
DLMFCOS: Efficient Dual-Path Lightweight Module for Fully Convolutional Object Detection

Abstract
:1. Introduction
- The proposed DLM optimal trade-off computational cost and accuracy compared to standard convolution by minimizing spatial and channel information loss.
- The proposed feature pyramid structure achieves a balance between accuracy and computational cost by improving the feature loss compared to the conventional methods.
- The proposed method minimizes computational costs by improving the conventional detection head structure.
2. Related Works
2.1. Fully Convolutional One-Stage Detector
2.2. Feature Pyramid
3. Proposed Method
3.1. Proposed Feature Pyramid Structure
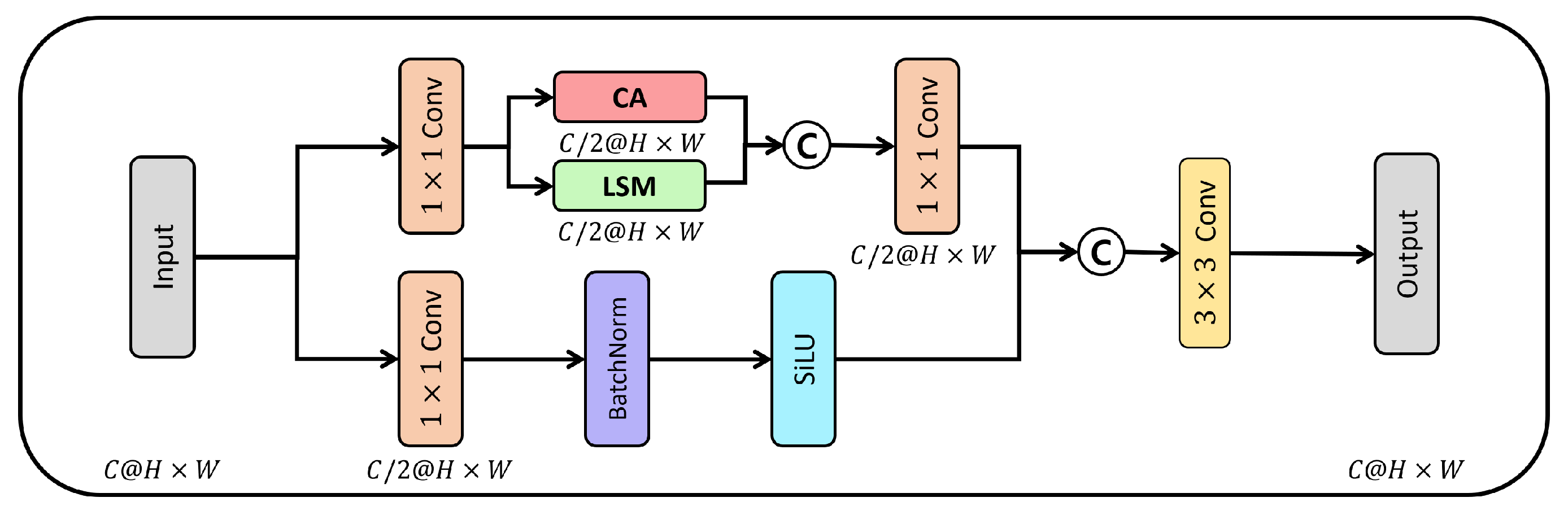
3.1.1. Dual Path Lightweight Module
3.1.2. Lightweight Spatial Module
3.1.3. Channel Attention
3.2. Lightweight Detection Head
3.3. Loss Function
4. Experiment Results and Discussion
4.1. Implementation Details
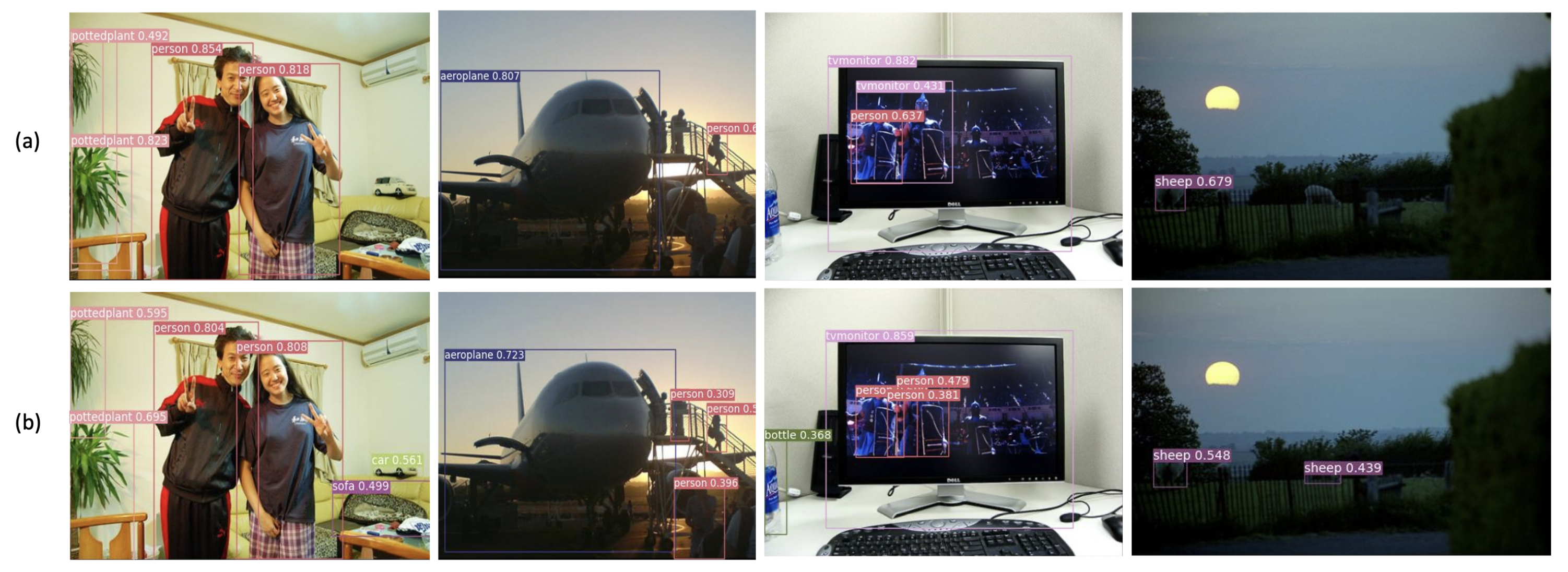
4.2. Comparison with Other Networks
4.2.1. PASCAL VOC07
4.2.2. MS COCO2017
4.3. Ablation Study
4.3.1. Ablation Study of the Proposed Module
4.3.2. Analysis of the Proposed FPN Structure
4.3.3. Analysis of Conventional Network
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shin, S.; Lee, S.; Han, H. EAR-Net: Efficient Atrous Residual Network for Semantic Segmentation of Street Scenes Based on Deep Learning. Appl. Sci. 2021, 11, 9119. [Google Scholar] [CrossRef]
- Park, C.; Lee, S.; Han, H. Efficient Shot Detector: Lightweight Network Based on Deep Learning Using Feature Pyramid. Appl. Sci. 2021, 11, 8692. [Google Scholar] [CrossRef]
- Hwang, B.; Lee, S.; Han, H. LNFCOS: Efficient Object Detection through Deep Learning Based on LNblock. Electronics 2022, 11, 2783. [Google Scholar] [CrossRef]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Wang, H.; Chen, Y.; Cai, Y.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. SFNet-N: An Improved SFNet Algorithm for Semantic Segmentation of Low-Light Autonomous Driving Road Scenes. IEEE Trans. Intell. Transp. Syst. 2022, 23, 21405–21417. [Google Scholar] [CrossRef]
- Yu, Y.; Samali, B.; Rashidi, M.; Mohammadi, M.; Nguyen, T.N.; Zhang, G. Vision-based concrete crack detection using a hybrid framework considering noise effect. J. Build. Eng. 2022, 61, 105246. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef] [Green Version]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar] [CrossRef] [Green Version]
