
Improved Multi-Model Classification Technique for Sound Event Detection in Urban Environments
 , ,
, ,
Abstract
:1. Introduction
- Our proposed stacked multi-model is accurate when used to split and classify artificial and natural sounds, with a high F1-score when fed into the S-CRNN separately.
- For overlapping sounds, that is, polyphonic sound events, CRNN works well compared to alternatives, with the overall ER improved to 0.11 and the F1-score by 10% on the evaluation dataset.
- Finally, for artificial sounds with continuous behavior, such as car sounds, a short filter mask is best; however, for non-continuous sounds, such as speaking, it is preferable to utilize a longer length of filter mask in the post-processing stage.
2. Related Work
3. Overview of DCASE Dataset
4. Proposed Methodology
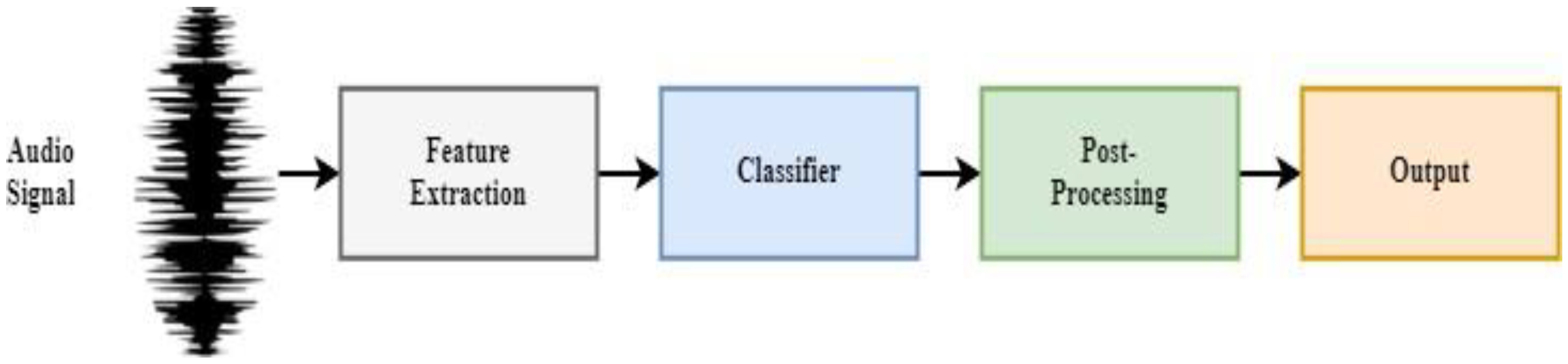
4.1. Input of Audio Signals
4.2. Features Extraction
4.2.1. MFCC
- The first step in the MFCC is to apply a pre-emphasis filter to increase the strength of the signal at higher frequencies. To decrease noise during audio capture, the following filtering procedure is carried out. Equation (1) presents the input–output connection in the time domain which provides the framework for this filter:where is the input audio signal, is a constant filter coefficient with a value equal to , is the output audio signal, and is the time domain.
- The audio signal is next split into frames within the range of 20 to 40 ms.
- A Hamming window is applied to each frame after the audio signal is segmented into frames, as modelled in Equation (2):where is the output audio signal and is the input audio signal convolved with , that is, the hamming window calculated in Equation (3):where N represents total number of frames and is the time domain.
- Using STFT, the time domain data are converted to frequency domain data for each frame N, which procedure is formulated in Equation (4):where denotes the ith frame of signal x such that i = 0, 1, 2,..., N − 1 and P is the power spectrum.
- A triangular filter is used to calculate the filter bank using Equation (5):where is the mel scale used to convert an audio frequency into a frequency range that people can hear and f represents the frequency, which can be computed using Equation (6):
- The inverse logarithm of this log spectrum should be determined after obtaining the relative auditory spectra.
4.2.2. RASTA-PLP
- First, audio signals are divided into frames.
- Then, the logarithm of the short-time critical-band spectrum is determined. The transformation of the bark frequency from the angular frequency is computed as shown in Equation (7):
- 3.
