi, M.A.H.A. Modeling and Scheduling a Case of Flexible Flowshops: Total Weighted Tardiness Minimization. Comput. Ind. Eng. 2009, 57, 1258–1267. [Google Scholar] [CrossRef]
- Xi, Y.; Jang, J. Minimizing Total Weighted Tardiness on a Single Machine with Sequence-Dependent Setup and Future Ready Time. Int. J. Adv. Manuf. Technol. 2013, 67, 281–294. [Google Scholar] [CrossRef]
- Diana, R.; Souza, S. Analysis of Variable Neighborhood Descent as a Local Search Operator for Total Weighted Tardiness Problem on Unrelated Parallel Machines. Comput. Oper. Res. 2020, 117, 104886. [Google Scholar] [CrossRef]
- Herr, O.; Goel, A. Comparison of Two Integer Programming Formulations for a Single Machine Family Scheduling Problem to Minimize Total Tardiness. Procedia CIRP 2014, 19, 174–179. [Google Scholar] [CrossRef]
- Liang, P.; Yang, H.; Liu, G.; Guo, J. An Ant Optimization Model for Unrelated Parallel Machine Scheduling with Energy Consumption and Total Tardiness. Math. Probl. Eng. 2015, 2015, e907034. [Google Scholar] [CrossRef]
- Lee, C.-H. A Dispatching Rule and a Random Iterated Greedy Metaheuristic for Identical Parallel Machine Scheduling to Minimize Total Tardiness. Int. J. Prod. Res. 2018, 56, 2292–2308. [Google Scholar] [CrossRef]
- Naderi, B.; Zandieh, M.; Khaleghi Ghoshe Balagh, A.; Roshanaei, V. An Improved Simulated Annealing for Hybrid Flowshops with Sequence-Dependent Setup and Transportation Times to Minimize Total Completion Time and Total Tardiness. Expert Syst. Appl. 2009, 36, 9625–9633. [Google Scholar] [CrossRef]
- Tran, T.H.; Ng, K.M. A Hybrid Water Flow Algorithm for Multi-Objective Flexible Flow Shop Scheduling Problems. Eng. Optim. 2013, 45, 483–502. [Google Scholar] [CrossRef]
- Allahverdi, A.; Aydilek, H.; Aydilek, A. No-Wait Flowshop Scheduling Problem with Two Criteria; Total Tardiness and Makespan. Eur. J. Oper. Res. 2018, 269, 590–601. [Google Scholar] [CrossRef]
- Wan, L.; Mei, J.; Du, J. Two-Agent Scheduling of Unit Processing Time Jobs to Minimize Total Weighted Completion Time and Total Weighted Number of Tardy Jobs. Eur. J. Oper. Res. 2021, 290, 26–35. [Google Scholar] [CrossRef]
- Allali, K.; Aqil, S.; Belabid, J. Distributed No-Wait Flow Shop Problem with Sequence Dependent Setup Time: Optimization of Makespan and Maximum Tardiness. Simul. Model. Pract. Theory 2022, 116, 102455. [Google Scholar] [CrossRef]
- Aydilek, A.; Aydilek, H.; Allahverdi, A. Algorithms for Minimizing the Number of Tardy Jobs for Reducing Production Cost with Uncertain Processing Times. Appl. Math. Model. 2017, 45, 982–996. [Google Scholar] [CrossRef]
- Najat, A.; Yuan, C.; Gursel, S.; Tao, Y. Minimizing the Number of Tardy Jobs on Identical Parallel Machines Subject to Periodic Maintenance. Procedia Manuf. 2019, 38, 1409–1416. [Google Scholar] [CrossRef]
