1. Introduction
With the popularization of personal electronic terminals such as smartphones and tablets, the amount of visual data available on the internet has been overgrown in recent years [
1]. Correspondingly, the performance of related image retrieval technologies is also improving and becoming more sophisticated [
2]. Content-based image retrieval (CBIR) is a type of search technology that aims to find images similar to the image input by users (query image), and it is extensively applied in the real world [
3]. For example, search engines of image retrieval functions (e.g., Google (
http://images.google.it, accessed on 23 February 2023)) and a similar production search of online shopping (e.g., Amazon (
https://www.amazon.co.jp/, accessed on 23 February 2023) and eBay (
https://www.ebay.com/, accessed on 23 February 2023))are examples of such applications. Conventional CBIR methods have exhibited remarkable precision in retrieving images that bear similarities to the query image, as documented in several studies [
4,
5,
6,
7]. It is feasible to efficiently and effectively retrieve associated images from a vast database using a single input image. In the last decade, extensive research efforts have been devoted to developing novel theories and models for CBIR, establishing several practical algorithms [
8]. However, as the volume of visual data on the web continues to increase, there is a growing imperative to consider users’ subjective preferences during image retrieval to enhance the value of the retrieved data and satisfy the increasing demands of users.
For users, whether the retrieval result is appropriate cannot be judged solely by the image content, but also based on the user’s preferences. The aforementioned problem is a crucial challenge known as the semantic gap [
9], which CBIR has been facing for a long time. Since the query image input by a user is rich in detail and information, it can be challenging for the CBIR model to accurately localize which specific part of the image the user intends to retrieve a similar one from the dataset [
10]. Conventional CBIR methods compare the features of the query image with the features of images in the dataset (candidate images) and rank these candidate images according to their similarity to the query image. Fadaei et al. [
11] proposed an approach to extract dominant color descriptors for CBIR. The approach uses a weighting mechanism that assigns more importance to the informative pixels of an image using suitable masks. However, these methods may fail to rank images fitting to the user’s preferences with a high rank consistently. To achieve user-oriented image retrieval, one of the possible strategies is to re-order the images of the initial retrieval, satisfying the user’s preferences with a higher position.
Re-ranking is an approach to re-order the results of initial retrieval using reliable information and typically plays a role in the post-processing step in image retrieval tasks [
12]. Re-ranking methods can be classified into two categories based on the information source employed: self-re-ranking and interactive re-ranking [
13]. Self-re-ranking approaches aim to improve the accuracy of initial retrieval results by identifying relevant visual patterns from them and re-ordering them based on external information, such as text labels or class information. For example, Zhang et al. [
14] proposed a new method based on a global model for extracting features from the entire image and a local model for extracting features from individual regions of interest in the image. The results from these two models are then combined using a re-ranking approach, which significantly improves the accuracy of the retrieval results. Conversely, interactive re-ranking approaches use user feedback from the initial retrieval results as preference information for re-ordering [
13]. Therefore, interactive re-ranking is expected to achieve higher user satisfaction by utilizing feedback reflecting users’ preferences.
Recent studies [
15,
16,
17] have shown that gaze information, which consists of human eye movements, plays a critical role in visual recognition during daily life and involves attention shifts. Gaze information is integral to non-verbal communication in an interaction process between humans and the natural world and is closely related to user’s preferences when viewing images [
18]. Therefore, by introducing the user’s gaze information into the initial retrieval re-order as the user’s feedback information for re-ranking, the users are expected to find their desired images in a higher rank. However, directly using gaze trace data in a coordinate format may not accurately capture the relationships between objects in an image, which could be problematic.
