
Predictive Distillation Method of Anchor-Free Object Detection Model for Continual Learning



Abstract
:1. Introduction
- It targets class incremental learning (class IL) without a separate task ID.
- A scenario is set up assuming that data and labels cannot be reused.
- It targets CL models that do not store samples or feature maps of training data so that learning data cannot be estimated.
- The model structure is fixed to avoid increasing the parameters such that the inference time of the model does not increase.
- In the next training step, information on the previous class object can only be delivered using the weights of the previous learning model.
- Scenarios are pre-defined according to the order of CL learning.
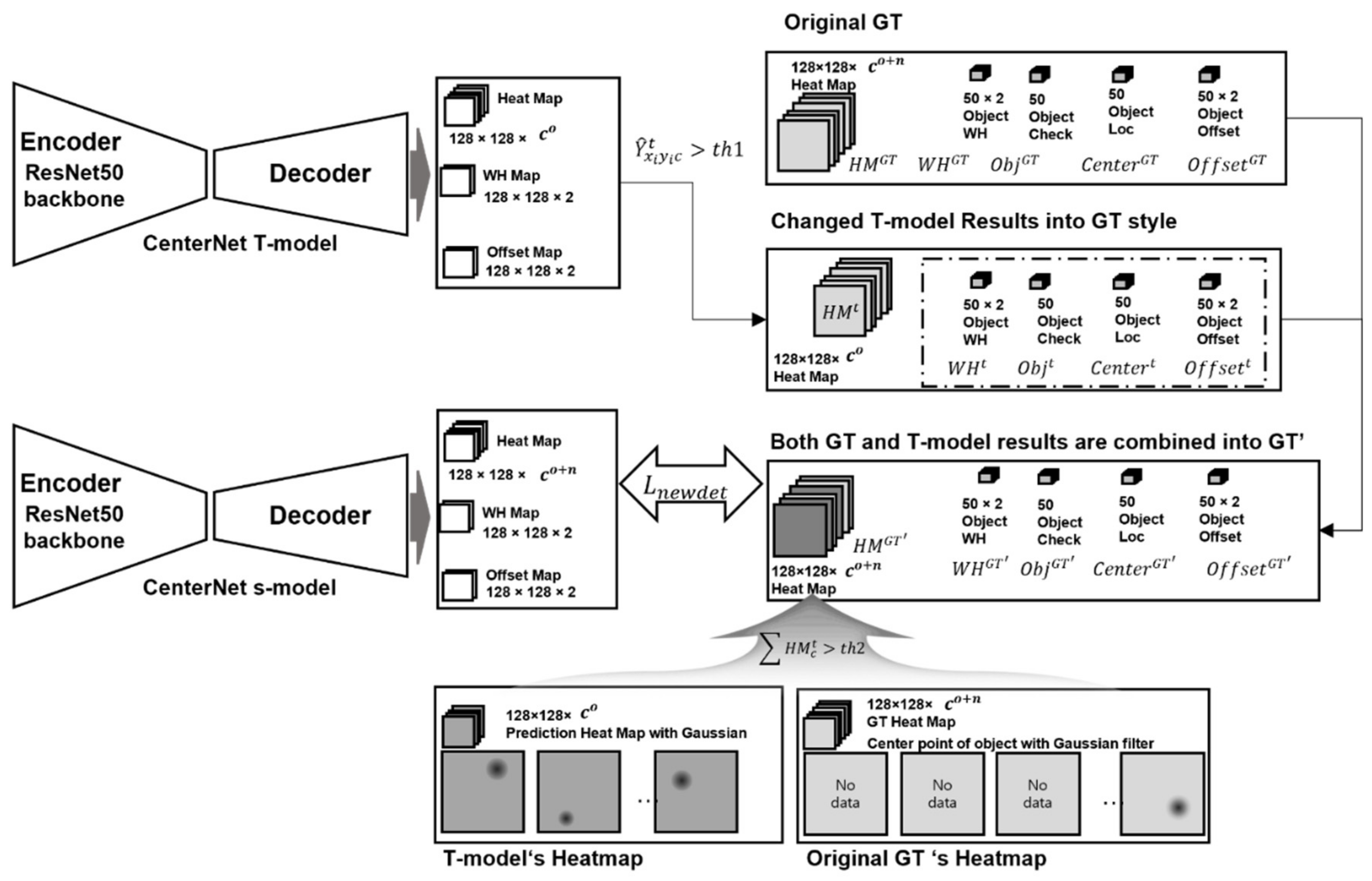
- The object detection CL model proposed in this study is an algorithm for distilling the teacher model prediction (t-pred) and delivering it to the next learning model. This can be distinguished from the models described in prior studies in the following ways:
- Instead of the simple layer distillation KD technique, we propose a method for generating the GT’ that combines t-pred with the ground truth (GT), which transforms t-pred into the same form as the GT.
