1. Introduction
Pedestrian attribute recognition has become popular because of its enormous application scope. It refers to recognizing the attributes of a pedestrian from a given image, i.e., gender, age, upper body dress, lower body dress, etc., as shown in
Figure 1. A surveillance scenario might contain multiple pedestrians. Recognizing all the pedestrians with their attributes from a surveillance image is a very challenging task [
1]. This attribute recognition task is mainly helpful for person retrieval, person re-identification, person search, etc. Machine learning and deep learning techniques are now required for automation jobs since they outperform conventional methods.
For image processing, deep learning algorithms are utilized instead of the previously prevalent handmade approaches. The primary reason for that is a deep learning-based model can automatically extract features, whereas handmade methods require user intervention. Deep neural network (DNN)-based models for image processing applications may be pretty sophisticated. There are a lot of parameters in these DNN models. Because of increases in computational power, image identification can now be made in real-time, but getting better results remains a problem. The convolutional neural network (CNN) is an essential approach for extracting characteristics from images. Deep CNN has a great learning ability due to the utilization of several function extraction stages that can automatically acquire representations from data. The availability of vast quantities of data, along with technology breakthroughs, has spurred CNN research, and numerous promising deep CNN designs have lately been released, as proposed in Khan et al. [
2].
This topic offers a lot of study potential because it is growing more popular and has less work. In a real-world context, it also has a wide range of applications. In a drone surveillance scenario, this may be useful. Pedestrian attribute recognition tasks have several applications, including public safety, soft bio-metrics, suspicious person identification, criminal investigation, and so on [
3].
Our primary goal in this research is to recognize pedestrians in a multitude of pedestrian scenarios. We have used the Richly Annotated Pedestrian(RAP) v2 dataset to experiment. Mask RCNN is used to extract isolated pedestrians from a multiple pedestrian scenario. After that, we experimented with multiple pre-trained CNN architectures, i.e., Inception ResNet v2, Xception, ResNet 152 v2, ResNet 101 v2, to obtain a better performing architecture. In addition, an extensive experiment on the proposed CNN architecture ResNet 152 v2 is performed by fine-tuning (freezing some layers). Many previous works [
4,
5,
6] applied transfer learning techniques for the pedestrian attribute recognition task. Transfer learning techniques displayed better performance in these works. In all cases, we used the transfer learning technique to obtain better results. However, the main contributions of the proposed framework are as follows:
Proposing a framework for recognizing attributes from a multiple pedestrian scenario.
Applying the transfer learning technique among various CNN architectures, i.e., Inception ResNet v2, Xception, ResNet 152 v2, ResNet 101 v2 to recognize pedestrian attributes.
Tuning the best performing model ResNet 152 v2 by freezing some layers and designing a customized fully connected layer.
Analyzing the RAP v2 dataset and applying data balancing techniques, i.e., oversampling.
2. Related Work
The pedestrian attribute recognition task is a series of steps. In a surveillance scenario, an image might contain pedestrians. The pedestrian attribute recognition task addresses the recognition of attributes of each of the pedestrians. The first step of the pedestrian attribute recognition task is to detect the pedestrians as accurately as possible. Several traditional and deep learning methods are applied to detect pedestrians from a surveillance scenario. After that, the next step is to recognize the pedestrian attributes. Many robust CNN architectures are used for this task.
Many traditional methods are applied to extract the pedestrians from a surveillance image. Face feature-based traditional methods are used to detect the face of a pedestrian. The use of colour space using YCbCr, HSV, etc., has a significant impact on detecting the face of multiple pedestrians [
7]. Additionally, the normalization method in one of the colour space channels extended the detection accuracy. However, motion feature-based techniques are also applied for pedestrian detection. Region segmentation and machine learning-based classification technique is proposed for the pedestrian detection task [
8]. Region segmentation is based on optical flow and feature extraction and classification based on Bandelet transform. Several component-based techniques are established to detect pedestrians. The main objective is to use body parts, i.e., head, arms, and leg., in an appropriate geometric configuration to detect the full pedestrian body. An AdaBoost learning algorithm is used to boost the accuracy of the Support Vector Machine(SVM) classifier for the component-based pedestrian detection task [
9].
Recently, deep learning techniques have become very popular for object classification, object recognition, object detection tasks. The advancement of GPU, as well as image data, has made deep learning more efficient. Deep learning-based systems may recognize a single object or multiple objects in an image more accurately than traditional object detection algorithms. Many advanced deep learning methods are applied for the pedestrian detection task. A Convolutional Neural Network is proposed to detect the pedestrians from a surveillance scenario [
10]. Three deep neural networks, i.e., supervised CNN, transfer learning-based CNN, and hierarchical extreme learning machine, are used for the task. The obtained results are very satisfactory. Additionally, many double stage CNN architectures are developed for the object detection task. These frameworks are also used to detect pedestrians. R-CNN [
11], Fast R-CNN [
12], Faster R-CNN [
13], and Mask R-CNN [
14] are the double stage CNN framework capable of detecting objects very effectively. The overall challenge for these frameworks is that they are typically slow for the large computation purpose of the two stages. This challenge is overcome by the single-stage CNN framework SSD [
15], YOLO [
16] as they contain only one stage which is responsible for the object detection task. However, the only challenge for single-stage detectors is detection accuracy. The Mask R-CNN can detect better in the case of object detection [
17]. Thus, to better detect the pedestrians for the pedestrian attribute recognition task, we introduced Mask R-CNN in our proposed framework.
The multi-label classification issue of pedestrian attribute recognition has been widely used to retrieve and re-identify individuals. Attribute analysis is becoming more common to infer high-level semantic details. Previously conducted research used conventional methods for resolving this issue. The AdaBoost algorithm can be used to make a discriminative recognition model [
18]. This algorithm resolves the problem of creating a particular handcrafted feature. Another approach is the Ensemble RankSVM method [
19] that solves the scalability problem caused by current SVM-based ranking methods for the pedestrian attribute recognition task. This new method requires less memory while maintaining adequate performance.
A new re-identification technique is applied based on the mid-level semantic features of the pedestrian attributes [
20,
21]. The model learns attribute-centric feature representation based on the body parts. The method to determine the mid-level semantic properties are also discussed in this work.
Later, a large-scale dataset was published [
22] that makes learning robust attribute detectors with strong generalization efficiency much more effortless. In addition, the benchmark output was presented using an SVM-based method, and an alternative approach was suggested that uses the background of neighbouring pedestrian images to enhance attribute inference. Additionally, a Richly Annotated Pedestrian (RAP) dataset was published [
23] with long-term data collection from real multi-camera surveillance scenarios. The data samples are annotated with not only fine-grained human attributes but also environmental and contextual variables. They also looked at how various ecological and contextual variables influenced pedestrian attribute recognition.
Recently, attribute recognition is becoming more prevalent for customizing a deep learning architecture in an individual re-identification challenge. Early research focused on datasets of pedestrian attributes that were relatively thin. In video surveillance, a part-based feature representation technique is suggested [
24] for human features such as facial hair, eyewear, and clothing colour. However, as opposed to current methods, the results are dismal. However, deep neural networks have shown significant improvements in the field of computer vision. Multiple CNN architecture based pedestrian attribute recognition methods, i.e., DeepSAR (with independent attributes) and DeepMAR (with dependent attributes), are also introduced [
1]. They surpassed the MRFr2 system, which is state-of-the-art. A technique for simultaneously retraining a CNN architecture is proposed [
25] for all attributes. It makes use of attribute interdependence, utilizing just the picture as input and no external posture, part, or context information. Their methodology is unique in its transdisciplinary nature. On two publicly available attribute datasets, CNN wins HATDB and Berkeley Attributes of People.
Likewise, a part-based system is proposed [
26] in which an image is divided into 15 overlapping image parts, and each component is fed into a multi-label Convolutional Neural Network (MLCNN) at the same time, in contrast to current methods that presume attribute independence during prediction. On the Vipers and GRID datasets, experimental findings show that the model performs better. Even so, it does not demonstrate a high level of efficiency. The network AlexNet is fine-tuned [
27] to make it encode an image into a discriminative function based on the corresponding attributes. The seven categories of attributes considered are gender, age, luggage-style, upper body clothing type, upper body colour, lower body colour, and lower body clothing type. The results of the experiment show that fine-tuning using attribute information enhances re-identification accuracy. However, the results are still unsatisfactory. Additionally, a grouping technique based on a fine-tuned VGG-16 structure is proposed [
6]. After grouping the characteristics, they are put into a pre-trained VGG-16 model with slight performance enhancements. However, a handmade CNN model for a specific job outperforms a pre-trained model such as AlexNet, or ResNet [
28].
