
Secure and Robust Internet of Things with High-Speed Implementation of PRESENT and GIFT Block Ciphers on GPU

Abstract
:1. Introduction
Contributions
- Fast GPU implementation of PRESENT and GIFT Both PRESENT and GIFT block ciphers utilize S-box, which can be pre-computed and stored on various GPU memories to achieve high encryption performance. In this paper, we move away from this traditional technique and focus on the advanced bit-slicing technique to further improve the throughput performance. Existing bit-slice implementation on GPU suffers from excessive use of registers. To avoid this issue, the proposed implementation generates the round keys on the fly instead of pre-computing them.
- First GPU-based exhaustive key search and bulk data encryption for both PRESENT and GIFT block ciphers. We performed practical analysis by testing practical use cases (i.e., exhaustive key search and bulk data encryption). When implementing an exhaustive key search, the counter value is directly generated in the bit-sliced form on the GPU kernel. In this way, we do need to transfer the counter values to the GPU. This also reduces the memory copy delay and improves performance significantly.
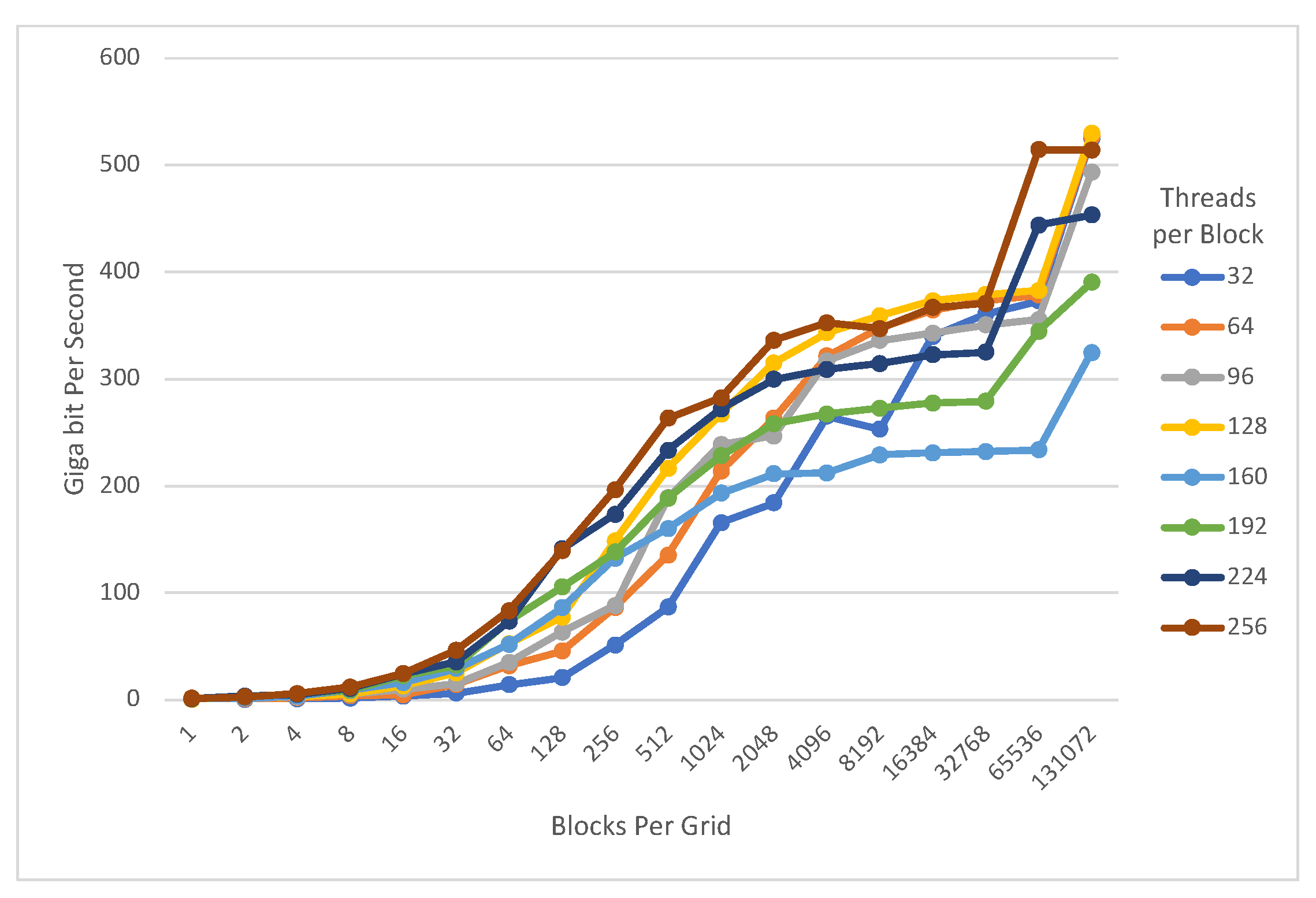
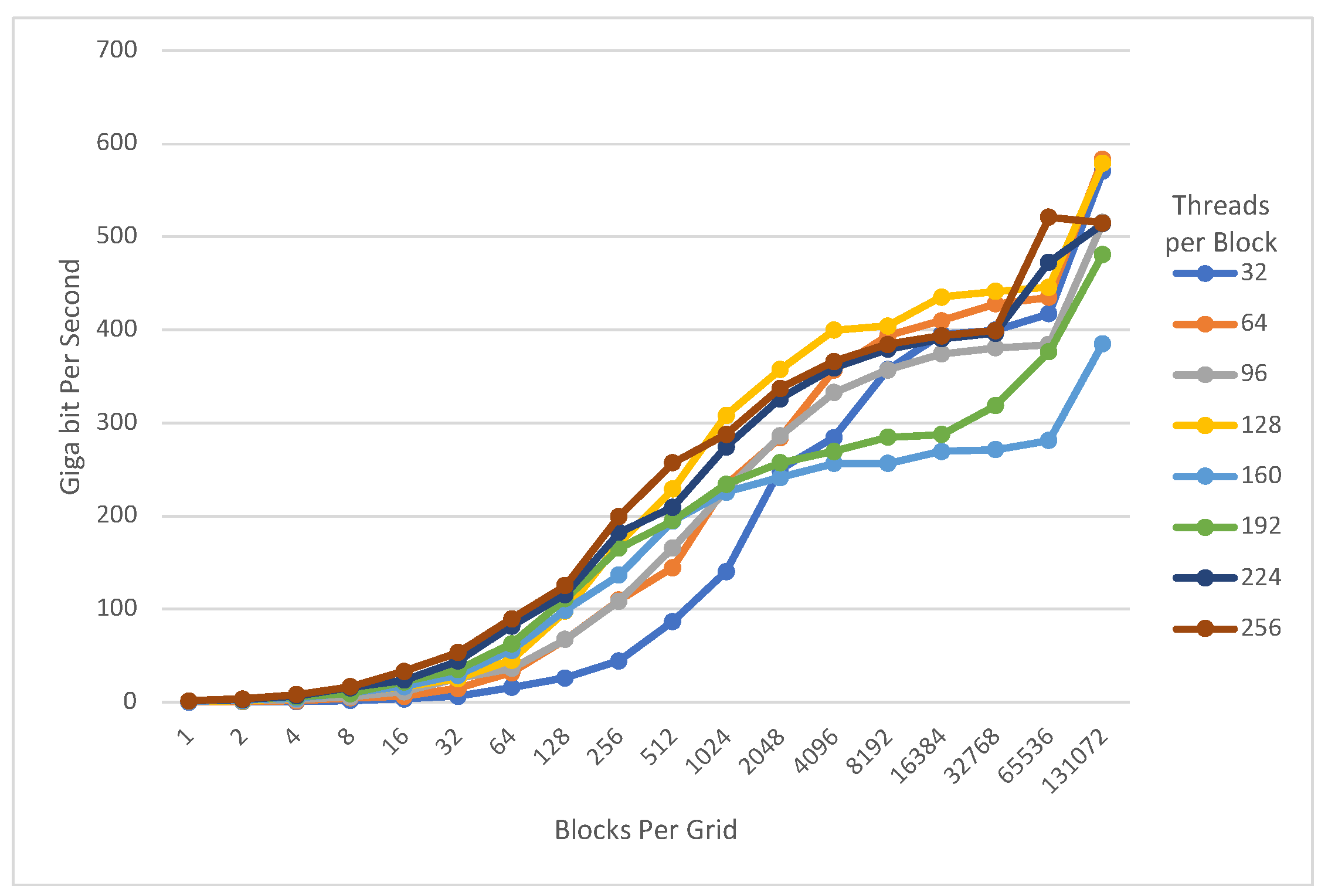
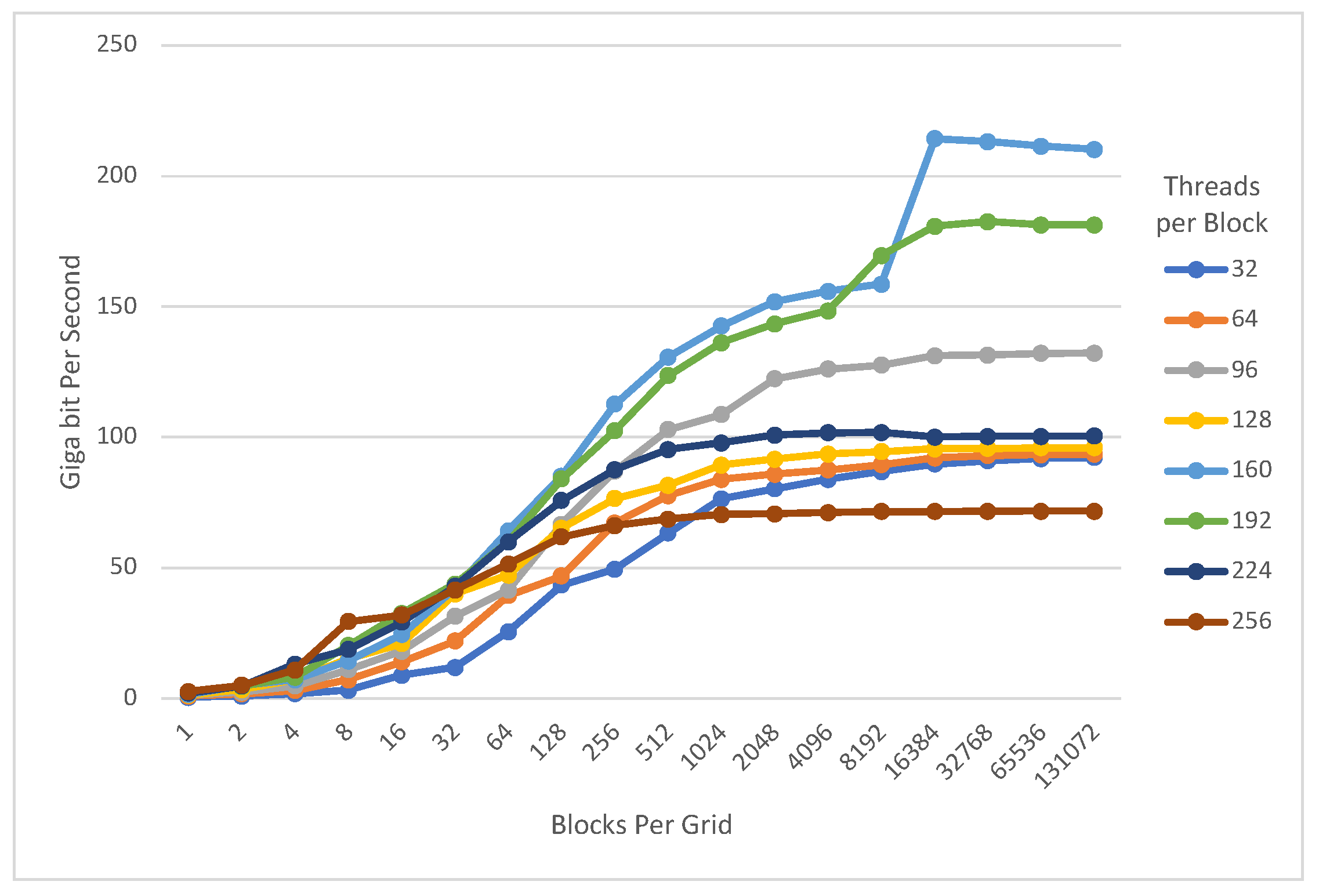
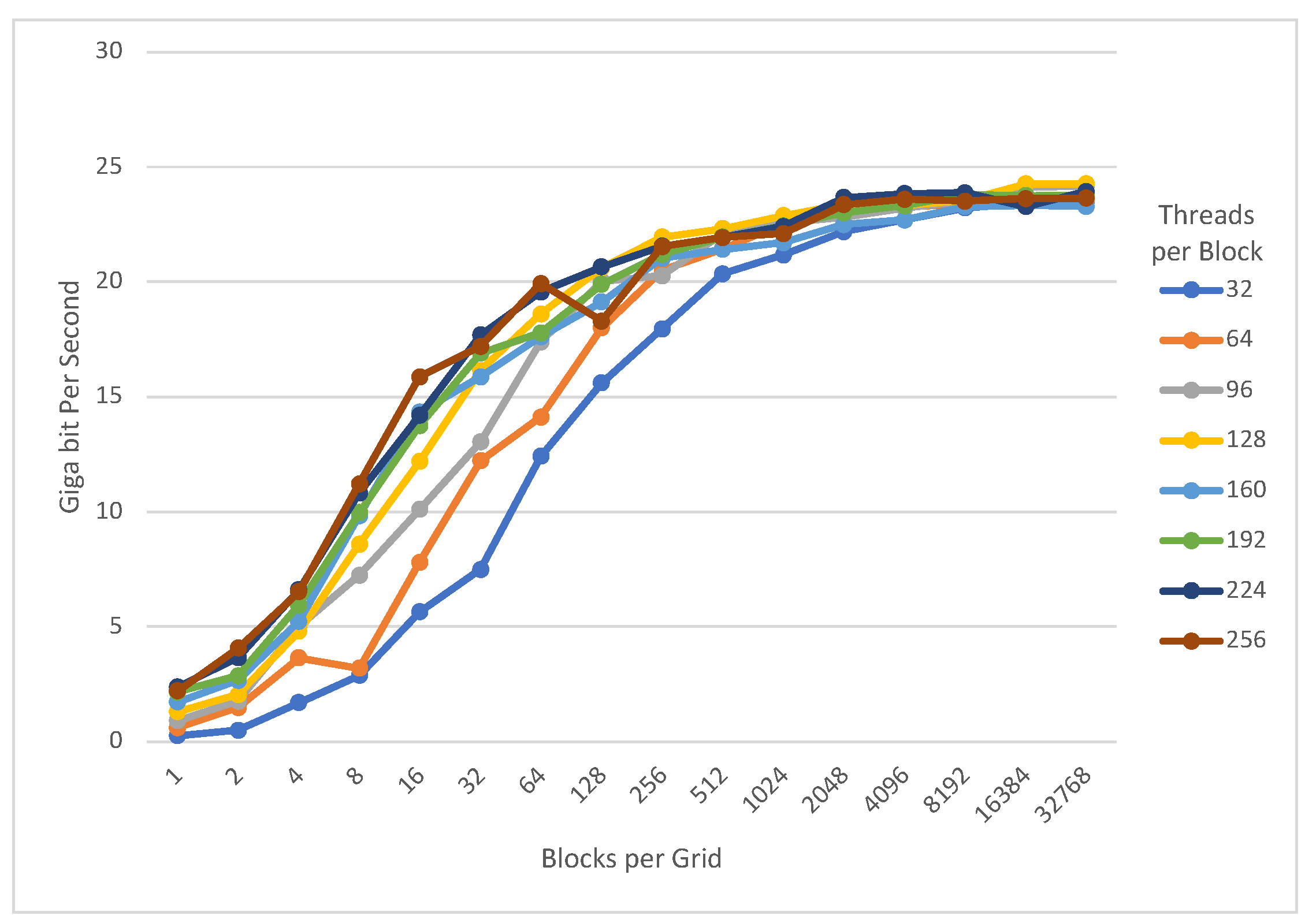
- Speed record result on modern GPU architecture (RTX) The proposed implementation was evaluated on the RTX 3060 with NVIDIA Ampere architecture. We are able to achieve 553.932 Gbps PRESENT-80, 529.952 Gbps PRESENT-128, 583.859 Gbps GIFT-64, and 214.284 Gbps GIFT-128 throughput for encryption, respectively. For exhaustive search, 24.264 Gbps PRESENT-80, 24.522 Gbps PRESENT-128, 85.283 Gbps GIFT-64, and 10.723 Gbps GIFT-128 throughput are achieved, respectively. Note that our implementation of PRESENT is approximately higher performance than the latest work that implements PRESENT [10].
