
Deep-Learning Based Algorithm for Detecting Targets in Infrared Images

Abstract
:1. Introduction
2. Related Work
2.1. Target Detection Framework Based on Deep Learning
2.2. Transfer Learning
2.3. Cross-Layer Connection Mechanism
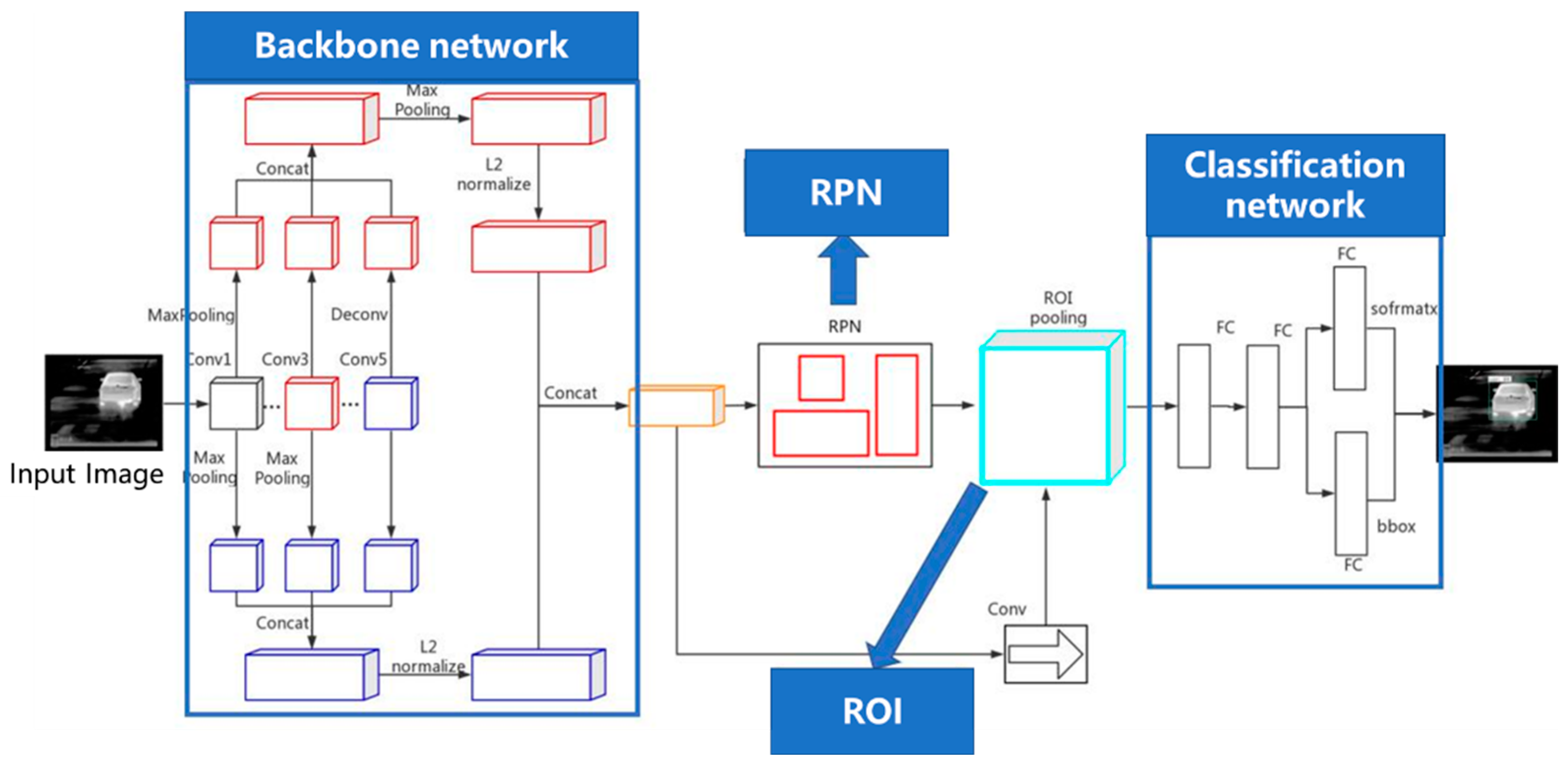
3. CMF Net
3.1. Network Structure of CMF Net
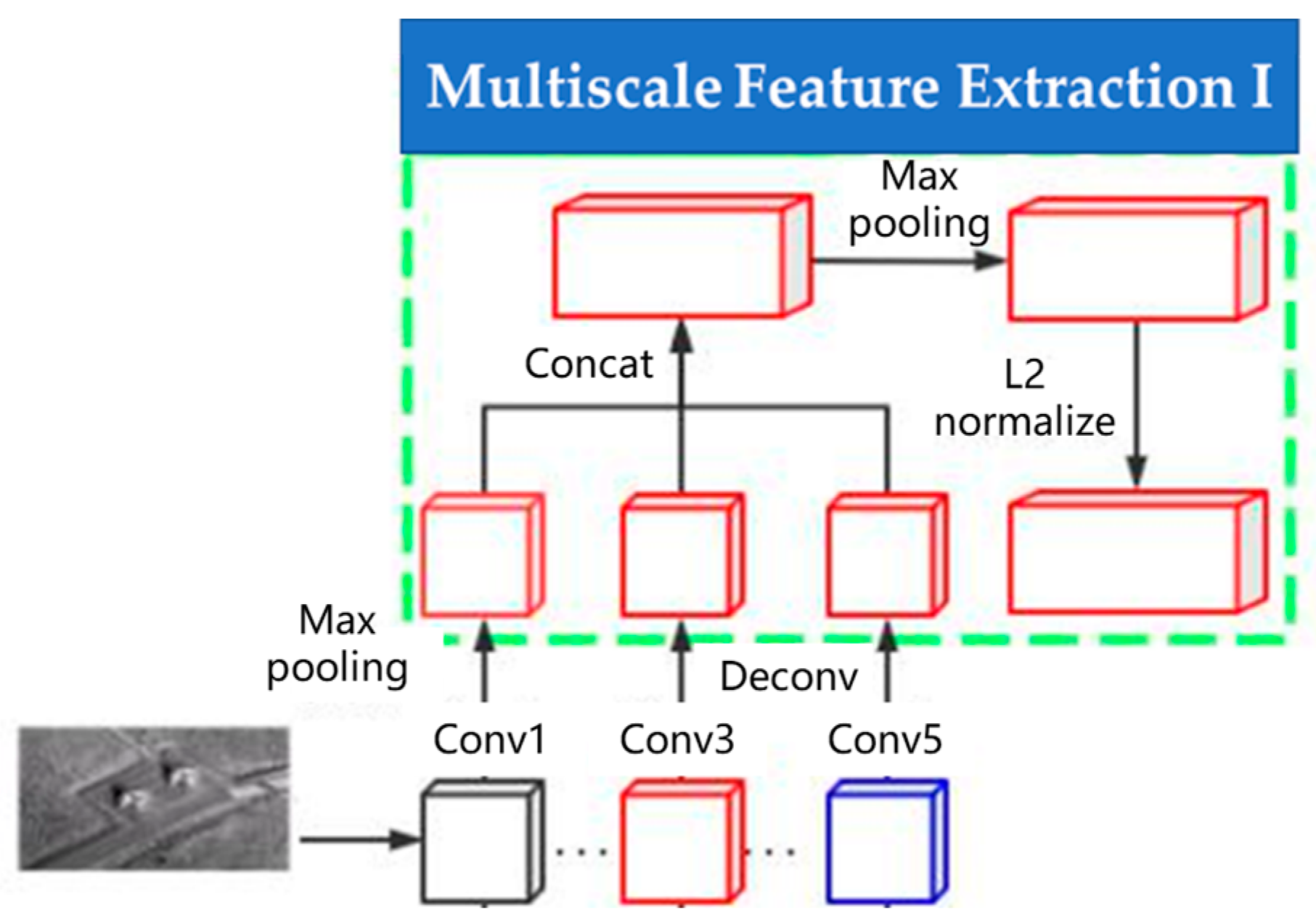
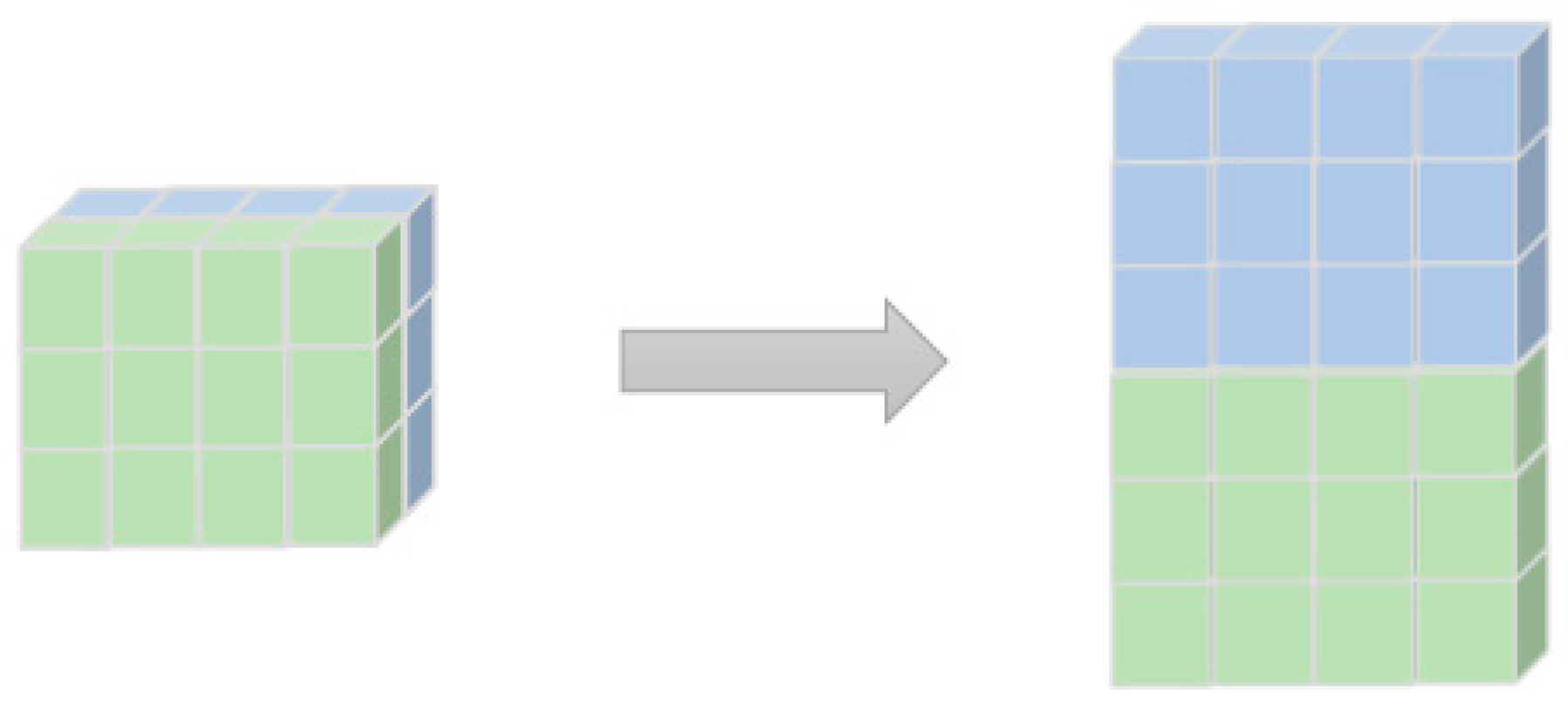
3.2. Multiscale Feature Extraction I
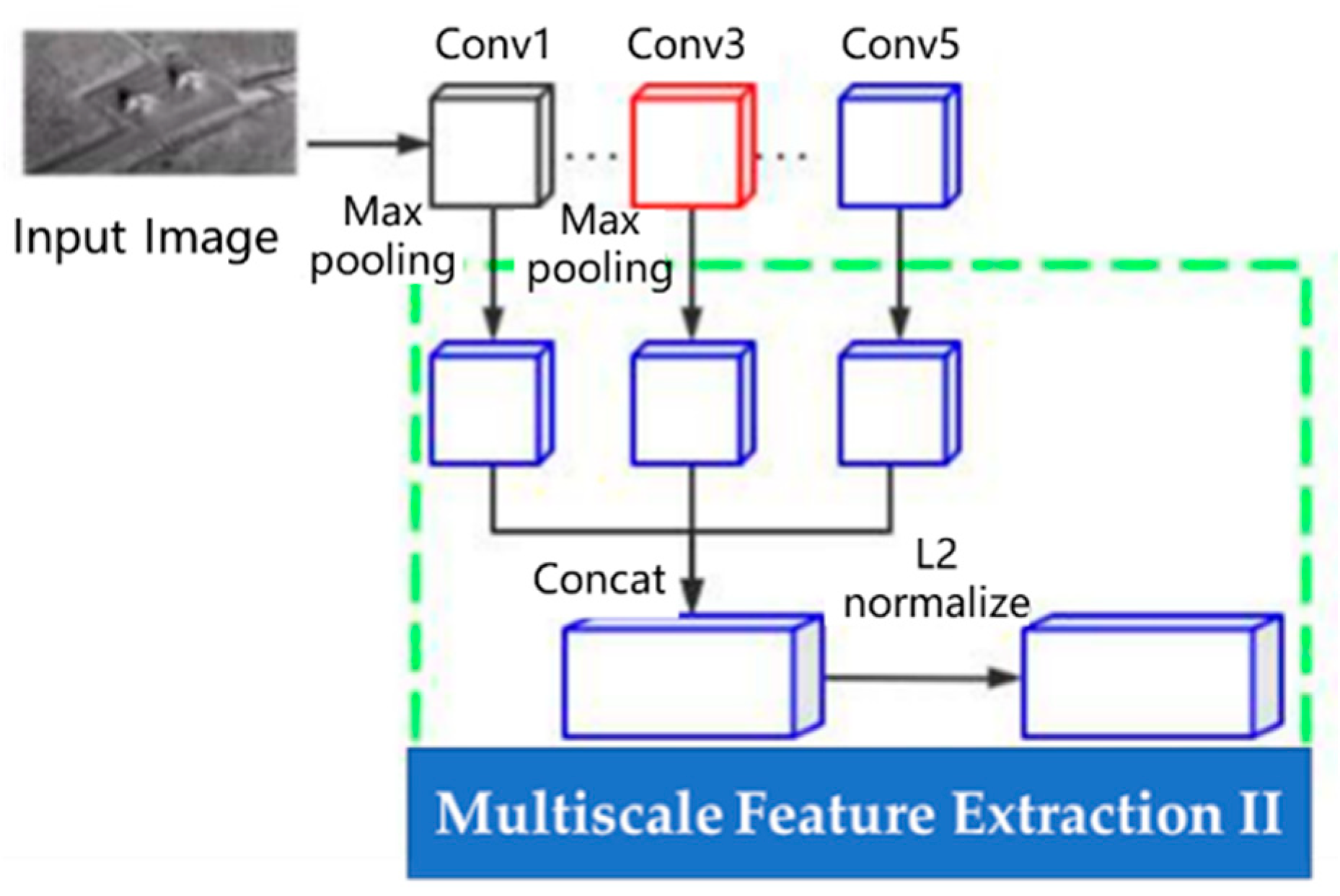
3.3. Multiscale Feature Extraction II
3.4. Feature Fusion Strategy
