
A Survey of Deep Learning for Electronic Health Records


Abstract
:1. Introduction
2. Evolution of EHR
3. EHR Datasets
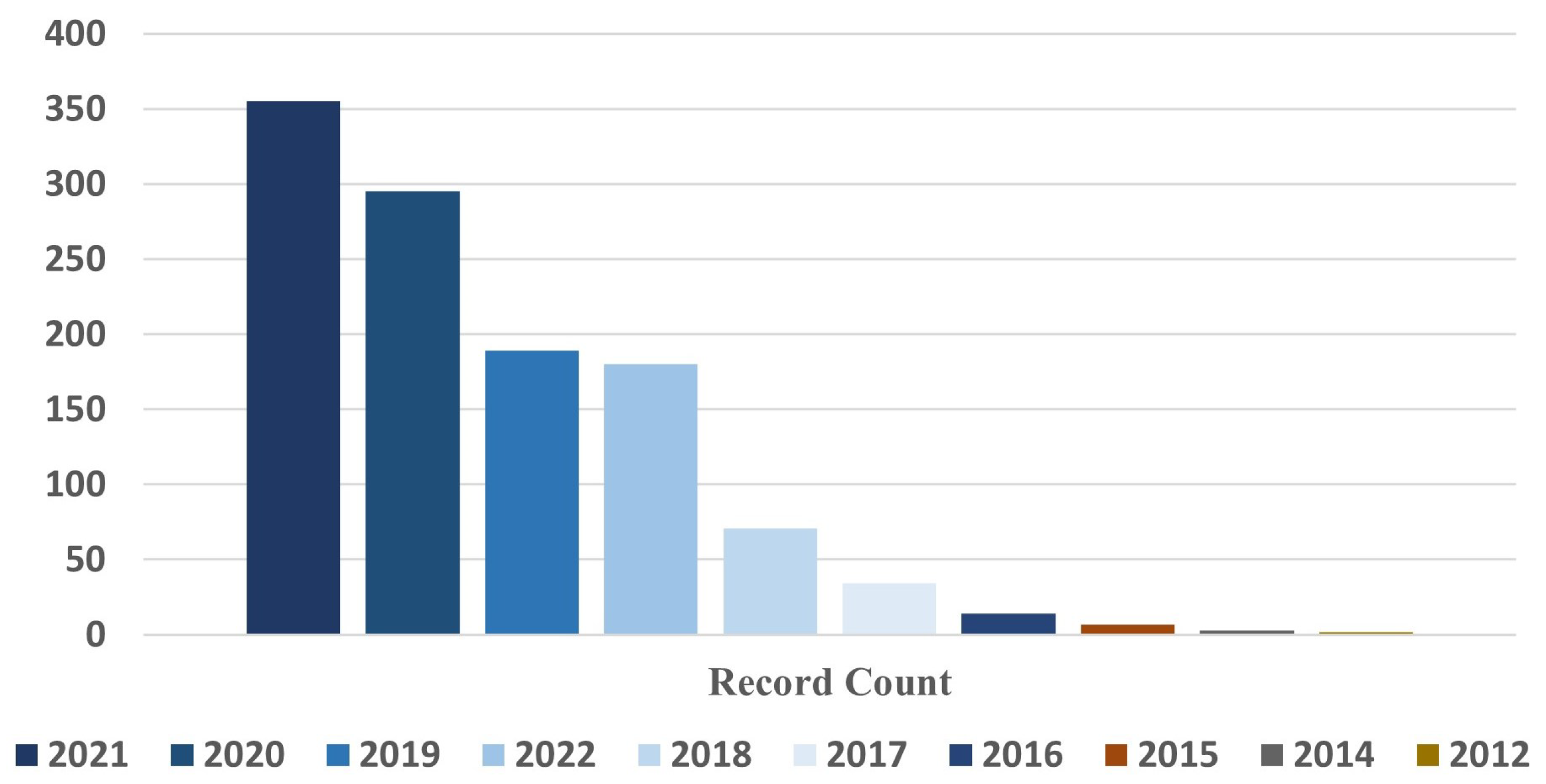
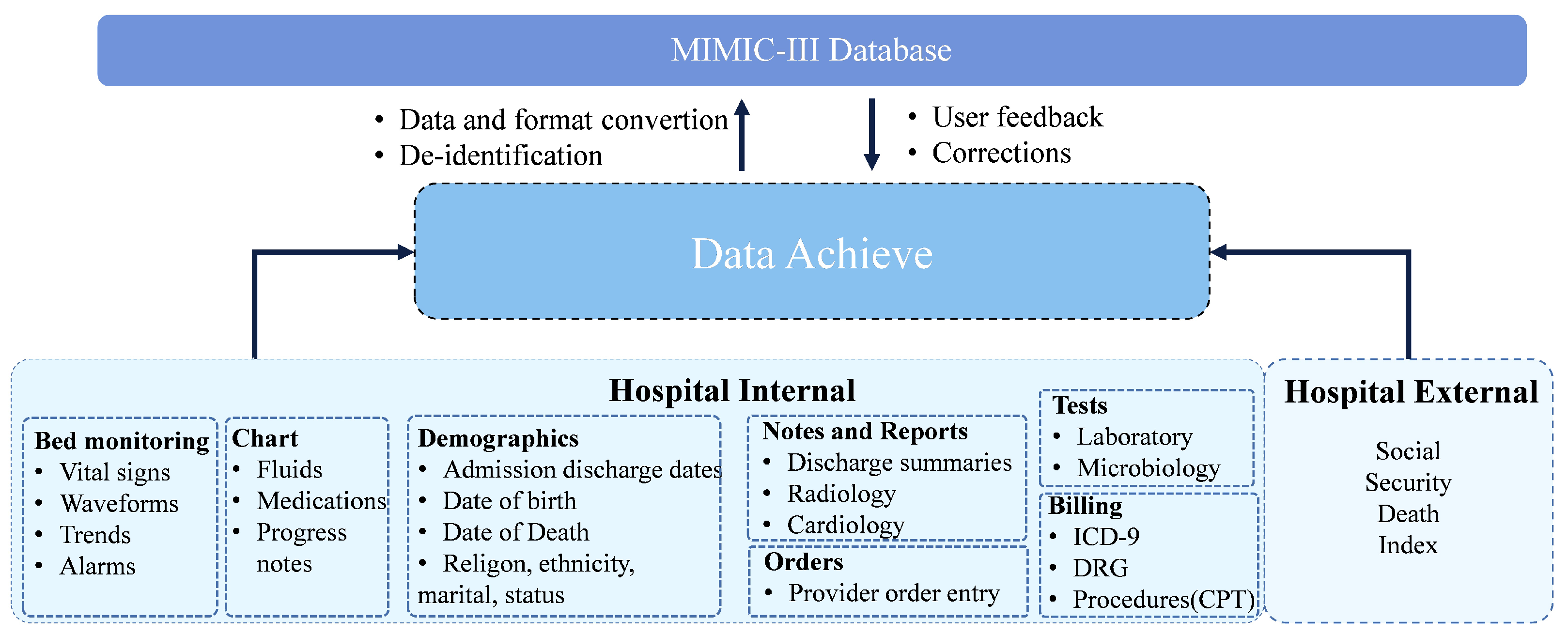
3.1. Medical Information Mart for Intensive Care (MIMIC)
3.2. eICU-CRD
3.3. PCORnet
3.4. Open NHS
3.5. NCBI-Disease
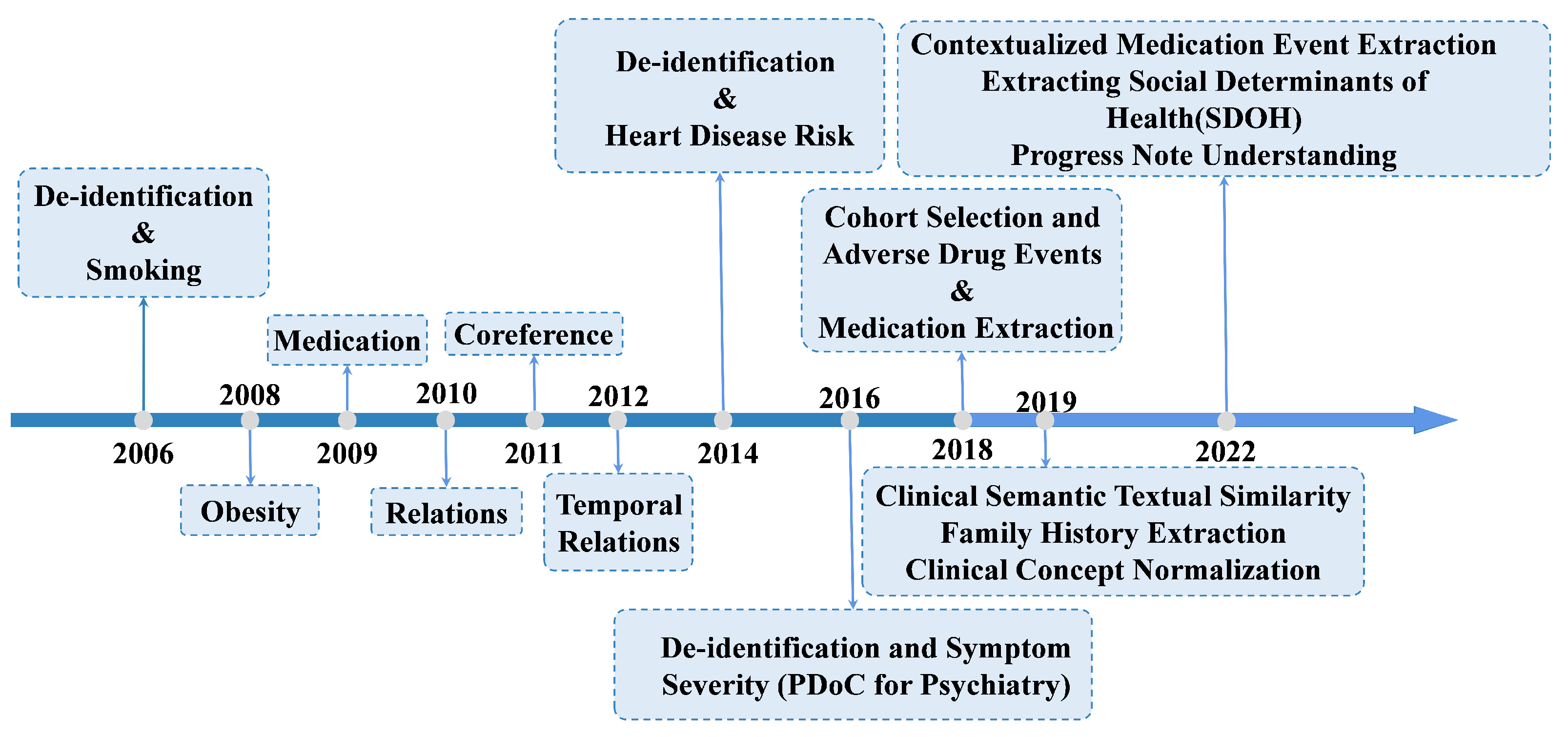
3.6. i2b2/n2c2 NLP Research Data Sets
4. Deep Learning Models
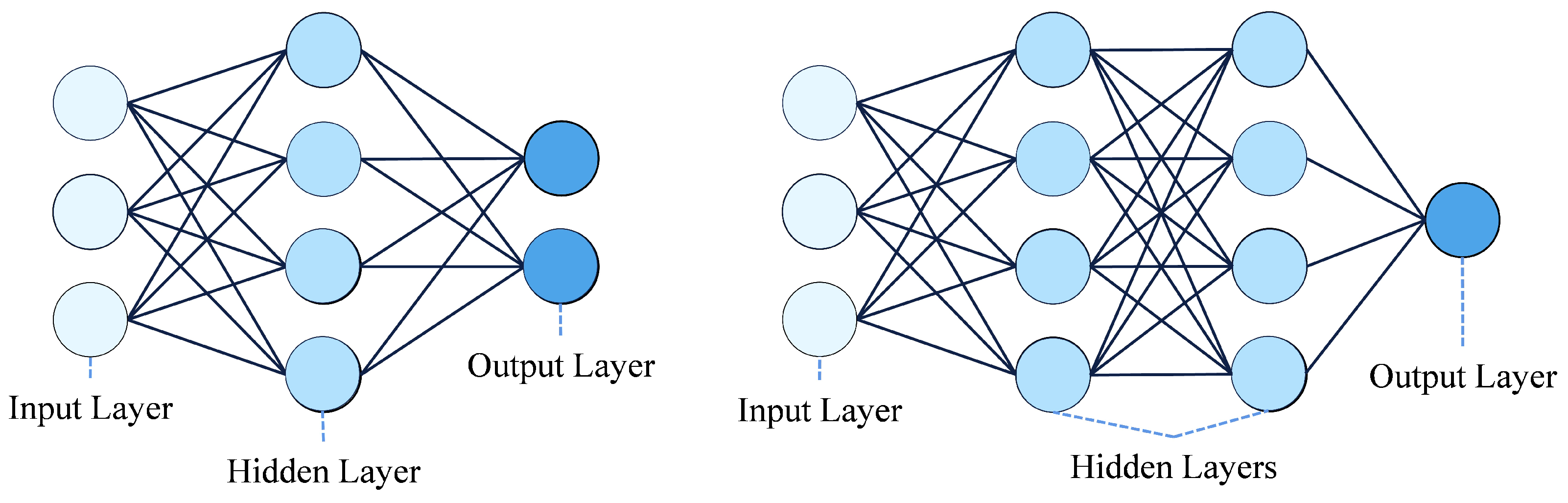
4.1. Artificial Neural Networks (ANNs)
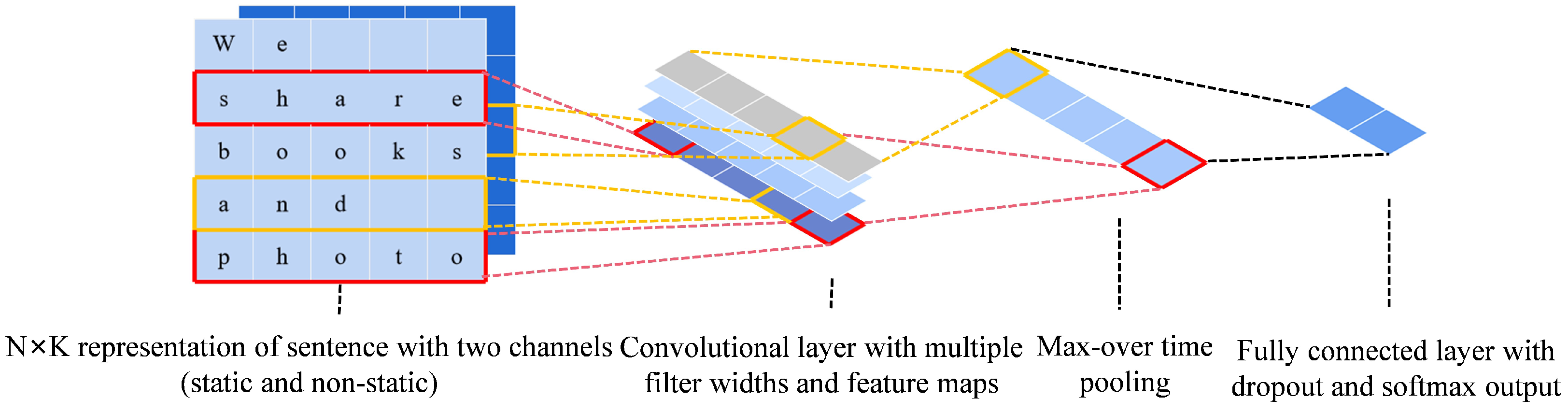
4.2. Convolutional Neural Networks (CNN)
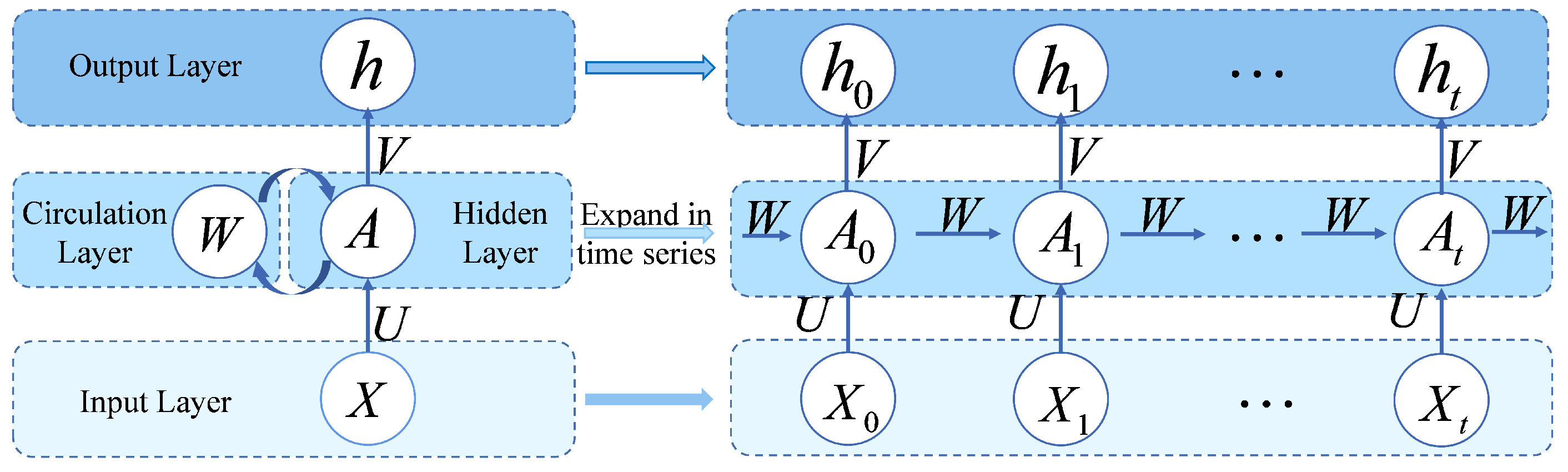
4.3. Recurrent Neural Networks (RNN)
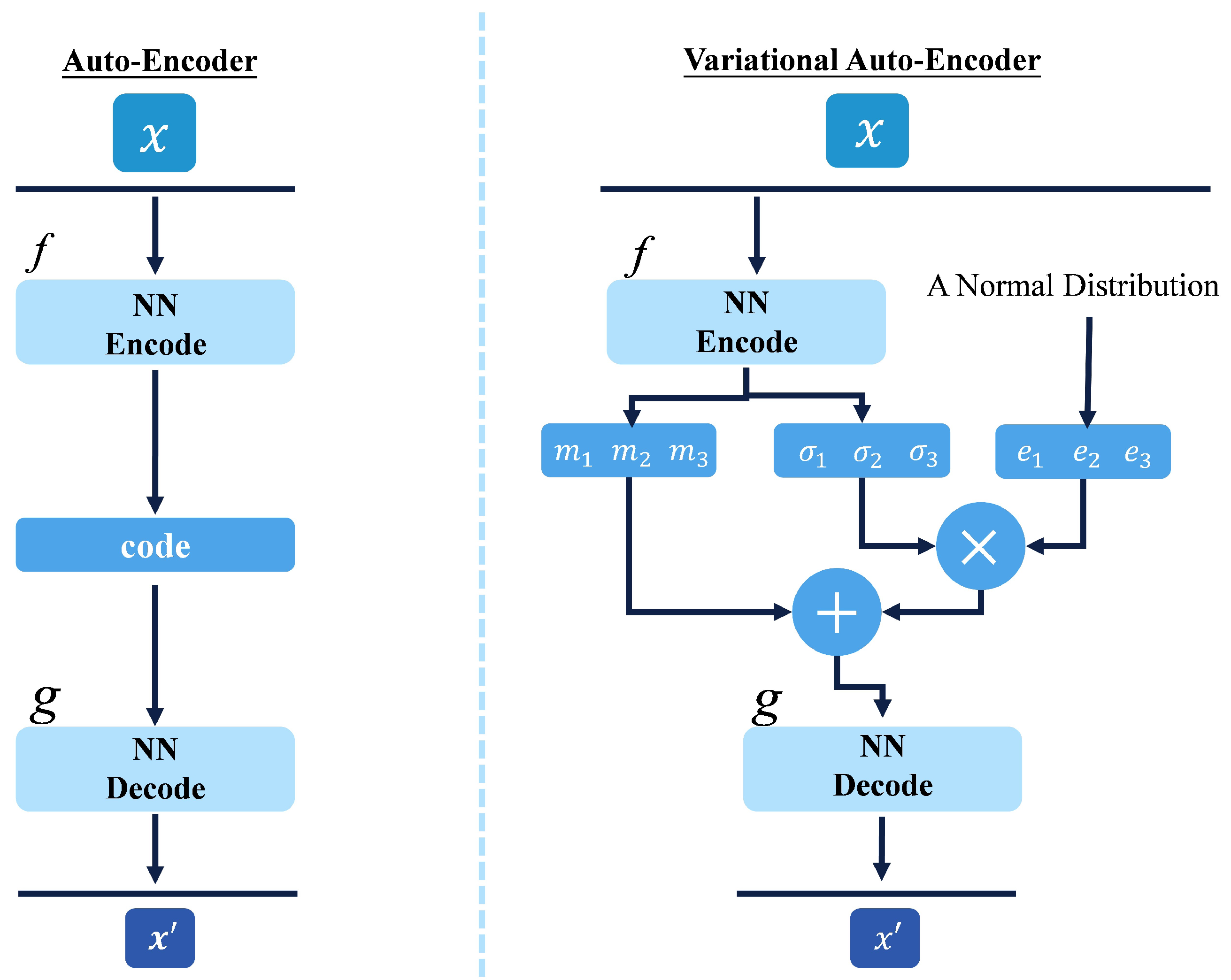
4.4. Auto-Encoder (AE)
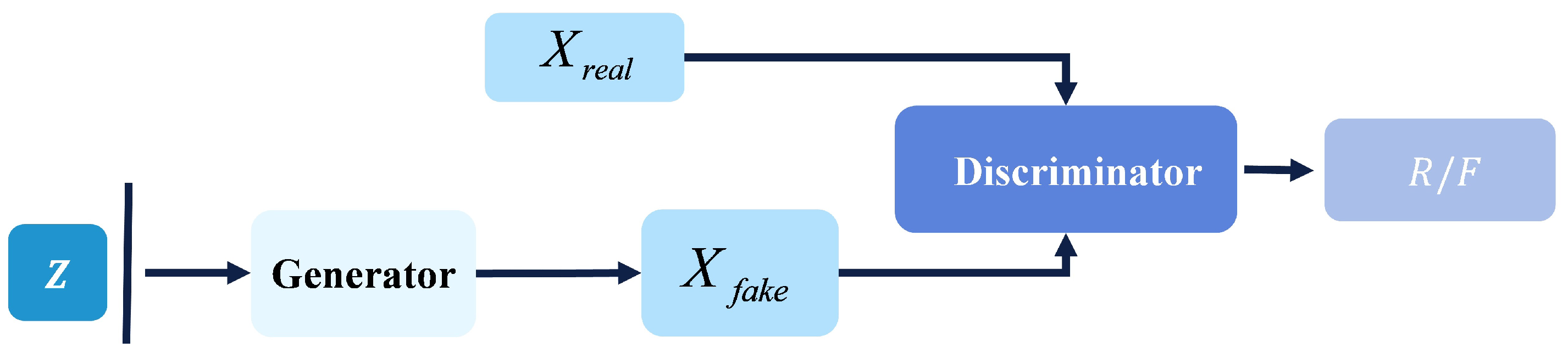
4.5. Generative Adversarial Network (GAN)
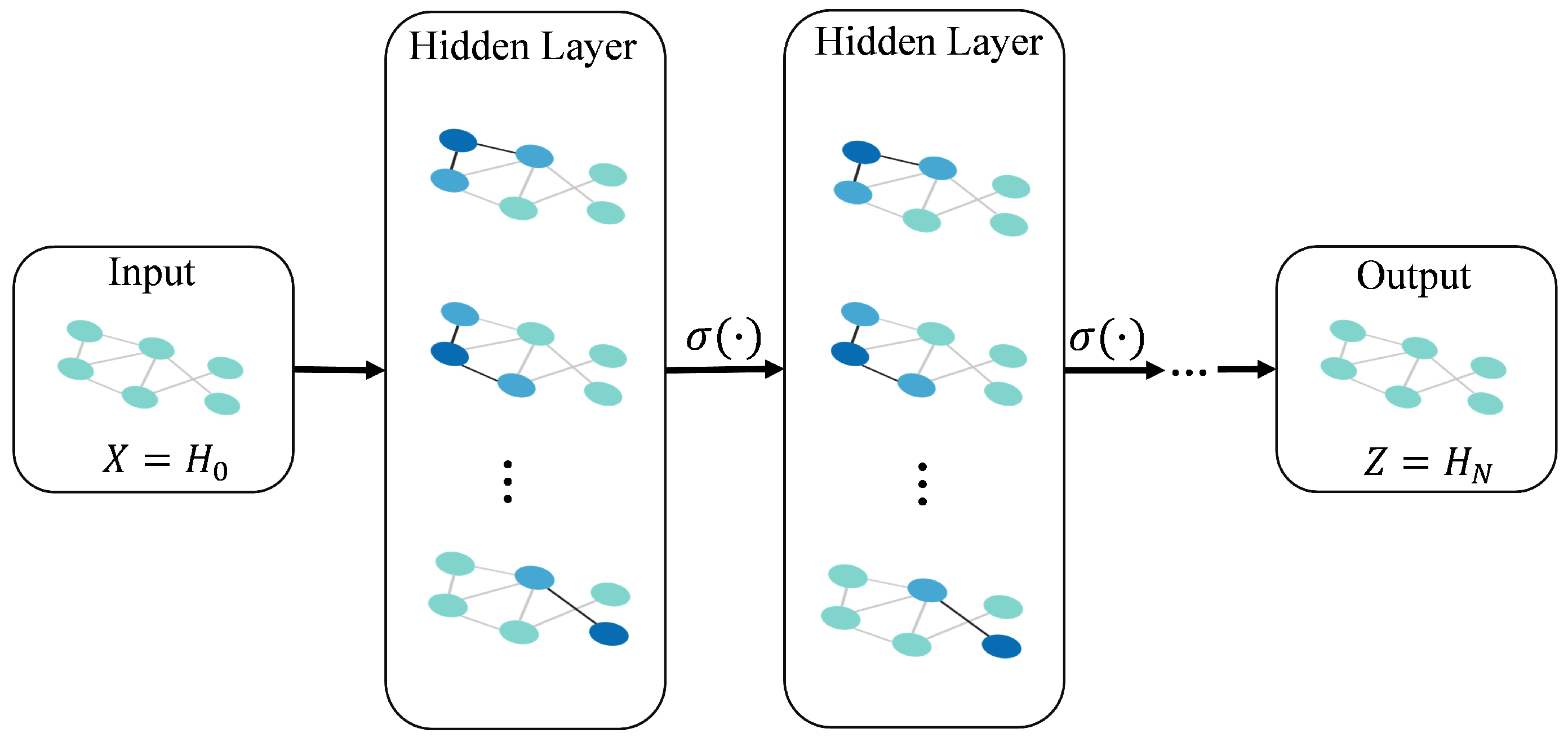
4.6. Graph Neural Network (GNN)
5. Deep Learning Applications in EHR
5.1. Information Extraction
5.1.1. Named Entity Recognition (NER)
5.1.2. Relation Extraction
5.1.3. Hiding Data Acquisition
5.2. Representation Learning
5.2.1. Vector-Based Patient Representation
5.2.2. Patient Representation Based on Time Matrix
5.2.3. Graphic-Based Patient Representation
5.2.4. Sequence-Based Patient Representation
5.3. Medical Prediction
5.3.1. Static Medical Prediction
5.3.2. Temporal Medical Prediction
5.4. Privacy Preservation
5.4.1. Data De-Identification
5.4.2. Patient Representation Protection
6. Challenges for EHR
6.1. Limitations in Representation Learning
6.2. Deficiencies in Information Extraction
6.3. Prospect of Patient Privacy Protection
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| KNN | K-Nearest Neighbor |
| LR | Logistic Regression |
| SVM | Support Vector Machine |
| EHR | Electronic Health Record |
| NLP | Natural Language Processing |
| CV | Computer Vision |
| ANN | Artificial Neural Network |
| ML | Machine Learning |
| SIR | Susceptible-Infected-Removed |
| SEIR | Susceptible-Exposed-Infected-Removed |
References
- Miotto, R.; Li, L.; Kidd, B.A.; Dudley, J.T. Deep patient: An unsupervised representation to predict the future of patients from the electronic health records. Sci. Rep. 2016, 6, 26094. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jagannatha, A.N.; Yu, H. Structured prediction models for RNN based sequence labeling in clinical text. In Proceedings of the EMNLP 2016: Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; p. 856. [Google Scholar]
- Jagannatha, A.N.; Yu, H. Bidirectional RNN for medical event detection in electronic health records. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; Association for Computational Linguistics: San Diego, CA, USA, 2016; Volume 2016, pp. 473–482. [Google Scholar]