2. Background
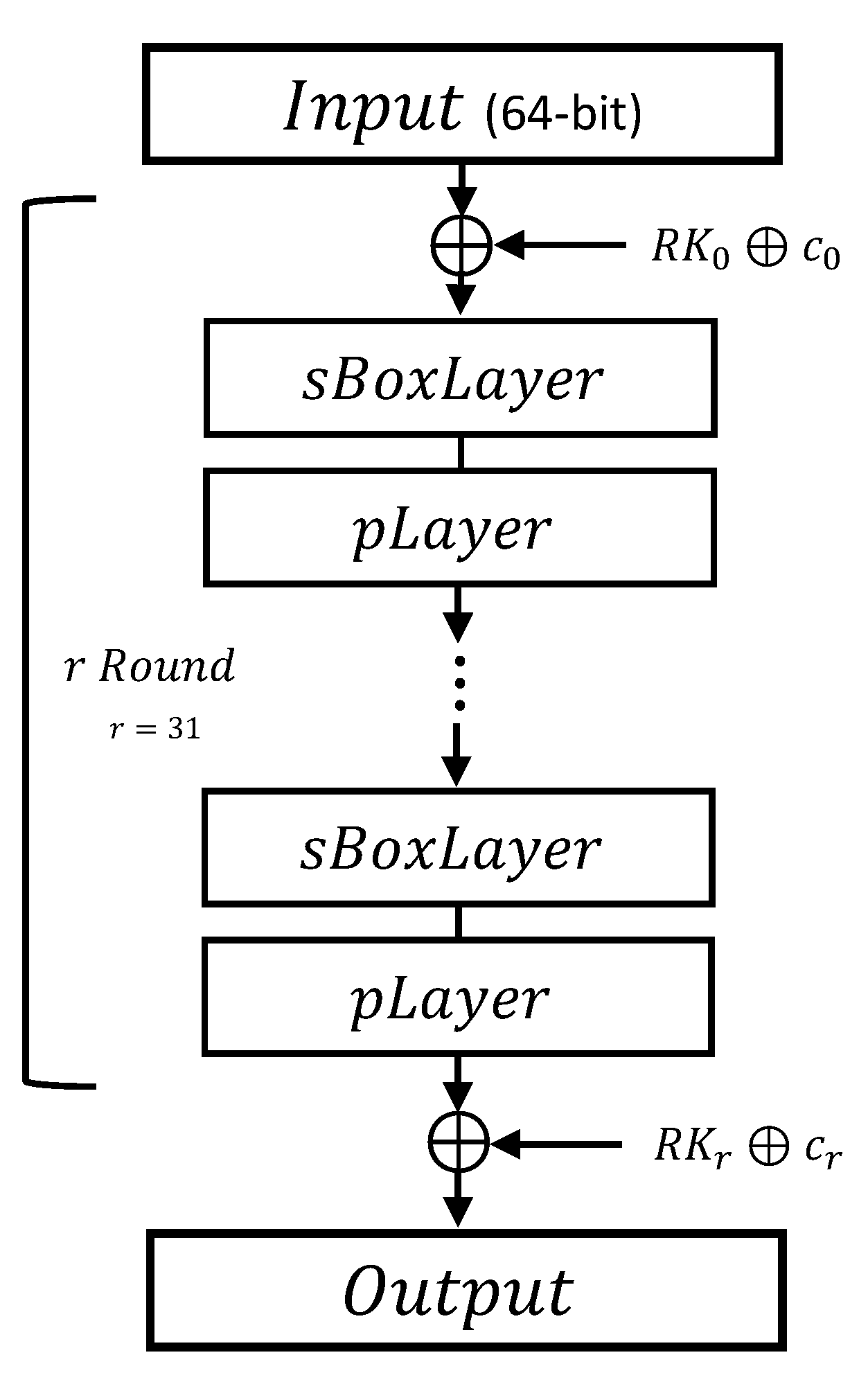
2.1. PRESENT Block Cipher
- AddRoundKey: Adding state to the 64-bit word of the round key using finite field arithmetic.
- sBoxLayer: Using an S-box (replacement box) with 16 values to replace 4-bits to 4-bits in the state.
- pLayer: Applying a bit-level shift to the state.