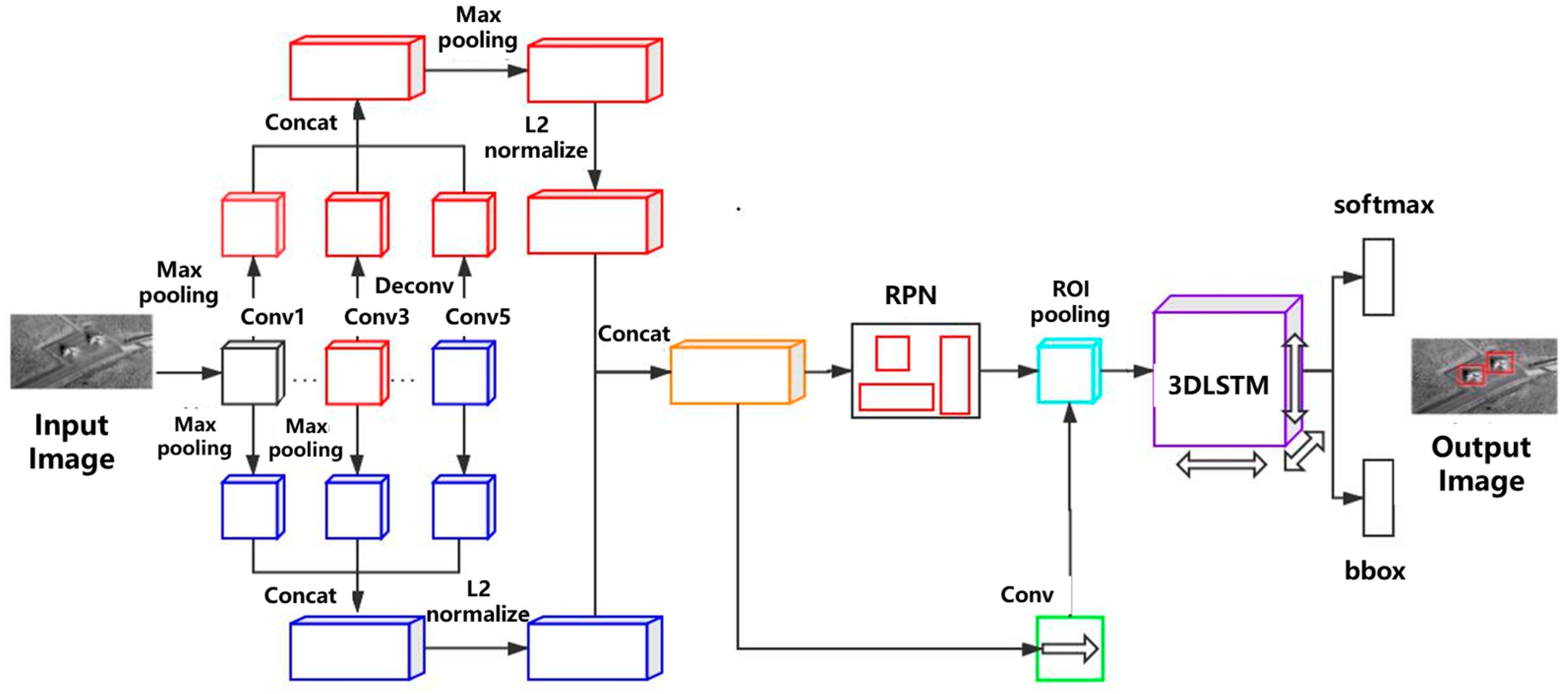
4. CMF-3DLSTM
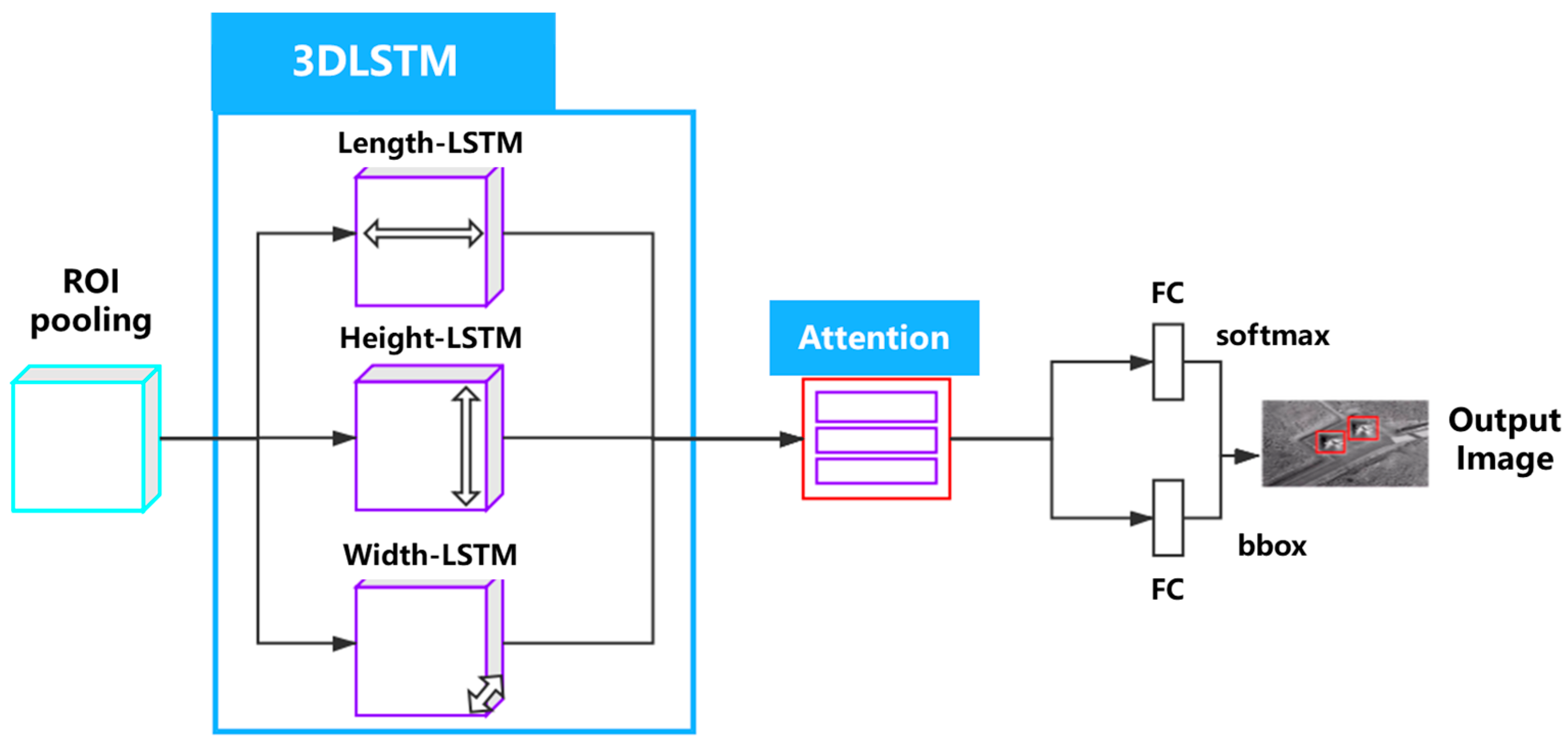
4.1. Network Structure of CMF-3DLSTM
4.2. Context Information Extraction Network
4.3. Attentional Mechanism
4.4. Model Training Strategy
| Algorithm 1: CMF-3DLSTM training process |
| Input: Infrared image dataset. Output: Target detection model CMF-3DLSTM. Step 1: Initialize the network parameters in Step2 and Step3 using the pre-training model on the VOC2007 dataset. Step 2: Use the first multiscale feature extraction mechanism to extract feature information. Step 