
A Personalized Learning Path Recommendation Method Incorporating Multi-Algorithm
Abstract
:1. Introduction
2. Problem Formulation
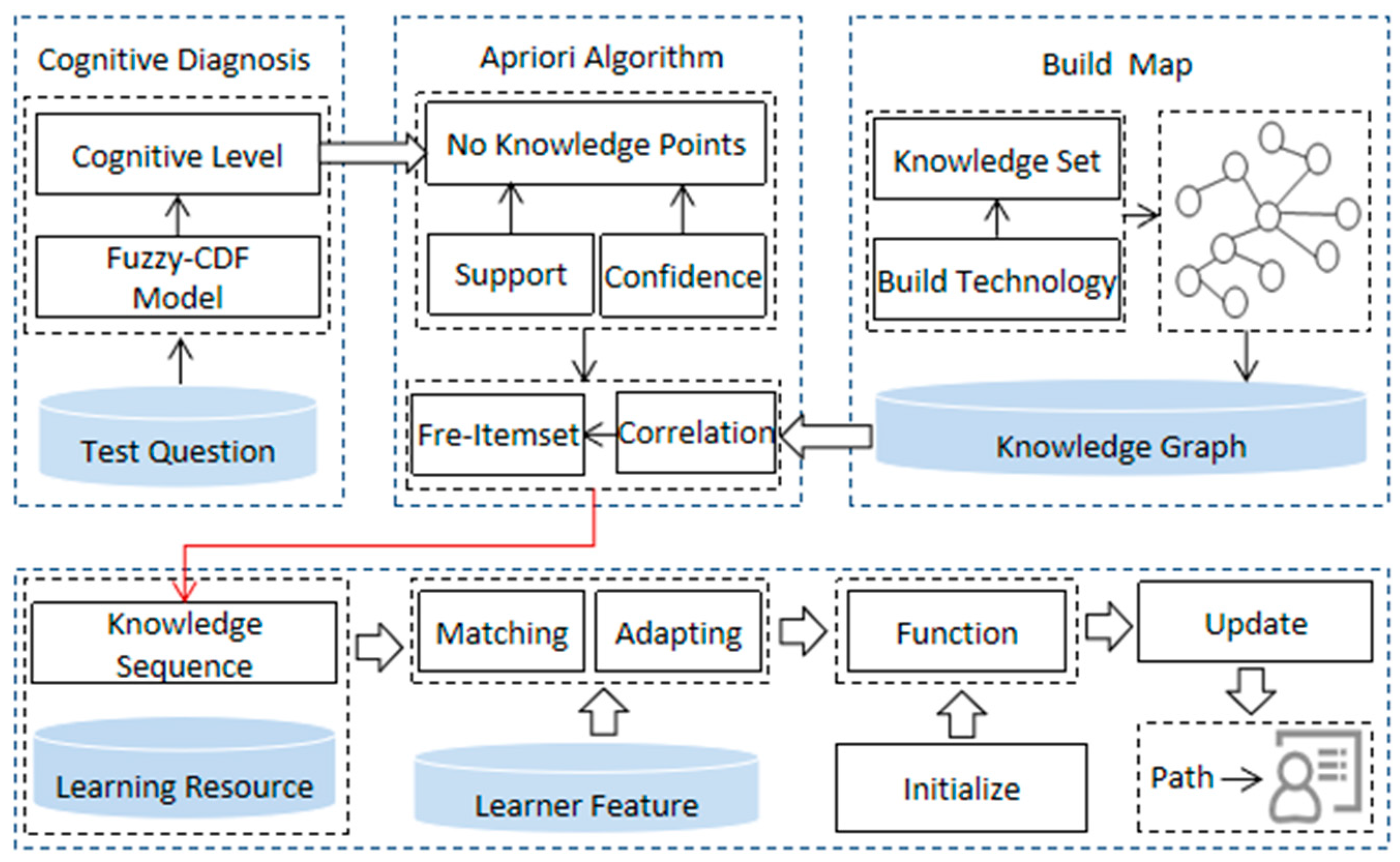
3. Methodology
3.1. Related Work
3.1.1. Cognitive Level Based on Fuzzy-CDF
3.1.2. Quantitative Learning Ability
- Executive Ability
- 2.
