
Fast and Efficient Union of Sparse Orthonormal Transforms via DCT and Bayesian Optimization †


Abstract
:1. Introduction
- The SOT provides powerful transform, which outperforms KLT, but it is limited because of the computation time and dictionary size.
- We propose an extension of the SOT to address the limitation of orthonormal dictionary learning, which is based on the union of orthonormal bases. However, in contrast to [10], we formulated an orthogonal sparse coding in several orthogonal sparse coding problems with subdatasets.
- We classified input data and allocate each orthogonal dictionary and its coefficients to each classified input data to help to make the input data sparse representation.
- To prevent time and iteration increase by the number of dictionaries, we used a double-sparsity structure proposed in [15] with a DCT matrix as a fixed base dictionary.
- To find the optimal value of , which is non-convex and continuous, we adapted Bayesian optimization in our proposed method and set the optimal parameter with fewer iterations.
2. Related Works
2.1. Sparse Orthonormal Transform
| Algorithm 1: Orthogonal sparse coding. |
 |
2.2. Union of Orthonormal Bases
2.3. Double Sparsity Model
3. Proposed Algorithm
3.1. Classification via Discrete Cosine Transform
3.2. Union of Orthogonal Sparse Coding in DCT Domain
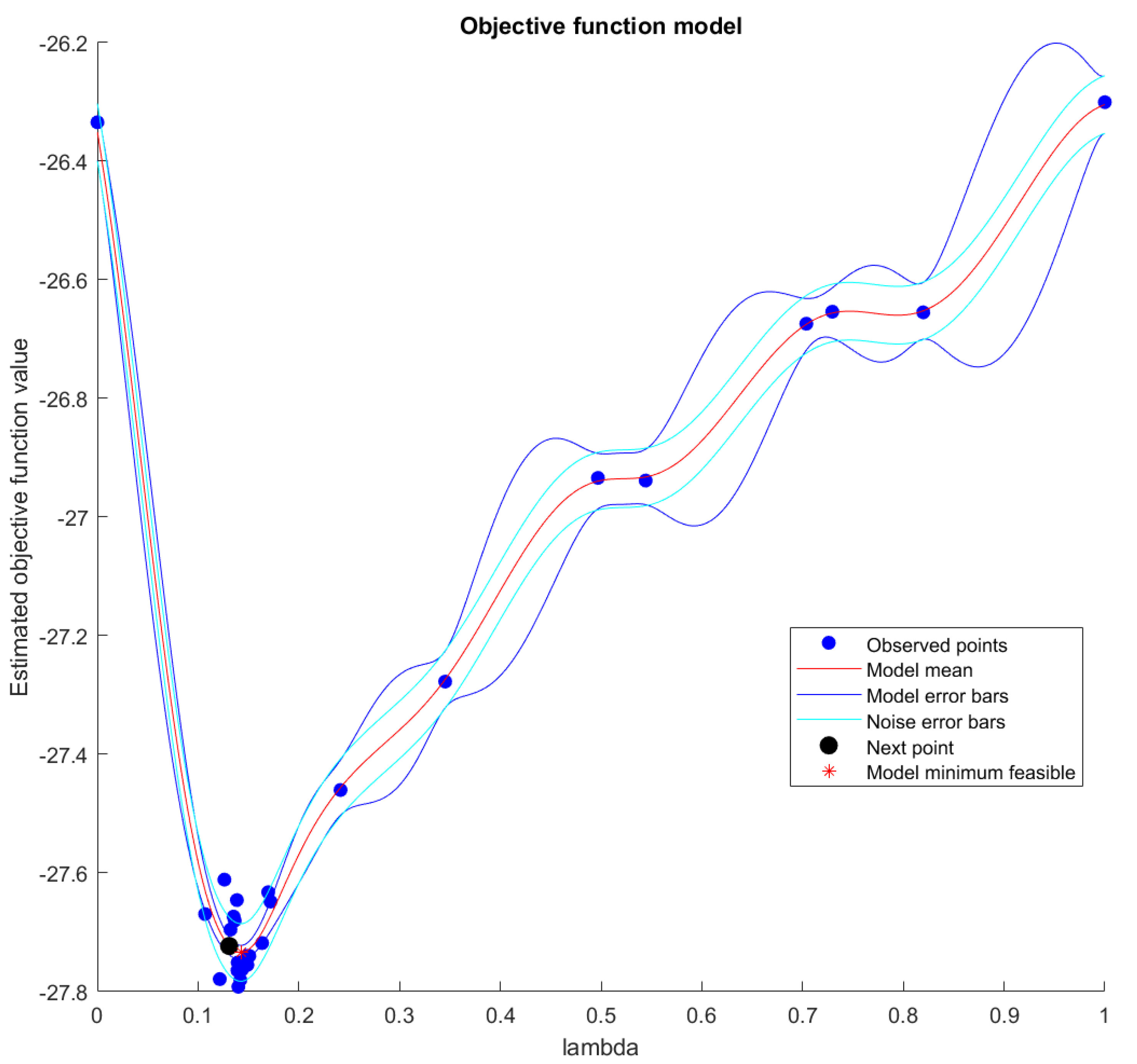
3.3. Parameter Setting via Bayesian Optimization
| Algorithm 2: Algorithm of proposed method. |
 |
4. Results
4.1. Experimental Environment
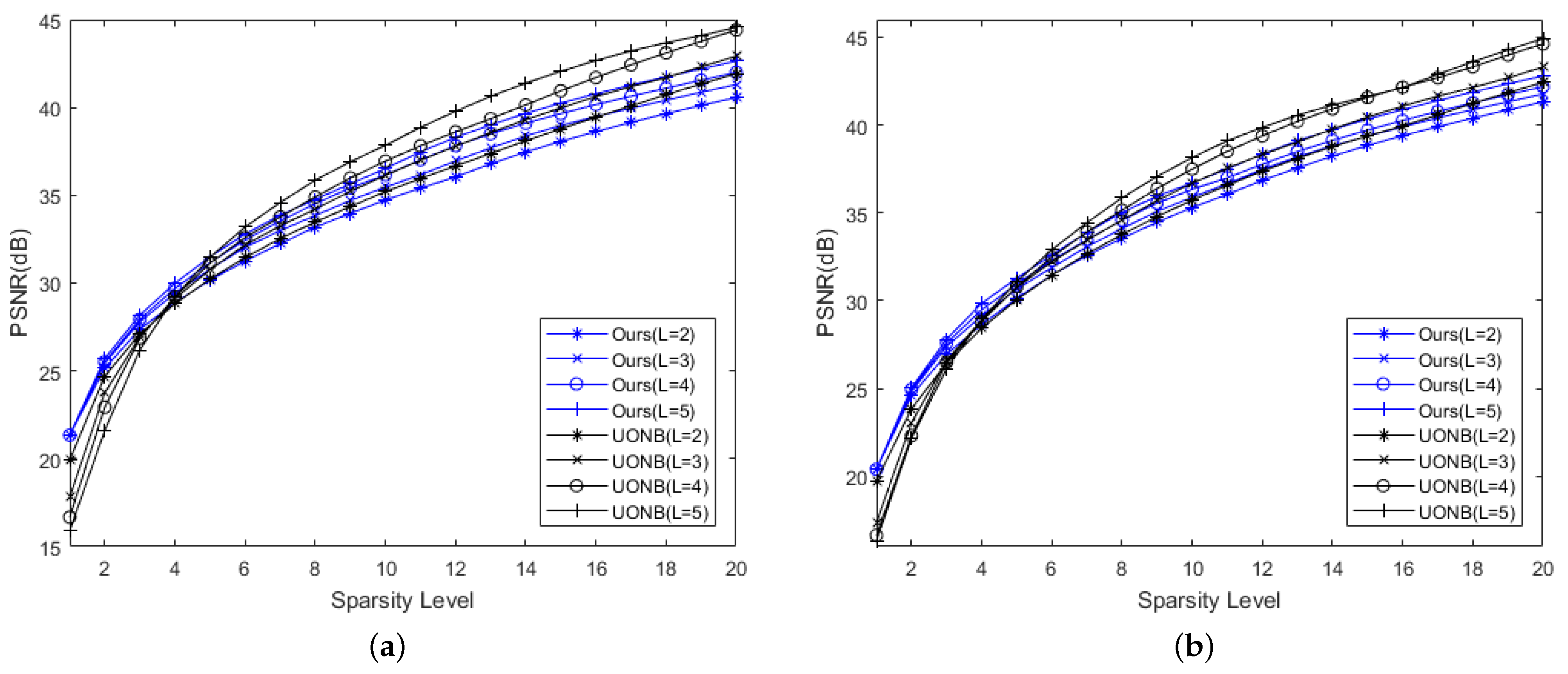
4.2. Comparison with Sparse Orthonormal Transform
4.3. Effect of Proposed Classification Method
4.4. Comparison with an Overcomplete Dictionary
4.5. Processing Time
4.6. Effects on a Bayesian Optimization
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| DCT | Discrete Cosine Transform |
| KLT | Karhunen–Loeve Transform |
| SOT | Sparse Orthonormal Transform |
| UONB | Union of Orthonormal Bases |
References