3: Using the second multiscale feature extraction mechanism to extract feature information. Step 4: CMF Net is used to carry out feature fusion for the feature information extracted by Step 2 and Step 3. Step 5: Train the RPN network to generate the proposals using the characteristic information obtained from Step 4. Step 6: Implement ROI Pooling of Step 5 and adjust them to the same size. Step 7: The 3DLSTM network is used to extract the context information of ROI in Step 6. Step 8: The attention mechanism is used to assign weight to the output of the features by Step 7. Step 9: Classification layer and regression layer are used for target detection for the output of the features by Ste p8. Step10: The unified network of Step 5 and Step 9 joint training is taken as the final model. |
5. Experiment and Analysis of Experimental Results
5.1. Description of Dataset
5.2. Description of Evaluation
5.3. Experimental Analysis
- (1)
- Experiment I: The performance of the target detection model depends mainly on whether the feature map contains rich features or not. To investigate which network layers and network layer combinations can make the model the best performance, we conduct seven sets of tests based on the Faster R-CNN target detection model. The final target detection performance of the feature maps output by convolutional layer 1 (single 1), convolutional layer 3 (single 2), and convolutional layer 5 (single 3) are first tested separately. Then, the target detection is performed for the feature maps output by the convolutional layer combination 1+2+3 (Group 1) and 3+4+5 (Group 2), respectively. Finally, the target detection is performed for