
Monocular Real Time Full Resolution Depth Estimation Arrangement with a Tunable Lens

 and
and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Setup
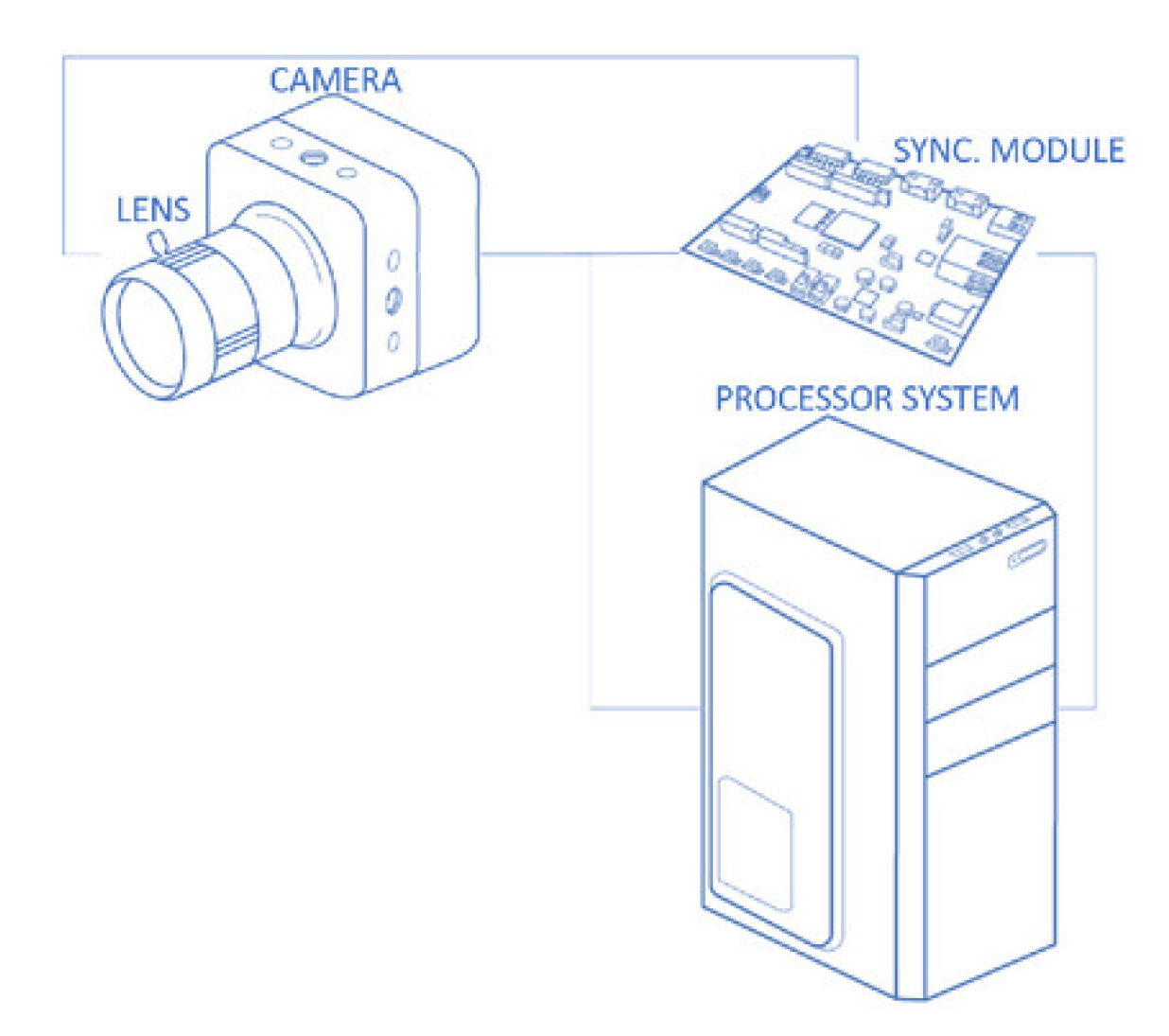
2.1.1. General Overview
2.1.2. Camera
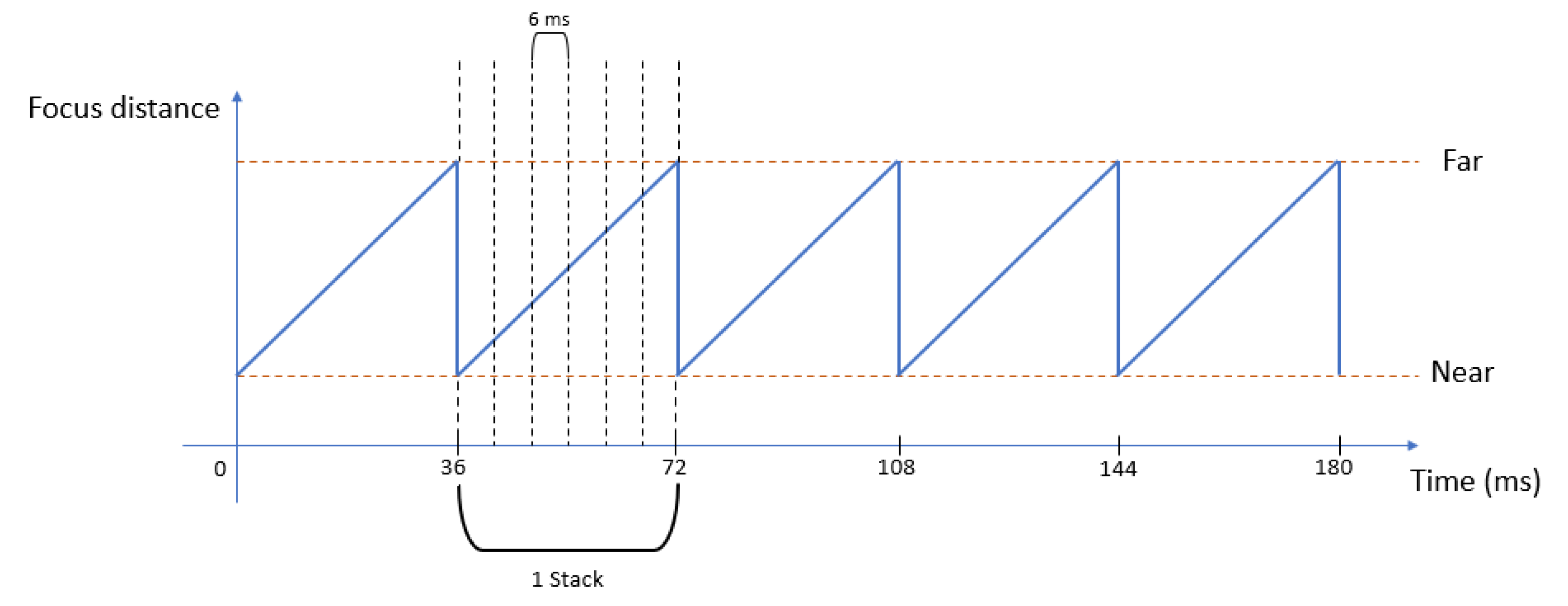
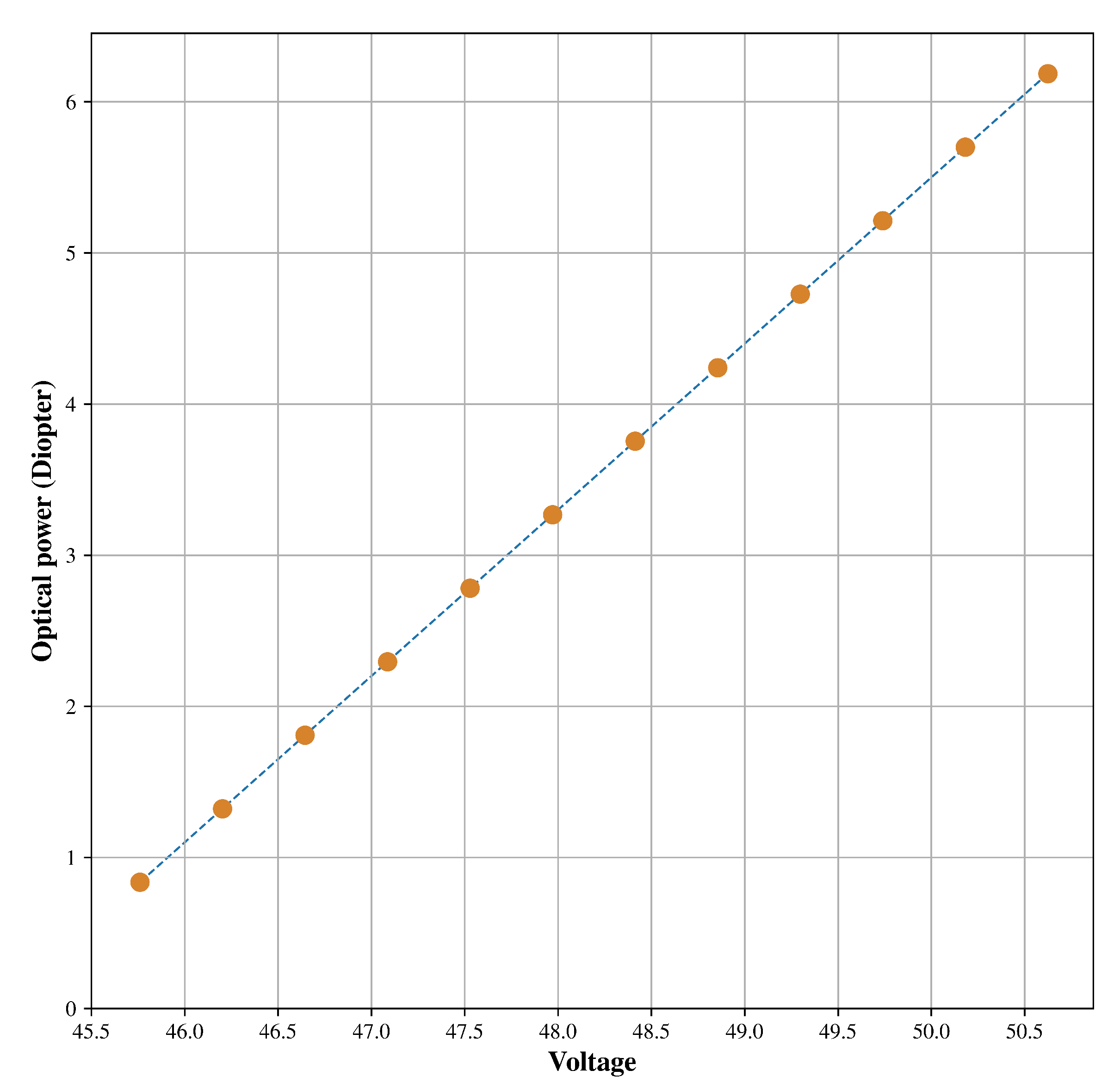
2.1.3. Variable Focus Lens
2.2. Synchronization Module
Processor System
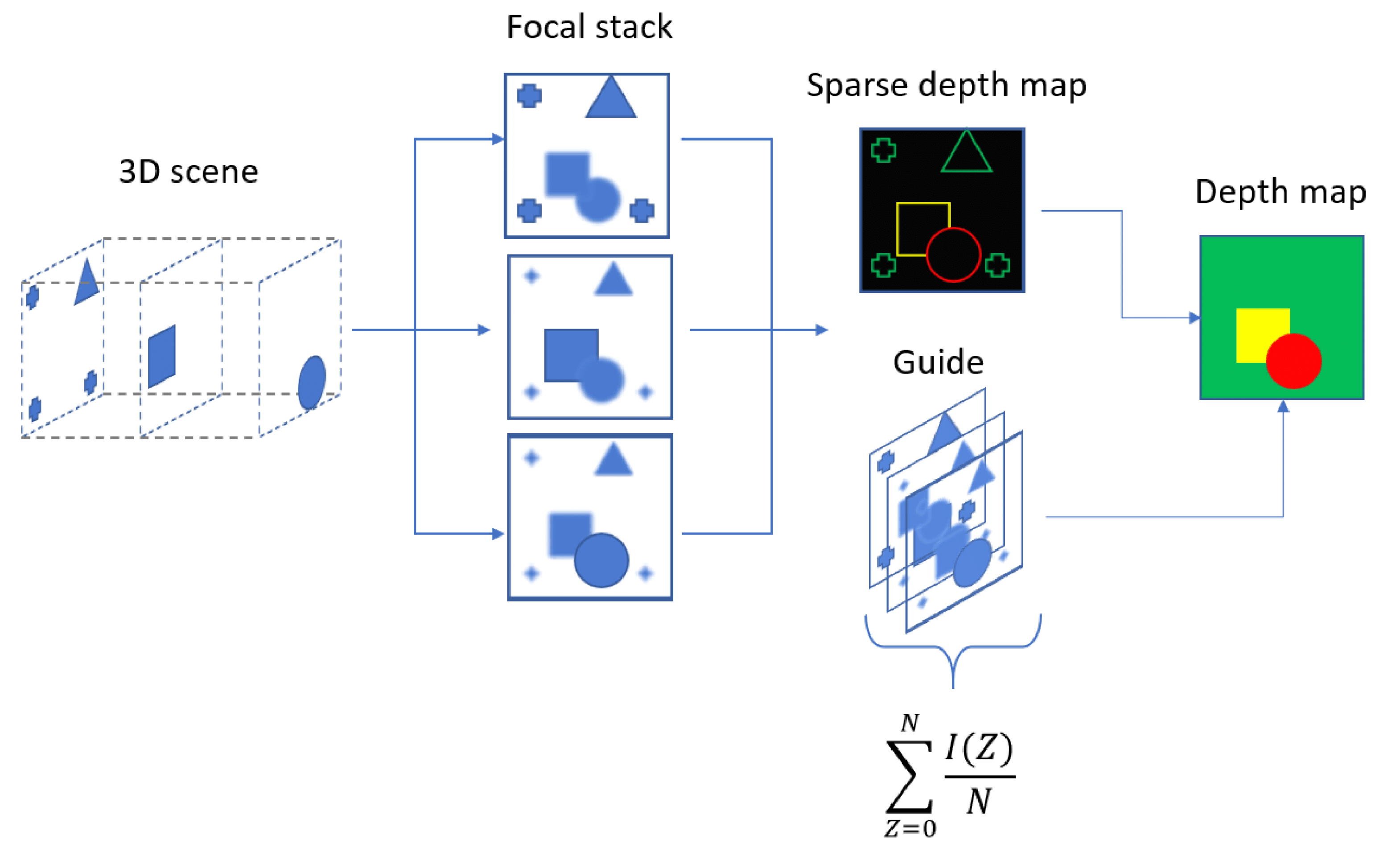
2.3. Depth Estimation Algorithm
- All the data points in the existing sparse depth map have to be present in the final solution.
- There are no missing depth values.
- The resulting depth map should be edge preserving and should be smooth within the map.
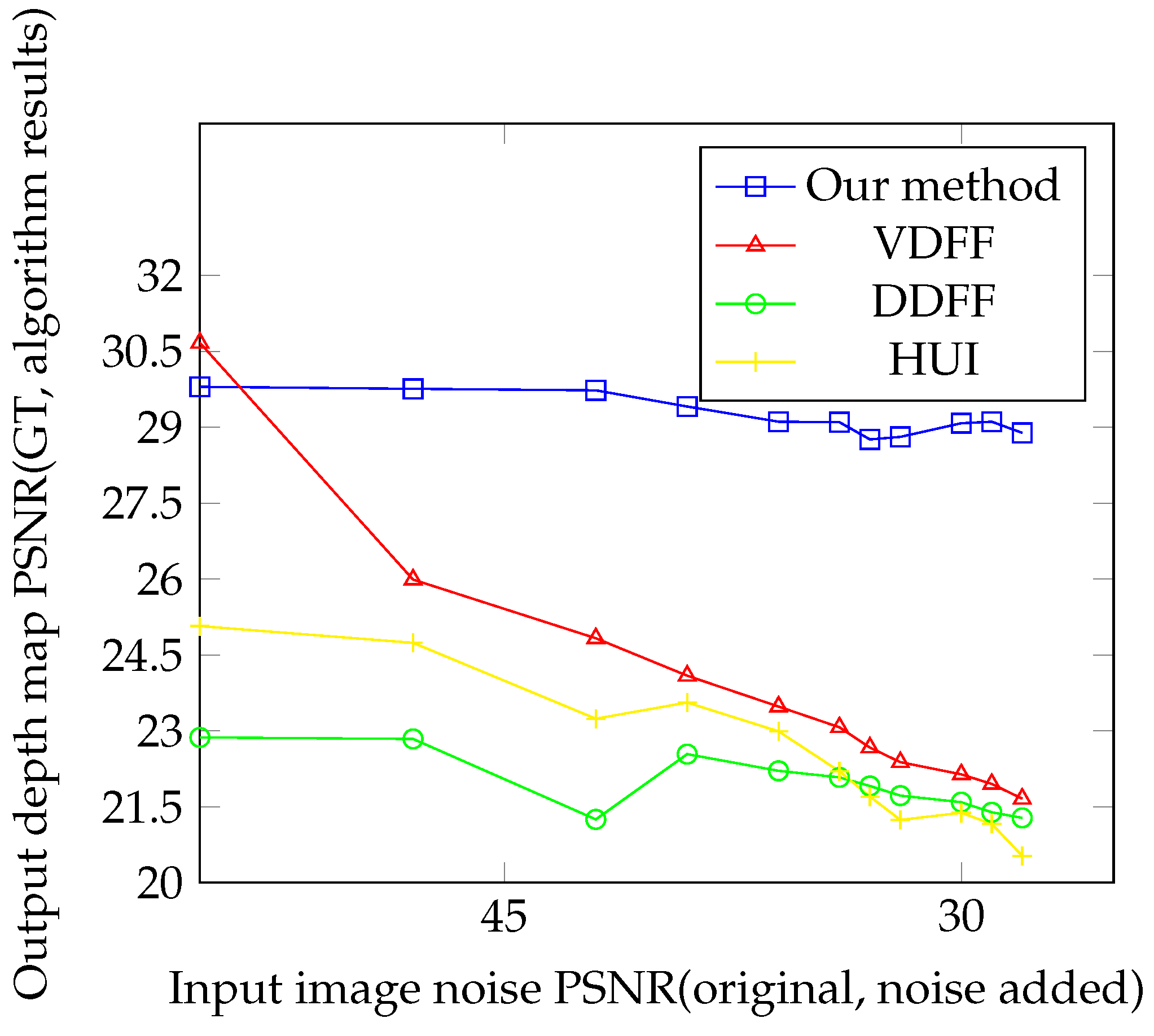
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DFF | Depth from focus |
| SFM | Structure from motion |
| VDFF | Variational depth from focus |
| DDFF | Deep depth from focus |
| RMDDFF | Relative multiscale Deep depth from focus |
| PSNR | Peak signal noise ratio |