- Pan, J.; Sun, H.; Song, Z.; Han, J. Dual-Resolution Dual-Path Convolutional Neural Networks for Fast Object Detection. Sensors 2019, 19, 3111. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shi, H.; Zhou, Q.; Ni, Y.; Wu, X.; Latecki, L.J. DPNET: Dual-Path Network for Efficient Object Detectioj with Lightweight Self-Attention. arXiv 2021, arXiv:2111.00500. [Google Scholar]
- Zhou, Q.; Shi, H.; Xiang, W.; Kang, B.; Wu, X.; Latecki, L.J. DPNet: Dual-Path Network for Real-time Object Detection with Lightweight Attention. arXiv 2022, arXiv:2209.13933. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Los Alamitos, CA, USA, 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar] [CrossRef] [Green Version]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef] [Green Version]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar] [CrossRef] [Green Version]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge; Springer: Berlin/Heidelberg, Germany, 2010; Volume 88, pp. 303–338. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Henderson, P.; Ferrari, V. End-to-end training of object class detectors for mean average precision. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 198–213. [Google Scholar] [CrossRef] [Green Version]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training Region-Based Object Detectors with Online Hard Example Mining. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 761–769. [Google Scholar] [CrossRef] [Green Version]
- Kong, T.; Yao, A.; Chen, Y.; Sun, F. Hypernet: Towards accurate region proposal generation and joint object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 845–853. [Google Scholar]
- Bell, S.; Zitnick, C.L.; Bala, K.; Girshick, R. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2874–2883. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar]
- Zhu, Y.; Zhao, C.; Wang, J.; Zhao, X.; Wu, Y.; Lu, H. CoupleNet: Coupling Global Structure with Local Parts for Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4146–4154. [Google Scholar] [CrossRef] [Green Version]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra r-cnn: Towards balanced learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 821–830. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature Selective Anchor-Free Module for Single-Shot Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 840–849. [Google Scholar] [CrossRef] [Green Version]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Li, L.; Shi, J. FoveaBox: Beyound Anchor-Based Object Detection. IEEE Trans. Image Process. 2020, 29, 7389–7398. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Descriptions | |
