
A Fitting Recognition Approach Combining Depth-Attention YOLOv5 and Prior Synthetic Dataset

Abstract
:1. Introduction
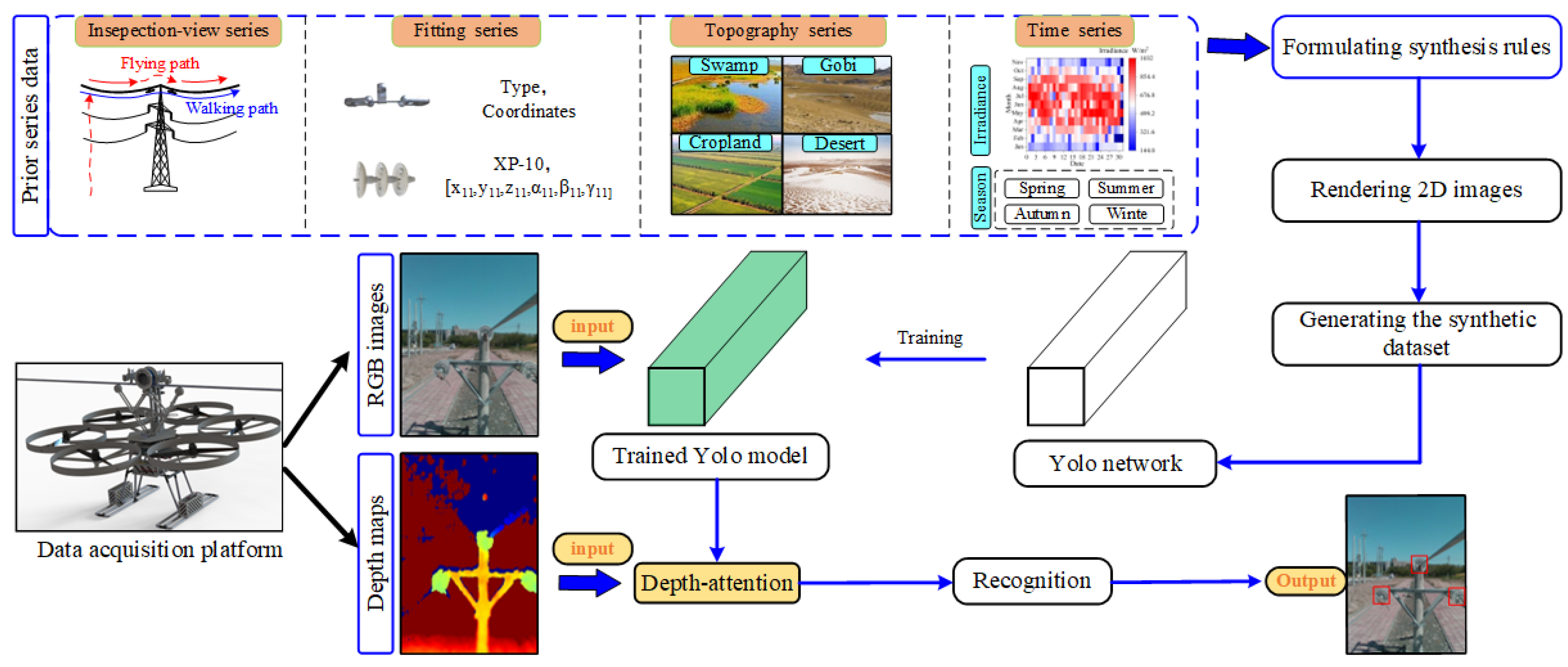
- Synthesizing automatic synthetic datasets with inspection features based on prior fitting series, prior inspection-view series, prior topography series, and prior time series. So, the proportion of inspection-unrelated features in the dataset is small, achieving better results with a smaller data volume for the deep learning model. In addition, the cost of obtained dataset acquisition is further reduced compared to other synthetic and real data collection methods.
- Proposing a unique data collection mode using FPTLIR as the acquisition platform, i.e., walking along the top ground line to collect sequence image data. The obtained image data in this collection mode has obvious time-space, stability, and depth difference, in particular, the RGB images and depth maps with depth differences between the fitting and the background, fusing the two data types in the deep learning model to improve the model accuracy.
