1. Introduction
As shipbuilding technology continues to improve, ships are getting bigger and faster, and the volume of seaborne trade worldwide increases every year [
1]. South Korea, surrounded by the sea on three sides, has developed fisheries and marine industries, while 99.7% of imports and exports are transported by ship [
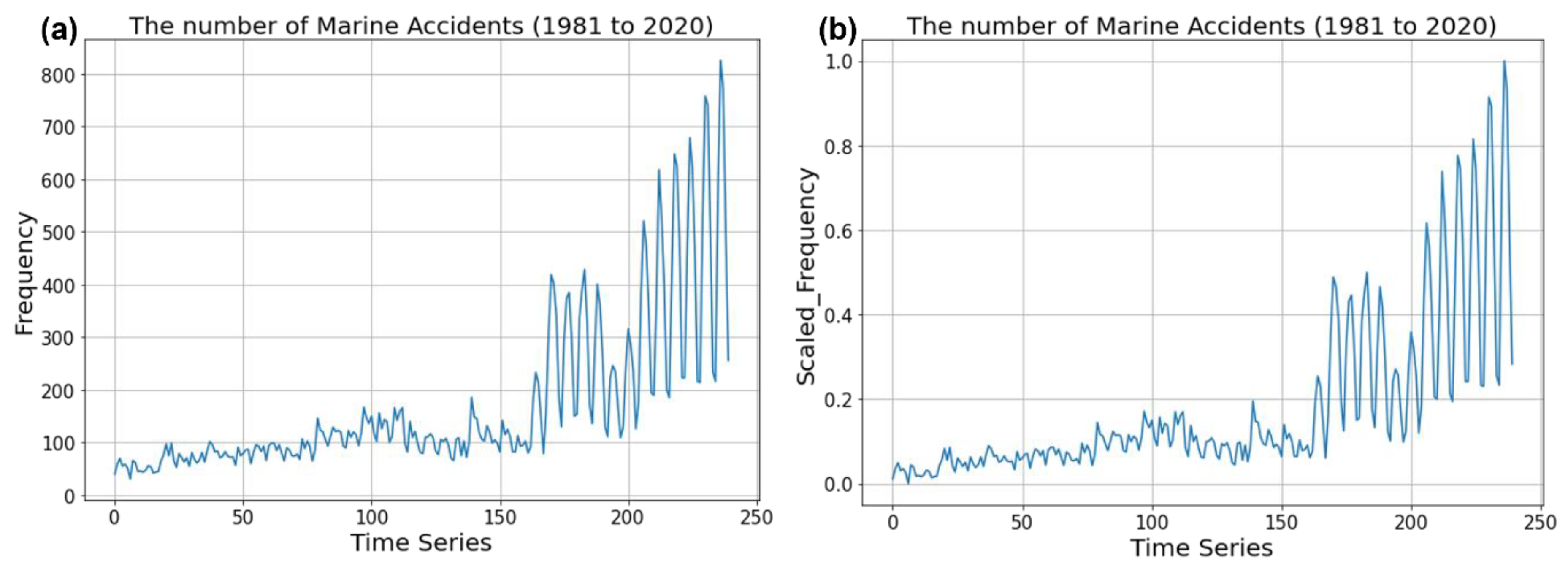
2]. It is also strategically located in the center of Northeast Asia, serving as an important logistics hub. Due to geographical influences, however, port areas and coastal waters used by ships for safe passage are limited. As the size of ships gets larger and the volume of ships passing through limited waterways increases, the risk of marine accidents increases. In South Korea, the number of marine accidents has increased by 1080.8%, from 335 in 1981 to 3156 in 2020, and the social costs are enormous [
3].
The Korean coast guard responds to marine accidents by using surveillance means such as coast guard ships, aircraft, and Vessel Traffic Service (VTS). However, monitoring per ship is so broad that it is more focused on follow-up than on preventing accidents [
4]. The VTS can help to improve maritime safety by providing safety information to ships, but this also has some limitations. It is imperative to predict the risk of marine accidents in advance to prevent or reduce marine accidents by means limited to such a wide range of areas. If the risk of marine accidents can be predicted in advance, then limited equipment and human resources can be deployed effectively. Thus, forecasting the risk of marine accidents is crucial for preventing or reducing marine accidents using limited surveillance capabilities.