the feature maps output by the convolutional layer combination 1+3+5 with two different multiscale feature extraction mechanisms (Group 3 and Group 4). The experimental results are shown in Table 4.
- (2)
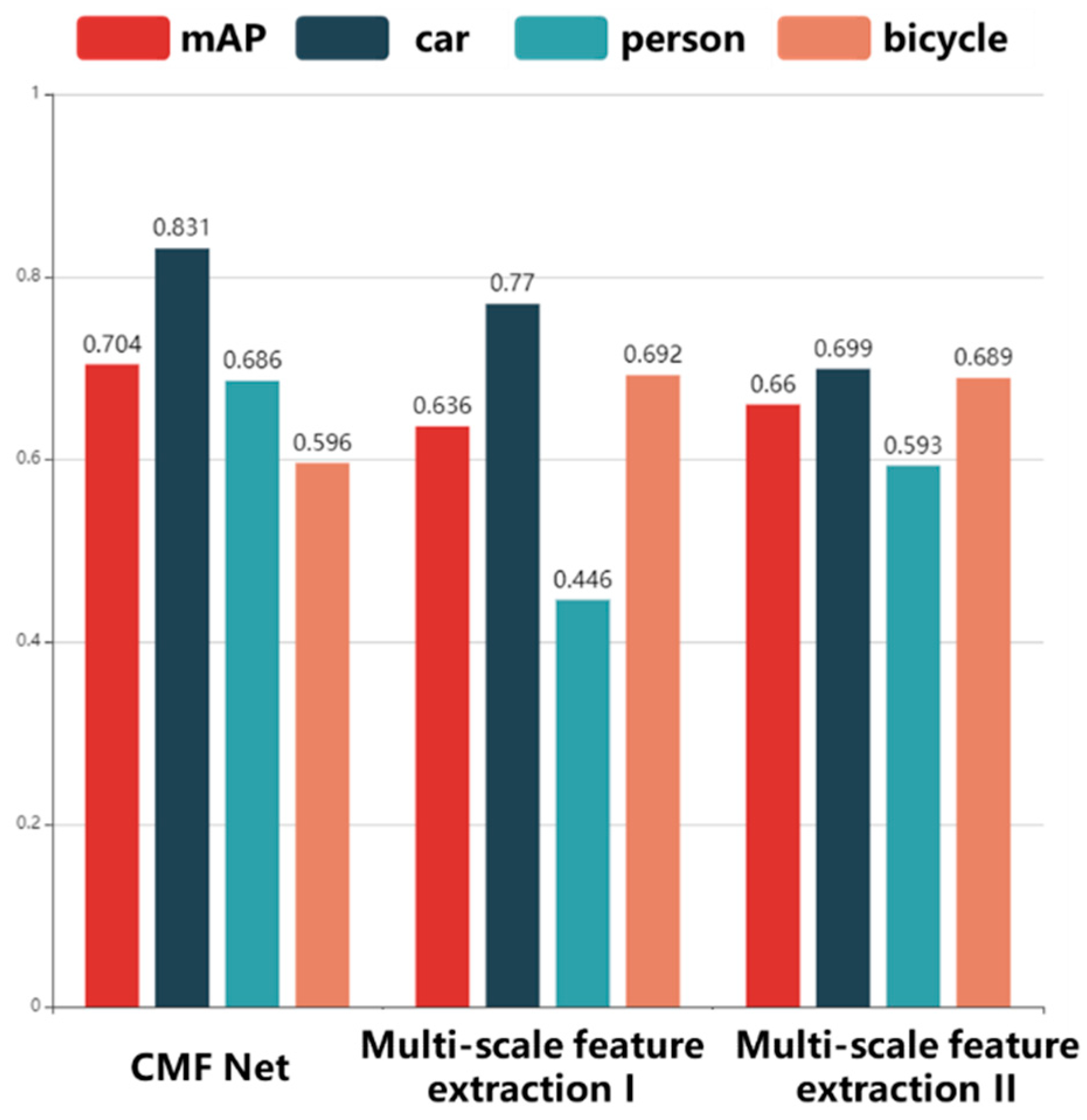
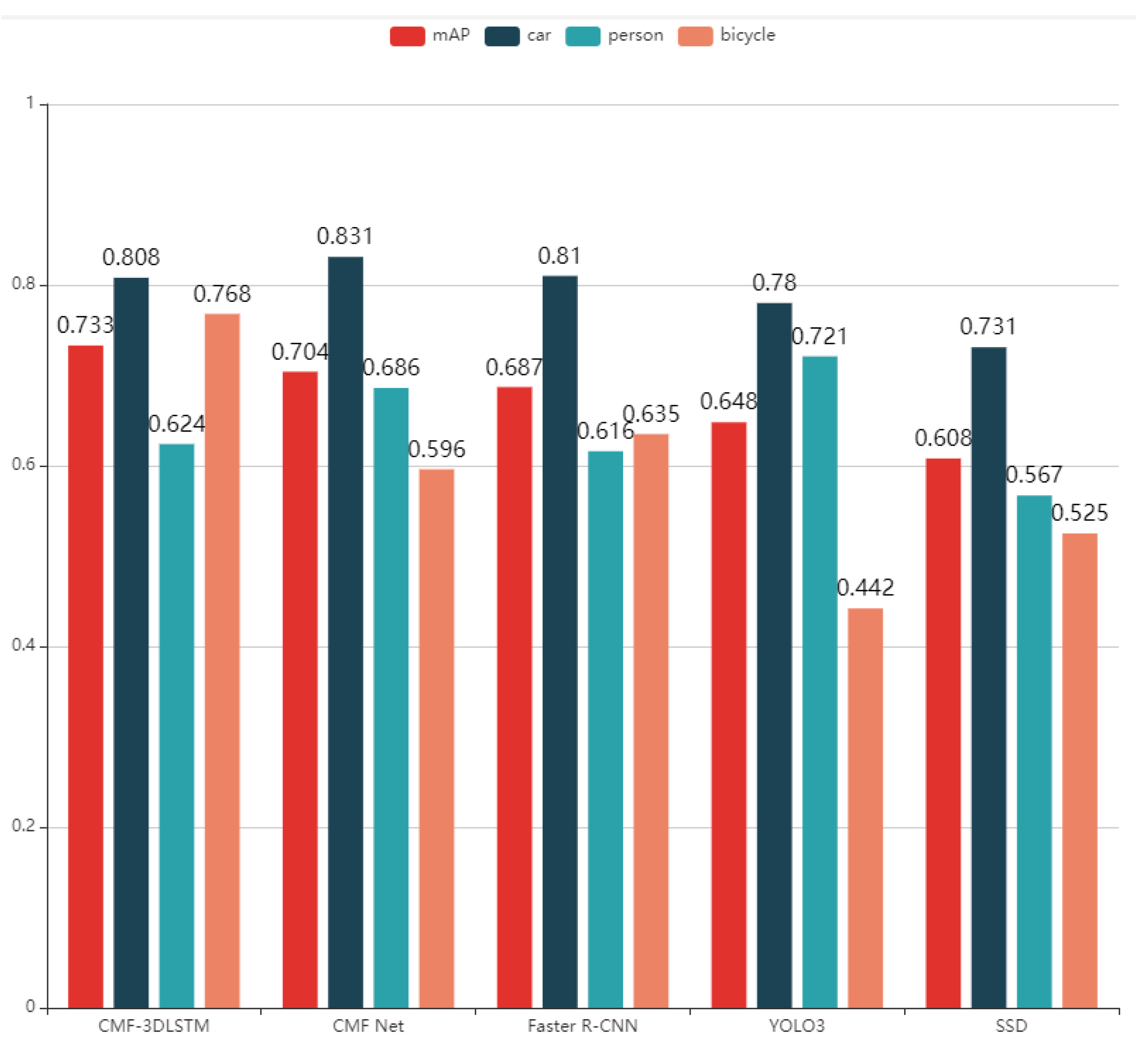
- Experiment II: To verify the performance of the two multiscale feature extraction mechanisms and CMF Net, we carried out three experiments, and the experimental results are shown in Figure 8. We found that our target detection model CMF Net has a great improvement.
