

Distinction of Scrambled Linear Block Codes Based on Extraction of Correlation Features

Abstract
:1. Introduction
2. Scrambled Linear Block Code Model
3. Analysis of Correlation Characteristics of Scrambled Linear Block Code
3.1. Cross-Correlation Characteristics of Symbols
3.2. Biased Autocorrelation Characteristics of Symbols
4. Scrambled Linear Block Code Identification Based on Correlation Features Extraction Network
4.1. Correlation Feature Extraction Network Model
4.2. Network Training Process
4.3. Input–Output Relationship of Each Network Layer
5. Results
5.1. Experimental Dataset
5.2. Network Model Parameters
5.2.1. Effect of LSTM Layers and Parameters on Recognition Rate
5.2.2. Effect of CNN Layers and Parameters on Recognition Rate
5.3. Experimental Results
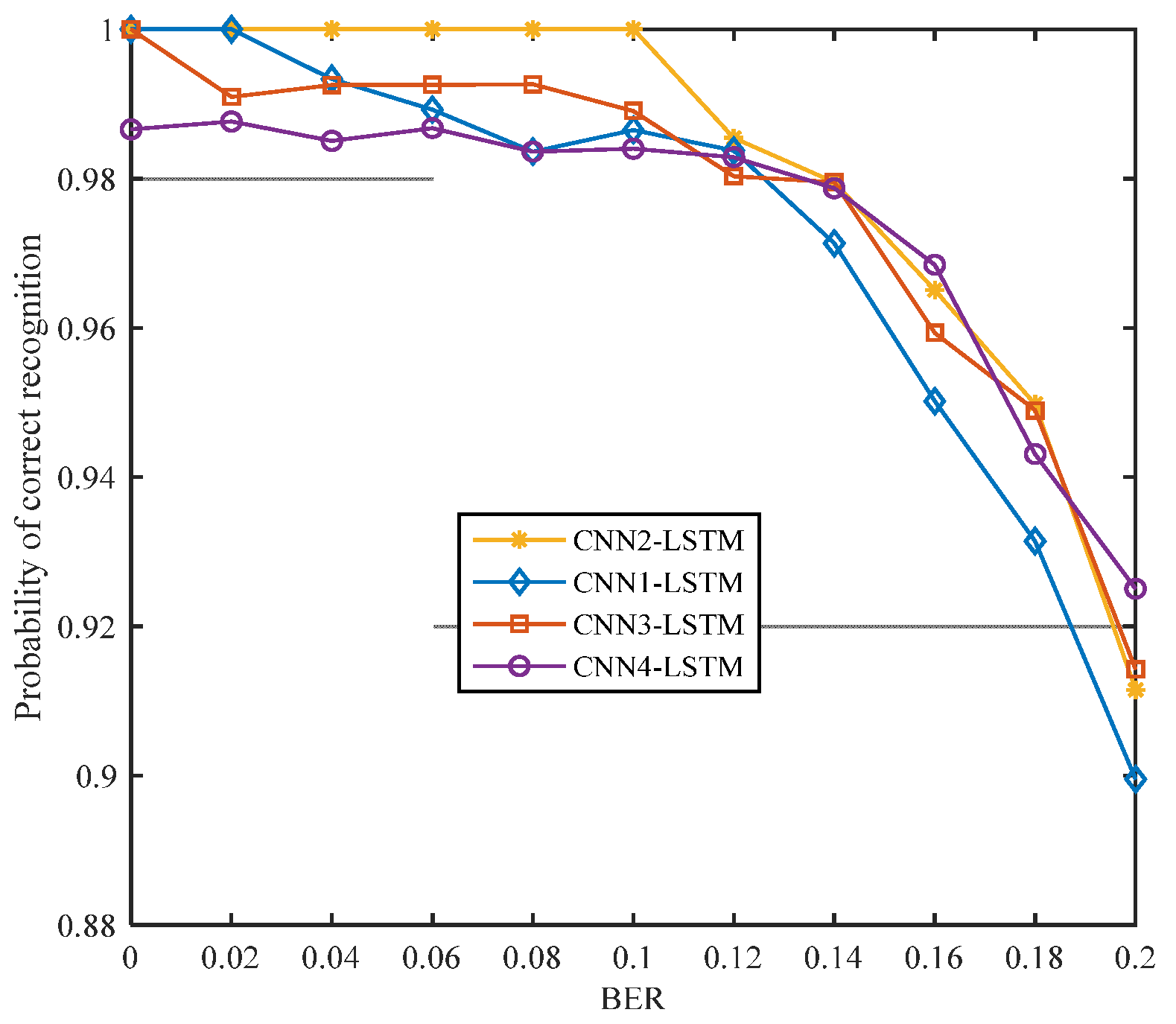
5.3.1. Recognition Rate of The Proposed Algorithm under Bit Error Condition
5.3.2. Recognition Rate of the Proposed Algorithm under the Condition of Gaussian White Noise
6. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, Z.L.; Peng, H. Scrambler blind recognition method based on soft information. J. Commun. 2017, 38, 174–182. [Google Scholar]
- Liang, C.; Wang, F.P.; Wang, Z.J. Low complexity method for spread sequence estimation of DSSS signal. Syst. Eng. Electron. 2009, 20, 41–49. [Google Scholar]
- Wu, L.P.; Li, Z.; Chen, L.C. A PN sequence estimation algorithm for DS signal based on average cross-correlation and eigen analysis in lower SNR conditions. Sci. China Inf. Sci. 2010, 53, 1666–1675. [Google Scholar] [CrossRef]
- Scholtz, R. The spread spectrum concept. IEEE Trans. Commun. 1997, 28, 748–755. [Google Scholar] [CrossRef]
- Ahlswede, R.; Csiszar, I. Common randomness in information theory and cryptography. I. Secret sharing. IEEE Trans. Inf. Theory 1993, 39, 1121–1132. [Google Scholar] [CrossRef]
- Jonsson, F.; Johansson, T. Theoretical analysis of a correlation attack based on convolutional codes. In Proceedings of the 2000 IEEE International Symposium on Information Theory, Sorrento, Italy, 6 August 2002. [Google Scholar] [CrossRef]
- Massey, J.L. Shift-register synthesis and BCH decoding. IEEE Trans. Inf. Theory 1969, 15, 122–127. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.B.; Koh, S.N.; Wu, X.W. Reconstructing a linear scrambler with improved detection capability and in the presence of noise. IEEE Trans. Inf. Forensics Secur. 2012, 7, 208–218. [Google Scholar] [CrossRef]
- Ma, Y.; Zhang, L.M. Reconstruction of Scrambler with Real-time Test. J. Electron. Inf. Technol. 2016, 38, 1794–1799. [Google Scholar]
- Xie, H.; Wang, F.H.; Huang, Z.T. Blind reconstruction of linear scrambler. J. Syst. Eng. Electron. 2014, 25, 560–565. [Google Scholar] [CrossRef]
- Cluzeau, M. Reconstruction of a Linear Scrambler. IEEE Trans. Comput. 2007, 56, 1283–1291. [Google Scholar] [CrossRef]
- Vijayakumaran, S. LFSR identification using Groebner bases. In Proceedings of the Twenty Second National Conference on Communication, Guwahati, India, 4–6 March 2016. [Google Scholar] [CrossRef]
- Xie, H.; Han, Z.Z.; Ding, S. Scrambling Sequence Estimation Method Based on Propagation Operator Algorithm. J. Syst. Eng. Electron. 2017, 39, 2327–2332. [Google Scholar]