- Zhang, Z.; Xu, Y.; Yang, J.; Li, X.; Zhang, D. A Survey of Sparse Representation: Algorithms and Applications. IEEE Access 2015, 3, 490–530. [Google Scholar] [CrossRef]
- Aharon, M.; Elad, M.; Bruckstein, A. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Elad, M.; Aharon, M. Image Denoising Via Sparse and Redundant Representations Over Learned Dictionaries. IEEE Trans. Image Process. 2006, 15, 3736–3745. [Google Scholar] [CrossRef]
- Sezer, O.G.; Guleryuz, O.G.; Altunbasak, Y. Approximation and Compression With Sparse Orthonormal Transforms. IEEE Trans. Image Process. 2015, 24, 2328–2343. [Google Scholar] [CrossRef]
- Kalluri, M.; Jiang, M.; Ling, N.; Zheng, J.; Zhang, P. Adaptive RD Optimal Sparse Coding With Quantization for Image Compression. IEEE Trans. Multimed. 2019, 21, 39–50. [Google Scholar] [CrossRef]
- Ravishankar, S.; Bresler, Y. Learning Sparsifying Transforms. IEEE Trans. Signal Process. 2013, 61, 1072–1086. [Google Scholar] [CrossRef]
- Ravishankar, S.; Bresler, Y. Learning overcomplete sparsifying transforms for signal processing. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 3088–3092. [Google Scholar] [CrossRef]
- Rusu, C.; Thompson, J. Learning fast sparsifying overcomplete dictionaries. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos, Greece, 28 August–2 September 2017; pp. 723–727. [Google Scholar] [CrossRef] [Green Version]
- Sezer, O.G.; Harmanci, O.; Guleryuz, O.G. Sparse orthonormal transforms for image compression. In Proceedings of the 2008 15th IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 149–152. [Google Scholar] [CrossRef]
- Lesage, S.; Gribonval, R.; Bimbot, F.; Benaroya, L. Learning unions of orthonormal bases with thresholded singular value decomposition. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP ’05), Philadelphia, PA, USA, 23 March 2005; Volume 5, pp. v/293–v/296. [Google Scholar] [CrossRef] [Green Version]
- Shen, B.; Sethi, I.K. Direct feature extraction from compressed images. In Storage and Retrieval for Still Image and Video Databases IV; Sethi, I.K., Jain, R.C., Eds.; International Society for Optics and Photonics, SPIE: Bellingham, WA, USA, 1996; Volume 2670, pp. 404–414. [Google Scholar] [CrossRef] [Green Version]
