1. Introduction
With the progress of modern science and technology, the identification methods of cultural relics have been gradually developing. More than 60,000 bone sticks have been unearthed from the third building site of the Weiyang Palace, of which more than 57,000 are inscribed with hundreds of thousands of characters. These are very precious archaeological materials for studying the history and culture of the Western Han Dynasty [
1]. The Western Han Dynasty was a crucial period in the development and change of ancient Chinese calligraphy and a confirmed period for modern Chinese characters. The bone stick text is of great academic importance for studying the derivation of calligraphic strokes in the Western Han Dynasty and exploring Chinese characters’ ancient and modern script changes [
2]. The bone stick text not only provides a large amount of biological data for the study of Han official offices, weapons manufacturing management, imperial city architecture, and the history of the Han dynasty but also provides an essential basis for the study of Han archives and the history of ancient archives [
3]. Correctly interpreting bone stick information is essential for exploring the history and culture of this period. However, bone stick text recognition relies only on experts to discriminate manually, which is time-consuming and laborious. Using image processing and artificial intelligence technology as a primary research method can assist scholars in quickly interpreting ancient texts or realizing image retrieval based on text content, improving work efficiency.
In recent years, convolutional neural networks have achieved inclusion in suitable applications in the field of image recognition. Ziyi Wu et al. [
4] proposed Chinese character recognition based on an integrated attention layer convolutional neural network, which can comprehensively extract Chinese character feature information and distinguish shapes similar to Chinese characters. However, this method has high complexity and low training efficiency. Guoying Liu [
5,
6] detailed the research progress of oracle character recognition and oracle character detection from the perspectives of the application of traditional methods to the attempt to use deep learning techniques and described the technical details of the appropriate methods, the information of the used data set, and the actual performance. Mengting Liu [
7] used strip convolution instead of ordinary convolution to reduce the number of neural network parameters and achieve lightweight recognition of oracle bone rubbing. Hao-Bin Wang [
8] combined region-based complete convolutional networks and feature pyramid networks to design and build a basic oracle bone character recognition algorithm framework. Li Wenying et al. [
9] proposed a deep learning-based inscription recognition method, which can accurately recognize text using a neural network model with two-stage feature mapping. However, the algorithm is limited by the amount of sample data. Ru et al. [
10] introduced a deformation convolution module based on a traditional convolutional neural network to improve a network’s modeling ability and training accuracy. However, the method can only recognize simple handwritten numerals, which has certain limitations. Yanlong Luo [
11] et al. improved the ResNet network structure to achieve oracle handwriting recognition, but the recognition rate is not high for complex background characters. Chunshan Wang [
12] et al. proposed multi-scale vegetable disease recognition to achieve a lightweight model, but the recognition accuracy is not high. Kuang-Bo et al. [
13] proposed multi-scale bronze inscription topography detection using a repetitive feature pyramid network, dual-FPN (dual-feature pyramid network), to more effectively fuse the feature maps of each scale in the model.
In this paper, we propose a multi-scale fusion method for bone stick text recognition which enhances the recognition rate of bone stick text by effectively using the detailed information continuously lost during the convolution process. In the model-building process, the last layer of features of each residual block in the ResNet convolution process is firstly retained. These five scale features are used to reduce the high-dimensional information using the maximum pooling operation. Then, the different scale features are fused using the channel splicing method. The corresponding fully connected layer parameters are increased, and this paper designs a comparison test of multiple fusion methods between different layers. In order to balance the recognition accuracy between different categories, internal weighting is performed using the focal loss function to further improve the accuracy. By comparing each neural network experiment and the ablation experiment, it can be found that the method introduced in this paper has the best ability for bone stick text recognition.
