
Efficient Realization for Third-Order Volterra Filter Based on Singular Value Decomposition


Abstract
:1. Introduction
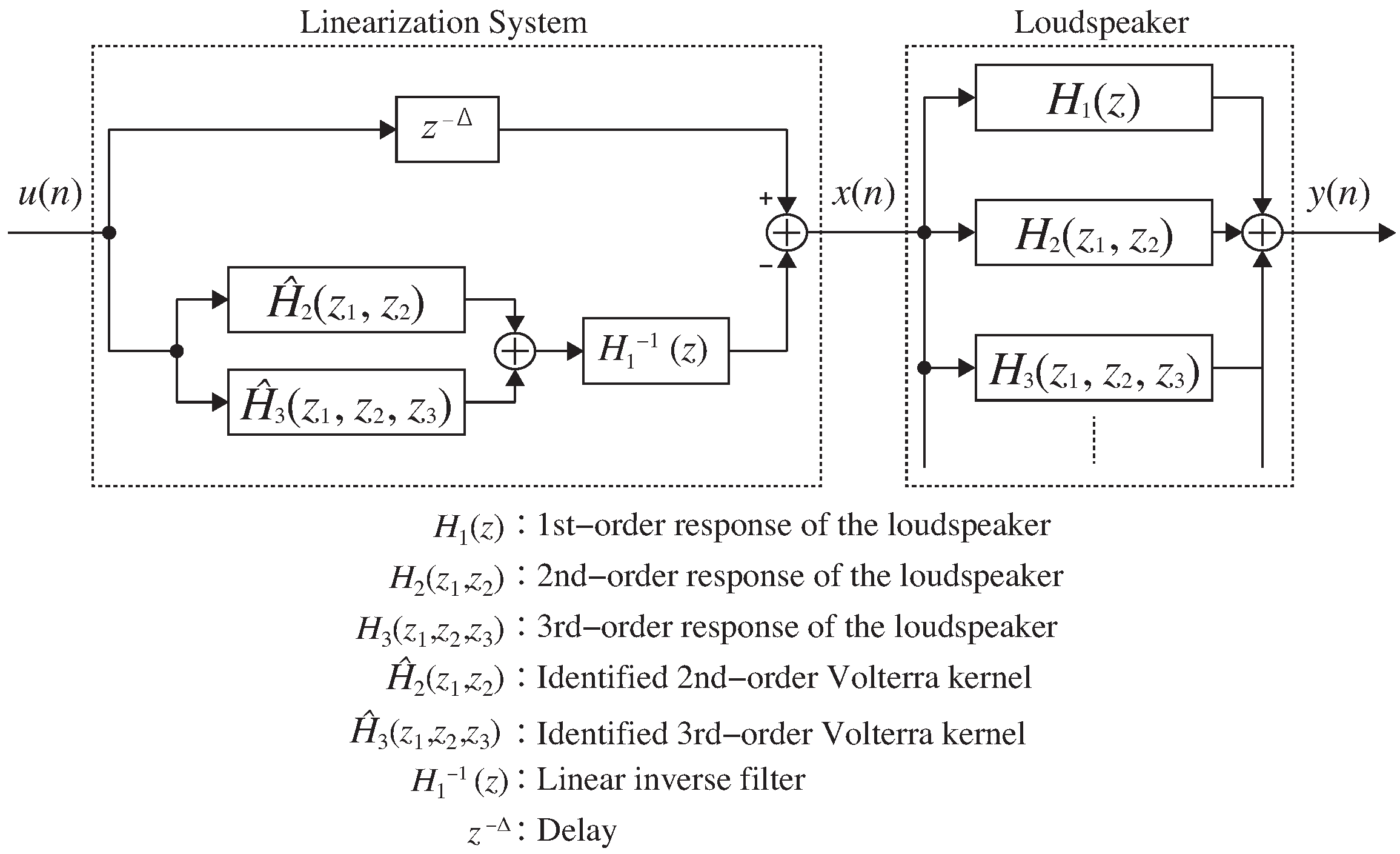
