
Concept and Architecture for Applying Continuous Machine Learning in Multi-Access Routing at Underground Mining Vehicles


Abstract
:Featured Application
Abstract
1. Introduction
2. Research Method and Process
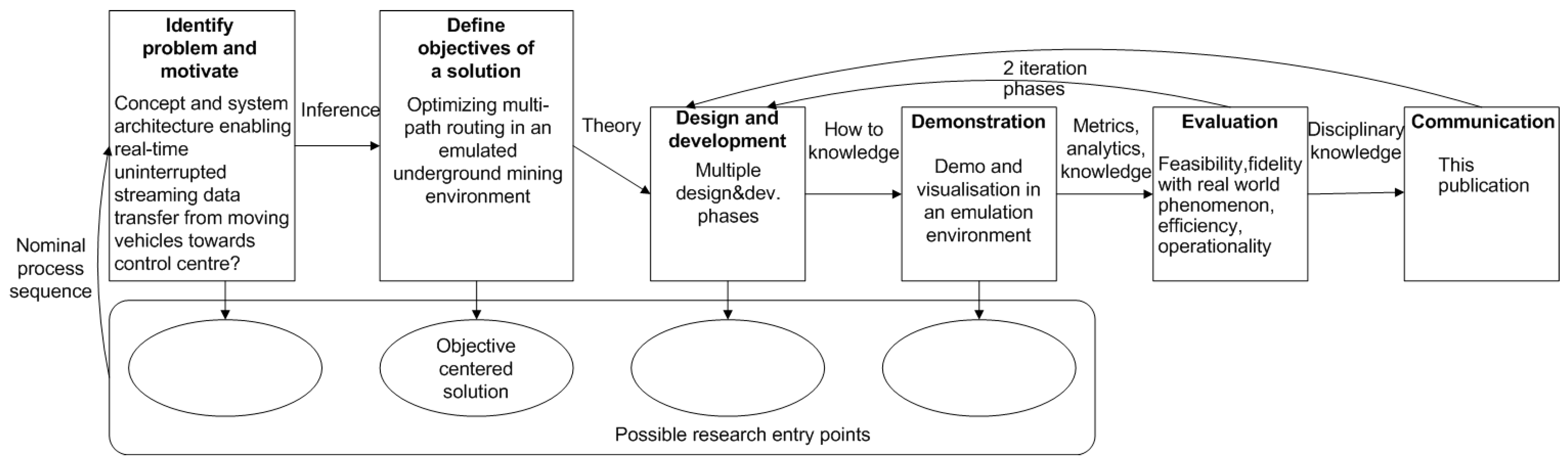
2.1. Research Method and Research Question
- What kind of concept and system architecture enables real-time uninterrupted streaming data transfer from moving vehicles towards a control center?
2.2. Research Process
3. Concept
3.1. Continuous ML in Emulation Environments
3.2. Continuous ML in a Real Mining Environment
4. Architecture Design
4.1. Continuous ML Pipeline in an Emulation Environment
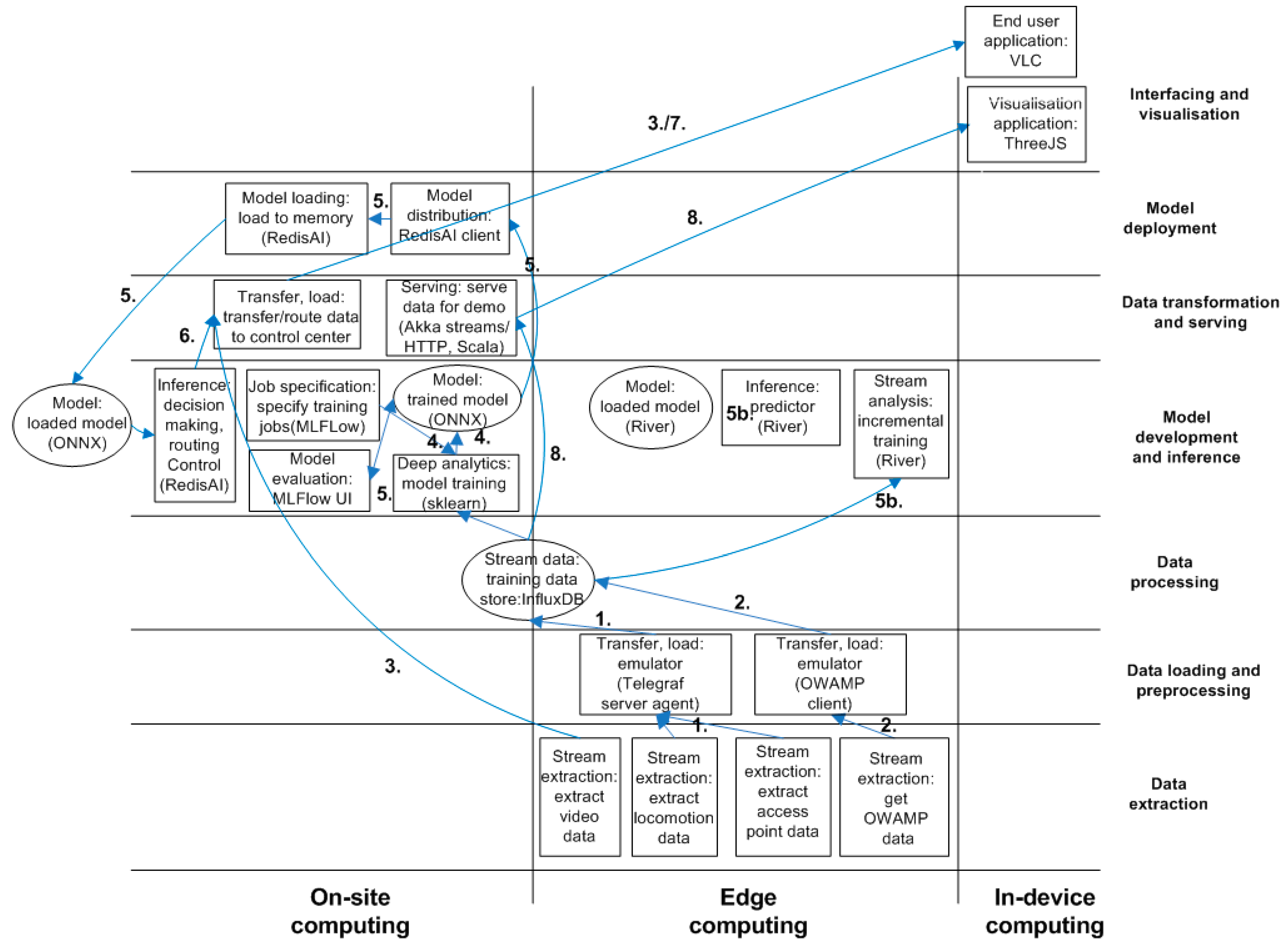
4.1.1. System View
4.1.2. Deployment Environment View
- 1: Access point data, vehicle speed, direction, and location were extracted (at the router), transferred, and loaded into a training data store (InfluxDB) from the emulator.