3. Multi-Scale Feature Fusion Model Design MS-ResNet
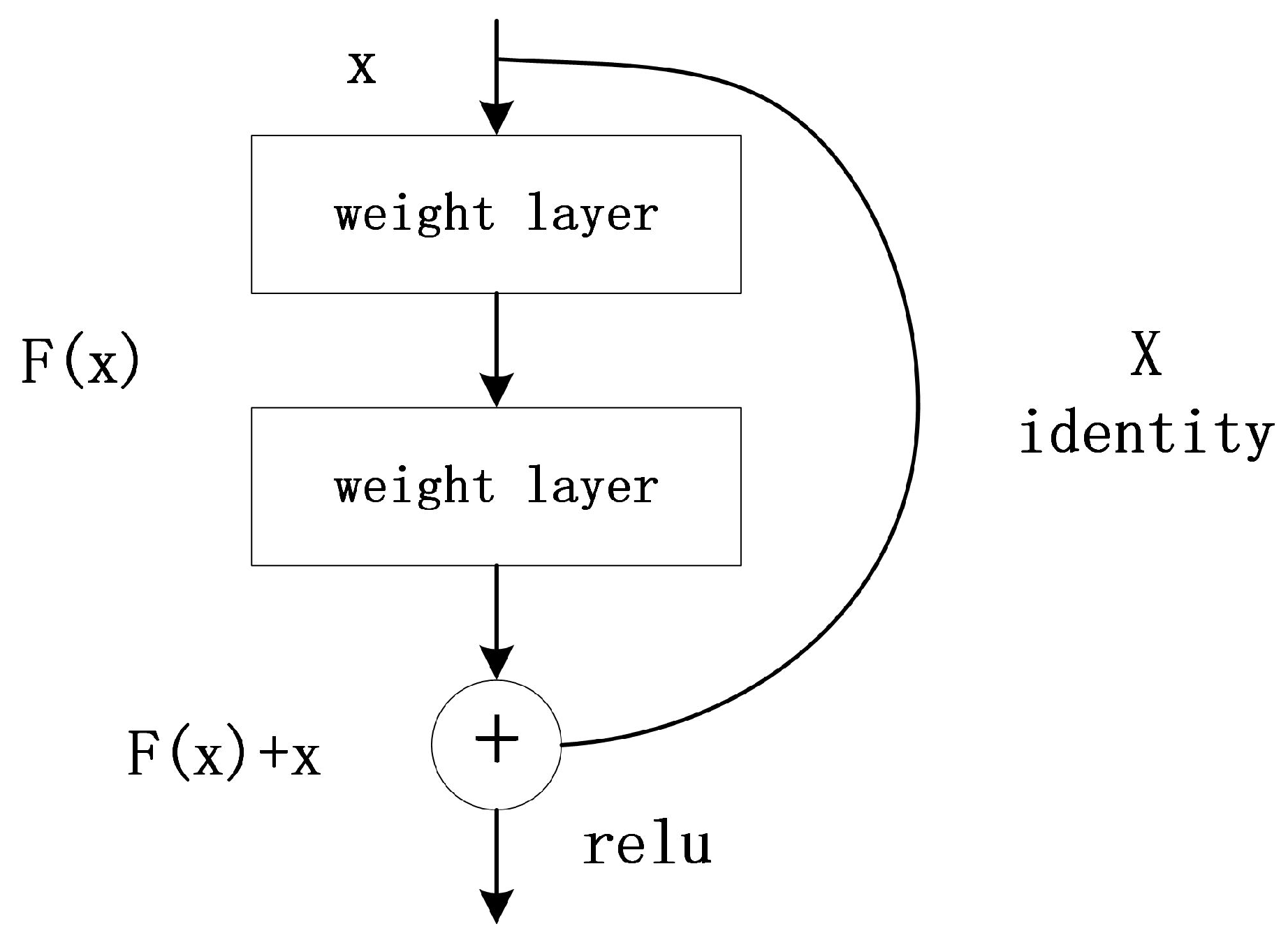
Bone sticks are old, the carriers are made of cow bones, different cow bones have different textures, the background color varies, the engraving strength varies, the bone stick stains and wears, decay damage is more serious, the bone stick writing style is variable, and there are cases of engraving in a “cursive” style where the traditional method can not be effectively recognized. Using deep learning methods in bone stick text recognition, the underlying feature map of the neural network contains some subtle features of the bone stick text, including texture, edge, angle, color, and other detailed features. In contrast, the higher-level feature map retains more important semantic information [
10]. As the convolution continues to deepen the neural network, the bottom features have high resolution and contain detailed information but less semantic information and more noise. The top features have more important semantic information but less detailed information at the bottom of the resolution [
22]. The feature maps extracted from the bone stick text after different depths of convolution layers are shown in
Figure 2.
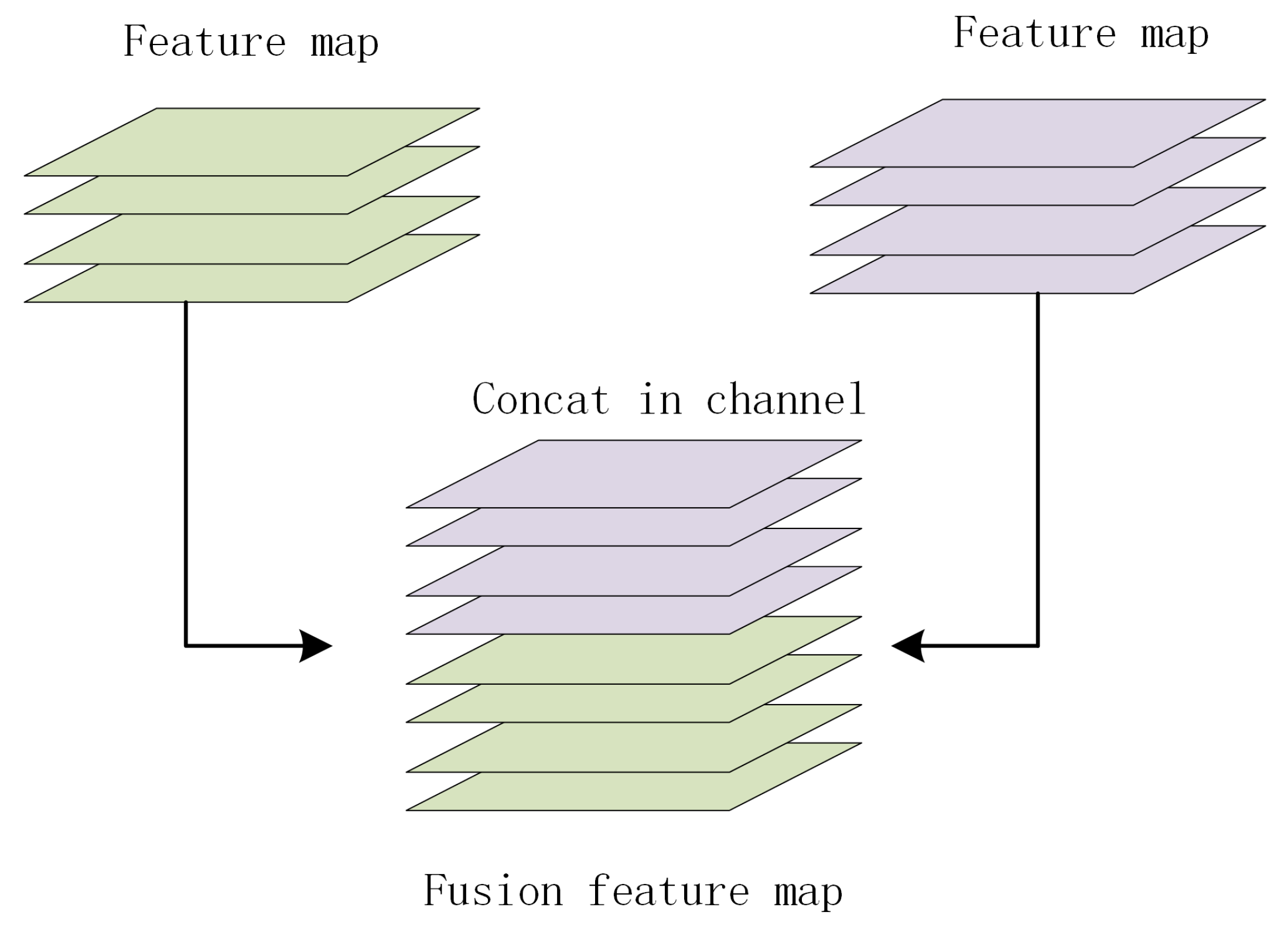
In bone stick text recognition, as the network deepens, the perceptual field gradually increases, the image information is compressed, the image detail information in the high-level feature map is continuously weakened, and text classification using only high-level features is too singular, so the detail perception is poor. Using a multi-scale model can effectively combine the advantages of both features and take into account the bone stick text details and semantic features, which is the key to improving the model feature extraction and thus enhancing the text recognition accuracy. In order to effectively extract different scale features, this paper designs a