


Cooperative Transmission Mechanism Based on Revenue Learning for Vehicular Networks
 ,
,
Abstract
:1. Introduction
2. System Model and Tool Analysis
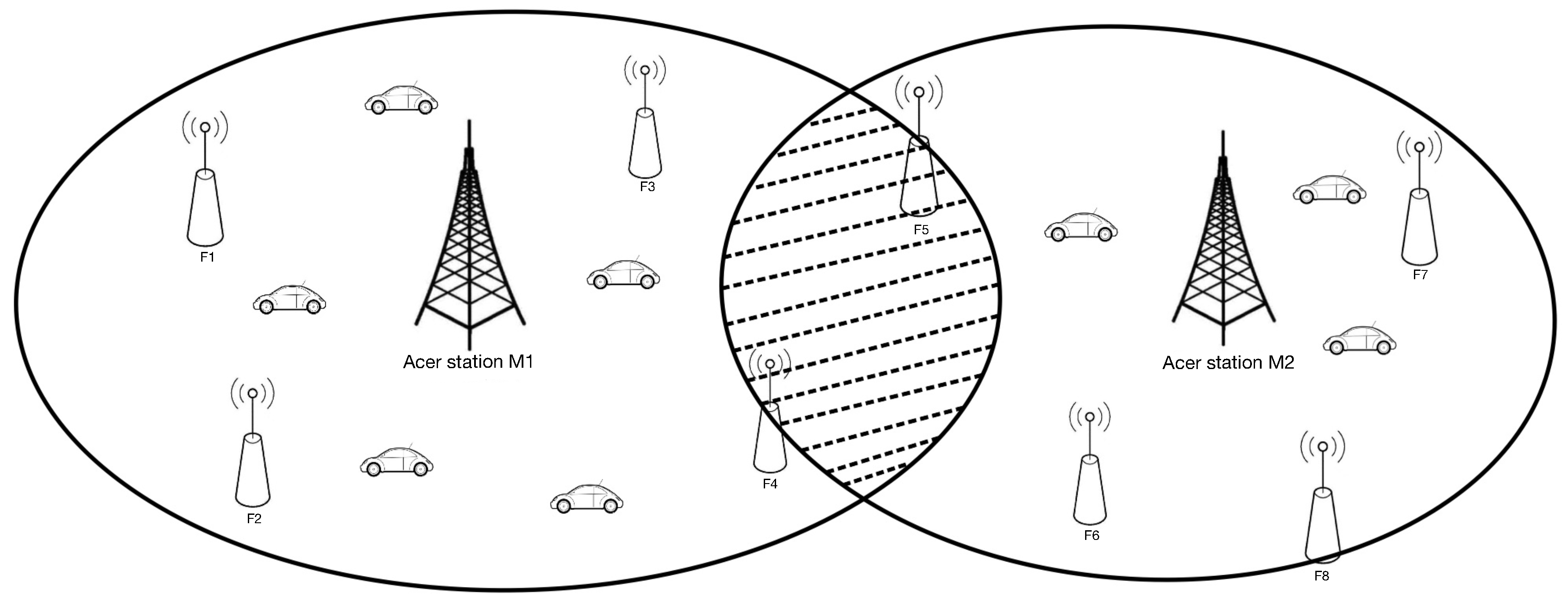
2.1. System Model
2.2. Multi-Point Cooperative Transmission Mechanism for Vehicular Users
2.3. Reinforcement Learning of Q-Learning
3. Joint Cell Anti-Jamming Map Based on Dual Connection
3.1. Interference Graph Model Based on Graph Theory
3.2. Maximum Clique Search Algorithm for Inter-Cell Interference Graph
| Algorithm 1 Cluster Searching Algorithm for Interference Graph |
1: Input: G(Vn, Em), Con(CV1, CV2,...,CVn), Ang(AV1, AV2, ...,AVn) 2: for i = 1 to n do 3: K = length(CVi) 4: while K ≥ 1 do 5: for j = 1 to K do 6: if AVi (j) >AVi (j + 1) then 7: temp = AVi (j + 1) 8: AVi (j + 1) = AVi (j) 9: AVi (j) = temp 10: temp = CVi (j + 1) 11: CVi (j + 1) = CVi (j) 12: CVi (j) = temp 13: end if 14: end for 15: K = K − 1 16: end while 17: end for 18: for i = 1 to n do 19: for j = 1 to length(CVi) do 20: Put {Vi,Vj,Vj+1} into Cli 21: end for 22: end for 23: Delete the repeating items of the Cli 24: Output: Cli |
3.3. Maximal Clique Approximate Search Algorithm
Algorithm 2 Cluster Searching Algorithm for Conflict Graph |
1:Input:col (V,E) 2:n = length(V) 3:Cm = Ø 4:for i = 1 to n do 5: Cd = Vi 6: Nv = search_adjacent_node(Vi) 7: K = length(Nv) 8: while Nv != Ø do 9: Node = Search_max_degree(Nv) 10: if cluster_judgement(Node, Cd) = =1 then 11: Cd = Cd∪ Node 12: end if 13: Delete Node from NV 14: end while 15: Cm = Cm ∪ Cd 16:Delete the repeat item in Cm 17:Output:Cm |
3.4. Interference Coordination Algorithm Based on Interference Graph
4. Collaborative Transmission Mechanism Based on Q-Learning for Vehicular Networks
4.1. Selection of Reinforcement Learning Algorithm