2. Linearization System for Loudspeaker
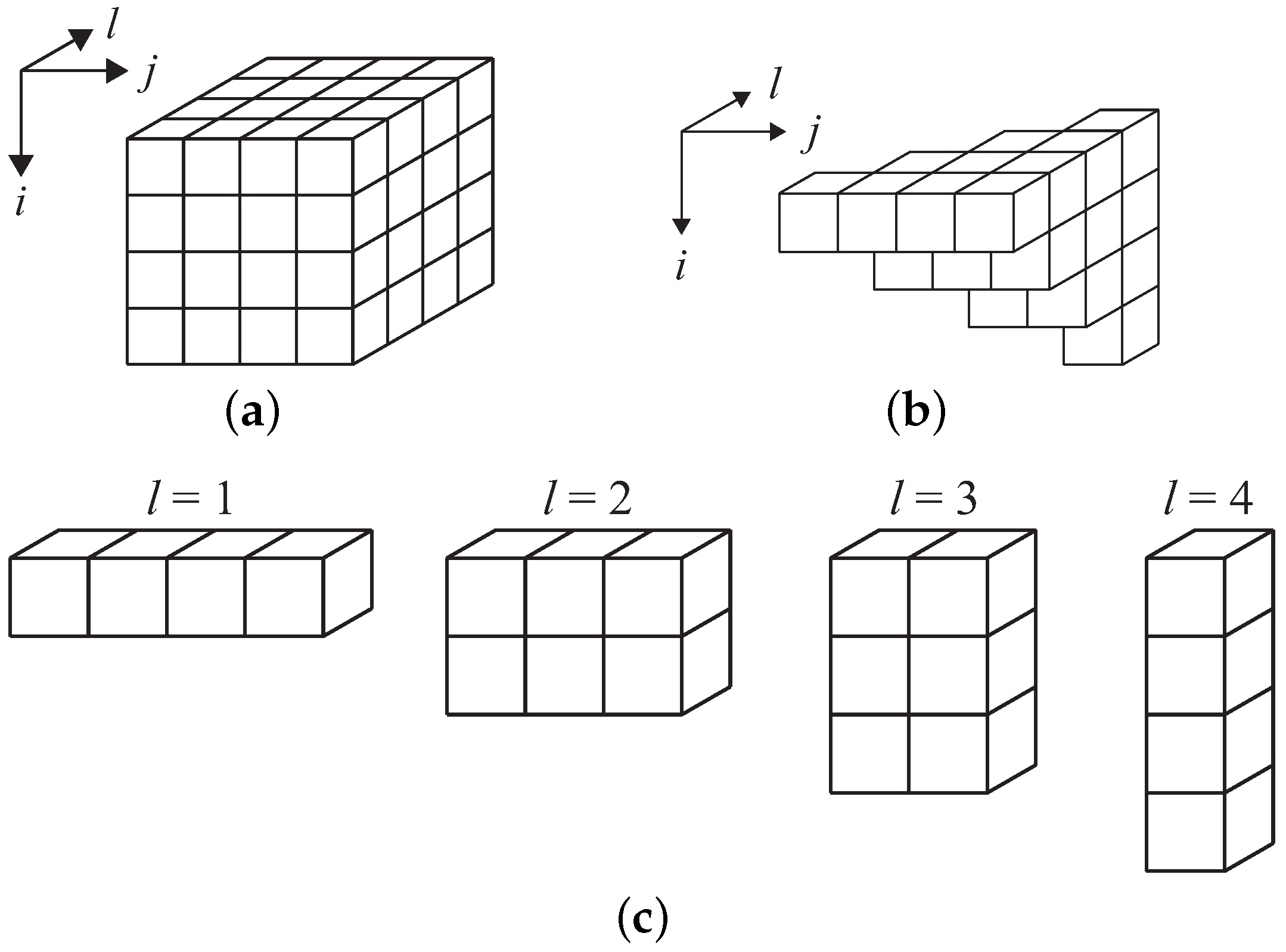
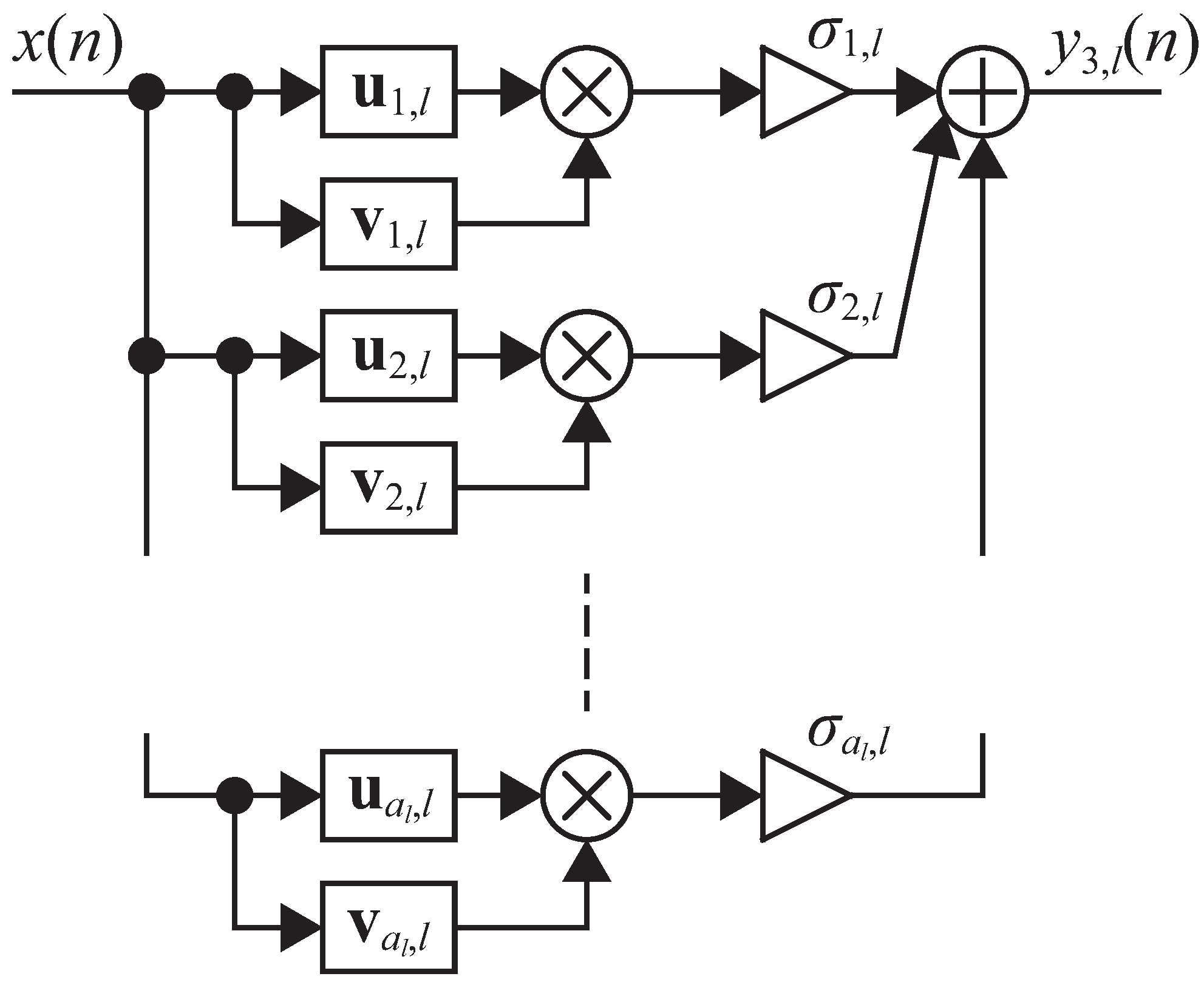
3. Efficient Realization for Third-Order Volterra Filter Using Singular Value Decomposition
- Obtain the third-order Volterra kernel of the target loudspeaker using an identification method such as FRM [16].
