
Abusive Content Detection in Arabic Tweets Using Multi-Task Learning and Transformer-Based Models

Abstract
:1. Introduction
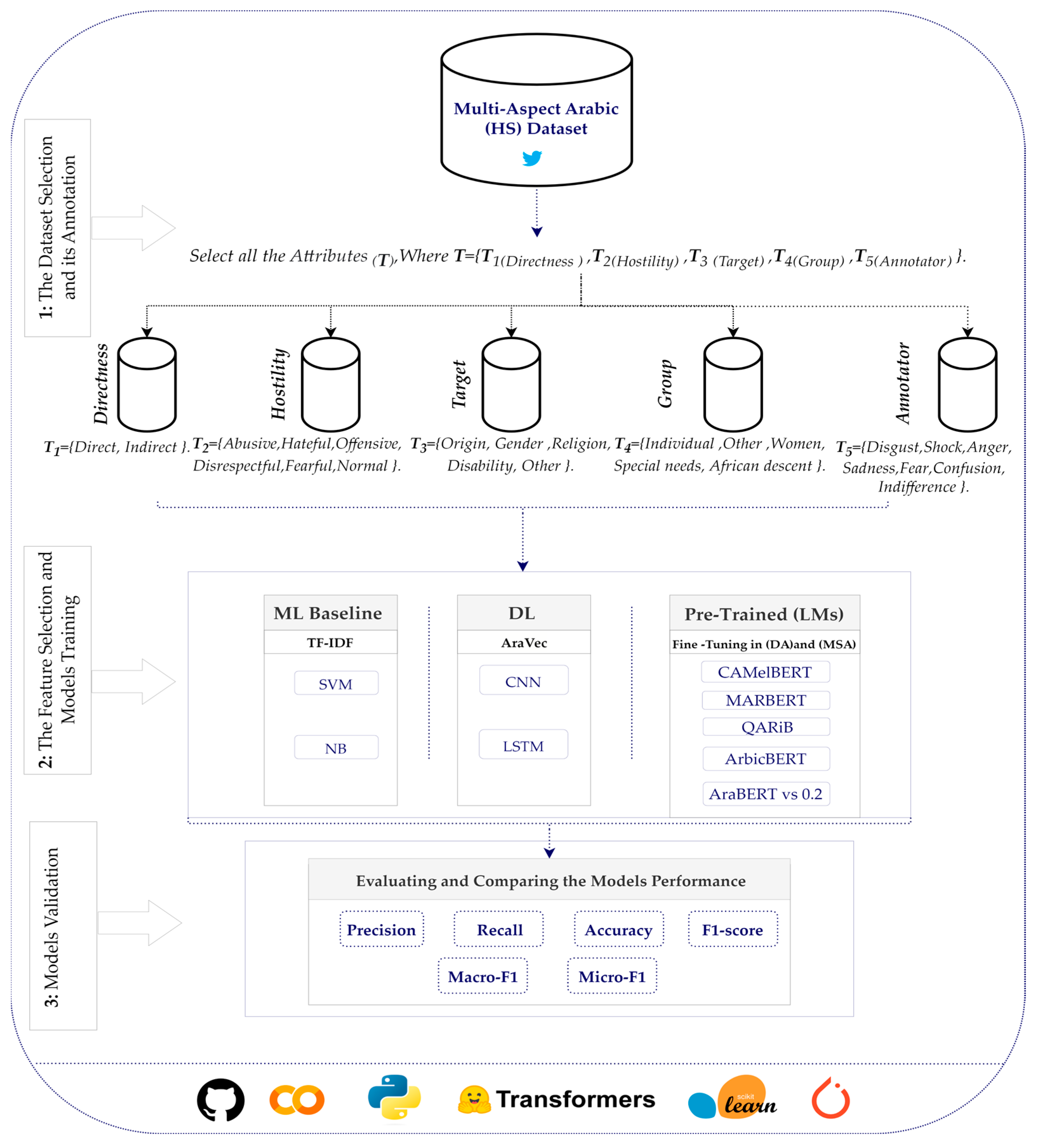
- We present a framework for automatic abusive content detection in Arabic by using the multi-aspect annotated dataset and applying ML, DL, and pretrained LMs in DA and MSA. Then, we comprehensively evaluate the performance of each approach.
