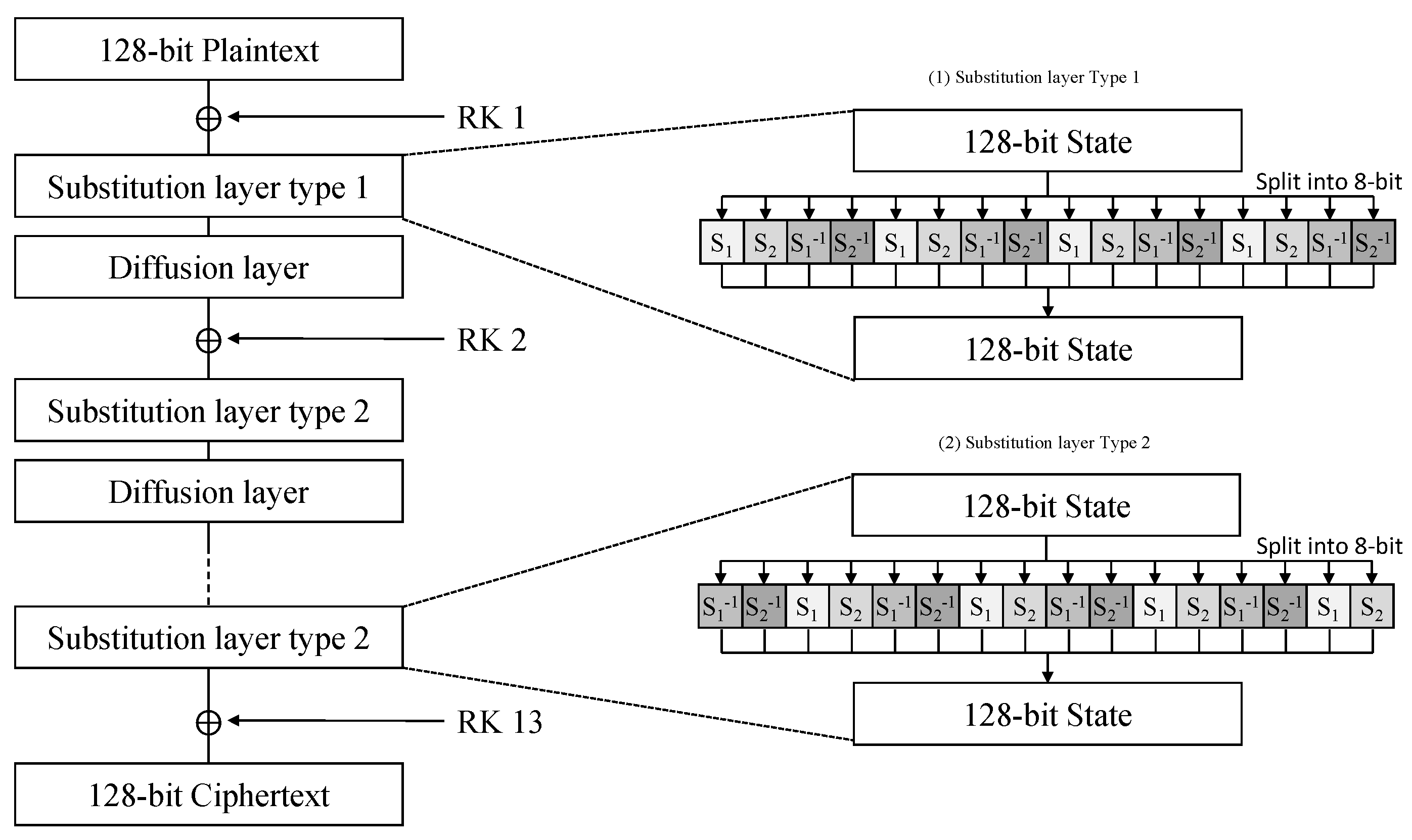
4.1. Evaluation on ARMv8 Implementation
In this section, we show the performance evaluation of the ARIA block cipher on ARMv8 architectures. The difference in key length is only the number of rounds, so we measured performance based on 128-bit key length. Performance is measured on a MacBook Pro 13 with the Apple M1, one of the latest ARMv8 processors. We used the Xcode framework, set the optimization option to -Os, and measured the performance. Since there are no existing studies on ARIA implementations for ARMv8 architectures, comparative analysis is performed with reference implementation. In addition, although the target processor is different, the performance of the previous study was also included for comparison. This can compare performance differences due to differences in hardware. In our works, CPB (cycle per byte) is calculated and analyzed using the following formula:
After running the encryption function 10,000,000 times, it is counted as the operating frequency (3.2 Ghz) and input bytes. Performance results are shown in
Table 2. Existing studies also show the performance results of the encryption function.