- Next, we take the regression line-based temporal derivative of the aforementioned spectrum.
- 4.
- Then, an IIR system is utilized to perform temporal derivative filtering on the log-critical band.
- 5.
- In order to imitate human hearing, an equal loudness curve is added.
- 6.
- The inverse logarithm of this log spectrum should be determined after obtaining the relative auditory spectra.
- 7.
- After all of the spectral pole models have been calculated, the PLP requirements are satisfied.
4.3. Classifier
4.4. Post-Processing
4.5. Output
5. Experimental and Performance Evaluation
5.1. Evolution Metrics
5.2. Results and Discussion
5.2.1. ANN-Based Classifier
5.2.2. CRNN-Based Classifier
5.2.3. S-CRNN-Based Classifier
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ANN | Artificial Neural Network |
| ASR | Automatic Speech Recognition |
| CNN | Convolutional Neural Network |
| DCASE | Detection and Classification of Acoustic Scenes and Events |
| DNN | Deep Neural Network |
| DCNN | Deep Convolutional Neural Network |
| ER | Error rate |
| FC | Fully connected |
| GMM−HMM | Gaussian Mixture Model–Hidden Markov Model |
| GLU | Gated Linear Unit |
| GTCC | Gammatone Cepstral Coefficients |
| GRU | Gated Recurrent Unit |
| IIR | Infinite Impulse Response |
| KNN | k-Nearest Neighbors |
| LSTM | Long short-term memory |
| MFCC | Mel-Frequency Cepstral Coefficients |
| MVDR | Minimum Variance Distortionless Response |
| NMF | Non-negative Matrix Factorization |
| NS | Noise Resistant |
| NB−ACF | Narrow-Band Autocorrelation Function Features |
| NN | Neural Network |
| PLP | Perceptual Linear Prediction |
| RASTA | RelAtive SpecTrA |
| RNN | Recurrent Neural Networks |
| S−CRNN | Stack Convolutional Recurrent Neural Network |
| SED | Sound Event Detection |
| SVM | Support Vector Machine |
| STFT | Short-Time Fourier Transform |
| TF | Time Frequency |
| TAU | Tamper University |
| WPE | Weighted Prediction Error |
References
- Mesaros, A.; Heittola, T.; Diment, A.; Elizalde, B.; Shah, A.; Vincent, E.; Raj, B.; Virtanen, T. DCASE 2017 challenge setup: Tasks, datasets and baseline system. In Proceedings of the DCASE 2017-Workshop on Detection and Classification of Acoustic Scenes and Events, Munich, Germany, 16–17 November 2017. [Google Scholar]
- Adavanne, S.; Virtanen, T. A report on sound event detection with different binaural features. arXiv 2017, arXiv:171002997. [Google Scholar]
- Chavdar, M.; Gerazov, B.; Ivanovski, Z.; Kartalov, T. Towards a system for automatic traffic sound event detection. In Proceedings of the 2020 28th Telecommunications Forum (TELFOR), Belgrade, Serbia, 24–25 November 2020; pp. 1–4. [Google Scholar]
- Harma, A.; McKinney, M.F.; Skowronek, J. Automatic surveillance of the acoustic activity in our living environment. In Proceedings of the 2005 IEEE International Conference on Multimedia and Expo, Amsterdam, The Netherlands, 6–8 July 2005; p. 4. [Google Scholar]
- Avgoustinakis, P.; Kordopatis-Zilos, G.; Papadopoulos, S.; Symeonidis, A.L.; Kompatsiaris, I. Audio-based near-duplicate video retrieval with audio similarity learning. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 5828–5835. [Google Scholar]
