
Machine Learning and Sustainable Mobility: The Case of the University of Foggia (Italy)


Abstract
:1. Introduction
Literature Review
2. Materials and Methods
2.1. Dataset Description
- The distance in kilometers that the respondents claim to travel;
- The frequency at which the respondents go to their reference facility per weekly;
- Whether it is the hot or cold season, which affects both the number of weeks of activity and different modes of travel;
- The mode of transport used.
2.2. Data Preparation
2.3. Machine Learning Imputation
- Prediction of the type of car fuel (the variable [car power]) used for moving (precisely the different types of petrol or diesel fuel) based on the variables [age, sex, department, role, distance, day cold, means cold, locations]. The accuracy, after cross validation, was 79.10% with a standard deviation of 1.5% (, MAPE , precision , recall , F1 , F2 );
- Prediction of the car registration period (variable [car registration]) based on the variables [age, sex, role, department, distance, day cold, means cold, locations, car power (previously determined)]. The accuracy, after cross validation, was 75.70% with a standard deviation of 0.7% (, MAPE , precision , recall , F1 , F2 );
- Prediction of the means of transport used in the hot season (variable [means hot]) based on the variables [age, sex, role, department, distance, day cold, means cold, car registration, car power (previously determined)]. The accuracy, after cross validation, was 91.30% with a standard deviation of 1.7% (, MAPE , precision , recall , F1 , F2 );
- In the same way, prediction of the means of transport used in the cold season (variable [means cold]) based on the variables [age, sex, role, department, distance, day hot, means hot, car registration, car power (previously determined)]. The accuracy, after cross validation, was 90.70% with a standard deviation of 1.5% (, MAPE , precision , recall , F1 , F2 ).
2.4. Factor Analysis
3. Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Banister, D. The sustainable mobility paradigm. Transp. Policy 2008, 15, 73–80. [Google Scholar] [CrossRef]
- Jeon, C.; Amekudzi, A. Addressing sustainability in transportation systems: Definitions, indicators, and metrics. J. Infrastruct. Syst. 2005, 11, 31–50. [Google Scholar] [CrossRef]
- Weichenthal, S.; Farrell, W.; Goldberg, M.; Joseph, L.; Hatzopoulou, M. Characterizing the impact of traffic and the built environment on near-road ultrafine particle and black carbon concentrations. Environ. Res. 2014, 132, 305–310. [Google Scholar] [CrossRef] [PubMed]
- Lopez-Arboleda, E.; Sarmiento, A.; Cardenas, L. Systemic approach for integration of sustainability in evaluation of public policies for adoption of electric vehicles. Syst. Pract. Action Res. 2021, 34, 399–417. [Google Scholar] [CrossRef]
- Torre, R.; Corlu, C.; Faulin, J.; Onggo, B.; Juan, A. Simulation, Optimization, and Machine Learning in Sustainable Transportation Systems: Models and Applications. Sustainability 2021, 13, 1551. [Google Scholar] [CrossRef]
- Simons, D.; Clarys, P.; Bourdeaudhuij, I.; Geus, B.; Vandelanotte, C. Why do young adults choose different transport modes? Transp. Policy 2014, 36, 151–159. [Google Scholar] [CrossRef]
- Becker, H.; Ciari, F.; Axhausen, K. Comparing car-sharing schemes in Switzerland: User groups and usage patterns. TRansportation Res. Part A Policy Pract. 2017, 97, 17–29. [Google Scholar] [CrossRef]
- Chakhtoura, C.; Pojani, D. Indicator-based evaluation of sustainable transport plans: A framework for Paris and other large cities. Transp. Policy 2016, 50, 15–28. [Google Scholar] [CrossRef]
