

An Adaptive Dynamic Channel Allocation Algorithm Based on a Temporal–Spatial Correlation Analysis for LEO Satellite Networks

Abstract
:1. Introduction
- The temporal–spatial correlation of handoff calls was analyzed and the Markov decision process (MDP) was used to formally describe the channel allocation process so that the channel allocation could be dynamically adjusted according to the environment.
- A policy for different call events was designed. Afterwards, an online RL algorithm—namely, SARSA—was used to solve the DCA problem. SARSA iteratively updated the policy from the performed actions so that the channel allocation could be adjusted in real-time according to the environment.
- The effectiveness of the proposed algorithm was verified by simulation experiments under different traffic distributions and different traffic intensities.
2. Related Technologies
2.1. Markov Decision Process
2.2. SARSA
3. The Proposed Algorithm
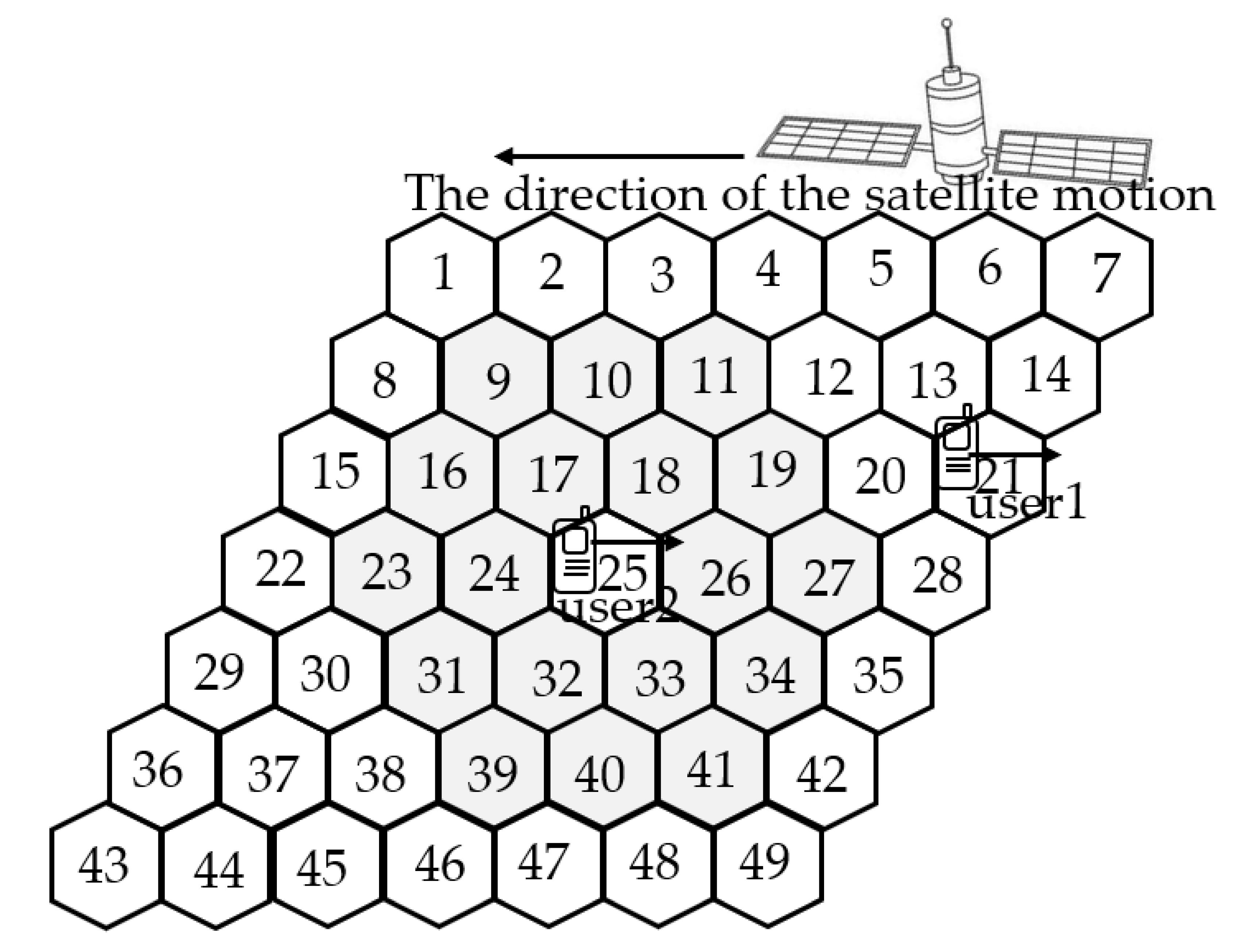
3.1. Temporal–Spatial Correlation Analysis
3.2. Markov Decision Process for the Dynamic Channel Allocation Process
3.3. SARSA for Solving the MDP Model
| Algorithm 1: SARSA for solving the MDP model |
| Input: α, δ, γ Output: Q*(s, a)X ←x0(n, k) = 0 ⧠⧠ //initialize the channel statusQ(s, a) = 0 //initialize the Q-value while list { call event } ≠ Ф do ⧠⧠⧠⧠ if et == at ← //perform at for the new call event else if et == at ← //perform at for the departure call event else if et == at ← //perform at for the handoff call event end if Xt+1 ← z(st, at) //transform the channel status //calculate the immediate reward Update Q(st, a) α ← α * δ //decline the learning rate with the decay factor δ st ← st+1 t = t + 1 |
| end |
3.3.1. The New Call Event
| Algorithm 2: Policy for a new call event |
| Input, st = (Xt, et) Output: at if Ã(n) == Ф rejected //reject the current new call event else if rand( ) < ε //select the eligible channel with ε at = random(Ã(n)) //select the eligible channel for the performed action else for a∈Ã(n) do if Q(st, a) > Q(st, at) at = a //select the channel represented by the selected action end if Xt+1 ← xt(n, at) = 1 //transform the channel status |