- Guo, X.; Su, S.; Qian, H. Scrambling Code Blind Identification in SDH Signal Intelligent Reception. In Proceedings of the 2021 2nd Information Communication Technologies Conference (ICTC), Nanjing, China, 7–9 May 2021. [Google Scholar] [CrossRef]
- Zhang, L.M.; Tan, J.Y.; Zhong, Z.G. Blind identification of self-synchronous scrambling codes based on cosine coincidence. J. Electron. Inf. Technol. 2022, 44, 1412–1420. [Google Scholar]
- Tan, J.Y.; Zhang, L.M.; Zhong, Z.G. Reconstruction of a Synchronous Scrambler Based on Average Check Conformity. Math. Probl. Eng. 2022, 2022, 6318317. [Google Scholar] [CrossRef]
- Liu, X.B.; Koh, S.N.; Chui, C.C. A Study on Reconstruction of Linear Scrambler Using Dual Words of Channel Encoder. IEEE Trans. Inf. Forensics Secur. 2013, 8, 542–552. [Google Scholar] [CrossRef]
- Ma, Y.; Zhang, L.M.; Wang, H.T. Reconstructing Synchronous Scrambler With Robust Detection Capability in the Presence of Noise. J. Commun. 2015, 10, 397–408. [Google Scholar]
- Zhang, M.; Lv, Q.T.; Zhu, Y.X. Blind identification of self-synchronous scrambling codes based on linear block codes. J. Appl. Sci. 2015, 33, 178–186. [Google Scholar]
- Shu, N.H.; Min, Z.; Xin, H.L. Reconstruction of Feedback Polynomial of Synchronous Scrambler Based on Triple Correlation Characteristics of M-sequences. Ieice Trans. Commun. 2018, E101.B, 1723–1732. [Google Scholar]
- Han, S.; Zhang, M. A Method for Blind Identification of a Scrambler Based on Matrix Analysis. IEEE Commun. Lett. 2018, 22, 2198–2201. [Google Scholar] [CrossRef]
- Gu, X.; Zhao, Z.; Shen, L. Blind estimation of pseudo-random codes in periodic long code direct sequence spread spectrum signals. IET Commun. 2016, 10, 1273–1281. [Google Scholar] [CrossRef]
- Kim, D.; Song, J.; Yoon, D. On the Estimation of Synchronous Scramblers in Direct Sequence Spread Spectrum Systems. IEEE Access 2020, 8, 166450–166459. [Google Scholar] [CrossRef]
- Kim, D.; Yoon, D. Blind Estimation of Self-Synchronous Scrambler in DSSS Systems. IEEE Access 2021, 9, 76976–76982. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, J.; Song, J. Blind Estimation of Self-Synchronous Scrambler Using Orthogonal Complement Space in DSSS Systems. IEEE Access 2022, 10, 66522–66528. [Google Scholar] [CrossRef]
- Li, X.H.; Zhang, M.; Han, S.N. Distinction of self-synchronous scrambled linear block codes based on multi-fractal spectrum. J. Syst. Eng. Electron. 2016, 27, 968–978. [Google Scholar] [CrossRef]
- Wang, Z.F.; Zhai, L.Q.; Wei, D. Blind Recognition Algorithm for Scrambled Channel Encoder Based on the Features of Signal Matrix and Layered Neural Network. In Proceedings of the 2021 15th International Symposium on Medical Information and Communication Technology (ISMICT), Xiamen, China, 14–16 April 2021. [Google Scholar] [CrossRef]
- Song, Y.Q.; Liu, F.; Shen, T.S. A novel noise reduction technique for underwater acoustic signals based on dual-path recurrent neural network. IET Commun. 2022; in press. [Google Scholar] [CrossRef]
- Gong, W.; Tian, J.; Liu, J. Underwater Object Classification Method Based on Depth wise Separable Convolution Feature Fusion in Sonar Images. Appl. Sci. 2022, 12, 3268. [Google Scholar] [CrossRef]
