
Utilizing Mask R-CNN for Solid-Volume Food Instance Segmentation and Calorie Estimation

Abstract
:1. Introduction
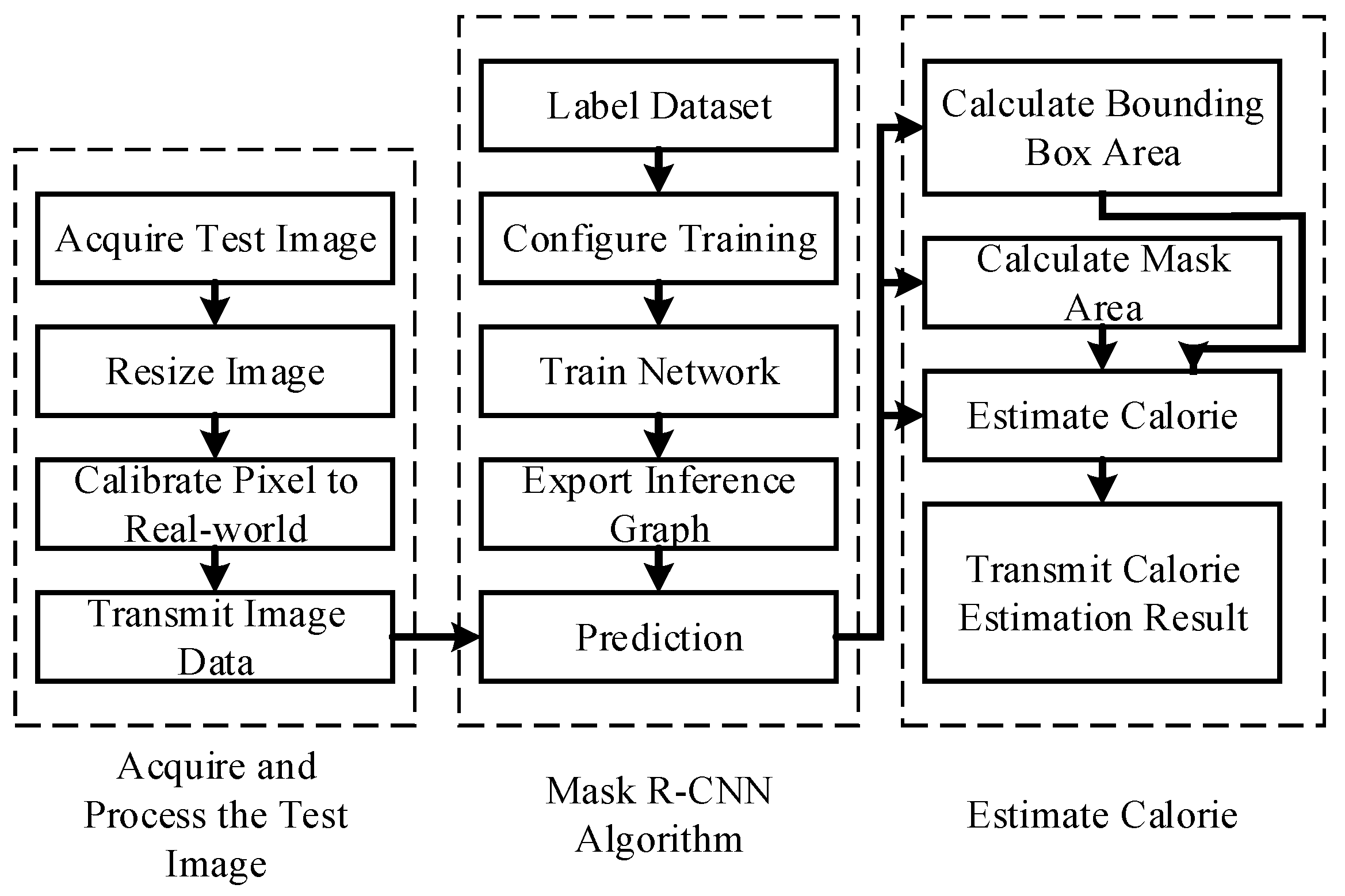
2. Instance Segmentation and Calorie Estimation System Overview
3. Mask R-CNN Algorithm
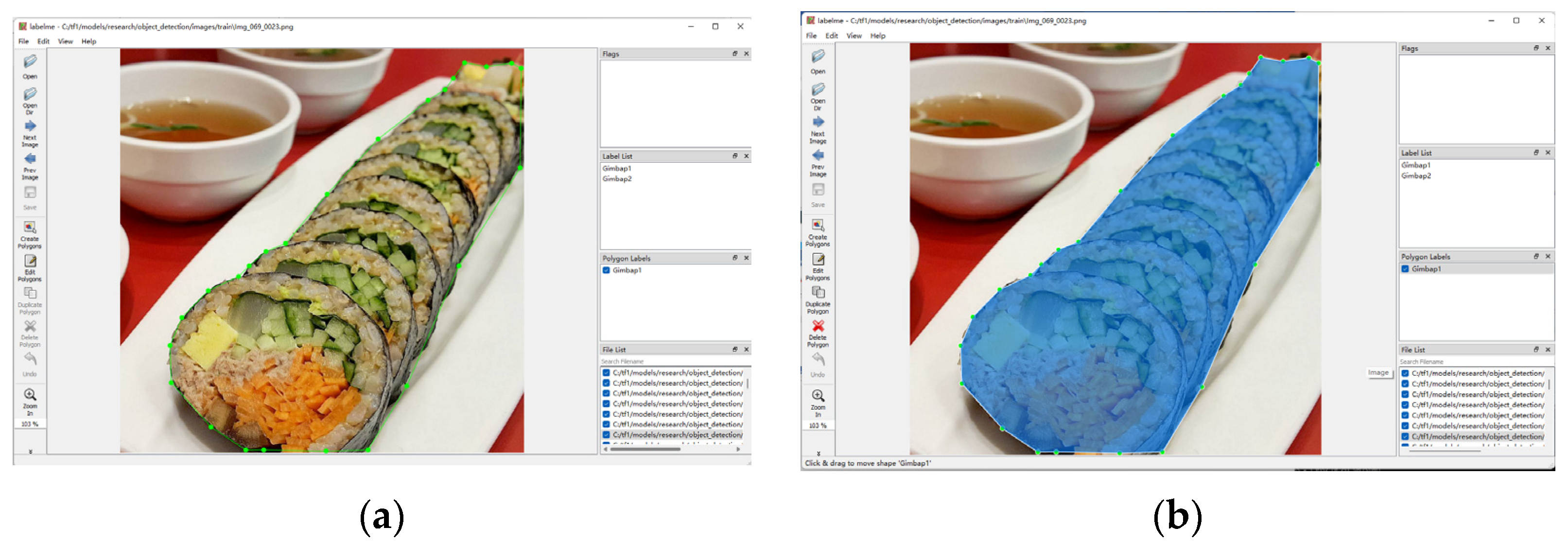
3.1. Prepare Datasets
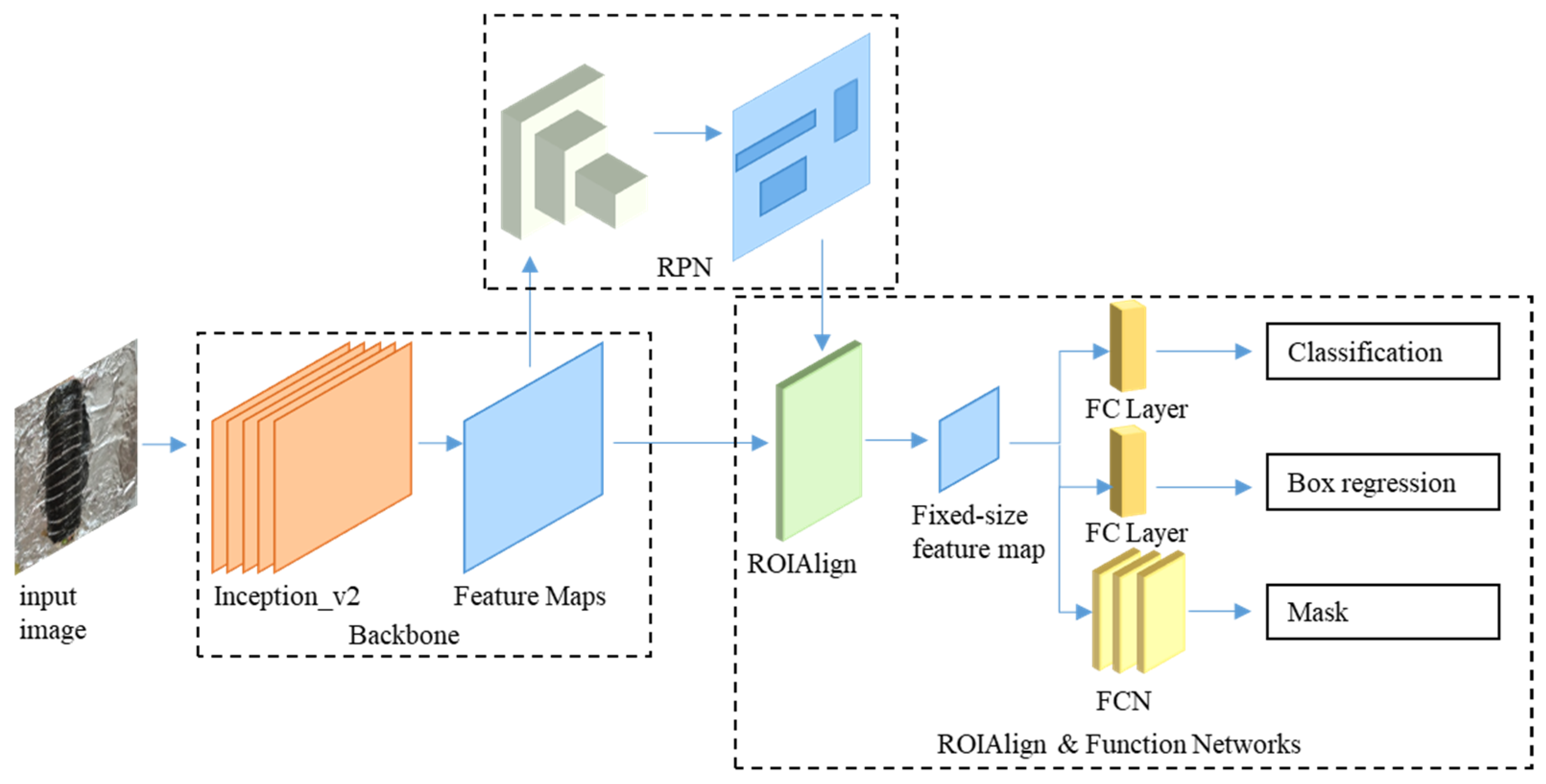
3.2. Mask R-CNN Architecture
3.3. Mask R-CNN Lost Function
4. Calorie Estimation Approach
5. Experimental Results
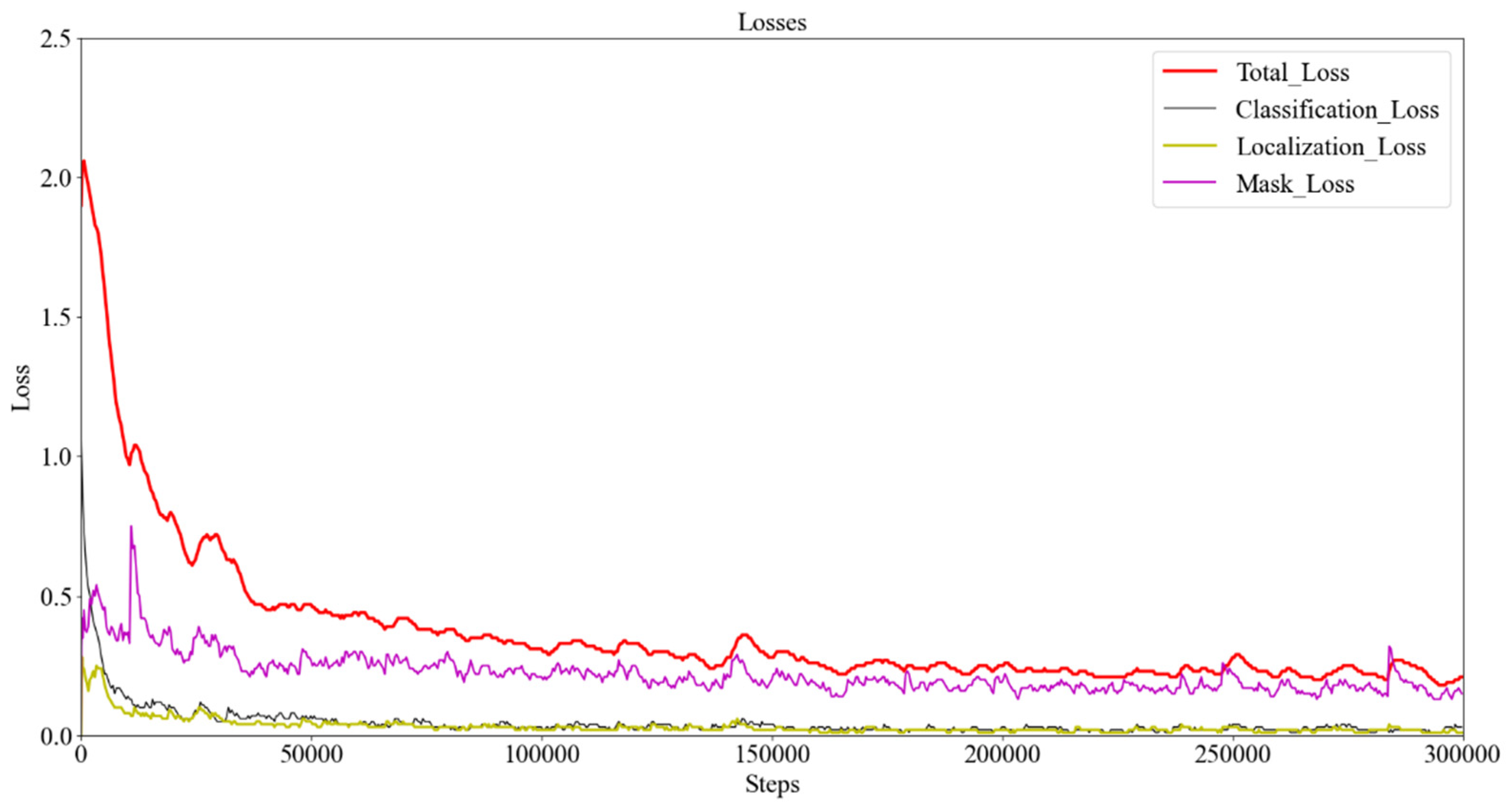
5.1. Gimbap Instance Segmentation Using Mask R-CNN
5.2. Gimbap Calorie Estimation