- Apply SVD to each of the sliced 2D components (matrices) to obtain singular value , left singular vector , and right singular vector .
- Based on the pre-defined reduction ratio r, leave the singular value , corresponding left singular vectors and right singular vectors up to the upper th, and implement the configuration in Figure 3.
4. Reduction of Computational Cost and Compensation Performance for the Third-Order Harmonic Distortion
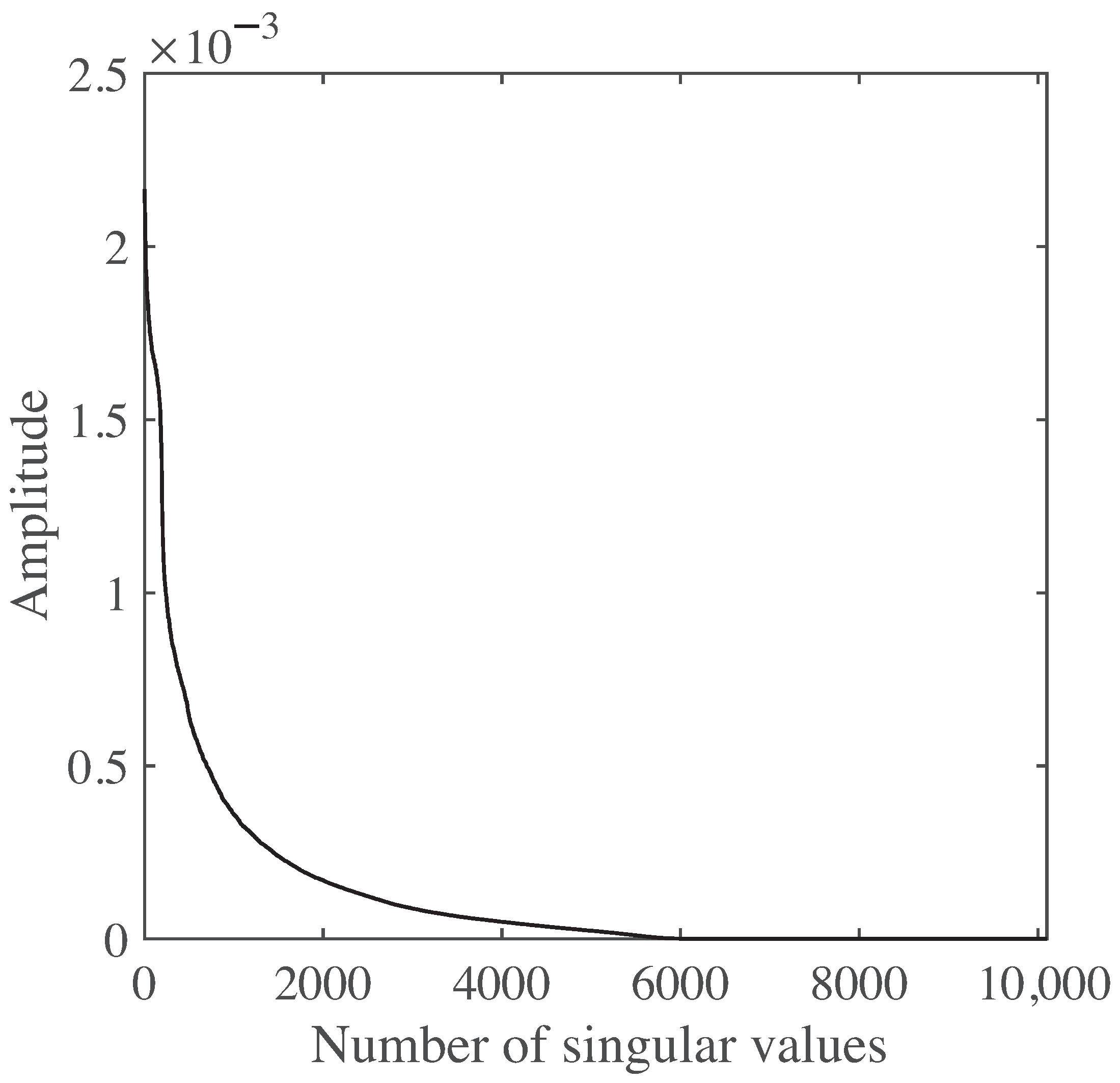
4.1. Computational Complexity of the Proposed Method
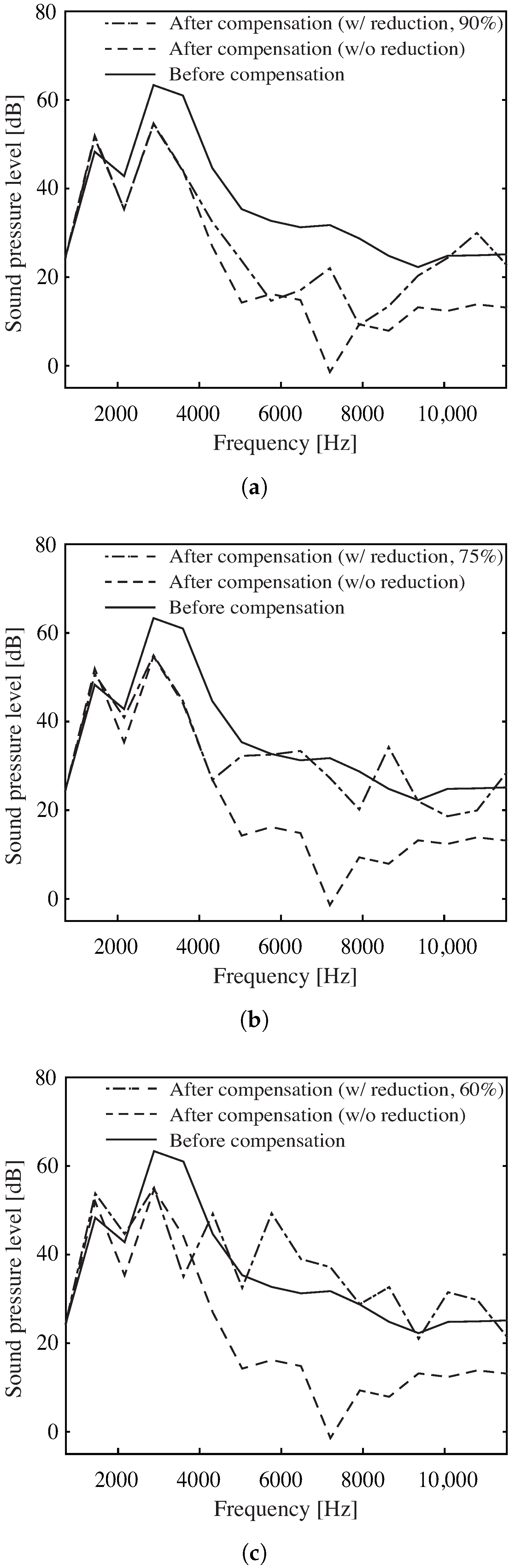
4.2. Compensation of Third-Order Harmonic Distortion
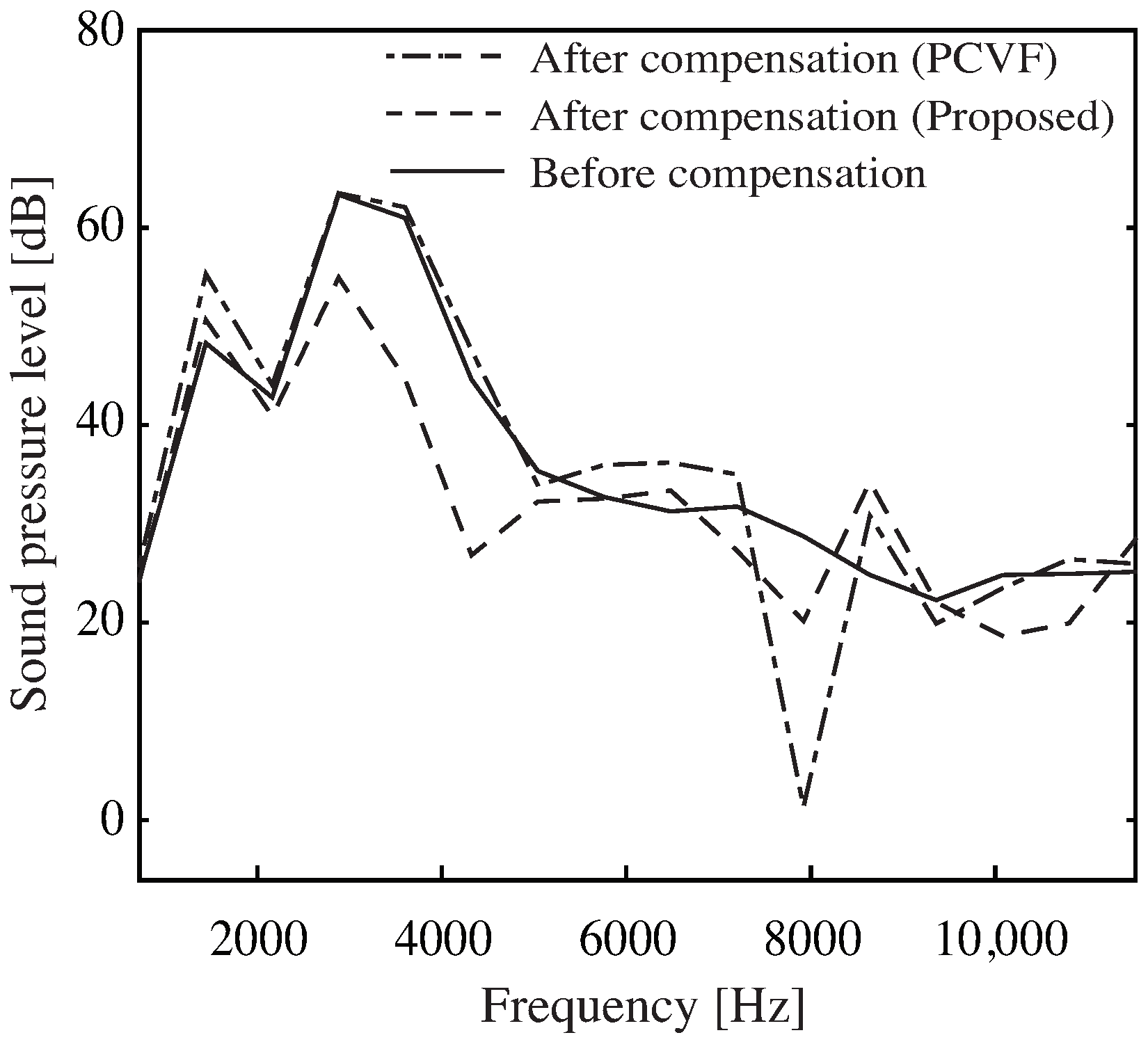
4.3. Comparison between Proposed Method and Parallel-Cascade Truncated Volterra Filter
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Klippel, W. Tutorial: Loudspeaker Nonlinearities—Causes, Parameters, Symptoms. J. Audio Eng. Soc. 2006, 54, 907–939. [Google Scholar]
- Klippel, W. The Mirror Filter—A New Basis for Reducing Nonlinear Distortion and Equalizing Response in Woofer Systems. J. Audio Eng. Soc. 1992, 40, 675–691. [Google Scholar]
- Schurer, H. Linearization of Electroacoustic Transducers; University of Twente Publications: Enschede, The Netherlands, 1997. [Google Scholar]
- Nakao, R.; Kajikawa, Y.; Nomura, Y. An Estimation Method of Parameters for Closed-box Loudspeaker System. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2008, E91-A, 3006–3013. [Google Scholar] [CrossRef]
- Iwai, K.; Kajikawa, Y. Third-order nonlinear IIR filter for compensating nonlinear distortions of loudspeaker systems. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2015, E98-A, 820–832. [Google Scholar] [CrossRef]