- Parascandolo, G.; Huttunen, H.; Virtanen, T. Recurrent neural networks for polyphonic sound event detection in real life recordings. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 6440–6444. [Google Scholar]
- Mesaros, A.; Heittola, T.; Dikmen, O.; Virtanen, T. Sound event detection in real life recordings using coupled matrix factorization of spectral representations and class activity annotations. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Queensland, Australia, 19–24 April 2015; pp. 151–155. [Google Scholar]
- Mesaros, A.; Heittola, T.; Eronen, A.; Virtanen, T. Acoustic event detection in real life recordings. In Proceedings of the 2010 18th European Signal Processing Conference, Aalborg, Denmark, 23–27 August 2010; pp. 1267–1271. [Google Scholar]
- Cakir, E.; Heittola, T.; Huttunen, H.; Virtanen, T. Polyphonic sound event detection using multi label deep neural networks. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–16 July 2015; pp. 1–7. [Google Scholar]
- Mesaros, A.; Heittola, T.; Virtanen, T.; Plumbley, M.D. Sound event detection: A tutorial. IEEE Signal Process. Mag. 2021, 38, 67–83. [Google Scholar] [CrossRef]
- Zhou, Q.; Feng, Z.; Benetos, E. Adaptive noise reduction for sound event detection using subband-weighted NMF. Sensors 2019, 19, 3206. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schröder, J.; Anemüller, J.; Goetze, S. Performance comparison of GMM, HMM and DNN based approaches for acoustic event detection within Task 3 of the DCASE 2016 challenge. In Proceedings of the DCASE, Budapest, Hungary, 3 September 2016; pp. 80–84. [Google Scholar]
- Yang, L.; Hao, J.; Gu, X.; Hou, Z. Sound Event Detection width Audio Tagging Consistency Constraint CRNN. J. Electron. Inf. Technol. 2022, 44, 1102–1110. [Google Scholar]
- Kong, Q.; Sobieraj, I.; Wang, W.; Plumbley, M. Deep neural network baseline for DCASE challenge 2016. In Proceedings of the DCASE, Budapest, Hungary, 3 September 2016. [Google Scholar]
- Mesaros, A.; Heittola, T.; Benetos, E.; Foster, P.; Lagrange, M.; Virtanen, T.; Plumbley, M.D. Detection and classification of acoustic scenes and events: Outcome of the DCASE 2016 challenge. IEEEACM Trans. Audio Speech Lang. Process. 2017, 26, 379–393. [Google Scholar] [CrossRef] [Green Version]
- Zhao, F.; Li, R.; Liu, X.; Xu, L. Soft-Median Selection: An adaptive feature smoothening method for sound event detection. Appl. Acoust. 2022, 192, 108715. [Google Scholar] [CrossRef]
- Meng, J.; Wang, X.; Wang, J.; Teng, X.; Xu, Y. A capsule network with pixel-based attention and BGRU for sound event detection. Digit. Signal Process. 2022, 123, 103434. [Google Scholar] [CrossRef]
- Shaer, I.; Shami, A. Sound Event Classification in an Industrial Environment: Pipe Leakage Detection Use Case. arXiv 2022, arXiv:220502706. [Google Scholar]
- Hou, Y.; Li, S. Sound event detection in real life audio using multimodel system. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2017, Munich, Germany, 16 November 2017. [Google Scholar]
- Dang, A.; Vu, T.H.; Wang, J.-C. Deep learning for DCASE2017 challenge. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2017, Munich, Germany, 16 November 2017. [Google Scholar]
- Zhou, J. Sound event detection in multichannel audio LSTM network. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2017, Munich, Germany, 16 November 2017. [Google Scholar]