- Della Croce, F.; T’kindt, V.; Ploton, O. Parallel Machine Scheduling with Minimum Number of Tardy Jobs: Approximation and Exponential Algorithms. Appl. Math. Comput. 2021, 397, 125888. [Google Scholar] [CrossRef]
- Hejl, L.; Šůcha, P.; Novák, A.; Hanzálek, Z. Minimizing the Weighted Number of Tardy Jobs on a Single Machine: Strongly Correlated Instances. Eur. J. Oper. Res. 2022, 298, 413–424. [Google Scholar] [CrossRef]
- Behnamian, J.; Zandieh, M.; Fatemi Ghomi, S.M.T. Due Window Scheduling with Sequence-Dependent Setup on Parallel Machines Using Three Hybrid Metaheuristic Algorithms. Int. J. Adv. Manuf. Technol. 2009, 44, 795–808. [Google Scholar] [CrossRef]
- Behnamian, J.; Fatemi Ghomi, S.M.T.; Zandieh, M. Development of a Hybrid Metaheuristic to Minimise Earliness and Tardiness in a Hybrid Flowshop with Sequence-Dependent Setup Times. Int. J. Prod. Res. 2010, 48, 1415–1438. [Google Scholar] [CrossRef]
- Behnamian, J.; Zandieh, M. A Discrete Colonial Competitive Algorithm for Hybrid Flowshop Scheduling to Minimize Earliness and Quadratic Tardiness Penalties. Expert Syst. Appl. 2011, 38, 14490–14498. [Google Scholar] [CrossRef]
- Otten, M.; Braaksma, A.; Boucherie, R.J. Minimizing Earliness/Tardiness Costs on Multiple Machines with an Application to Surgery Scheduling. Oper. Res. Health Care 2019, 22, 100194. [Google Scholar] [CrossRef]
- Schaller, J.; Valente, J.M.S. Minimizing Total Earliness and Tardiness in a Nowait Flow Shop. Int. J. Prod. Econ. 2020, 224, 107542. [Google Scholar] [CrossRef]
- Kellerer, H.; Rustogi, K.; Strusevich, V.A. A Fast FPTAS for Single Machine Scheduling Problem of Minimizing Total Weighted Earliness and Tardiness about a Large Common Due Date. Omega 2020, 90, 101992. [Google Scholar] [CrossRef]
- Graham, R.L.; Lawler, E.L.; Lenstra, J.K.; Kan, A.H.G.R. Optimization and Approximation in Deterministic Sequencing and Scheduling: A Survey. In Annals of Discrete Mathematics; Discrete Optimization II; Hammer, P.L., Johnson, E.L., Korte, B.H., Eds.; Elsevier: Amsterdam, The Netherlands, 1979; Volume 5, pp. 287–326. [Google Scholar]
- Laborie, P.; Rogerie, J.; Shaw, P.; Vilím, P. IBM ILOG CP Optimizer for Scheduling: 20+ Years of Scheduling with Constraints at IBM/ILOG. Constraints 2018, 23, 210–250. [Google Scholar] [CrossRef]



| Objective Function | Year | Author | Reference | Constraints | Approach | ||||
|---|---|---|---|---|---|---|---|---|---|
| //m | |||||||||
| Total weighted tardiness | 1997 | Lee and Pinedo | [33] | ✓ | ✓ | ✓ | Dispatching rule ATCS (Apparent Tardiness Cost with Setups) | ||
| 2000 | Park et al. | [34] | ✓ | ✓ | Dispatching rule | ||||
| 2009 | Naderi et al. | [35] | ✓ | ✓ | MIP and EMA metaheuristic | ||||
| 2013 | Xi and Jang | [36] | ✓ | ✓ | Dispatching rules (ATCS) | ||||
| 2020 | Diana et al. | [37] | ✓ | ✓ | VND metaheuristic | ||||
| Total tardiness | 2009 | Chen | [31] | ✓ | ✓ | ✓ | Hybrid Approach (ATCS+SA) | ||
| 2014 | Herr and Goel | [38] | ✓ | ✓ | MIP | ||||
| 2015 | Liang et al. | [39] | ✓ | ACO algorithm | |||||