References
- Percoco, G.; Salmerón, A.J.S. Photogrammetric measurement of 3D freeform millimetre-sized objects with micro features: An experimental validation of the close-range camera calibration model for narrow angles of view. Meas. Sci. Technol. 2015, 26, 095203. [Google Scholar] [CrossRef] [Green Version]
- Yakar, M. Using close range photogrammetry to measure the position of inaccessible geological features. Exp. Tech. 2009, 35, 54–59. [Google Scholar] [CrossRef]
- Remondino, F.; Guarnieri, A.; Vettore, A. 3D modeling of Close-Range Objects: Photogrammetry or Laser Scanning. Proc. SPIE 2004, 5665, 216–225. [Google Scholar] [CrossRef] [Green Version]
- Samaan, M.; Héno, R.; Deseilligny, M. Close-range photogrammetric tools for small 3D archeological objects. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, XL-5/W2, 549–553. [Google Scholar] [CrossRef] [Green Version]
- Lastilla, L.; Ravanelli, R.; Ferrara, S. 3D high-quality modeling of small and complex archaeological inscribed objects: Relevant issues and proposed methodology. In Proceedings of the GEORES 2019—2nd International Conference of Geomatics and Restoratio, Milan, Italy, 8–10 May 20; Volume XLII–2/W11. [CrossRef] [Green Version]
- Huang, J.C.; Liu, C.S.; Chiang, P.J.; Hsu, W.Y.; Liu, J.L.; Huang, B.H.; Lin, S.R. Design and experimental validation of novel 3D optical scanner with zoom lens unit. Meas. Sci. Technol. 2017, 28, 105904. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z. Microsoft Kinect Sensor and Its Effect. IEEE Multimed. 2012, 19, 4–10. [Google Scholar] [CrossRef] [Green Version]
- Christian, J.A.; Cryan, S.P. A survey of LIDAR technology and its use in spacecraft relative navigation. In Proceedings of the AIAA Guidance, Navigation, and Control (GNC) Conference, Boston, MA, USA, 19–22 August 2013. [Google Scholar]