- Tafidis, P.; Sdoukopoulos, A.; Pitsiava-Latinopoulou, M. Sustainable urban mobility indicators: Policy versus practice in the case of Greek cities. Transp. Res. Procedia 2017, 24, 304–312. [Google Scholar] [CrossRef]
- Suchanek, M.; Szmelter-Jarosz, A. Environmental Aspects of Generation Y’s Sustainable Mobility. Sustainability 2019, 11, 3204. [Google Scholar] [CrossRef] [Green Version]
- Cappelletti, G.; Grilli, L.; Russo, C.; Santoro, D. Sustainable Mobility in Universities: The Case of the University of Foggia (Italy). Environments 2021, 8, 57. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, M.; Li, D. Bike-sharing or taxi? Modeling the choices of travel mode in Chicago using machine learning. J. Transp. Geogr. 2019, 79, 102479. [Google Scholar] [CrossRef]
- Basu, R.; Ferreira, J. Understanding household vehicle ownership in Singapore through a comparison of econometric and machine learning models. Transp. Res. Procedia 2020, 48, 1674–1693. [Google Scholar] [CrossRef]
- Yang, Y.; Heppenstall, A.; Turner, A.; Comber, A. Using graph structural information about flows to enhance short-term demand prediction in bike-sharing systems. Comput. Environ. Urban Syst. 2020, 83, 101521. [Google Scholar] [CrossRef]
- Tang, T.; Liu, R.; Choudhury, C. Incorporating weather conditions and travel history in estimating the alighting bus stops from smart card data. Sustain. Cities Soc. 2020, 53, 101927. [Google Scholar] [CrossRef]
- Migliore, M.; Burgio, A.; Giovanna, M. Parking pricing for a sustainable transport system. Transp. Res. Procedia 2014, 3, 403–412. [Google Scholar] [CrossRef]
- Liang, L.; Xu, M.; Grant-Muller, S.; Mussone, L. Household travel mode choice estimation with large-scale data – An empirical analysis based on mobility data in Milan. Int. J. Sustain. Transp. 2019, 15, 70–85. [Google Scholar] [CrossRef]
- Asensio, O.; Alvarez, K.; Dror, A.; Wenzel, E.; Hollauer, C.; Ha, S. Real-time data from mobile platforms to evaluate sustainable transportation infrastructure. Nat. Sustain. 2020, 3, 463–471. [Google Scholar] [CrossRef]
- Nandal, M.; Mor, N.; Sood, H. An Overview of Use of Artificial Neural Network in Sustainable Transport System. Comput. Methods Data Eng. 2020, 1227, 83–91. [Google Scholar]
- Hasan, U.; Whyte, A.; Jassmi, H. A Review of the Transformation of Road Transport Systems: Are We Ready for the Next Step in Artificially Intelligent Sustainable Transport? Appl. Syst. Innov. 2020, 3, 1. [Google Scholar] [CrossRef]
- Kaplan, H.; Tehrani, K.; Jamshidi, M. A Fault Diagnosis Design Based on Deep Learning Approach for Electric Vehicle Applications. Energies 2021, 14, 6599. [Google Scholar] [CrossRef]
- Ghamisi, P.; Li, H.; Jackisch, R.; Rasti, B.; Gloaguen, R. Remote Sensing and Deep Learning for Sustainable Mining. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience And Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 3739–3742. [Google Scholar]
- Delnevo, G.; Mirri, S.; Sole, M.; Giusto, D.; Girau, R. A deep learning approach to anthropogenic load assessment for sustainable coastal tourism. In Proceedings of the 2021 IEEE Globecom Workshops (GC Wkshps), Madrid, Spain, 7–11 December 2021; pp. 1–6. [Google Scholar]
- Adeodato, P.; Arnaud, A.; Vasconcelos, G.; Cunha, R.; Monteiro, D. MLP ensembles improve long term prediction accuracy over single networks. Int. J. Forecast. 2011, 27, 661–671. [Google Scholar] [CrossRef]
- Xiao, C.; Xia, W.; Jiang, J. Stock price forecast based on combined model of ARI-MA-LS-SVM. Neural Comput. Appl. 2020, 32, 5379–5388. [Google Scholar] [CrossRef]
- Zaccagnino, R.; Capo, C.; Guarino, A.; Lettieri, N.; Malandrino, D. Techno-regulation and intelligent safeguards. Multimed. Tools Appl. 2021, 80, 15803–15824. [Google Scholar] [CrossRef]