MS-ResNet model with multi-scale fusion. It introduces a multi-scale fusion strategy based on the ResNet34 neural network to fuse different levels of image features and enhance the text’s shallow detail features. In order to avoid the bottom detail features extracted from the features being covered by the higher-level features, resulting in the loss of detail features, channel stitching is used to fuse the feature maps of different scales, which not only retains the deep features but also adds the bottom features of different depths to obtain a multi-scale feature representation with richer information. Channel splicing means that two feature vectors are added in the channel dimension, the new vector retains both sets of vector features, and the channel splicing process is schematically shown in
Figure 3.
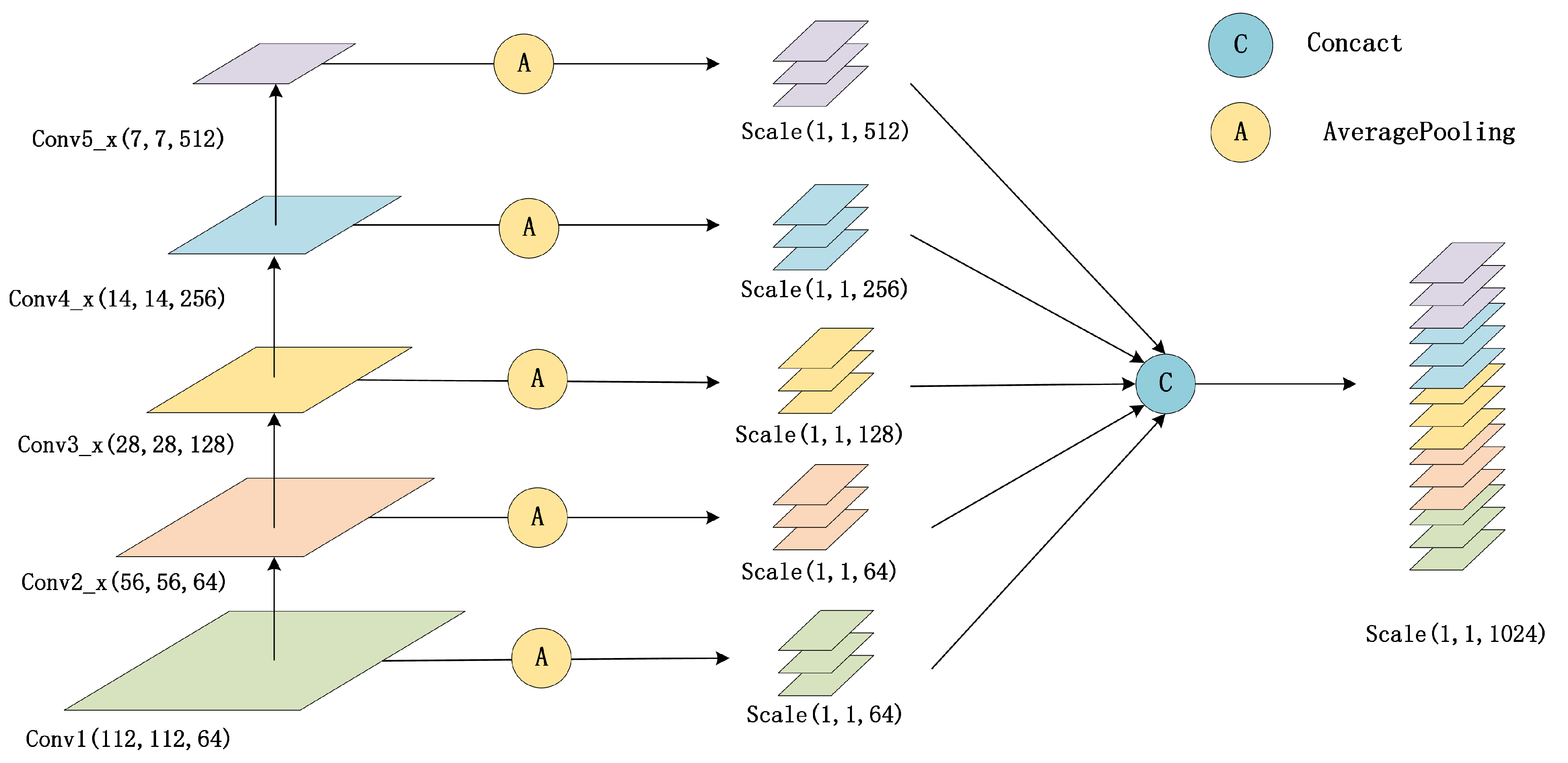
The multi-scale feature fusion method for bone stick text designed in this paper, the first layer 7 × 7 convolutional Conv1 features of ResNet, and the last layer output features Conv2_x, Conv3_x, Conv4_x, and Conv5_x in each residual block are selected. The above five feature maps are pooled on average and stitched in the channel dimension, and the feature fusion module can be expressed as Equation (
5)
where
is the Conv1 feature;
,
,
, and
denote the last residual output feature of the Conv2_x, Conv3_x, Conv4_x, and Conv5_x layers, respectively;
P denotes the global average pooling operation; and
denotes the splicing operation along the channel dimension.
ResNet first layer convolution of Conv1 features and the last residual output features in each Conv2_x, Conv3_x, Conv4_x, and Conv5_x layer yield Scale1, Scale2, Scale3, Scale4, and Scale5 with dimensions of (112,112,64), (56,56, 64), (28,28,128), (14,14,256), (7,7,512), respectively. The above five feature maps are pooled by averaging to obtain features with sizes of (1,1,64), (1,1,64), (1,1,128), (1,1,256), and (1,1,512), respectively. The five-layer feature vectors are stitched in the channel dimension to obtain (1,1,1024)-dimensional fused feature vectors. The fusion process is shown in