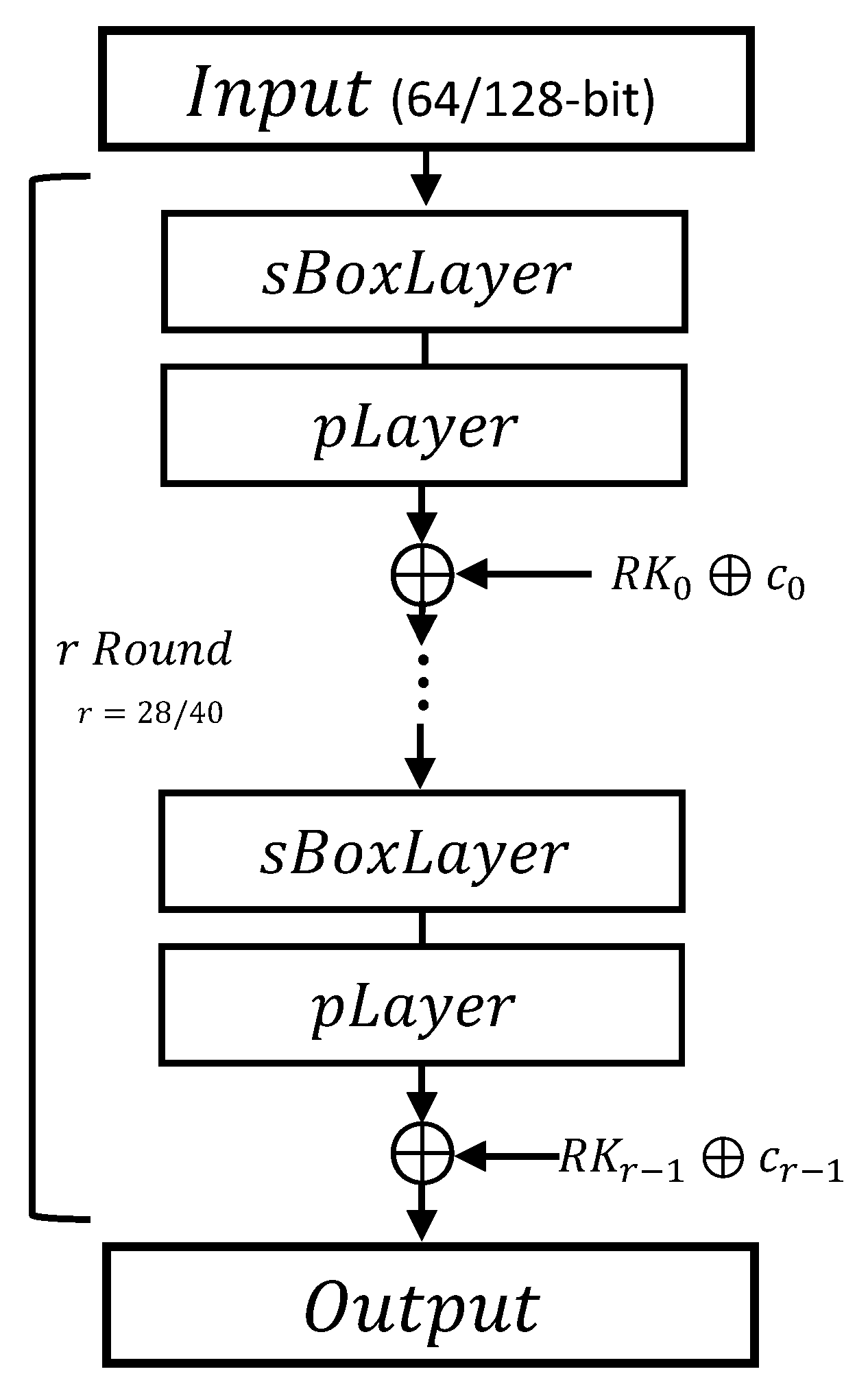
2.2. GIFT Block Cipher
- sBoxLayer: S-box with 16 values (Substitute box) to replace from 4 bits to 4 bits in the state.
- pLayer: Applying a bit-level shift to the state.
- AddRoundKey: Adding state to the 64-bit word of the round key using finite field arithmetic.
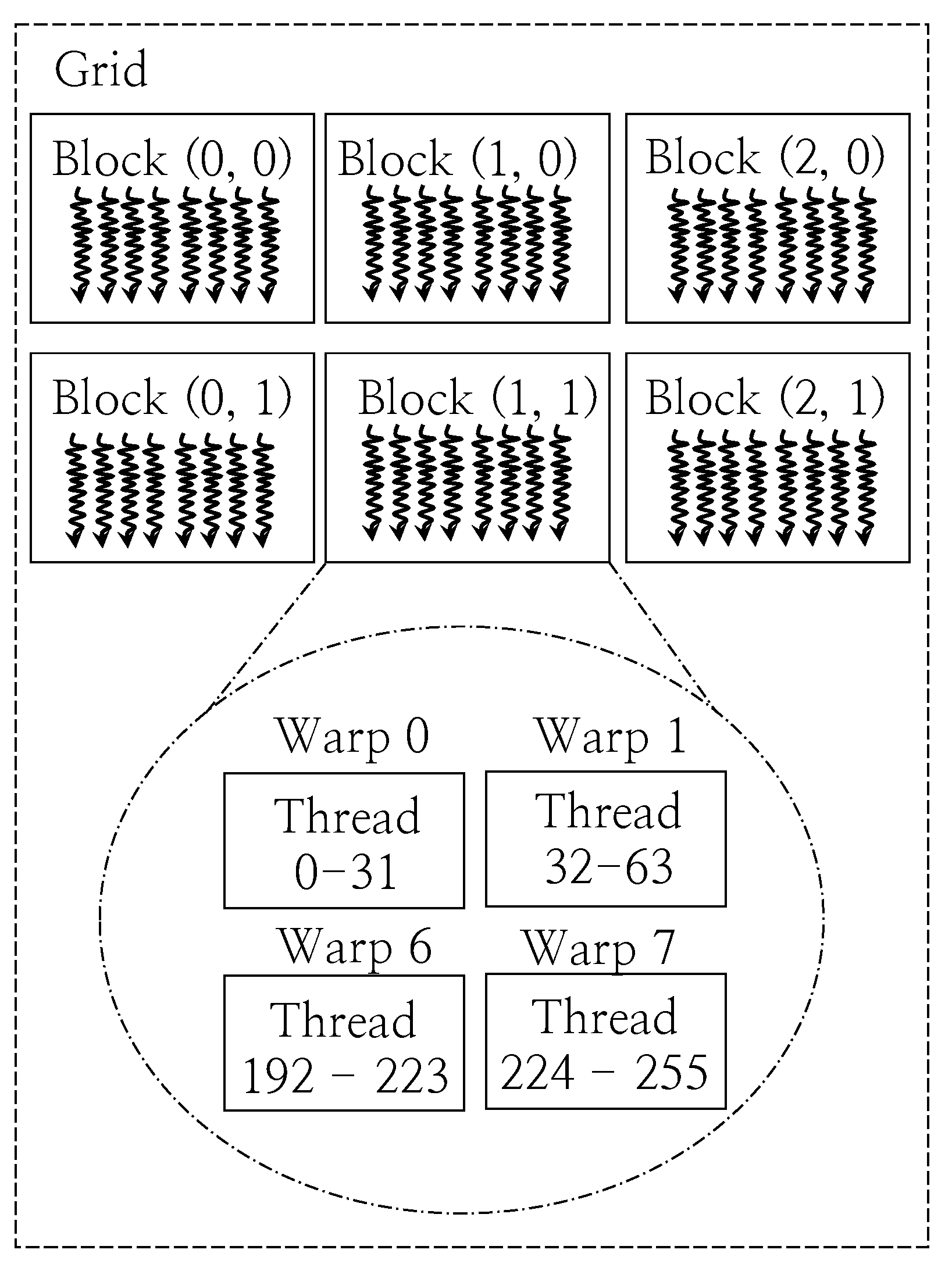
2.3. CUDA Framework
3. Proposed Method
3.1. Bit-Slicing Techniques
3.2. PRESENT Block Cipher
3.2.1. S-Box in Bit-Slicing Form
| Algorithm 1 PRESENT S-box |
| Input: Output:
|
3.2.2. Permutation Layer (pLayer)
| Algorithm 2 PRESENT RoundKey Update |
| Input:r, X Output:Y
|
3.3. GIFT Block Cipher
3.3.1. S-Box in Bit-Slicing Form
| Algorithm 3 GIFT S-box |
| Input:x3, x2, x1, x0 Output:x3, x2, x1, x0
|
3.3.2. Permutation Layer (pLayer)
3.3.3. Roundkey Update
- _ _device_ _ void addRoundConstant ( uint32_t ∗ X, uint32_t r)
- {
- uint32_t GIFT_RC[28] =
- {0x01, 0x03, 0x07, 0x0F, 0x1F, 0x3E, 0x3D,
- 0x3B, 0x37, 0x2F, 0x1E, 0x3C, 0x39, 0x33,
- 0x27, 0x0E, 0x1D, 0x3A, 0x35, 0x2B, 0x16,
- 0x2C, 0x18, 0x30, 0x21, 0x02, 0x05, 0x0B };
- X[ 3] ^= (GIFT_RC[r] & 0x1) ∗ 0xFFFFFFFF;
- X[ 7] ^= ((GIFT_RC[r] >> 1) & 0x1) ∗ 0xFFFFFFFF;
- X[11] ^= ((GIFT_RC[r] >> 2) & 0x1) ∗ 0xFFFFFFFF;
- X[15] ^= ((GIFT_RC[r] >> 3) & 0x1) ∗ 0xFFFFFFFF;
- X[19] ^= ((GIFT_RC[r] >> 4) & 0x1) ∗ 0xFFFFFFFF;
- X[23] ^= ((GIFT_RC[r] >> 5) & 0x1) ∗ 0xFFFFFFFF;
- X[63] ^= 0xFFFFFFFF;
- }
3.4. Overhead of Data Transmission between CPU and GPU
- uint32_t tid = blockIdx.x ∗ blockDim.x + threadIdx.x;
- uint32_t subkeys[80] = {0,};
- subkeys[0] = 0x55555555;
- subkeys[1] = 0x33333333;
- subkeys[2] = 0x0F0F0F0F;
- subkeys[3] = 0x00FF00FF;
- subkeys[4] = 0x0000FFFF;
- for (uint32_t i = 0; i < 31; i++) {
- subkeys[i+5] = ((tid & (1<<i)) >> i) ∗ 0xFFFFFFFF;