- Proposing a depth-attention mechanism activated in the detection stage to change the attention on the images according to depth information. It is directly introduced into the deep learning model without secondary training, reducing the probability of model misdetection and omission more conveniently and quickly. The experiments prove the feasibility and validity of the proposed approach, and the results are significantly better than other attention mechanisms, which have practical application significance.
2. Related Works
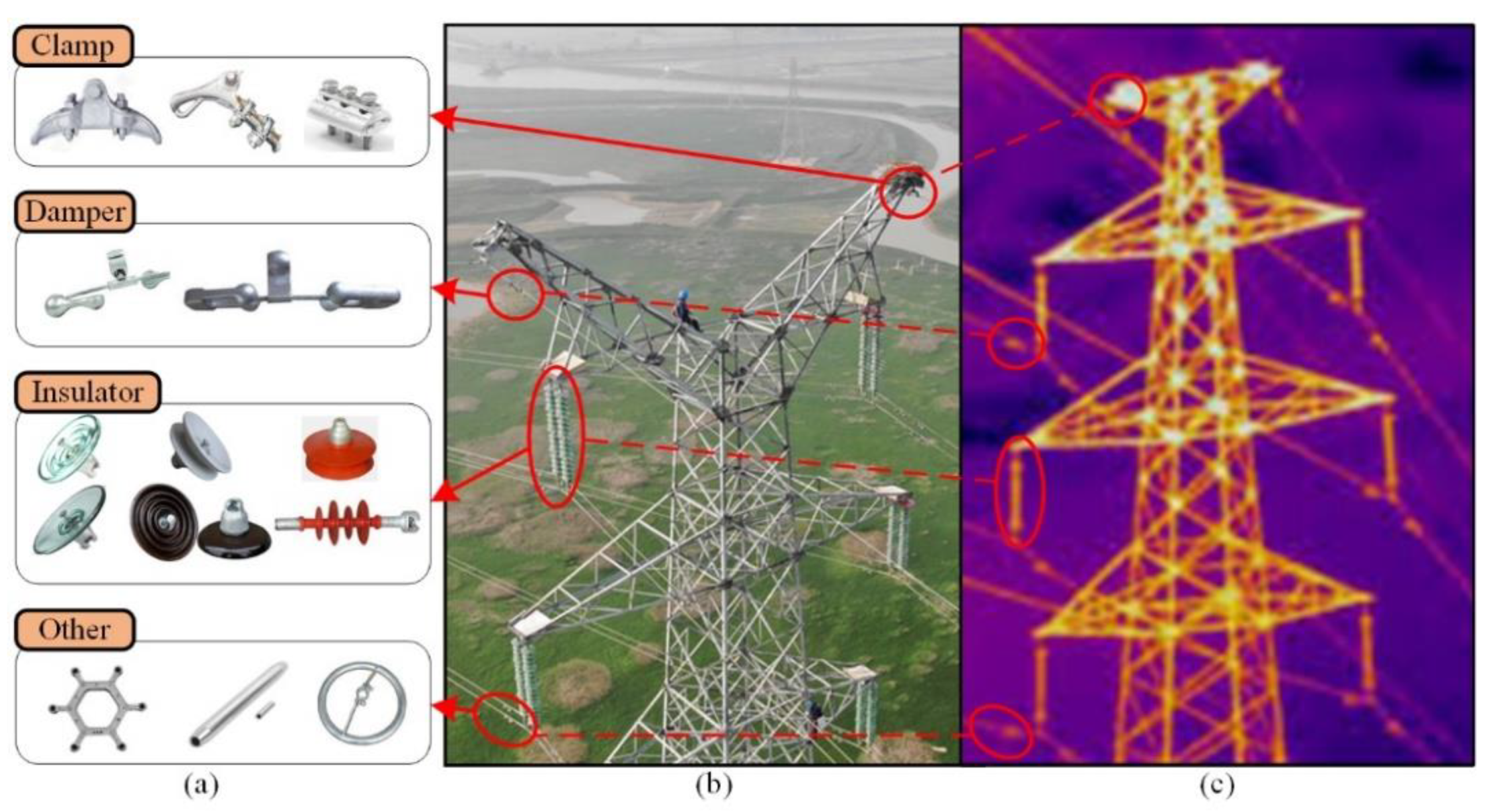
2.1. Fitting Dataset
2.2. Vision-Based Inspection System
2.3. YOLO Series
2.4. Attention Mechanism
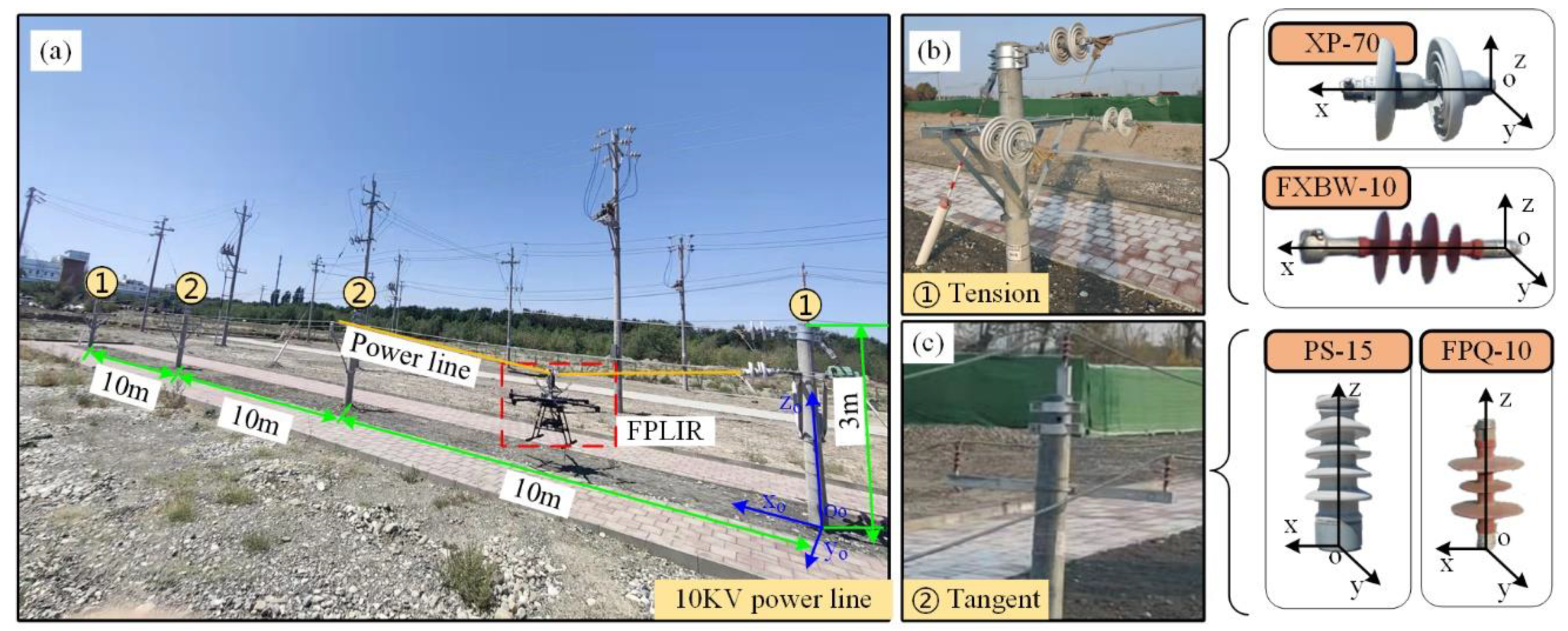
3. Hardware and Data
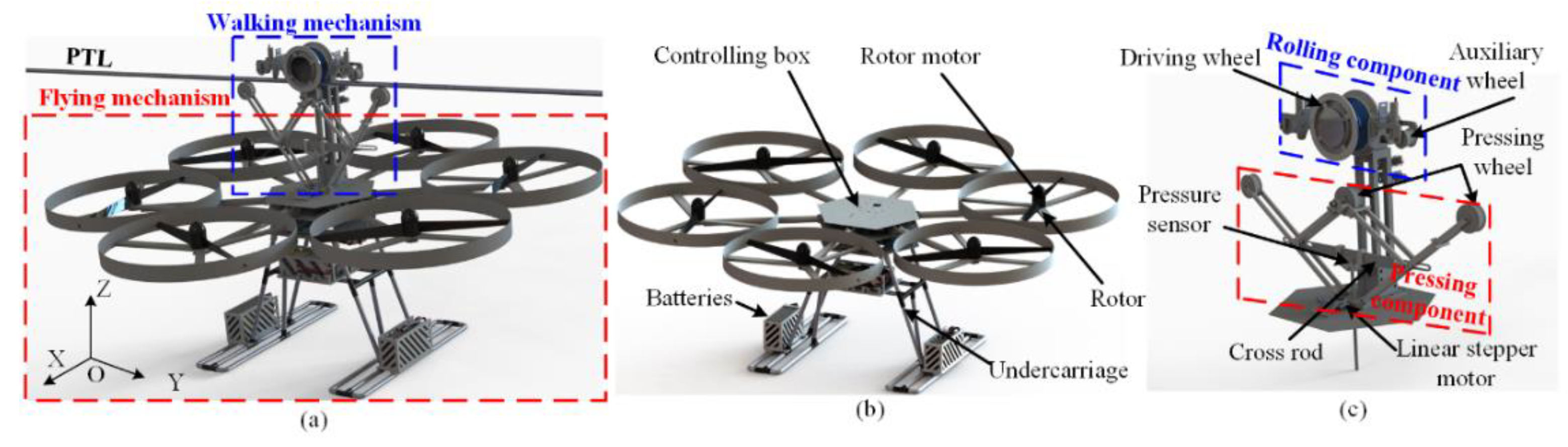
3.1. System Structure
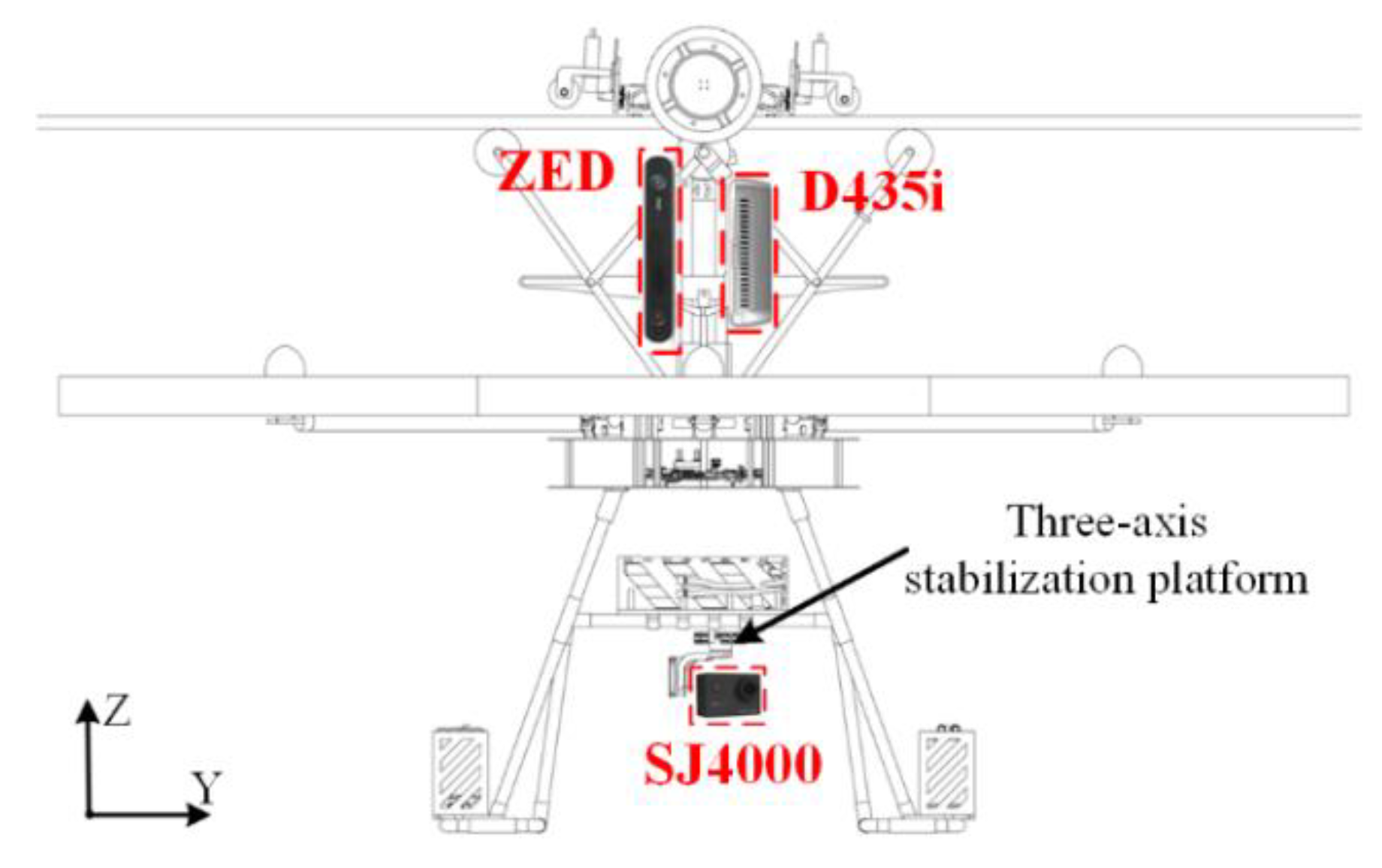
3.2. System Integration
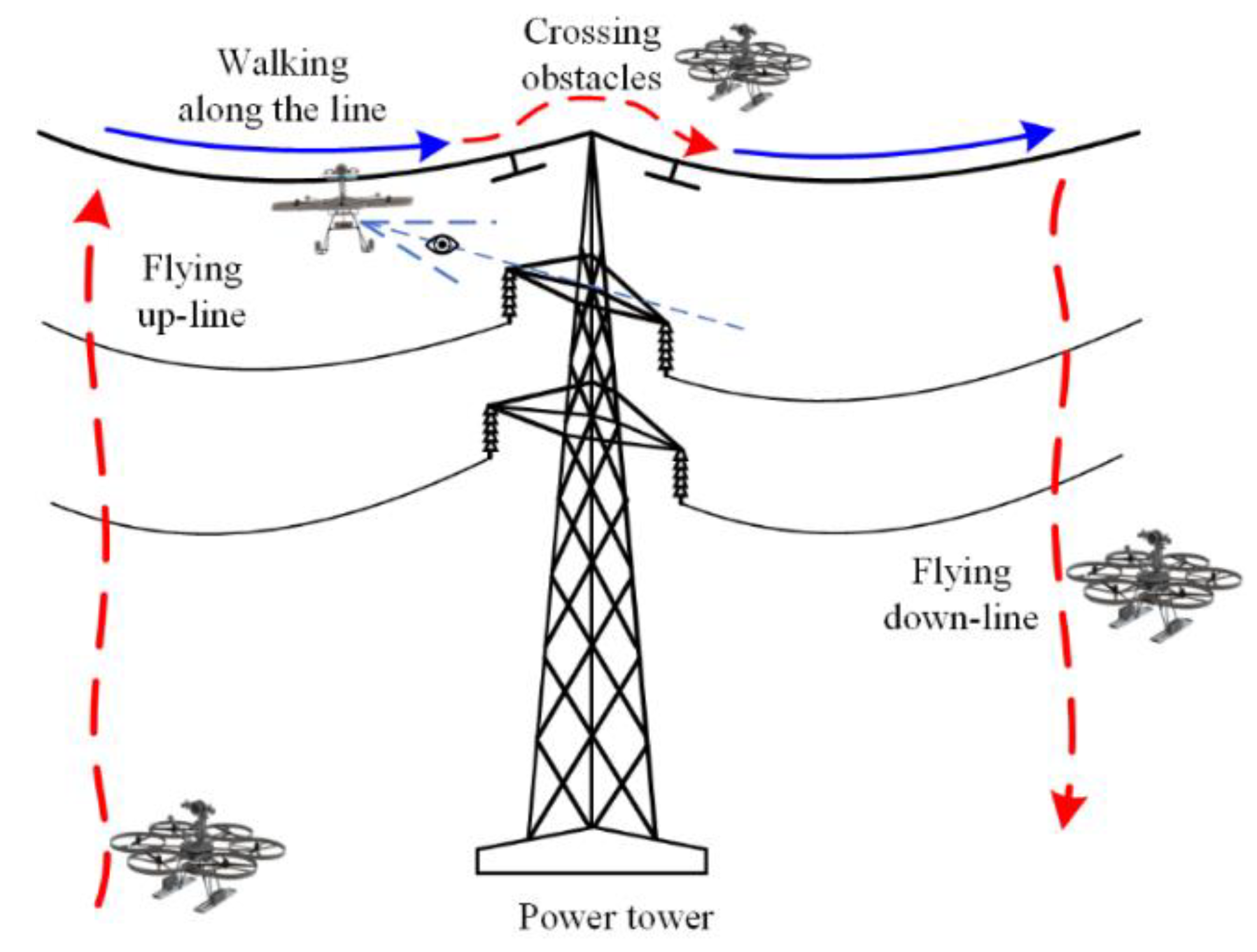
3.3. Inspection Data
- The background of collected images by FPTLIR is mostly ground, and the data is continuously collected along the line to obtain a complete database of PTL corridor.
- The robot’s viewpoint is located at the top ground line with the oblique downward view angle, and the collected depth maps have a significant depth difference between the target and background.