- Adaptive Ability
- 3.
- Knowledge Management Ability
- 4.
- Ability to analyse and solve problems
3.1.3. Learning Style Based on the Felder Silverman Scale
3.1.4. Learning Intensity Modelling
- Learning Engagement
- Participation
- Activity
3.2. Generating Knowledge Point Sequences
3.3. Design of Recommendation Algorithm
3.3.1. Matching Degree
3.3.2. Adaptability of Learners and Resources
4. Experiments and Results
4.1. Experimental Data
4.2. Experimental Design
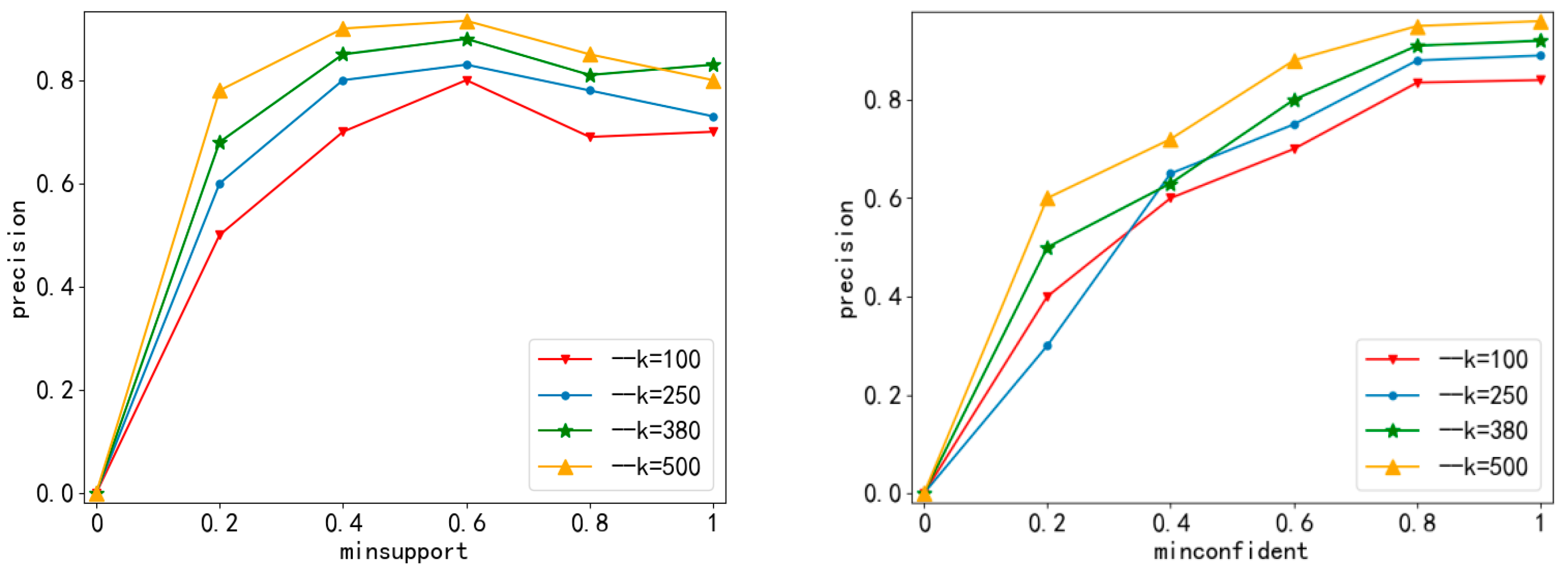
4.2.1. Experiment of Knowledge Point Sequence
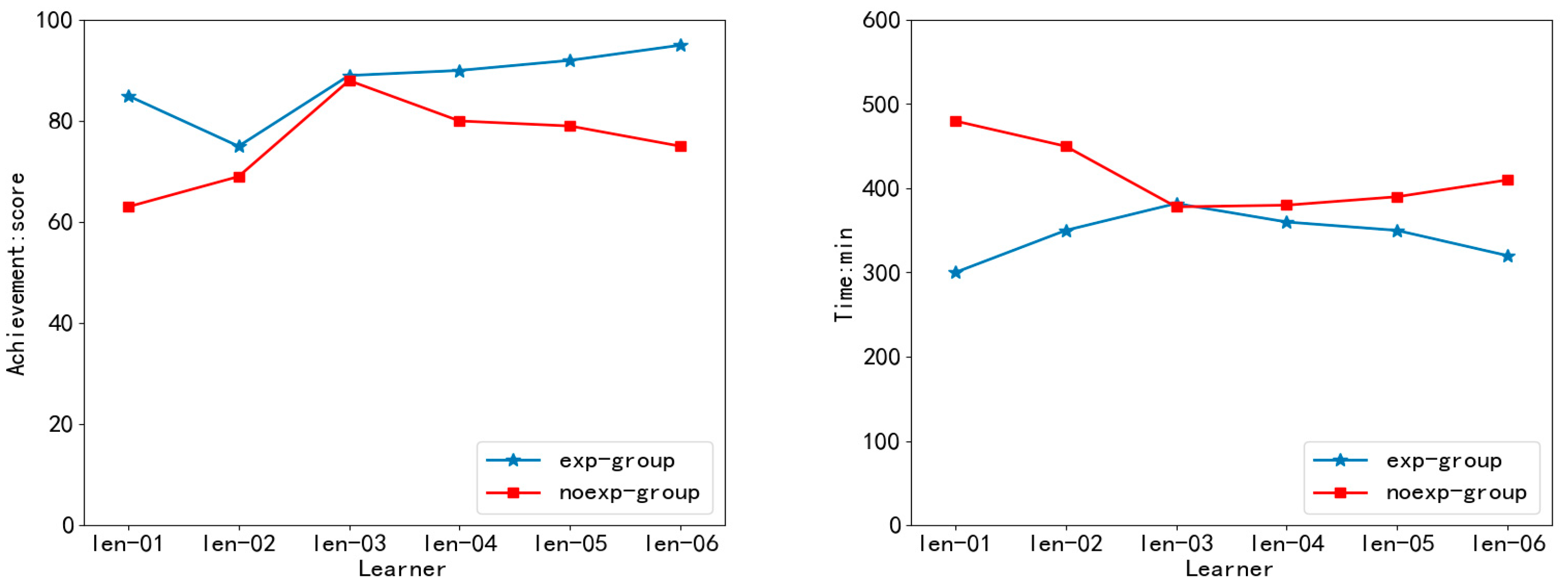
4.2.2. Experiment of Recommended Model
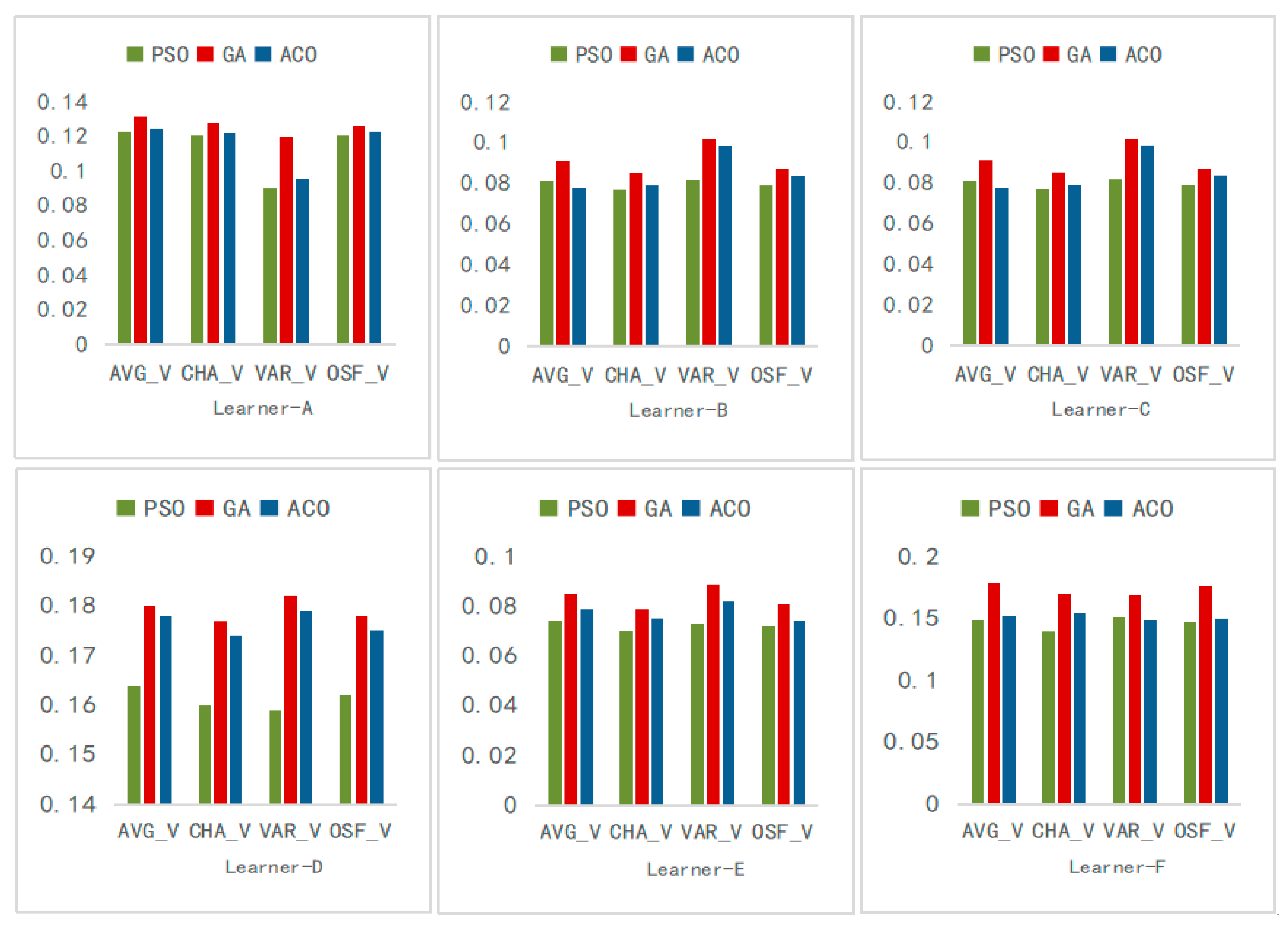
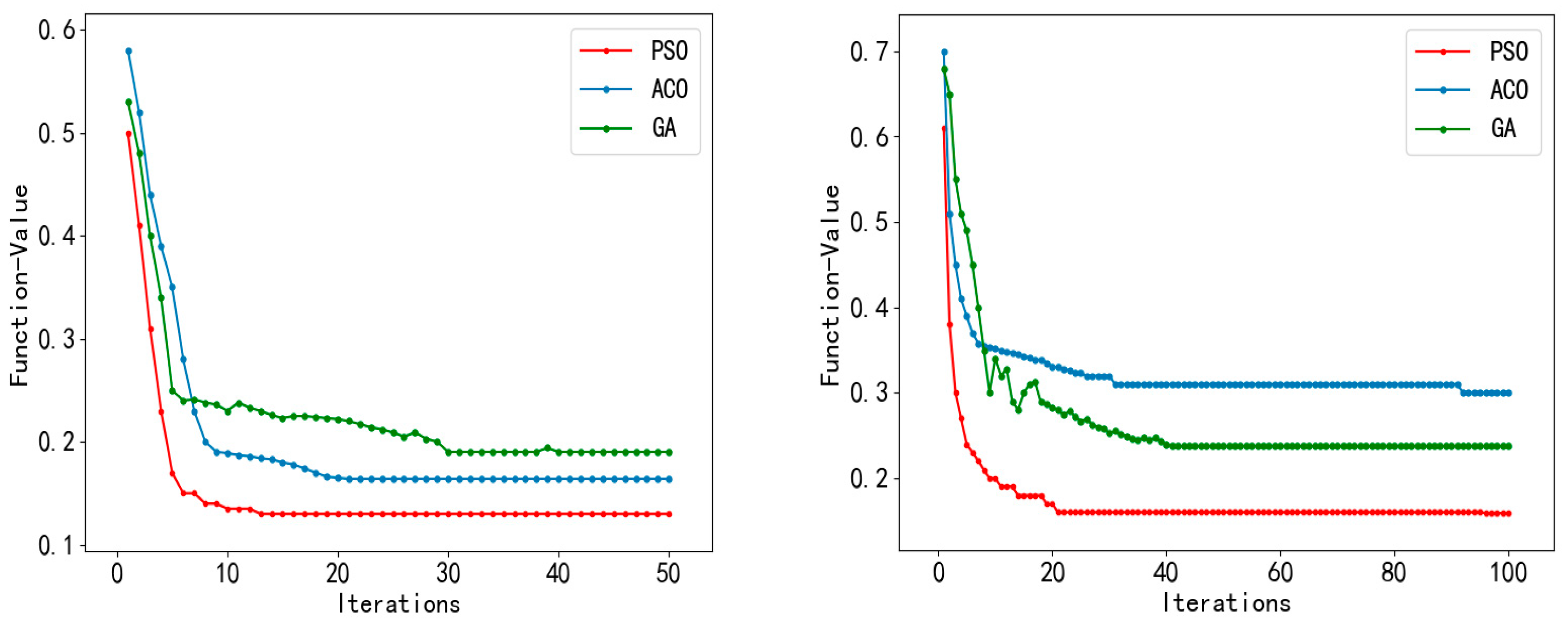
4.3. Result Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, X.; Liu, S.; Wang, H. Personalized learning path recommendation for e-learning based on knowledge graph and graph convolutional network. J. Int. J. Softw. Eng. Knowl. Eng. 2023, 33, 109–131. [Google Scholar] [CrossRef]
- Sun, Y.; Liang, J.; Niu, P. Personalized Recommendation of English Learning Based on Knowledge Graph and Graph Convolutional Network. In Artificial Intelligence and Security(ICAIS); Springer International Publishing: Cham, Switzerland, 2021; pp. 157–166. [Google Scholar]
- Son, N.T.; Jaafar, J.; Aziz, I.A.; Anh, B.N. Meta-Heuristic Algorithms for Learning Path Recommender at MOOC. IEEE Access 2021, 9, 59093–59107. [Google Scholar] [CrossRef]