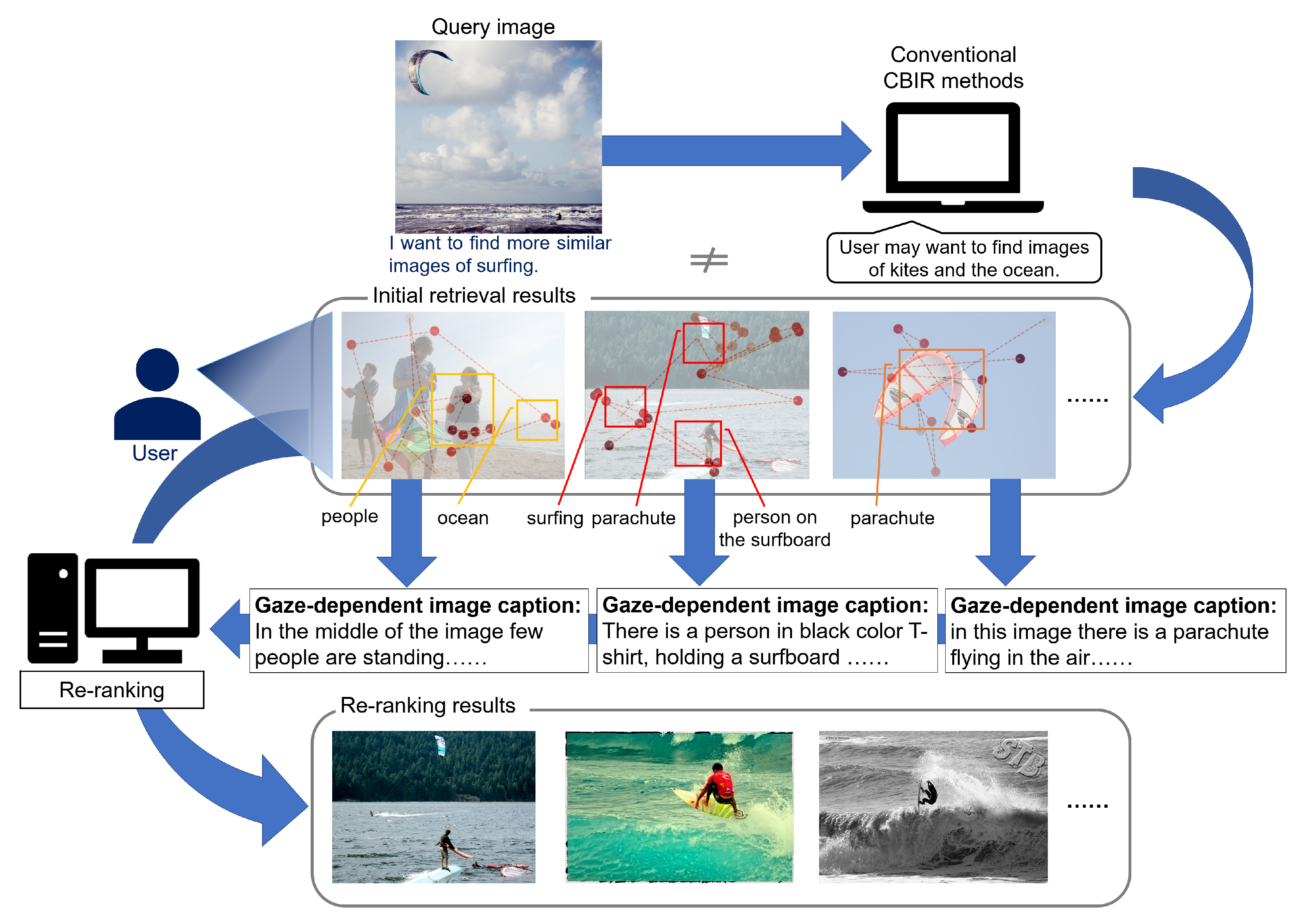
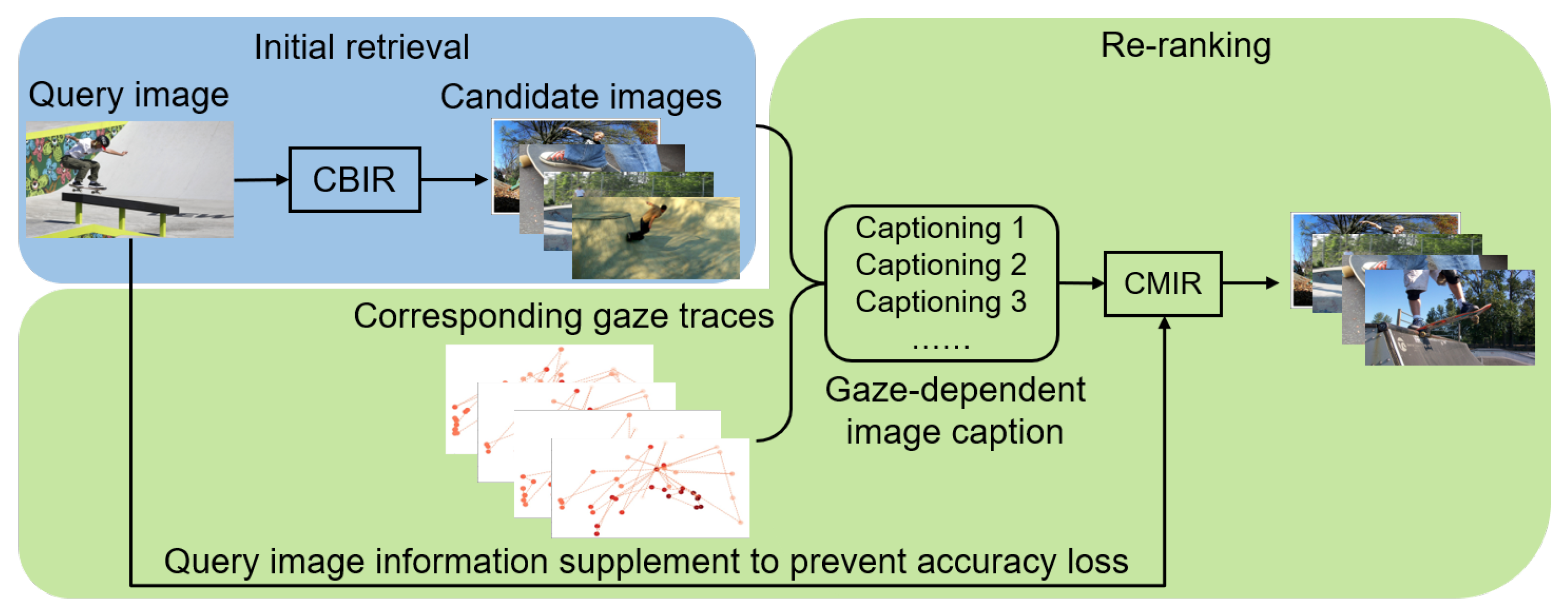
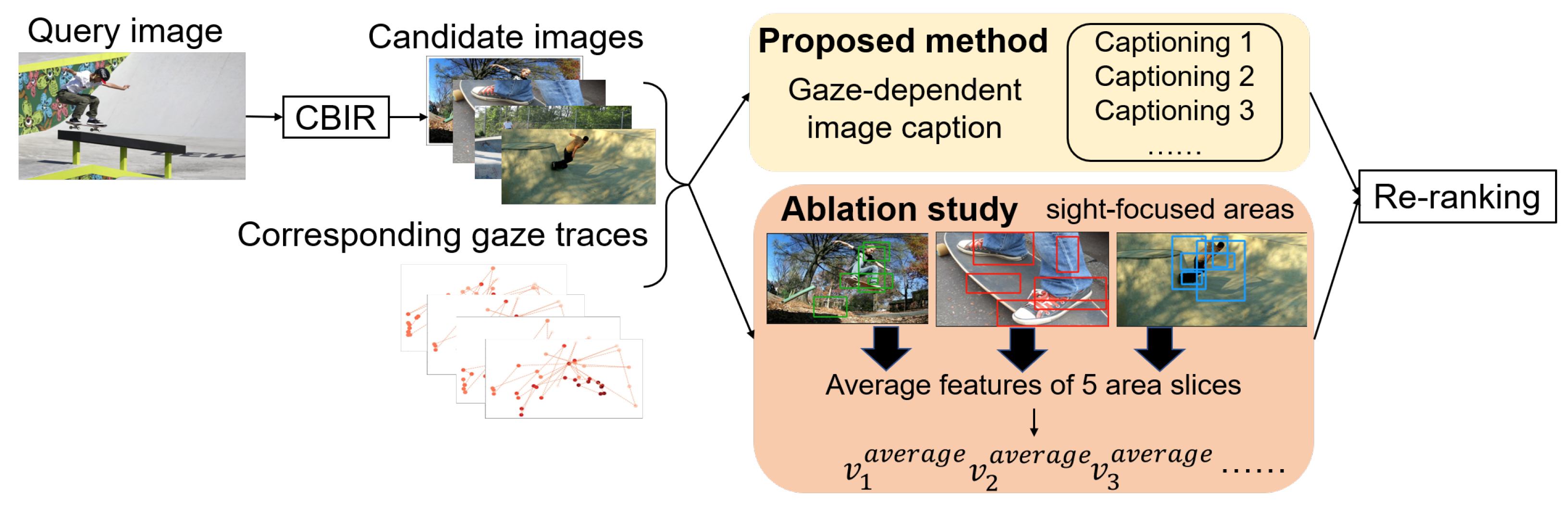
To tackle the abovementioned issue, we propose a novel CBIR method utilizing image captioning as a gaze-dependent image re-ranking method.
Figure 1 illustrates the underlying concept of our proposed image re-ranking method. Our method leverages the interdisciplinary technology of image captioning. This technique enables machines to automatically produce natural language descriptions for any given image [
19]. The proposed method entails developing a neural network that integrates images and gaze information to generate image captioning controlled by gaze traces. The transformer is used in the proposed method, focusing on its characteristics. In contrast to convolutional neural networks (CNNs) that rely on local connectivity, the transformer achieves a global representation through shallow layers and preserves spatial information [