- }
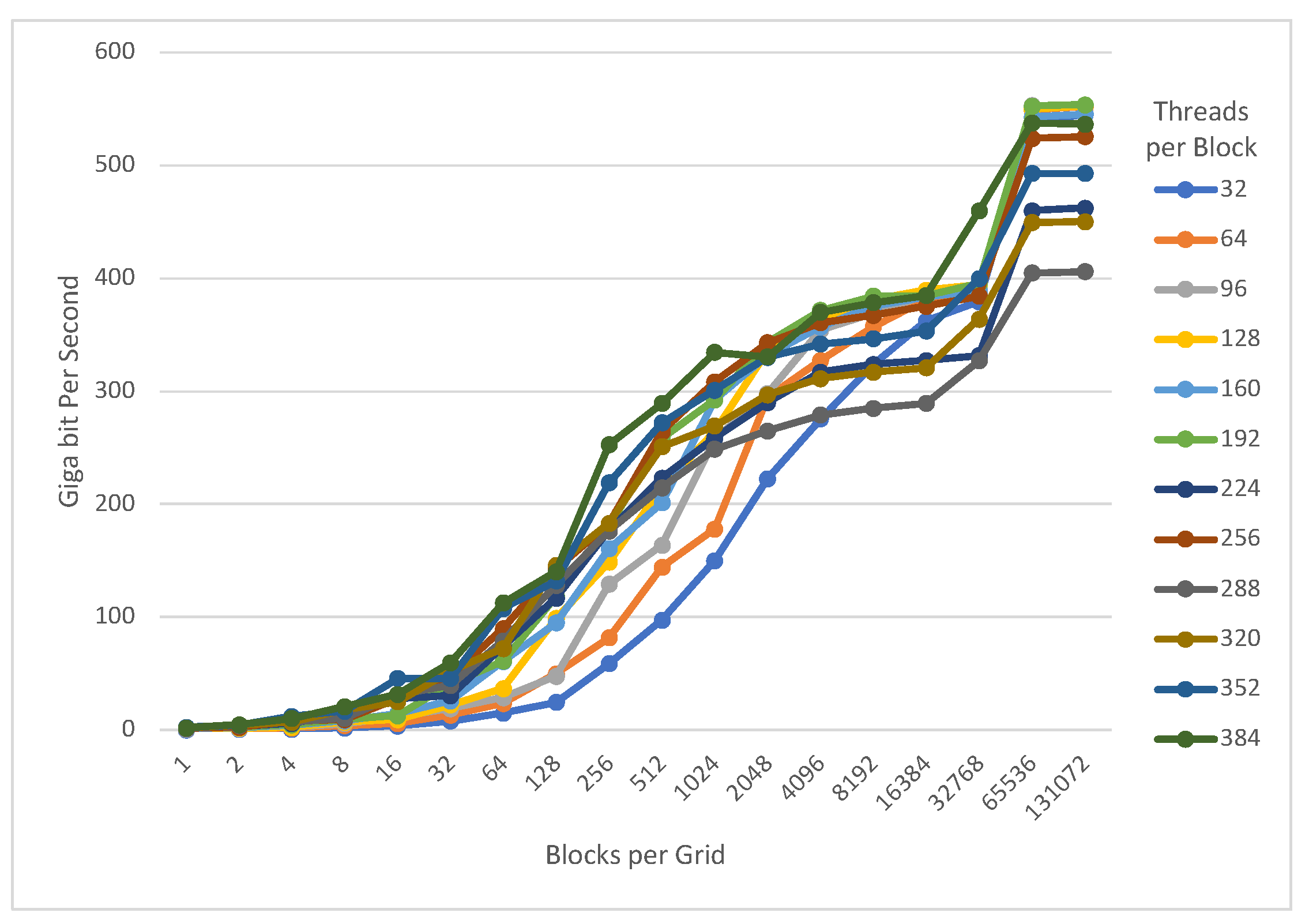
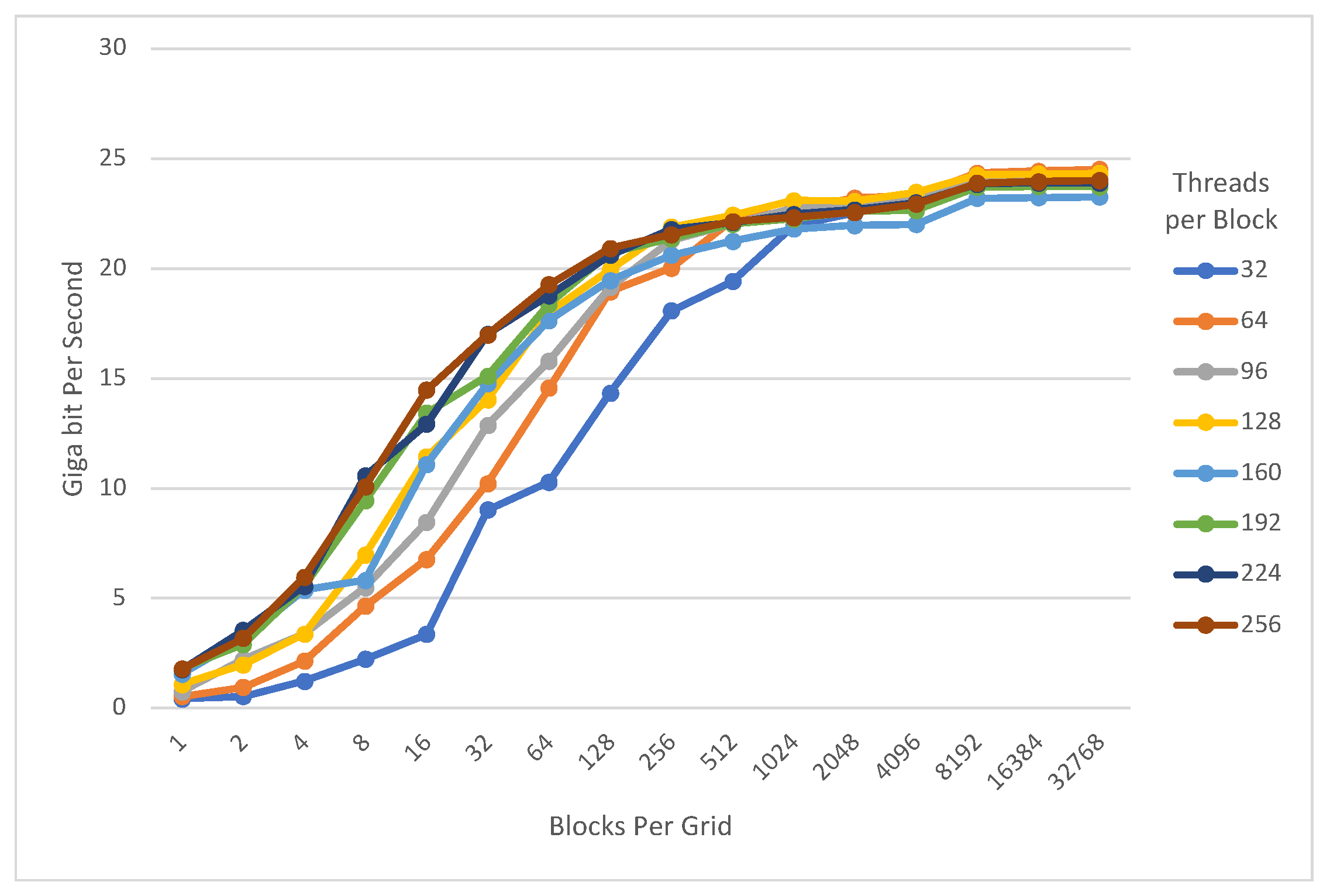
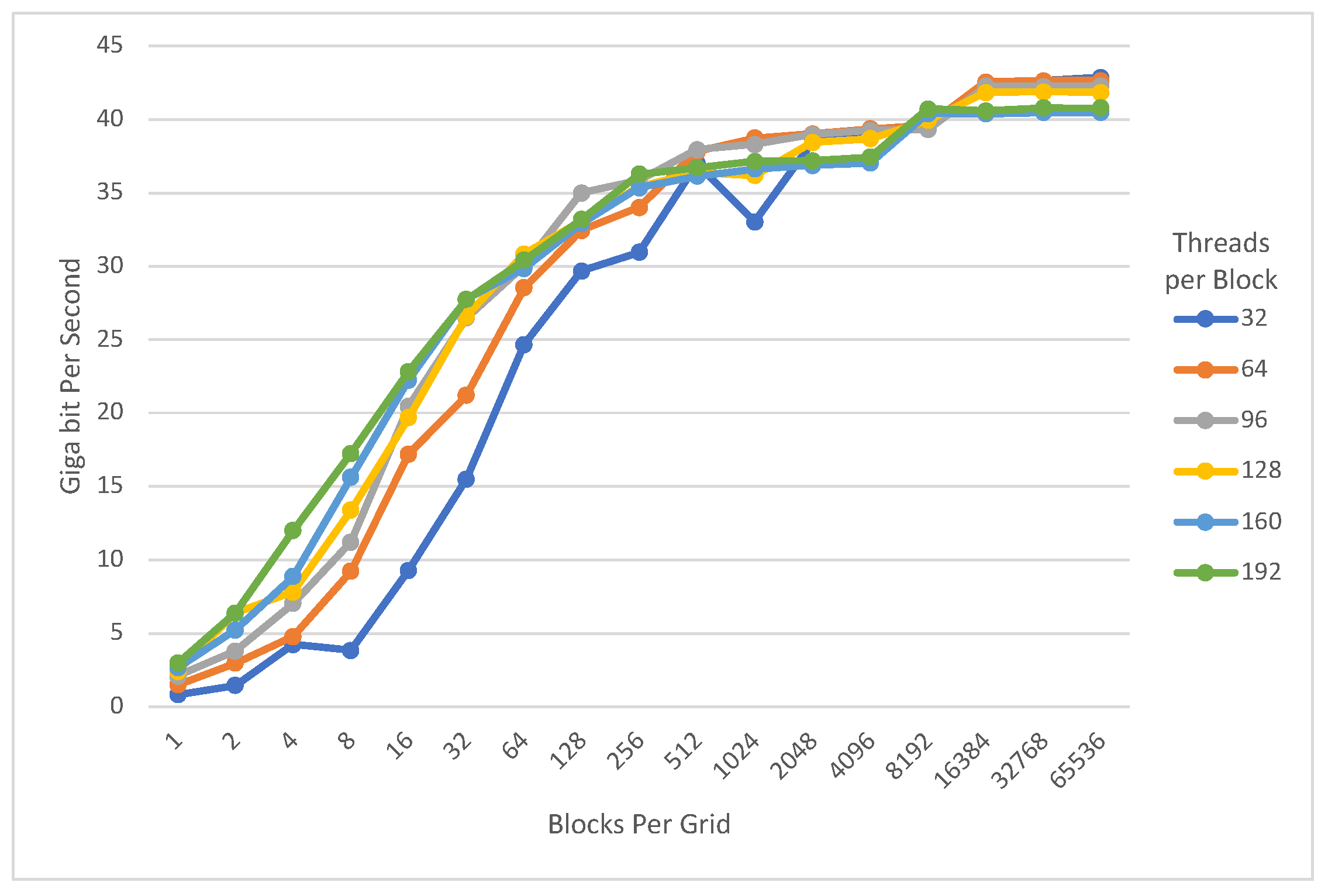
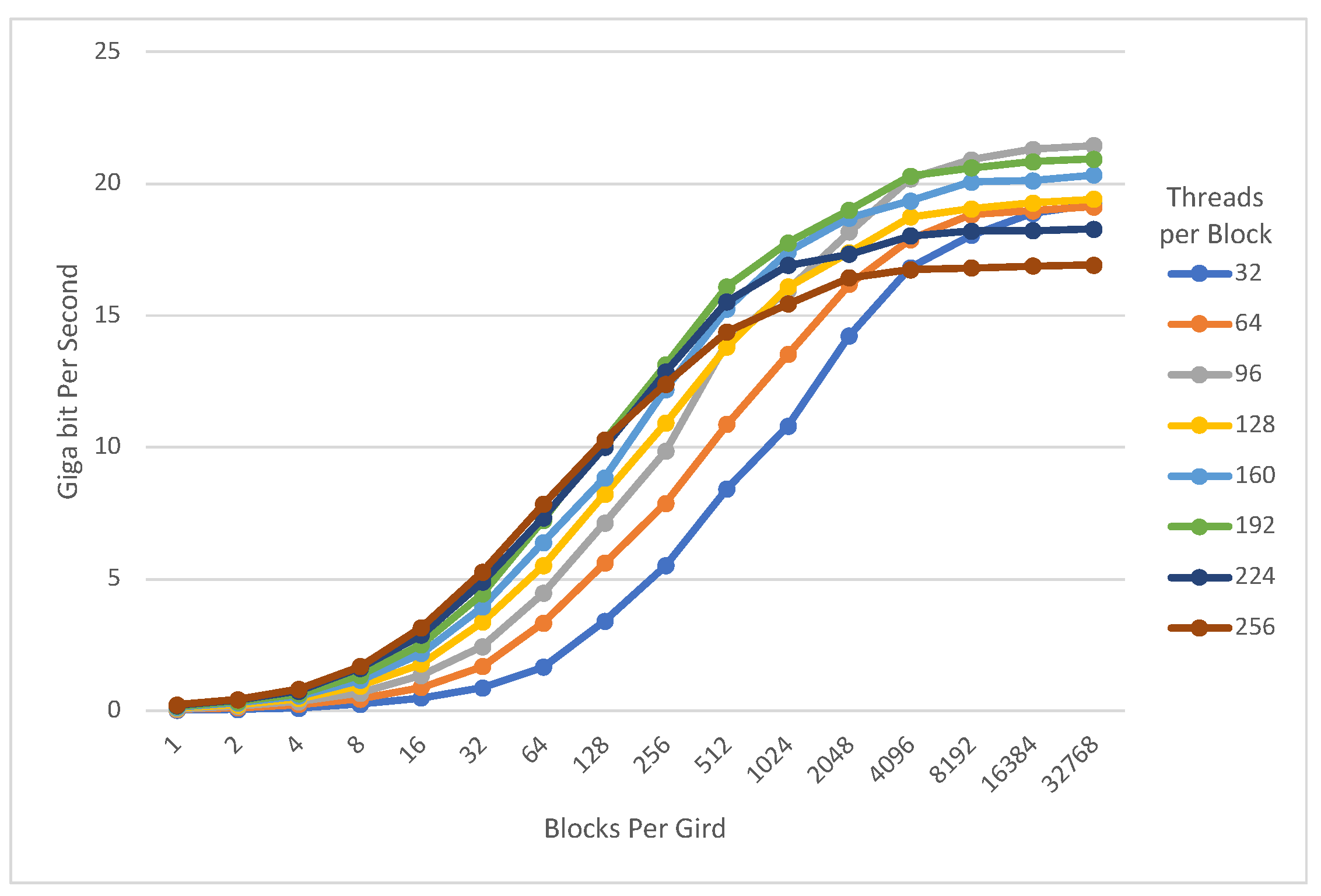
4. Evaluation
4.1. Exhaustive Search
4.2. Data Encryption
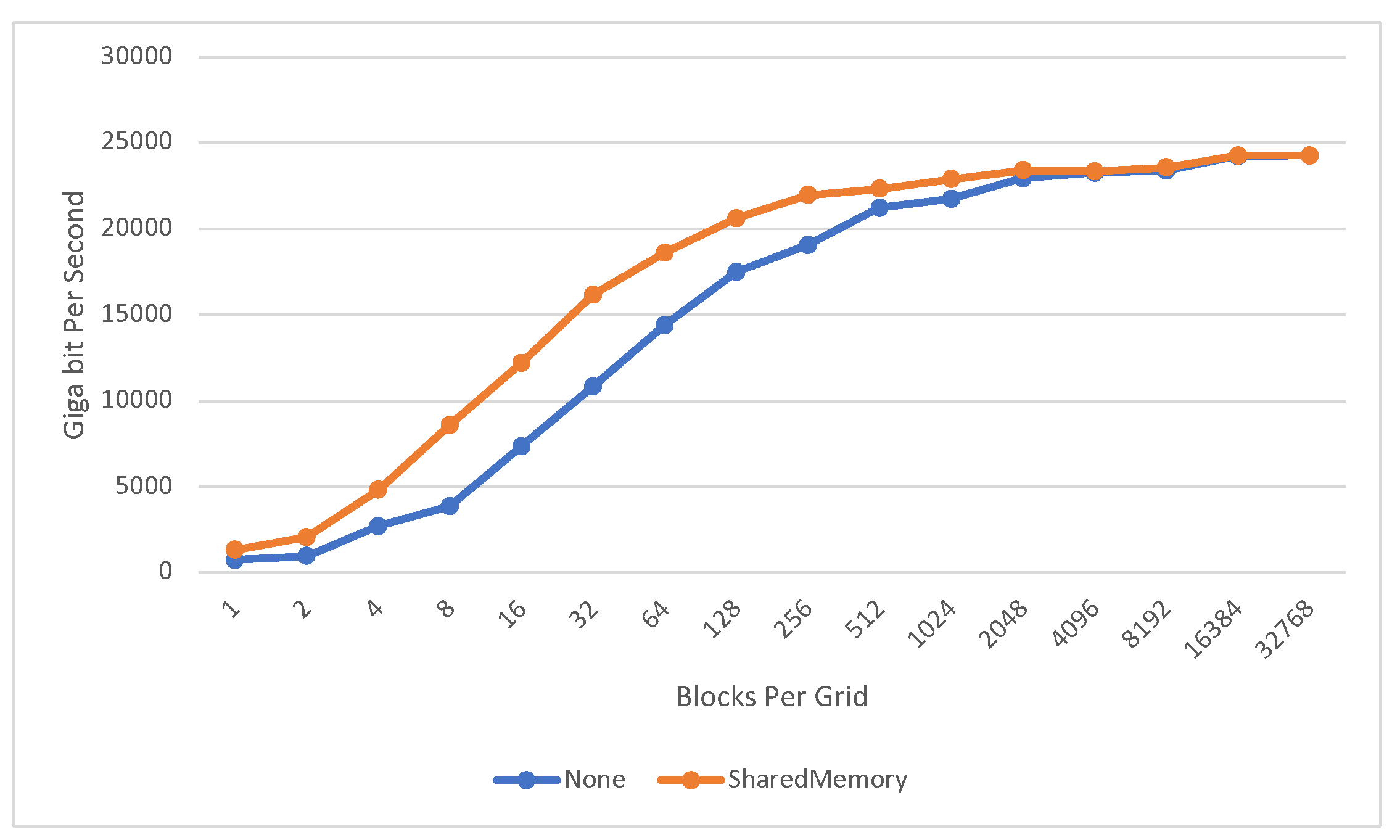
4.3. Shared Memory
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Singh, S.; Sharma, P.K.; Moon, S.Y.; Park, J.H. Advanced lightweight encryption algorithms for IoT devices: Survey, challenges and solutions. J. Ambient. Intell. Humaniz. Comput. 2017, 1–18. [Google Scholar] [CrossRef]
- Seo, H.; Park, T.; Heo, S.; Seo, G.; Bae, B.; Hu, Z.; Zhou, L.; Nogami, Y.; Zhu, Y.; Kim, H. Parallel implementations of LEA, revisited. In International Workshop on Information Security Applications; Springer: Berlin/Heidelberg, Germany, 2016; pp. 318–330. [Google Scholar]
- Lee, W.K.; Goi, B.M.; Phan, R.C.W. Terabit encryption in a second: Performance evaluation of block ciphers in GPU with Kepler, Maxwell, and Pascal architectures. Concurr. Comput. Pract. Exp. 2019, 31, e5048. [Google Scholar] [CrossRef]
- Hajihassani, O.; Monfared, S.K.; Khasteh, S.H.; Gorgin, S. Fast AES implementation: A high-throughput bitsliced approach. IEEE Trans. Parallel Distrib. Syst. 2019, 30, 2211–2222. [Google Scholar] [CrossRef]
- Gupta, N.; Jati, A.; Chauhan, A.K.; Chattopadhyay, A. Pqc acceleration using gpus: Frodokem, newhope, and kyber. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 575–586. [Google Scholar] [CrossRef]
- An, S.; Seo, S.C. Efficient parallel implementations of LWE-based post-quantum cryptosystems on graphics processing units. Mathematics 2020, 8, 1781. [Google Scholar] [CrossRef]
- Lee, W.K.; Hwang, S.O. High throughput implementation of post-quantum key encapsulation and decapsulation on GPU for Internet of Things applications. IEEE Trans. Serv. Comput. 2021. [Google Scholar] [CrossRef]