- Cai, D.; Zhang, Y.; Dai, B. Learning path recommendation based on knowledge tracing model and reinforcement learning. In Proceedings of the International Conference on Computer and Communications (ICCC), Chengdu, China, 6–9 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1881–1885. [Google Scholar]
- Li, W.; Zhang, L. Personalized learning path generation based on network embedding and learning effects. In Proceedings of the International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 18–20 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 316–319. [Google Scholar]
- Cheng, B.; Zhang, Y.; Shi, D. Ontology-based personalized learning path recommendation for course learning. In Proceedings of the International Conference on Information Technology in Medicine and Education (ITME), Hangzhou, China, 19–21 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 531–535. [Google Scholar]
- Chen, Y.H.; Huang, N.F.; Tzeng, J.W.; Lee, C.-A.; Huang, Y.-X.; Huang, H.-H. A Personalized Learning Path Recommender System with LINE Bot in MOOCs Based on LSTM. In Proceedings of the 2022 11th International Conference on Educational and Information Technology (ICEIT), Chengdu, China, 6–8 January 2022; pp. 40–45. [Google Scholar]
- Dibello, L.V.; Roussos, L.A.; Stout, W. 31A review of cognitively diagnostic assessment and a summary of psychometric models. J. Handb. Stat. 2006, 26, 979–1030. [Google Scholar]