As current approaches have difficulty localizing the areas corresponding to different attributes, a novel Localization Directed Network is proposed [
29] based on the connection between previously extracted proposals, attribute positions, and attribute-specific weights to local features. An attribute aware pooling algorithm is proposed [
30] that explores and exploits the association between attributes for the pedestrian attribute recognition challenge, extending the strength of deep convolutional neural networks (CNNs) to the pedestrian attribute recognition issue. Mutual learning of three attention mechanisms, i.e., Parsing attention, Label attention, and Spatial attention, is proposed [
31] for pedestrian attribute analysis to select relevant and discriminative regions or pixels against variations.
Additionally, an attention-based neural network made up of a Convolutional Neural Network, Channel Attention (CAtt), and Convolutional Long Short-Term Memory (ConvLSTM) (CNN-CAtt) is also suggested [
32] for the pedestrian attribute recognition task. They intended to address the issue of pedestrian attribute recognition methods already in use. The reason for the poor performance is that they ignored the relationship between pedestrian attributes and spatial information. A novel Co-Attentive Sharing (CAS) module is proposed [
33] to address the same problem, which extracts discriminative channels and partial regions for more efficient feature sharing in multi-task learning.
An image-attribute reciprocal guidance representation (RGR) method is proposed [
34] to explore the image-guided and attribute-guided features. They considered concrete attributes, i.e., hairstyle, shoe style, and abstract attributes, i.e., age range, role types. Moreover, a fusion attention method is used to allocate different attention levels to certain RGR aspects. Furthermore, a combination of focal and cross-entropy loss is used to solve the problem of attribute imbalance.
A novel weighted cross-entropy loss function-based work has been introduced to reduce the class imbalance problem for the pedestrian attribute recognition task [
35]. GoogleNet is used as the base CNN architecture, and features from different layers of the architecture are passed into a Flexible Spatial Pyramid Pooling layer (FSPP). The outputs of these FSPP are passed to a neural network for classification purposes.
Additionally, an adaptively weighted deep framework is proposed [
36] to learn the multiple person attributes. Moreover, validation loss is used to automatically update the weights of the CNN architecture, i.e., ResNet 50. Their work’s main motive is to prioritize the important task by adding higher weights on those tasks.
Similar approaches, i.e., clothing attribute prediction, related to pedestrian attribute recognition, can help in the person re-identification task. A task-aware attention mechanism is proposed [
37] for the clothing attribute prediction task to explore the impact of each position across different tasks. A cloth detector is used to explore the target region, and a CNN architecture extracts the features of that region. The task and spatial attention modules are used to learn the feature maps. For optimization, the t-distribution Stochastic Triplet Embedding loss function is used.
As a result, pedestrian attribute recognition has been significant for years. Additionally, deep learning models combined with a broad range of tuning and applying transfer learning techniques have recently surpassed established state-of-the-art methods. In our proposed framework, we used transfer learning techniques and tuning of the hyperparameters to obtain satisfactory results. Additionally, implementing this research in a surveillance situation is a novel notion that helps to increase people’s security.
3. Proposed Approach
A real-world surveillance scenario contains multiple pedestrians in a single image. Thus, the first step for the pedestrian attribute recognition task is to detect the pedestrians from a multiple pedestrian scenario. Mask R-CNN is capable of object detection tasks better than other CNN architectures by 47.3% mean precision [
38]. We have used the Mask RCNN object detector to isolate the pedestrians from a multiple pedestrian scenario in our proposed framework.
A similar study [
39] used the R-CNN framework for clothing attribute recognition. The proposed regions of the clothes are extracted by applying the modified selective search algorithm. Then, the Inception ResNet v1 CNN architecture is used to classify the proposed regions. However, the approach is limited to only a single clothing scenario. Additionally, the Mask R-CNN does not require a selective search algorithm for the proposed regions and can perform efficiently in multiple pedestrian scenarios. Our proposed Mask R-CNN-based framework with the fine-tuned ResNet 152 v2 CNN architecture can efficiently recognize pedestrian attributes.
The next step is to recognize the attributes of each pedestrian. An image contains spatial features which are responsible for recognizing an object because of its unique characteristics. Convolutional Neural Network is the best choice to capture the spatial features responsible for recognizing an object. However, obtaining optimum performance from a CNN architecture, some prepossessing is required for the images, i.e., resizing, scaling, augmentation, normalization. In our proposed framework, we used the aforementioned preprocessing techniques. After that, we proposed a CNN architecture by experimenting with different CNN architectures to extract the spatial features. Then, the spatial features are passed to a classifier which is a customized, fully connected layer. The classifier predicts the pedestrian attributes for each pedestrian from the multiple pedestrian scenario.
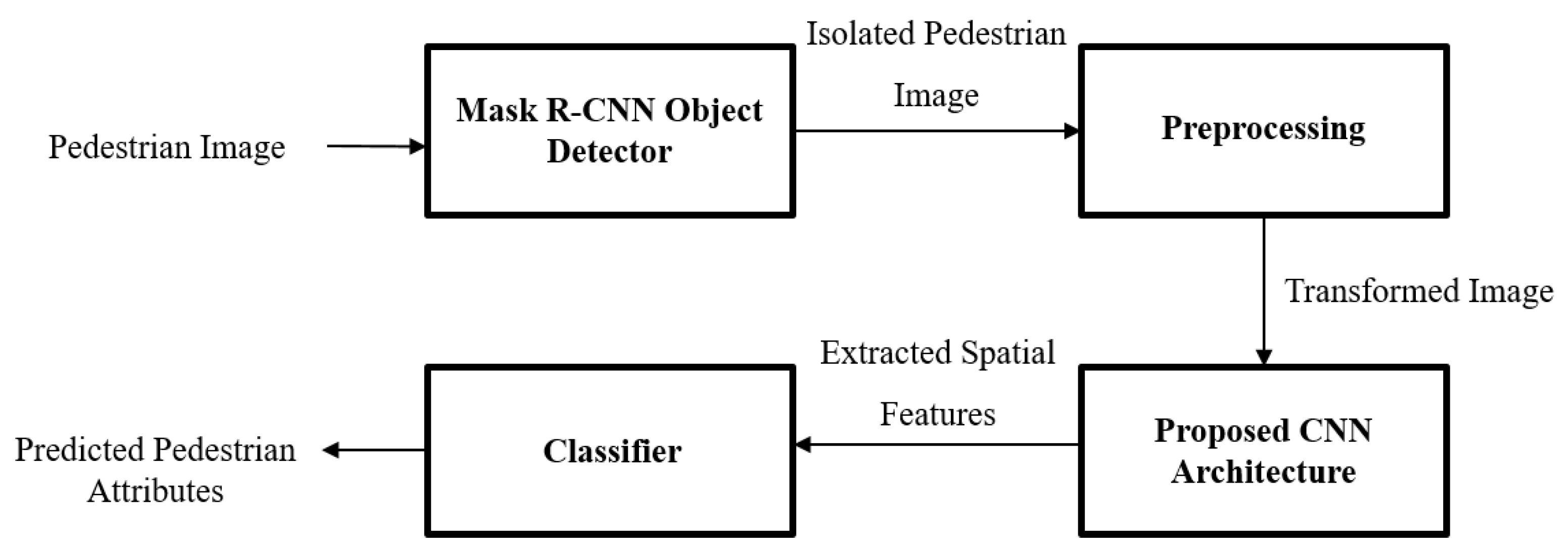
Figure 2 shows the proposed framework for the pedestrian attribute recognition task.