Figure 4.
After multi-scale fusion, the Conv5_x features are retained, and the Conv1, Conv2_x, Conv3_x, and Conv4_x layer features are incorporated using the channel splicing method. The number of the original 512 classification features is increased to 1024, which increases the underlying detail of the bone stick text information. Finally, it uses the obtained fused features for fully connected layer classification.
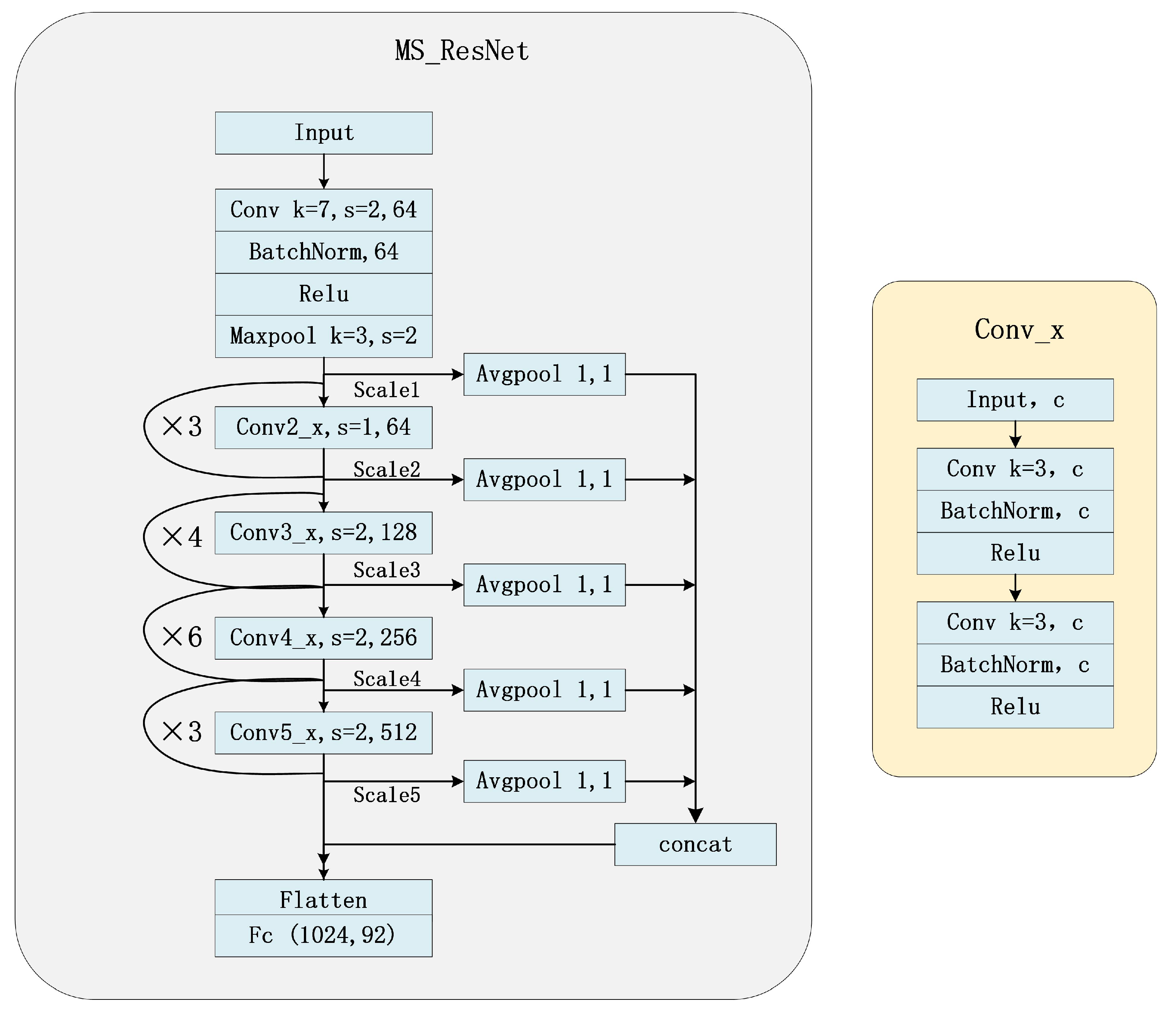
The structure of MS-ResNet is shown in
Figure 5. The MS-ResNet model mainly consists of 34 layers of the network. The first layer uses 7 × 7 convolution with a step size of 2 and a channel number of 64, followed by a maximum pooling operation to reduce the image size by half to obtain the feature map S1. Then, we enter the Conv2_x, Conv3_x, Conv4_x, and Conv5_x layers with channel numbers 64, 128, 256, 512, and 512, respectively. Each Conv_x has 3, 4, 6, and 3 residual blocks, respectively, and each residual block is stacked with two 3 × 3 convolutions to increase the network depth. The last residual convolution of each Conv_x yields S2, S3, S4, and S5, respectively, and then these five feature maps are pooled equally to obtain vectors with 1 × 1 × (number of channels) features. These five one-dimensional feature vectors are fused and stitched together using the channel stitching method to obtain new features, increasing the number of features to 1024 from the original 512 features, and finally, the fully connected layer is used.
4. Experimental Analysis and Discussion
4.1. Introduction of Experimental Data