- Junker, B.W.; Sijtsma, K. Cognitive assessment models with few assumptions, and connections with nonparametric item response theory. J. Appl. Psychol. Meas. 2001, 25, 258–272. [Google Scholar] [CrossRef]
- Templin, J.L.; Henson, R.A. Measurement of psychological disorders using cognitive diagnosis models. J. Psychol. Methods 2006, 11, 287–305. [Google Scholar] [CrossRef] [PubMed]
- Liu, Q.; Wu, R.; Chen, E.; Xu, G.; Su, Y.; Chen, Z.; Hu, G. Fuzzy cognitive diagnosis for modelling examinee performance. J. ACM Trans. Intell. Syst. Technol. 2018, 9, 1–26. [Google Scholar] [CrossRef]
- Jantzen, J. Foundations of Fuzzy Control: A Practical Approach, 2nd ed.; John Wiley & Sons Inc.: Hoboken, NJ, USA, 2013. [Google Scholar]
- He, H.; Zhu, Z.; Guo, Q.; Huang, X. A personalized e-learning services recommendation algorithm based on user learning ability. In Proceedings of the International Conference on Advanced Learning Technologies (ICALT), Maceio, Brazil, 15–18 July 2019; pp. 318–320. [Google Scholar]
- Yi, B.; Zhang, D.; Wang, Y.; Liu, H.; Zhang, Z.; Shu, J.; Lv, Y. Research on personalized learning model under informatization environment. In Proceedings of the International Symposium on Educational Technology (ISET), Hong Kong, China, 27–29 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 48–52. [Google Scholar]
- Sihombing, J.H.; Laksitowening, K.A.; Darwiyanto, E. Personalized e-learning content based on Felder-Silverman learning style model. In Proceedings of the International Conference on Information and Communication Technology (ICoICT), Yogyakarta, Indonesia, 24–26 June 2020; pp. 1–6. [Google Scholar]