- 2: OWD was measured/extracted with OWAMP tools and the results were saved.
- 3: Video data were streamed and transferred towards the control center for visualization purposes at end-user application (VLC).
- 4: A ML engineer/data scientist specified jobs for model training (deep analytics), and the results were logged to MLFlow.
- 5: The trained model(s) were evaluated via MLFlow UI, transformed to open neural network exchange (ONNX) format [25], and distributed to the inference service (RedisAI), and loaded into memory.
- 5b: Alternatively, a ML engineer/data scientist may manage incremental ML (stream analysis) at the router. In such a case, a local inference service would be executed at the router.
- 6: Predictions provided by RedisAI were utilized for decision-making purposes regarding multi-point routing (i.e., video stream).
- 7: Video streams were visualized with a video player (VLC).
- 8: Emulation data were served for 3D visualization purposes of the moving vehicles in a mining environment.
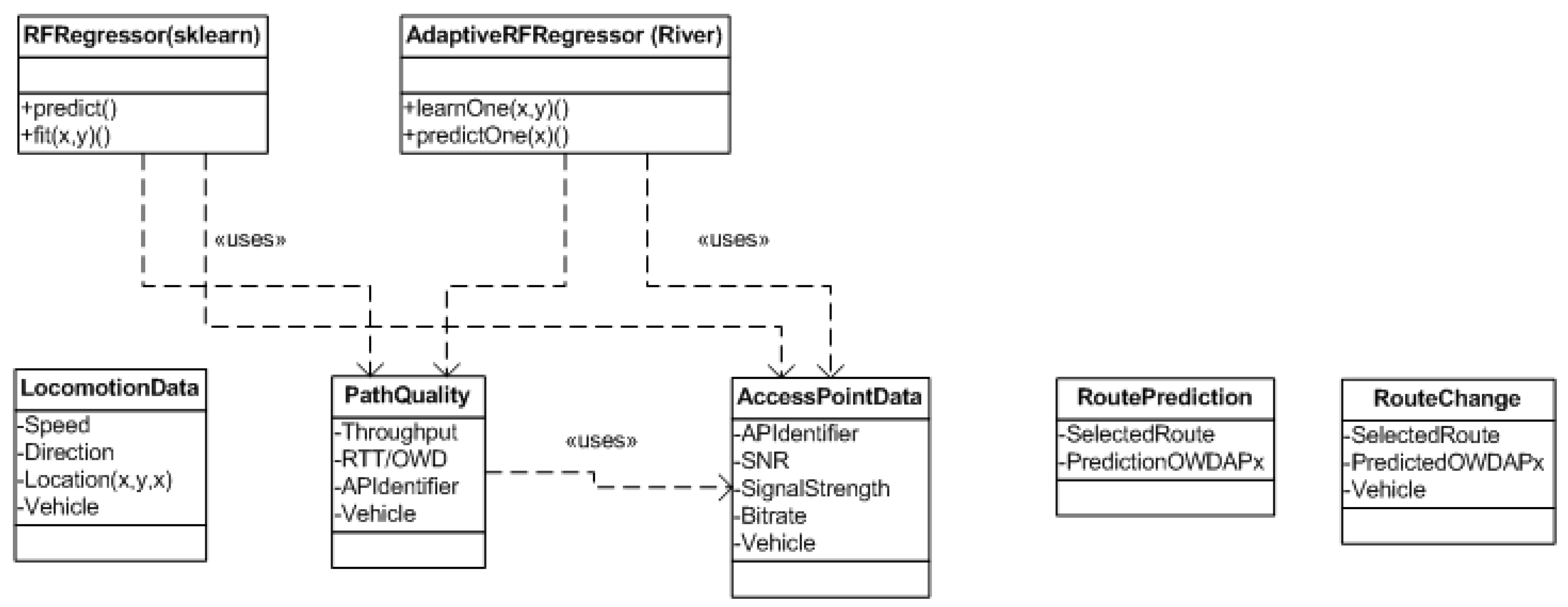
4.1.3. Data View
4.1.4. Model Training and Deployment
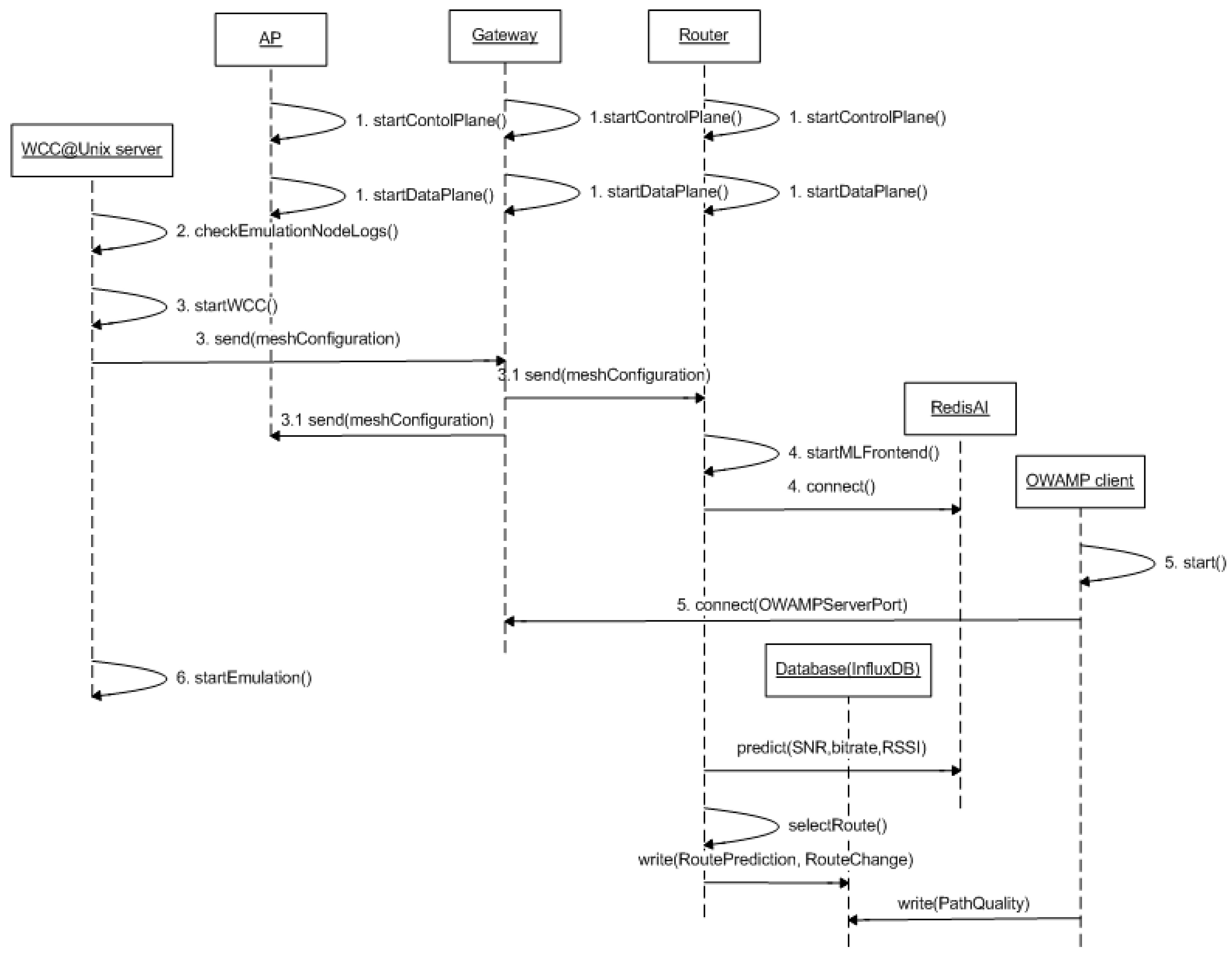
- Steps 1.2–1.3: The OWAMP client is started for measurement of OWD during emulation. During/after emulation, measurement data are saved into a database (Figure 6) at the edge node.
- Step 2.1: The ML engineer/data scientist manages ML pipelines, which includes mainly model training with different parameters. Model training is started.
- Steps 2.11–2.3: A model training job reads training data from the database and trains a prediction model. The model is logged into MLFlow.
- Steps 2.4–2.5: The ML engineer/data scientist may evaluate different versions of models via MLFlow UI. After evaluation, the most suitable model is selected for deployment.
- Steps 2.5–2.53 The model is transformed into ONNX format. Subsequently, the model file is transferred to RedisAI (with a RedisAI client), where the model is loaded into memory.
4.1.5. ML-Based Inference
- Steps 3.1–3.2: OWAMP client is started for measurement of OWD. Additionally, the emulation is started.
- Step 3.3: The emulator reads access point data from a pre-configured file regarding communication quality in real time. The data are provided to the predictor (RedisAI), which returns OWD predictions for different APs.
- Steps 3.31–3.32: The prediction(s) are used for decision-making purposes regarding multi-access routing. The AP associated with the lowest (predicted) OWD is selected for routing.
- Step 3.33: The predicted and measured OWD, AP data, route predictions, and routing table changes are saved into the database during emulation.
- Steps 3.4–3.5: The ML scientist reads predicted and realized OWD from the database and evaluates performance of the ML-based model after emulation.
- Step 4: The ML scientist selects a model for deployment after comparing the performance of several ML-based models with emulations.
