
OFDM Emitter Identification Method Based on Data Augmentation and Contrastive Learning


Abstract
:1. Introduction
- We constitute the first attempt to study OFDM emitter identification on deep learning methods.
- We propose a generalized framework, including contrastive learning, data augmentation, and ResNet, which can extract effective features from complex OFDM data under few-shots condition;
- We perform extensive experiments and analyze the results, demonstrating the effectiveness of our method. The results reflect that the preprocessing and training methods in our framework can be migrated to other machine learning models and our works can be effectively migrated to other signals.
2. Related Work
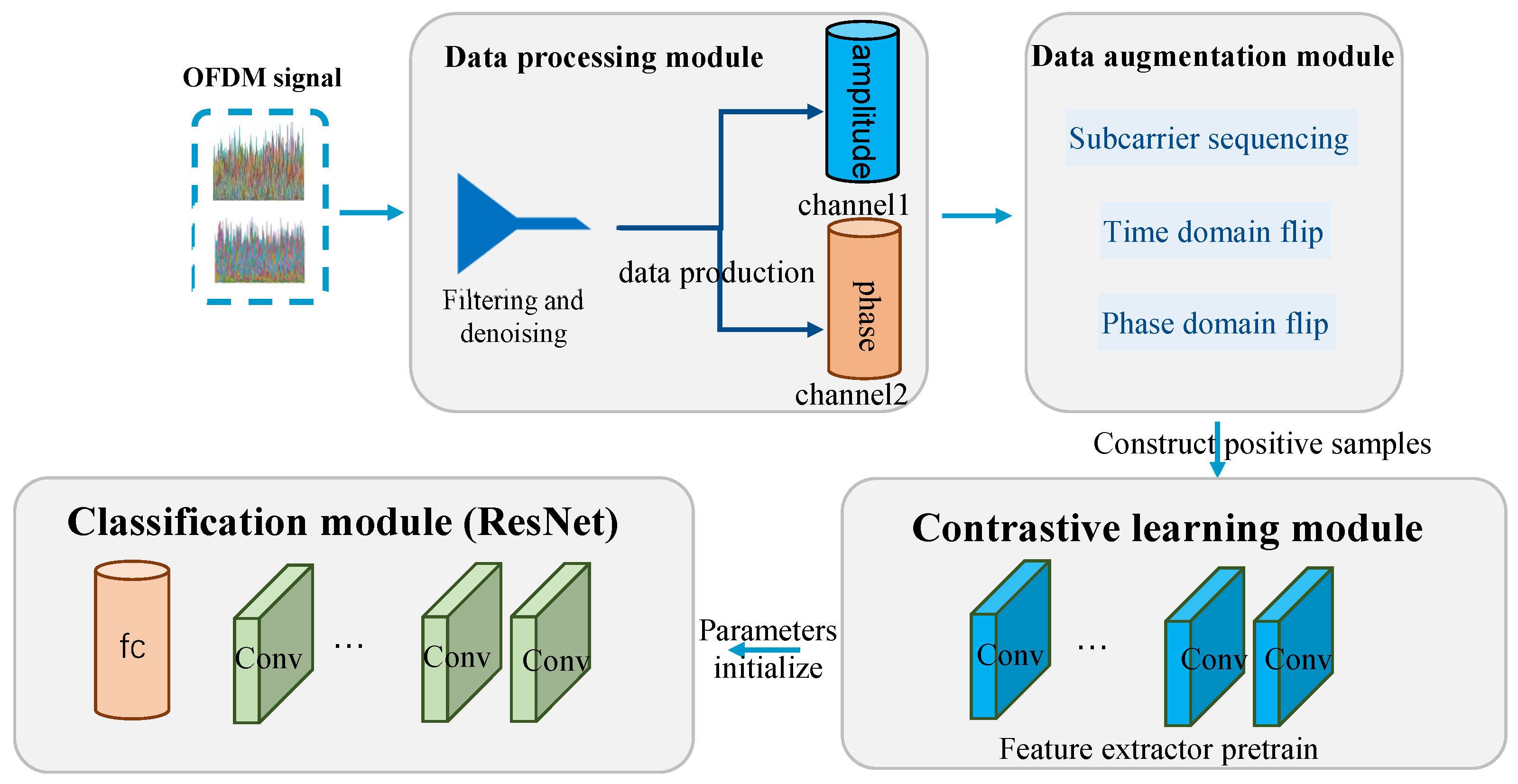
3. Proposed Method
3.1. Data Collection
3.2. Data Preprocessing
3.3. Data Augmentation
3.4. Contrastive Learning and Residual Network Framework
| Algorithm 1: Training Strategy |
 |
4. Experiments
4.1. Data Construction
4.2. Implementation Details
4.3. Experimental Results and Analysis
4.4. Model Robustness Experiment
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jia, Y. The Research on Communication Emitters Identification Technology. Ph.D. Thesis, UESTC, Chengdu, China, 2017. [Google Scholar]
- Yu, Q.; Cheng, W. Specific Emitter Identification Using Wavelet Transform Feature Extraction. J. Signal Process. 2018, 34, 10. [Google Scholar]
- Ding, G.; Huang, Z.; Wang, X. Radio frequency fingerprint extraction based on singular values and singular vectors of time-frequency spectrum. In Proceedings of the 2018 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Qingdao, China, 14–16 September 2018; pp. 1–6. [Google Scholar]
- Jie, R.D.T. Communication Emitter Identification Based on Bispectrum and Feature Selection. J. Inf. Eng. Univ. 2018, 19, 6. [Google Scholar]
- Tang, Z.; Lei, Y. The extraction of latent fine feature of communication transmitter. Chin. J. Radio Sci. 2016, 31, 8. [Google Scholar]
- Lin, J.J. RF fingerprint extraction method based on bispectrum. J. Terahertz Sci. Electron. Inf. Technol. 2021, 19, 5. [Google Scholar]
- Huang, G.; Yuan, Y.; Wang, X.; Huang, Z. Specific emitter identification based on nonlinear dynamical characteristics. Can. J. Electr. Comput. Eng. 2016, 39, 34–41. [Google Scholar] [CrossRef]