4. Proposed Approach
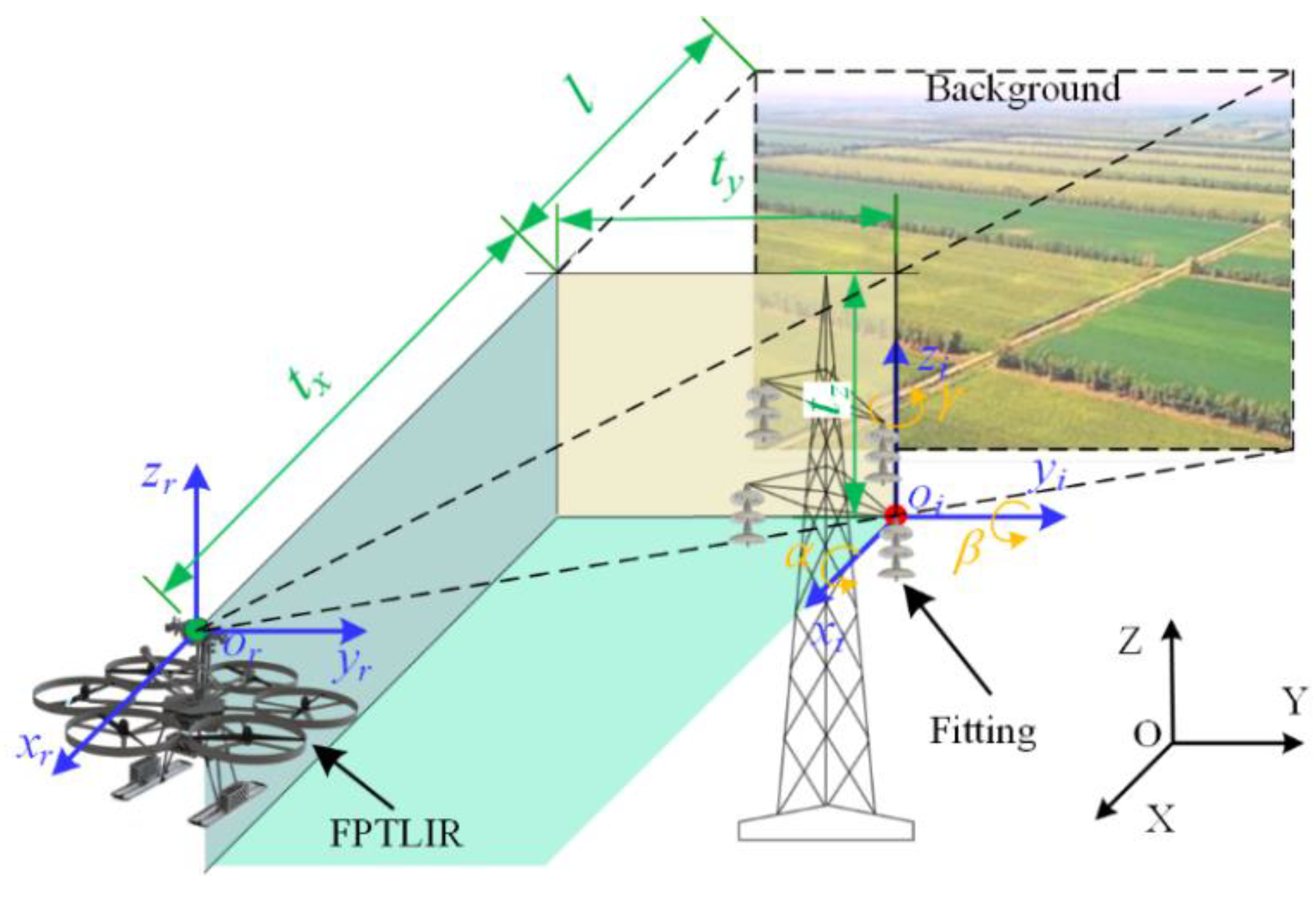
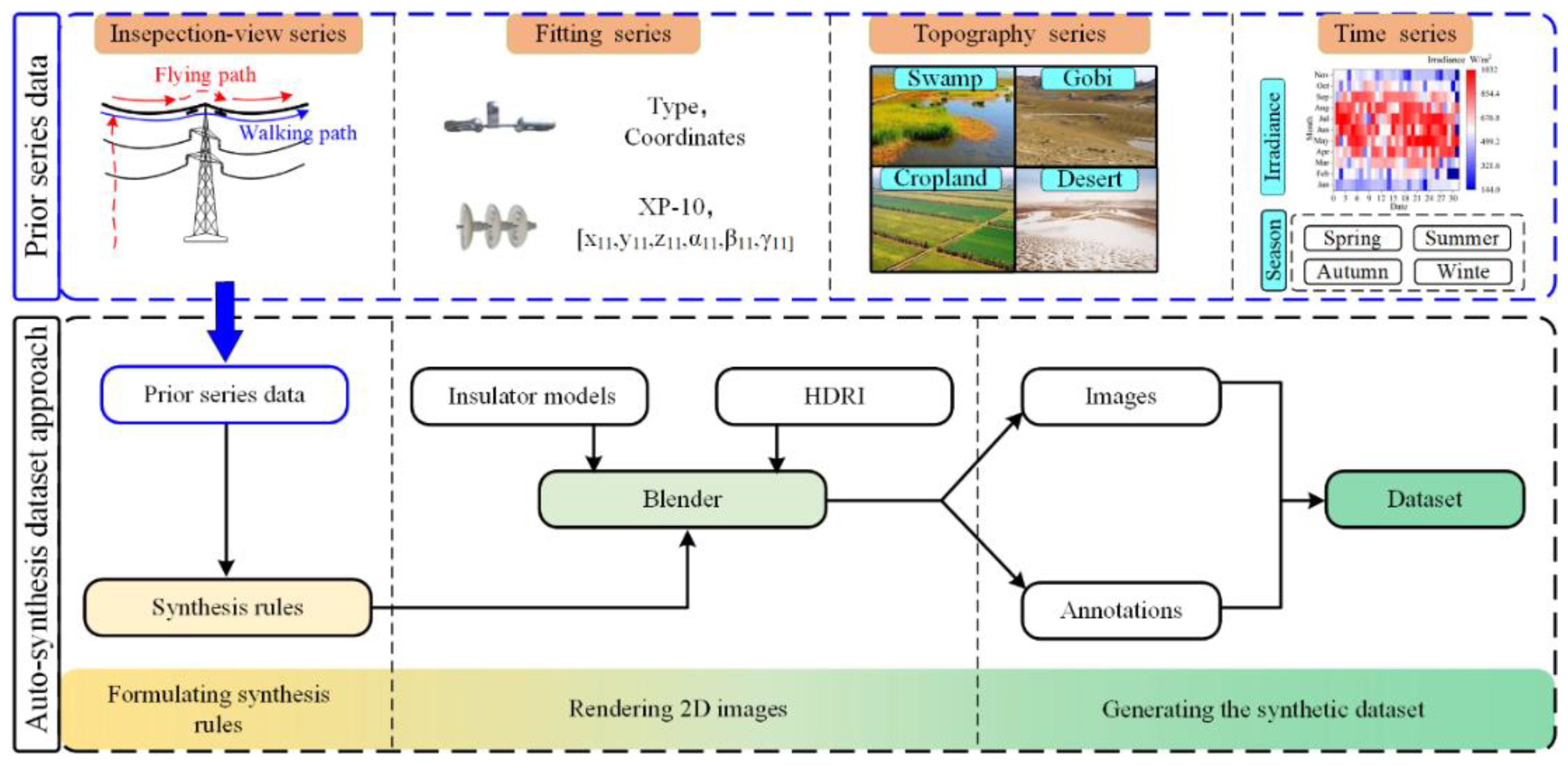
4.1. Prior Synthetic Dataset
| Algorithm 1 Auto-synthesis dataset algorithm |
| for hdris in hdri_file: # Traversing hdri files |
| for k in range(1, num_hdri): # Number of cycles per hdri |
| hdri_adjust() # Adjustment of environmental parameters |
| move() # Mobile fitting |
| light() # Adjusting ambient light |
| save(save_name_image ) # Output RGB image |
| bpy.data.worlds[“World”].node_tree.nodes[“Background”].inputs [1].default_value = 1 # Disconnecting background nodes |