- We propose a MTL model that is built upon pretrained LMs in DA (called MARBERT) to investigate its impact on automatic abusive Arabic content detection.
- We apply four different neural network (NN) architectures to the MTL model and then comprehensively evaluate the performance of each experiment.
2. Literature Review
2.1. Automatic Abusive Content Detection in the Arabic Language
2.2. The Available Datasets for Automatic Abusive Content Detection in the Arabic Language
3. Materials and Methods
3.1. Dataset Description
3.2. The Proposed Framework for Automatic Abusive Content Detection in the Arabic Language
3.3. The Proposed MTL Architecture
4. Experimental Setup
4.1. Experiment Settings
4.2. Performance Measures
5. Results and Discussion
5.1. Results of the Proposed Framework
5.2. Results of the MTL Models
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DA | Dialectal Arabic |
| NLP | Natural language processing |
| ML | Machine learning |
| DL | Deep learning |
| LMs | Language models |
| MTL | Muti-task learning |
| BERT | Bidirectional encoder representations from transformers |
| MSA | Modern standard Arabic |
| CA | Classical Arabic |
| NN | Neural network |
| SVM | Support vector machine |
| LR | Logistic regression |
| NB | Naive Bayes |
| DNN | Deep neural network |
| LSTM | Long short-term memory |
| BiLSTM | Bidirectional LSTM |
| GRU | Gated recurrent units |
| CNN | Convolutional neural network |
| OSACT | Open-source Arabic corpora and processing tools |
References
- Salem, F. Social Media and the Internet of Things (The Arab Social Media Report 2017); MBR School of Government: Dubai, United Arab Emirates, 2017. [Google Scholar]
- Abdelali, A.; Mubarak, H.; Samih, Y.; Hassan, S.; Darwish, K. Arabic Dialect Identification in the Wild. arXiv 2020, arXiv:2005.06557. [Google Scholar]
- Fraiwan, M. Identification of Markers and Artificial Intelligence-Based Classification of Radical Twitter Data. Appl. Comput. Informatics 2022. [Google Scholar] [CrossRef]
- MacAvaney, S.; Yao, H.R.; Yang, E.; Russell, K.; Goharian, N.; Frieder, O. Hate Speech Detection: Challenges and Solutions. PLoS ONE 2019, 14, e0221152. [Google Scholar] [CrossRef]
- AlKhamissi, B.; Diab, M. Meta AI at Arabic Hate Speech 2022: MultiTask Learning with Self-Correction for Hate Speech Classification. arXiv 2022, arXiv:2205.07960. [Google Scholar]
- Sanguinetti, M.; Poletto, F.; Bosco, C.; Patti, V.; Stranisci, M. An Italian Twitter Corpus of Hate Speech against Immigrants. In Proceedings of the LREC 2018—11th International Conference on Language Resources and Evaluation, Miyazaki, Japan, 7–12 May 2018; pp. 2798–2805. [Google Scholar]
- Assimakopoulos, S.; Muskat, R.V.; Van Der Plas, L.; Gatt, A. Annotating for Hate Speech: The MaNeCo Corpus and Some Input from Critical Discourse Analysis. arXiv 2020, arXiv:2008.06222. [Google Scholar]
- Alshalan, R.; Al-Khalifa, H. A Deep Learning Approach for Automatic Hate Speech Detection in the Saudi Twittersphere. Appl. Sci. 2020, 10, 8614. [Google Scholar] [CrossRef]