3.1. Mask R-CNN Object Detector
The first stage of the pedestrian attribute recognition framework is the Mask R-CNN object detector. The purpose of this stage is to extract the pedestrians from a surveillance scenario for further analysis. Pedestrian detection has so many applications in the real world, i.e., smart vehicles, robotics, security [
40]. Mask-RCNN or Mask Region-Based Convolutional Neural Network in [
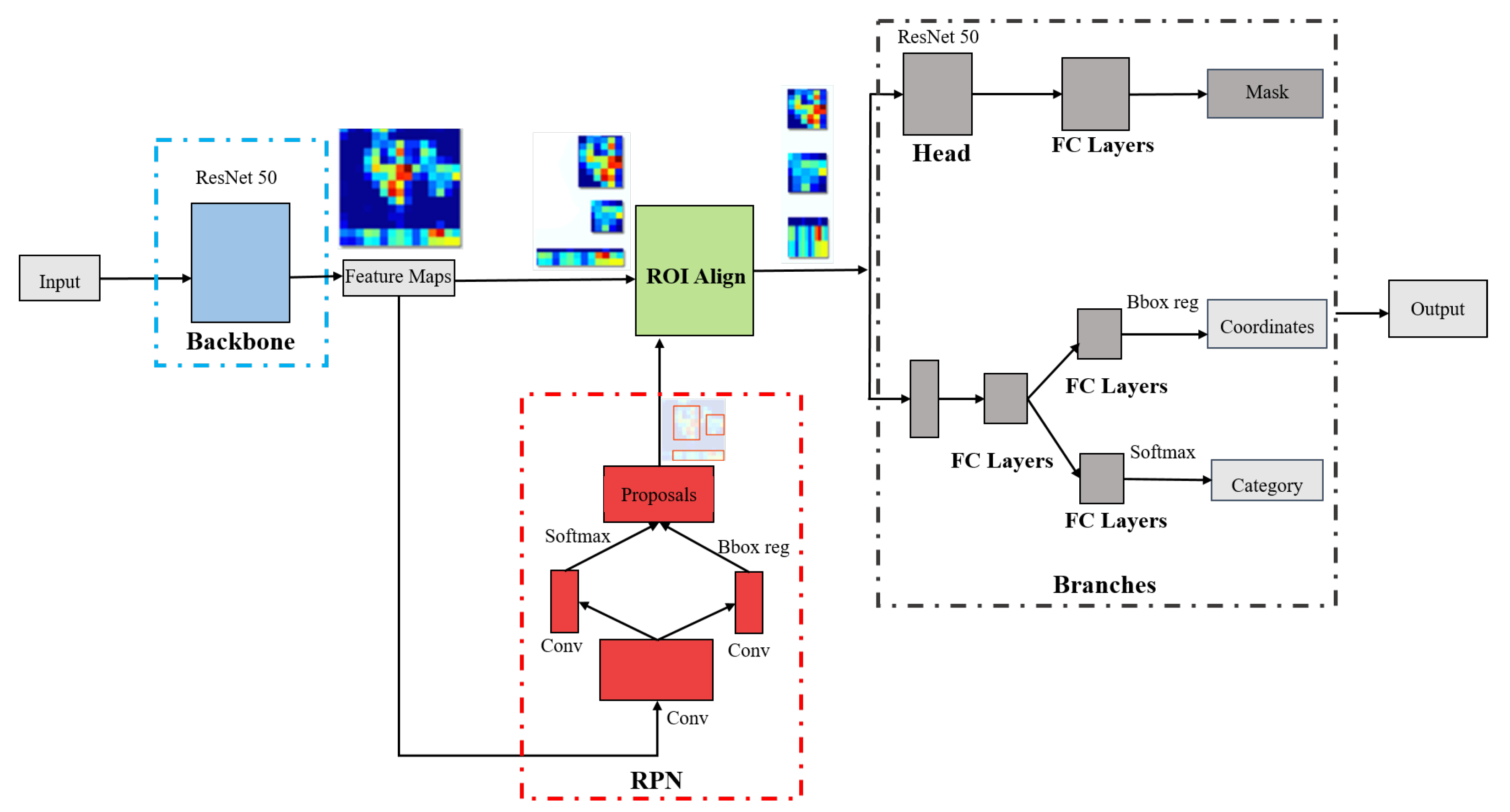
41] was developed as a result of a more in-depth investigation of deep learning for pedestrian detection. The overview of the Mask RCNN object detector is shown in
Figure 3. It is a double stage CNN architecture. The first stage is responsible for proposing object regions. The second stage is responsible for providing the masked regions of the objects, the bounding box of the objects, and the classification of the objects. Each stage of the Mask R-CNN is explained briefly in the following:
First Stage
Backbone: The first stage of Mask R-CNN consists of Backbone and RPN. The Backbone of the Mask R-CNN is responsible for extracting the features of a given input image. ResNet 50 CNN architecture is used in the Backbone to extract the features. The extracted features are passed to the second stage via the ROI layer. Additionally, the features are also forwarded to the RPN network.
RPN: Region Proposal Network(RPN) is responsible for proposing regions of the location of an object. Several convolution layers are used to predict the probability of an object presence using the softmax function. The bounding box of the objects is also predicted in the RPN. The RPN provides the objects to the ROI align layer, passing the individual objects to the second stage.
Second Stage
Branches: The objects from the ROI align layers are passed to the Branches stage. This stage has three parts, i.e., Mask, Coordinates, Category. The Mask part provides the masked regions of an object. Similarly, the Coordinate part provides the object’s bounding box, and the Category part provides the object’s class name.
Figure 4 shows an example of Mask RCNN in real-world scenario. The image source is available in [
25].
3.2. Preprocessing
Convolutional Neural Networks require image preprocessing for better performance. It has been proved that a prepossessed image can highlight features more than a raw image. In our proposed framework, we have applied image resizing, scaling, augmentation, and normalization techniques for capturing spatial features more robustly.
Image resizing is performed by changing the resolution of an image. As a CNN architecture can only operate on the same resolution images, we change the image resolution to . Another reason for this resolution of the images is to reduce computation cost. As the images are RGB images, the pixel values are in the range [0, 255]. To process the images faster, we divided every pixel value by 255.0, i.e., the scaling technique.
Overfitting occurs when the CNN architectures learn only on train data. As a result, it does not perform well on test data. Thus, if the variation of the image is introduced to the CNN model, then it performs better on test data. The image augmentation technique performs the variation. Our proposed framework has applied several augmentation techniques, i.e., rotation, width shift, height shift, horizontal flip, and shearing.
Normalization is applied to standardize raw input pixels. It is a technique that transforms the input pixels of an image by subtracting the batch mean and then dividing the value by the batch standard deviation. The formula for standardization is shown in Equation (
1). Additionally, the effect of normalization on the performance of pedestrian attribute recognition is shown in the next section:
where,
refers to input pixel,
refers to batch mean, and
refers to batch standard deviation.
When a pixel in a picture has a large number in comparison to others, and it becomes dominant. This causes the outcome of predictions to be less accurate. In this case, normalization is important as it makes a uniform distribution of the pixels and makes the pixel values smaller. It makes computation faster. In addition, normalization may cause convergence faster than unnormalized data. A brief experiment is performed among them, which is shown in the next section.
3.3. Spatial Feature Extraction
The spatial features of an image are responsible for identifying an object in that image. Recent research shows that CNN architectures are very efficient in extracting spatial features. CNN architecture is a series of convolution and pooling operations. The convolution operation is performed on an image by some kernels, and it produces a feature map. After that, the feature map is passed to an activation function to introduce nonlinearity. The main purpose of convolution operation is to reduce spatial capture features as well as reduce image dimension. Then, pooling operation is performed on a given window where max or avg value from that window is taken, which is called max pool or average pool. The purpose of pooling operation is to reduce computation costs drastically. In our proposed framework, our proposed CNN architecture ResNet 152 v2 performs these similar operations in a more complex structural way. As a result, the features to recognize the pedestrian attributes are better captured.