- Guarino, A.; Malrino, D.; Zaccagnino, R. An automatic mechanism to provide privacy awareness and control over unwittingly dissemination of online private information. Comput. Netw. 2022, 202, 108614. [Google Scholar] [CrossRef]
- Liu, H.; Tian, Y.; Wang, Y.; Pang, L.; Huang, T. Deep Relative Distance Learning: Tell the Difference between Similar Vehicles. In Proceedings of the 2016 IEEE Conference On Computer Vision And Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2167–2175. [Google Scholar]
- Jin, Z.; Yang, Y.; Liu, Y. Stock closing price prediction based on sentiment analysis and LSTM. Neural Comput. Appl. 2020, 32, 9713–9729. [Google Scholar] [CrossRef]
- Madow, W.; Nisselson, H.I.O.; Rubin, D. Incomplete Data in Sample Surveys 1, 2, and 3; Academic Press: New York, NY, USA, 1983. [Google Scholar]
- Rubin, D. Inference and missing data (with discussion). Biometrika. 1976, 63, 581–592. [Google Scholar] [CrossRef]
- Little, R.; Rubin, D. Statistical Analysis with Missing Data; Wiley: New York, NY, USA, 1987. [Google Scholar]
- Laird, N. Missing data in longitudinal studies. Stat. Med. 1988, 7, 305–315. [Google Scholar] [CrossRef]
- Ibrahim, J. Incomplete Data in Generalized Linear Models. Journals Am. Stat. Assoc. 1990, 85, 765–769. [Google Scholar] [CrossRef]
- Horton, N.; Laird, N. Maximum likelihood analysis of generalized linear models with missing covariates. Stat. Methods Med. Res. 1999, 8, 37–50. [Google Scholar] [CrossRef] [PubMed]
- Raghunathan, T.E.; Lepkowski, J.M.; Van Hoewyk, J.; Solenberger, P. A multivariate technique for multiply imputing missing values using a sequence of regression models. Surv. Methodol. 2001, 27, 85–95. [Google Scholar]
- Rubin, D. Multiple Imputation for Nonresponse in Surveys; Wiley: New York, NY, USA, 1987. [Google Scholar]
- van Buuren, S. Multiple imputation of discrete and continuous data by fully conditional specification. Stat. Methods Med. Res. 2007, 16, 219–242. [Google Scholar] [CrossRef] [PubMed]
- Horton, N.; Lipsitz, S. Multiple Imputation in Practice. Am. Stat. 2001, 55, 244–254. [Google Scholar] [CrossRef]
- Jerez, J.; Molina, I.; Garcia-Laencina, P.; Alba, E.; Ribelles, N.; Martin, M.; Franco, L. Missing data imputation using statistical and machine learning methods in a real breast cancer problem. Artif. Intell. Med. 2010, 50, 105–115. [Google Scholar] [CrossRef] [PubMed]
- García-Laencina, P.; Sancho-Gómez, J.L.; Figueiras-Vidal, A. Pattern classification with missing data: A review. Neural Comput. Appl. 2010, 19, 263–282. [Google Scholar] [CrossRef]
- Silva-Ramírez, E.; Pino-Mejías, R.; López-Coello, M. Single imputation with multilayer perceptron and multiple imputation combining multilayer perceptron and k-nearest neighbours for monotone patterns. Appl. Soft Comput. 2015, 29, 65–74. [Google Scholar] [CrossRef]
- Templeton, G.; Kang, M.; Tahmasbi, N. Regression imputation optimizing sample size and emulation: Demonstrations and comparisons to prominent methods. Decis. Support Syst. 2021, 151, 113624. [Google Scholar] [CrossRef]
- Lin, W.; Tsai, C.; Zhong, J. Deep learning for missing value imputation of continuous data and the effect of data discretization. Knowl.-Based Syst. 2022, 239, 108079. [Google Scholar] [CrossRef]
- Curran, M. Life Cycle Assessment Handbook: A Guide for Environmentally Sustainable Products; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2012. [Google Scholar]
- JRC-IES International Reference Life Cycle Data System (ILCD) Handbook—General Guide for Life Cycle Assessment—Detailed Guidance; Publications Office of the European Union: Luxembourg, 2010.