- Keselman, L.; Woodfill, J.I.; Grunnet-Jepsen, A.; Bhowmik, A. Intel RealSense stereoscopic depth cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Atkinson, G.A.; Hansen, M.F.; Smith, M.L.; Smith, L.N. A efficient and practical 3D face scanner using near infrared and visible photometric stereo. Procedia Comput. Sci. 2010, 2, 11–19. [Google Scholar] [CrossRef] [Green Version]
- Aubreton, O.; Bajard, A.; Verney, B.; Truchetet, F. Infrared system for 3D scanning of metallic surfaces. Mach. Vis. Appl. 2013, 24, 1513–1524. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Lai, Z.; Huang, G.; Wang, B.H.; van der Maaten, L.; Campbell, M.; Weinberger, K.Q. Anytime Stereo Image Depth Estimation on Mobile Devices. arXiv 2018, arXiv:1810.11408. [Google Scholar]
- Hirschmuller, H. Stereo Processing by Semiglobal Matching and Mutual Information. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 328–341. [Google Scholar] [CrossRef] [PubMed]
- Konolige, K. Small Vision Systems: Hardware and Implementation; Robotics Research; Shirai, Y., Hirose, S., Eds.; Springer: London, UK, 1998; pp. 203–212. [Google Scholar]
- Nyimbili, P.; Demirel, H.; Seker, D.; Erden, T. Structure from Motion (SfM)—Approaches and applications. In Proceedings of the International Scientific Conference on Applied Sciences, Antalya, Turkey, 27–30 September 2016; pp. 27–30. [Google Scholar]
- Schönberger, J.L.; Frahm, J. Structure-from-Motion revisited. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar]
- Özyesil, O.; Voroninski, V.; Basri, R.; Singer, A. A Survey on Structure from Motion. Acta Numer. 2017, 26, 305–364. [Google Scholar] [CrossRef]
- Suwajanakorn, S.; Hernandez, C.; Seitz, S.M. Depth from focus with your mobile phone. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3497–3506. [Google Scholar]
- Hazirbas, C.; Soyer, S.G.; Staab, M.C.; Leal-Taixé, L.; Cremers, D. Deep depth from focus. In Proceedings of the Asian Conference on Computer Vision, Perth, WA, Australia, 2–6 December 2018. [Google Scholar]
- Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; Tao, D. Deep Ordinal Regression Network for Monocular Depth Estimation. arXiv 2018, arXiv:1806.02446. [Google Scholar]
- Ranftl, R.; Lasinger, K.; Hafner, D.; Schindler, K.; Koltun, V. Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer. arXiv 2020, arXiv:1907.01341. [Google Scholar] [CrossRef] [PubMed]
- Martel, J.N.P.; Müller, L.K.; Carey, S.J.; Müller, J.; Sandamirskaya, Y.; Dudek, P. Real-Time Depth From Focus on a Programmable Focal Plane Processor. IEEE Trans. Circuits Syst. Regul. Pap. 2018, 65, 925–934. [Google Scholar] [CrossRef] [Green Version]
- Flare 2MP. Available online: http://www.ioindustries.com/flare2mp.html (accessed on 5 October 2020).
- Matrox Radient eV-CL. Available online: https://www.matrox.com/en/imaging/products/components/frame-grabbers/radient-ev-cl (accessed on 5 October 2020).
- C-C-39N0-250. Available online: https://www.corning.com/cala/es/innovation/corning-emerging-innovations/corning-varioptic-lenses/auto-focus-lens-modules-c-c-series/varioptic-C-C-39N0-250.html (accessed on 5 October 2020).