| end if |
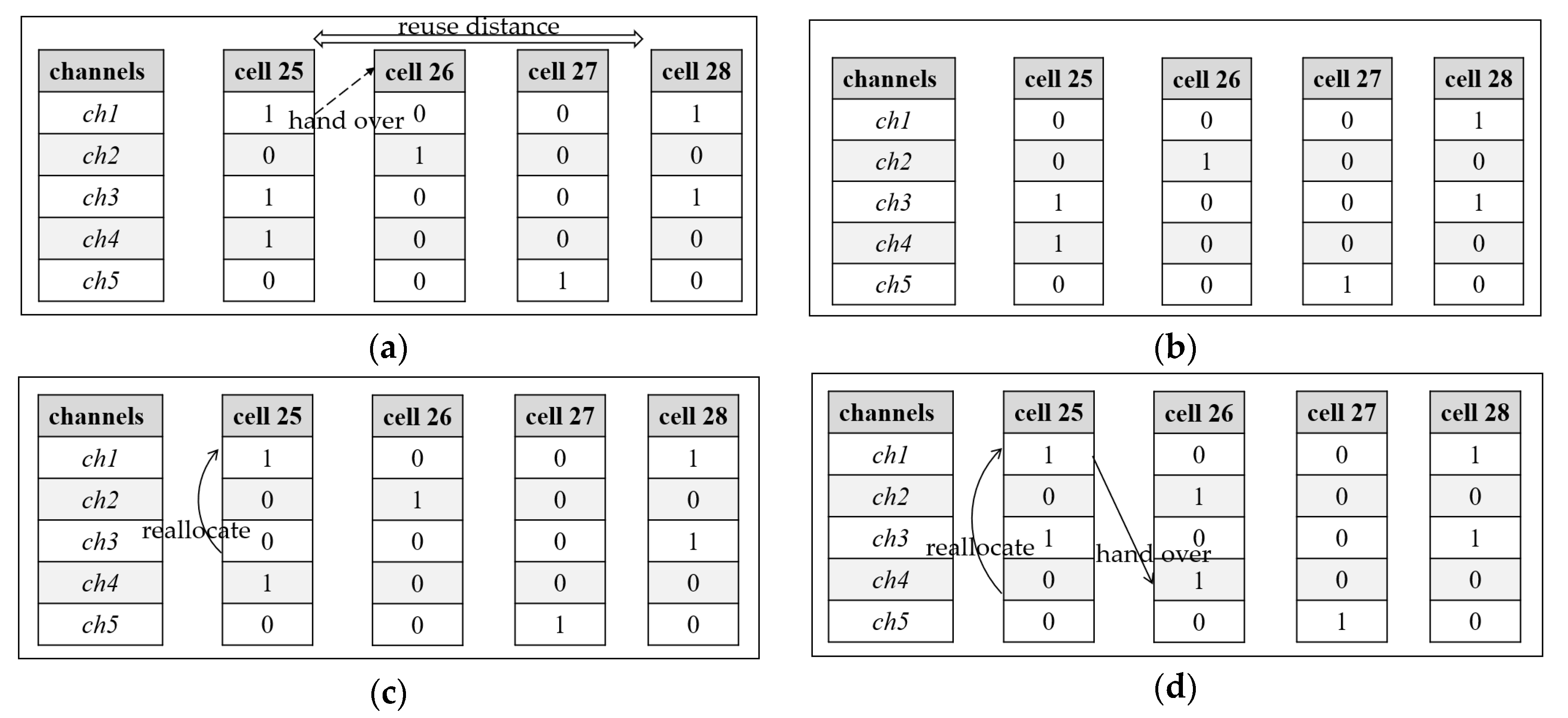
3.3.2. The Departure Call Event
| Algorithm 3: Policy for a departure call event |
| Input: et =, st = (Xt, et) Output: at for a∈{aj, xt(n, j) = 1} do if Q(st, a) < Q(st, at) at = a //select the channel represented by the action with the minimal Q-value end if if(at == k) //judge whether the value of the selected action is k xt(n, k) = 0 //release the channel occupied by the current departure call event else reallocation( ) //reallocate channel k to the call occupying the channel at |
| end if |
3.3.3. The Handoff Call Event
| Algorithm 4: Policy for a handoff call event |
| Input: et =, st = (Xt, et) Output: at, Q(st, at) for at ∈π((Xt, )) do //handle the departure call event k = at //perform the current action corresponding to channel k ← xt+1 (n, k) = 0 //transform the status of channel k in cell n for at+1 ∈ π(Xt+1,) do //handle the new call event in adjacent cell Xt+2 ← xt+2(m, at+1) = 1 //transform the channel status for the new call event if Q(st+1, at+1) > Q(st, at) at = at+1 Q(st, at) = Q(st+1, at+1) // update the current Q-value end if end for |
| end for |
4. Simulation
4.1. Simulation Settings
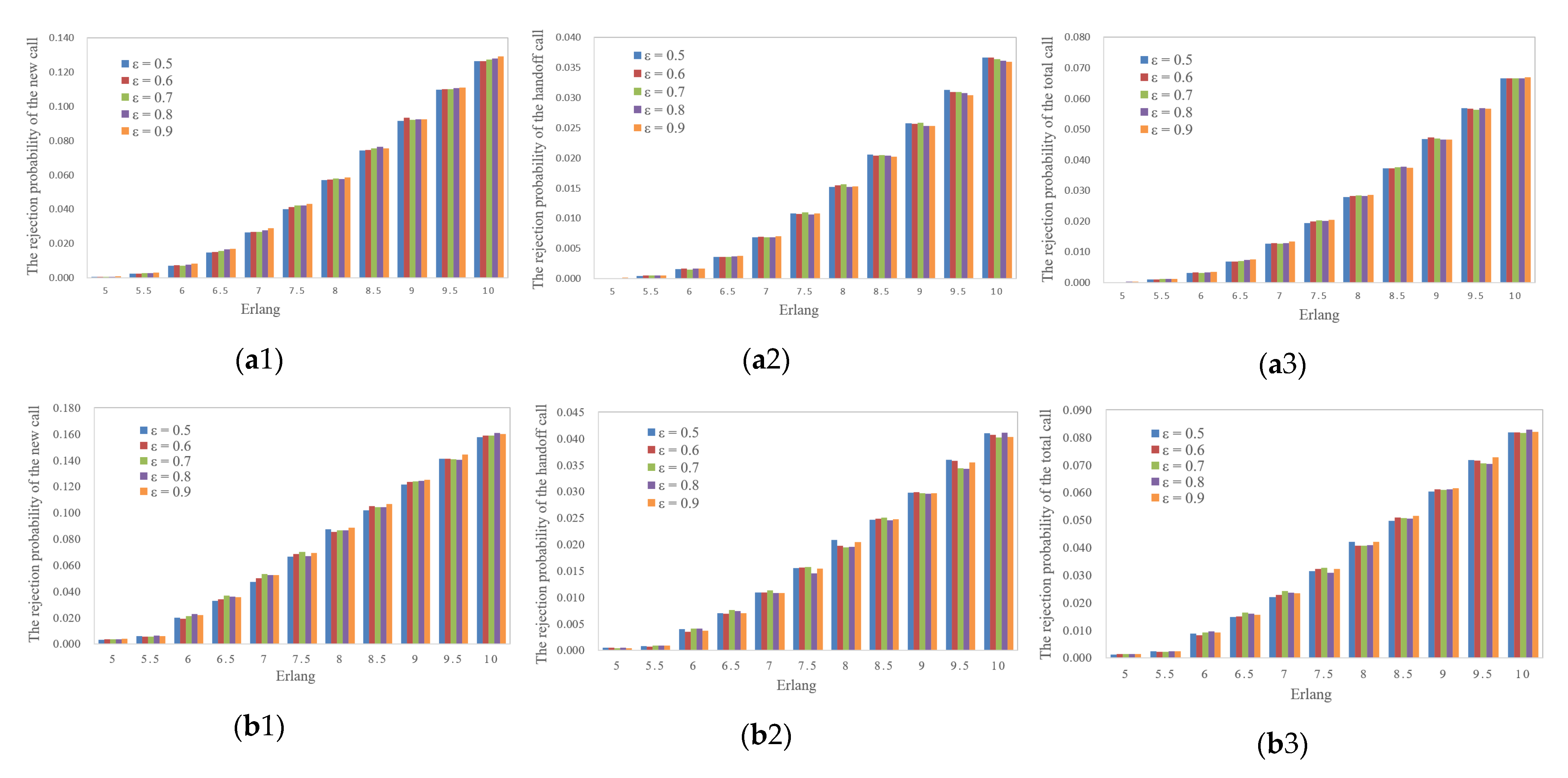
4.2. Results and Analysis
4.3. Parameter Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Niephaus, C.; Kretschmer, M.; Ghinea, G. QoS provisioning in converged satellite and terrestrial networks: A survey of the state-of-the-art. IEEE Commun. Surv. Tuts. 2016, 18, 2415–2441. [Google Scholar] [CrossRef]
- Su, Y.T.; Liu, Y.Q.; Zhou, Y.Q.; Yuan, J.H.; Cao, H.; Shi, J.L. Broadband leo satellite communications: Architectures and key technologies. IEEE Wirel. Commun. 2019, 26, 55–61. [Google Scholar] [CrossRef]
- Zhang, Z.J.; Zhang, W.Y.; Tseng, F.H. Satellite mobile edge computing: Improving QoS of high-speed satellite-terrestrial networks using edge computing techniques. IEEE Netw. 2019, 33, 70–76. [Google Scholar] [CrossRef]
- Wang, Y.X.; Yang, J.; Guo, X.Y.; Qu, Z. Satellite edge computing for the internet of things in aerospace. Sensors 2019, 19, 3607. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wei, J.Y.; Han, J.R.; Cao, S.Z. Satellite IoT edge intelligent computing: A research on architecture. Electronics 2019, 8, 1247. [Google Scholar] [CrossRef] [Green Version]