- EC European Commission. Guidance for the Development of Product Environmental Footprint Category Rules (PEFCRs); version 6.3; Environmental Footprint Guidance document; European Commission: Brussels, Belgium, 2018.



{kind=link}
{kind=link}
| Feature | Description |
|---|---|
| Sex | Sex of respondents |
| Age | Age of respondents |
| Role | Role within the university |
| Department | Respondent department |
| Distance | Kilometers covered by respondents (round trip) |
| Min | Time taken to reach the department |
| Day hot | Number of days (hot season) that the respondent goes to university |
| Day cold | Number of days (cold season) that the respondent goes to university. |
| Means cold | Means of transport (cold season) used to get to the university |
| Means hot | Means of transport (hot season) used to get to the university |
| Car power | Power supply of the car (if it has been chosen as a means of transport) |
| Car registration | Year of registration of the car |
| Passengers | Number of passengers carried during the car journey |
| Locations | Moving to other university locations (other than your own department) |
| First choice rent | First choice alternative solutions for clean mobility |
| Second choice rent | Second choice alternative solutions for clean mobility |
| Third choice rent | Third choice alternative solutions for clean mobility |
| Fourth choice rent | Fourth choice alternative solutions for clean mobility |
| Lunch | Number of times the respondent has lunch at the university |
| Type lunch | Type of lunch eaten at the university (brought from home or purchased) |
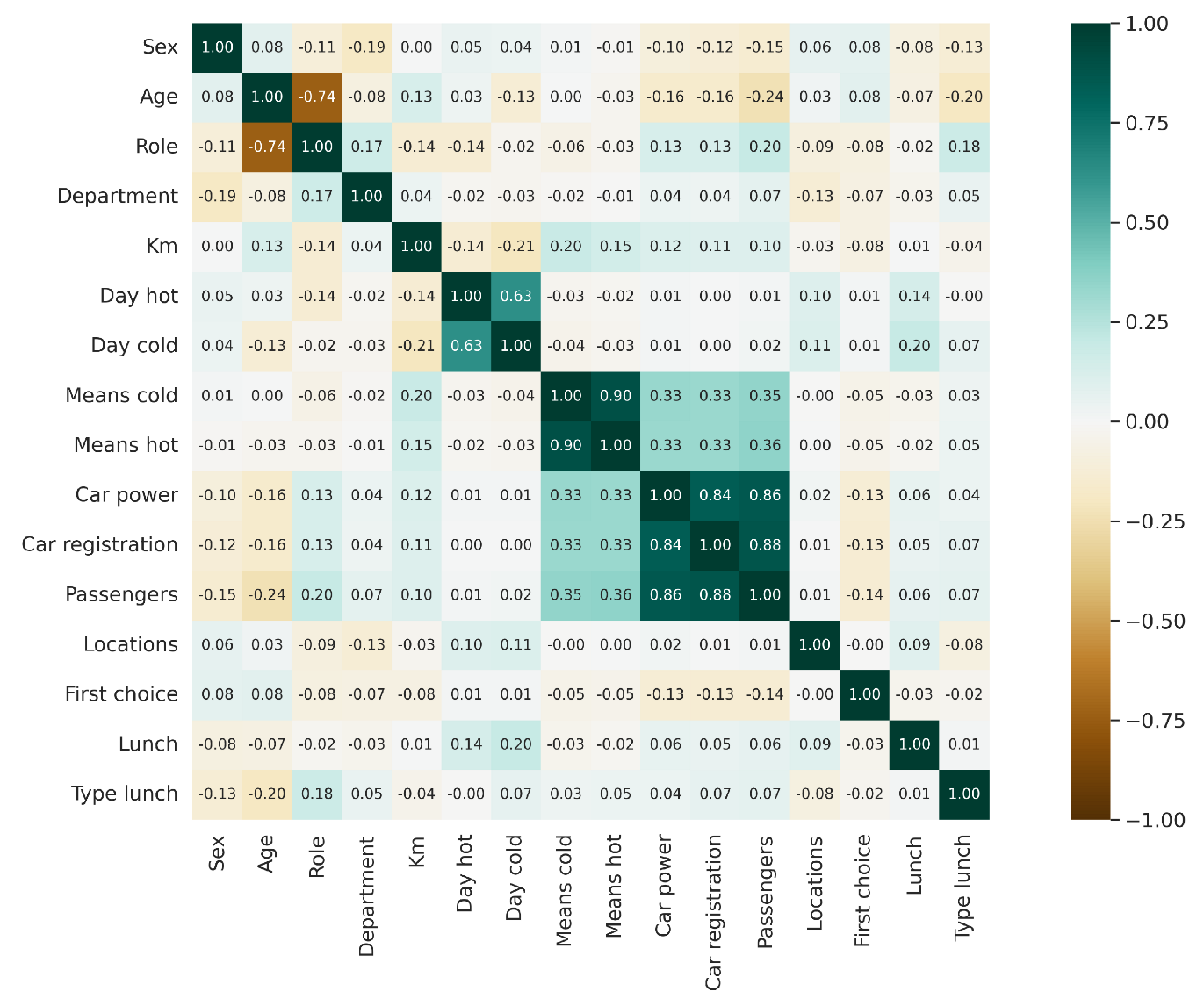
| Sex | Age | Role | Dept | Km | Day Hot | Day Cold | Means Cold | Means Hot | Car Power | Car reg. | Passengers | Locations | First Choice | Lunch | Type Lunch | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sex | 0 | 0 | 0 | 0 | 0.875 | 0.0035 | 0.0162 | 0.5056 | 0.4761 | 0 | 0 | 0 | 0.0004 | 0 | 0 | 0 |