20]. Given the expectation that the transformer model is more closely aligned with human visual characteristics than CNNs [
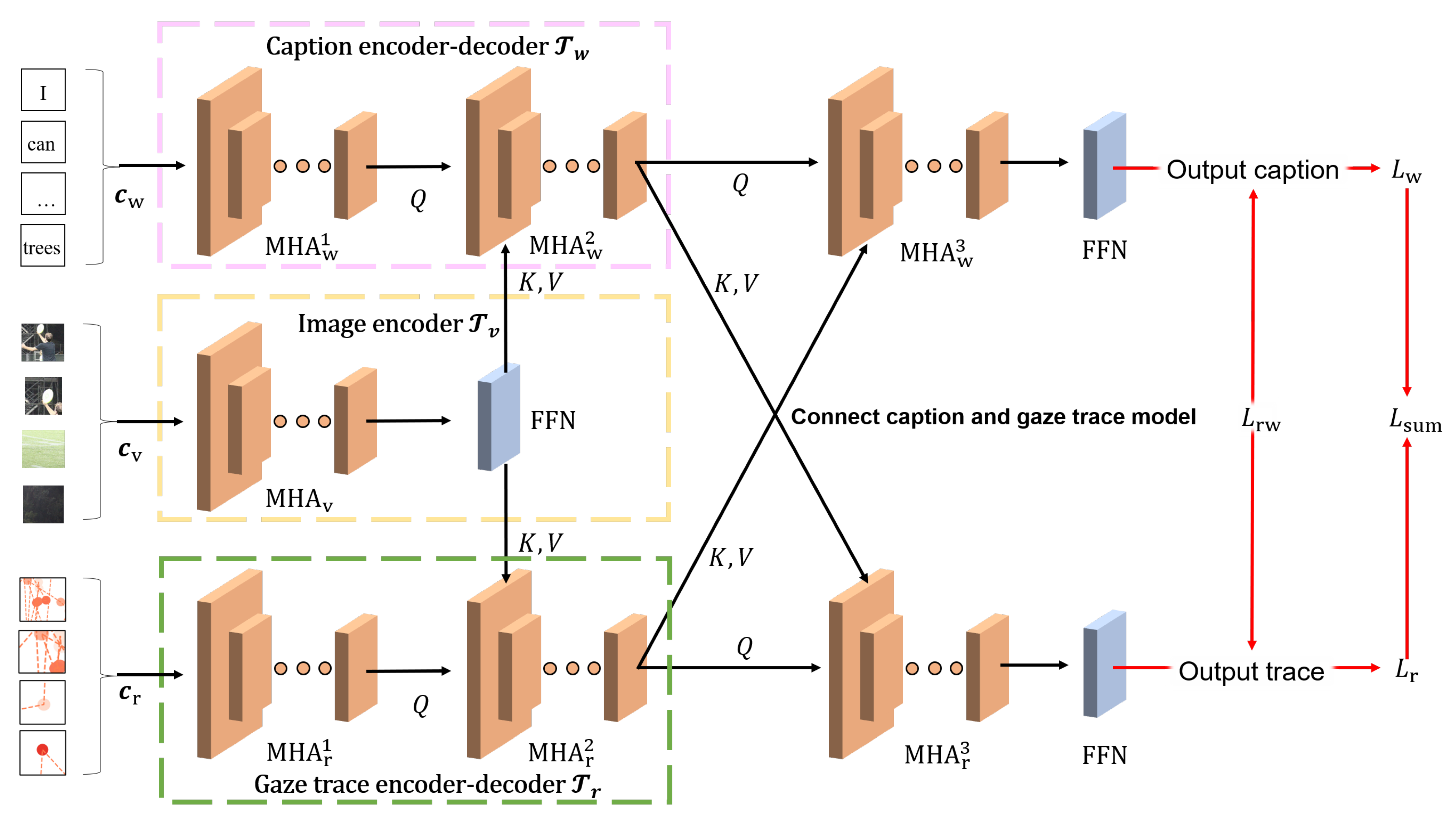
21], the proposed method trains a connected caption and gaze trace (CGT) model [
22] on the basis of the transformer architecture. This enables the model to learn the intricate relationship between images, captioning, and gaze traces.
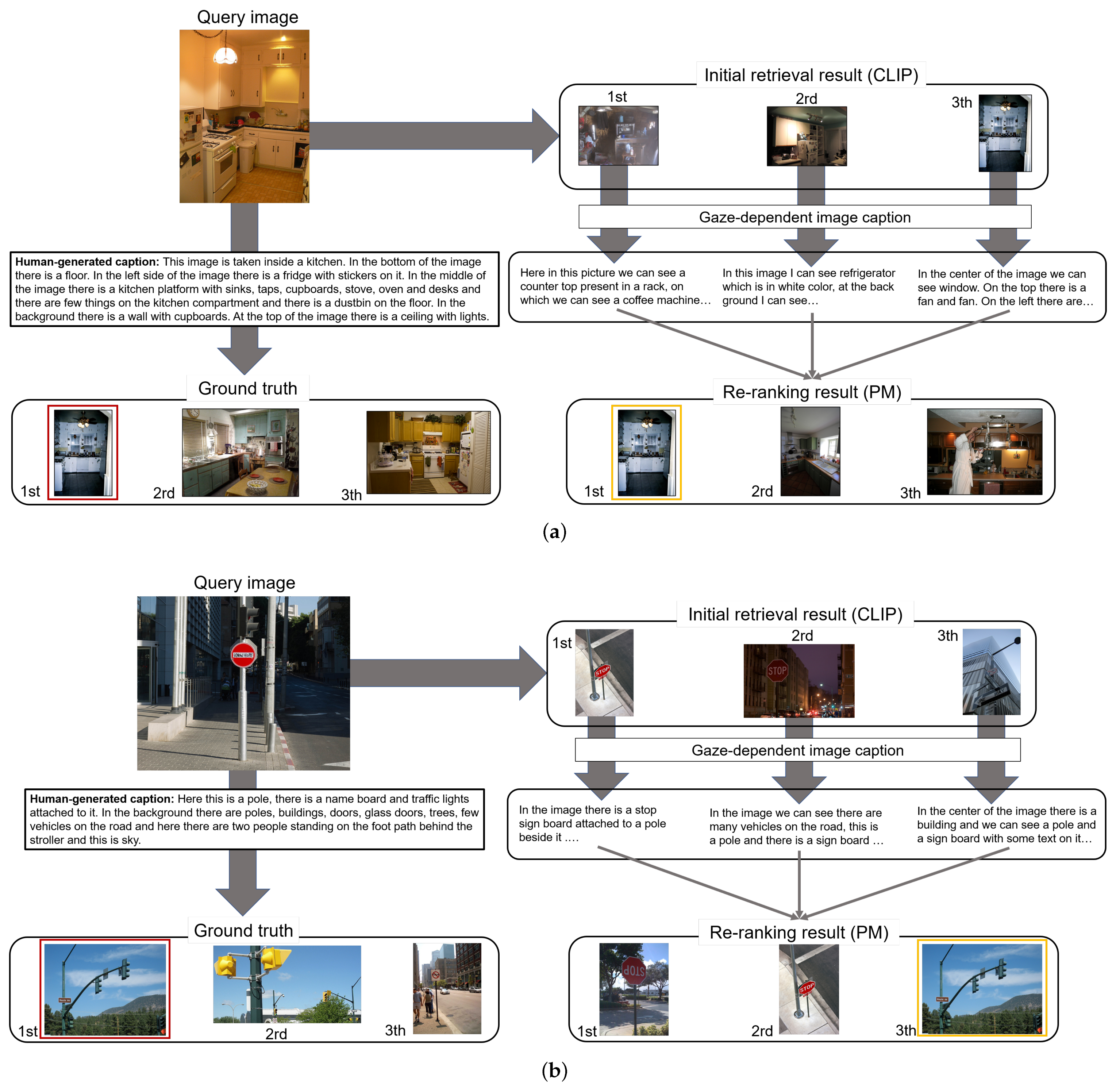
With the introduction of image captioning, which connects image features and gaze information, the proposed method can explicitly express semantic information in images (e.g., relationships between objects that users focus on) to realize the re-ranking that accurately reflects the user’s preferences. Specifically, our method uses the Contrastive Language-Image Pre-Training (CLIP) model [