| save(save_name_nobackground_image ) # Output background-free image |
| cv_label() # Automatic annotation |
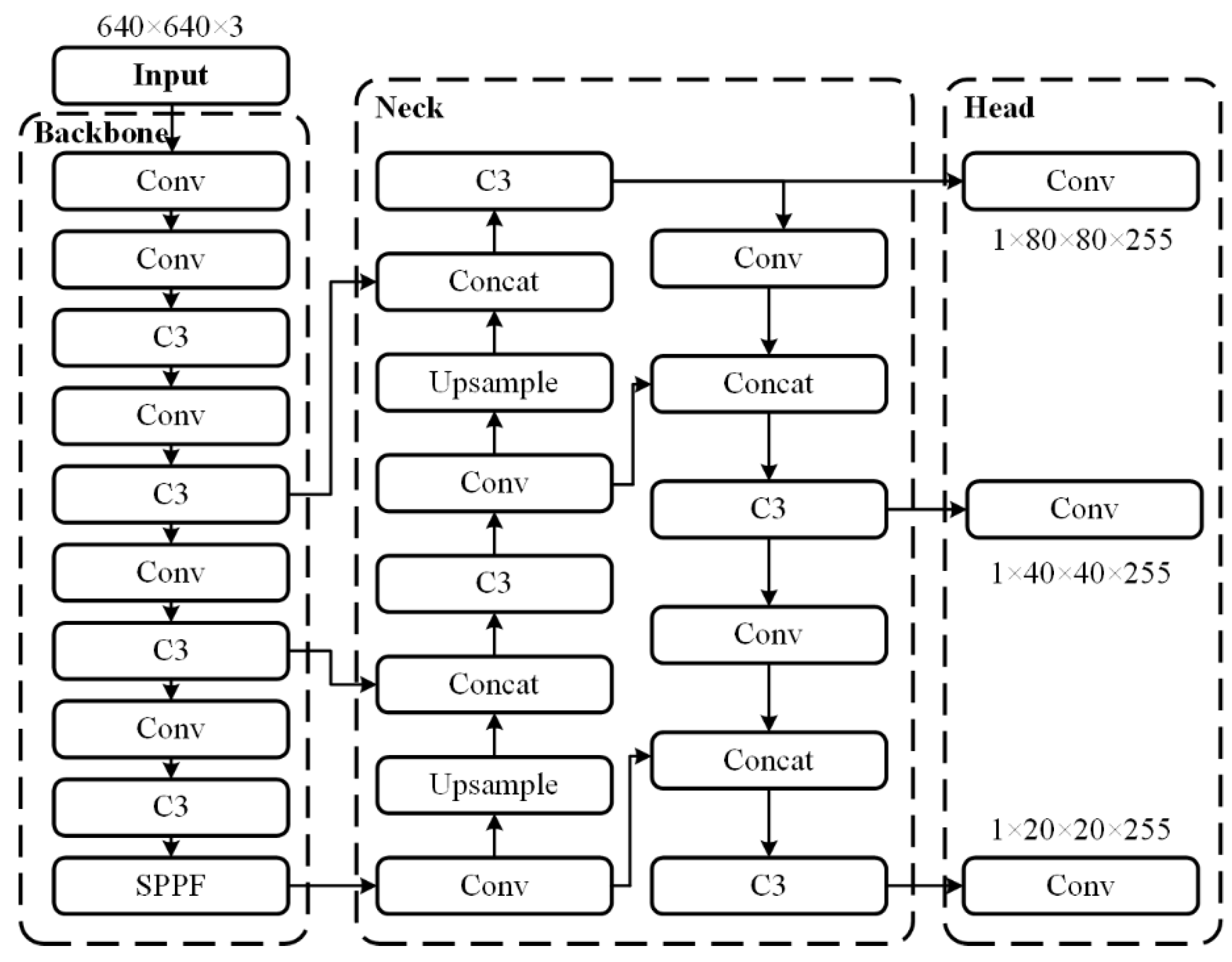
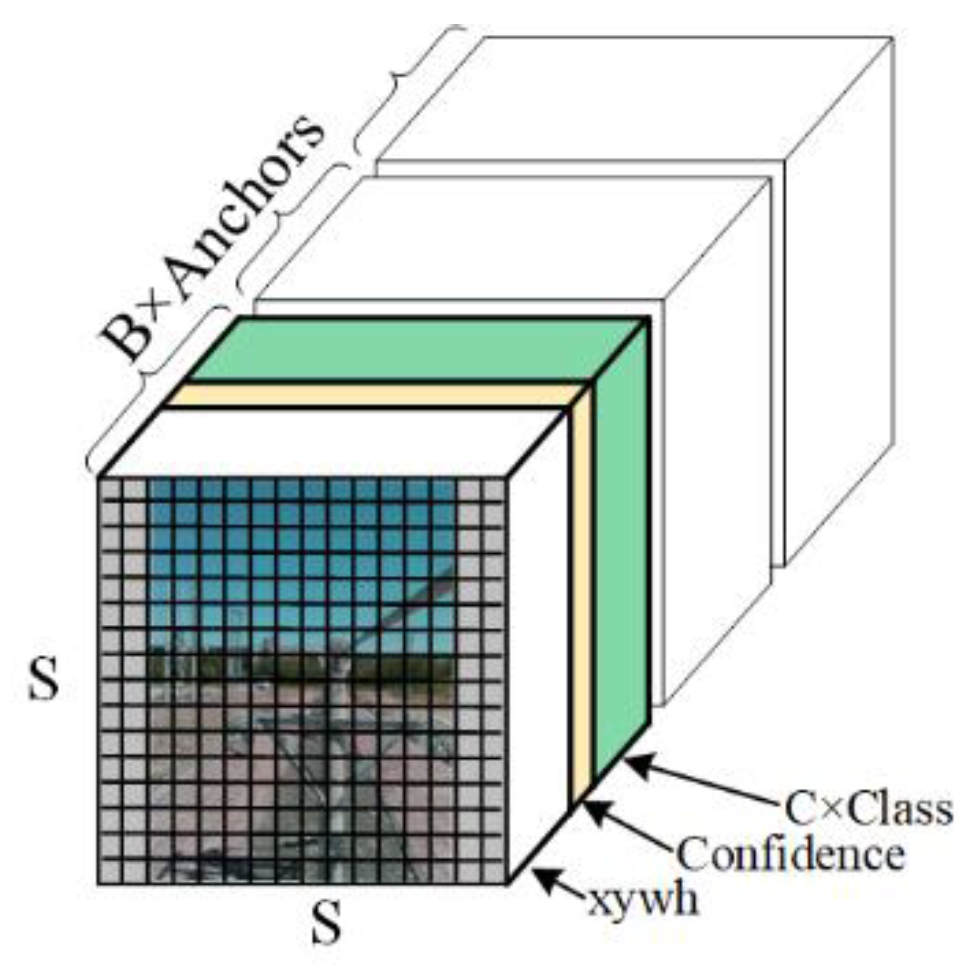
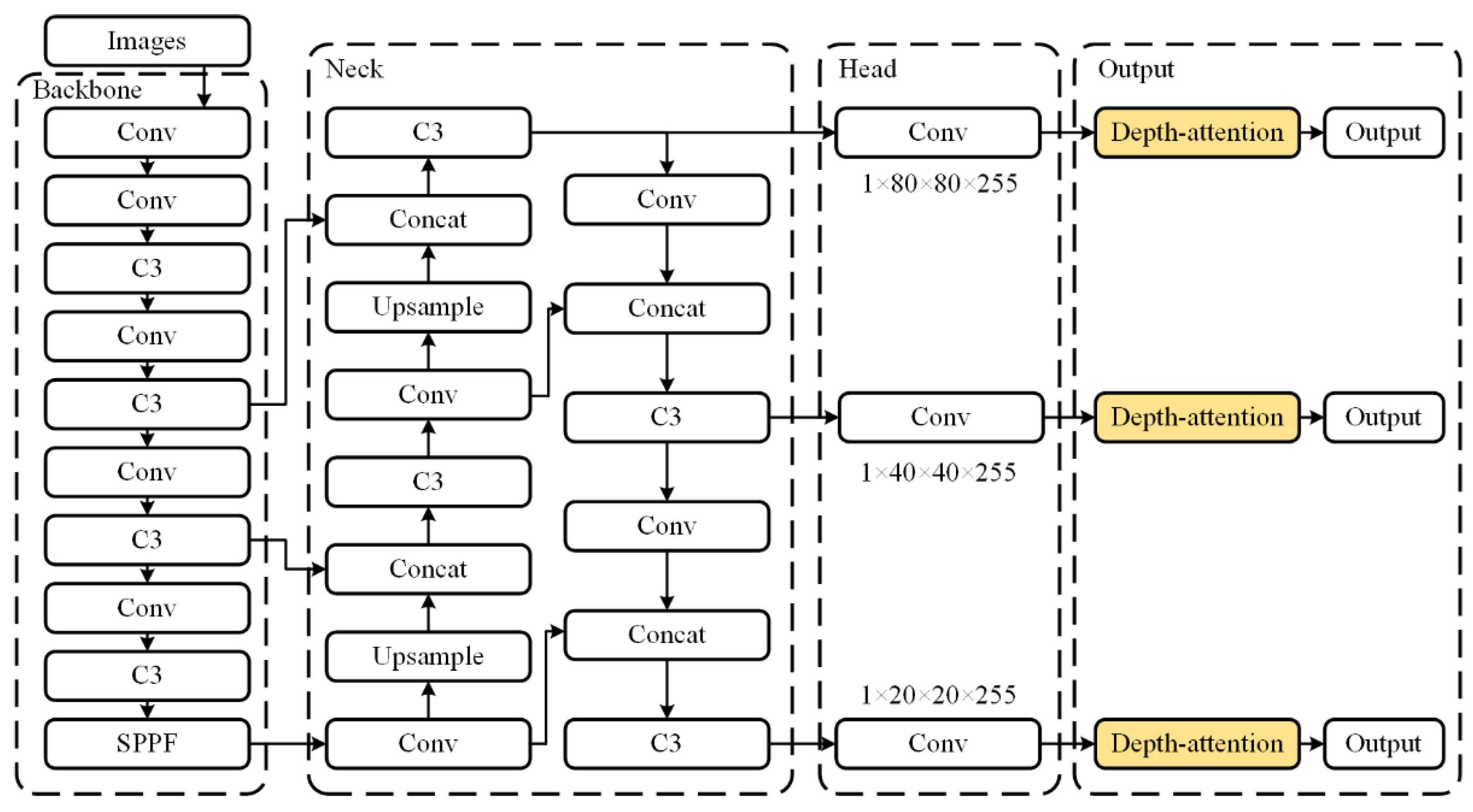
4.2. YOLOv5 Network Model
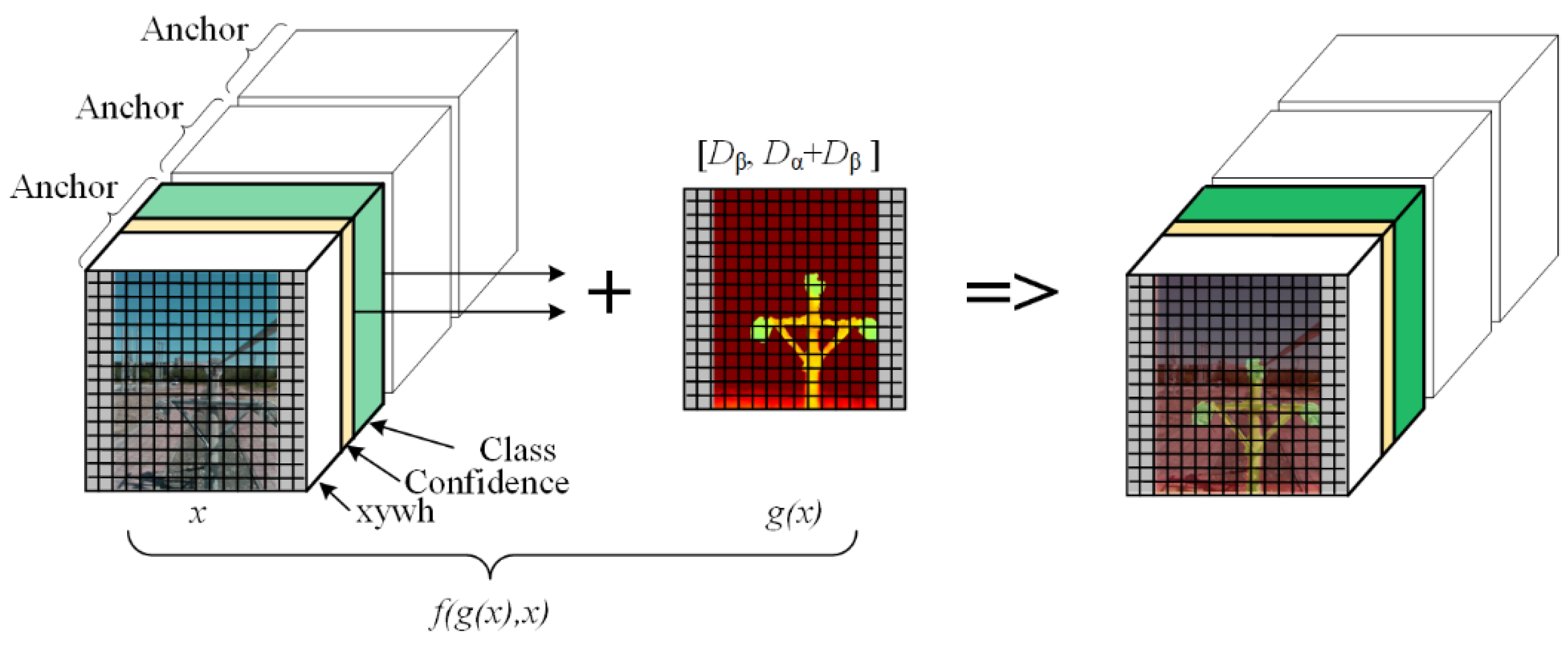
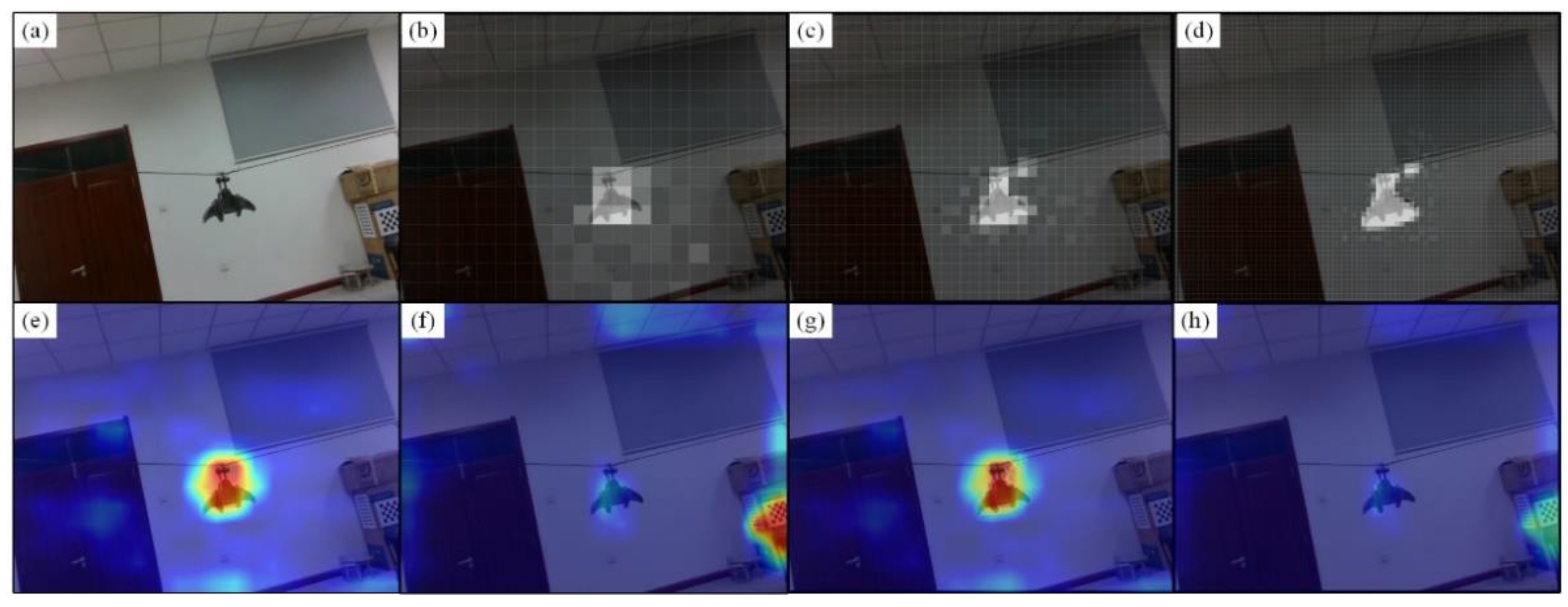
4.3. Depth-Attention Mechanism
4.3.1. Principle of Depth-Attention
4.3.2. Depth-Attention Matrix
5. Experiments and Results
5.1. Test Field Experiment
- A fitting dataset is synthesized, and a standard YOLOv5 model is trained.