- Wang, F.; Jiang, D.D.; Qi, S.; Qiao, C.; Shi, L. A dynamic resource scheduling scheme in edge computing satellite networks. Mobile Netw. Appl. 2021, 26, 597–608. [Google Scholar] [CrossRef]
- Wang, S.H.; Ding, S.T.; Chen, C. Edge computing enabled video segmentation for real-time traffic monitoring in internet of vehicles. Patten Recogn. 2022, 121, 108146. [Google Scholar]
- Wu, Y.R.; Guo, H.F.; Chakraborty, C. Edge Computing Driven Low-Light Image Dynamic Enhancement for Object Detection. IEEE Trans. Netw. Sci. Eng. 2022. [Google Scholar] [CrossRef]
- Wu, Y.R.; Zhang, L.L.; Berretti, S. Medical Image Encryption by Content-aware DNA Computing for Secure Healthcare. IEEE Trans. Industr. Inform. 2022, 1–9. [Google Scholar] [CrossRef]
- Xu, F.M.; Yang, F.; Zhao, C.L.; Wu, S. Deep reinforcement learning based joint edge resource management in maritime network. China Commun. 2022, 5, 211–222. [Google Scholar] [CrossRef]
- Zhou, J.; Ye, X.G.; Pan, Y.; Xiao, F.; Sun, L.J. Dynamic channel reservation scheme based on priorities in LEO satellite systems. J. Syst. Eng. Electron. 2015, 26, 1–9. [Google Scholar] [CrossRef]
- Moscholios, L.D.; Vassilakis, V.G.; Sagias, N.C.; Logothetis, M.D. On channel sharing policies in LEO mobile satellite systems. IEEE T. Aerosp. Electron. Syst. 2018, 54, 1628–1640. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.Z.; Sun, S.H.; Kang, S.L. System integration of terrestrial mobile communication and satellite communication–the trends, challenges and key technologies in B5G and 6G. China Commun. 2020, 17, 156–171. [Google Scholar] [CrossRef]
- Liu, J.J.; Shi, Y.P.; Fadlullah, Z.M.; Kato, N. Space-air-ground integrated network: A survey. IEEE Commun. Surv. Tutor. 2018, 20, 2714–2741. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiler, M. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Du, J.; Jiang, C.X.; Wang, J.; Ren, Y.; Yu, S.; Han, Z. Resource allocation in space multiaccess systems. IEEE Trans. Aerosp. Electron. Syst. 2017, 53, 598–618. [Google Scholar] [CrossRef]