Based on marine accident statistics data, previous studies used the Markov model [
5] or ANOVA analysis [
6] to classify the type of marine accidents, and Lee et al. [
7] identified factors affecting accidents of ships controlled by VTS using a regression model. Wang et al. [
8] evaluated the safety of maritime transport utilizing Markov chains, Hänninen [
9] examined the benefits and disadvantages of using Bayesian networks for predicting marine accidents, and Lim [
10] analyzed seafarers’ behavioral errors using Hidden Markov models. As such, a variety of statistical and probability-based methods have been investigated to prevent marine accidents.
Recently, research on deep learning has been conducted in many fields with an understanding of artificial intelligence (AI). Oh et al. [
11] developed a regression model, an artificial neural network (ANN), and a structural equation model (SEM) to predict the frequency of traffic accidents, respectively. Rye et al. [
12] constructed a traffic accident prediction model using deep learning technology and proposed that a deep learning approach is helpful for traffic accident-related research by comparing the results with traditional analysis methods. Ren et al. [
13] analyzed that traffic flow is the most critical factor in traffic accidents using the deep learning model. Pan et al. [
14] constructed crash modeling using Deep Brief Networks (DBN). They demonstrated that deep learning techniques are excellent as an alternative to predicting the frequency of traffic accidents using real-world crash datasets. In addition, Benoit [
15] developed a long-short term memory (LSTM) neural network to predict and visualize traffic accidents in Switzerland, and Sameen and Pradhan [
16] analyzed that the recurrent neural network (RNN) method is advantageous in predicting the severity of traffic accidents compared to conventional NNs using traffic accident records in Malaysia for six years. Roh and Bae [
17] proposed a LSTM model to forecast a traffic accident occurrence pattern. Many studies have used deep learning to predict traffic accidents and demonstrate that the RNN model is optimized for predicting time series data compared to other algorithms. However, most of the studies focused on the comparative analysis of the models to increase the predictive accuracy of traffic accidents on land, and studies predicting the occurrence of maritime traffic accidents were found to be insufficient. Only a few studies have been investigated for the development of marine traffic accident prediction models with machine learning techniques. Atak and Arslanoğlu [