- Iwai, K.; Kajikawa, Y. Parameter estimation method using Volterra kernels for nonlinear IIR filters. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2014, E97-A, 2189–2199. [Google Scholar] [CrossRef]
- Iwai, K.; Kajikawa, Y. Modified second-order nonlinear infinite impulse response (IIR) filter for equalizing frequency response and compensating nonlinear distortions of electrodynamic loudspeaker. Appl. Acoust. 2018, 132, 202–209. [Google Scholar] [CrossRef]
- Uesako, N.; Kajikawa, Y. Relationship between the Nonlinear Distortions Compensation Performance and Each Parameter of the Electro-dynamic Loudspeaker System. In Proceedings of the 9th International Conference on Information, Communications & Signal Processing (ICICS 2013), Tainan, Taiwan, 10–13 December 2013; pp. 1–5. [Google Scholar]
- Schetzen, M. The Volterra and Wiener Theories of Nonlinear Systems; Krieger: Malabar, FL, USA, 1989. [Google Scholar]
- Kaizer, A.J.M. Modeling of the Nonlinear Response of an Electrodynamic Loudspeaker by a Volterra Series Expansion. J. Audio Eng. Soc. 1987, 35, 412–432. [Google Scholar]
- Mathews, V.J. Adaptive Polynomial Filters. IEEE Signal Process. Mag. 1991, 8, 10–26. [Google Scholar] [CrossRef]
- Mathews, V.J.; Sicuranza, G.L. Polynomial Signal Processing; John Wiley: New York, NY, USA, 2000. [Google Scholar]
- Sicuranza, G.L. Quadratic filters for signal processing. Proc. IEEE 1992, 80, 1263–1285. [Google Scholar] [CrossRef]
- Frank, W.A. An Efficient Approximation to the Quadratic Volterra Filter and its Application in Real-time Loudspeaker Linearization. Signal Process. 1995, 45, 97–113. [Google Scholar] [CrossRef]