- He, D.J.; You, P.; Yong, S.W. Mobility management in LEO satellite communication networks. Chines Space Sci. Technol. 2016, 36, 1–14. [Google Scholar]
- Kato, N.; Fadlullah, Z.M.; Tang, F.X.; Mao, B.M.; Tani, S.; Okamura, A.; Liu, J.J. Optimizing space-air-ground integrated networks by artificial intelligence. IEEE Wirel. Commun. 2019, 26, 140–147. [Google Scholar] [CrossRef] [Green Version]
- Del Re, E.; Fantacci, R.; Giambene, G. Handover queuing strategies with dynamic and fixed channel allocation techniques in low earth orbit mobile satellite systems. IEEE Trans. Commun. 1999, 47, 89–102. [Google Scholar] [CrossRef]
- Li, Y.T.; Wang, S.; Zhou, W.Y. A novel dynamic resource optimization method in LEO-MSS downlink with multi-service based on handover forecasting. In Proceedings of the 5th International Conference Computer and Communications (ICCC), Chengdu, China, 9 June 2019; pp. 809–814. [Google Scholar]
- Liu, S.J. The Research on Dynamic Resource Management Techniques for Satellite Communication System; Beijing University of Posts and Telecommunications: Beijing, China, 2018. [Google Scholar]
- Nie, J.H.; Haykin, S. A Q-learning-based dynamic channel assignment technique for mobile communication systems. IEEE Trans. Veh. Technol. 1999, 48, 1676–1687. [Google Scholar]
- Hu, X.; Liu, S.J.; Chen, R.; Wang, W.D.; Wang, C.T. A deep reinforcement learning-based framework for dynamic resource allocation in multibeam satellite systems. IEEE Commun. Lett. 2018, 22, 1612–1615. [Google Scholar] [CrossRef]
- Liu, S.J.; Hu, X.; Wang, W.D. Deep reinforcement learning based dynamic channel allocation algorithm in multibeam satellite systems. IEEE Access 2018, 6, 15733–15742. [Google Scholar] [CrossRef]
- Zheng, F.; Pi, Z.; Zhou, Z.; Wang, K.Z. Leo satellite channel allocation scheme based on reinforcement learning. Mob. Inf. Syst. 2020, 2020, 8868888. [Google Scholar] [CrossRef]
- Wang, J.; Sun, L.J.; Zhou, J.; Han, C. A dynamic channel reservation strategy based on priorities of multi-traffic and multi-user in LEO satellite networks. J. Circuit. Syst. Comp. 2020, 29, 2050082. [Google Scholar] [CrossRef]