- Wu, H.; Liu, Q.; Zhang, Z. Analysis of University Students Employment Recommendation System Based on Apriori Algorithm. In Proceedings of the 2020 Asia-Pacific Conference on Image Processing, Electronics and Computers (IPEC), Dalian, China, 14–16 April 2020; pp. 262–265. [Google Scholar]
- Sha, O. Student detection and people counting system based on apriori algorithm. In Proceedings of the 2022 International Conference on Education, Network and Information Technology (ICENIT), Liverpool, UK, 2–3 September 2022; pp. 138–142. [Google Scholar]
- Gupta, A.; Virmani, A.; Mahajan, P.; Nallanthigal, R. A Particle Swarm Optimization-Based Cooperation Method for Multiple-Target Search by Swarm UAVs in Unknown Environments. In Proceedings of the 2021 7th International Conference on Automation, Robotics and Applications (ICARA), Prague, Czech Republic, 4–6 February 2021; pp. 95–100. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Learning Style | B-P | Pattern Quantization | Threshold | |
|---|---|---|---|---|
| L<->M | M<->H | |||
| Active/Meditating | P-V (+) | Posting data of all learning tasks | <2 | >5 |
| PB-V (−) | Reply data of all learning tasks | <10 | >30 | |
| FV-T (+) | (Forum visit/total course) × 100% | <5% | >15% | |
| D-A (+) | Discussion amount of learning task | <2 | >5 | |
| T-A (+) | Test amount of learned task | <2 | >5 | |