| Algorithm 3 Q-learning algorithm 1 (ϵ-greedy) |
1: Initialize Q(s,a) arbitrary 2: Repeat (for all episode): 4: Random take action a 5: else: 6: Take action a which is the greatest in Q(s’,a) 8: Update s’ |
| Algorithm 4 Q-learning algorithm 2 (softmax) |
1: Initialize Q(s,a) arbitrary 2: Repeat (for all episode): 4: Take action a correspond with A 5: 6: Update s’ |
4.2. Multi-Point Collaborative Transmission with Revenue Learning
| Algorithm 5 Collaborative multipoint transmission collaborative algorithm flow |
1: Initialize Q(action, combination) for all the cluster arbitrary 2: Repeat (for all time_slots): 3: Initiate process below for the cluster scheduled in this time slot: 4: 5: Random take action for all the unused base station in the cluster 6: else: 7: Take action with the greatest value in Q for all the stations 8: Update Q as below: |
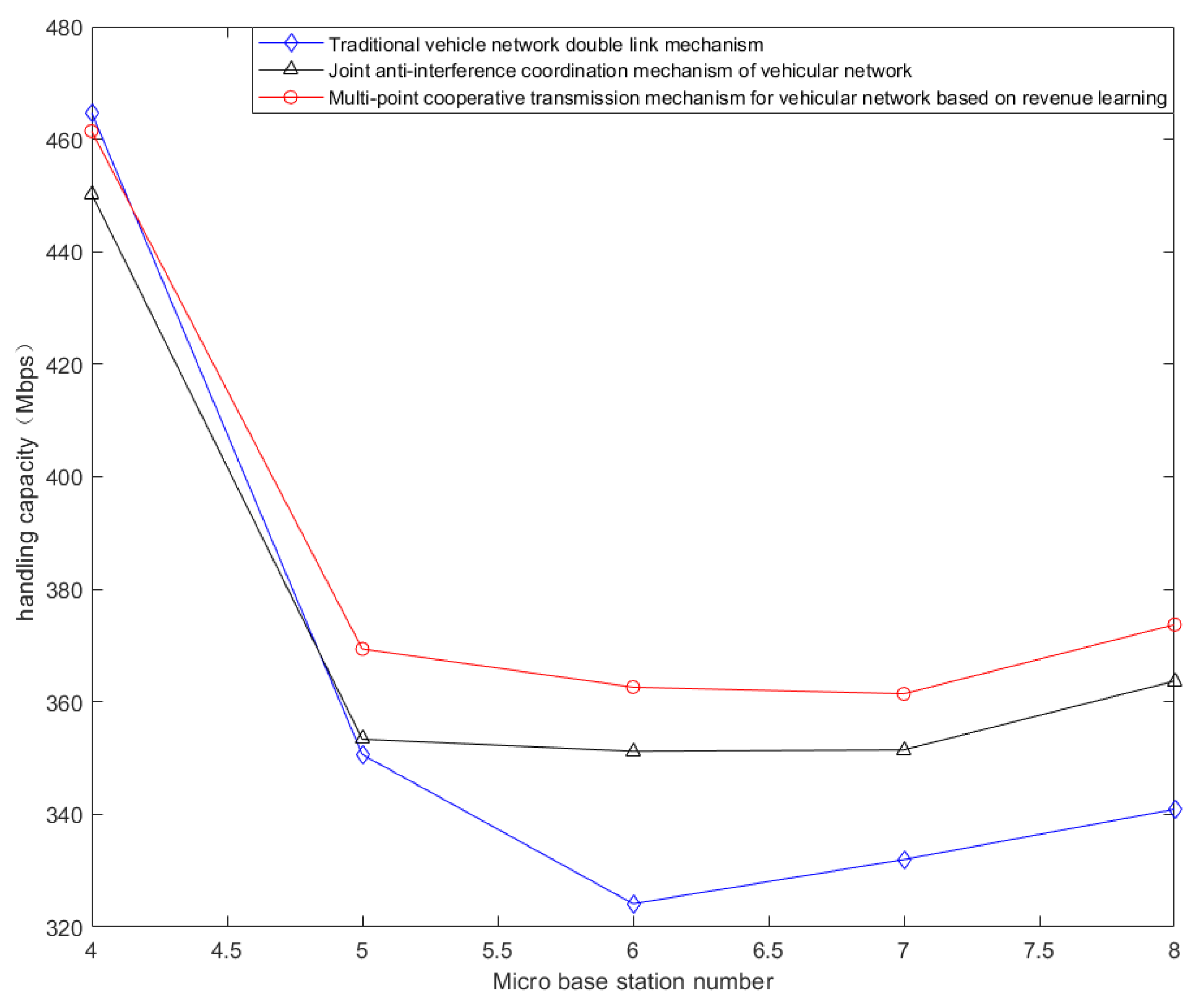
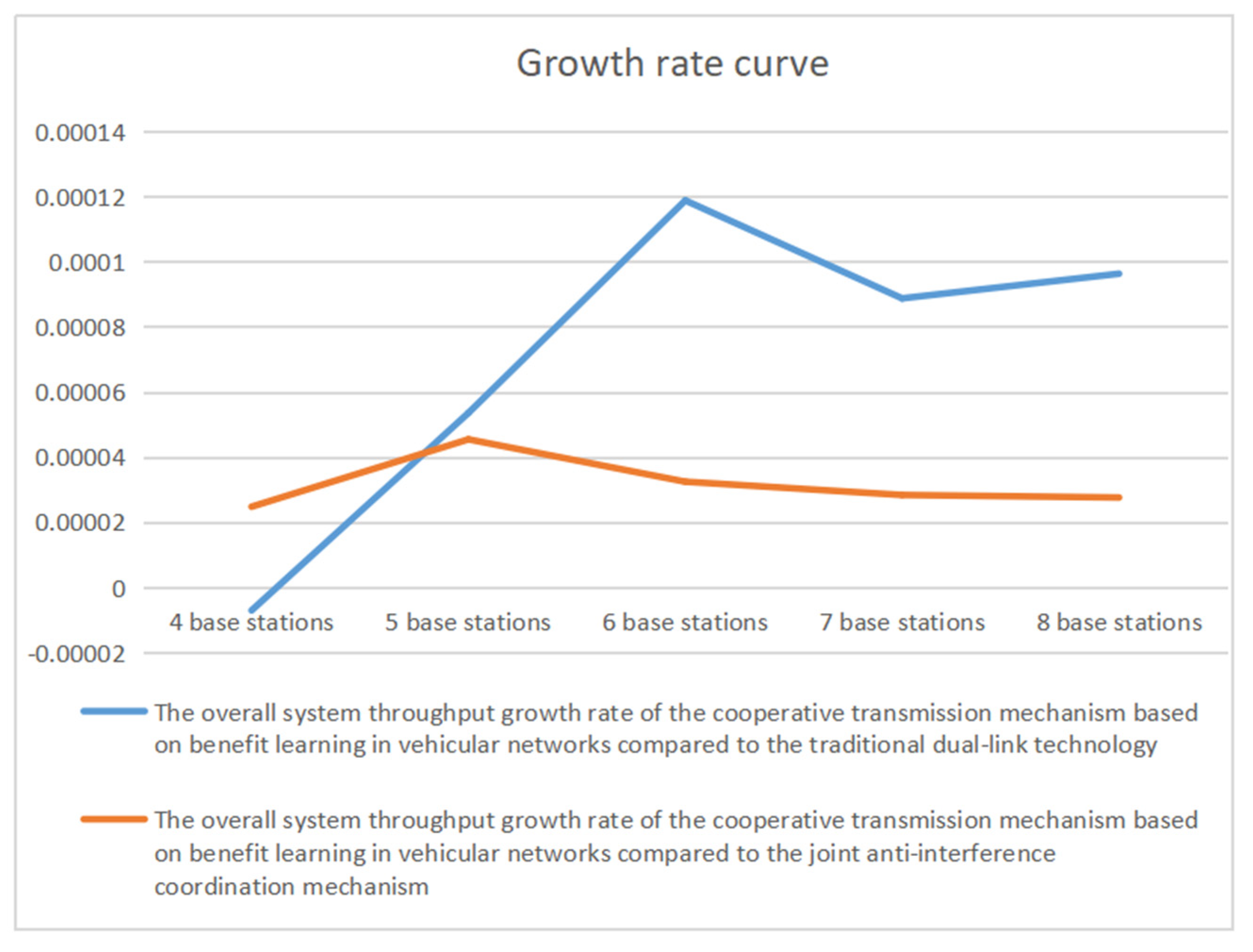
5. Simulation Results and Comparative Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Qian, Y.; Yu, M.; Guo, X.; Huang, H.; Li, S. Development of intelligent control technology for unmanned vehicle. Sci. Technol. Eng. 2022, 22, 3846–3858. [Google Scholar]
- Ding, M.; Luo, H. Multi-Point Cooperative Communication Systems: Theory and Applications, 1st ed.; Shanghai Jiao Tong University Press: Shanghai, China; Springer: Berlin/Heidelberg, Germany, 2013; pp. 217–243. [Google Scholar]
- Hu, S.; Liu, X.; Zhang, W.; Xiao, H. Vehicular cooperative communication relay selection based on supervised machine learning. Comput. Appl. 2021, 41, 167–174. [Google Scholar]
- Krishnan, K.R.; Luss, H. Power selection for maximizing SINR in femtocells for specified SINR in macrocell. In Proceedings of the 2011 IEEE Wireless Communications and Networking Conference, Cancun, Mexico, 28–31 March 2011; pp. 563–568. [Google Scholar] [CrossRef]