3.4. Transfer Learning Approach
The concept of transfer learning arrived from the scarcity of training data. A CNN architecture, trained for a specific task on a particular dataset, can gain the knowledge of detecting edges and other low-level features. The kernels of the CNN architecture are updated during the training. These kernels are responsible for extracting features. Thus, when there is limited data for a particular task, and the goal is to better perform with this limited data, the transfer learning approach is used in this scenario. This technique uses the previously learned knowledge and applies it to a new task. Previous works [
4,
5,
6] included transfer learning technique to obtain satisfactory results. We also applied the transfer learning technique on several powerful CNN architectures in our proposed framework, i.e., Inception ResNet v2, Xception, ResNet 152 v2, ResNet 101 v2. These architectures are trained on the IMAGENET dataset, which has over 14M images and 1000 classes. The best performing architecture, i.e., ResNet 152 v2, is obtained by tuning the layers of the neural network. The ResNet 152 v2 architecture has approximately 60 M parameters according to [
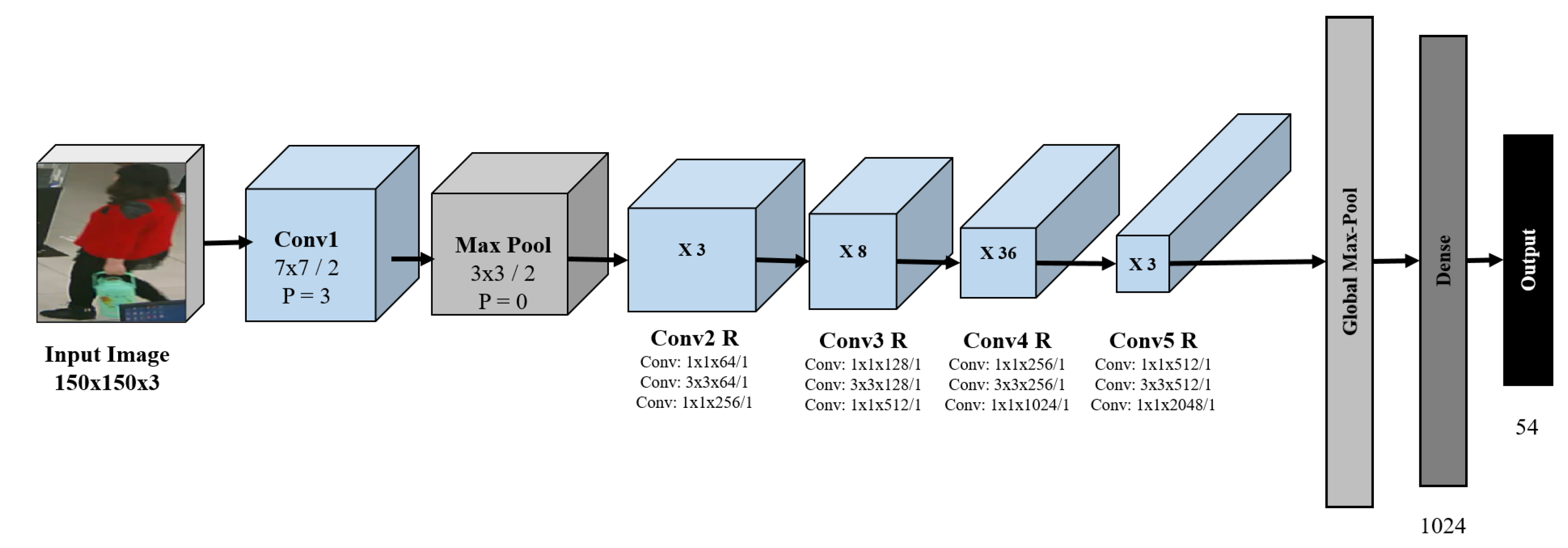
42]. The performance comparison among the architectures is illustrated in the next section. Then, fine-tuning the ResNet 152 v2 architecture by freezing all layers except the last 4, 8, 12, 14, 20, all, and no layers is performed. The purpose is to increase the efficiency of the architecture. The details of the experiment are discussed in the next section. The architecture of the proposed ResNet 152 v2 is shown in
Figure 5. A brief explanation of each of the blocks is given below:
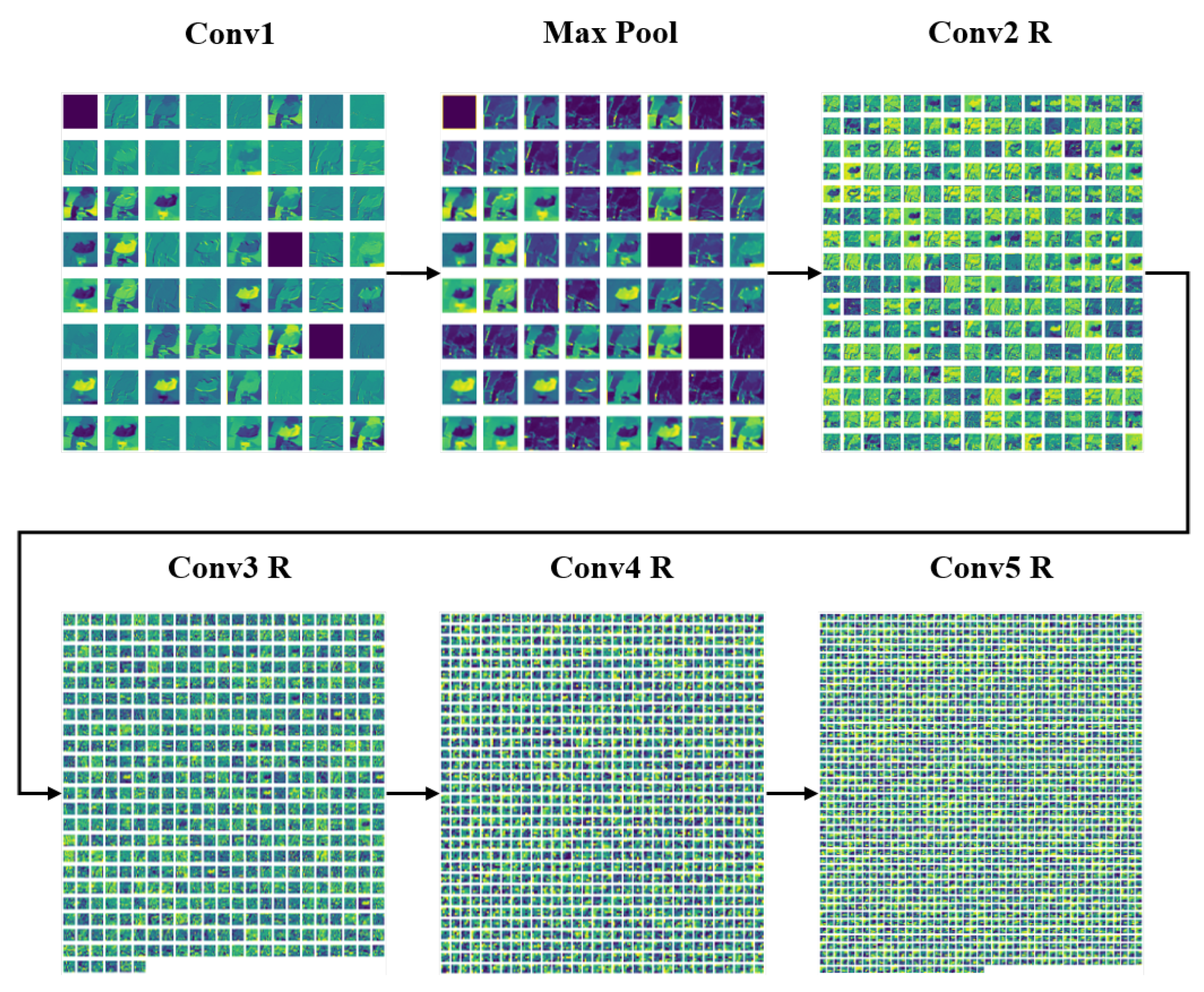
Conv1: It is the first block of ResNet 152 architecture. The kernel size is which reduces the feature map. The purpose of this block is to reduce image size.
Max Pool: To extract the dominant features, initially, a max pool operation is performed. As a result, the feature map becomes smaller.
Conv R: Several blocks, i.e., Conv2 R, Conv3 R, Conv4 R, Conv5 R with residual connections are shown in
Figure 5. Each block has a series of convolution layers with an increasing number of channels. The convolution layer has a residual connection among them. This connection aims to make the network learn from its early layers so that the knowledge is not forgotten. The increasing number of channels indicates that the feature map gradually decreases and captures the dominant spatial features.
3.5. Classification
A fully connected layer consists of a series of flatten layers and dense layers. It is used for the classification of pedestrian attributes. The output layer of the fully connected layer gives values in the range [0, 1]. The sigmoid activation function is used in the output layer. The value 0 refers to the lowest probability for an attribute, and the value 1 refers to the highest probability of an attribute. The formula for the sigmoid activation function is shown in Equation (
2):
where,
z is the input value and
is sigmoid value. The input value
z can be calculated by using the formula shown in Equation (
3).
where,
w,
x and
b are the weights, features and bias of the previous layer of the output layer.