- Poongodi, T.; Sumathi, D.; Suresh, P.; Balusamy, B. Deep Learning Techniques for Electronic Health Record (EHR) Analysis. In Bio-Inspired Neurocomputing; Springer: Berlin/Heidelberg, Germany, 2021; pp. 73–103. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Pai, M.M.; Ganiga, R.; Pai, R.M.; Sinha, R.K. Standard electronic health record (EHR) framework for Indian healthcare system. Health Serv. Outcomes Res. Methodol. 2021, 21, 339–362. [Google Scholar] [CrossRef]
- Harrison, J.E.; Weber, S.; Jakob, R.; Chute, C.G. ICD-11: An international classification of diseases for the twenty-first century. BMC Med. Inform. Decis. Mak. 2021, 21, 206. [Google Scholar] [CrossRef] [PubMed]
- Jacobs, J.P.; Franklin, R.C.; Béland, M.J.; Spicer, D.E.; Colan, S.D.; Walters, H.L.; Bailliard, F.; Houyel, L.; Louis, J.D.S.; Lopez, L.; et al. Nomenclature for pediatric and congenital cardiac care: Unification of clinical and administrative nomenclature–the 2021 international paediatric and congenital cardiac code (IPCCC) and the eleventh revision of the International classification of diseases (ICD-11). Cardiol. Young 2021, 31, 1057–1188. [Google Scholar]
- Bowie, M.J. Understanding Current Procedural Terminology and HCPCS Coding Systems, 2021; Cengage Learning: Boston, MA, USA, 2021. [Google Scholar]
- Benson, T.; Grieve, G. LOINC. In Principles of Health Interoperability; Springer: Berlin/Heidelberg, Germany, 2021; pp. 325–338. [Google Scholar]
- Tayebati, S.K.; Nittari, G.; Mahdi, S.S.; Ioannidis, N.; Sibilio, F.; Amenta, F. Identification of World Health Organisation ship’s medicine chest contents by Anatomical Therapeutic Chemical (ATC) classification codes. Int. Marit. Health 2017, 68, 39–45. [Google Scholar] [CrossRef] [Green Version]
- Bodenreider, O.; Cornet, R.; Vreeman, D.J. Recent developments in clinical terminologies—SNOMED CT, LOINC, and RxNorm. Yearb. Med. Inform. 2018, 27, 129–139. [Google Scholar] [CrossRef] [Green Version]
- Huang, S.; Cai, N.; Pacheco, P.P.; Narrandes, S.; Wang, Y.; Xu, W. Applications of support vector machine (SVM) learning in cancer genomics. Cancer Genom. Proteom. 2018, 15, 41–51. [Google Scholar]
- Svetnik, V.; Liaw, A.; Tong, C.; Culberson, J.C.; Sheridan, R.P.; Feuston, B.P. Random forest: A classification and regression tool for compound classification and QSAR modeling. J. Chem. Inf. Comput. Sci. 2003, 43, 1947–1958. [Google Scholar] [CrossRef]
- Act, A. Health insurance portability and accountability act of 1996. Public Law 1996, 104, 191. [Google Scholar]
- Johnson, A.E.; Pollard, T.J.; Shen, L.; Lehman, L.w.H.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Anthony Celi, L.; Mark, R.G. MIMIC-III, a freely accessible critical care database. Sci. Data 2016, 3, 160035. [Google Scholar] [CrossRef] [Green Version]
- Johnson, A.; Bulgarelli, L.; Pollard, T.; Horng, S.; Celi, L.A.; Mark, R. Mimic-iv. PhysioNet. 2020. Available online: https://physionet.org/content/mimiciv/1.0/ (accessed on 23 August 2021).
- Pollard, T.J.; Johnson, A.E.; Raffa, J.D.; Celi, L.A.; Mark, R.G.; Badawi, O. The eICU Collaborative Research Database, a freely available multi-center database for critical care research. Sci. Data 2018, 5, 180178. [Google Scholar] [CrossRef] [PubMed]