- Ousidhoum, N.; Lin, Z.; Zhang, H.; Song, Y.; Yeung, D.Y. Multilingual and Multi-Aspect Hate Speech Analysis. In Proceedings of the EMNLP-IJCNLP 2019—2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 4675–4684. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Abdul-Mageed, M.; Elmadany, A.R.; Nagoudi, E.M.B. ARBERT & MARBERT: Deep Bidirectional Transformers for Arabic. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 5–6 August 2021; Association for Computational Linguistics: Cedarville, OH, USA, 2021; pp. 7088–7105. [Google Scholar] [CrossRef]
- Safaya, A.; Abdullatif, M.; Yuret, D. KUISAIL at SemEval-2020 Task 12: BERT-CNN for Offensive Speech Identification in Social Media. In Proceedings of the 14th International Workshops on Semantic Evaluation, SemEval 2020—Co-Located 28th International Conference on Computational Linguistics, Virtual, 8–12 December 2020; pp. 2054–2059. [Google Scholar]
- Inoue, G.; Alhafni, B.; Baimukan, N.; Bouamor, H.; Habash, N. The Interplay of Variant, Size, and Task Type in Arabic Pre-Trained Language Models. In Proceedings of the WANLP 2021—6th Arabic Natural Language Processing Workshop, Proceedings of the Workshop, Kyiv, Ukraine, 19 April 2021; pp. 92–104. [Google Scholar]
- Abdelali, A.; Hassan, S.; Mubarak, H.; Darwish, K.; Samih, Y. Pre-Training BERT on Arabic Tweets: Practical Considerations. arXiv 2021, arXiv:2102.10684. [Google Scholar]
- Antoun, W.; Baly, F.; Hajj, H. AraBERT: Transformer-Based Model for Arabic Language Understanding. arXiv 2020. [Google Scholar] [CrossRef]
- Zampieri, M.; Malmasi, S.; Nakov, P.; Rosenthal, S.; Farra, N.; Kumar, R. SemEval-2019 Task 6: Identifying and Categorizing Offensive Language in Social Media (OffensEval). arXiv 2019, arXiv:1903.08983. [Google Scholar]
- Liu, P.; Li, W.; Zou, L. NULI at SemEval-2019 Task 6: Transfer Learning for Offensive Language Detection Using Bidirectional Transformers. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 87–91. [Google Scholar]
- Dai, W.; Yu, T.; Liu, Z.; Fung, P. Kungfupanda at SemEval-2020 Task 12: BERT-Based Multi-Task Learning for Offensive Language Detection. In Proceedings of the 14th International Workshops on Semantic Evaluation, SemEval 2020—Co-Located 28th International Conference on Computational Linguistics, Virtual, 8–13 December 2020; pp. 2060–2066. [Google Scholar]
- Albadi, N.; Kurdi, M.; Mishra, S. Are They Our Brothers? Analysis and Detection of Religious Hate Speech in the Arabic Twittersphere. In Proceedings of the IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining—ASONAM 2018, Barcelona, Spain, 28–31 August 2018; pp. 69–76. [Google Scholar]
- Duwairi, R.; Hayajneh, A.; Quwaider, M. A Deep Learning Framework for Automatic Detection of Hate Speech Embedded in Arabic Tweets. Arab. J. Sci. Eng. 2021, 46, 4001–4014. [Google Scholar] [CrossRef]
- Mulki, H.; Haddad, H.; Bechikh Ali, C.; Alshabani, H. L-HSAB: A Levantine Twitter Dataset for Hate Speech and Abusive Language; Association for Computational Linguistics: Florence, Italy, 2019; pp. 111–118. Available online: https://aclanthology.org/W19-3512 (accessed on 28 September 2022).