| Perceptual/Intuitive | DV-A (+) | (Document views/total views) × 100% | <50% | >75% |
| DB-T (+) | (Relative brows/total brows) × 100% | <75% | >100% | |
| DD-T (−) | (material downloads/total downloads) × 100%—Video, courseware, exercises | <50% | >75% | |
| TD-T (+) | (Test-S/maximum-S allowed) × 100% | <70% | >90% | |
| Visual/Verbal | VB-T (+) | (Actual view-T/expected view-T) × 100% | <75% | >100% |
| VP-A (+) | (Video playback-S/total playback-S) × 100% | <75% | >100% | |
| MV-A (+) | (Map views/total views) × 100% | <50% | >75% | |
| MB-T (−) | (Actual browsing duration of the atlas/total browsing duration) × 100% | <75% | >100% | |
| Sequential/Comprehensive | CC-A (+) | (Times of clicking chapter button/total times) × 100% | <30% | >70% |
| KC-A (−) | (Number of clicks on knowledge points/total times) × 100% | <30% | >70% | |
| S-A (+) | (Number of search maps/total search times) × 100%—comprehensive maps, sub maps of chapters | <30% | >70% | |
| Question No. | Knowledge Points Not Mastered (ng) |
|---|---|
| EX-NO-01 | 2, 4, 15, 23 |
| EX-NO-02 | 2, 7, 8, 10 |
| EX-NO-03 | 1, 5, 9, 20, 21 |
| EX-NO-04 | 19, 16, 3, 6 |
| EX-NO-05 | 11, 25, 14, 17 |
| Serial No. | Itemset | Support (%) |
|---|---|---|
| FQ-IT-1 | 1, 4, 13, 17, 20 | 30 |
| FQ-IT-2 | 1, 2, 4, 7, 19 | 55 |
| FQ-IT-3 | 1, 4, 7, 17, 19 | 66 |
| FQ-IT-4 | 4, 7, 8, 11, 15 | 12 |
| FQ-IT-5 | 2, 3, 10, 21, 25 | 53 |
| Learner | NO-A | NO-B | NO-C | NO-D | NO-E | NO-F |
|---|---|---|---|---|---|---|