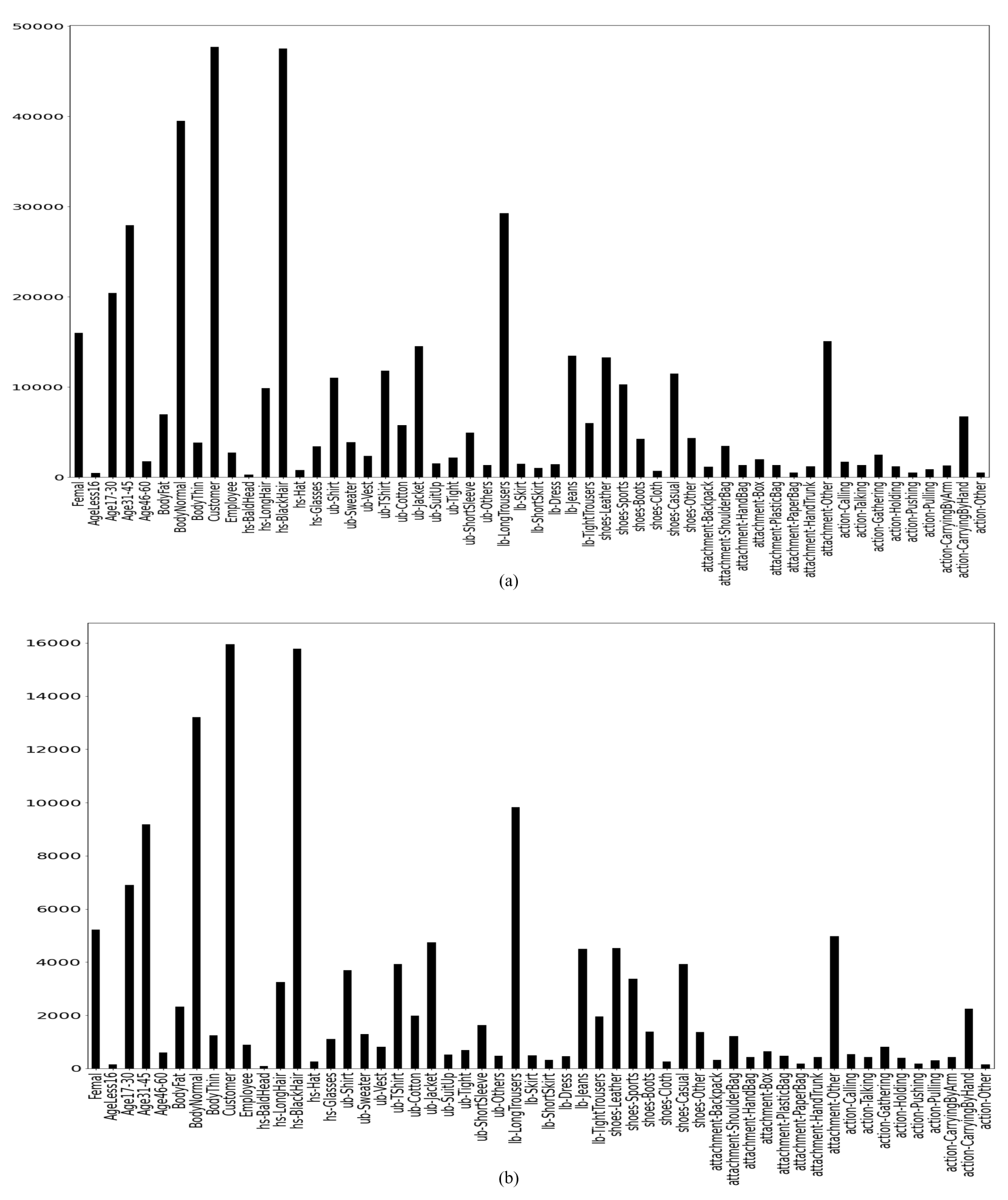
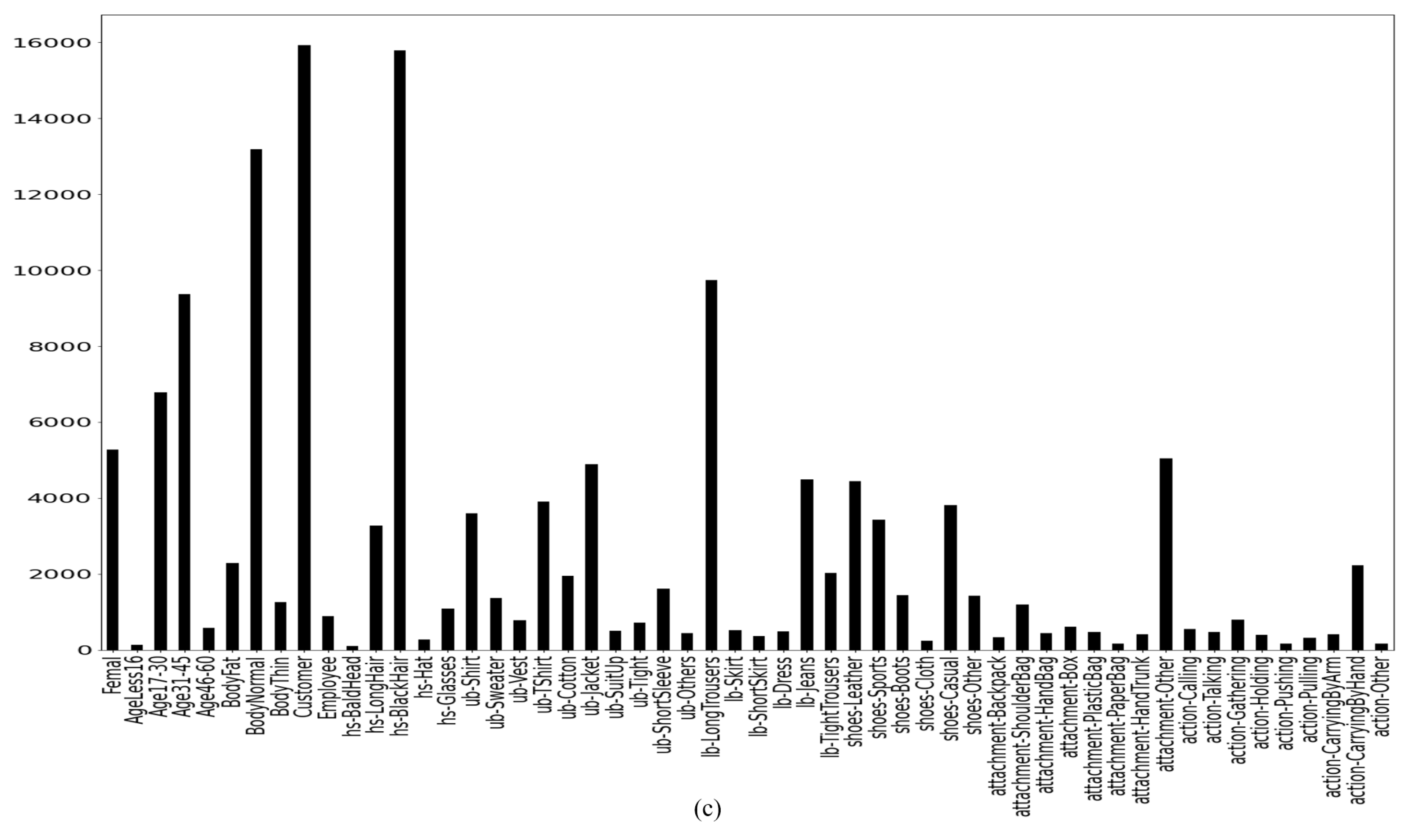
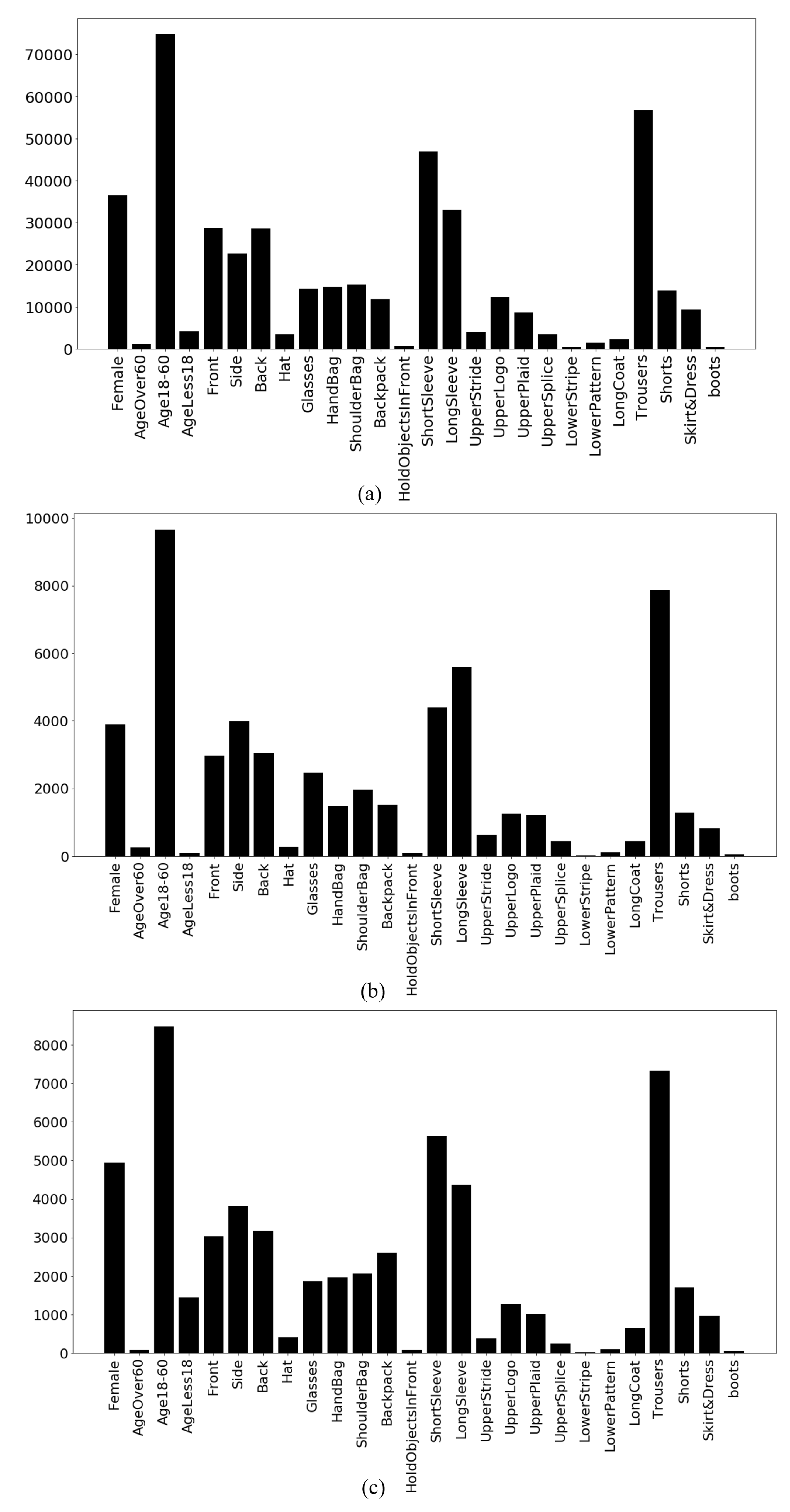
After extracting the spatial features from the convolution layers, the features are passed to a classifier, i.e., a neural network. After vivid experimentation, dense layers of 1024 nodes is chosen for our ResNet 152 v2 architecture. Additionally, the output layers contain 54 nodes, as our RAP v2 dataset has 54 attributes. The details of the experiments and dataset are described in the next section.
3.6. Data Oversampling
As our dataset RAP v2 [
43] is highly imbalanced, which is described in the next section, we also performed some data balancing experiments, i.e., data oversampling, to compare the performance of our proposed architecture in both scenarios, i.e., without oversampling, with oversampling. Some study [
44] suggests that undersampling is better than oversampling on the performance on cost with the decision tree learner C4.5. In our proposed framework, we have used only oversampling technique to mitigate the class imbalance problem because the undersampling technique will greatly reduce the amount of data based on the lowest majority classes of the dataset. As the dataset contains a variety of pedestrian scenarios, reducing the variety can cause the CNN architecture to learn only from the limited variations. Thus, the overall recognition of pedestrian attributes should be limited to some scenarios. To avoid limited learning, we have used oversampling data technique in our proposed framework.