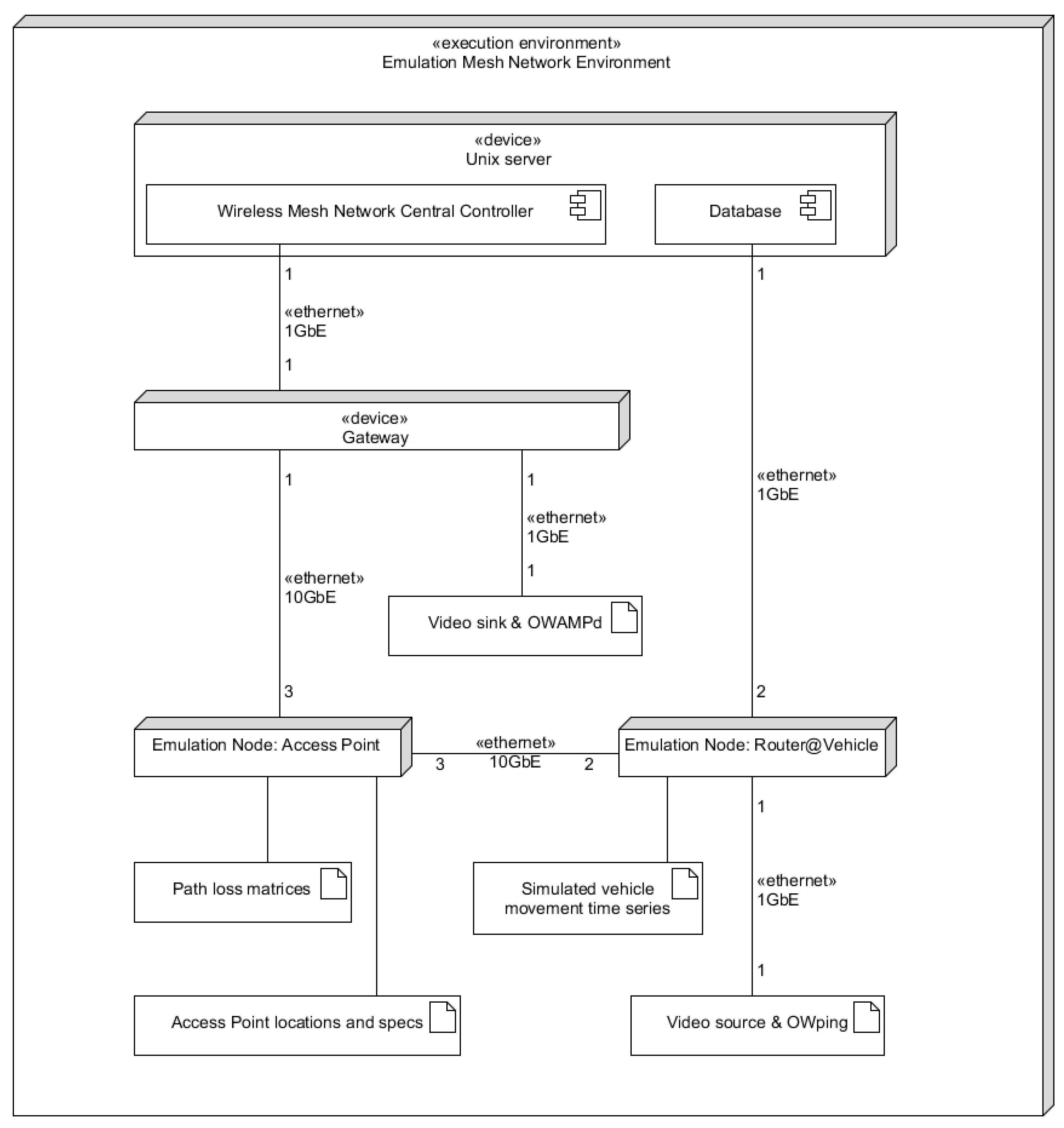
4.2. Emulation Environment
4.2.1. Network and Vehicle Movement Simulation
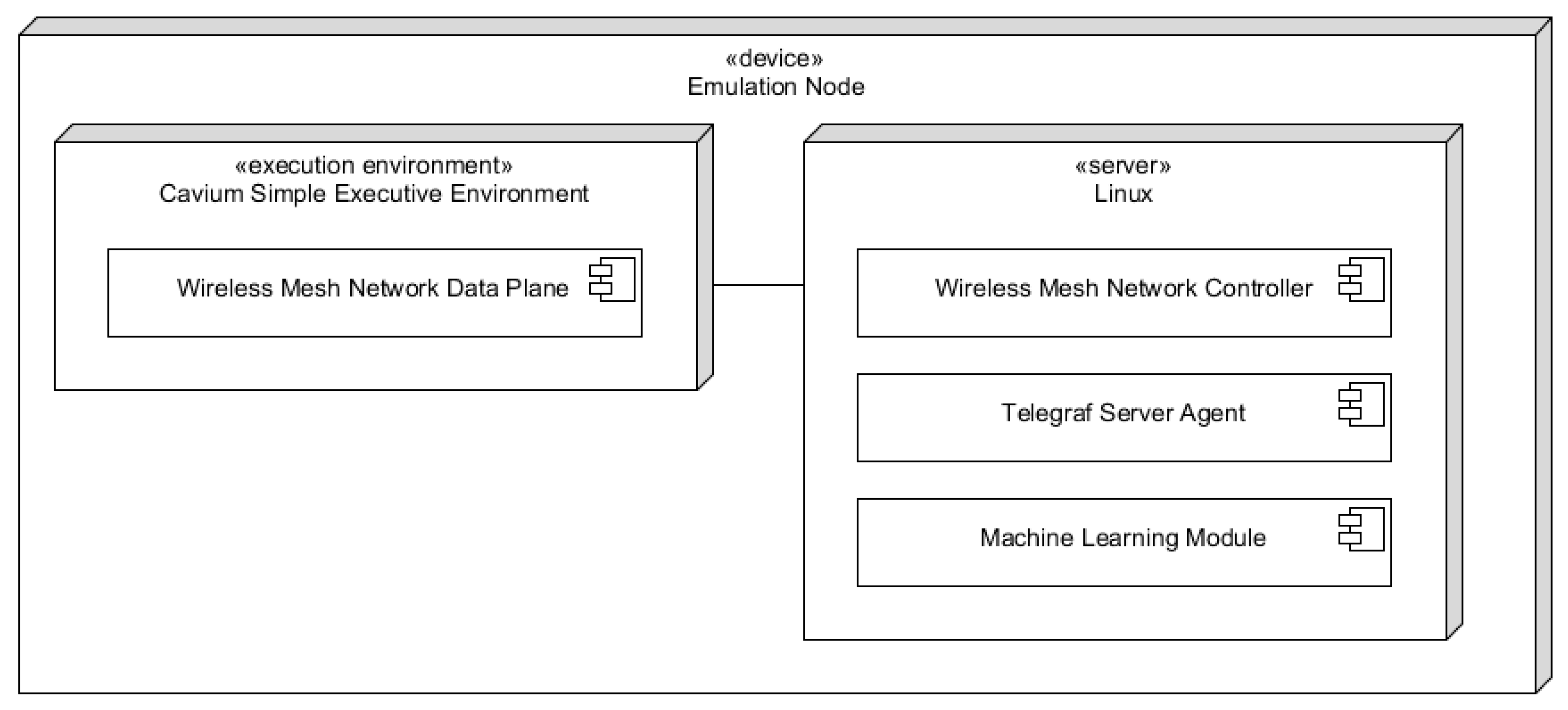
4.2.2. Wireless Mesh Network Emulation Environment
- Handles packet routing between 10 Gbe mesh ports and between mesh ports and 1 Gbe user data ports. In access points, it manipulates packet flow according to emulation rules received from the wireless mesh network controller.