- Al-Hassan, A.; Al-Dossari, H. Detection of Hate Speech in Arabic Tweets Using Deep Learning. Multimedia Systems; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Soliman, A.B.; Eissa, K.; El-Beltagy, S.R. AraVec: A Set of Arabic Word Embedding Models for Use in Arabic NLP. Procedia Comput. Sci. 2017, 117, 256–265. [Google Scholar] [CrossRef]
- Mubarak, H.; Darwish, K.; Magdy, W.; Al-Khalifa, H. Overview of OSACT4 Arabic Offensive Language Detection Shared Task; European Language Resource Association: Marseille, France, 2020; pp. 11–16. Available online: https://aclanthology.org/2020.osact-1.7 (accessed on 25 September 2021).
- Hassan, S.; Samih, Y.; Mubarak, H.; Abdelali, A.; Rashed, A.; Chowdhury, S.A. ALT Submission for OSACT Shared Task on Offensive Language Detection. In Proceedings of the OSACT 2020, Marseille, France, 12 May 2020. [Google Scholar]
- Husain, F. OSACT4 Shared Task on Offensive Language Detection: Intensive Preprocessing-Based Approach; European Language Resource Association: Marseille, France, 2020; Available online: https://aclanthology.org/2020.osact-1.8 (accessed on 28 September 2022).
- Djandji, M.; Baly, F.; Antoun, W.; Hajj, H. Multi-Task Learning Using AraBert for Offensive Language Detection. In Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, with a Shared Task on Offensive Language Detection, Marseille, France, 12 May 2020; pp. 97–101. [Google Scholar]
- Farha, I.A.; Magdy, W. Multitask Learning for Arabic Offensive Language and Hate-Speech Detection. In Proceedings of the OSACT 2020, Marseille, France, 12 May 2020. [Google Scholar]
- Aldjanabi, W.; Dahou, A.; Al-Qaness, M.A.A.; Elaziz, M.A.; Helmi, A.M.; Damaševičius, R. Arabic Offensive and Hate Speech Detection Using a Cross-Corpora Multi-Task Learning Model. Informatics 2021, 8, 69. [Google Scholar] [CrossRef]
- Balikas, G.; Moura, S.; Amini, M.R. Multitask Learning for Fine-Grained Twitter Sentiment Analysis. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 1005–1008. [Google Scholar] [CrossRef]
- Lu, G.; Zhao, X.; Yin, J.; Yang, W.; Li, B. Multi-Task Learning Using Variational Auto-Encoder for Sentiment Classification. Pattern Recognit. Lett. 2020, 132, 115–122. [Google Scholar] [CrossRef]
- Jin, N.; Wu, J.; Ma, X.; Yan, K.; Mo, Y. Multi-Task Learning Model Based on Multi-Scale CNN and LSTM for Sentiment Classification. IEEE Access 2020, 8, 77060–77072. [Google Scholar] [CrossRef]
- Al-Khalifa, H.; Mubarak, H.; Al-Thubaity, A.; Magdy, W.; Darwish, K. UPV at the Arabic Hate Speech 2022 Shared Task: Offensive Language and Hate Speech Detection Using Transformers and Ensemble Models. In Proceedings of the 5th Workshop on Open-Source Arabic Corpora and Processing Tools with Shared Tasks on Qur’an QA and Fine-Grained Hate Speech Detection, Marseille, France, 20 June 2022; pp. 20–25. [Google Scholar]
- Haddad, H.; Mulki, H.; Oueslati, A. T-HSAB: A Tunisian Hate Speech and Abusive Dataset. Commun. Comput. Inf. Sci. 2019, 1108, 251–263. [Google Scholar] [CrossRef]
- Amazon Mechanical Turk. Available online: https://www.mturk.com/ (accessed on 1 February 2023).
- Artstein, R.; Poesio, M. Inter-Coder Agreement for Computational Linguistics. Comput. Linguist. 2008, 34, 555–596. [Google Scholar] [CrossRef]
- Voyant Tools. Available online: https://voyant-tools.org/ (accessed on 1 February 2023).