| 2018 | Lee | [40] | ✓ | Random iteration greedy metaheuristic | |||||
| 2020 | Rossi and Nagano | [11] | ✓ | MILP, heuristics and metaheuristics | |||||
| Makespan and total tardiness/tardy jobs | 2009 | Naderi et al. | [41] | ✓ | ✓ | SA algorithm | |||
| 2013 | Tran et Ng | [42] | ✓ | A hybrid water flow algorithm | |||||
| 2018 | Allahverdi et al. | [43] | ✓ | AA algorithm | |||||
| 2021 | Wan et al. | [44] | A pseudo-polynomial algorithm and a dual FPTAS | ||||||
| 2022 | Allali et al. | [45] | ✓ | MILP and metaheuristics (GA, ABC, MBO) | |||||
| Tardy jobs | 2017 | Aydilek et al. | [46] | A DR algorithm | |||||
| 2019 | Najat et al. | [47] | ✓ | Mathematical programming and heuristics | |||||
| 2021 | Della Croce et al. | [48] | ✓ | Exponential time approximation algorithms | |||||
| 2022 | Hejl et al. | [49] | ✓ | A decomposed ILP model | |||||
| Bi-objective Sum of weighted earliness and weighted tardiness | 2008 | Behnamian et al. | [50] | ✓ | A hybrid metaheuristic algorithm that combines ACO, SA, and VNS | ||||
| 2009 | Behnamian et al. | [51] | ✓ | Three hybrid metaheuristics | |||||
| 2011 | Behnamian et Zandieh | [52] | ✓ | ✓ | ✓ | A discrete colonial competitive algorithm | |||
| 2019 | Otten et al. | [53] | ✓ | Heuristic | |||||
| 2020 | Schaller and valente | [54] | ✓ | BB and heuristics | |||||
| 2020 | Kellerer et al. | [55] | FPTAS | ||||||
| Problem Data | |
|---|---|
| i, i’ | Index for jobs where i, i’ ∈ {1,…,N}. |
| j | Index for operations. |
| O | The total number of operations. |
| Oij | The operation of job i ∈ N. |
| k | Index for machines where k ∈ {1,…, m}. |
| M | Number of all material resources. |
| N | Number of jobs to be scheduled. |
| Set of operations of job i ∈ N. | |
| Processing time job i ∈ N. | |
| Due date of job i ∈ N. | |
| ⊂ M | Set of material resources that can perform the operation j ∈ ji. |
| Setup time to pass from the execution of an operation to operation on machine k. | |
| BigM | A very large number. |
| Set of machines on which operations j of job i and j’ of job i’ can be processed. | |
| The number of unavailability periods on machine . | |
| The starting time of the unavailability period of material resource . | |
| The ending time of the unavailability period of material resource | |
| Decision Variables | |
|---|---|
| = | 1 if the operation Oij is assigned to the material resource k. 0 otherwise. |
| = | 1 if the operation Oij is processed before the operation Oi’j’ on the material resource k. 0 otherwise. |
| = | Starting time of the operation Oij on machine k. |
| = | Completion time of the operation Oij on machine k. |
| = | Completion time of job i. |
| Decision Variables | |
|---|---|
| = | An interval variable for each operation |
| = | An optional interval variable for each possible assignment of operation to machine |
| Instance Characteristics | ||||||