The performance difference from previous studies clearly shows the large difference due to the difference in processors. Compared to the reference C implementation, which is not an assembly-optimized implementation, the difference is about 60×. This means that hardware differences lead to large performance differences.
In 4-plaintext of our implementation, the performance was 1.73 cpb, which was 2.76× higher than that of reference implementation. The 16-plaintext showed a performance of 0.57 cpb, and 8.73× improved performance compared to reference implementation. It also showed 3.04× better performance compared to 4-plaintext. The result shows that the highly optimized ARIA block cipher in a parallel way can achieve much higher throughput than that of sequential implementation. In addition, the same ARMv8 architecture was used, but the effect of the operating frequency was investigated by measuring the performance in an environment with different operating frequencies. Performance was measured on an Apple IPad Air (3rd) with an A12 Bionic chip. The operating frequency speed of Apple M1 is 3.2 Ghz, whereas in A12 it is 2.49 GHz. As a result, it shows 1.6× and 1.25× higher performance in M1 with high operating frequency. From this, it can be seen that the higher the operating frequency, the better the performance.
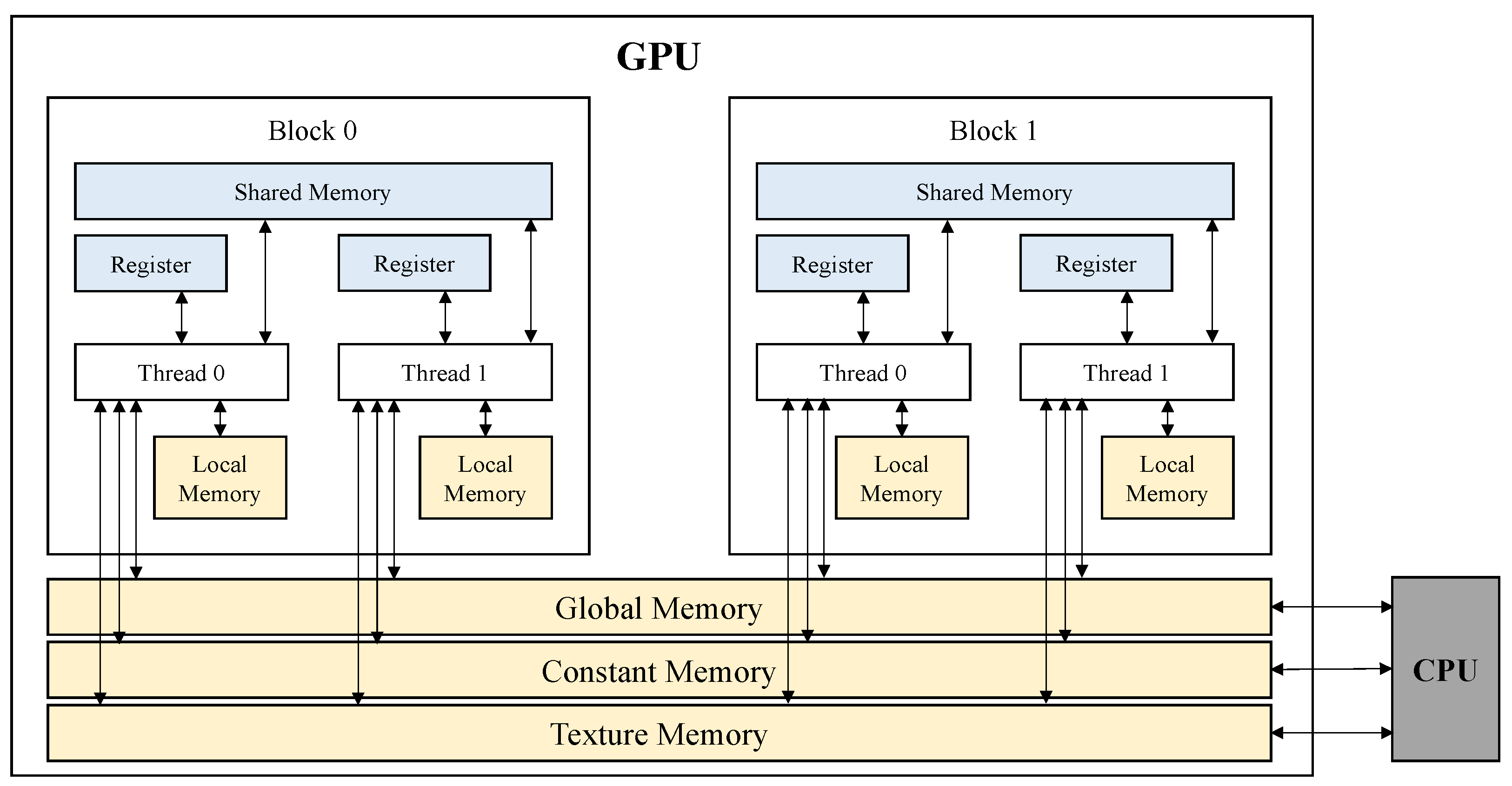
4.2. Evaluation on GPU Implementation
In this section, we show the performance of ARIA block cipher implementations depending on various types of memory in the GPU. As with the ARMv8 performance evaluation, the difference in key length is only the number of rounds, so we measured performance based on 128-bit key length. Factors that affect GPU implementation performance include number of threads and number of blocks. Performance measurements were taken while correcting for these factors. The Nvidia GeForce GTX 3060 laptop GPU was used for the testing. It was implemented in the Visual Studio, and the CUDA 11.8 Runtime template was used. Performance is presented in several tables for more convenient performance comparison. The size of the input data for each implementation is (number of blocks × number of threads × block size). That is, if the number of blocks is 1024 and the number of threads is 32, the size of the input data is 0.5 MB (1024 × 32 × 16). The input data are used as a random value. Our goal is to find the optimal implementation environment (e.g., type of memory, number of threads, number of blocks). The Roundkey was used by storing it in the GPU’s constant memory. When all threads refer to the same memory, the Roundkey is stored in constant memory because it is better for performance to use constant memory.