- Kowsari, K.; Meimandi, K.J.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text Classification Algorithms: A Survey. Informatics 2019, 10, 150. [Google Scholar] [CrossRef]
- HKUST-KnowComp/MLMA_hate_speech: Dataset and Code of Our EMNLP 2019 Paper “Multilingual and Multi-Aspect Hate Speech Analysis”. Available online: https://github.com/HKUST-KnowComp/MLMA_hate_speech (accessed on 1 October 2022).
- Davidson, T.; Warmsley, D.; Macy, M.; Weber, I. Automated Hate Speech Detection and the Problem of Offensive Language. arXiv 2017, arXiv:1703.04009. [Google Scholar] [CrossRef]
- Robertson, S. Understanding Inverse Document Frequency: On Theoretical Arguments for IDF. J. Doc. 2004, 60, 503–520. [Google Scholar] [CrossRef]
- Mehdad, Y.; Tetreault, J. Do Characters Abuse More Than Words? 2016. Available online: https://aclanthology.org/W16-3638 (accessed on 5 October 2020).
- Schmidt, A.; Wiegand, M. A Survey on Hate Speech Detection Using Natural Language Processing. In Proceedings of the SocialNLP 2017—5th International Workshop on Natural Language Processing for Social Media, Proceedings of the Workshop AFNLP SIG SocialNLP, Valencia, Spain, 3 April 2017; pp. 1–10. [Google Scholar]
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to Fine-Tune BERT for Text Classification? In Chinese Computational Linguistics; Springer: Cham, Switzerland, 2019; Volume 11856, pp. 194–206. [Google Scholar] [CrossRef]
- Zhu, Y.; Kiros, R.; Zemel, R.; Salakhutdinov, R.; Urtasun, R.; Torralba, A.; Fidler, S. Aligning Books and Movies: Towards Story-like Visual Explanations by Watching Movies and Reading Books. Proc. IEEE Int. Conf. Comput. Vis. 2015, 2015, 19–27. [Google Scholar] [CrossRef]
- Hedderich, M.A.; Lange, L.; Adel, H.; Strötgen, J.; Klakow, D. A Survey on Recent Approaches for Natural Language Processing in Low-Resource Scenarios. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Virtual, 6–11 June 2021; pp. 2545–2568. [Google Scholar] [CrossRef]
- Nlpaug.Augmenter.Word.Context_word_embs—Nlpaug 1.1.11 Documentation. Available online: https://nlpaug.readthedocs.io/en/latest/augmenter/word/context_word_embs.html (accessed on 12 April 2022).
- Kang, Z.; Grauman, K.; Fei, S. Learning with Whom to Share in Multi-Task Feature Learning. 2011. Available online: https://dl.acm.org/doi/10.5555/3104482.3104548 (accessed on 21 September 2022).
- Long, M.; Cao, Z.; Wang, J.; Yu, P.S. Learning Multiple Tasks with Multilinear Relationship Networks. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 2017, pp. 1595–1604. [Google Scholar]
- Dankers, V.; Rei, M.; Lewis, M.; Shutova, E. Modelling the Interplay of Metaphor and Emotion through Multitask Learning. In Proceedings of the EMNLP-IJCNLP 2019—2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 2218–2229. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Welcome to Colaboratory—Colaboratory. Available online: https://colab.research.google.com/notebooks/intro.ipynb#recent=true (accessed on 3 February 2022).
- Transformers. Available online: https://huggingface.co/docs/transformers/index (accessed on 20 January 2022).