5.3. Comparison with the Other Algorithm
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tahir, G.A.; Loo, C.K. A Comprehensive Survey of Image-Based Food Recognition and Volume Estimation Methods for Dietary Assessment. Healthcare 2021, 9, 1676. [Google Scholar] [CrossRef] [PubMed]
- Kaur, P.; Sikka, K.; Wang, W.; Belongie, S.J.; Divakaran, A. Foodx-251: A dataset for fine-grained food classification. arXiv 2019, arXiv:1907.06167. [Google Scholar]
- Jiang, S.; Min, W.; Liu, L.; Luo, Z. Multi-Scale Multi-View Deep Feature Aggregation for Food Recognition. IEEE Trans. Image Process. 2019, 29, 265–276. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Yap, K.-H.; Kot, A.C. Fusion Learning using Semantics and Graph Convolutional Network for Visual Food Recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2021; pp. 1710–1719. [Google Scholar] [CrossRef]
- Sun, M.; Burke, L.E.; Baranowski, T.; Fernstrom, J.D.; Zhang, H.; Chen, H.C.; Bai, Y.; Li, Y.; Li, C.; Yue, Y.; et al. An exploratory study on a chest-worn computer for evaluation of diet, physical activity and lifestyle. J. Healthc. Eng. 2015, 6, 641861. [Google Scholar] [CrossRef] [PubMed]
- Lo, F.P.-W.; Sun, Y.; Qiu, J.; Lo, B.P.L. Point2Volume: A Vision-Based Dietary Assessment Approach Using View Synthesis. IEEE Trans. Ind. Inform. 2020, 16, 577–586. [Google Scholar] [CrossRef]
- Christ, P.F.; Schlecht, S.; Ettlinger, F.; Grun, F.; Heinle, C.; Tatavatry, S.; Ahmadi, S.-A.; Diepold, K.; Menze, B.H. Diabetes60—Inferring Bread Units from Food Images Using Fully Convolutional Neural Networks. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 1526–1535. [Google Scholar] [CrossRef]
- Gimbap. Available online: https://en.wikipedia.org/wiki/Gimbap (accessed on 20 September 2022).