- The mobile router sends emulated AP signal quality data to the machine learning module, receives delay predictions from it, and makes a routing decision, which it sends to the data plane, and via Telegraf server agent, to InfluxDB.
- The access point node reads emulated packet flow rules from the received files and sends them to the data plane.
- The gateway node receives a network topology configuration from WCC and sends it to the data plane to be broadcasted to other nodes.
- Receives routing data from the controller and sends it to the InfluxDB data base.
- Communicates received AP signal quality data to RedisAI, receives predictions, and returns them to the caller (wireless mesh network controller).
5. Results
5.1. Experiments
5.2. Evaluation of the Artifacts
5.2.1. Feasibility Evaluations
- RF regressor was trained with sklearn and integrated with MLFlow for visualization of performance (10-fold cross validation) with MLFlow UI. MLFlow had to be executed on the same node with a model training process (sklearn) for realizing performance evaluation with MLFlow UI.
- The RF regressor-based model was converted to ONNX format (with sklearn-onnx library [29]) for transferring to RedisAI. PMML-based models were also experimented with (converted with sklearn2pmml library [30]), but initial inference performance was slower (~19 ms vs. ~1 ms with ONNX-based model in RedisAI).
- A new MLFlow plugin for RedisAI was needed for realizing model deployment (to RedisAI), because the existing RedisAI plugin only supported Tensorflow models. The new MLFlow plugin enabled transfer of ONNX models to RedisAI. The trained ONNX-based model was deployed from MLFlow to RedisAI by executing the plugin from the command line.
- RedisAI was executed as a Docker image and provided predictions for the emulator (via redisai-py library [31]).