- O’Shea, T.J.; Corgan, J.; Clancy, T.C. Convolutional Radio Modulation Recognition Networks. In Proceedings of the International Conference on Engineering Applications of Neural Networks, Aberdeen, UK, 2–5 September 2016; pp. 213–226. [Google Scholar] [CrossRef] [Green Version]
- Saif, W.S.; Ragheb, A.M. Performance Investigation of Modulation Format Identification in Super-Channel Optical Networks. IEEE Photonics J. 2022, 14, 8514910. [Google Scholar] [CrossRef]
- Acarturk, C.; Sirlanci, M.; Balikcioglu, P.G. Malicious Code Detection: Run Trace Output Analysis by LSTM. IEEE Access 2021, 9, 9625–9635. [Google Scholar] [CrossRef]
- Ahn, G.; Kim, K.; Park, W.; Shin, D. Malicious File Detection Method using Machine Learning and Interworking with MITRE ATT&CK Framework. Appl. Sci. 2022, 12, 10761. [Google Scholar] [CrossRef]
- Sagduyu, Y.E. Adversarial Deep Learning for Over-the-Air Spectrum Poisoning Attacks. IEEE Trans. Mob. Comput. 2020, 20, 306–319. [Google Scholar] [CrossRef] [Green Version]
- Pan, Y.W.; Yang, S.H.; Peng, H. Specific Emitter Identification Based on Deep Residual Networks. IEEE Access 2019, 7, 54425–54434. [Google Scholar] [CrossRef]
- Vaseghi, S.V. Advanced Digital Signal Processing and Noise Reduction, 4th ed.; John Wiley & Sons: New York, NY, USA, 2009. [Google Scholar]
- Xiao, Q.; Chang, X.; Zhang, X. Multi-Information Spatial–Temporal LSTM Fusion Continuous Sign Language Neural Machine Translation. IEEE Access 2020, 8, 216718–216728. [Google Scholar] [CrossRef]
- Bandara, K.; Bergmeir, C.; Hewamalage, H. LSTM-MSNet: Leveraging Forecasts on Sets of Related Time Series With Multiple Seasonal Patterns. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 1586–1599. [Google Scholar] [CrossRef] [PubMed]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Label | Number of Signals | Number of Samples |
|---|---|---|---|
| linear block code | 0 | 2000 | |
| self-synchronous scrambler | 1 | 2000 | |
| synchronous scrambler | 2 | 2000 |
| Dataset | Label | Number of Signals | Number of Samples |
|---|---|---|---|
| linear block code | 0 | 2000 | |
| self-synchronous scrambler | 1 | 2000 | |
| synchronous scrambler | 2 | 2000 |
| Network Parameters | Numerical Value |
|---|---|
| batch size | 20 |
| learning rate initial value | |
| final number of epochs | 100 |
| validation part of training set | 25% of the training set |
| initial value of the weight constraint coefficient | 0.01 |
| number of LSTM units with shared weights | 6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, J.; Zhang, L.; Zhong, Z. Distinction of Scrambled Linear Block Codes Based on Extraction of Correlation Features. Appl. Sci. 2022, 12, 11305. https://doi.org/10.3390/app122111305
Tan J, Zhang L, Zhong Z. Distinction of Scrambled Linear Block Codes Based on Extraction of Correlation Features. Applied Sciences. 2022; 12(21):11305. https://doi.org/10.3390/app122111305
Chicago/Turabian StyleTan, Jiyuan, Limin Zhang, and Zhaogen Zhong. 2022. "Distinction of Scrambled Linear Block Codes Based on Extraction of Correlation Features" Applied Sciences 12, no. 21: 11305. https://doi.org/10.3390/app122111305