- Maral, G.; Restrepo, J.; Del Re, E. Performance analysis for a guaranteed handover service in an LEO constellation with a ‘satellite-fixed cell’ system. IEEE Trans. Veh. Technol. 1998, 47, 1200–1214. [Google Scholar] [CrossRef]
- Del Re, E. Different queuing policies for handover requests in low earth orbit mobile satellite systems. IEEE Trans. Veh. Technol. 1999, 48, 448–458. [Google Scholar] [CrossRef]
- Deng, B.Y.; Jiang, C.X.; Yao, H.P. The next generation heterogeneous satellite communication of resource management and deep reinforcement learning. IEEE Wirel. Commun. 2020, 27, 105–111. [Google Scholar] [CrossRef]
- Shi, G.C.; Wu, Y.R.; Liu, J. Incremental Few-Shot Semantic Segmentation via Embedding Adaptive-Update and Hyper-class Representation. arXiv 2022. [Google Scholar] [CrossRef]
- Zhou, J.; Han, T.T.; Xiao, F. Multi-scale network traffic prediction method based on deep echo state network for internet of things. IEEE Internet Things J. 2022, 9, 21862–21874. [Google Scholar] [CrossRef]
- Luong, N.C.; Hoang, D.T.; Gong, S.M.; Niyato, D.; Wang, P.; Liang, Y.C.; Kim, D. Applications of deep reinforcement learning in communications and networking: A survey. IEEE Commun. Surv. Tutor. 2019, 21, 3133–3174. [Google Scholar] [CrossRef] [Green Version]
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming; John Wiley & Sons: New York, USA, 2014. [Google Scholar]
- Alfakin, T.; Hassan, M.M.; Gumae, A.; Savaglio, C.; Fortino, G. Task offloading and resource allocation for mobile edge computing by deep reinforcement learning based on SARSA. IEEE Access 2020, 8, 54074–54084. [Google Scholar] [CrossRef]
- Liu, C.F.; Bennis, M.; Debbah, M.; Vincent, P. Dynamic task offloading and resource allocation for ultra-reliable low-latency edge computing. IEEE Trans. Commun. 2019, 67, 4132–4150. [Google Scholar] [CrossRef] [Green Version]
- Lilith, N.; Dogancay, K. Reduced-state SARSA featuring extended channel reassignment for dynamic channel allocation in mobile cellular networks. LNCS 2005, 3421, 531–542. [Google Scholar]
- Torstein, S. Contributions to Centralized Dynamic Channel Allocation Reinforcement Learning Agents; Norwegian University of Science and Technology: Trondheim, Norway, 2018. [Google Scholar]