- Stenger, A.; Trautmann, L.; Rabenstein, R. Volterra filters using multirate signal processing and their application to loudspeaker systems. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Salt Lake City, UT, USA, 7–11 May 2001. [Google Scholar]
- Tsujikawa, M.; Shiozaki, T.; Kajikawa, Y.; Nomura, Y. Identification and Elimination of Second–order Nonlinear Distortion of Loudspeaker Systems Using Volterra Filter. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Geneva, Switzerland, 28–31 May 2000; pp. 249–252. [Google Scholar]
- Frank, W.; Reger, R.; Appel, U. Realtime Loudspeaker Linearization. In Proceedings of the IEEE Winter Workshop on Nonlinear Digital Signal Processing, Tampere, Finland, 17–20 January 1993. [Google Scholar]
- Kajikawa, Y. Linearization method based on multiple loudspeaker systems. Acoust. Sci. Technol. 2011, 32, 220–223. [Google Scholar] [CrossRef] [Green Version]
- Gan, W.S.; Tan, E.L.; Kuo, S.M. Audio Projection. IEEE Signal Process. Mag. 2011, 28, 43–57. [Google Scholar] [CrossRef]
- Gan, W.S.; Yang, J.; Kamakura, T. A review of parametric acoustic array in air. Appl. Acoust. 2012, 73, 1211–1219. [Google Scholar] [CrossRef]
- Shi, C.; Kajikawa, Y.; Gan, W.S. An overview of directivity control methods of the parametric array loudspeaker. APSIPA Trans. Signal Inf. Process. 2014, 3, e20. [Google Scholar] [CrossRef] [Green Version]
- Hatano, Y.; Shi, C.; Kajikawa, Y. Compensation for Nonlinear Distortion of the Frequency Modulation-Based Parametric Array Loudspeaker. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1709–1717. [Google Scholar] [CrossRef]