| Age | 0 | 0 | 0 | 0 | 0 | 0.0632 | 0 | 0.9905 | 0.0925 | 0 | 0 | 0 | 0.1571 | 0 | 0.0001 | 0 |
| Role | 0 | 0 | 0 | 0 | 0 | 0 | 0.1954 | 0.0014 | 0.1465 | 0 | 0 | 0 | 0 | 0 | 0.2641 | 0 |
| Dept | 0 | 0 | 0 | 0 | 0.0176 | 0.3117 | 0.0907 | 0.397 | 0.6989 | 0.0239 | 0.0543 | 0.0001 | 0 | 0 | 0.0631 | 0.005 |
| Km | 0.875 | 0 | 0 | 0.0176 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.096 | 0 | 0.6761 | 0.0168 |
| Day hot | 0.0035 | 0.0632 | 0 | 0.3117 | 0 | 0 | 0 | 0.1269 | 0.3498 | 0.4339 | 0.7868 | 0.6469 | 0 | 0.5534 | 0 | 0.9799 |
| Day cold | 0.0162 | 0 | 0.1954 | 0.0907 | 0 | 0 | 0 | 0.0195 | 0.1495 | 0.6361 | 0.8489 | 0.241 | 0 | 0.5256 | 0 | 0.0001 |
| Means cold | 0.5056 | 0.9905 | 0.0014 | 0.397 | 0 | 0.1269 | 0.0195 | 0 | 0 | 0 | 0 | 0 | 0.8642 | 0.0058 | 0.0589 | 0.0554 |
| Means hot | 0.4761 | 0.0925 | 0.1465 | 0.6989 | 0 | 0.3498 | 0.1495 | 0 | 0 | 0 | 0 | 0 | 0.874 | 0.0135 | 0.261 | 0.0121 |
| Car power | 0 | 0 | 0 | 0.0239 | 0 | 0.4339 | 0.6361 | 0 | 0 | 0 | 0 | 0 | 0.3192 | 0 | 0.0013 | 0.0288 |
| Car registration | 0 | 0 | 0 | 0.0543 | 0 | 0.7868 | 0.8489 | 0 | 0 | 0 | 0 | 0 | 0.6767 | 0 | 0.0049 | 0.0002 |
| Passengers | 0 | 0 | 0 | 0.0001 | 0 | 0.6469 | 0.241 | 0 | 0 | 0 | 0 | 0 | 0.4477 | 0 | 0.0005 | 0 |
| Locations | 0.0004 | 0.1571 | 0 | 0 | 0.096 | 0 | 0 | 0.8642 | 0.874 | 0.3192 | 0.6767 | 0.4477 | 0 | 0.7958 | 0 | 0 |
| First choice | 0 | 0 | 0 | 0 | 0 | 0.5534 | 0.5256 | 0.0058 | 0.0135 | 0 | 0 | 0 | 0.7958 | 0 | 0.0628 | 0.1915 |
| Lunch | 0 | 0.0001 | 0.2641 | 0.0631 | 0.6761 | 0 | 0 | 0.0589 | 0.261 | 0.0013 | 0.0049 | 0.0005 | 0 | 0.0628 | 0 | 0.5154 |
| Type lunch | 0 | 0 | 0 | 0.005 | 0.0168 | 0.9799 | 0.0001 | 0.0554 | 0.0121 | 0.0288 | 0.0002 | 0 | 0 | 0.1915 | 0.5154 | 0 |