The source of experimental data in this paper is a data set of pictures of bone stick text provided by the Institute of Archaeology of the Chinese Academy of Sciences, and a total of 2000 bone stick texts in two volumes were selected as experimental data. The pictures are whole bone sticks, and it is necessary to use LabelImg software to frame the bone stick text and input the corresponding word against the bone stick interpretation provided by the expert to realize bone stick text data labeling, and the data labeling process is shown in
Figure 6.
After labeling the text data of the bone stick, an XML file was generated, the XML file was parsed using python, and the labeled text was cropped and sorted into different folders. From this, a bone stick text data set was established in which some text samples were insufficient. This experiment selected bone stick text with a sample number of more than 10 as the experimental object, which created a data set that had 92 types of bone stick text and a total of 7312 images. In the face of the complex bone stick text situation, denoising the pictures will destroy the original morphological structure of the bone stick text. Therefore, this paper uses the original pictures for text training recognition without uniform denoising and binarizing of the bone stick text pictures. The bone stick text is cropped from the bone stick image, and its image size varies. In order to improve the recognition accuracy of the algorithm, a common image size normalization method, bilinear interpolation, is used to normalize the image size to 224 × 224 pixels. In order to expand the training sample, avoid overfitting the neural network, and obtain better recognition results, data enhancement methods were used to expand the bone stick text images before model training. In this paper, we used image flip, rotation, contrast enhancement, and brightness enhancement methods to expand the number of images to five times the original number of images and establish a unified bone stick text database with 36,560 images. Some of the bone stick text images are shown in
Figure 7.