- Panicker, T.M.; Mathews, V.J.; Sicuraza, G.L. Adaptive parallel-cascade truncated Volterra filters. IEEE Trans. Signal Process. 1998, 46, 2664–2673. [Google Scholar] [CrossRef] [Green Version]
- Panicker, T.M.; Mathews, V.J. Parallel-cascade realizations and approximations of truncated Volterra systems. IEEE Trans. Signal Process. 1998, 46, 2829–2832. [Google Scholar] [CrossRef] [Green Version]
- Khouaja, A.; Kibangou, A.; Favier, G. Third-order Volterra kernels complexity reduction using PARAFAC. In Proceedings of the First International Symposium on Control, Communications and Signal Processing, Hamamet, Tunisia, 21–24 March 2004; pp. 857–860. [Google Scholar]
- Kibangou, A.Y.; Favier, G. Identification of parallel–cascade Wiener systems using joint diagonalization of third-order Volterra kernel slices. IEEE Signal Process Lett. 2009, 16, 188–191. [Google Scholar] [CrossRef]
- Furuhashi, H.; Kajikawa, Y.; Nomura, Y. Linearization of Loudspeaker Systems Using a Subband Parallel Cascade Volterra Filter. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2007, E90-A, 1616–1619. [Google Scholar] [CrossRef]
- Burton, T.G.; Goubran, R.A.; Beaucoup, F. Nonlinear System Identification Using a Subband Adaptive Volterra Filter. IEEE Trans. Instrum. Meas. 2009, 58, 1389–1397. [Google Scholar] [CrossRef]
- Burton, T.G.; Goubran, R. A Generalized Proportionate Subband Adaptive Second-Order Volterra Filter for Acoustic Echo Cancellation in Changing Environments. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 2364–2373. [Google Scholar] [CrossRef]
- Batista, E.L.O.; Tobias, O.J.; Seara, R. A sparse-interpolated scheme for implementing adaptive Volterra filters. IEEE Trans. Signal Process. 2010, 58, 2022–2033. [Google Scholar] [CrossRef]