- Two problems of t-pred, the prediction result of the t-model, are solved as follows:
- Not all results of t-pred are correct; to delete the error results, prediction information is only used when the prediction score of t-pred is greater than or equal to the threshold value.
- Objects included in the GT only have information about new classes, but the t-model only interprets new images as past class lists; as a result, t-pred can misclassify new class objects into past classes. To solve this problem, the IoU scores of the object of the GT and the object of t-pred are compared to prevent misclassification by using only objects below the threshold.
- Among the objects included in the new learning image target, the number of objects related to the previous class was small. Considering this problem, KD can be performed for entire output layers to distill all the information related to the class, size, and size correction values of the object.
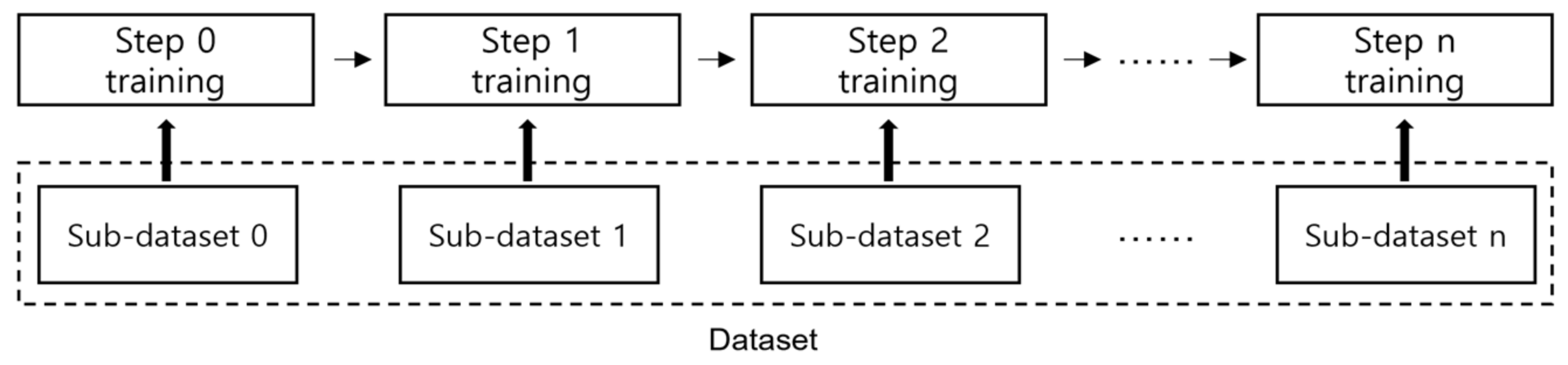
- In our study, old data and old class labels are not reused in the learning process of the s-model. The dataset is used separately in learning as shown in Figure 1. In this process, when the existing loss function of the CenterNet model is used as it is, information on the existing class cannot be learned in the new class learning process. It means there is a problem in that the weight associated with the existing class is changed. We suggest that the loss function associated with the existing class is modified among the loss functions.
- The s-model first learns new classes at the GT and then learns information from the previous class and new class information together at the GT’ to reduce the occurrence of catastrophic forgetting about existing classes when learning new classes.
2. Related Work
2.1. Continual Learning and Knowledge Distillation
2.2. Data Scenario
- Sequential: The image used in the previous learning is not used in the subsequent learning. When there is label information about the previous (old) class in the image used in the subsequent learning, then the information is included in the learning process [15].
- Disjoint: The images used in the previous learning are not used in the subsequent learning. However, in disjoint, if there is label information for the previous (old) class in the new images, then the information is not included in the subsequent learning [15].