- Lee, G.; Choe, Y. Fast and Efficient Union of Sparse Orthonormal Transform for Image Compression. In Proceedings of the 18th International Conference on Signal Processing and Multimedia Applications, SIGMAP 2021, Online Streaming, 6–8 July 2021; Santini, S., Sung, A.H., Eds.; SCITEPRESS: Milano, Italy, 2021; pp. 95–102. [Google Scholar] [CrossRef]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical Bayesian Optimization of Machine Learning Algorithms. In Advances in Neural Information Processing Systems; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; Volume 25. [Google Scholar]
- Frazier, P.I. A Tutorial on Bayesian Optimization. arXiv 2018, arXiv:1807.02811. [Google Scholar]
- Rubinstein, R.; Zibulevsky, M.; Elad, M. Double Sparsity: Learning Sparse Dictionaries for Sparse Signal Approximation. IEEE Trans. Signal Process. 2010, 58, 1553–1564. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers. Found. Trends® Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Yang, J.; Zhang, Y. Alternating Direction Algorithms for L1-Problems in Compressive Sensing. SIAM J. Sci. Comput. 2011, 33, 250–278. [Google Scholar] [CrossRef]
- Schütze, H.; Barth, E.; Martinetz, T. Learning Efficient Data Representations with Orthogonal Sparse Coding. IEEE Trans. Comput. Imaging 2016, 2, 177–189. [Google Scholar] [CrossRef]
- Rusu, C.; Dumitrescu, B. Block orthonormal overcomplete dictionary learning. In Proceedings of the 21st European Signal Processing Conference (EUSIPCO 2013), Marrakech, Morocco, 9–13 September 2013; pp. 1–5. [Google Scholar]
- Bao, C.; Cai, J.F.; Ji, H. Fast Sparsity-Based Orthogonal Dictionary Learning for Image Restoration. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3384–3391. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| L | # of Retained Coefficients | SOT | UONB | Proposed | |||
|---|---|---|---|---|---|---|---|
| Iterations | Time (s) | Iterations | Time (s) | Iterations | Time (s) | ||