- Carbone, M.; Domeneghetti, D.; Cutolo, F.; D’Amato, R.; Cigna, E.; Parchi, P.D.; Gesi, M.; Morelli, L.; Ferrari, M.; Ferrari, V. Can Liquid Lenses Increase Depth of Field in Head Mounted Video See-Through Devices? J. Imaging 2021, 7, 138. [Google Scholar] [CrossRef] [PubMed]
- Ma, L.L.; Wu, S.B.; Hu, W.; Liu, C.; Chen, P.; Qian, H.; Wang, Y.; Chi, L.; Lu, Y.Q. Self-Assembled Asymmetric Microlenses for Four-Dimensional Visual Imaging. ACS Nano 2019, 13, 13709–13715. [Google Scholar] [CrossRef] [PubMed]
- Arty Z7. Available online: https://reference.digilentinc.com/reference/programmable-logic/arty-z7/start (accessed on 5 October 2020).
- Pertuz, S.; Puig, D.; García, M. Analysis of focus measure operators in shape-from-focus. Pattern Recognit. 2012, 46, 1415–1432. [Google Scholar] [CrossRef]
- Barron, J.T.; Poole, B. The fast bilateral solver. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Barron, J.T.; Adams, A.; Shih, Y.; Hernández, C. Fast bilateral-space stereo for synthetic defocus. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Chen, J.; Paris, S.; Durand, F. Real-time edge-aware image processing with the bilateral grid. ACM Trans. Graph. 2007, 26, 103. [Google Scholar] [CrossRef]
- Cignoni, P.; Callieri, M.; Corsini, M.; Dellepiane, M.; Ganovelli, F.; Ranzuglia, G. MeshLab: An open-source mesh processing tool. In Proceeding of the Italian Chapter Conference 2020—Smart Tools and Apps in Computer Graphics, STAG 2020, Virtual Event, Italy, 12–13 November 2020; Scarano, V., Chiara, R.D., Erra, U., Eds.; The Eurographics Association: Geneva, Switzerland, 2020. [Google Scholar] [CrossRef]
- Hui, L.; Fan, P.; Yuntao, W.; Yanduo, Z.; Xiaolin, X. Depth map sensor based on optical doped lens with multi-walled carbon nanotubes of liquid crystal. Appl. Opt. 2016, 55, 140–147. [Google Scholar] [CrossRef]
- Salokhiddinov, S.; Lee, S. Deep Spatialfocal Network for Depth from Focus. J. Imaging Sci. Technol. 2021, 65, 40501-1–40501-14. [Google Scholar] [CrossRef]
- Moeller, M.; Benning, M.; Schönlieb, C.; Cremers, D. Variational Depth From Focus Reconstruction. IEEE Trans. Image Process. 2015, 24, 5369–5378. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ceruso, S.; Bonaque-González, S.; Oliva-García, R.; Rodríguez-Ramos, J.M. Relative multiscale deep depth from focus. Signal Process. Image Commun. 2021, 99, 116417. [Google Scholar] [CrossRef]
- Mousnier, A.; Vural, E.; Guillemot, C. Partial light field tomographic reconstruction from a fixed-camera focal stack. arXiv 2015, arXiv:1503.01903. [Google Scholar]
- Scharstein, D.; Pal, C. Learning conditional random fields for stereo. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007. [Google Scholar] [CrossRef]
- Lee, J.; Lee, S.; Cho, S.; Lee, S. Deep defocus map estimation using domain adaptation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12214–12222. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Runtime (ms) | PSNR Average (dB) |
|---|---|---|
| Ours | 38 | 29.25 |
| DDFF | 580 | 22.01 |
| Hui et al | 3700 | 22.77 |
| VDFF | 7362 | 24.87 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oliva-García, R.; Ceruso, S.; Marichal-Hernández, J.G.; Rodriguez-Ramos, J.M. Monocular Real Time Full Resolution Depth Estimation Arrangement with a Tunable Lens. Appl. Sci. 2022, 12, 3141. https://doi.org/10.3390/app12063141
Oliva-García R, Ceruso S, Marichal-Hernández JG, Rodriguez-Ramos JM. Monocular Real Time Full Resolution Depth Estimation Arrangement with a Tunable Lens. Applied Sciences. 2022; 12(6):3141. https://doi.org/10.3390/app12063141
Chicago/Turabian StyleOliva-García, Ricardo, Sabato Ceruso, José G. Marichal-Hernández, and José M. Rodriguez-Ramos. 2022. "Monocular Real Time Full Resolution Depth Estimation Arrangement with a Tunable Lens" Applied Sciences 12, no. 6: 3141. https://doi.org/10.3390/app12063141