- Fleurence, R.L.; Curtis, L.H.; Califf, R.M.; Platt, R.; Selby, J.V.; Brown, J.S. Launching PCORnet, a national patient-centered clinical research network. J. Am. Med. Inform. Assoc. 2014, 21, 578–582. [Google Scholar] [CrossRef] [Green Version]
- Stubbs, A.; Kotfila, C.; Uzuner, Ö. Automated systems for the de-identification of longitudinal clinical narratives: Overview of 2014 i2b2/UTHealth shared task Track 1. J. Biomed. Inform. 2015, 58, S11–S19. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Bottou, L. LeNet-5, Convolutional Neural Networks. 2015. Available online: http://yann.lecun.com/exdb/lenet (accessed on 3 November 2022).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chen, Y. Convolutional Neural Network for Sentence Classification. Master’s Thesis, University of Waterloo, Waterloo, ON, Canada, 2015. [Google Scholar]
- Sundermeyer, M.; Schlüter, R.; Ney, H. LSTM neural networks for language modeling. In Proceedings of the INTERSPEECH 2012, 13th Annual Conference of the International Speech Communication Association, Portland, OR, USA, 9–13 September 2012. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Chung, J.; Kastner, K.; Dinh, L.; Goel, K.; Courville, A.C.; Bengio, Y. A recurrent latent variable model for sequential data. Adv. Neural Inf. Process. Syst. 2015, 28, 2980–2988. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Dai, B.; Fidler, S.; Urtasun, R.; Lin, D. Towards diverse and natural image descriptions via a conditional gan. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2970–2979. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Denton, E.L.; Chintala, S.; Fergus, R. Deep generative image models using a laplacian pyramid of adversarial networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1486–1494. [Google Scholar]
- Friedrich, M.; Köhn, A.; Wiedemann, G.; Biemann, C. Adversarial learning of privacy-preserving text representations for de-identification of medical records. arXiv 2019, arXiv:1906.05000. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Tai, K.S.; Socher, R.; Manning, C.D. Improved semantic representations from tree-structured long short-term memory networks. arXiv 2015, arXiv:1503.00075. [Google Scholar]
- Wang, C.; Pan, S.; Long, G.; Zhu, X.; Jiang, J. Mgae: Marginalized graph autoencoder for graph clustering. In Proceedings of the 2017 ACM Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 889–898. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. STAT 2017, 1050, 20. [Google Scholar]
- Zhu, R.; Zhao, K.; Yang, H.; Lin, W.; Zhou, C.; Ai, B.; Li, Y.; Zhou, J. Aligraph: A comprehensive graph neural network platform. arXiv 2019, arXiv:1902.08730. [Google Scholar] [CrossRef]
- Liu, M.; Luo, Y.; Wang, L.; Xie, Y.; Yuan, H.; Gui, S.; Yu, H.; Xu, Z.; Zhang, J.; Liu, Y.; et al. Dig: A turnkey library for diving into graph deep learning research. arXiv 2021, arXiv:2103.12608. [Google Scholar]