| coverage (%) | 91 | 90 | 99 | 93 | 94 | 96 |
| Learner | Target (%) | APRIORI | TO | FA | TL-KG | DL |
|---|---|---|---|---|---|---|
| learner-A | precision | 88.2 | 72.1 | 83.6 | 87.3 | 84.2 |
| coverage | 90.6 | 87.0 | 79.3 | 82.9 | 78.3 | |
| learner-B | precision | 79.2 | 72.3 | 79.5 | 77.3 | 72.5 |
| coverage | 77.8 | 69.3 | 75.3 | 71.8 | 74.7 | |
| learner-C | precision | 97.0 | 95.2 | 94.3 | 92.1 | 85.4 |
| coverage | 86.3 | 84.0 | 79.4 | 82.8 | 78.6 | |
| learner-D | precision | 82.2 | 78.4 | 79.2 | 80.2 | 82.3 |
| coverage | 93.1 | 80.3 | 86.4 | 90.1 | 85.2 | |
| learner-E | precision | 75.5 | 70.4 | 72.0 | 69.8 | 74.1 |
| coverage | 80.1 | 78.0 | 80.0 | 75.3 | 72.2 | |
| learner-F | precision | 98.5 | 86.3 | 90.0 | 87.2 | 89.3 |
| coverage | 89.3 | 85.0 | 82.9 | 87.4 | 88.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Y.; Wang, L.; Zhang, J.; Liu, F.; Jiang, Q. A Personalized Learning Path Recommendation Method Incorporating Multi-Algorithm. Appl. Sci. 2023, 13, 5946. https://doi.org/10.3390/app13105946
Ma Y, Wang L, Zhang J, Liu F, Jiang Q. A Personalized Learning Path Recommendation Method Incorporating Multi-Algorithm. Applied Sciences. 2023; 13(10):5946. https://doi.org/10.3390/app13105946
Chicago/Turabian StyleMa, Yongjuan, Lei Wang, Jiating Zhang, Fengjuan Liu, and Qiaoyong Jiang. 2023. "A Personalized Learning Path Recommendation Method Incorporating Multi-Algorithm" Applied Sciences 13, no. 10: 5946. https://doi.org/10.3390/app13105946