18] developed a machine learning-based model for predicting marine port accidents focused on container terminals. Kim et al. [
19] predicted accidents at Korean container terminals using machine learning techniques. However, there were no relevant studies using deep learning techniques. To the best of our knowledge, therefore, our study represents the first attempt to use a deep learning approach to forecast marine accidents.
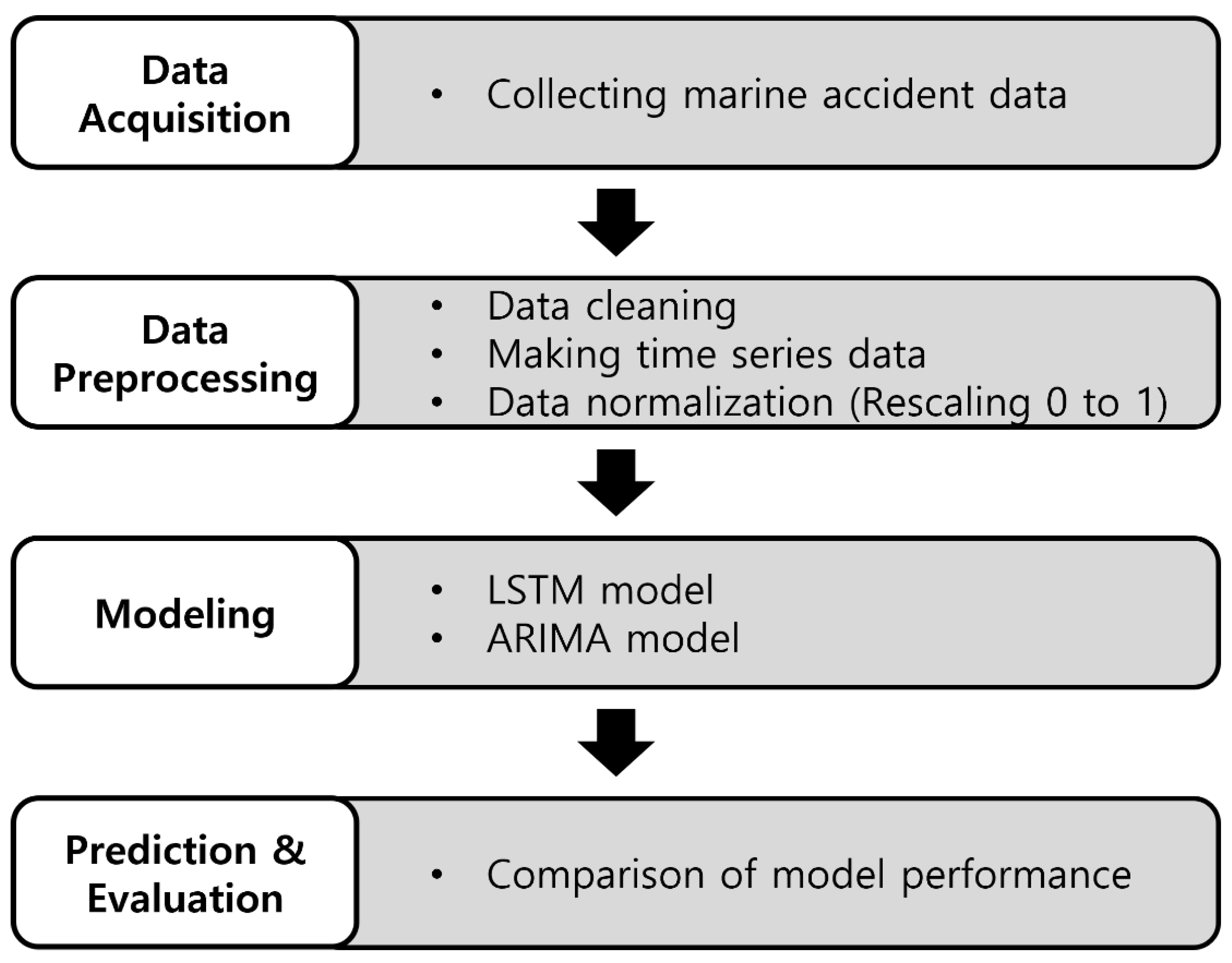
The purpose of this study was to build a model that can predict the frequency of marine accidents using LSTM by utilizing statistical data on marine accidents as a fundamental study to predict the risk of marine accidents. We also aimed to find the best LSTM models to forecast marine accidents by navigators’ watch duty time with different setups and to see if the LSTM models outperform the traditional statistical analysis methods. In order to achieve our objectives, we built four different LSTM models and compared the proposed LSTM models with an autoregressive integrated moving average (ARIMA) model, which is one of the commonly used models for time series forecasting. Through this LSTM-based prediction model, the risk of future marine accidents could be anticipated in advance using certified marine accident statistics data, and a monitoring system could be effectively established.
The remainder of the paper is organized as follows: We first describe how the data were collected and preprocessed for this study. Next, the prediction model and the research methodology utilized in this study are presented, followed by the results. Lastly, the findings and implications of this study are discussed.
4. Discussion
Many researchers studied the prediction of the number of marine accidents, but no research was conducted on the prediction of marine accidents according to the navigator’s duty time. In addition, existing studies related to predicting the number of marine accidents have been conducted via different methods. However, studies related to deep learning, such as LSTM, have been relatively insufficient. To the best of our knowledge, this was the first attempted study to predict the number of marine accidents using LSTM. In this study, marine accidents that occurred in Korea over the past 39 years from 1981 to 2019 were classified by navigator’s duty time, and the number of marine accidents by duty time in 2020 was predicted through the LSTM model. The prediction results were compared with the actual number of marine accidents in 2020.