- RedisAI had to be placed near the decision-making point. Initially, ~30 ms inference latency was observed, when RedisAI was placed further from the decision-making point (emulator). This led to large OWD peaks in experiments. OWD predictions were needed for each AP for making a decision regarding the most suitable AP for routing (total prediction latency = number of APs * RedisAI prediction latency). Thus, to perform timely/real-time decisions, prediction latency needed to be minimized (~1 ms latency) by placing RedisAI close to the emulator, which led to improved OWD performance.
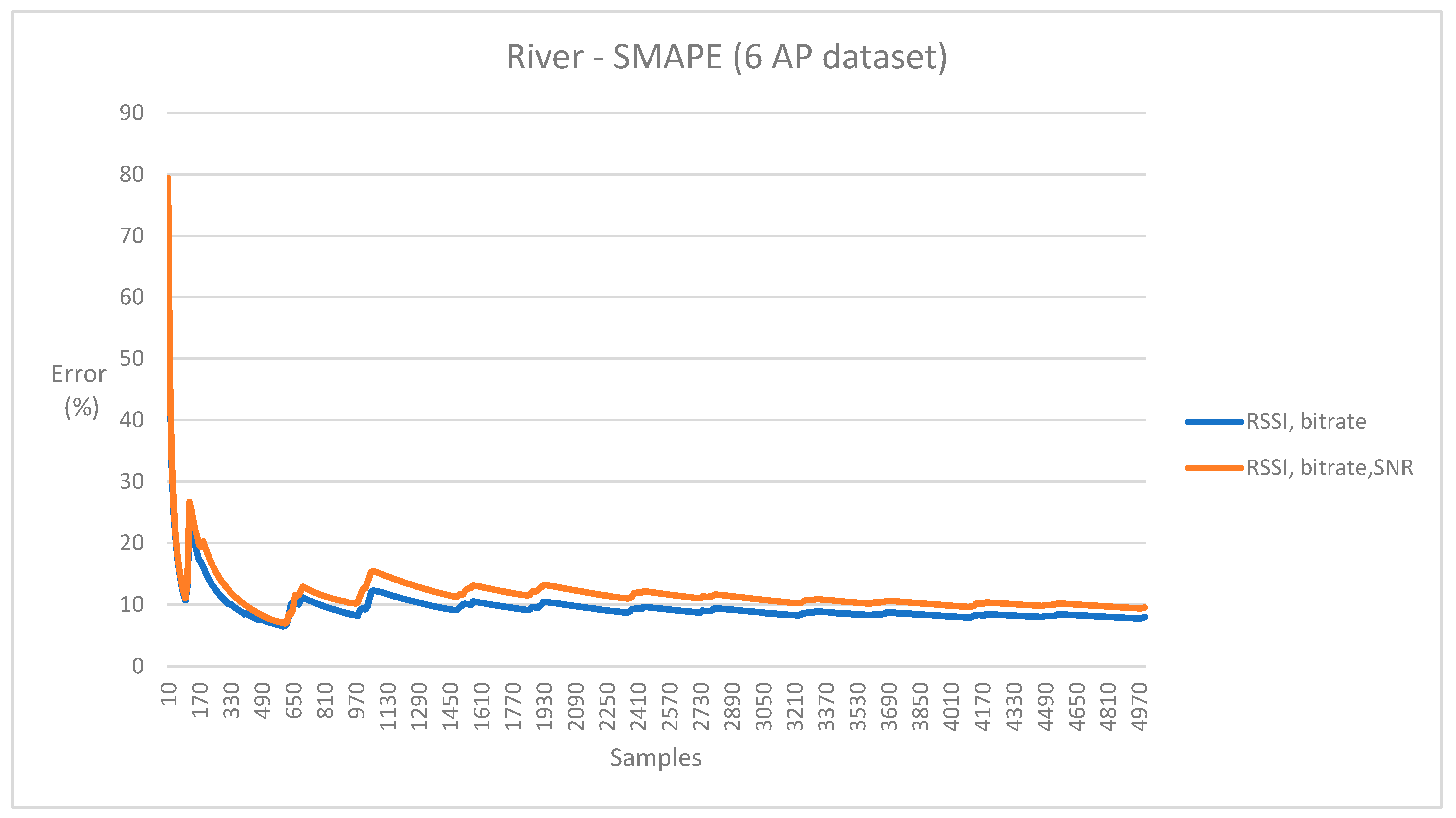
- River-based training could not be integrated with MLFlow. Instead, the training process was managed manually.
- Online training was experimented with using River by updating and retraining the model periodically with new data samples (every 2 s). The trained model was kept in memory.
- The model was locked periodically for both training and inference process with multi-threading. This approach was feasible, since training takes a short time, and the model is available most of the time for prediction purposes (~1.5–1.8 s/2 s). However, this approach also caused occasional inference peaks when the model was trained during inference requests. Prediction delays in the emulator were typically ~1 ms, with occasional peaks (~10–50 ms) during model updates, when predictions were fetched every 200 ms.
- Utilization of the model in online emulation experiments was hindered by not having real time OWD measurements available for training purposes (future work).
5.2.2. Efficiency Evaluations
5.2.3. Operationality Evaluation
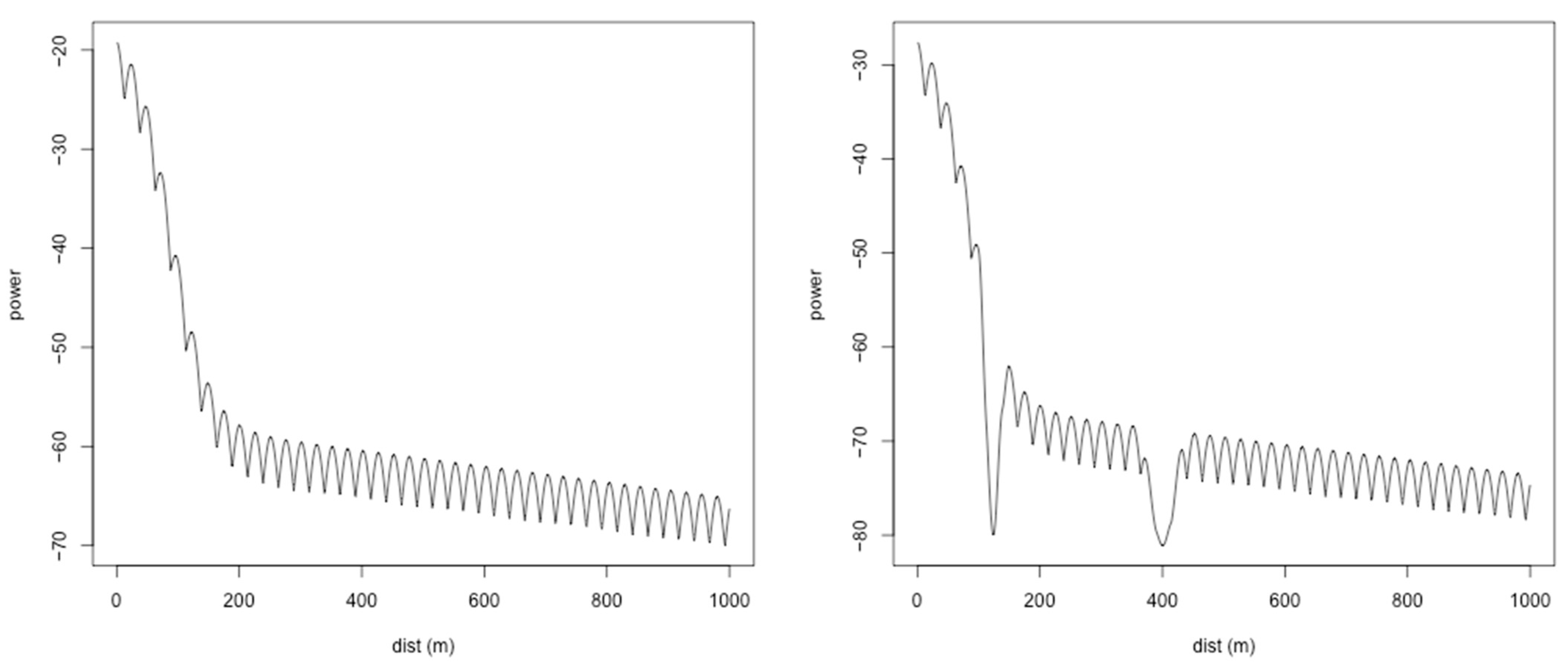
5.2.4. Fidelity to Real World Phenomenon Evaluation
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Appendix A
- Copy emulation CSV files (“ap_data”, “signal_obs”, and “vehiclemove”) into mesh nodes (Rainier machines; e.g., router@vehicle).