- Zou, Q.Y.; Zhu, L.D. Dynamic channel allocation strategy of satellite communication systems based on grey prediction. In Proceedings of the International Symposium on Networks, Computers and Communications (ISNCC), Istanbul, Turkey, 18–20 June 2019; pp. 1–5. [Google Scholar]
- Lima, M.A.; Araujo, A.F.; Cesar, A.C. Adaptive genetic algorithms for dynamic channel assignment in mobile cellular communication systems. IEEE Trans. Veh. Technol. 2007, 56, 2685–2696. [Google Scholar] [CrossRef]
- Lilith, N.; Dogancay, K. Dynamic channel allocation for mobile cellular traffic using reduced-state reinforcement learning. In Proceedings of the Wireless Communications & Networking Conference (WCNC), Atlanta, GA, USA, 21–25 March 2004; pp. 2195–2200. [Google Scholar]
- Wang, Z.P.; Mathiopoulos, P.T.; Schober, R. Performance analysis and improvement methods for channel resource management strategies of leo-mss with multiparty traffic. IEEE Trans. Veh. Technol. 2008, 57, 3832–3842. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Description | Value |
|---|---|---|
| α | Learning rate | 0.019389 |
| δ | Decay factor of α | 0.999999 |
| γ | Discount factor | 0.845 |
| ε | Exploration factor | 0.8 |
| N | The number of cells | 49 |
| K | The number of channels | 70 |
| r | The radius of cell | 450 km |
| vs | The velocity of satellites | 7 k/s |
| 1/μ | Call duration | 3 min |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Sun, L.; Zhou, J.; Han, C. An Adaptive Dynamic Channel Allocation Algorithm Based on a Temporal–Spatial Correlation Analysis for LEO Satellite Networks. Appl. Sci. 2022, 12, 10939. https://doi.org/10.3390/app122110939
Wang J, Sun L, Zhou J, Han C. An Adaptive Dynamic Channel Allocation Algorithm Based on a Temporal–Spatial Correlation Analysis for LEO Satellite Networks. Applied Sciences. 2022; 12(21):10939. https://doi.org/10.3390/app122110939
Chicago/Turabian StyleWang, Juan, Lijuan Sun, Jian Zhou, and Chong Han. 2022. "An Adaptive Dynamic Channel Allocation Algorithm Based on a Temporal–Spatial Correlation Analysis for LEO Satellite Networks" Applied Sciences 12, no. 21: 10939. https://doi.org/10.3390/app122110939