- (3)
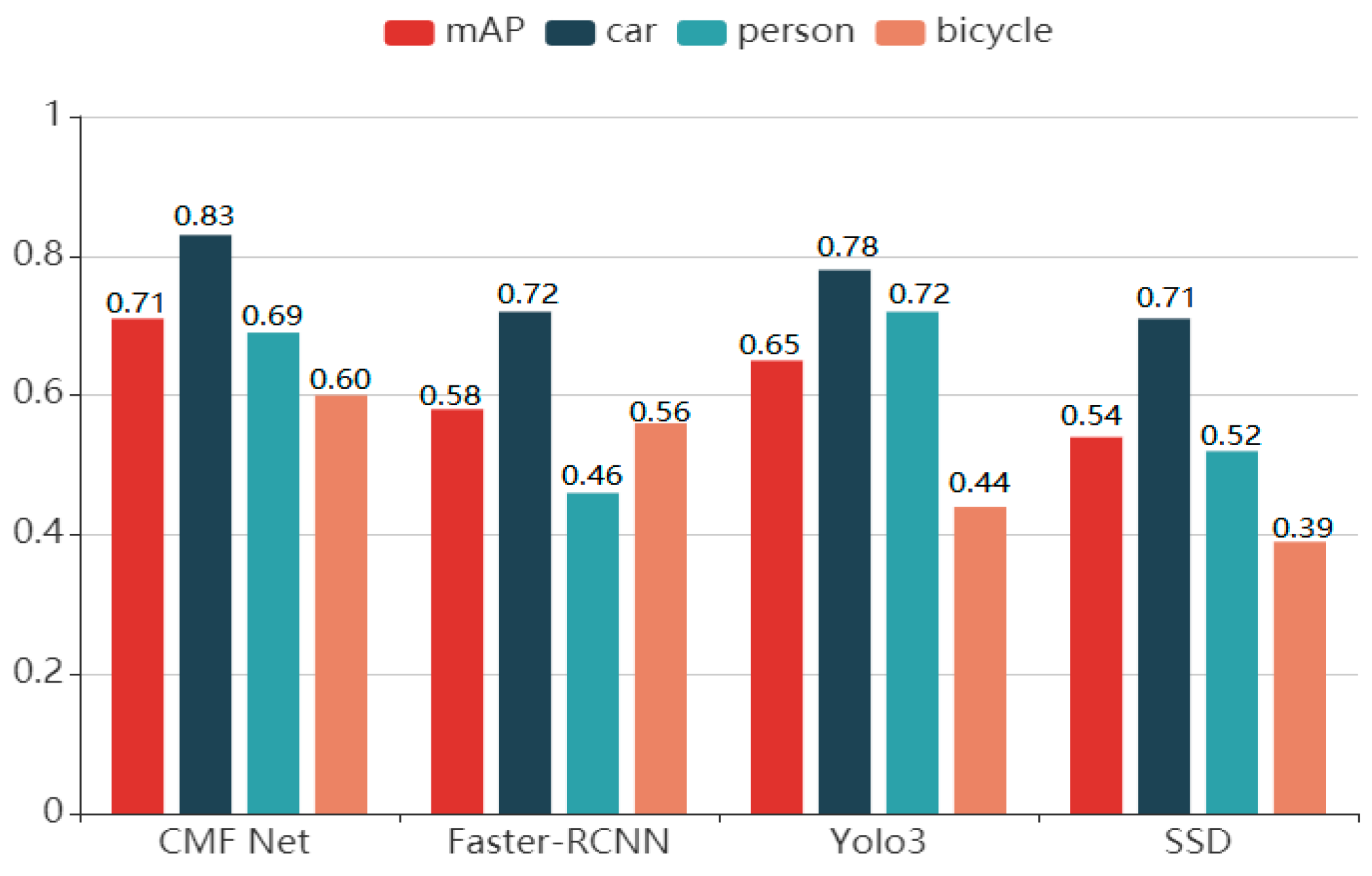
- Experiment III: To fully prove the correctness of our multiscale feature extraction strategy, we still adopted the idea of transfer learning to migrate the pre-training networks of Faster R-CNN, YOLO, and SSD, which are currently popular in the visible light domain, to FLIR infrared driving image dataset, continue training until the model converges.