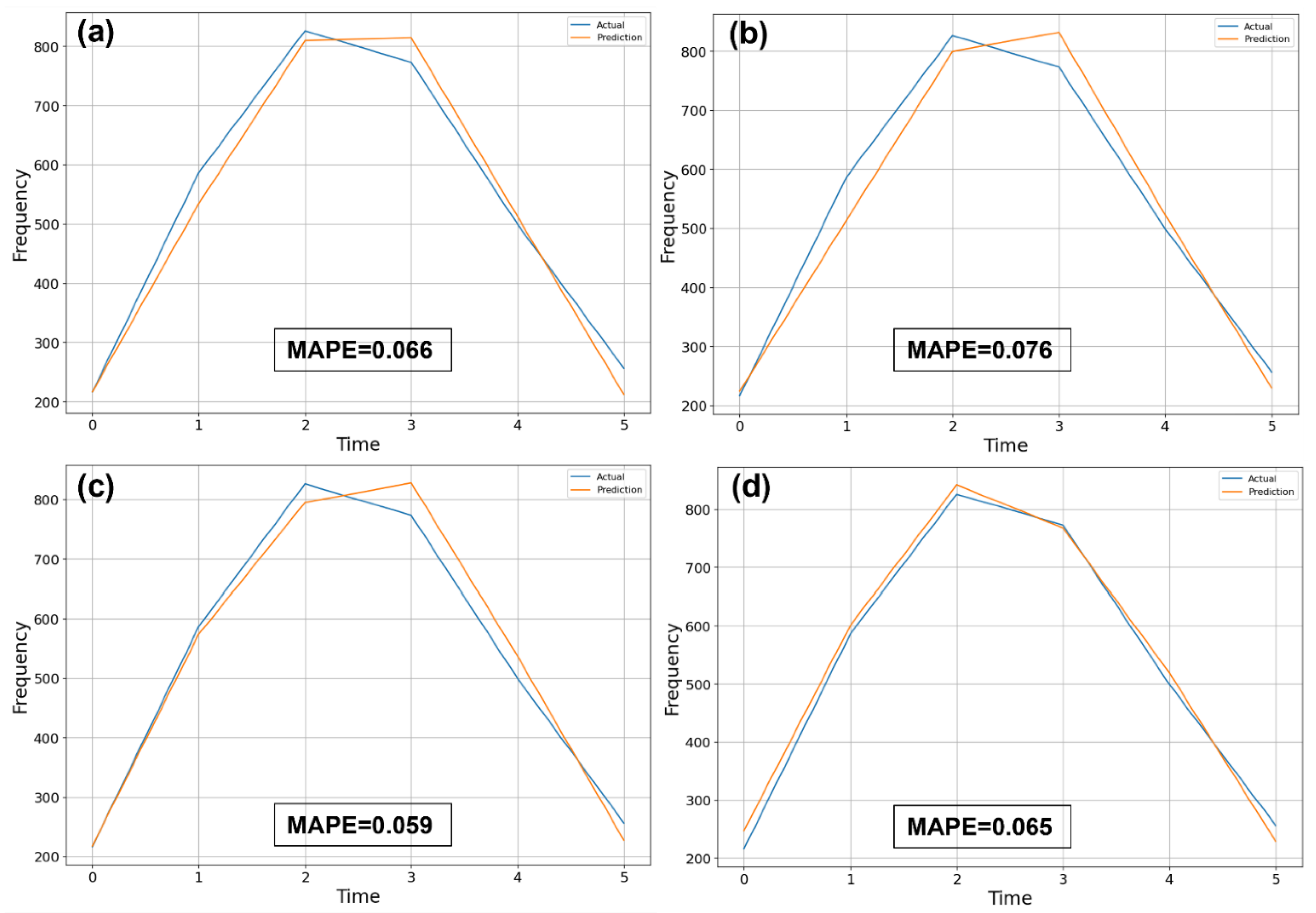
This study showed that the number of marine accidents by the navigator’s watch duty time can be predicted using LSTM through time series data. As a result of comparing the number of marine accidents predicted using the LSTM model with the actual number of marine accidents by duty time in 2020, the proposed LSTM models performed reliably. The MAPEs for all four LSTM models were less than 0.1, which means that the accuracies of the proposed LSTMs were greater than 90%. The best LSTM model was LSTM3, with the smallest MAPE, as shown in
Table 7. We found that two LSTM layers (i.e., LSTM3 (MAPE = 0.059) and lSTM4 (MAPE = 0.065)) performed better than a single LSTM layer (i.e., LSTM1 (MAPE = 0.066) and LSTM2 (MAPE = 0.076)). In terms of the effect of hidden units, we noticed that 64 hidden units were better than 128 or 256 hidden units. In addition, the best batch size for each model varied from 18, 24, 30, and 6, respectively. These results can help us guide in the building of a more complex LSTM network structure for our future studies.