- A depth-attention is introduced in YOLOv5, comparing the recognition results of the standard YOLOv5 and depth-attention YOLOv5 on the test.
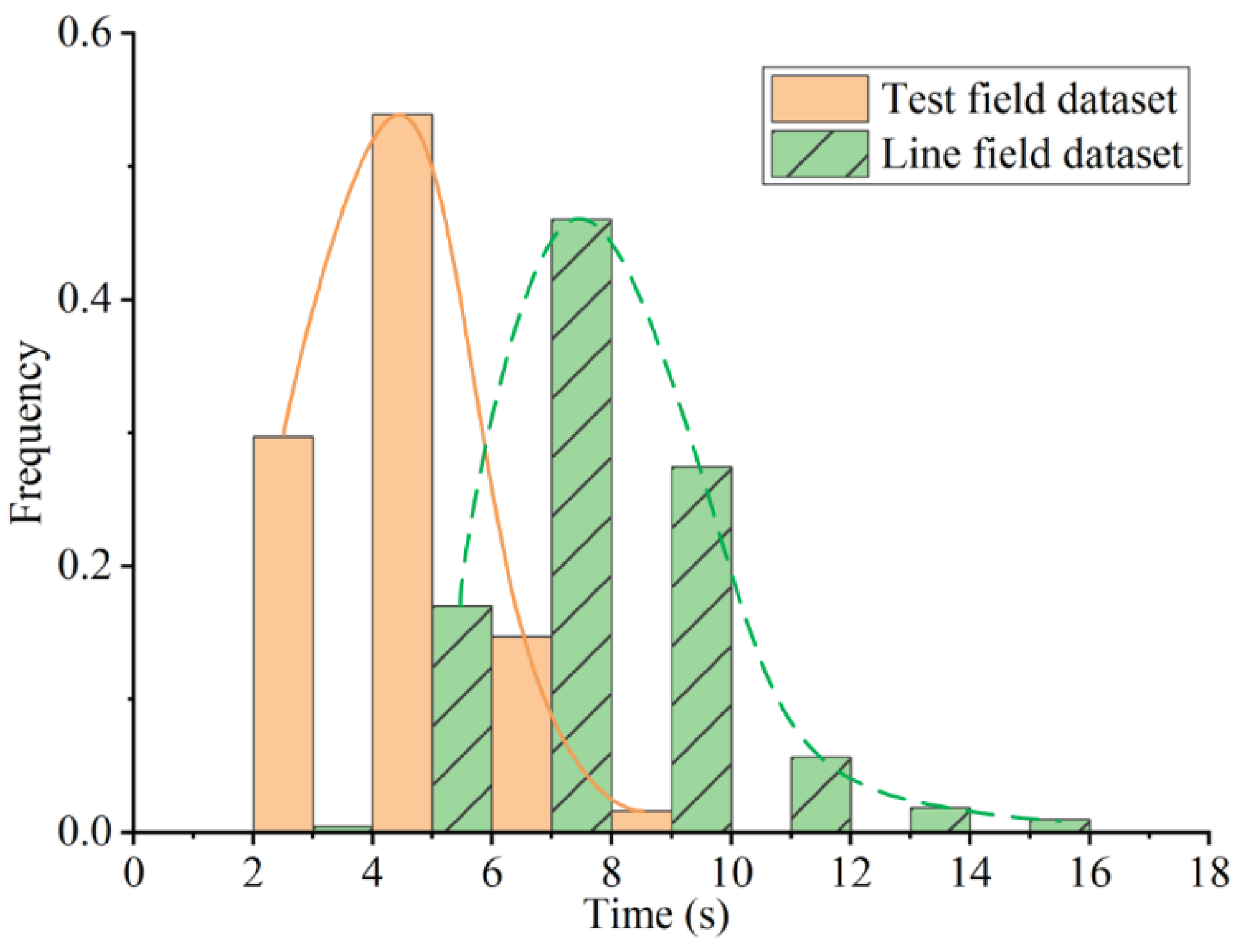
5.1.1. Datasets
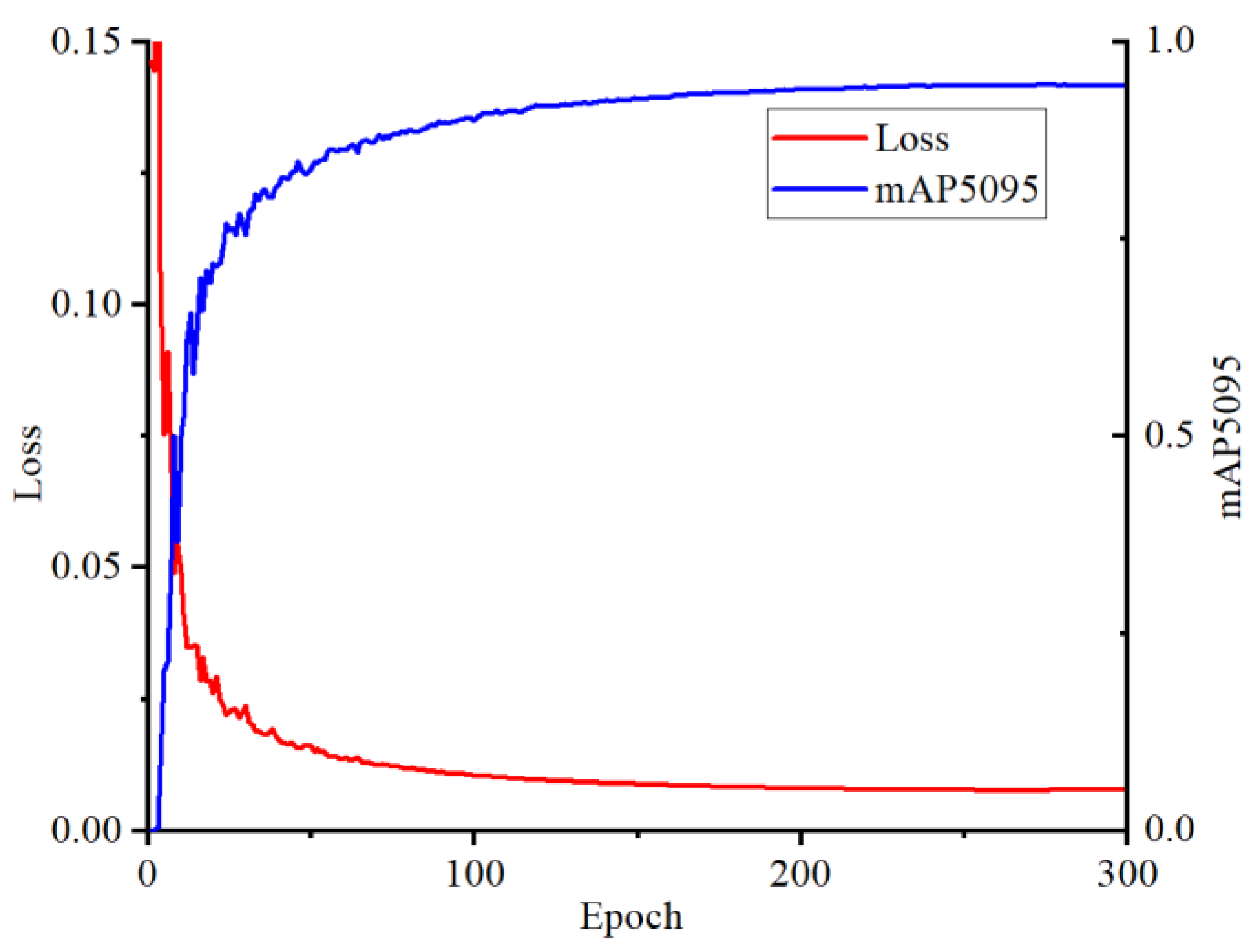
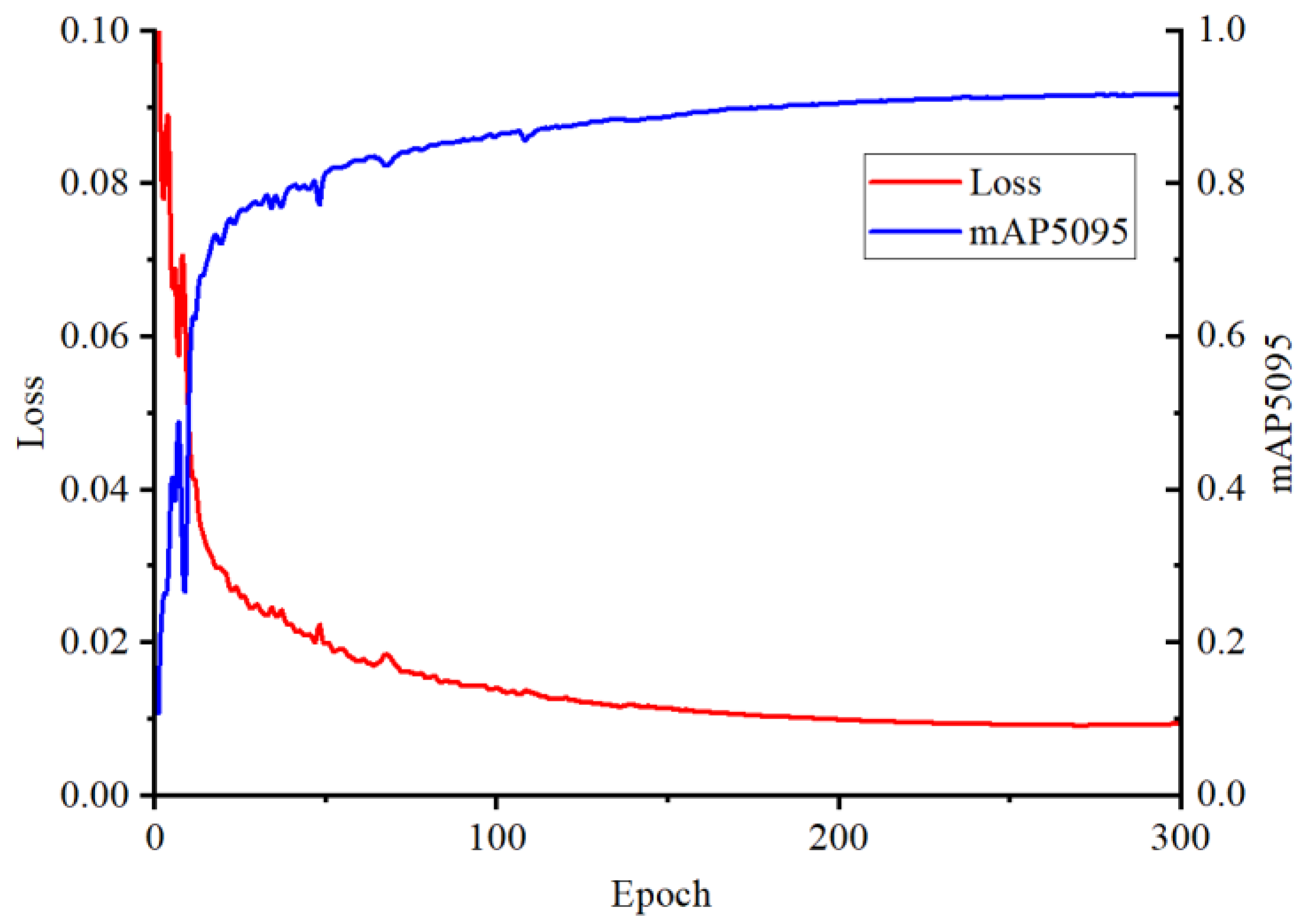
5.1.2. Training
5.1.3. Comparison between YOLOv5s and Our Proposed Method
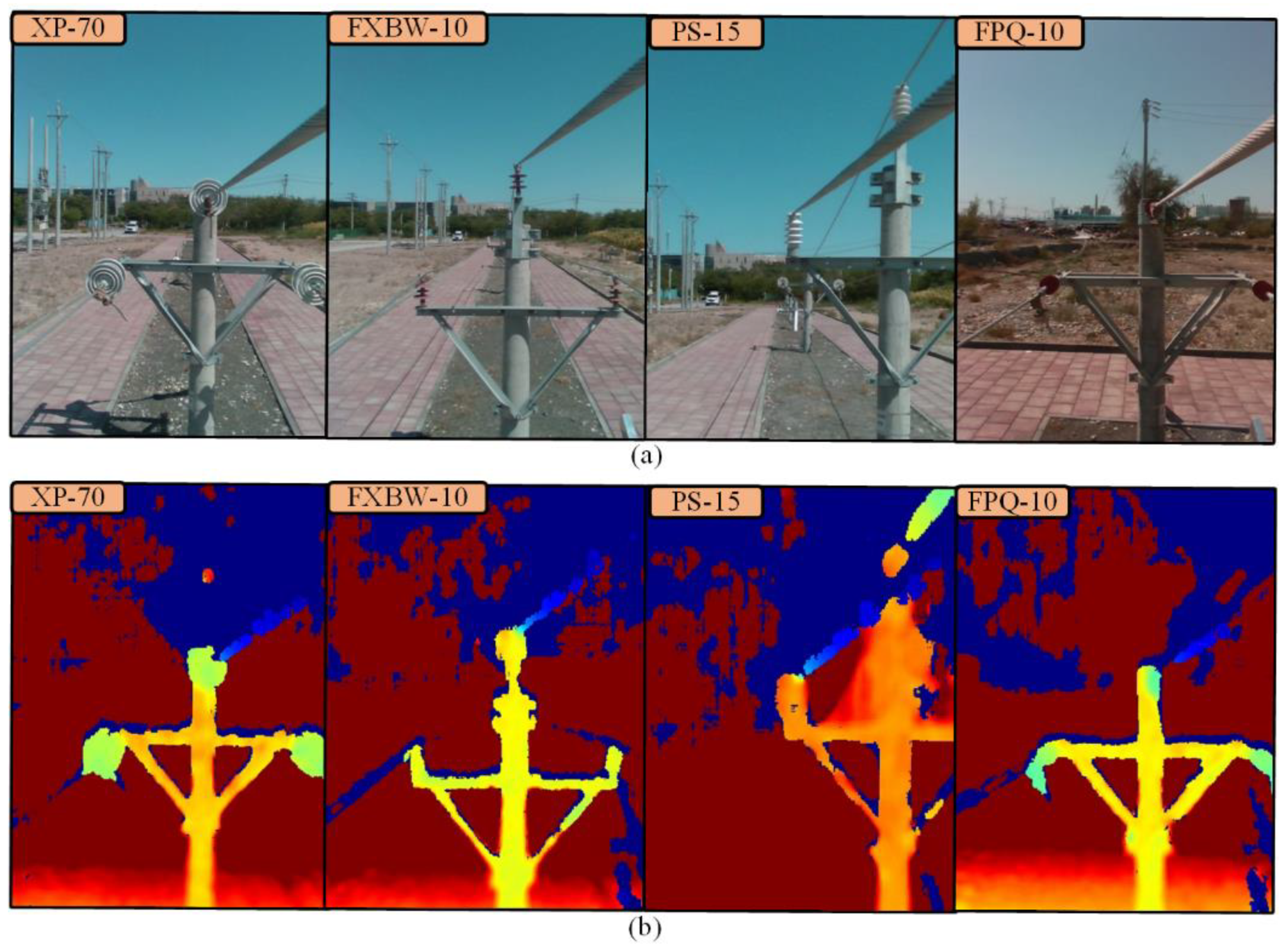
5.2. Line Field Experiment
5.2.1. Test Site
5.2.2. Synthetic Dataset
5.2.3. Test Dataset
5.2.4. Training
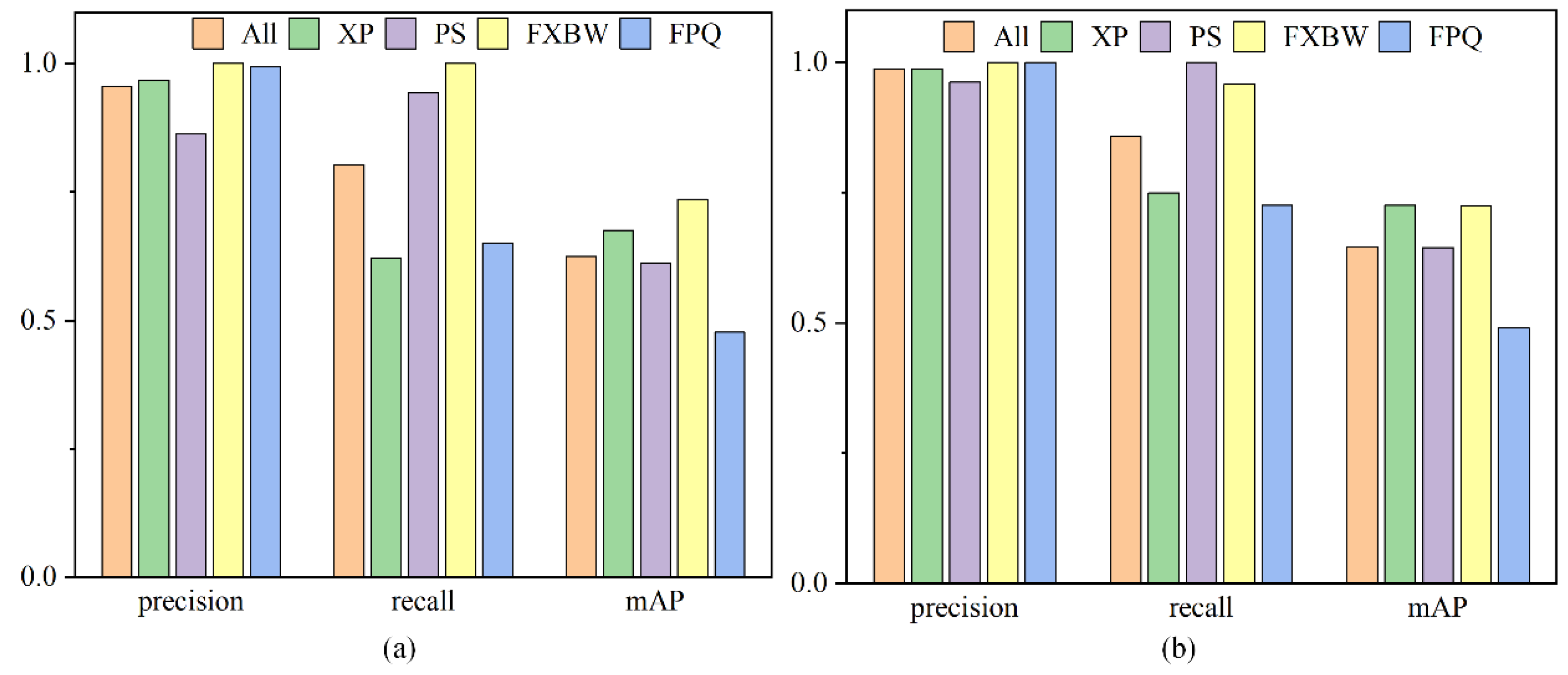
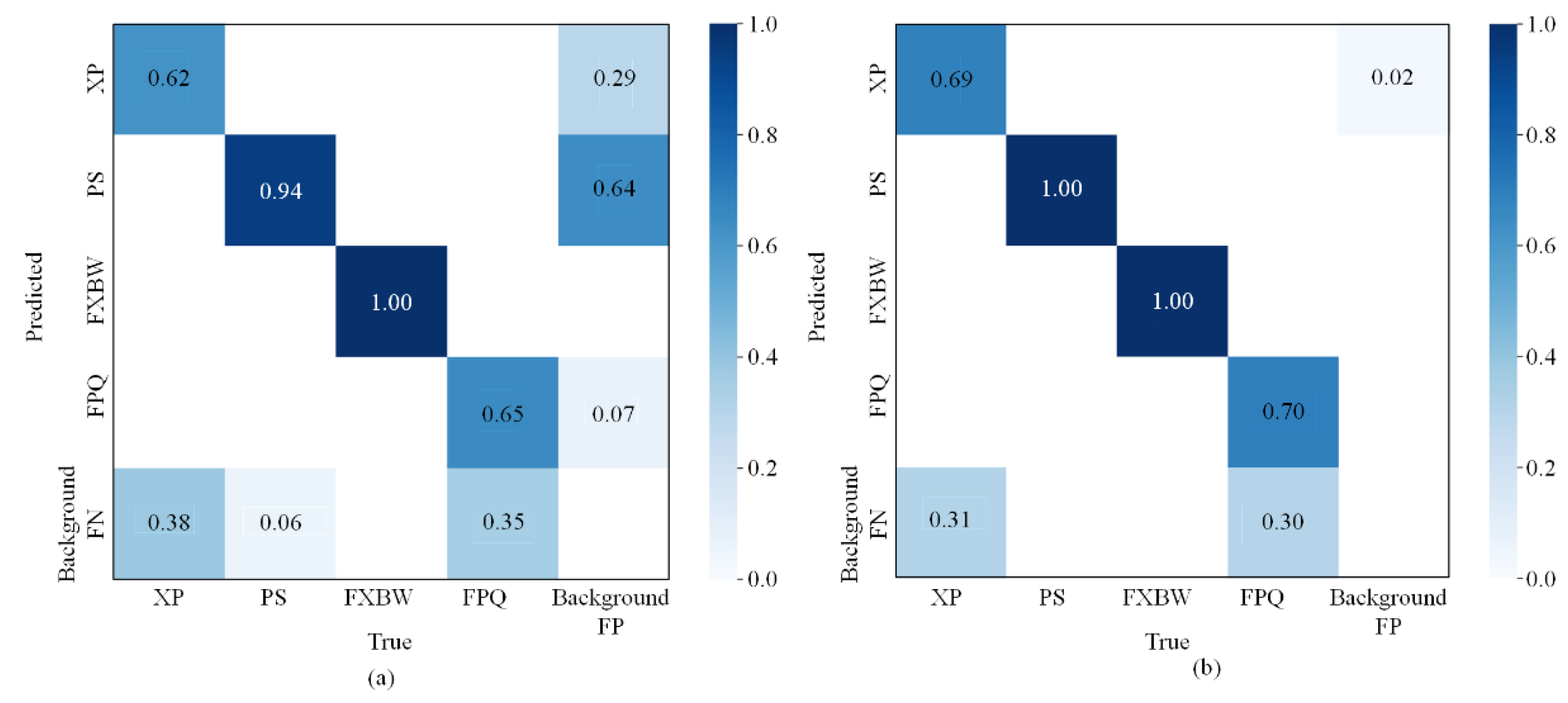
5.2.5. Experimental Results in Test Dataset