- Copy “roles.csv” into mesh nodes. It contains information about nodes meant to act as AP:s or vehicles in emulation). The format is:
- Set emulation topology in WMN centralized controller (WCC) configuration file [control center]. The topology determines the links and interfaces of mesh nodes used for vehicle–AP communication.
- In WCC configuration file, the gateway and vehicle nodes must be configured to accept the same combination of IP subnets in user data.
- Ensure, that servers (Edge-node 3, OWAMP-client node) connected to mesh gateway node and vehicle (Router@vehicle) user data ports and the gateway node itself are connected to the network time protocol (NTP) network. The IP addresses of server interfaces to the nodes must belong to a subnet accepted by the gateway and vehicle nodes in WCC configuration.
- Start OWAMP daemon in a server machine (edge node) connected to the gateway node user data port.
- Send SSH command to emulation nodes [router@vehicle] to start the data and control planes in them. The control plane application “wmn_control” check from “roles.csv” if the node has an AP or vehicle role in emulation and reads the corresponding data from the CSV files.
- Check from control plane traces [monitored in control center], that all needed links come up in emulation nodes. If not, reboot the node and restart data and control planes.
- Start WCC in a server machine [control center]. WCC sends the mesh configuration to the nodes, which organize according to the configured topology. AP and vehicle nodes receive information from their neighbor emulation nodes.
- Log with SSH to vehicle node [router@vehicle]. Start the ML service front end script “ml_frontend_redis.py”. It connects to the Redis server [Edge-node 2] and the local control plane.
- Start OWAMP client [OWAMP client] in a server machine [OWAMP-client node] connected to the vehicle node user data port. The ping interval should be the same as the vehicle node ML query interval, e.g., 300 ms with six AP:s. The destination address is the server interface address connected to the gateway user data port. The client dumps the measured delays into a file.owping -t -c 12000 -i 0.3f -L 10 -R 192.168.200.2 > res.txt
- Start emulation from the WCC command prompt [control center]. Give optionally a number indicating delay (seconds) before emulation start (if omitted, delay is 10 s)

Appendix B


References
- Sandvik Underground Trucks. Available online: https://www.rocktechnology.sandvik/en/products/underground-loaders-and-trucks/underground-trucks/ (accessed on 29 August 2022).
- Sandvik Automine. Available online: https://www.rocktechnology.sandvik/en/products/automation/automine-equipment-and-teleoperation-systems/ (accessed on 29 August 2022).
- Network Simulator NS-3. Available online: https://www.nsnam.org/ (accessed on 29 August 2022).
- EXata Network Emulator. Available online: https://www.ncs-in.com/product/exata-network-emulator/ (accessed on 29 August 2022).
- Baylor, D.; Haas, K.; Katsiapis, K.; Leong, S.; Liu, R.; Menwald, C.; Miao, F.; Polyzotis, N.; Trott, M.; Zinkevich, M. Continuous Training for Production ML in the TensorFlow Extended (TFX) Platform. In Proceedings of the USENIX Conference on Operational Machine Learning, Santa Clara, CA, USA, 20 May 2019. [Google Scholar]
- Luong, M.; Pham, C. Incremental Learning for Autonomous Navigation of Mobile Robots based on Deep Reinforcement Learning. J. Intell. Robot. Syst. 2021, 101, 1–11. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, D.; Yan, H.; Cui, Y.; Chen, L. A New Algorithm of the Best Path Selection Based on Machine Learning. IEEE Access 2019, 7, 126913–126928. [Google Scholar] [CrossRef]
- Roselló, M.M. Multi-path Scheduling with Deep Reinforcement Learning. In Proceedings of the European Conference on Networks and Communications (EuCNC), Valencia, Spain, 18–21 June 2019. [Google Scholar]
- Chung, J.; Han, D.; Kim, J.; Kim, C. Machine learning based path management for mobile devices over MPTCP. In Proceedings of the IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju, Korea, 13–16 February 2017. [Google Scholar]
- Polese, M.; Bonati, M.; D’Oro, S.; Basagni, S.; Melodia, T. ColO-RAN: Developing Machine Learning-based xApps for Open RAN Closed-loop Control on Programmable Experimental Platforms. IEEE Trans. Mob. Comput. 2022. [Google Scholar] [CrossRef]
- MLflow. Available online: https://mlflow.org/ (accessed on 29 August 2021).
- RedisAI. Available online: https://oss.redislabs.com/redisai/ (accessed on 29 August 2021).