- Jang, K.B.; Kim, H.J.; Lim, S.J.; Seo, H.J. Parallel Implementation of SPECK, SIMON and SIMECK by Using NVIDIA CUDA PTX. J. Korea Inst. Inf. Secur. Cryptol. 2021, 31, 423–431. [Google Scholar]
- Han, K.; Lee, W.K.; Hwang, S.O. cuGimli: Optimized implementation of the Gimli authenticated encryption and hash function on GPU for IoT applications. Clust. Comput. 2022, 25, 433–450. [Google Scholar] [CrossRef]
- Tezcan, C. Key lengths revisited: GPU-based brute force cryptanalysis of DES, 3DES, and PRESENT. J. Syst. Archit. 2022, 124, 102402. [Google Scholar] [CrossRef]
- Lee, W.K.; Seo, H.J.; Seo, S.C.; Hwang, S.O. Efficient Implementation of AES-CTR and AES-ECB on GPUs With Applications for High-Speed FrodoKEM and Exhaustive Key Search. IEEE Trans. Circuits Syst. II Express Briefs 2022, 69, 2962–2966. [Google Scholar] [CrossRef]
- Li, P.; Zhou, S.; Ren, B.; Tang, S.; Li, T.; Xu, C.; Chen, J. Efficient implementation of lightweight block ciphers on volta and pascal architecture. J. Inf. Secur. Appl. 2019, 47, 235–245. [Google Scholar] [CrossRef]
- An, S.; Seo, S.C. Highly efficient implementation of block ciphers on graphic processing units for massively large data. Appl. Sci. 2020, 10, 3711. [Google Scholar] [CrossRef]
- Biham, E. A fast new DES implementation in software. In International Workshop on Fast Software Encryption; Springer: Berlin/Heidelberg, Germany, 1997; pp. 260–272. [Google Scholar]
- Reis, T.; Aranha, D.F.; López, J. PRESENT runs fast. In International Conference on Cryptographic Hardware and Embedded Systems; Springer: Berlin/Heidelberg, Germany, 2017; pp. 644–664. [Google Scholar]