- Chen, K.; Yao, L.; Zhang, D.; Wang, X.; Chang, X.; Nie, F. A semisupervised recurrent convolutional attention model for human activity recognition. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 1747–1756. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.; Yao, L.; Chen, K.; Wang, S.; Chang, X.; Liu, Y. Making sense of spatio-temporal preserving representations for EEG-based human intention recognition. IEEE Trans. Cybern. 2019, 50, 3033–3044. [Google Scholar] [CrossRef]
- Luo, M.; Chang, X.; Nie, L.; Yang, Y.; Hauptmann, A.G.; Zheng, Q. An adaptive semisupervised feature analysis for video semantic recognition. IEEE Trans. Cybern. 2017, 48, 648–660. [Google Scholar] [CrossRef]
- Ding, L.; Wang, S.; Wang, F.; Zhang, W. Specific emitter identification via convolutional neural networks. IEEE Commun. Lett. 2018, 22, 2591–2594. [Google Scholar] [CrossRef]
- Shieh, C.S.; Lin, C.T. A vector neural network for emitter identification. IEEE Trans. Antennas Propag. 2002, 50, 1120–1127. [Google Scholar] [CrossRef] [Green Version]
- Matuszewski, J.; Sikorska-Łukasiewicz, K. Neural network application for emitter identification. In Proceedings of the 2017 18th International Radar Symposium (IRS), Prague, Czech Republic, 28–30 June 2017; pp. 1–8. [Google Scholar]
- Kong, M.; Zhang, J.; Liu, W.; Zhang, G. Radar emitter identification based on deep convolutional neural network. In Proceedings of the 2018 International Conference on Control, Automation and Information Sciences (ICCAIS), Hangzhou, China, 24–27 October 2018; pp. 309–314. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Jia, Q. Individual Identification of Communication Emmiter Based On Deep Learning. Ph.D. Thesis, BUPT, Beijing, China, 2019. [Google Scholar]
- Wu, Z.; Chen, H.; Lei, Y.; Li, X.; Xiong, H. Communication emitter individual identification based on stacked LSTM network. Syst. Eng. Electron. 2020, 42, 9. [Google Scholar]
- Chen, Y.; Lei, Y.; Li, X.; Ye, L.; Mei, F. Specific Emitter Identification of Communication Radiation Source Based on the Characteristics IQ Graph Features. J. Signal Process. 2021, 37, 120–125. [Google Scholar]
- Liu, G.; Zhang, X. A method for personal identification of communication radiation source based on deep belief network. Chin. J. Radio Sci. 2020, 35, 9. [Google Scholar]
- Zhang, M.; Diao, M.; Guo, L. Convolutional neural networks for automatic cognitive radio waveform recognition. IEEE Access 2017, 5, 11074–11082. [Google Scholar] [CrossRef]
- Chen, H.; Yang, J. Communicaiton transmitter individual identification based on deep residual adaptation network. Syst. Eng. Electron. 2021, 43, 7. [Google Scholar]