|---|---|---|
| Dataset | PASCALVOC | MS COCO |
| Epoch | 50 | 30 |
| Batch size | 32 | 8 |
| Learning rate | 0.02 | |
| momentum | 0.9 | |
| Weight decay | 0.0001 | |
| Optimizer | Stochastic gradient descent (SGD) | |
| Scheduler | MultistepLR | |
| Data augmentation | Color jitter | |
| Random rotation | ||
| Random resized crop | ||
| Item | Descriptions |
|---|---|
| CPU | AMD 3700X |
| RAM | 64GB |
| GPU | Geforce RTX3090 |
| OS | Linux Ubuntu 21.10 |
| Deep learning framework | PyTorch 1.11.0 |
| Detector | Backbone | Input Resolution | Parmas (M) | FLOPs (G) | mAP (%) | FPS |
|---|---|---|---|---|---|---|
| Two-stage | ||||||
| Fast R-CNN [7] | VGG-16 [31] | ∼ | - | - | 70.0 | 0.5 |
| Faster R-CNN [8] | VGG-16 | ∼ | 42.0 | - | 73.2 | 7 |
| OHEM [32] | VGG-16 | ∼ | - | - | 74.6 | 7 |
| HyperNet [33] | VGG-16 | ∼ | - | - | 76.3 | 0.88 |
| Fast R-CNN | ResNet-101 | ∼ | 60.0 | - | 76.4 | 2.4 |
| ION [34] | VGG-16 | ∼ | - | - | 76.5 | 1.25 |
| R-FCN [35] | ResNet-101 | ∼ | 50.9 | - | 80.5 | 9 |
| CoupleNet [36] | Resnet-101 | ∼ | - | - | 82.7 | 8.2 |
| One-stage | ||||||
| YOLO | GoogLeNet | - | - | 63.4 | 45 | |
| RON | VGG-16 | - | - | 75.4 | 15 | |
| SSD321 | ResNet-101 | - | 77.1 | 11.2 | ||
| SSD300 [10] | VGG-16 | 26.3 | - | 77.2 | 46 | |
| FCOS | ResNet-50 | 32.1 | 103.1 | 78.3 | 58 | |
| YOLOv2 | DarkNet-19 | 51.0 | - | 78.6 | 40 | |
| DSSD321 [37] | ResNet-101 | - | - | 78.6 | 9.5 | |
| SSD512 | VGG-16 | 29.4 | - | 79.8 | 19 | |
| SSD513 | ResNet-101 | - | - | 80.6 | 6.8 | |
| DSSD513 | ResNet-101 | - | - | 81.5 | 5.5 | |
| Proposed method | ResNet-50 | 29.7 | 68.2 | 80.0 | 62 | |
| Detector | Backbone | Input Resolution | AP | AP50 | AP75 | Params (M) | FPS |
|---|---|---|---|---|---|---|---|
| Two-stage | |||||||
| CoupleNet [36] | Resnet-101 | ∼ | 34.4 | 54.8 | 37.2 | - | 8.2 |
| MASK R-CNN [9] | ResNet-101 | ∼ | 38.2 | 60.4 | 41.7 | - | - |
| Faster R-CNN [38] | ResNet-50 | ∼ | 38.4 | - | - | 134.7 | 2.4 |
| Libra R-CNN [39] | ResNet-50 | ∼ | 38.5 | 59.3 | 42.0 | - | - |
| One-stage | |||||||
| YOLOv3 [40] | DarkNet-53 | 33.0 | 57.9 | 34.4 | 65.2 | 20 | |