- Adomnicai, A.; Najm, Z.; Peyrin, T. Fixslicing: A new GIFT representation: Fast constant-time implementations of GIFT and GIFT-COFB on ARM Cortex-M. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2020, 2020, 402–427. [Google Scholar] [CrossRef]
- Adomnicai, A.; Peyrin, T. Fixslicing AES-like ciphers: New bitsliced AES speed records on ARM-Cortex M and RISC-V. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2020, 2021, 402–425. [Google Scholar] [CrossRef]
- Bogdanov, A.; Knudsen, L.R.; Leander, G.; Paar, C.; Poschmann, A.; Robshaw, M.J.; Seurin, Y.; Vikkelsoe, C. PRESENT: An ultra-lightweight block cipher. In International Workshop on Cryptographic Hardware and Embedded Systems; Springer: Berlin/Heidelberg, Germany, 2007; pp. 450–466. [Google Scholar]
- Banik, S.; Pandey, S.K.; Peyrin, T.; Sasaki, Y.; Sim, S.M.; Todo, Y. GIFT: A small present. In International Conference on Cryptographic Hardware and Embedded Systems; Springer: Berlin/Heidelberg, Germany, 2017; pp. 321–345. [Google Scholar]
- Pepton21. PRESENT-cipher GitHub Repo. 2019. Available online: https://github.com/Pepton21/present-cipher (accessed on 7 October 2022).
- giftcipher. GIFT GitHub Repo. 2020. Available online: https://github.com/giftcipher/gift (accessed on 7 October 2022).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ⋯ | ⋯ | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ⋯ | ⋯ | |||||||||
| ⋯ | ⋯ | |||||||||
| ⋯ | ⋯ | |||||||||
| ⋯ | ⋯ | |||||||||
| ⋯ | ⋯ | |||||||||
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | |
| ⋯ | ⋯ |
| Cipher | Blocks per Gird | Threads per Block | Throughput |
|---|---|---|---|
| PRESENT-80 | 131,072 | 192 | 553.932 |
| PRESENT-128 | 131,072 | 128 | 529.952 |
| GIFT-64 | 131,072 | 64 | 583.859 |
| GIFT-128 | 16,384 | 160 | 214.284 |
| Cipher | Ref. | Model | Throughput |