- Strawn, G. Claude Shannon: Mastermind of Information Theory. IT Prof. 2014, 16, 70–72. [Google Scholar] [CrossRef]
- Jie, B. Discussion on the application of Collaborative Multi-Point Transmission Technology in 5G. Guangdong Commun. Technol. 2022, 42, 43–46. [Google Scholar]
- Watkin, C.J.C.H.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Huang, W.; Cui, X.; Chen, J.; Rao, Y. Coordinated scheduling of Energy interconnection Park based on multi-agent Q learning algorithm. Eng. J. Wuhan Univ. 2022, 55, 1141–1148. [Google Scholar]
- Kim, S.; Kim, K.; Kim, C. A Simulator for Performance Comparison of Four Color Allocation. In Proceedings of the 2017 International Conference on Intelligent Environments (IE), Seoul, Republic of Korea, 21–25 August 2017; pp. 136–141. [Google Scholar] [CrossRef]
- Szabó, S.; Zaválnij, B. A different approach to maximum clique search. In Proceedings of the 2018 20th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC), Timisoara, Romania, 20–23 September 2018; pp. 310–316. [Google Scholar]
- Porjazoski, M.; Popovski, B. Contribution to analysis of Inter cell interference coordination in LTE: A fractional frequency reuse case. In Proceedings of the Global Mobile Congress, Shanghai, China, 18–19 October 2010; pp. 1–4. [Google Scholar]
- Lei, X.; Li, J.; Xue, Y.; Duan, M.; Ma, W. Roundness error evaluation based on polar mesh searching algorithm. In Proceedings of the 2009 International Conference on Mechatronics and Automation, Changchun, China, 9–12 August 2009; pp. 3855–3859. [Google Scholar] [CrossRef]