- Grandini, M.; Bagli, E.; Visani, G. Metrics for Multi-Class Classification: An Overview. arXiv 2020, arXiv:2008.05756. [Google Scholar]
- Mubarak, H.; Rashed, A.; Darwish, K.; Samih, Y.; Abdelali, A. Arabic Offensive Language on Twitter: Analysis and Experiments. In Proceedings of the WANLP 2021—6th Arabic Natural Language Processing Workshop, Kyiv, Ukraine, 19 April 2021; pp. 126–135. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Source | Language | Size | Classification Type | Link |
|---|---|---|---|---|---|
| Albadi et al. [19] | Arabic (DA) | 6.1 K tweets | Binary (HS, not HS) | DS1 | |
| Alshalan and Al-Khalifa [8] | Arabic (DA) Saudi | 9.3 K tweets | Binary (HS, not HS) | DS2 | |
| OSACT 4 [24] | Arabic (DA)/ (MSA) | 10 K tweets | Binary (HS, not HS) (OFF, not OFF) | DS3 | |
| OSACT 5 [33] | Arabic (DA)/ (MSA) | 12.6 K tweets | Binary (HS, not HS) (OFF, not OFF) Multi-HS (gender, race, religion, and others) | DS4 | |
| L-HSAB [21] | Arabic (DA) Levantine | 5.8 K tweets | Ternary (abusive, HS, and normal) | DS5 | |
| T-HSAB [34] | Facebook and YouTube | Arabic (DA) Tunisian | 6.02 K posts and comments | Ternary (abusive, HS, and normal) | DS6 |
| Ousidhoum et al. [9] | Arabic (DA) | 3.3 K tweets | Muti-Aspects (directness, hostility, target, group, and annotator) | DS7 |
| Attribute | Label | No. Instances |
|---|---|---|
| Directness | Direct | 1684 |
| Indirect | 754 | |
| Hostility | Abusive | 610 |
| Hateful | 755 | |
| Offensive | 1151 | |
| Disrespectful | 615 | |
| Fearful | 41 | |
| Normal | 1197 | |
| Target | Origin | 877 |
| Gender | 548 | |
| Religion | 145 | |
| Disability | 1 | |
| Other | 1782 | |
| Group | Individual | 915 |
| Other | 1470 | |
| Women | 722 | |
| Special needs | 2 | |
| African descent | 51 | |
| Annotator | Disgust | 778 |
| Shock | 917 | |
| Anger | 356 | |
| Sadness | 388 | |
| Fear | 35 | |
| Confusion | 115 | |
| Indifference | 1825 |
| Pretrained Arabic LMs | Size | # Word | # Token | Language Type |
|---|---|---|---|---|
| MARBERT [11] | 128 GB | 100 K | 15.6 B | DA |
| ArabicBERT [12] | 95 GB | 32 K | 8.2 B | DA |
| CAMeLBERT [13] | 16 7 B | 30 K | 17.3 B | DA/CA/MSA |
| QARiB [14] | 127 GB | 64 K | 14.0 B | DA |
| AraBERTv0.2 [15] | 77 GB | 60 K | 8.6 B | DA/MSA |
| Attribute | ML Baseline Models | Performance Metrics | |||
|---|---|---|---|---|---|
| Macro-Avg | Micro-F1 | ||||
| Prec. | Recall | F1 | Acc. | ||
| Directness | SVM | 0.58 | 0.57 | 0.56 | 0.59 |