First, for performance comparison according to memory types, the number of blocks was fixed to 1024 × 32 and the number of threads to 256 to show the implementation performance according to the type of memory. Shared[256] is an implementation of Listing 2 that uses Sbox tables copied to shared memory. Shared[4][256] and Shared[256][4] are an implementation of Listing 3 that uses Sbox tables copied to shared memory. The performance results are shown in
Table 3.
As shown in
Table 1, it can be seen that the use of shared memory improves computation and memory throughput and, as a result, shortens the kernel operation time. In terms of kernel execution time, performance is improved by 1.08× using shared memory. However, we found that implementations of extending Sbox tables to avoid bank conflicts performed worse than using global memory. While the size of the bank is 32, it seems that it cannot prevent a complete bank collision, because only four copies were copied. To analyze this in more detail, we compare the performance according to the number of table copies. We use a fixed number of blocks and threads as above (block: 1024 × 32, thread: 256). The performance results are shown in
Table 4.
Due to the size limit of shared memory, up to 12 tables can be copied. As a result of the measurement, it was confirmed that the higher the number of copies of the table, the lower the performance. When performing front table expansions (), the increased number of copies slowed down memory throughput, resulting in poor performance. Increasing the number of copies only increases the number of copies of the table from global memory to shared memory and degrades performance because the bank conflicts cannot be resolved. When performing back table expansions (), the increased number of copies slowed down compute throughput, resulting in poor performance. An increase in bank collisions is considered to be the cause of a decrease in the computational throughput. As a result, it is inefficient to apply this technique when it is impossible to copy as much as the bank size.
Next, we checked the performance comparison according to the number of blocks, which is one of the factors affecting performance. In this case, we fixed only the number of threads (256) and increased the number of blocks during the measurement. We did not compare the performance of table extension implementations, we only compared the performance of global and shared memory implementations, because we saw above that table expansion is inefficient. The performance results are shown in
Table 5.
In this case, when the same memory type is used, the kernel operation time (duration) cannot be compared because the input data increases as the number of blocks increases. However, the kernel operation time is also included for comparison according to memory types. In fact, increasing the number of blocks did not affect performance, but here we can see that the number of blocks does not affect performance (in implementation of ARIA block cipher). Additionally, we can reaffirm that using shared memory can help improve performance.
Finally, we compare the performance according to the number of threads. The number of blocks is fixed (1024 × 32) and performance is measured by increasing the number of threads. We compare the performance of global and shared memory implementations, such as comparing performance by number of blocks. The performance results are shown in
Table 6.
It can be seen that the lower the number of threads (32), the better the performance is to use global memory. This is because the process of copying from global to shared memory is higher than the improvements achieved using shared memory. The greater the number of threads, the greater the performance difference that can be achieved using shared memory. In the performance of the shared memory implementation, it can be seen that as the number of threads increases, the performance becomes better than that of global memory, but the computational throughput decreases. This is because as the number of threads increases, more bank conflicts occur.
Table 7,
Table 8 and
Table 9 show the overall performance of global, shared memory, and extended Sbox using shared memory implementations. Overall, depending on the implementation, it is more efficient to use global memory in implementations with fewer than 32 threads, and more efficient to use shared memory when using more than 32 threads. Increasing the number of blocks can improve memory throughput, but does not significantly improve performance as compute throughput cannot support it. Therefore, a large number of blocks is not always efficient, so it is recommended to use an appropriate number of blocks depending on the size of the data. Memory throughput has always been higher than computational throughput. Therefore, for the number of threads, it is recommended to use the number of threads 64, 128 because the compute throughput is highest when using shared memory.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}