- Jeong, I.-Y.; Lee, S.; Han, Y.; Lee, K. Audio Event Detection Using Multiple-Input Convolutional Neural Network. In Proceedings of the DCASE, Munich, Germany, 16–17 November 2017; pp. 51–54. [Google Scholar]
- Lu, R.; Duan, Z. Bidirectional GRU for sound event detection. In Proceedings of the DCASE, Munich, Germany, 16–17 November 2017; pp. 1–3. [Google Scholar]
- Chen, Y.; Zhang, Y.; Duan, Z. DCASE2017 sound event detection using convolutional neural network. In Proceedings of the DCASE, Munich, Germany, 16–17 November 2017. [Google Scholar]
- Xia, X.; Togneri, R.; Sohel, F.; Huang, D. Class wise distance based acoustic event detection. In Proceedings of the DCASE, Munich, Germany, 16–17 November 2017. [Google Scholar]
- Kroos, C.; Plumbley, M. Neuroevolution for sound event detection in real life audio: A pilot study. In Proceedings of the DCASE, Munich, Germany, 16–17 November 2017. [Google Scholar]
- Li, Y.; Li, X. The SEIE-SCUT systems for IEEE AASP challenge on DCASE 2017: Deep learning techniques for audio representation and classification. In Proceedings of the DCASE, Munich, Germany, 16–17 November 2017. [Google Scholar]
- Marsal, P.P.; Pol, S.; Hagen, A.; Bourlard, H.; Nadeu, C. Comparison and combination of RASTA-PLP and FF features in a hybrid HMM/MLP speech recognition system. In Proceedings of the 7th Intertnational Conference on Spoken Language Processing, Denver, CO, USA, 16–20 September 2002. [Google Scholar]
- Zhang, Z. Improved adam optimizer for deep neural networks. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018; pp. 1–2. [Google Scholar]
- Ho, Y.; Wookey, S. The real-world-weight cross-entropy loss function: Modeling the costs of mislabeling. IEEE Access 2019, 8, 4806–4813. [Google Scholar] [CrossRef]
- Abadi, M. TensorFlow: Learning functions at scale. In Proceedings of the 21st ACM SIGPLAN International Conference on Functional Programming, Nara, Japan, 18–22 September 2016; p. 1. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Literature (Year) | SED Model | Classification Strategy/Network | Audio Environment | Feature(s) |
|---|---|---|---|---|
| [1] 2017 | Baseline 2017 | Multi-layer perceptron | Urban | Log-mel energy |
| [2] 2017 | Adavanne TUT 1 | CRNN | Urban | Log-mel energy |
| [8] 2016 | Baseline 2016 | GMM | Urban | MFCC |
| [16] 2022 | Soft-Median Choice | CB+SMC+CDPP | Domestic | Log-mel energy |
| [17] 2022 | Capsule Network | PBA-AttCapsNet-BGRU | Smart cars | Log-mel energy |
| [13] 2022 | Audio Tagging Consistency Constraint | ATCC-CRNN | Domestic | Log-mel energy |
| [18] 2022 | Pipe Leakages | SVM | Pipe leakage | Time-domain features |
| [20] 2017 | Vu-Task3 | RNN | Urban | Log-mel energy |
| [28] 2002 | Viterbi Algorithm | HMM/MLP | Clean Speech | RASTA-PLP Frequency filtering |
| [21] 2017 | Zhou PKU 1 | LSTM | Urban | Log-mel energy |
| [22] 2017 | Lee SNU 3 | CNN | Urban | Log-mel energy |
| [23] 2017 | Lu THU 1 | RNN | Urban | MFCC Pitch |
| [24] 2017 | Chen UR 1 | CNN | Urban | Log-mel energy |
| [25] 2017 | Xia UWA 3 | CNN | Urban | Log-mel energy |
| [26] 2017 | Kroos CVSSP 2 | Neuro- evolution | Urban | Scattering transfer Clustering |
| [19] 2017 | Hu BUPT 2 | BGRU | Urban | Raw audio |