- Shen, Y.; Zeng, C. An Adaptive Approach for the Exploration-Exploitation Dilemma in Non-stationary Environment. In Proceedings of the 2008 International Conference on Computer Science and Software Engineering, Wuhan, China, 12–14 December 2008; Volume 1, pp. 497–500. [Google Scholar] [CrossRef]
- Zheng, Y.; Luo, S.; Zhang, J. Greedy exploration policy of Q-learning based on state balance. In Proceedings of the TENCON 2005—2005 IEEE Region 10 Conference, Melbourne, VIC, Australia, 21–24 November 2005; pp. 1–4. [Google Scholar] [CrossRef]
- Tijsma, A.D.; Drugan, M.M.; Wiering, M.A. Comparing exploration strategies for Q-learning in random stochastic mazes. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Du, D.; Li, X.; Fei, M.; Bai, H.; Song, Y. Self-learning fuzzy control strategy of two-layer networked learning control systems based on improved RBF neural network. In Proceedings of the 30th Chinese Control Conference, Yantai, China, 22–24 July 2011; pp. 4735–4740. [Google Scholar]
- Xiaobo, X.; Kangfeng, Z.; Yixian, Y.; Guoai, X. A model for real-time simulation of large-scale networks based on network processor. In Proceedings of the 2009 2nd IEEE International Conference on Broadband Network & Multimedia Technology, Beijing, China, 18–20 October 2009; pp. 237–241. [Google Scholar] [CrossRef]
- Drozdova, V.G.; Akhpashev, R.V. Ordinary least squares in COST 231 Hata key parameters optimization base on experimental data. In Proceedings of the 2017 International Multi-Conference on Engineering, Computer and Information Sciences (SIBIRCON), Novosibirsk, Russia, 18–22 September 2017; pp. 236–238. [Google Scholar] [CrossRef]
- Cui, K.; Koibuchi, M. Performance Evaluation of Collective Communication on Random Network Topology. In Proceedings of the 2018 Sixth International Symposium on Computing and Networking Workshops (CANDARW), Takayama, Japan, 27–30 November 2018; pp. 159–162. [Google Scholar] [CrossRef]