| LR * | - | - | 0.53 | 0.56 | |
| NB | 0.53 | 0.53 | 0.51 | 0.51 | |
| Hostility | SVM | 0.34 | 0.25 | 0.25 | 0.43 |
| LR * | - | - | 0.25 | 0.48 | |
| NB | 0.26 | 0.36 | 0.30 | 0.39 | |
| Target | SVM | 0.43 | 0.40 | 0.41 | 0.59 |
| LR * | - | - | 0.47 | 0.53 | |
| NB | 0.38 | 0.39 | 0.38 | 0.46 | |
| Group | SVM | 0.70 | 0.72 | 0.70 | 0.68 |
| LR * | - | - | 0.40 | 0.62 | |
| NB | 0.50 | 0.43 | 0.45 | 0.52 | |
| Annotator | SVM | 0.12 | 0.15 | 0.13 | 0.39 |
| LR * | - | - | 0.14 | 0.46 | |
| NB | 0.20 | 0.22 | 0.21 | 0.31 | |
| Attribute | DL Models | Performance Metrics | |||
|---|---|---|---|---|---|
| Macro-Avg | Micro-F1 | ||||
| Prec. | Recall | F1 | Acc. | ||
| Directness | CNN | 0.62 | 0.56 | 0.53 | 0.61 |
| LSTM | 0.62 | 0.57 | 0.55 | 0.62 | |
| BiLSTM * | - | - | 0.84 | 0.72 | |
| Hostility | CNN | 0.22 | 0.22 | 0.21 | 0.31 |
| LSTM | 0.21 | 0.24 | 0.22 | 0.35 | |
| BiLSTM * | - | - | 0.31 | 0.47 | |
| Target | CNN | 0.38 | 0.34 | 0.34 | 0.55 |
| LSTM | 0.39 | 0.40 | 0.40 | 0.55 | |
| BiLSTM * | - | - | 0.63 | 0.50 | |
| Group | CNN | 0.69 | 0.49 | 0.52 | 0.60 |
| LSTM | 0.45 | 0.46 | 0.45 | 0.61 | |
| BiLSTM * | - | - | 0.04 | 0.58 | |
| Annotator | CNN | 0.14 | 0.16 | 0.13 | 0.42 |
| LSTM | 0.10 | 0.15 | 0.09 | 0.41 | |
| BiLSTM * | - | - | 0.12 | 0.48 | |
| Attribute | Pretrained Arabic LMs | Performance Metrics | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Before NLPaug | After NLPaug | ||||||||
| Macro-Avg | Micro F1 | Macro-Avg | Micro-F1 | ||||||
| Prec. | Recall | F1 | Acc. | Prec. | Recall | F1 | Acc. | ||
| Directness | MARBERT | 0.63 | 0.60 | 0.60 | 0.64 | 0.68 | 0.65 | 0.65 | 0.67 |
| CAMeLBERT | 0.64 | 0.63 | 0.63 | 0.65 | 0.64 | 0.62 | 0.62 | 0.64 | |
| QARiB | 0.70 | 0.61 | 0.58 | 0.66 | 0.65 | 0.64 | 0.64 | 0.65 | |
| ArabicBERT | 0.64 | 0.59 | 0.57 | 0.64 | 0.63 | 0.61 | 0.60 | 0.63 | |
| AraBERTv0.2 | 0.62 | 0.60 | 0.59 | 0.63 | 0.65 | 0.64 | 0.64 | 0.66 | |
| Hostility | MARBERT | 0.28 | 0.29 | 0.26 | 0.41 | 0.45 | 0.46 | 0.44 | 0.46 |
| CAMeLBERT | 0.30 | 0.31 | 0.26 | 0.43 | 0.44 | 0.44 | 0.43 | 0.45 | |
| QARiB | 0.30 | 0.29 | 0.25 | 0.41 | 0.42 | 0.42 | 0.40 | 0.43 | |
| ArabicBERT | 0.23 | 0.28 | 0.25 | 0.40 | 0.43 | 0.43 | 0.40 | 0.45 | |
| AraBERTv0.2 | 0.24 | 0.27 | 0.24 | 0.38 | 0.42 | 0.43 | 0.41 | 0.44 | |
| Target | MARBERT | 0.57 | 0.61 | 0.57 | 0.63 | 0.79 | 0.80 | 0.79 | 0.79 |
| CAMeLBERT | 0.58 | 0.61 | 0.58 | 0.59 | 0.81 | 0.82 | 0.82 | 0.81 | |