- Overlapped: Unlike sequential and disjoint, the images used in the previous learning are also used in the subsequent learning. However, the class label only uses information that has been newly added to the corresponding order of learning [15].
3. Methodology
3.1. CenterNet
3.2. Prediction Distillation of Teacher Model
3.3. Knowledge Distillation of Output Layers
3.4. Total Loss Function of the Proposed Model
4. Experiment
4.1. Experiment Environment
4.2. Comparison Verification Configuration
4.3. Experimental Results
4.4. Consideration
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, Z.; Liu, B. Lifelong Machine Learning. In Synthesis Lectures on Artificial Intelligence and Machine Learning, 2nd ed.; Morgan & Claypool Publishers: San Rafael, CA, USA, 2016; Volume 10, pp. 1–27. [Google Scholar]
- Masana, M.; Liu, X.; Twardowski, B.; Menta, M.; Bagdanov, A.D.; van de Weijer, J. Class-incremental learning: Survey and performance evaluation on image classification. arXiv 2020, arXiv:2010.15277. [Google Scholar]
- Van de Ven, G.M.; Tolias, A.S. Three scenarios for continual learning. arXiv 2019, arXiv:1904.07734. [Google Scholar]
- Mai, Z.; Li, R.; Jeong, J.; Quispe, D.; Kim, H.; Sanner, S. Online Continual Learning in Image Classification: An Empirical Survey. Neurocomputing 2021, 469, 28–51. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network Geoffrey. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Li, Z.; Hoiem, D. Learning without Forgetting. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2935–2947. [Google Scholar] [CrossRef] [Green Version]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Peng, C.; Zhao, K.; Maksoud, S.; Li, M.; Lovell, B.C. SID: Incremental learning for anchor-free object detection via Selective and Inter-related Distillation. Comput. Vis. Image Underst. 2021, 210, 103229. [Google Scholar] [CrossRef]
- Delange, M.; Aljundi, R.; Masana, M.; Parisot, S.; Jia, X.; Leonardis, A.; Slabaugh, G.; Tuytelaars, T. A continual learning survey: Defying forgetting in classification tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3366–3385. [Google Scholar] [CrossRef] [PubMed]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, H.-E.; Kim, S.; Lee, J. Keep and Learn: Continual Learning by Constraining the Latent Space for Knowledge Preservation in Neural Networks. Lect. Notes Comput. Sci. 2018, 11070, 520–528. [Google Scholar]
- Gang, S.; Chung, D.; Lee, J.J. Knowledge Distillation Based Continual Learning for PCB Part Detection. J. Korea Multimed. Soc. 2021, 24, 868–879. [Google Scholar]
- Shmelkov, K.; Schmid, C.; Alahari, K. Incremental Learning of Object Detectors without Catastrophic Forgetting. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3420–3429. [Google Scholar] [CrossRef] [Green Version]
- Zhou, W.; Chang, S.; Sosa, N.; Hamann, H.; Cox, D. Lifelong Object Detection. arXiv 2020, arXiv:2009.01129. [Google Scholar]
- Michieli, U.; Zanuttigh, P. Continual Semantic Segmentation via Repulsion-Attraction of Sparse and Disentangled Latent Representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 25 June 2021. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 28 October 2019; pp. 9626–9635. [Google Scholar]
- Feng, T.; Wang, M. Response-based Distillation for Incremental Object Detection. arXiv 2021, arXiv:2110.13471. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized Focal Loss V2: Learning Reliable Localization Quality Estimation for Dense Object Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 25 June 2021; pp. 11627–11636. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. Lect. Notes Comput. Sci. 2018, 11211, 833–851. [Google Scholar]
- Michieli, U.; Zanuttigh, P. Knowledge Distillation for Incremental Learning in Semantic Segmentation. arXiv 2019, arXiv:1911.03462. [Google Scholar] [CrossRef]
- Michieli, U.; Zanuttigh, P. Incremental Learning Techniques for Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- GitHub—Xingyizhou/CenterNet: Object Detection, 3D Detection, and Pose Estimation Using Center Point Detection. Available online: https://github.com/xingyizhou/CenterNet (accessed on 24 October 2021).