- Koppen, M.; Yoshida, K.; Tsuru, M. Unsorting the proportional fairness relation. In Proceedings of the 2011 Third International Conference on Intelligent Networking and Collaborative Systems, Fukuoka, Japan, 30 November–2 December 2011; pp. 47–52. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Combination | User 1 | User 2 | User 3 … | User n | ||
|---|---|---|---|---|---|---|
| Actions | ||||||
| Leave unused | ||||||
| User 1 | - | |||||
| User 2 | - | |||||
| User 3 | - | |||||
| ... | - | |||||
| User n | - | |||||
| Parameter | The Values |
|---|---|
| Acer station transmit power | 46 dbm |
| Transmit power for micro base station and vehicular network users | 20 dbm |
| Number of Acer stations | 1 |
| Number of micro base stations | 4 ≤ U ≤ 8 |
| Number of users | Twice the number of micro base stations |
| Small scale fading | A lognormal distribution with a mean of 3 dB |
| Acer station bandwidth | 20 Mhz |
| Bandwidth for micro base stations and vehicular network users | 100 Mhz |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, M.; Cui, H.; Nie, M.; Chen, Q.; Yang, S.; Du, Y.; Dai, F. Cooperative Transmission Mechanism Based on Revenue Learning for Vehicular Networks. Appl. Sci. 2022, 12, 12651. https://doi.org/10.3390/app122412651
Chen M, Cui H, Nie M, Chen Q, Yang S, Du Y, Dai F. Cooperative Transmission Mechanism Based on Revenue Learning for Vehicular Networks. Applied Sciences. 2022; 12(24):12651. https://doi.org/10.3390/app122412651
Chicago/Turabian StyleChen, Mingyang, Haixia Cui, Mingsheng Nie, Qiuxian Chen, Shunan Yang, Yongliang Du, and Feipeng Dai. 2022. "Cooperative Transmission Mechanism Based on Revenue Learning for Vehicular Networks" Applied Sciences 12, no. 24: 12651. https://doi.org/10.3390/app122412651