| QARiB | 0.58 | 0.65 | 0.60 | 0.63 | 0.78 | 0.79 | 0.78 | 0.78 | |
| ArabicBERT | 0.58 | 0.51 | 0.53 | 0.58 | 0.78 | 0.78 | 0.77 | 0.77 | |
| AraBERTv0.2 | 0.60 | 0.61 | 0.59 | 0.61 | 0.80 | 0.81 | 0.80 | 0.80 | |
| Group | MARBERT | 0.57 | 0.60 | 0.58 | 0.77 | 0.89 | 0.89 | 0.89 | 0.88 |
| CAMeLBERT | 0.76 | 0.78 | 0.76 | 0.75 | 0.84 | 0.84 | 0.84 | 0.84 | |
| QARiB | 0.75 | 0.78 | 0.75 | 0.77 | 0.81 | 0.81 | 0.80 | 0.81 | |
| ArabicBERT | 0.71 | 0.63 | 0.66 | 0.72 | 0.80 | 0.80 | 0.79 | 0.80 | |
| AraBERTv0.2 | 0.72 | 0.70 | 0.71 | 0.70 | 0.81 | 0.81 | 0.80 | 0.83 | |
| Annotator | MARBERT | 0.17 | 0.17 | 0.16 | 0.36 | 0.55 | 0.54 | 0.54 | 0.55 |
| CAMeLBERT | 0.19 | 0.17 | 0.16 | 0.35 | 0.56 | 0.57 | 0.56 | 0.57 | |
| QARiB | 0.14 | 0.13 | 0.13 | 0.26 | 0.15 | 0.15 | 0.28 | 0.55 | |
| ArabicBERT | 0.14 | 0.16 | 0.14 | 0.26 | 0.46 | 0.50 | 0.46 | 0.51 | |
| AraBERTv0.2 | 0.18 | 0.17 | 0.16 | 0.28 | 0.38 | 0.41 | 0.38 | 0.43 | |
| Models | Attribute | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Directness | Hostility | Target | Group | Annotator | ||||||
| Acc (%) | F1 (%) | Acc (%) | F1 (%) | Acc (%) | F1 (%) | Acc (%) | F1 (%) | Acc (%) | F1 (%) | |
| STSL (BiLSTM) * | 0.72 | 0.84 | 0.47 | 0.31 | 0.50 | 0.63 | 0.58 | 0.04 | 0.48 | 0.12 |
| MARBERT | 0.64 | 0.60 | 0.41 | 0.26 | 0.63 | 0.57 | 0.77 | 0.58 | 0.36 | 0.16 |
| MTL (MARBERT) | 0.73 | 0.72 | 0.47 | 0.34 | 0.67 | 0.51 | 0.88 | 0.80 | 0.45 | 0.23 |
| MTL (MARBERT + LSTM) | 0.76 | 0.76 | 0.46 | 0.34 | 0.75 | 0.71 | 0.88 | 0.87 | 0.39 | 0.22 |
| MTL (MARBERT + LSTM + CNN) | 0.70 | 0.70 | 0.44 | 0.29 | 0.68 | 0.51 | 0.87 | 0.66 | 0.47 | 019 |
| MTL (MARBERT + BiLSTM + CNN) | 0.75 | 0.75 | 0.45 | 0.32 | 0.60 | 0.59 | 0.89 | 0.91 | 0.41 | 0.23 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alrashidi, B.; Jamal, A.; Alkhathlan, A. Abusive Content Detection in Arabic Tweets Using Multi-Task Learning and Transformer-Based Models. Appl. Sci. 2023, 13, 5825. https://doi.org/10.3390/app13105825
Alrashidi B, Jamal A, Alkhathlan A. Abusive Content Detection in Arabic Tweets Using Multi-Task Learning and Transformer-Based Models. Applied Sciences. 2023; 13(10):5825. https://doi.org/10.3390/app13105825
Chicago/Turabian StyleAlrashidi, Bedour, Amani Jamal, and Ali Alkhathlan. 2023. "Abusive Content Detection in Arabic Tweets Using Multi-Task Learning and Transformer-Based Models" Applied Sciences 13, no. 10: 5825. https://doi.org/10.3390/app13105825