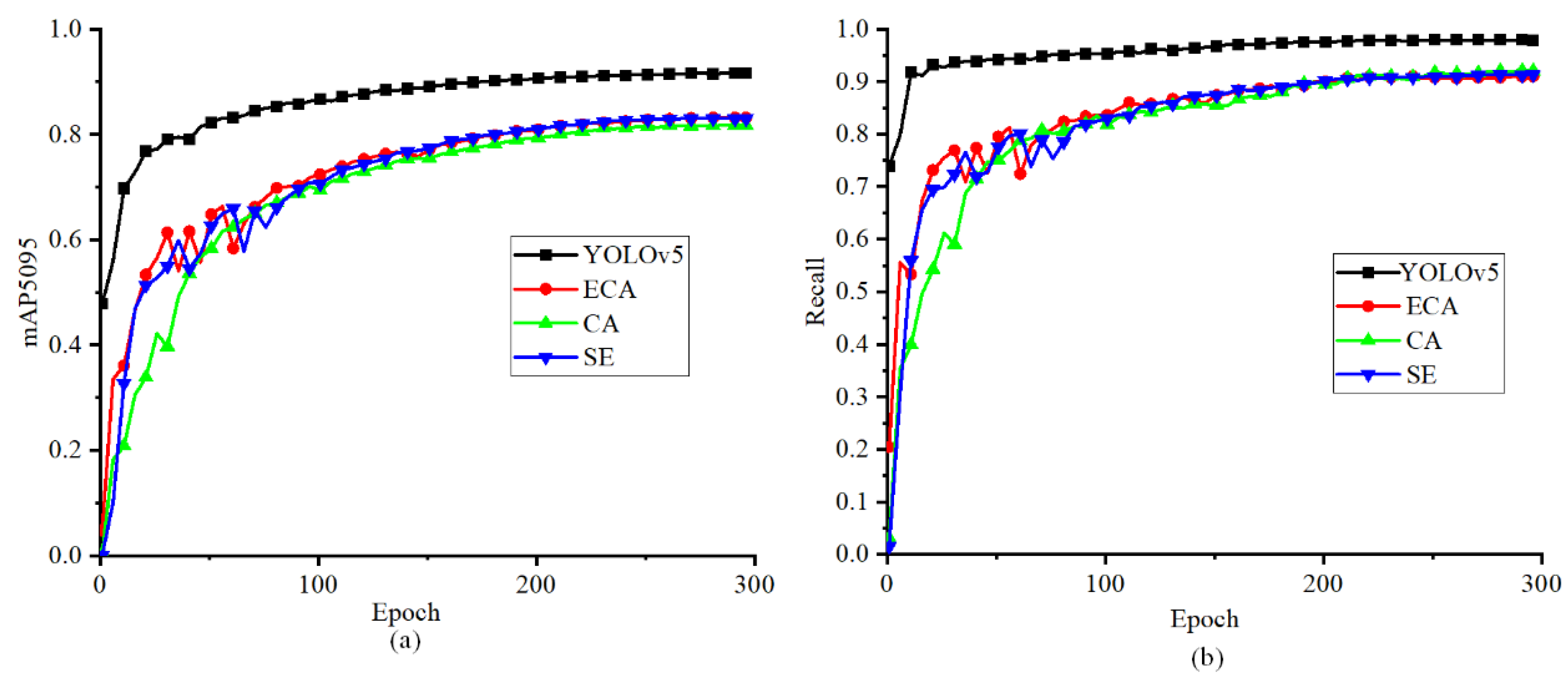
5.2.6. Comparison with the Recognition Results Using Different Attentional Mechanisms
6. Discussion
6.1. Time-Cost Synthetic Dataset
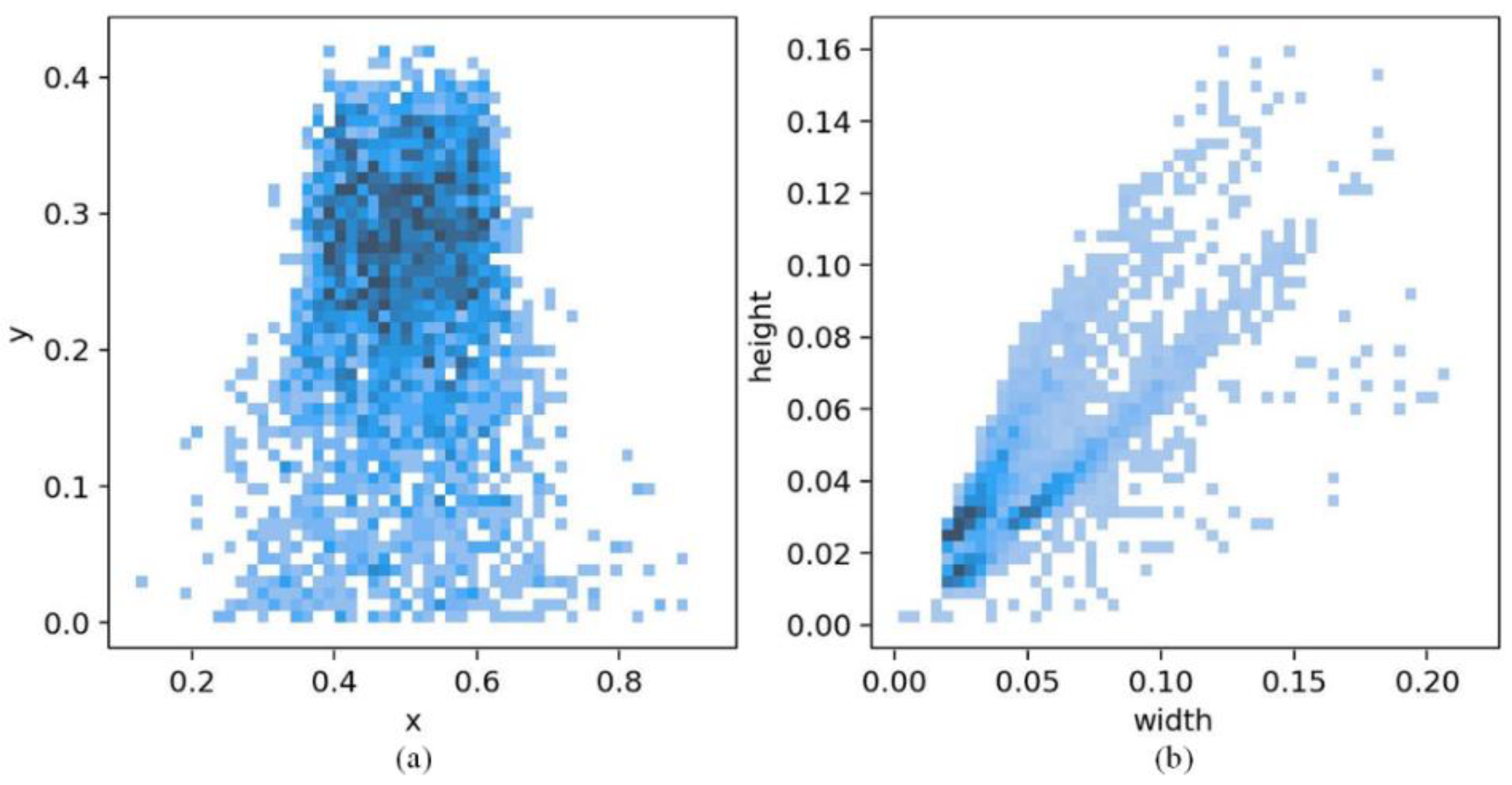
6.2. Influence of Increasing Dataset Volume on Results
6.3. The Effect of Dα and Dβ on the Depth-Attention Mechanism
6.4. Substitution of Depth Information
7. Conclusions
- Datasets are automatically synthesized based on prior series data, expediting the efficiency of algorithm development. Three synthetic datasets are generated, including a dataset of 4000 images with a size of 640 × 480 on the test field, a dataset of 4000 images with a size of 720 × 1280 on line field, and a dataset of 8000 XP images with a size of 640 × 480. The synthetic datasets spend 26.4 h, and the synthetic dataset with the largest volume takes 12.6 h.
- Depth-attention mechanism is proposed based on the depth difference of collected data, applying to target recognition with depth difference information. The test field experiments verify the feasibility of the depth-attention mechanism to improve the accuracy of the YOLOv5 model. Among them, AP, recall, and precision are 68.1%, 98.3%, and 98.3%, increasing by 5.2%, 4.8%, and 4.1%, respectively.