| Factor | ||||||
|---|---|---|---|---|---|---|
| Feature | 1 | 2 | 3 | 4 | 5 | 6 |
| Age | −0.015 | 0.006 | −0.020 | 0.983 | 0.069 | −0.005 |
| Distance | 0.066 | 0.109 | −0.129 | −0.094 | 0.599 | −0.026 |
| Day hot | 0.004 | −0.009 | 0.861 | 0.057 | −0.044 | 0.149 |
| Day cold | 0.001 | −0.007 | 0.674 | −0.102 | −0.168 | 0.293 |
| Means cold | 0.195 | 0.957 | −0.009 | 0.014 | 0.122 | −0.033 |
| Means hot | 0.207 | 0.892 | −0.007 | 0.009 | 0.063 | −0.009 |
| Car power | 0.890 | 0.156 | 0.011 | −0.033 | 0.076 | 0.039 |
| Car registration | 0.912 | 0.149 | 0.004 | −0.032 | 0.059 | 0.022 |
| Passengers | 0.928 | 0.175 | 0.010 | −0.107 | 0.055 | 0.040 |
| Locations | 0.010 | 0.005 | 0.086 | 0.032 | −0.030 | 0.177 |
| First choice | −0.130 | −0.011 | 0.010 | 0.069 | −0.122 | −0.036 |
| Lunch | 0.042 | −0.032 | 0.085 | −0.066 | 0.064 | 0.482 |
| Feature | Age | Distance | Day Hot | Day Cold | Means c. | Means h. | Car Power | Car Regis. | Passengers | Locations | First c. | Lunch |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Communality | 0.99 | 0.40 | 0.77 | 0.58 | 0.97 | 0.84 | 0.82 | 0.86 | 0.90 | 0.04 | 0.03 | 0.25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cappelletti, G.M.; Grilli, L.; Russo, C.; Santoro, D. Machine Learning and Sustainable Mobility: The Case of the University of Foggia (Italy). Appl. Sci. 2022, 12, 8774. https://doi.org/10.3390/app12178774
Cappelletti GM, Grilli L, Russo C, Santoro D. Machine Learning and Sustainable Mobility: The Case of the University of Foggia (Italy). Applied Sciences. 2022; 12(17):8774. https://doi.org/10.3390/app12178774
Chicago/Turabian StyleCappelletti, Giulio Mario, Luca Grilli, Carlo Russo, and Domenico Santoro. 2022. "Machine Learning and Sustainable Mobility: The Case of the University of Foggia (Italy)" Applied Sciences 12, no. 17: 8774. https://doi.org/10.3390/app12178774