- Reproducibility—PyTorch 1.10.0 Documentation. Available online: https://pytorch.org/docs/stable/notes/randomness.html (accessed on 1 November 2021).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | 20 Classes | 19 Classes | Fine Tuning | LwF [6] | SID [8] | SID [8] k = 3 | SID [8] k = 4 | SDR [15] KD1 | SDR [15] KD2 | Proposed |
|---|---|---|---|---|---|---|---|---|---|---|
| aeroplane | 73.7 | 76.6 | 10.7 | 41.9 | 62.5 | 59.5 | 52.4 | 67.7 | 54.1 | 69.1 |
| bicycle | 79.1 | 81.2 | 11.7 | 33.5 | 66.7 | 68.3 | 62 | 73.7 | 63.5 | 78.2 |
| bird | 70.6 | 72.1 | 26.1 | 34 | 52.1 | 41.1 | 25.9 | 64.5 | 58.1 | 64.6 |
| boat | 62.6 | 60.1 | 11.7 | 26.1 | 36.7 | 27.9 | 14.9 | 49.7 | 35.4 | 49 |
| bottle | 56.9 | 54.5 | 8.5 | 21.5 | 38.4 | 24.7 | 30.4 | 47.9 | 28.3 | 50.1 |
| bus | 79.1 | 77.7 | 12.9 | 38.9 | 64.1 | 61.8 | 52.3 | 66.1 | 34.7 | 72.1 |
| car | 83.7 | 84.3 | 14.4 | 45.5 | 64.3 | 76.2 | 70.8 | 48.7 | 34.1 | 73.6 |
| cat | 81.2 | 80.5 | 49 | 58.4 | 68.7 | 44.8 | 18.2 | 78 | 74.8 | 76.2 |
| chair | 58.4 | 58.6 | 9.1 | 21.4 | 35.4 | 39.6 | 37.1 | 40.5 | 24.4 | 49.8 |
| cow | 78.8 | 79.5 | 30.4 | 60.6 | 69 | 67.1 | 54.9 | 73.3 | 66.9 | 74.6 |
| diningtable | 70.5 | 67.5 | 11.6 | 22.3 | 58.1 | 56.7 | 57.6 | 59.1 | 54 | 65.7 |
| dog | 79.3 | 78.5 | 27.3 | 39.5 | 66.8 | 57.8 | 41.7 | 72.1 | 65.8 | 71.9 |
| horse | 81.6 | 84 | 14.4 | 40.9 | 67.2 | 61.7 | 42.8 | 78.1 | 62.9 | 78.4 |
| motorbike | 79.3 | 81.9 | 0.5 | 10.9 | 59.1 | 73 | 61.1 | 65.3 | 49.4 | 70.2 |
| person | 78.7 | 79.4 | 27.5 | 57.1 | 65.6 | 53 | 38.9 | 73.7 | 68.1 | 77.5 |
| pottedplant | 47.7 | 45.5 | 9.1 | 17.8 | 30.8 | 23.6 | 28.5 | 34.1 | 29.3 | 40.6 |
| sheep | 77.9 | 77.6 | 40.5 | 45 | 68.9 | 60.5 | 48.9 | 70.7 | 69.9 | 77.1 |
| sofa | 70.1 | 69.7 | 19.5 | 33.1 | 58.5 | 40.5 | 24.3 | 58.4 | 51.5 | 63.4 |
| train | 79.1 | 79.5 | 27.2 | 54.3 | 63.5 | 63.9 | 57.6 | 71.7 | 54.4 | 73.7 |
| tv/monitor | 73.4 | - | 42.4 | 22.6 | 16.4 | 15.9 | 12.5 | 13.9 | 17.2 | 27.7 |
| mAP | 73.1 | 73.1 | 20.2 | 36.3 | 55.6 | 50.9 | 41.6 | 60.4 | 49.8 | 65.2 |
| 1–19 mAP | - | 73.1 | 19 | 37 | 57.7 | 52.7 | 43.2 | 62.8 | 51.5 | 67.1 |
| 20 mAP | - | - | 42.4 | 22.6 | 16.4 | 15.9 | 12.5 | 13.9 | 17.2 | 27.7 |
| - | - | 26.3 | 28.1 | 25.5 | 24.4 | 19.3 | 22.8 | 25.8 | 39.2 |