- Kinoshita, S.; Kajikawa, Y. New Sub-Band Adaptive Volterra Filter for Identification of Loudspeaker. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2019, E102-A, 1946–1955. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Micro-speaker | HDR9267 (Hosiden) |
| Dimensions of target micro-speaker | mm |
| Rated power | 0.4 W |
| Input impedance | 7.3 |
| Resonance frequency | 1008 Hz |
| Enclosure type | closed-box |
| Inside dimensions | mm |
| Input voltage | 1.2 Vrms |
| Sampling frequency | 48,000 Hz |
| Frequency range | 240–12,000 Hz |
| Tap length of 1st-order Volterra kernel | 200 |
| Tap length of 2nd-order Volterra kernel | 200 × 200 |
| Tap length of 3rd-order Volterra kernel | 200 × 200 × 200 |
| Removed Path Ratio r [%] | # of Multiplications | Average Compensation [dB] |
|---|---|---|
| original (no SVD) | 4,060,200 | 13.5 dB |
| 0 % | 2,050,500 | 13.5 dB |
| 60 % | 820,320 | 7.9 dB |
| 75 % | 512,775 | 3.5 dB |
| 90 % | 205,230 | dB |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nakahira, Y.; Iwai, K.; Kajikawa, Y. Efficient Realization for Third-Order Volterra Filter Based on Singular Value Decomposition. Appl. Sci. 2022, 12, 10710. https://doi.org/10.3390/app122110710
Nakahira Y, Iwai K, Kajikawa Y. Efficient Realization for Third-Order Volterra Filter Based on Singular Value Decomposition. Applied Sciences. 2022; 12(21):10710. https://doi.org/10.3390/app122110710
Chicago/Turabian StyleNakahira, Yuya, Kenta Iwai, and Yoshinobu Kajikawa. 2022. "Efficient Realization for Third-Order Volterra Filter Based on Singular Value Decomposition" Applied Sciences 12, no. 21: 10710. https://doi.org/10.3390/app122110710