In the experimental training phase, the training set, validation set, and test set were divided into 8:1:1. In order to expand the training sample, avoid overfitting the neural network, and obtain better recognition results, data augmentation methods were used to expand the data of the bone stick text images before model training. In this paper, we mainly considered brightness, contrast, flip, and rotation, a method that has no glyph changes and can retain the original image information. The training data set was expanded by making a series of changes to the training images to produce similar but different training samples. With the ResNet model, the test set’s accuracy was improved by 3% after experimental data enhancement. After data enhancement, the final number of images was expanded to five times the original number of images, totaling 36,560 bone stick text images in the training set. The graphs before and after data enhancement are shown in
Figure 8.
4.2. Experiment Environment
This experiment used Windows, GeForce RTX 3090 GPU, a Pytorch framework environment, model training with a cross-entropy loss function and Adam optimizer, a ReLu hidden layer activation function, a batch size of 32, an initial learning rate of 0.001, a cosine learning rate decay method, and the number of model training iterations was 100.
During the training of the neural network text recognition model, excessive recognition will degrade the neural network recognition performance. In order to explore the best bone stick text recognition model, the training weights of each iteration of the model were kept during the training process, the test set was tested, and the best experimental results in 100 iterations were selected for comparison. In order to quantitatively evaluate the performance of each model, the experiments used recall, precision, f1, accuracy (Acc), and fixed test set loss values as evaluation indexes to comprehensively evaluate the recognition and classification results of different algorithms.
4.3. Comparison of Different Fusions of Different Feature Layers with Each Other
In order to verify the effectiveness of the fusion effect using five-layer features, this paper designed 10 groups of fusion methods and compared the experiments using the bottom-layer features alone for recognition. Various feature layers fused with each other, S1, S2, S3, S4, and S5, respectively, denote the first layer of the MS-ResNet features and the five layers of the last output layer of each residual from shallowest to deepest. The bottom layer features S5 and the middle layers are fused with each other. For example, the first-, third-, and fifth-layer features are fused as S1+S3+S5. The following experiments were conducted to fuse different feature layers on bone stick text recognition, and their various effects are shown in
Table 1.
As can be seen from the table, S5 represents the accuracy of recognition originally using only single-layer features, which is only 88.6%, and the classification results of fusing different underlying features are all higher than 88.6%. Multi-scale feature fusion improves the accuracy of bone stick text recognition to different degrees for different layer fusion methods compared with single high-level feature classification, indicating that each intermediate feature layer contributes to bone stick text recognition. Therefore, the effectiveness of the fusion of different underlying features to enhance the fine-grained features of text and improve the accuracy of bone stick text recognition is verified, and the superiority of the multi-scale fusion approach of this paper’s model is validated.
In
Figure 9 below, there are 23 samples for “Man” and 23 samples for “Shuo”, which are similar in number and shape. The original ResNet is weak in extracting details, and “Man” is identified as “Shuo”. There are 41 samples for ”fruit” and 70 samples for “public opinion”, which have a similar number of samples and a similar morphology. The original network model incorrectly identifies “Guo” as “Yu”. The MS-ResNet model with multi-scale feature fusion allows the features to better capture text details and shallow contours and reduces the recognition of misspellings with similar morphological features.
4.4. Comparison Test with Classical Network Model Method
Each classical network has a wide range of applications in Chinese character recognition. In this paper, we compared the classical AlexNet, DenseNet121, GooLeNet, Vgg16, ResNet34 network models and the MS-ResNet model of a multi-scale feature fusion network. Among the classical networks, ResNet was the best in recognition performance, with a slightly longer running time than AlexNet but excellent accuracy performance. The improved MS-ResNet neural network model in this paper based on ResNet can effectively improve the recognition rate of bone stick text with an accuracy rate of 90.3%, which is higher than AlexNet, DenseNet121, GooLeNet, Vgg16, and ResNet34, with accuracy rates of 8.6%, 5.0%, 4.2%, 2.7%, 1.7%, respectively. At the same time, the algorithm in this paper also has a higher recall, accuracy, and F1 value, and the algorithm produced the lowest loss value.
This experiment shows that classical convolutional neural network algorithms have a lower recognition rate for bone stick text. The multi-scale feature fusion model enhances the underlying detail features of bone stick text, and the overall recognition effect on the data set of this paper is better than other neural network methods. The final recognition rate results of different methods on the data set are shown in
Table 2 below.