- Sun, C.; Zhan, W.; She, J.; Zhang, Y. Object Detection from the Video Taken by Drone via Convolutional Neural Networks. Math. Probl. Eng. 2020, 2020, 4013647. [Google Scholar] [CrossRef]
- Sezer, A.; Altan, A. Detection of solder paste defects with an optimization-based deep learning model using image processing techniques. Solder. Surf. Mt. Technol. 2021, 33, 291–298. [Google Scholar] [CrossRef]
- Sezer, A.; Altan, A. Optimization of Deep Learning Model Parameters in Classification of Solder Paste Defects. In Proceedings of the 2021 3rd International Congress on Human-Computer Interaction, Optimization and Robotic Applications (HORA), Ankara, Turkey, 11–13 June 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Shima, R.; Yunan, H.; Fukuda, O.; Okumura, H.; Arai, K.; Bu, N. Object classification with deep convolutional neural network using spatial information. In Proceedings of the 2017 International Conference on Intelligent Informatics and Biomedical Sciences (ICIIBMS), Okinawa, Japan, 24–26 November 2017; pp. 135–139. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in neural Information Processing Systems 25, Lake Tahoe, Nevada, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Tan, M.X.; le Quoc, V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th international Conference Machine Learning, PMLR97, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Afzaal, U.; Bhattarai, B.; Pandeya, Y.R.; Lee, J. An Instance Segmentation Model for Strawberry Diseases Based on Mask R-CNN. Sensors 2021, 21, 6565. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and segmantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R.G. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.M.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.M.; Hariharan, B.; Belongie, S. Reature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- He, K.M.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the International Conference of Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Machefer, M.; Lemarchand, F.; Bonnefond, V.; Hitchins, A.; Sidiropoulos, P. Mask R-CNN Refitting Strategy for Plant Counting and Sizing in UAV Imagery. Remote Sens. 2020, 12, 3015. [Google Scholar] [CrossRef]
- Braun, M.S.; Frenzel, P.; Kading, C.; Fuchs, M. Utilizing Mask R-CNN for Waterline Detection in Canoe Sprint Video Analysis. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 3826–3835. [Google Scholar]
- Min, H.J. Generating Synthetic Dataset for Scale-invariant Instance Segmentation of Food Materials Based Upon Mask R-CNN. J. Inst. Control. Robot. Syst. 2021, 27, 502–509. [Google Scholar] [CrossRef]
- Tran, D.L. Mask R-CNN with Data Augmentation for Food Detection and Recognition. TechRxiv 2020. Available online: https://www.techrxiv.org/articles/preprint/Mask_R-CNN_with_data_augmentation_for_food_detection_and_recognition/11974362/1 (accessed on 29 September 2022). [CrossRef]
- Zhon, T.F.; Wang, W.G.; Liu, S.; Yang, Y.; Gool, L.V. Differentiable Multi-Granularity Human Representation Learning for Instance-Aware Human Semantic Parsing. In Proceedings of the Computer Vision and Pattern Recognition (CVPR 2021), Nashville, TN, USA, 19–25 June 2021; pp. 1622–1631. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Loffe, S.; Shlens, J. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Collection | Number of Gimbaps Labeled as Gimbap1 | Number of Gimbaps Labeled as Gimbap2 | Number of Other Foods |
|---|---|---|---|
| Train | 1318 | 655 | 278 |
| Test | 385 | 106 | 56 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, Y.; Park, S.; Lee, K. Utilizing Mask R-CNN for Solid-Volume Food Instance Segmentation and Calorie Estimation. Appl. Sci. 2022, 12, 10938. https://doi.org/10.3390/app122110938
Dai Y, Park S, Lee K. Utilizing Mask R-CNN for Solid-Volume Food Instance Segmentation and Calorie Estimation. Applied Sciences. 2022; 12(21):10938. https://doi.org/10.3390/app122110938
Chicago/Turabian StyleDai, Yanyan, Subin Park, and Kidong Lee. 2022. "Utilizing Mask R-CNN for Solid-Volume Food Instance Segmentation and Calorie Estimation" Applied Sciences 12, no. 21: 10938. https://doi.org/10.3390/app122110938