| [27] 2017 | Li Scut 2 | Bi-LSTM | Urban | MFCC |
| Proposed 2022 | Stacked Multi-Model | CRNN, S-CRNN, and ANN | Urban | RASTA-PLP, MFCC |
| Event (Subclass) | Brakes Squeaking | Car | Children | Large Vehicle | People Speaking | People Walking | Total Occurrences |
|---|---|---|---|---|---|---|---|
| Dev-Set | 52 | 304 | 44 | 61 | 89 | 109 | 659 |
| Eval-Set | 23 | 106 | 15 | 24 | 37 | 42 | 272 |
| Parameters | MFCC | RASTA-PLP |
|---|---|---|
| Sampling frequency | 44.1 kHz | 44.1 kHz |
| Hop length | 20 ms | 20 ms |
| Mel-filter length | 40 | Nil |
| Model order | Nil | 12 |
| Window | Hamming | Hamming |
| Window size | 1024 | 1024 |
| Do Rasta | Nil | Yes |
| Sound Events Class | Baseline [1] | ANN | ||||
|---|---|---|---|---|---|---|
| MFCC | MFCC | RASTA-PLP | ||||
| ER | F1-Score | ER | F1-Score | ER | F1-Score | |
| Brakes Squeaking | 0.98 | 4 | 1.00 | 0 | 0.95 | 7 |
| Car | 0.57 | 74 | 0.51 | 55 | 0.47 | 63 |
| Children | 1.35 | 0 | 1.01 | 40 | 1.21 | 0 |
| Large Vehicle | 0.9 | 51 | 0.80 | 27 | 0.67 | 38 |
| People Speaking | 1.25 | 18 | 0.99 | 0 | 0.92 | 10 |
| People Walking | 0.9 | 51 | 0.93 | 10 | 0.58 | 48 |
| Sound Events Class | Baseline [1] | CRNN | ||||||
|---|---|---|---|---|---|---|---|---|
| MFCC | MFCC | RASTA-PLP | MFCC+ RASTA-PLP | |||||
| ER | F1-Score | ER | F1-Score | ER | F1-Score | ER | F1-Score | |
| Brakes Squeaking | 0.98 | 4 | 0.81 | 0.28 | 0.97 | 0.04 | 0.85 | 0.09 |
| Car | 0.57 | 74 | 0.44 | 0.6 | 0.38 | 0.71 | 0.44 | 0.55 |
| Children | 1.35 | 0 | 0.98 | 0 | 1 | 0 | 1.2 | 0 |
| Large Vehicle | 0.9 | 51 | 0.70 | 0.52 | 0.67 | 0.43 | 0.69 | 0.51 |
| People Speaking | 1.25 | 18 | 0.95 | 0.07 | 0.98 | 0.02 | 0.99 | 0 |
| People Walking | 0.9 | 51 | 0.57 | 0.56 | 0.78 | 0.32 | 0.8 | 0.41 |
| Sound Events Class | Dev-Set | Eval-Set | ||||||
|---|---|---|---|---|---|---|---|---|
| Baseline [1] | S-CRNN | Baseline [1] | S-CRNN | |||||
| MFCC | MFCC+RASTA-PLP | MFCC | MFCC+RASTA-PLP | |||||
| ER | F1-Score | ER | F1-Score | ER | F1-Score | ER | F1-Score | |
| Brakes Squeaking | 0.98 | 4 | 0.69 | 48 | 0.92 | 16.5 | 0.69 | 55 |
| Car | 0.57 | 74 | 0.33 | 67 | 0.76 | 61.5 | 0.14 | 66 |
| Children | 1.35 | 0 | 0.87 | 17 | 2.6 | 0 | 0.8 | 0 |
| Large Vehicle | 0.9 | 51 | 0.46 | 55 | 1.44 | 42.7 | 0. 9 | 14 |
| People Speaking | 1.25 | 18 | 0.79 | 22 | 1.29 | 8.6 | 1 | 10 |
| People Walking | 0.9 | 51 | 0.48 | 57 | 1.44 | 33.5 | 1 | 54 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, M.S.; Shah, M.; Khan, A.; Aldweesh, A.; Ali, M.; Tag Eldin, E.; Ishaq, W.; Hussain, L. Improved Multi-Model Classification Technique for Sound Event Detection in Urban Environments. Appl. Sci. 2022, 12, 9907. https://doi.org/10.3390/app12199907
Khan MS, Shah M, Khan A, Aldweesh A, Ali M, Tag Eldin E, Ishaq W, Hussain L. Improved Multi-Model Classification Technique for Sound Event Detection in Urban Environments. Applied Sciences. 2022; 12(19):9907. https://doi.org/10.3390/app12199907
Chicago/Turabian StyleKhan, Muhammad Salman, Mohsin Shah, Asfandyar Khan, Amjad Aldweesh, Mushtaq Ali, Elsayed Tag Eldin, Waqar Ishaq, and Lal Hussain. 2022. "Improved Multi-Model Classification Technique for Sound Event Detection in Urban Environments" Applied Sciences 12, no. 19: 9907. https://doi.org/10.3390/app12199907