To explore the advantage of the LSTM models, we also implemented an ARIMA model, which is a traditional statistical algorithm for time series forecasts. We also compared the performance results of the LSTMs with the ARIMA model. It was shown that all LSTMs outperformed the ARIMA model (MAPE = 0.089). This result proved the superiority of LSTM compared to the ARIMA. Thus, we can say that the LSTM is better than the ARIMA at predicting the frequency of marine accidents by watch duty hours.
Nevertheless, this study still has several limitations. First, although we tuned several hyperparameters, there are more hyperparameters that could significantly affect the performance of the LSTM models. Also, the application of various deep learning algorithms in marine accident prediction models other than LSTM is required. However, since this study is the first attempt to make marine accident predictions using deep learning technology, it can be a guideline when making a complex model for forecasting marine accidents in the future. In addition, this study only used data on the frequency of marine accidents, as this is a univariate time series forecasting study which only uses the previous values of the time series to predict its future values. No other factors were included in this study. Regardless, it is necessary to expand the prediction scope of marine accidents by using time series data with different variables such as weather, human errors, traffic density, and mechanical defects that may be involved in marine accidents. Since this study is a leading study in predicting accidents using deep learning, we believe that it can be a stepping-stone to the study of complex accident prediction models in the future. Lastly, predicting accident frequency does not help prevent it directly. However, by predicting the number of accidents by watch duty time, the pattern of accidents can be learned, and, in fact, most of the accidents occurred during the daytime. This might be because most fishing boats returned in the morning from night fishing and most of the cruise ships and passenger ships that come and go between land and islands were operated during the daytime. Furthermore, many accidents occurred during the watch time of junior officers. On the basic premise that the frequency of marine accidents changes according to the navigator’s experience, it is possible to establish customized accident prevention measures by time by identifying whether the actual marine accidents are concentrated during the junior officer’s duty time. Thus, it is also necessary to reflect the trend of accidents according to these duty hours in the marine accident reduction policy. Using the results, we will be able to help prevent accidents in advance if we make VTS or coast guard officers pay more attention during the time when accidents occur the most. Further study is needed to address these limitations in the future.
5. Conclusions
Marine accidents cause human, material, and environmental damage. In order to minimize the damage caused by the occurrence of an accident, it is necessary to respond to the accident as soon as possible. In other words, if it is possible to predict the approximate time when many marine accidents occur, the department in charge of responding to marine accidents will be able to prevent the spread of additional damage caused by marine accidents by preparing in advance. In this study, we developed the prediction model of the frequency of marine accidents using the LSTM. The proposed LSTM models reliably predicted the number of marine accidents compared to another traditional statistical method, the ARIMA model.
In terms of academic implications, this study could be used for the basis of deep learning approaches for marine accident prediction. In terms of industrial implications, this study could help develop technologies for marine accident prediction and can be used to prevent accidents in industries engaged in maritime safety, such as VTS or the coast guard. The results of this study are expected to be used as basic data to prevent the spread of additional damage by predicting the number of marine accidents by duty time of the navigator and responding early in the event of marine accidents. Although the number of marine accidents can be predicted, it is still insufficient to utilize it to prevent marine accidents in advance. Therefore, future studies will predict marine accidents and propose a model to prevent marine accidents in advance based on the results of this study.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}