| 20 Classes | 20 Classes | 15 Classes | Fine Tuning | LwF [6] | SID [8] | SID [8] | SID [8] | SDR [15] KD1 | SDR [15] KD2 | Proposed |
|---|---|---|---|---|---|---|---|---|---|---|
| aeroplane | 73.7 | 74.9 | 26.4 | 9.1 | 59 | 44.3 | 33.7 | 51.9 | 2.3 | 68 |
| bicycle | 79.1 | 81.3 | 0 | 9.1 | 77.3 | 77.5 | 76.4 | 75.7 | 38.4 | 78.9 |
| bird | 70.6 | 70.1 | 9.1 | 9.1 | 53.8 | 54.4 | 54.9 | 52 | 14.3 | 61.7 |
| boat | 62.6 | 60.3 | 4.9 | 25.6 | 51.4 | 55.6 | 53 | 8.5 | 0 | 56.2 |
| bottle | 56.9 | 54.7 | 9.1 | 0 | 41.9 | 48.3 | 44.3 | 15.9 | 0.3 | 49.7 |
| bus | 79.1 | 76.6 | 0 | 6.1 | 63.9 | 55.2 | 70.2 | 41.4 | 7.3 | 54.9 |
| car | 83.7 | 84.1 | 34.8 | 16.2 | 77.6 | 79.1 | 79.4 | 38.8 | 34.8 | 79.8 |
| cat | 81.2 | 79.6 | 9.1 | 0 | 62.1 | 53.7 | 53.7 | 73.4 | 50.4 | 78.6 |
| chair | 58.4 | 56.9 | 9.1 | 0 | 43.7 | 48.9 | 50.9 | 28.7 | 13.4 | 50 |
| cow | 78.8 | 70.5 | 18.4 | 0 | 54.5 | 36.8 | 54.4 | 46.8 | 14 | 51 |
| diningtable | 70.5 | 63.1 | 0 | 0 | 60.3 | 59.3 | 56.2 | 54.1 | 0.3 | 61.2 |
| dog | 79.3 | 76.1 | 7.7 | 0 | 67.8 | 61.7 | 57 | 56.8 | 33.3 | 52.7 |
| horse | 81.6 | 82.9 | 27.2 | 0 | 79 | 78.6 | 77.9 | 73.7 | 41.5 | 75.4 |
| motorbike | 79.3 | 81 | 0 | 9.1 | 68.3 | 75.9 | 75.7 | 59.5 | 23.4 | 71 |
| person | 78.7 | 79.2 | 35.2 | 27 | 74.8 | 76.7 | 77.3 | 72.8 | 48.6 | 77 |
| pottedplant | 47.7 | - | 21.4 | 18.7 | 19.2 | 9.5 | 0.8 | 9.8 | 18.3 | 15.9 |
| sheep | 77.9 | - | 19.2 | 19.1 | 15.5 | 14.9 | 14.3 | 12.6 | 15.3 | 15.8 |
| sofa | 70.1 | - | 38 | 35.5 | 27.3 | 19.4 | 16.1 | 14.9 | 29.1 | 26.7 |
| train | 79.1 | - | 14.5 | 22.8 | 12.9 | 11.2 | 9 | 14.7 | 13.7 | 21.7 |
| tv/monitor | 73.4 | - | 41.3 | 32.5 | 37.1 | 17.1 | 12.4 | 26.4 | 39.9 | 34.5 |
| mAP | 73.1 | 72.8 | 16.3 | 12 | 52.4 | 48.9 | 48.4 | 41.4 | 21.9 | 54 |
| 1–15 mAP | - | 72.8 | 12.7 | 7.4 | 62.4 | 60.4 | 61 | 50 | 21.5 | 64.4 |
| 16–20 mAP | - | - | 26.9 | 25.7 | 22.4 | 14.4 | 10.5 | 15.7 | 23.3 | 22.9 |
| - | - | 17.3 | 11.5 | 32.9 | 23.3 | 17.9 | 23.9 | 22.3 | 33.8 |
| 20 Classes | 20 Classes | 10 Classes | Fine Tuning | LwF [6] | SID [8] | SID [8] | SID [8] | SDR [15] KD1 | SDR [15] KD2 | Proposed |
|---|---|---|---|---|---|---|---|---|---|---|
| aeroplane | 73.7 | 73.5 | 0 | 0 | 33 | 60 | 59 | 33.2 | 0.1 | 56.2 |
| bicycle | 79.1 | 78.4 | 0 | 0 | 58.1 | 70.2 | 68 | 8.3 | 0.2 | 67.8 |