| 1 | 3 | 2095 | 1.4553 | - | - | - | - |
| 5 | 2741 | 1.9480 | - | - | - | - | |
| 2 | 3 | - | - | 622 | 49.7882 | 72 | 0.0498 |
| 5 | - | - | 536 | 82.9780 | 107 | 0.0650 | |
| 3 | 3 | - | - | 628 | 343.3251 | 183 | 0.1174 |
| 5 | - | - | 505 | 97.5815 | 157 | 0.0872 | |
| 4 | 3 | - | - | 482 | 57.8052 | 195 | 0.0920 |
| 5 | - | - | 754 | 101.3284 | 192 | 0.1007 | |
| Methods | Bayesian Method | Exhaustive Method | ||||
|---|---|---|---|---|---|---|
| Iterations | 10 | 30 | 100 | 1000 | ||
| Barbara | 4 × 4 | PSNR(dB) | 31.7748 | 31.8543 | 31.8395 | 31.8545 |
| 0.0396964 | 0.040544 | 0.0200 | 0.0140 | |||
| 8 × 8 | PSNR(dB) | 27.01254 | 27.1991 | 25.1582 | 27.1911 | |
| 0.13714 | 0.063292 | 0.0070 | 0.1330 | |||
| House | 4 × 4 | PSNR(dB) | 35.5931 | 35.6488 | 35.6092 | 35.6709 |
| 0.041138 | 0.026825 | 0.0200 | 0.0150 | |||
| 8 × 8 | PSNR(dB) | 30.3563 | 30.3577 | 30.3283 | 30.3559 | |
| 0.319391 | 0.099313 | 0.1600 | 0.0980 | |||
| Lena | 4 × 4 | PSNR(dB) | 32.9539 | 33.0129 | 32.9817 | 33.0218 |
| 0.051326 | 0.034557 | 0.0400 | 0.0320 | |||
| 8 × 8 | PSNR(dB) | 27.7297 | 27.8073 | 27.7918 | 27.8325 | |
| 0.16529 | 0.069484 | 0.1400 | 0.0940 | |||
| Peppers | 4 × 4 | PSNR(dB) | 33.1043 | 33.1161 | 33.0836 | 33.1197 |
| 0.046513 | 0.06335 | 0.0500 | 0.0350 | |||
| 8 × 8 | PSNR(dB) | 27.3874 | 27.4054 | 27.3951 | 27.4300 | |
| 0.2068 | 0.21706 | 0.1900 | 0.2050 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, G.; Choe, Y. Fast and Efficient Union of Sparse Orthonormal Transforms via DCT and Bayesian Optimization. Appl. Sci. 2022, 12, 2421. https://doi.org/10.3390/app12052421
Lee G, Choe Y. Fast and Efficient Union of Sparse Orthonormal Transforms via DCT and Bayesian Optimization. Applied Sciences. 2022; 12(5):2421. https://doi.org/10.3390/app12052421
Chicago/Turabian StyleLee, Gihwan, and Yoonsik Choe. 2022. "Fast and Efficient Union of Sparse Orthonormal Transforms via DCT and Bayesian Optimization" Applied Sciences 12, no. 5: 2421. https://doi.org/10.3390/app12052421