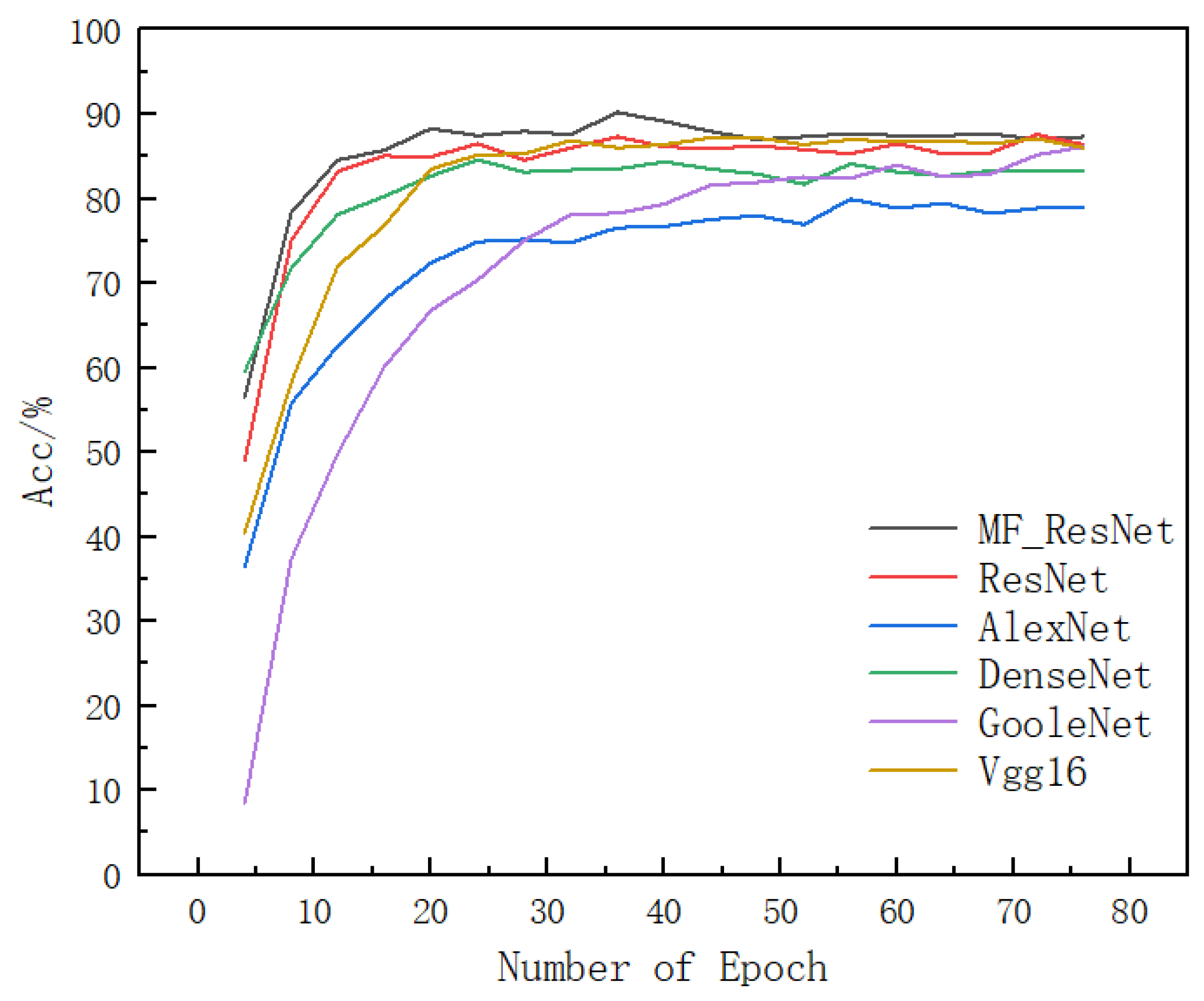
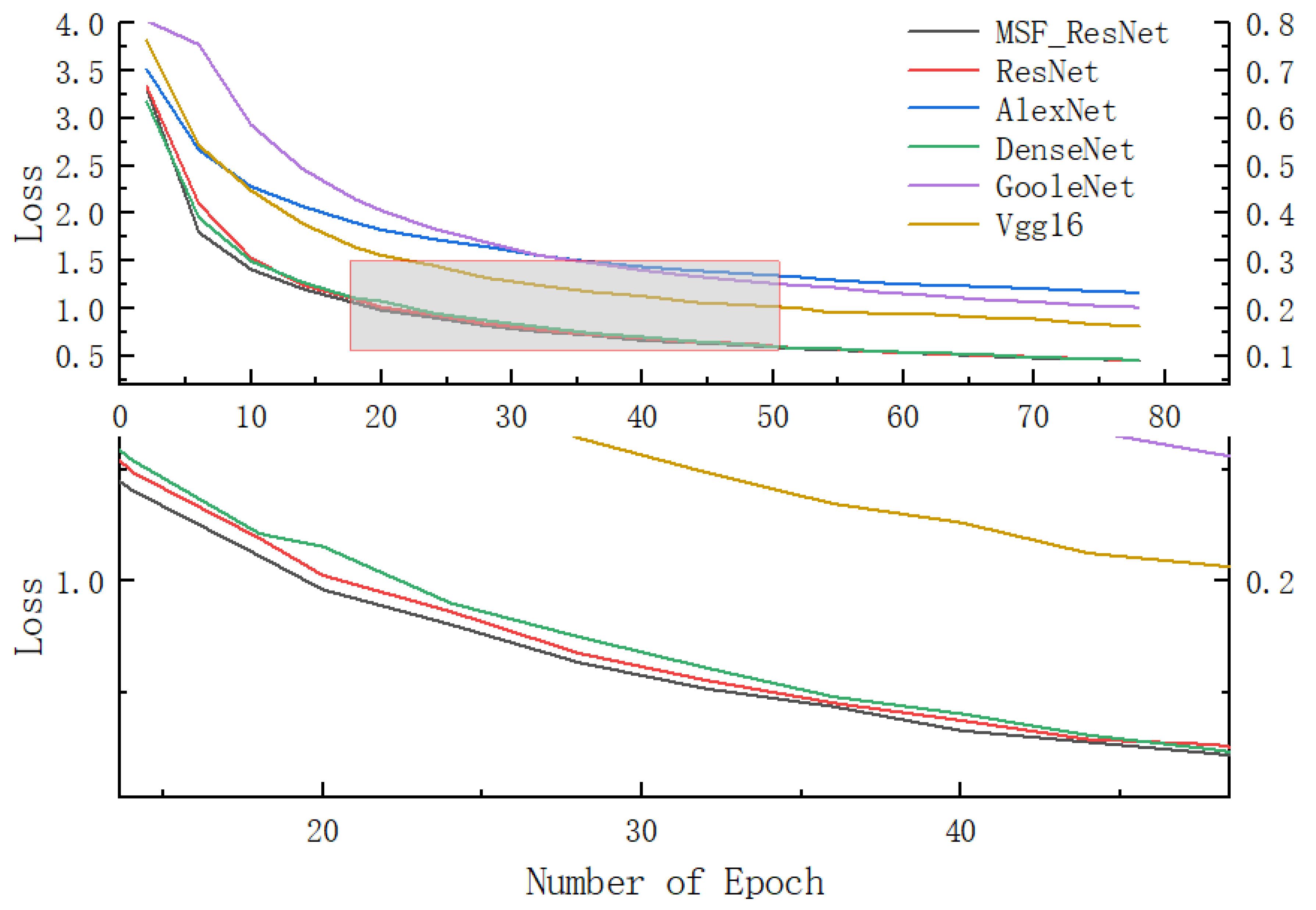
Figure 10 and
Figure 11 below show the test set’s accuracy curve and the training set’s loss value of the bone stick text dataset in the first 80 iterations of each algorithm. The figure shows that the MS-ResNet network model converges the fastest, reaches the highest accuracy rate at more than 30 rounds of training, and outperforms the other networks overall, achieving the highest accuracy rate of 90.3%. The data show that excessive network training while yielding smaller loss values, can lead to performance degradation due to the overtraining of the network. ResNet has the second-highest accuracy and convergence speed, AlexNet has the slowest convergence speed and the lowest recognition rate of 81%, and DenseNet has the fastest convergence speed. However, the recognition accuracy is not high, remaining at 84%, andthe recognition rate of Vgg16 is not much different from that of ResNet, but the model convergence speed is slower, and the training time is increased by three times.
4.5. Experimental Validation of the Effectiveness of the Focal Loss Function
In order to show that the average performance of the methods in this paper is meaningful, the experiments are deliberately divided into different test subsets, with the number of text images in each category in the test set being three. The F1 value is used as the evaluation criterion for each method. It can be seen that the MS-ResNet network model has a higher F1 value and performs optimally in different test subsets. The results are shown in
Table 3.
4.6. Experimental Validation of the Effectiveness of the Focal Loss Function
In order to verify the effectiveness of the improved multi-scale MS-ResNet model and the incorporation of the focal loss function for ablation experiments, the MSF-ResNet (multi-scale and focal loss ResNet) model combining the two achieved the highest recognition accuracy of 90.5%. Compared with the classical ResNet34 residual network model, the recall, precision, F1 score, and accuracy are improved by 4.9%, 1.1%, 3.2%, and 1.9%, respectively. Compared with the ResNet network model using only the focal loss function, the above indexes are improved by 3.4%, 1.0%, 2.4%, and 1.6%, respectively. Compared with the multi-scale network model without the focal loss function, the above indexes are improved by 0.8%, 0.4%, 0.7%, and 0.2%, respectively. The experimental results are shown in