|---|---|---|---|
| PRESENT-80 ECB | [20] | intel i7-9750H | 0.001 |
| PRESENT-80 ECB | [12] | Tesla V100 | 14.15 |
| PRESENT-80 ECB using multiple stream | [12] | Tesla V100 | 24.525 |
| PRESENT-80 ECB | this work | RTX 3060 | 24.264 |
| PRESENT-80 CTR | [10] | RTX 3070 | 115.73 |
| PRESENT-128 ECB | [12] | Tesla V100 | 14.15 |
| PRESENT-128 ECB using multiple stream | [12] | Tesla V100 | 24.525 |
| PRESENT-128 ECB | this work | RTX 3060 | 24.522 |
| GIFT-64 ECB | [21] | intel i7-9750H | 0.003 |
| GIFT-64 ECB | this work | RTX 3060 | 85.283 |
| GIFT-128 ECB | [21] | intel i7-9750H | 0.014 |
| GIFT-128 ECB | this work | RTX 3060 | 10.723 |
| PRESENT-80 EXHAUSTIVE | [10] | RTX 3070 | 120.64 |
| PRESENT-80 EXHAUSTIVE | this work | RTX 3060 | 553.932 |
| Cipher | Blocks per Gird | Threads per Block | Throughput |
|---|---|---|---|
| PRESENT-80 | 32,768 | 128 | 24.264 |
| PRESENT-128 | 32,768 | 64 | 24.522 |
| GIFT-64 | 32,768 | 32 | 85.283 |
| GIFT-128 | 32,768 | 96 | 10.723 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim , H.; Eum , S.; Lee , W.-K.; Lee , S.; Seo, H. Secure and Robust Internet of Things with High-Speed Implementation of PRESENT and GIFT Block Ciphers on GPU. Appl. Sci. 2022, 12, 10192. https://doi.org/10.3390/app122010192
Kim H, Eum S, Lee W-K, Lee S, Seo H. Secure and Robust Internet of Things with High-Speed Implementation of PRESENT and GIFT Block Ciphers on GPU. Applied Sciences. 2022; 12(20):10192. https://doi.org/10.3390/app122010192
Chicago/Turabian StyleKim , Hyunjun, Siwoo Eum , Wai-Kong Lee , Sokjoon Lee , and Hwajeong Seo. 2022. "Secure and Robust Internet of Things with High-Speed Implementation of PRESENT and GIFT Block Ciphers on GPU" Applied Sciences 12, no. 20: 10192. https://doi.org/10.3390/app122010192