- Cen, Y.; Hou, Z.; Wang, Y.; Chen, Q.; Luo, Y.; Yao, X.; Zeng, A.; Guo, S.; Zhang, P.; Dai, G.; et al. Cogdl: An extensive toolkit for deep learning on graphs. arXiv 2021, arXiv:2103.00959. [Google Scholar]
- Lu, Q.; Nguyen, T.H.; Dou, D. Predicting patient readmission risk from medical text via knowledge graph enhanced multiview graph convolution. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Montreal, QC, Canada, 11–15 July 2021; pp. 1990–1994. [Google Scholar]
- Koleck, T.A.; Dreisbach, C.; Bourne, P.E.; Bakken, S. Natural language processing of symptoms documented in free-text narratives of electronic health records: A systematic review. J. Am. Med. Inform. Assoc. 2019, 26, 364–379. [Google Scholar] [CrossRef]
- Sheikhalishahi, S.; Miotto, R.; Dudley, J.T.; Lavelli, A.; Rinaldi, F.; Osmani, V. Natural language processing of clinical notes on chronic diseases: Systematic review. JMIR Med. Inform. 2019, 7, e12239. [Google Scholar] [CrossRef] [Green Version]
- Savova, G.K.; Danciu, I.; Alamudun, F.; Miller, T.; Lin, C.; Bitterman, D.S.; Tourassi, G.; Warner, J.L. Use of Natural Language Processing to Extract Clinical Cancer Phenotypes from Electronic Medical RecordsNatural Language Processing for Cancer Phenotypes from EMRs. Cancer Res. 2019, 79, 5463–5470. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2020, 36, 1234–1240. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sachan, D.S.; Xie, P.; Sachan, M.; Xing, E.P. Effective use of bidirectional language modeling for transfer learning in biomedical named entity recognition. In Proceedings of the Machine Learning for Healthcare Conference, Palo Alto, CA, USA, 17–18 August 2018; pp. 383–402. [Google Scholar]
- Wang, X.; Zhang, Y.; Ren, X.; Zhang, Y.; Zitnik, M.; Shang, J.; Langlotz, C.; Han, J. Cross-type biomedical named entity recognition with deep multi-task learning. Bioinformatics 2019, 35, 1745–1752. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, S.; Liu, T.; Zhao, S.; Wang, F. A neural multi-task learning framework to jointly model medical named entity recognition and normalization. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 817–824. [Google Scholar]
- Nie, B.; Li, C.; Wang, H. KA-NER: Knowledge Augmented Named Entity Recognition. In CCKS 2021: Knowledge Graph and Semantic Computing: Knowledge Graph Empowers New Infrastructure Construction, Proceedings of the 6th China Conference on Knowledge Graph and Semantic Computing, Guangzhou, China, 4–7 November 2021; Springer: Singapore, 2021; pp. 60–75. [Google Scholar]
- Wei, Q.; Ji, Z.; Li, Z.; Du, J.; Wang, J.; Xu, J.; Xiang, Y.; Tiryaki, F.; Wu, S.; Zhang, Y.; et al. A study of deep learning approaches for medication and adverse drug event extraction from clinical text. J. Am. Med. Inform. Assoc. 2020, 27, 13–21. [Google Scholar] [CrossRef]