|---|---|---|---|---|---|---|
| Instance | ||||||
| WOS1 | 5 | 7 | 0 | 5 | 0 | 4 |
| WOS2 | 5 | 12 | 0 | 8 | 0 | 4 |
| WOS3 | 5 | 20 | 0 | 12 | 0 | 4 |
| WOS4 | 8 | 10 | 0 | 11 | 0 | 4 |
| WOS5 | 8 | 25 | 0 | 50 | 0 | 5 |
| WOS6 | 8 | 30 | 0 | 69 | 0 | 5 |
| WOS7 | 10 | 17 | 0 | 58 | 0 | 5 |
| WOS8 | 10 | 29 | 0 | 110 | 0 | 5 |
| WOS9 | 10 | 43 | 0 | 180 | 0 | 12 |
| WOS10 | 10 | 49 | 0 | 270 | 0 | 12 |
| WOS11 | 13 | 18 | 0 | 90 | 0 | 12 |
| WOS12 | 13 | 34 | 0 | 250 | 0 | 21 |
| WOS13 | 13 | 49 | 0 | 360 | 0 | 21 |
| WOS14 | 15 | 20 | 2870 | 240 | 2870 | 21 |
| WOS15 | 15 | 45 | 4076 | 300 | 4076 | 32 |
| WOS16 | 15 | 53 | 5760 | 410 | 5760 | 32 |
| WOS17 | 15 | 59 | 7120 | 360 | 7120 | 32 |
| WOS18 | 20 | 29 | 8200 | 380 | 8200 | 45 |
| WOS19 | 20 | 55 | 9590 | 520 | 9590 | 40 |
| WOS20 | 20 | 64 | 14,200 | 730 | 14,200 | 45 |
| Average | 12 | 33 | 2591 | 221 | 2591 | 18 |
| Instance Characteristics | ||||||
|---|---|---|---|---|---|---|
| Instance | ||||||
| LWOS1 | 30 | 66 | 0 | 320 | 0 | 6 |
| LWOS2 | 30 | 80 | 5760 | 850 | 5760 | 6 |
| LWOS3 | 40 | 88 | 9852 | 1710 | 9712 | 6 |
| LWOS4 | 40 | 96 | _ | >1800 | 9980 | 6 |
| LWOS5 | 50 | 110 | _ | >1800 | 12,100 | 12 |
| LWOS6 | 50 | 127 | _ | >1800 | 19,560 | 12 |
| LWOS7 | 65 | 143 | _ | >1800 | 19,800 | 12 |
| LWOS8 | 65 | 150 | _ | >1800 | 21,600 | 30 |
| LWOS9 | 65 | 165 | _ | >1800 | 22,400 | 26 |
| LWOS10 | 65 | 185 | _ | >1800 | 23,980 | 26 |
| LWOS11 | 70 | 164 | _ | >1800 | 23,800 | 30 |
| LWOS12 | 70 | 172 | _ | >1800 | 25,000 | 42 |
| LWOS13 | 70 | 190 | _ | >1800 | 26,960 | 42 |
| LWOS14 | 75 | 182 | _ | >1800 | 26,740 | 73 |
| LWOS15 | 75 | 198 | _ | >1800 | 27,880 | 73 |
| LWOS16 | 75 | 212 | _ | >1800 | 29,660 | 73 |
| LWOS17 | 80 | 210 | _ | >1800 | 29,920 | 49 |
| LWOS18 | 80 | 225 | _ | >1800 | 38,500 | 70 |
| LWOS19 | 100 | 320 | _ | >1800 | 40,940 | 87 |
| LWOS20 | 100 | 380 | _ | >1800 | 48,520 | 87 |
| Average | 65 | 173 | _ | _ | 23,141 | 38 |
| Instance Characteristics | |||||||
|---|---|---|---|---|---|---|---|
| Instance | U | ||||||
| RCWOS1 | 5 | 7 | 1 | 0 | 10 | 0 | 302 |
| RCWOS2 | 5 | 12 | 1 | 0 | 14 | 0 | 302 |
| RCWOS3 | 5 | 20 | 2 | 0 | 18 | 0 | 302 |
| RCWOS4 | 8 | 10 | 2 | 0 | 15 | 0 | 302 |
| RCWOS5 | 8 | 25 | 2 | 0 | 58 | 0 | 302 |
| RCWOS6 | 8 | 30 | 3 | 0 | 82 | 0 | 950 |
| RCWOS7 | 10 | 17 | 3 | 0 | 68 | 0 | 950 |
| RCWOS8 | 10 | 29 | 3 | 0 | 140 | 0 | 950 |
| RCWOS9 | 10 | 43 | 3 | 180 | 240 | 180 | 950 |
| RCWOS10 | 10 | 49 | 4 | 1330 | 320 | 1330 | 950 |
| RCWOS11 | 13 | 18 | 4 | 685 | 40 | 685 | 950 |
| RCWOS12 | 13 | 34 | 4 | 1258 | 380 | 1258 | 950 |
| RCWOS13 | 13 | 49 | 4 | 2780 | 450 | 2780 | 1100 |
| RCWOS14 | 15 | 20 | 4 | 4200 | 490 | 4200 | 1100 |
| RCWOS15 | 15 | 45 | 5 | 7200 | 820 | 7200 | 1100 |
| RCWOS16 | 15 | 53 | 5 | 8400 | 1080 | 8320 | 1100 |
| RCWOS17 | 15 | 59 | 5 | 9600 | 1202 | 8592 | 1300 |
| RCWOS18 | 20 | 29 | 5 | 10,800 | 1440 | 9987 | 1300 |