- The depth-attention YOLOv5 model is trained using a synthetic dataset for real line experiments, and the results show that the depth-attention mechanism acquires a map of 64.6%, improving mAP by 3.2%. Compared with other attention mechanisms, the depth-attention mechanism improves the mAP in all aspects and reduces omission and misdetection, providing better results and faster inference.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Luo, Y.; Yu, X.; Yang, D.; Zhou, B. A survey of intelligent transmission line inspection based on unmanned aerial vehicle. Artif. Intell. Rev. 2022, in press. [Google Scholar] [CrossRef]
- Yang, L.; Fan, J.; Liu, Y.; Li, E.; Peng, J.; Liang, Z. A Review on State-of-the-Art Power Line Inspection Techniques. IEEE Trans. Instrum. Meas. 2020, 69, 9350–9365. [Google Scholar] [CrossRef]
- Fan, F.; Wu, G.; Wang, M.; Cao, Q.; Yang, S. Multi-Robot Cyber Physical System for Sensing Environmental Variables of Transmission Line. Sensors 2018, 18, 3146. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xinyan, Q.; Gongping, W.; Jin, L. Detecting Inspection Objects of Power Line from Cable Inspection Robot LiDAR Data. Sensors 2018, 18, 1284. [Google Scholar] [CrossRef] [Green Version]
- Qin, X.; Wu, G.; Lei, J.; Fan, F.; Ye, X.; Mei, Q. A novel method of autonomous inspection for transmission line based on cable inspection robot lidar data. Sensors 2018, 18, 596. [Google Scholar] [CrossRef] [Green Version]
- Bian, J.; Hui, X.; Zhao, X.; Tan, M. A novel monocular-based navigation approach for UAV autonomous transmission-line inspection. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Bian, J.; Hui, X.; Zhao, X.; Tan, M. A point-line-based SLAM framework for UAV close proximity transmission tower inspection. In Proceedings of the 2018 IEEE International Conference on Robotics and Biomimetics (ROBIO), Kuala Lumpur, Malaysia, 12–15 December 2018; pp. 1016–1021. [Google Scholar] [CrossRef]
- Alhassan, A.B.; Zhang, X.; Shen, H.; Xu, H. Power transmission line inspection robots: A review, trends and challenges for future research. Int. J. Electr. Power Energy Syst. 2020, 118, 105862. [Google Scholar] [CrossRef]
- Yu, Y.; Cao, H.; Wang, Z.; Li, Y.; Li, K.; Xie, S. Texture-and-shape based active contour model for insulator segmentation. IEEE Access 2019, 7, 78706–78714. [Google Scholar] [CrossRef]
- Yao, X.; Liu, L.; Li, Z.; Cheng, X. Identification method of railway insulator based on edge features. IOP Conf. Ser. Mater. Sci. Eng. 2018, 394, 32023. [Google Scholar] [CrossRef]
- Zhai, Y.; Chen, R.; Yang, Q.; Li, X.; Zhao, Z. Insulator fault detection based on spatial morphological features of aerial images. IEEE Access 2018, 6, 35316–35326. [Google Scholar] [CrossRef]
- Pernebayeva, D.; Irmanova, A.; Sadykova, D.; Bagheri, M.; James, A. High voltage outdoor insulator surface condition evaluation using aerial insulator images. High Volt. 2019, 4, 178–185. [Google Scholar] [CrossRef]
- Miao, X.; Liu, X.; Chen, J.; Zhuang, S.; Fan, J.; Jiang, H. Insulator detection in aerial images for transmission line inspection using single shot multibox detector. IEEE Access 2019, 7, 9945–9956. [Google Scholar] [CrossRef]
- Jianhua, W.; Yijin, L.; Shaotong, P.; Lihui, L.; Yunpeng, L. Infrared evaluation classification method for deteriorated insulator based on Bayesian algorithm. J. Phys. Conf. Ser. 2019, 1314, 12080. [Google Scholar] [CrossRef]
- Lin, T.; Liu, X. An intelligent recognition system for insulator string defects based on dimension correction and optimized faster R-CNN. Electr. Eng. 2021, 103, 541–549. [Google Scholar] [CrossRef]
- Ayoub, N.; Schneider-Kamp, P. Real-Time On-Board Deep Learning Fault Detection for Autonomous UAV Inspections. Electronics 2021, 10, 1091. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar] [CrossRef]
- Xu, S.; Wang, X.; Lv, W.; Chang, Q.; Cui, C.; Deng, K.; Wang, G.; Dang, Q.; Wei, S.; Du, Y. PP-YOLOE: An evolved version of YOLO. arXiv 2022, arXiv:2203.16250. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar] [CrossRef]
- Rahman, E.U.; Zhang, Y.; Ahmad, S.; Ahmad, H.I.; Jobaer, S. Autonomous vision-based primary distribution systems porcelain insulators inspection using UAVs. Sensors 2021, 21, 974. [Google Scholar] [CrossRef] [PubMed]
- Tao, X.; Zhang, D.; Wang, Z.; Liu, X.; Zhang, H.; Xu, D. Detection of Power Line Insulator Defects Using Aerial Images Analyzed With Convolutional Neural Networks. IEEE Trans. Syst. Man Cybern. Syst. 2020, 50, 1486–1498. [Google Scholar] [CrossRef]
- Zhang, J.; Qin, X.; Lei, J.; Jia, B.; Li, B.; Li, Z.; Li, H.; Zeng, Y.; Song, J. A Novel Auto-Synthesis Dataset Approach for Fitting Recognition Using Prior Series Data. Sensors 2022, 22, 4364. [Google Scholar] [CrossRef] [PubMed]
- Zengin, A.T.; Erdemir, G.; Akinci, T.C.; Seker, S. Measurement of Power Line Sagging Using Sensor Data of a Power Line Inspection Robot. IEEE Access 2020, 8, 99198–99204. [Google Scholar] [CrossRef]
- Gulzar, M.A.; Kumar, K.; Javed, M.A.; Sharif, M. High-voltage transmission line inspection robot. In Proceedings of the 2018 International Conference on Engineering and Emerging Technologies (ICEET), Lahore, Pakistan, 22–23 February 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Richard, P.L.; Pouliot, N.; Morin, F.; Lepage, M.; Hamelin, P.; Lagac, M.; Sartor, A.; Lambert, G.; Montambault, S. LineRanger: Analysis and Field Testing of an Innovative Robot for Efficient Assessment of Bundled High-Voltage Powerlines. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 9130–9136. [Google Scholar] [CrossRef]
- Lima, E.J.; Bomfim, M.H.S.; de Miranda Mourão, M.A. POLIBOT–power lines inspection robot. Ind. Robot. Int. J. 2017, 45, 98–109. [Google Scholar] [CrossRef]
- Mirallès, F.; Hamelin, P.; Lambert, G.; Lavoie, S.; Pouliot, N.; Montfrond, M.; Montambault, S. LineDrone Technology: Landing an Unmanned Aerial Vehicle on a Power Line. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 6545–6552. [Google Scholar] [CrossRef]
- Yue, X.; Feng, Y.; Jiang, B.; Wang, L.; Hou, J. Automatic Obstacle-Crossing Planning for a Transmission Line Inspection Robot Based on Multisensor Fusion. IEEE Access 2022, 10, 63971–63983. [Google Scholar] [CrossRef]
- Qin, X.; Jia, B.; Lei, J.; Zhang, J.; Li, H.; Li, B.; Li, Z. A novel flying–walking power line inspection robot and stability analysis hanging on the line under wind loads. Mech. Sci. 2022, 13, 257–273. [Google Scholar] [CrossRef]
- Wang, H.; Li, E.; Yang, G.; Guo, R. Design of an Inspection Robot System with Hybrid Operation Modes for Power Transmission Lines. In Proceedings of the 2019 IEEE International Conference on Mechatronics and Automation (ICMA), Tianjin, China, 4–7 August 2019; pp. 2571–2576. [Google Scholar] [CrossRef]
- Chang, W.; Yang, G.; Yu, J.; Liang, Z.; Cheng, L.; Zhou, C. Development of a power line inspection robot with hybrid operation modes. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 973–978. [Google Scholar] [CrossRef]
- Jocher, G. Yolov5. Available online: https://github.com/ultralytics/yolov5 (accessed on 8 August 2022).
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Yuan, Y.; Huang, L.; Guo, J.; Zhang, C.; Chen, X.; Wang, J. Ocnet: Object context network for scene parsing. arXiv 2018, arXiv:1809.00916. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the Computer Vision(ECCV), Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. Fcanet: Frequency channel attention networks. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 783–792. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar] [CrossRef] [Green Version]
- Yang, L.; Zhang, R.-Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 11863–11874. [Google Scholar]
- Zhang, J. Fitting Synthetic Dataset (Insulator). Available online: https://github.com/zjlanthe/synthetic_data_insulator_blender (accessed on 8 August 2022).
- Guo, M.-H.; Xu, T.-X.; Liu, J.-J.; Liu, Z.-N.; Jiang, P.-T.; Mu, T.-J.; Zhang, S.-H.; Martin, R.R.; Cheng, M.-M.; Hu, S.-M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Brief Description | Quantity | Type | Website |
|---|---|---|---|---|
| Insulator [30] | Aerial images, including normal insulators and defective insulators (CPLID) | 848 | Real and Synthetic | https://github.com/InsulatorData/InsulatorDataSet (accessed on 30 October 2022) |
| Insulator [31] | Synthesis datasets based on prior series data using virtual models | 10,800 | Synthetic | https://github.com/zjlanthe/synthetic_data_insulator_blender (accessed on 30 October 2022) |
| Insulator [29] | Low- to medium-voltage porcelain insulators | 5939 | Real | https://ieee-dataport.org/open-access/low-medium-voltage-porcelain-insulators-primary-distribution-systems-dataset (accessed on 30 October 2022) |
| Insulator | The insulator defect image dataset (IDID) | 1596 | Real | https://ieee-dataport.org/competitions/insulator-defect-detection (accessed on 30 October 2022) |
| Component Name | Mode | Amount | |
|---|---|---|---|
| FPTLIR body | Flying mode | 1 | |
| Walking mode | 1 | ||
| Cameras | D-RGB cameras | D435i | 1 |
| ZED | 1 | ||
| Inspection camera | SJ4000 | 1 | |
| Controllers | Central control | NVIDIA Jetson NX | 1 |
| Walking mode control | STM32 | 1 | |
| Flying mode control | PX4 | 1 | |
| Model | Fitting | mAP 50(%) | mAP 5095(%) | P | R | Inference Speed (ms) |
|---|---|---|---|---|---|---|
| YOLOv5 | XG | 96% | 62.9% | 0.942 | 0.935 | 7.9 |
| Depth-attention YOLOv5 | XG | 99% | 68.1% | 0.983 | 0.983 | 11 |
| Object | Fitting Coordinates(m) | Fitting Rotation Angle (°) | Viewpoint Coordinates (m) | Illumination (W/m2) |
|---|---|---|---|---|
| XP-70 | x: [1, 6], y: [−0.5, 0.5], z: [2, 3] | α: 0, β: [−30, 30], γ: [70, 110], [−110, −70] | [0, 0, 2~3] | [0, 1000] |
| FXBW-10 | x: [1, 6], y: [−0.5, 0.5], z: [2, 3] | α: 0, β: [−30, 30], γ: [70, 110], [−110, −70] | [0, 0, 2~3] | [0, 1000] |
| PS-15 | x: [1, 6], y: [−0.5, 0.5], z: [2, 3] | α: [−30, 30], β: [−30, 30], γ: 0 | [0, 0, 2~3] | [0, 1000] |
| FPQ-10 | x: [1, 6], y: [−0.5, 0.5], z: [2, 3] | α: [−30, 30], β: [−30, 30], γ: 0 | [0, 0, 2~3] | [0, 1000] |
| Model | Add Location | Best Result Category | P | R | mAP 5095(%) | Inference Speed (ms) |
|---|---|---|---|---|---|---|
| YOLOv5 | - | All | 0.863 | 0.87 | 61.4% | 9.1 |
| XP | 0.92 | 0.78 | 70.4% | |||
| PS | 0.59 | 0.99 | 57.6% | |||
| FXBW | 1 | 0.907 | 69% | |||
| FPQ | 0.941 | 0.804 | 48.6% | |||
| ECA | C3 | PS | 0.943 | 1 | 68.2% | 27.3 |
| FXBW | 1 | 1 | 59.4% | |||
| CA | C3 | PS | 0.82 | 1 | 67% | 22.4 |
| FXBW | 1 | 0.863 | 62.6% | |||
| SE | C3 | PS | 0.98 | 1 | 69.2% * | 27.1 |
| FXBW | 1 | 1 | 59.7% | |||
| Depth-attention YOLOv5 | Head last | All | 0.987 | 0.858 | 64.6% * | 12.6 |
| XP | 0.987 | 0.749 | 72.6% * | |||
| PS | 0.962 | 1 | 64.4% | |||
| FXBW | 1 | 0.958 | 72.4% * | |||
| FPQ | 1 | 0.726 | 49.0% * |
| Model | Fitting | mAP 50(%) | mAP 5095(%) | P | R |
|---|---|---|---|---|---|
| YOLOv5 | XP | 97.8% | 80.5% | 1 | 0.957 |
| Depth-Attention YOLOv5 | XP | 98.8% | 80.8% | 1 | 0.977 |
| Dα | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| Dβ | |||||
| 0 | 64.30% | 64.60% | 64% | 64% | |
| −1 | 64.00% | 64.60% | 64.70% | 63.90% | |
| −2 | 63.40% | 64.20% | 64.60% | 64.10% | |
| −3 | - | 63.70% | 64.50% | 64.60% | |
| −4 | - | 63.10% | 64.20% | 64.60% | |
| −5 | - | - | 63.50% | 64.50% | |
| −6 | - | - | 63.20% | 64.10% | |
| −7 | - | - | - | 63.60% | |
| −8 | - | - | - | 63.00% | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Lei, J.; Qin, X.; Li, B.; Li, Z.; Li, H.; Zeng, Y.; Song, J. A Fitting Recognition Approach Combining Depth-Attention YOLOv5 and Prior Synthetic Dataset. Appl. Sci. 2022, 12, 11122. https://doi.org/10.3390/app122111122
Zhang J, Lei J, Qin X, Li B, Li Z, Li H, Zeng Y, Song J. A Fitting Recognition Approach Combining Depth-Attention YOLOv5 and Prior Synthetic Dataset. Applied Sciences. 2022; 12(21):11122. https://doi.org/10.3390/app122111122
Chicago/Turabian StyleZhang, Jie, Jin Lei, Xinyan Qin, Bo Li, Zhaojun Li, Huidong Li, Yujie Zeng, and Jie Song. 2022. "A Fitting Recognition Approach Combining Depth-Attention YOLOv5 and Prior Synthetic Dataset" Applied Sciences 12, no. 21: 11122. https://doi.org/10.3390/app122111122