- Wunnava, S.; Qin, X.; Kakar, T.; Sen, C.; Rundensteiner, E.A.; Kong, X. Adverse drug event detection from electronic health records using hierarchical recurrent neural networks with dual-level embedding. Drug Saf. 2019, 42, 113–122. [Google Scholar] [CrossRef]
- Munkhdalai, T.; Liu, F.; Yu, H. Clinical relation extraction toward drug safety surveillance using electronic health record narratives: Classical learning versus deep learning. JMIR Public Health Surveill. 2018, 4, e9361. [Google Scholar] [CrossRef]
- Wei, Q.; Ji, Z.; Si, Y.; Du, J.; Wang, J.; Tiryaki, F.; Wu, S.; Tao, C.; Roberts, K.; Xu, H. Relation extraction from clinical narratives using pre-trained language models. AMIA Annu. Symp. Proc. 2019, 2019, 1236–1245. [Google Scholar]
- Sun, X.; Dong, K.; Ma, L.; Sutcliffe, R.; He, F.; Chen, S.; Feng, J. Drug-drug interaction extraction via recurrent hybrid convolutional neural networks with an improved focal loss. Entropy 2019, 21, 37. [Google Scholar] [CrossRef] [Green Version]
- Jun, E.; Mulyadi, A.W.; Choi, J.; Suk, H.I. Uncertainty-gated stochastic sequential model for ehr mortality prediction. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4052–4062. [Google Scholar] [CrossRef]
- Che, Z.; Kale, D.; Li, W.; Bahadori, M.T.; Liu, Y. Deep computational phenotyping. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 507–516. [Google Scholar]
- Rajkomar, A.; Oren, E.; Chen, K.; Dai, A.M.; Hajaj, N.; Hardt, M.; Liu, P.J.; Liu, X.; Marcus, J.; Sun, M.; et al. Scalable and accurate deep learning with electronic health records. NPJ Digit. Med. 2018, 1, 18. [Google Scholar] [CrossRef]
- Cheng, Y.; Wang, F.; Zhang, P.; Hu, J. Risk prediction with electronic health records: A deep learning approach. In Proceedings of the 2016 SIAM International Conference on Data Mining, Miami, FL, USA, 5–7 May 2016; pp. 432–440. [Google Scholar]
- Choi, Y.; Chiu, C.Y.I.; Sontag, D. Learning low-dimensional representations of medical concepts. AMIA Summits Transl. Sci. Proc. 2016, 2016, 41. [Google Scholar] [PubMed]
- Wang, F.; Lee, N.; Hu, J.; Sun, J.; Ebadollahi, S. Towards heterogeneous temporal clinical event pattern discovery: A convolutional approach. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 453–461. [Google Scholar]
- Zhou, J.; Wang, F.; Hu, J.; Ye, J. From micro to macro: Data driven phenotyping by densification of longitudinal electronic medical records. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 135–144. [Google Scholar]
- Liu, C.; Wang, F.; Hu, J.; Xiong, H. Temporal phenotyping from longitudinal electronic health records: A graph based framework. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 705–714. [Google Scholar]
- Choi, E.; Bahadori, M.T.; Song, L.; Stewart, W.F.; Sun, J. GRAM: Graph-based attention model for healthcare representation learning. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 787–795. [Google Scholar]