- (4)
- Experiment IV: CMF Net, a target detection model based on multiscale feature fusion, has a problem: it is easy to cause misjudgment in the complex situation of multi-target detection. In particular, it is challenging to detect CMF Net effectively when multiple targets are close to or even overlapping each other. It is imperative to use the contextual information around the target effectively. This paper proposes an infrared image target detection model CMF-3DLSTM based on multiscale feature fusion and context analysis. CMF-3DLSTM is inherited from CMF Net. The difference between CMF-3DLSTM and CMF Net is that it replaces the complete connection layer of the classification regression network with a 3D long- and short-term memory network. Context information can be extracted based on multiscale feature fusion. CMF-3DLSTM improved target detection performance by about 2.9% on the infrared image dataset FLIR compared to CMF Net’s mAP.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Tan, P.; Mao, K.; Zhou, S. Image Target Detection Algorithm of Smart City Management Cases. IEEE Access 2020, 8, 163357–163364. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; pp. 886–893. [Google Scholar] [CrossRef] [Green Version]
- Papageorgiou, C.; Poggio, T. A Trainable System for Object Detection. Int. J. Comput. Vis. 2000, 38, 15–33. [Google Scholar] [CrossRef]
- Wu, B.; Nevatia, R. Detection of multiple, partially occluded humans in a single image by Bayesian combination of edgelet part detectors. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’2005), Beijing, China, 17–21 October 2005; Volume 1. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015. [Google Scholar]
- Bell, S.; Lawrence Zitnick, C.; Bala, K.; Girshick, R. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2874–2883. [Google Scholar]
- Enkelmann, W.; Struck, G.; Geisler, J. ROMA—A system for model-based analysis of road markings. In Proceedings of the Intelligent Vehicles ’95. Symposium, Detroit, MI, USA, 25–28 September 1995. [Google Scholar] [CrossRef]
- Otsuka, Y.; Muramatsu, S.; Takenaga, H.; Kobayashi, Y.; Monj, T. Multitype lane markers recognition using local edge direction. In Proceedings of the Intelligent Vehicle Symposium, Versaille, France, 17–21 June 2002. [Google Scholar] [CrossRef]
- Kluge, K.; Lakshmanan, S. A deformable-template approach to lane detection. In Proceedings of the Intelligent Vehicles ’95. Symposium, Detroit, MI, USA, 25–26 September 2002. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2012, 60, 84–90. [Google Scholar] [CrossRef]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Zhang, Y.; Sohn, K.; Villegas, R.; Pan, G.; Lee, H. Improving object detection with deep convolutional networks via Bayesian optimization and structured prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 249–258. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. Int. J. Comp. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Cheng, M.M.; Zhang, Z.; Lin, W.Y.; Torr, P. BING: Binarized normed gradients for objectness estimation at 300 fps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zitnick, C.L.; Dollár, P. Edge boxes: Locating object proposals from edges. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Kuo, W.; Hariharan, B.; Malik, J. Deepbox: Learning objectness with convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? arXiv 2014, arXiv:1411.1792. [Google Scholar]
- Sermanet, P.; Kavukcuoglu, K.; Chintala, S.; LeCun, Y. Pedestrian detection with unsupervised multi-stage feature learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Wang, C.; Shi, J.; Yang, X.; Zhou, Y.; Wei, S.; Li, L.; Zhang, X. Geospatial object detection via deconvolutional region proposal network. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2019, 12, 3014–3027. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | Value |
|---|---|
| The Anchor scale | 32, 64, 128 |
| MiniBatch Quantity | 256 |
| PRN foreground–background ratio | 1:1 |
| IOU threshold used by NMS for RPN training | 0.3 |
| IOU thresholds used by NMS for RPN prediction | 0.7 |
| Model | Backbone Network | RPN | ROI Pooling | Classification Network | Total |
|---|---|---|---|---|---|
| Faster R-CNN | 14,714,688 | 2,382,893 | 0 | 11,961,1408 | 136,708,989 |
| CMF Net | 17,077,824 | 7,691,309 | 0 | 127,279,632 | 152,048,765 |
| CMF-3DLSTM | 17,077,824 | 7,691,309 | 0 | 15,992,336 | 40,761,469 |
| Content | Synced annotated thermal imagery and non-annotated RGB imagery for reference. Camera centerlines approximately 2 inches apart and collimated to minimize parallax |
| Images | >10 K from short video segments and random image samples. |
| Image Capture Refresh Rate | Recorded at 30Hz. Dataset sequences sampled at 2 frames/s or 1 frame/s. Video annotations were performed at 30 frames/s recording. |
| Frame Annotation Label Totals | 10,228 total frames and 9214 frames with bounding boxes.
|
| Driving Conditions | Day (60%) and night (40%) driving on Santa Barbara, CA area streets and highways from November to May with clear to overcast weather. |
| Dataset File Format |
|
| Layers | Single 1 | Single 2 | Single 3 | Group 1 | Group 2 | Group 3 | Group 4 |
|---|---|---|---|---|---|---|---|
| mAP | 0.514 | 0.605 | 0.583 | 0.567 | 0.618 | 0.636 | 0.661 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, L.; Liu, S.; Zhao, Y. Deep-Learning Based Algorithm for Detecting Targets in Infrared Images. Appl. Sci. 2022, 12, 3322. https://doi.org/10.3390/app12073322
Yang L, Liu S, Zhao Y. Deep-Learning Based Algorithm for Detecting Targets in Infrared Images. Applied Sciences. 2022; 12(7):3322. https://doi.org/10.3390/app12073322
Chicago/Turabian StyleYang, Lifeng, Shengzong Liu, and Yiqi Zhao. 2022. "Deep-Learning Based Algorithm for Detecting Targets in Infrared Images" Applied Sciences 12, no. 7: 3322. https://doi.org/10.3390/app12073322