| RCWOS19 | 20 | 55 | 6 | _ | >1800 | 12,600 | 1300 |
| RCWOS20 | 20 | 64 | 7 | _ | >1800 | 18,600 | 1300 |
| Average | 12 | 33 | 4 | 2609 | 326 | 3783 | 888 |
| Instance Characteristics | |||||||
|---|---|---|---|---|---|---|---|
| Instance | U | ||||||
| LRCWOS1 | 30 | 66 | 1 | _ | >1800 | 0 | 1300 |
| LRCWOS2 | 30 | 80 | 1 | _ | >1800 | 6760 | 1300 |
| LRCWOS3 | 40 | 88 | 2 | _ | >1800 | 9900 | 1300 |
| LRCWOS4 | 40 | 96 | 2 | _ | >1800 | 9998 | 1300 |
| LRCWOS5 | 50 | 110 | 2 | _ | >1800 | 13,100 | 1300 |
| LRCWOS6 | 50 | 127 | 3 | _ | >1800 | 19,760 | 1300 |
| LRCWOS7 | 65 | 143 | 3 | _ | >1800 | 20,100 | 1487 |
| LRCWOS8 | 65 | 150 | 3 | _ | >1800 | 21,900 | 1487 |
| LRCWOS9 | 65 | 165 | 3 | _ | >1800 | 23,254 | 1487 |
| LRCWOS10 | 65 | 185 | 4 | _ | >1800 | 23,978 | 1487 |
| LRCWOS11 | 70 | 164 | 4 | _ | >1800 | 23,900 | 1487 |
| LRCWOS12 | 70 | 172 | 4 | _ | >1800 | 26,020 | 1487 |
| LRCWOS13 | 70 | 190 | 4 | _ | >1800 | 26,990 | 1580 |
| LRCWOS14 | 75 | 182 | 4 | _ | >1800 | 26,840 | 1580 |
| LRCWOS15 | 75 | 198 | 5 | _ | >1800 | 28,520 | 1580 |
| LRCWOS16 | 75 | 212 | 5 | _ | >1800 | 29,760 | 1580 |
| LRCWOS17 | 80 | 210 | 5 | _ | >1800 | _ | >1800 |
| LRCWOS18 | 80 | 225 | 5 | _ | >1800 | _ | >1800 |
| LRCWOS19 | 100 | 320 | 6 | _ | >1800 | _ | >1800 |
| LRCWOS20 | 100 | 380 | 7 | _ | >1800 | _ | >1800 |
| Average | 65 | 173 | 4 | _ | _ | 19,424 | _ |
| Instance Characteristics | |||||||
|---|---|---|---|---|---|---|---|
| U | Gap | ||||||
| 60 | 148 | 19 | 5 | 30,120 | 22,695 | 4 | 25% |
| 70 | 160 | 19 | 6 | 48,215 | 27,458 | 4 | 43% |
| 80 | 189 | 19 | 7 | 68,743 | 38,548 | 6 | 44% |
| 90 | 210 | 19 | 9 | 80,471 | 49,895 | 8 | 38% |
| 100 | 260 | 19 | 9 | 94,875 | 58,951 | 8 | 38% |
| 110 | 298 | 19 | 11 | 100,458 | 64,251 | 8 | 36% |
| 120 | 352 | 19 | 12 | 124,524 | 70,589 | 12 | 43% |
| 130 | 397 | 19 | 15 | 150,427 | 86,758 | 12 | 42% |
| 140 | 410 | 19 | 16 | 159,751 | 89,827 | 12 | 44% |
| 150 | 480 | 19 | 20 | 180,058 | 118,745 | 19 | 34% |
| 105 | 290 | 19 | 11 | 103,764 | 62,772 | 9 | 39% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oujana, S.; Amodeo, L.; Yalaoui, F.; Brodart, D. Mixed-Integer Linear Programming, Constraint Programming and a Novel Dedicated Heuristic for Production Scheduling in a Packaging Plant. Appl. Sci. 2023, 13, 6003. https://doi.org/10.3390/app13106003
Oujana S, Amodeo L, Yalaoui F, Brodart D. Mixed-Integer Linear Programming, Constraint Programming and a Novel Dedicated Heuristic for Production Scheduling in a Packaging Plant. Applied Sciences. 2023; 13(10):6003. https://doi.org/10.3390/app13106003
Chicago/Turabian StyleOujana, Soukaina, Lionel Amodeo, Farouk Yalaoui, and David Brodart. 2023. "Mixed-Integer Linear Programming, Constraint Programming and a Novel Dedicated Heuristic for Production Scheduling in a Packaging Plant" Applied Sciences 13, no. 10: 6003. https://doi.org/10.3390/app13106003