- Ma, F.; You, Q.; Xiao, H.; Chitta, R.; Zhou, J.; Gao, J. Kame: Knowledge-based attention model for diagnosis prediction in healthcare. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 743–752. [Google Scholar]
- Rasmy, L.; Xiang, Y.; Xie, Z.; Tao, C.; Zhi, D. Med-BERT: Pretrained contextualized embeddings on large-scale structured electronic health records for disease prediction. NPJ Digit. Med. 2021, 4, 86. [Google Scholar] [CrossRef] [PubMed]
- Choi, E.; Xu, Z.; Li, Y.; Dusenberry, M.; Flores, G.; Xue, E.; Dai, A. Learning the graphical structure of electronic health records with graph convolutional transformer. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 606–613. [Google Scholar]
- Song, H.; Rajan, D.; Thiagarajan, J.; Spanias, A. Attend and diagnose: Clinical time series analysis using attention models. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–3 February 2018. [Google Scholar]
- Li, Y.; Rao, S.; Solares, J.R.A.; Hassaine, A.; Ramakrishnan, R.; Canoy, D.; Zhu, Y.; Rahimi, K.; Salimi-Khorshidi, G. BEHRT: Transformer for electronic health records. Sci. Rep. 2020, 10, 7155. [Google Scholar] [CrossRef] [PubMed]
- Choi, E.; Schuetz, A.; Stewart, W.F.; Sun, J. Medical concept representation learning from electronic health records and its application on heart failure prediction. arXiv 2016, arXiv:1602.03686. [Google Scholar]
- Tran, T.; Nguyen, T.D.; Phung, D.; Venkatesh, S. Learning vector representation of medical objects via EMR-driven nonnegative restricted Boltzmann machines (eNRBM). J. Biomed. Inform. 2015, 54, 96–105. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Zhang, Z.; Razavian, N. Deep EHR: Chronic disease prediction using medical notes. In Proceedings of the 3rd Machine Learning for Healthcare Conference, Palo Alto, CA, USA, 17–18 August 2018; pp. 440–464. [Google Scholar]
- Gao, J.; Sharma, R.; Qian, C.; Glass, L.M.; Spaeder, J.; Romberg, J.; Sun, J.; Xiao, C. STAN: Spatio-temporal attention network for pandemic prediction using real-world evidence. J. Am. Med. Inform. Assoc. 2021, 28, 733–743. [Google Scholar] [CrossRef]
- Gjoreski, M.; Gradišek, A.; Budna, B.; Gams, M.; Poglajen, G. Machine learning and end-to-end deep learning for the detection of chronic heart failure from heart sounds. IEEE Access 2020, 8, 20313–20324. [Google Scholar] [CrossRef]
- Yang, H.; Kuang, L.; Xia, F. Multimodal temporal-clinical note network for mortality prediction. J. Biomed. Semant. 2021, 12, 3. [Google Scholar] [CrossRef]
- Peng, X.; Long, G.; Shen, T.; Wang, S.; Jiang, J.; Zhang, C. BiteNet: Bidirectional temporal encoder network to predict medical outcomes. In Proceedings of the 2020 IEEE International Conference on Data Mining (ICDM), Sorrento, Italy, 17–20 November 2020; pp. 412–421. [Google Scholar]
- Dernoncourt, F.; Lee, J.Y.; Uzuner, O.; Szolovits, P. De-identification of patient notes with recurrent neural networks. J. Am. Med. Inform. Assoc. 2017, 24, 596–606. [Google Scholar] [CrossRef] [Green Version]