- Montiel, J.; Halford, M.; Mastelin, S.M.; Bolmier, G.; Sourty, R.; Vaysse, R.; Zouitine, A.; Gomes, H.M.; Read, J.; Abdessalem, T.; et al. River: Machine learning for streaming data in Python. arXiv 2020, arXiv:aabs/2012.04740. [Google Scholar]
- Chen, A.; Chow, A.; Davidson, A.; Cunha, A.; Ghodsi, A.; Hon, S.; Konwinski, A.; Mewald, C.; Murching, S.; Nykodym, T.; et al. Developments in MLflow: A System to Accelerate the Machine Learning Lifecycle. In Proceedings of the Fourth International Workshop on Data Management for End-to-End Machine Learning, Portland, OR, USA, 14 June 2020. [Google Scholar]
- Ray, S.K.; Susan, S. Performance Evaluation using Online Machine Learning Packages for Streaming Data. In Proceedings of the International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 25–27 January 2022. [Google Scholar]
- Niu, Z.; Xue, J.; Qu, D.; Wang, Y.; Zheng, J.; Zhu, H. A novel approach based on adaptive online analysis of encrypted traffic for identifying Malware in IIoT. Inf. Sci. 2022, 601, 162–174. [Google Scholar] [CrossRef]
- Tang, J.; Liu, G.; Pan, Q. A review on representative swarm intelligence algorithms for solving optimization problems: Applications and trends. IEEE/CAA J. Autom. Sin. 2021, 8, 1627–1643. [Google Scholar] [CrossRef]
- Peffers, K.; Tuunanen, T.; Rothenberger, M.A.; Shatterjee, S. A Design Science Research Methodology for Information Systems. J. Manag. Inf. Syst. 2007, 24, 45–77. [Google Scholar] [CrossRef]
- March, S.T.; Smith, G.F. Design and natural science research on information technology. Decis. Support Syst. 1995, 15, 251–266. [Google Scholar] [CrossRef]
- Sonnenberg, C.; vom Brocke, J. Evaluations in the Science of the Artificial–Reconsidering the Build-Evaluate Pattern in Design Science Research. In Proceedings of the International Conference on Design Science Research in Information Systems and Technology, Las Vegas, NV, USA, 14–15 May 2012. [Google Scholar]
- OWAMP. Available online: https://software.internet2.edu/owamp/owping.man.html (accessed on 29 August 2022).
- InfluxDB. Available online: https://www.influxdata.com/ (accessed on 29 August 2022).
- SKLearn/Scikit-Learn. Available online: https://scikit-learn.org/ (accessed on 29 August 2022).
- Pääkkönen, P.; Pakkala, D. Extending reference architecture of big data systems towards machine learning in edge computing environments. J. Big Data 2020, 7, 1–29. [Google Scholar] [CrossRef] [Green Version]
- Open Neural Network Exchange (ONNX). Available online: https://onnx.ai/ (accessed on 29 August 2022).
- Jacksha, R.; Zhou, C.; Sunderman, C. Measurement of the Influence of Antennas on Radio Signal Propagation in Underground Mines and Tunnels. Prog. Electromagn. Res. C Pier C 2019, 94, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Wainio, P.; Seppänen, K. Self-optimizing last-mile backhaul network for 5G small cells. In Proceedings of the IEEE International Conference on Communications Workshops (ICC), Kuala Lumpur, Malaysia, 23–27 May 2016. [Google Scholar]
- Seppänen, K.; Kilpi, J.; Paananen, J.; Suihko, T.; Wainio, P.; Kapanen, J. Multipath routing for mmWave WMN backhaul. In Proceedings of the IEEE International Conference on Communications Workshops (ICC), Kuala Lumpur, Malaysia, 23–27 May 2016. [Google Scholar]
- Sklearn-Onnx. Available online: https://github.com/onnx/sklearn-onnx/ (accessed on 29 August 2022).
- Sklearn2pmml. Available online: https://github.com/jpmml/sklearn2pmml (accessed on 29 August 2022).
- Redisai-py. Available online: https://github.com/RedisAI/redisai-py (accessed on 29 August 2022).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | MLP Regressor | RandomForestRegressor | River |
|---|---|---|---|
| Training features | RSSI, bitrate, and SNR | RSSI, bitrate, and SNR | RSSI and bitrate or RSSI, bitrate, and SNR |
| Algorithm configuration | default | n_estimators = 100 | n_models = 10, seed = random, algorithm = AdaptiveRandomForestRegressor |
| Accuracy metric | Stratified K-fold (10) | Stratified K-fold (10) | Symmetric MAPE |
| Feature importances | - | RSSI = 0.0386, bit rate = 0.946, SNR = 0.015 | - |
| Accuracy | 0.91± 0.07 | 0.935 ± 0.05 | RSSI, bitrate, and SNR: 6.648% |
| Short Test: 6 min | Long Test: 1 h | |||
|---|---|---|---|---|
| Vehicle 1 | OWD (ms) | Prediction error (%) | OWD (ms) | Prediction error (%) |
| RSSI | 15.40 | 16.10 | ||
| ML | 14.58 | 14.03 | ||
| ML improvement (%) | 5.34 | 5.70 | 12.85 | 7.52 |
| Vehicle 2 | ||||
| RSSI | 15.16 | 15.90 | ||
| ML | 13.42 | 14.04 | ||
| ML improvement (%) | 11.53 | 6.11 | 11.71 | 5.38 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pääkkönen, P.; Backman, J.; Pakkala, D.; Paananen, J.; Seppänen, K.; Ahola, K. Concept and Architecture for Applying Continuous Machine Learning in Multi-Access Routing at Underground Mining Vehicles. Appl. Sci. 2022, 12, 10679. https://doi.org/10.3390/app122010679
Pääkkönen P, Backman J, Pakkala D, Paananen J, Seppänen K, Ahola K. Concept and Architecture for Applying Continuous Machine Learning in Multi-Access Routing at Underground Mining Vehicles. Applied Sciences. 2022; 12(20):10679. https://doi.org/10.3390/app122010679
Chicago/Turabian StylePääkkönen, Pekka, Jere Backman, Daniel Pakkala, Jori Paananen, Kari Seppänen, and Kimmo Ahola. 2022. "Concept and Architecture for Applying Continuous Machine Learning in Multi-Access Routing at Underground Mining Vehicles" Applied Sciences 12, no. 20: 10679. https://doi.org/10.3390/app122010679