For the multi-label pedestrian attribute recognition task, we applied the oversampling technique for balancing our data. Additionally, to minimize the impact of majority class samples, we used the weighted binary cross-entropy loss function. The process to perform oversampling in our proposed framework is given below:
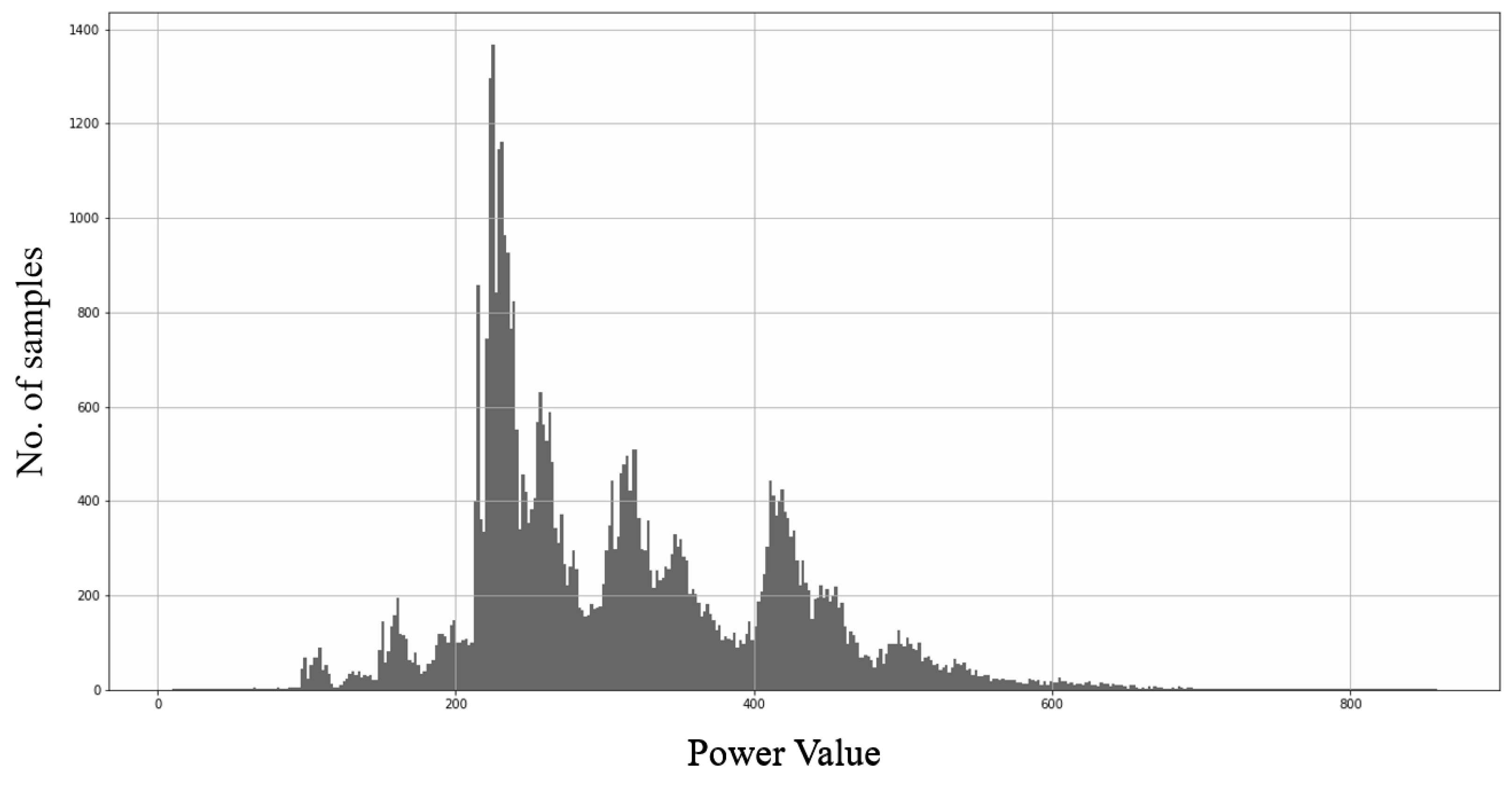
Give every data a power value;
Find the frequency of power values;
Take the max power value;
For each power value:
- –
Get size of data = (max power value − power value);
- –
Take a random copy from the dataset with the same power value;
- –
Add it with the amount of size of data in the original dataset.
3.7. Weighted Binary Cross-Entropy Loss
This loss function is similar to the binary cross-entropy loss function. The weights of the positive and negative samples are integrated into this loss function to make the architecture learn minority samples. The following steps calculate the weights:
For each attribute:
- –
Compute positive weight, = Total data size/2 × Total Positive Samples.
- –
Compute negative weight, = Total data size/2 × Total Negative Samples.
Apply the weights to the following loss function in (
4):
where,
represents the actual class and
is the probability of that class.