- Yadav, S.; Ekbal, A.; Saha, S.; Bhattacharyya, P. Deep learning architecture for patient data de-identification in clinical records. In Proceedings of the Clinical Natural Language Processing Workshop (ClinicalNLP); The COLING 2016 Organizing Committee: Osaka, Japan, 2016; pp. 32–41. [Google Scholar]
- Ahmed, T.; Aziz, M.M.A.; Mohammed, N. De-identification of electronic health record using neural network. Sci. Rep. 2020, 10, 18600. [Google Scholar] [CrossRef]
- Festag, S.; Spreckelsen, C. Privacy-preserving deep learning for the detection of protected health information in real-world data: Comparative evaluation. JMIR Form. Res. 2020, 4, e14064. [Google Scholar] [CrossRef] [PubMed]
- Coavoux, M.; Narayan, S.; Cohen, S.B. Privacy-preserving neural representations of text. arXiv 2018, arXiv:1808.09408. [Google Scholar]
- Jordon, J.; Yoon, J.; Van Der Schaar, M. PATE-GAN: Generating synthetic data with differential privacy guarantees. In Proceedings of the Sixth International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A.; Bottou, L. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Doersch, C. Tutorial on variational autoencoders. arXiv 2016, arXiv:1606.05908. [Google Scholar]
- Salah, R.; Vincent, P.; Muller, X. Contractive auto-encoders: Explicit invariance during feature extraction. In Proceedings of the 28th International Conference on International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011; pp. 833–840. [Google Scholar]
- NirmalaDevi, M.; alias Balamurugan, S.A.; Swathi, U. An amalgam KNN to predict diabetes mellitus. In Proceedings of the 2013 IEEE International Conference on Emerging Trends in Computing, Communication and Nanotechnology (ICECCN), Tirunelveli, India, 25–26 March 2013; pp. 691–695. [Google Scholar]
- Tu, J.V. Advantages and disadvantages of using artificial neural networks versus logistic regression for predicting medical outcomes. J. Clin. Epidemiol. 1996, 49, 1225–1231. [Google Scholar] [CrossRef]
- Boateng, E.Y.; Abaye, D.A. A review of the logistic regression model with emphasis on medical research. J. Data Anal. Inf. Process. 2019, 7, 190–207. [Google Scholar] [CrossRef] [Green Version]
- Vijayarani, S.; Dhayanand, S. Liver disease prediction using SVM and Naïve Bayes algorithms. Int. J. Sci. Eng. Technol. Res. (IJSETR) 2015, 4, 816–820. [Google Scholar]
- Mantzaris, D.H.; Anastassopoulos, G.C.; Lymberopoulos, D.K. Medical disease prediction using artificial neural networks. In Proceedings of the 2008 8th IEEE International Conference on BioInformatics and BioEngineering, Athens, Greece, 8–10 October 2008; pp. 1–6. [Google Scholar]
- Lipton, Z.C.; Kale, D.C.; Elkan, C.; Wetzel, R. Learning to diagnose with LSTM recurrent neural networks. arXiv 2015, arXiv:1511.03677. [Google Scholar]
- Wu, L.; Fisch, A.; Chopra, S.; Adams, K.; Bordes, A.; Weston, J. Starspace: Embed all the things! In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–3 February 2018.