| bird | 70.6 | 68.5 | 0 | 0 | 20.6 | 56.2 | 58.5 | 12.2 | 2.3 | 37.2 |
| boat | 62.6 | 62.5 | 0 | 0 | 15.3 | 44.3 | 39.1 | 30.5 | 4.6 | 38.8 |
| bottle | 56.9 | 54.5 | 0 | 0 | 6.1 | 35 | 33.2 | 5.7 | 0 | 42 |
| bus | 79.1 | 74.7 | 0 | 0 | 56.9 | 63 | 63.1 | 24.4 | 0.1 | 30.9 |
| car | 83.7 | 84.9 | 0 | 0 | 69 | 77.9 | 76.5 | 56.3 | 0.2 | 75.1 |
| cat | 81.2 | 70.7 | 0 | 0 | 46.5 | 38.7 | 61.4 | 45.9 | 18.1 | 34.8 |
| chair | 58.4 | 56.7 | 0 | 0 | 29.2 | 33 | 42.5 | 11.6 | 0.1 | 48.6 |
| cow | 78.8 | 57.3 | 0 | 0 | 55.2 | 31.6 | 29.8 | 19.3 | 27.3 | 40.8 |
| diningtable | 70.5 | - | 50.1 | 35.7 | 38.3 | 38.6 | 26.4 | 32.9 | 49.6 | 43.1 |
| dog | 79.3 | - | 47.9 | 35.8 | 39.5 | 42.3 | 27.4 | 40.6 | 46.1 | 47 |
| horse | 81.6 | - | 68.7 | 60.5 | 62.8 | 61.1 | 51 | 63.4 | 68.8 | 67.5 |
| motorbike | 79.3 | - | 55 | 44.7 | 55.1 | 44.3 | 36.9 | 46.2 | 53.6 | 60.9 |
| person | 78.7 | - | 75.1 | 67.1 | 72.6 | 70.3 | 64.1 | 66.3 | 74.4 | 71.8 |
| pottedplant | 47.7 | - | 41.4 | 29.3 | 36.3 | 33 | 20.5 | 26.6 | 41.9 | 37.5 |
| sheep | 77.9 | - | 66.5 | 44.9 | 58.5 | 58.5 | 38.2 | 59.4 | 65.9 | 63.5 |
| sofa | 70.1 | - | 55.4 | 49.1 | 46.1 | 48.2 | 37.8 | 48.7 | 55.6 | 55.4 |
| train | 79.1 | - | 38 | 31.2 | 29.7 | 40.8 | 30 | 28.2 | 36.5 | 44.1 |
| tv/monitor | 73.4 | - | 62.2 | 51.8 | 61.3 | 58.5 | 46.9 | 49.5 | 57.8 | 61.6 |
| mAP | 73.1 | 68.2 | 28 | 22.5 | 44.5 | 50.3 | 45.5 | 35.5 | 30.1 | 51.2 |
| 1–15 mAP | - | 68.2 | 0 | 0 | 39 | 51 | 53.1 | 24.7 | 5.3 | 47.2 |
| 16–20 mAP | - | - | 56 | 45 | 50 | 49.6 | 37.9 | 46.2 | 55 | 55.2 |
| - | - | 0 | 0 | 43.8 | 50.3 | 44.2 | 32.2 | 9.6 | 50.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gang, S.; Chung, D.; Lee, J. Predictive Distillation Method of Anchor-Free Object Detection Model for Continual Learning. Appl. Sci. 2022, 12, 6419. https://doi.org/10.3390/app12136419
Gang S, Chung D, Lee J. Predictive Distillation Method of Anchor-Free Object Detection Model for Continual Learning. Applied Sciences. 2022; 12(13):6419. https://doi.org/10.3390/app12136419
Chicago/Turabian StyleGang, Sumyung, Daewon Chung, and Joonjae Lee. 2022. "Predictive Distillation Method of Anchor-Free Object Detection Model for Continual Learning" Applied Sciences 12, no. 13: 6419. https://doi.org/10.3390/app12136419