5. Conclusions
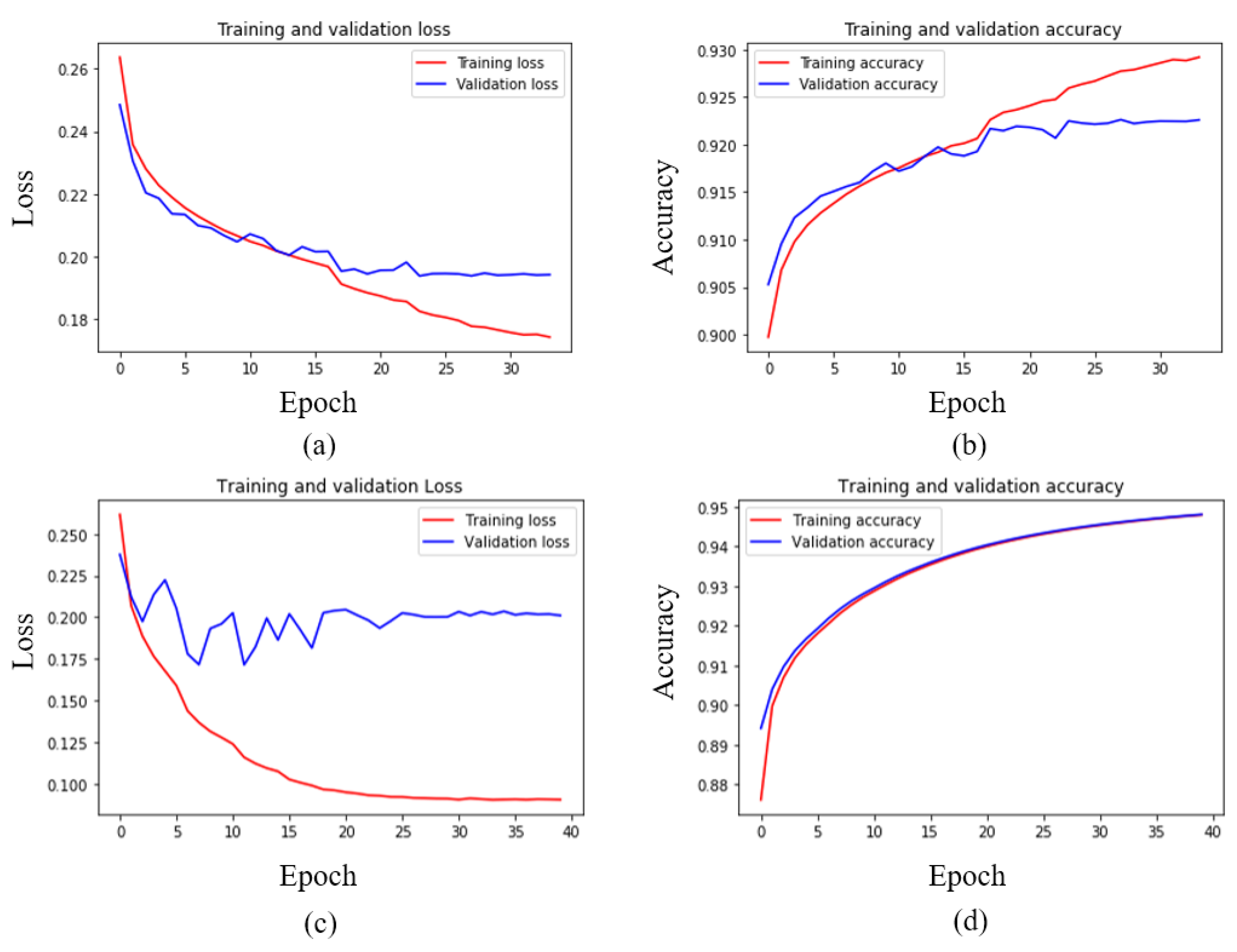
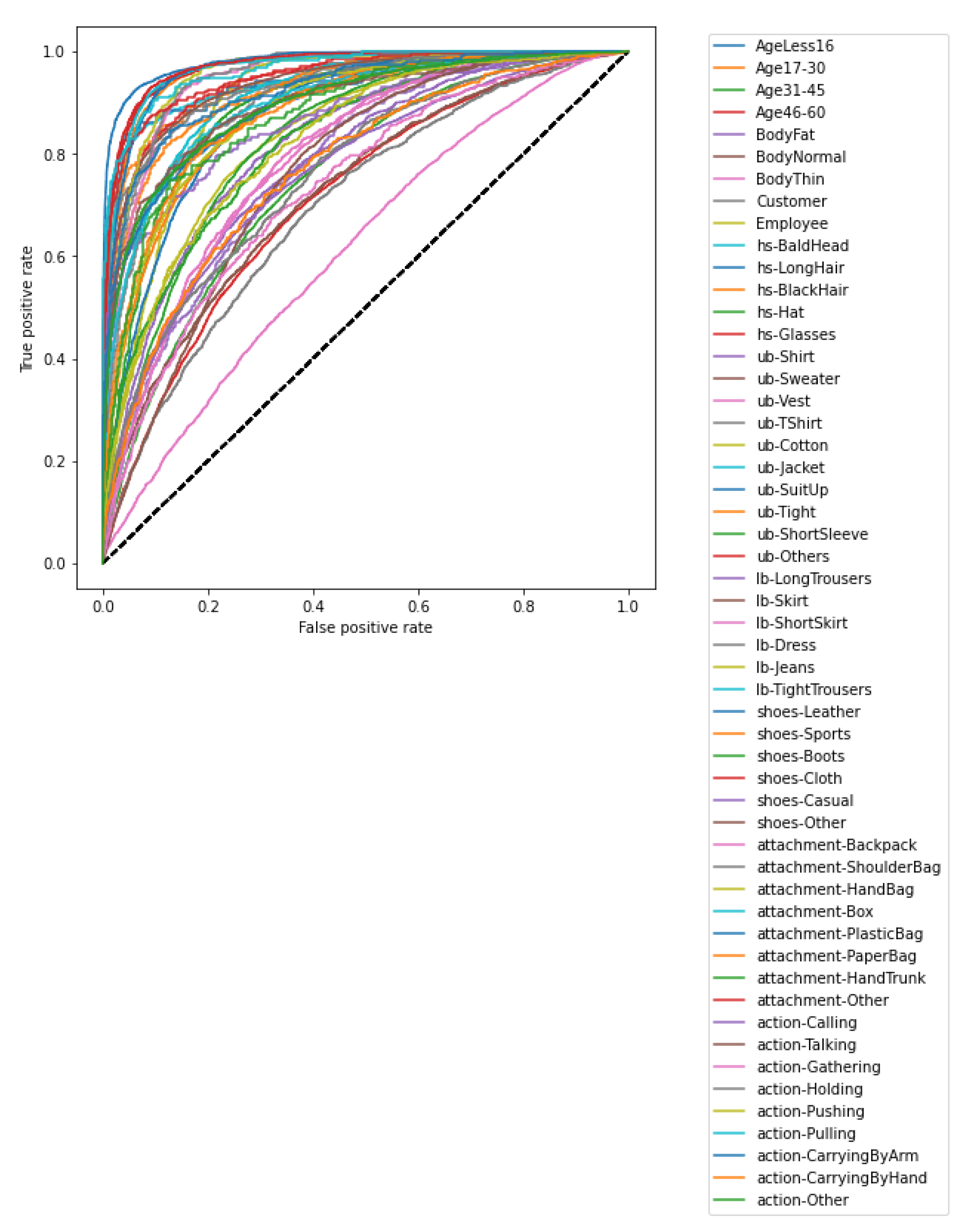
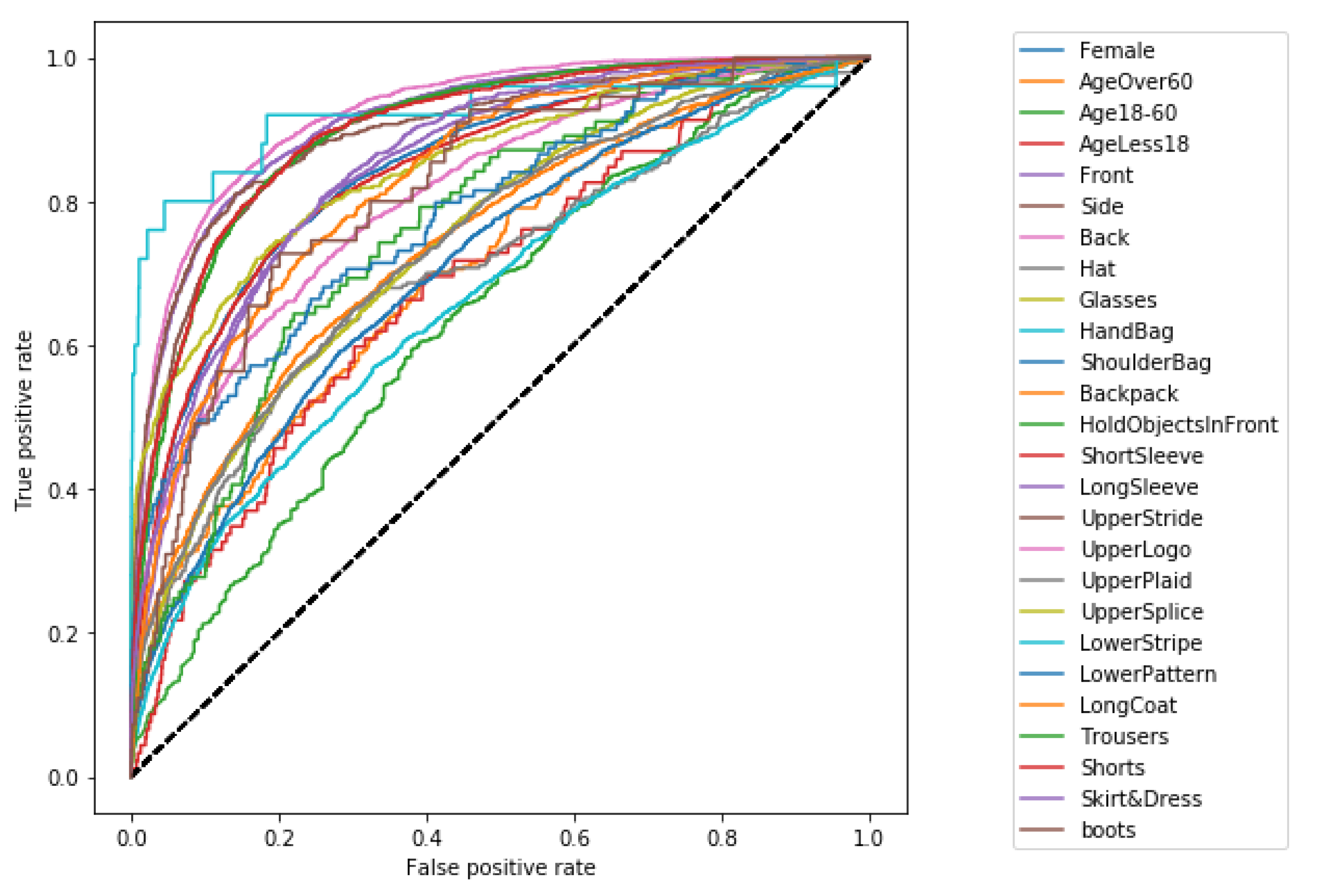
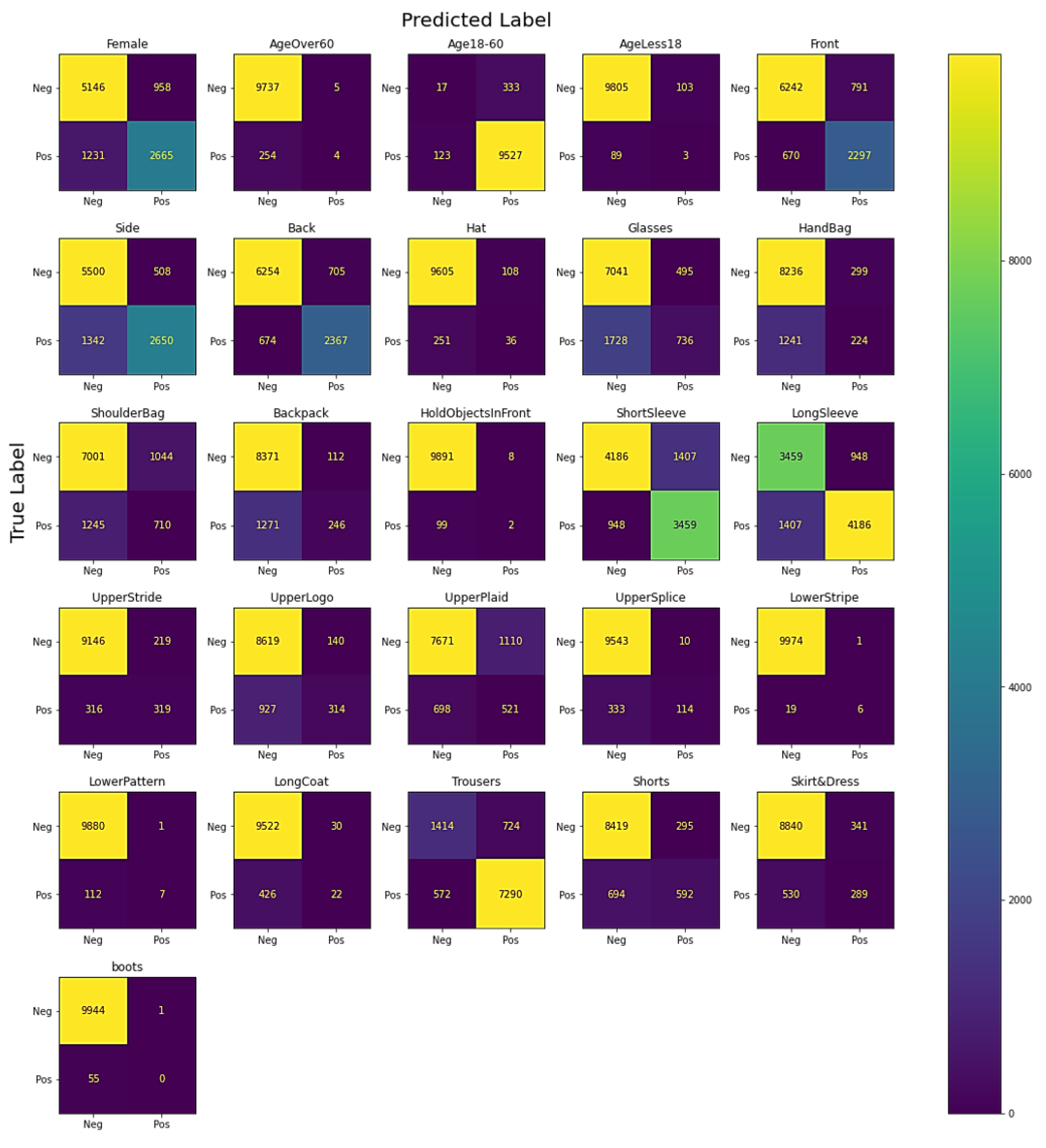
In our proposed framework, we have applied the Mask R-CNN object detector to isolate the pedestrians from a multiple pedestrian scenario. Initially, ResNet 152 v2 architecture obtained better results on the RAP v2 dataset, i.e., 92.14% mA, among other architectures, i.e., Xception, Inception ResNet v2, ResNet 101 v2. Additionally, we have also proposed a fine-tuned ResNet 152 v2 (Model 5) architecture after thorough experimentation. Our proposed CNN architecture, i.e., Model 5, obtained 93.41% accuracy. Moreover, we experimented with hyperparameters to obtain a set of hyperparameters, i.e., initial learning rate 0.01, 1 hidden layer with 1024 nodes, batch size 64, number of epochs 40, and “Adam” optimizer that provided satisfactory results. Furthermore, we have displayed the dataset distribution to show the class imbalance problem. However, after applying the oversampling and weighted loss technique, the class imbalance problem is not resolved. Analysis of applying oversampling and weighted loss on Model 5 shows that our proposed fine-tuned Model 5 obtains 93.41% mA without it. Additionally, we have experimented on an outdoor-based dataset, i.e., PARSE100K, to evaluate our proposed framework in terms of generalization. Our proposed framework outperformed existing SOTA methods with 89.24% mA. The loss and accuracy curve displays the smooth training of the proposed CNN architecture. The confusion matrix and ROC show the performance of Model 5. The feature map visualization of Model 5 gives an abstract of image transformation through every block of Model 5. Our proposed CNN architecture has higher accuracy but additionally has large network parameters, i.e., 6.65 M. In the future, we tend to work with a more balanced dataset to overcome the class imbalance problem. Nevertheless, pedestrian attribute recognition has so many applications. Person re-identification is very useful in surveillance scenarios. We tend to extend our proposed framework for person re-identification tasks.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}