- West, N.E.; O’shea, T. Deep architectures for modulation recognition. In Proceedings of the 2017 IEEE International Symposium on Dynamic Spectrum Access Networks (DySPAN), Baltimore, MD, USA, 6–9 March 2017; pp. 1–6. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Chen, X.; Fan, H.; Girshick, R.; He, K. Improved baselines with momentum contrastive learning. arXiv 2020, arXiv:2003.04297. [Google Scholar]
- Chen, T.; Kornblith, S.; Swersky, K.; Norouzi, M.; Hinton, G.E. Big self-supervised models are strong semi-supervised learners. Adv. Neural Inf. Process. Syst. 2020, 33, 22243–22255. [Google Scholar]
- Kim, M.; Tack, J.; Hwang, S.J. Adversarial self-supervised contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 2983–2994. [Google Scholar]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Dim | Flops | Parameters |
|---|---|---|
| (1, 2, 108, 1200) | 9828 M | 11.17 M |
| (8, 2, 108, 1200) | 78,624 M | 11.17 M |
| (16, 2, 108, 1200) | 157,248 M | 11.17 M |
| (32, 2, 108, 1200) | 314,497 M | 11.17 M |
| Method | Max Accuracy | Average ± Deviation | |
|---|---|---|---|
| Input Backbone:ResNet18 | spectrum map | 32.26 | 32.21 ± 2.16 |
| amplitude | 70.69 | 67.07 ± 3.65 | |
| amplitude and phase | 72.41 | 68.28 ± 2.80 | |
| Model | 1dResNet18 | 74.14 | 70.86 ± 1.43 |
| Data augmentation in Contrastive learning | Subcarrier rerank | 82.76 | 78.45 ± 2.07 |
| Time domain flip | 81.03 | 79.82 ± 1.10 | |
| Phase domain flip | 82.76 | 80.03 ± 1.50 | |
| Random | 84.48 | 81.55 ± 1.73 | |
| Radio signals | ResNet18 | 98.89 | 98.67 ± 0.44 |
| Method | Training Set Size | Accuracy | Gain |
|---|---|---|---|
| ResNet | 50,000 | 96.86% | - |
| ResNet | 500 | 85.98% | - |
| Ours | 50,000 | 97.48% | +0.62% |
| Ours | 500 | 90.40% | +4.42% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, J.; Yuan, Y.; Zhang, Q.; Zhang, W.; Fan, Z.; Jin, F. OFDM Emitter Identification Method Based on Data Augmentation and Contrastive Learning. Appl. Sci. 2023, 13, 91. https://doi.org/10.3390/app13010091
Yu J, Yuan Y, Zhang Q, Zhang W, Fan Z, Jin F. OFDM Emitter Identification Method Based on Data Augmentation and Contrastive Learning. Applied Sciences. 2023; 13(1):91. https://doi.org/10.3390/app13010091
Chicago/Turabian StyleYu, Jiaqi, Ye Yuan, Qian Zhang, Wei Zhang, Ziyu Fan, and Fusheng Jin. 2023. "OFDM Emitter Identification Method Based on Data Augmentation and Contrastive Learning" Applied Sciences 13, no. 1: 91. https://doi.org/10.3390/app13010091