| RetinaNet [24] | ResNet-50 | 36.3 | 55.3 | 38.6 | 37.7 | - | |
| FSAF [41] | ResNet-50 | 37.2 | 57.2 | 39.4 | - | - | |
| RetinaNet + Foveabox [42] | ResNet-50 | 36.4 | 56.2 | 38.7 | - | - | |
| FCOS [14] | ResNet-50 | 37.4 | 56.1 | 40.3 | 32.2 | 58 | |
| Proposed method | ResNet-50 | 38.9 | 58.0 | 41.6 | 29.7 | 62 | |
| Method | Parmas (M) | FLOPs (G) | mAP (%) |
|---|---|---|---|
| FCOS (Stdconv) | 32.2 | 88.40 | 78.5 |
| FCOS (MBconv [43]) | 28.7 | 84.90 | |
| FCOS (DLM) | 29.8 | 83.44 | 80.5 |
| Method | Parmas (M) | FLOPs (G) | mAP (%) |
|---|---|---|---|
| LSM (K = 3, D = 1) | 29.7 | 83.40 | 79.9 |
| LSM (K = 3, D = 2) | 29.7 | 83.40 | 79.9 |
| LSM (K = 5, D = 1) | 29.7 | 83.44 | 79.4 |
| LSM (K = 5, D = 2) | 29.7 | 83.44 | 80.0 |
| LSM (K = 7, D = 1) | 29.8 | 83.48 | 79.8 |
| LSM (K = 7, D = 2) | 29.8 | 83.48 | 79.8 |
| Method | Parmas (M) | FLOPs (G) | mAP (%) |
|---|---|---|---|
| FCOS + FPN [13] | 32.2 | 103.14 | 78.5 |
| FCOS + PAN [44] | 33.3 | 104.66 | 79.7 |
| FCOS + Proposed | 29.8 | 83.44 | 80.5 |
| Detector | Class | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| FCOS [14] | aero | bike | bird | boat | bottle | bus | car | cat | chair | cow |
| 80.8 | 86.8 | 81.5 | 72.2 | 63.4 | 84.8 | 88.1 | 91.1 | 58.8 | 80.3 | |
| table | dog | horse | mbike | person | plant | sheep | sofa | train | tv | |
| 66.0 | 88.6 | 86.1 | 84.8 | 84.2 | 51.0 | 80.8 | 72.1 | 88.9 | 79.3 | |
| DLMFCOS | aero | bike | bird | boat | bottle | bus | car | cat | chair | cow |
| 84.7 | 88.0 | 84.7 | 70.3 | 66.7 | 86.3 | 89.3 | 90.6 | 60.4 | 83.3 | |
| table | dog | horse | mbike | person | plant | sheep | sofa | train | tv | |
| 71.4 | 91.0 | 87.1 | 85.9 | 85.3 | 50.7 | 83.8 | 76.0 | 88.5 | 79.9 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hwang, B.; Lee, S.; Han, H. DLMFCOS: Efficient Dual-Path Lightweight Module for Fully Convolutional Object Detection. Appl. Sci. 2023, 13, 1841. https://doi.org/10.3390/app13031841
Hwang B, Lee S, Han H. DLMFCOS: Efficient Dual-Path Lightweight Module for Fully Convolutional Object Detection. Applied Sciences. 2023; 13(3):1841. https://doi.org/10.3390/app13031841
Chicago/Turabian StyleHwang, Beomyeon, Sanghun Lee, and Hyunho Han. 2023. "DLMFCOS: Efficient Dual-Path Lightweight Module for Fully Convolutional Object Detection" Applied Sciences 13, no. 3: 1841. https://doi.org/10.3390/app13031841