23], extensively acknowledged as one of the most sophisticated cross-modal embedding techniques currently available. The primary objective of CLIP is to create a common latent space for computing the similarity between images and text. Therefore, we can compare the gaze-dependent image captions and the candidate images by embedding them in the latent space and ranking the images that reflect the user’s preferences higher in the re-order process. Extensive experimentation demonstrates the remarkable performance of the proposed method in re-ranking for image retrieval on a publicly available dataset [
24] of annotated images in the MSCOCO dataset [
25].
In conclusion, the key contributions of our study are as follows.
We propose a novel gaze-dependent re-ranking method for CBIR to tackle the “semantic gap” challenge of the conventional CBIR methods.
We introduce the gaze-dependent image caption to convert coordinate-format visual information into text-format semantic information, thereby realizing re-ranking according to the users’ preferences.
Note that we have previously presented some preliminary results of our current work in a prior study [
22], where we demonstrated the effectiveness of incorporating gaze-dependent image captioning for achieving personalized image retrieval. In this study, we build upon our previous work and extend it in the following ways. First, we expand on our previous study by utilizing gaze-dependent image captioning as auxiliary information to achieve user-oriented image re-ranking. Second, we evaluate the effectiveness of previous cross-modal retrieval methods and interactive re-ranking methods to validate the robustness of our proposed method. Finally, in our ablation study, we verify the novelty of our method by comparing the effectiveness of incorporating gaze data directly for re-ranking and transforming the data from coordinate data into a text format to bridge the semantic gap in CBIR effectively.
The remainder of this paper is structured as follows.
Section 2 briefly overviews the related works.
Section 3 presents a detailed description of our proposed gaze-dependent image re-ranking method for CBIR. The experimental results are presented in
Section 4, where we provide qualitative and quantitative results of the proposed method.
Section 5 discusses the implications of our findings and limitations associated with our study. Finally, we conclude with a summary of our contributions in
Section 6.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}