Table 4.
The focus loss function can effectively balance the recognition rate of small sample categories, such as in
Figure 12, where the“Zhi” data sample size of 18 can be expanded to 90. However, for “Man” there are 166 training samples, and after the expansion there are 830. After adding the focal loss function, the category weight of small samples is increased, and the small samples that were incorrectly identified before can be correctly identified, strengthening the accuracy of small sample text recognition.
The MSF-ResNet model with multi-scale feature fusion using focal loss function enhances the feature extraction ability while strengthening the ability to balance small samples, enabling better bone stick text model recognition applications.
4.7. Comparison Experiments with Other Literature Methods
In order to evaluate the classification performance of the improved MS-ResNet network for bone stick text, references [
8,
12,
13] are used as the control group to compare the classification accuracy with the method of this paper. Their experimental results are shown in
Table 5.
From the table, it can be seen that the improved multi-scale ResNet in the literature [
13] has a low recognition accuracy on the bone stick data set and is not designed for the characteristics of the data set. The introduction of multi-scale also reduces the recognition accuracy of the bone stick text, and this method is only applicable to the classification of fewer categories. The ResNet with an improved network structure in the literature [
12] does not improve the recognition effect of the bone stick text, there are too many convolutional layers, and the recognition time is slow.The long convolutional bars in the improved oracle recognition method in the literature [
8] have no positive effect on bone stick text recognition and the network model is too simple. After the above comparison, the proposed multi-scale fusion bone stick text recognition method in this paper achieves good results in terms of accuracy and time effectiveness. The proposed method has more potential for applications in bone stick text recognition.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}