- Chapman, W.W.; Bridewell, W.; Hanbury, P.; Cooper, G.F.; Buchanan, B.G. A simple algorithm for identifying negated findings and diseases in discharge summaries. J. Biomed. Inform. 2001, 34, 301–310. [Google Scholar] [CrossRef] [Green Version]
- Deng, S.; Wang, S.; Rangwala, H.; Wang, L.; Ning, Y. Graph message passing with cross-location attentions for long-term ILI prediction. arXiv 2019, arXiv:1912.10202. [Google Scholar]
- Kapoor, A.; Ben, X.; Liu, L.; Perozzi, B.; Barnes, M.; Blais, M.; O’Banion, S. Examining covid-19 forecasting using spatio-temporal graph neural networks. arXiv 2020, arXiv:2007.03113. [Google Scholar]
- Choi, E.; Bahadori, M.T.; Sun, J.; Kulas, J.; Schuetz, A.; Stewart, W. Retain: An interpretable predictive model for healthcare using reverse time attention mechanism. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3512–3520. [Google Scholar]
- Nguyen, P.; Tran, T.; Wickramasinghe, N.; Venkatesh, S. Deepr: A convolutional net for medical records. IEEE J. Biomed. Health Inform. 2016, 21, 22–30. [Google Scholar] [CrossRef] [PubMed]
- Ma, F.; Chitta, R.; Zhou, J.; You, Q.; Sun, T.; Gao, J. Dipole: Diagnosis prediction in healthcare via attention-based bidirectional recurrent neural networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1903–1911. [Google Scholar]
- Sweeney, L. Computational Disclosure Control: A Primer on Data Privacy Protection. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2001. [Google Scholar]
- Sibanda, T.; He, T.; Szolovits, P.; Uzuner, O. Syntactically-informed semantic category recognizer for discharge summaries. AMIA Annu. Symp. Proc. 2006, 2006, 714–718. [Google Scholar]
- Sibanda, T.C. Was the Patient Cured?: Understanding Semantic Categories and Their Relationship in Patient Records. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2006. [Google Scholar]
- Neamatullah, I.; Douglass, M.M.; Lehman, L.W.H.; Reisner, A.; Villarroel, M.; Long, W.J.; Szolovits, P.; Moody, G.B.; Mark, R.G.; Clifford, G.D. Automated de-identification of free-text medical records. BMC Med. Inform. Decis. Mak. 2008, 8, 32. [Google Scholar] [CrossRef] [PubMed]
- Xie, L.; Lin, K.; Wang, S.; Wang, F.; Zhou, J. Differentially private generative adversarial network. arXiv 2018, arXiv:1802.06739. [Google Scholar]
- Fredrikson, M.; Jha, S.; Ristenpart, T. Model inversion attacks that exploit confidence information and basic countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1322–1333. [Google Scholar]
- Shokri, R.; Shmatikov, V. Privacy-preserving deep learning. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1310–1321. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Research | Record Numbers | Percentage (%) |
|---|---|---|
| Health Care Sciences Services | 851 | 73.489 |
| Computer Science | 771 | 66.580 |
| Mathematical Computational Biology | 622 | 53.713 |
| Medical Informatics | 455 | 39.292 |
| Mathematics | 379 | 32.729 |
| Task | Model/Method | Publication Year | Proprosed by |
|---|---|---|---|
| Named Entity Recognition | - | 2019 | Koleck et al. [43] |
| - | 2019 | Sheikhalishahi et al. [44] | |
| - | 2019 | Savova et al. [45] | |
| Bio-BERTv1.1 (+PubMed) | 2020 | Lee et al. [46] | |
| Bidirection Language Modeling | 2018 | Sachan et al. [47] | |
| MTM-CW | 2019 | Wang et al. [48] | |
| MTL-MEN & MER feedback + Bi-LSTM-CNNs-CRF | 2019 | Zhao et al. [49] | |
| KA-NER | 2021 | Nie et al. [50] | |
| Bi-LSTM + CRF | 2020 | Wei et al. [51] | |
| DLADE | 2019 | Wunnava et al. [52] | |
| Relation Extraction | JOINT | 2020 | Wei et al. [51] |
| SVM, Deep Learning model, Rule Induction | 2018 | Munkhdalai et al. [53] | |
| FT-BERT, FC-BERT | 2019 | Wei et al. [54] | |
| Hybrid CNN architecture with focus loss function | 2019 | Sun et al. [55] | |
| Hidden Data Extraction | VRNN + VAE | 2015 | Chung et al. [29] |
| VRNN + GRU-U | 2020 | Jun et al. [56] | |
| Vector based patient representation | Fully Connected Neural Network | 2015 | Che et al. [57] |
| LSTM, TANN, NN with boosted time based decision stumps | 2018 | Rajkomar et al. [58] | |
| CNN | 2016 | Cheng et al. [59] | |
| AE-based | 2016 | Miotto et al. [1] | |
| MCEMJ, MCEMC and MCECN | 2016 | Choi et al. [60] | |
| Patient representation based on time matrix | CNN-based + NMF | 2016 | Cheng et al. [59] |
| - | 2012 | Wang et al. [61] | |
| - | 2014 | Zhou et al. [62] | |
| Graphic-based patient representation | Temporal Graph Model | 2015 | Liu et al. [63] |
| GCT | 2017 | Choi et al. [64] | |
| KAME | 2018 | Ma et al. [65] | |
| CogDL | 2021 | Cen et al. [41] | |
| DIG | 2021 | Liu et al. [40] | |
| Sequence-based patient representation | Med-BERT | 2021 | Rasmy et al. [66] |
| GCT | 2020 | Choi et al. [67] | |
| Attention Model | 2018 | Song et al. [68] | |
| BEHRT | 2020 | Li et al. [69] | |
| Static medical prediction | ANN + Linear model | 2016 | Choi et al. [70] |
| enRBM | 2015 | Truyen et al. [71] | |
| AE-based + LR Classifier | 2016 | Miotto et al. [1] | |
| Deep EHR | 2018 | Liu et al. [72] | |
| Temporal medical prediction | STAN | 2021 | Gao et al. [73] |
| End-to-end DL + Classic ML | 2020 | Martin et al. [74] | |
| Multimodel based on LSTM and CNN | 2021 | Yang et al. [75] | |
| BiteNet | 2020 | Peng et al. [76] | |
| Data de-identification | RNN | 2017 | Dernoncourt et al. [77] |
| multiple RNN | 2016 | Yadav et al. [78] | |
| Stack RNN + attention mechanism | 2020 | Ahmed et al. [79] | |
| Patient representation protection | Collaborative Privacy Representation Learning Method | 2020 | Festag et al. [80] |
| Adversarial Learning | 2016 | Yadav et al. [78] | |
| Confrontational Learning Method & De-clustering | 2016 | Coavous et al. [81] | |
| Self-joining Adversarial Network | 2019 | Friedrich et al. [34] | |
| PATE-GAN | 2018 | Jordon et al. [82] |
| Method | Dataset | F1-Scores % |
|---|---|---|
| Bio-BERTv1.1 (+PubMed) [46] | NCBI Disease | 89.7 |
| 2010i2b2/V A | 86.73 | |
| BC5CDR | 87.15 | |
| MTM-CW [48] | BC2GM (Exact) | 80.74 ± 0.04 |
| BC2GM (Alternative) | 89.06 ± 0.32 | |
| BC4CHEMD | 89.37 ± 0.07 | |
| BC5CDR | 88.78 ± 0.12 | |
| NCBI-Disease | 86.14 ± 0.31 | |
| JNLPBA | 73.52 ± 0.03 | |
| MTL-MEN & MER feedback + Bi-LSTM-CNNs-CRF [49] | NCBI Disease | 88.23 |
| BC5CDR | 89.17 | |
| Bidirectional Language Modeling [47] | NCBI Disease | 87.34 |
| BC5CDR | 89.28 | |
| BC2GM | 81.69 | |
| JNLPBA | 75.03 | |
| KA-NER [50] | NCBI-Disease | 86.12 |
| CoNLL03 | 92.40 | |
| Genia | 75.59 | |
| SEC | 85.16 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, J.; Xi, X.; Chen, J.; Sheng, V.S.; Ma, J.; Cui, Z. A Survey of Deep Learning for Electronic Health Records. Appl. Sci. 2022, 12, 11709. https://doi.org/10.3390/app122211709
Xu J, Xi X, Chen J, Sheng VS, Ma J, Cui Z. A Survey of Deep Learning for Electronic Health Records. Applied Sciences. 2022; 12(22):11709. https://doi.org/10.3390/app122211709
Chicago/Turabian StyleXu, Jiabao, Xuefeng Xi, Jie Chen, Victor S. Sheng, Jieming Ma, and Zhiming Cui. 2022. "A Survey of Deep Learning for Electronic Health Records" Applied Sciences 12, no. 22: 11709. https://doi.org/10.3390/app122211709