
SRMANet: Toward an Interpretable Neural Network with Multi-Attention Mechanism for Gearbox Fault Diagnosis


Abstract
:1. Introduction
- (1)
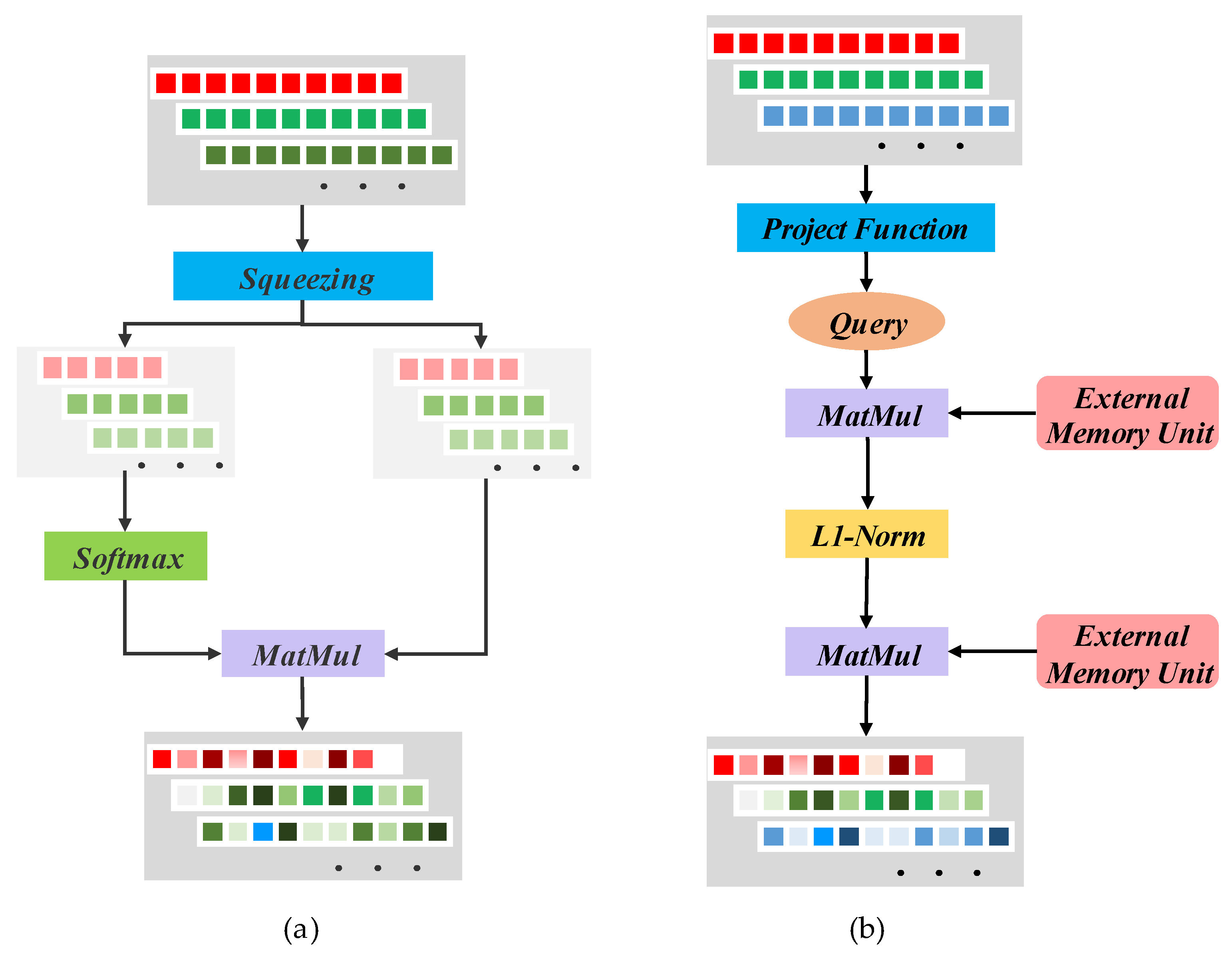
- Two self-attention mechanisms, Squeeze-Attention and External-Attention, are proposed for extracting vibration signals. This work will also discuss the affinity of features in the temporal direction that can be obtained, as well as the subject of refining the features by fusing the two methods.
- (2)
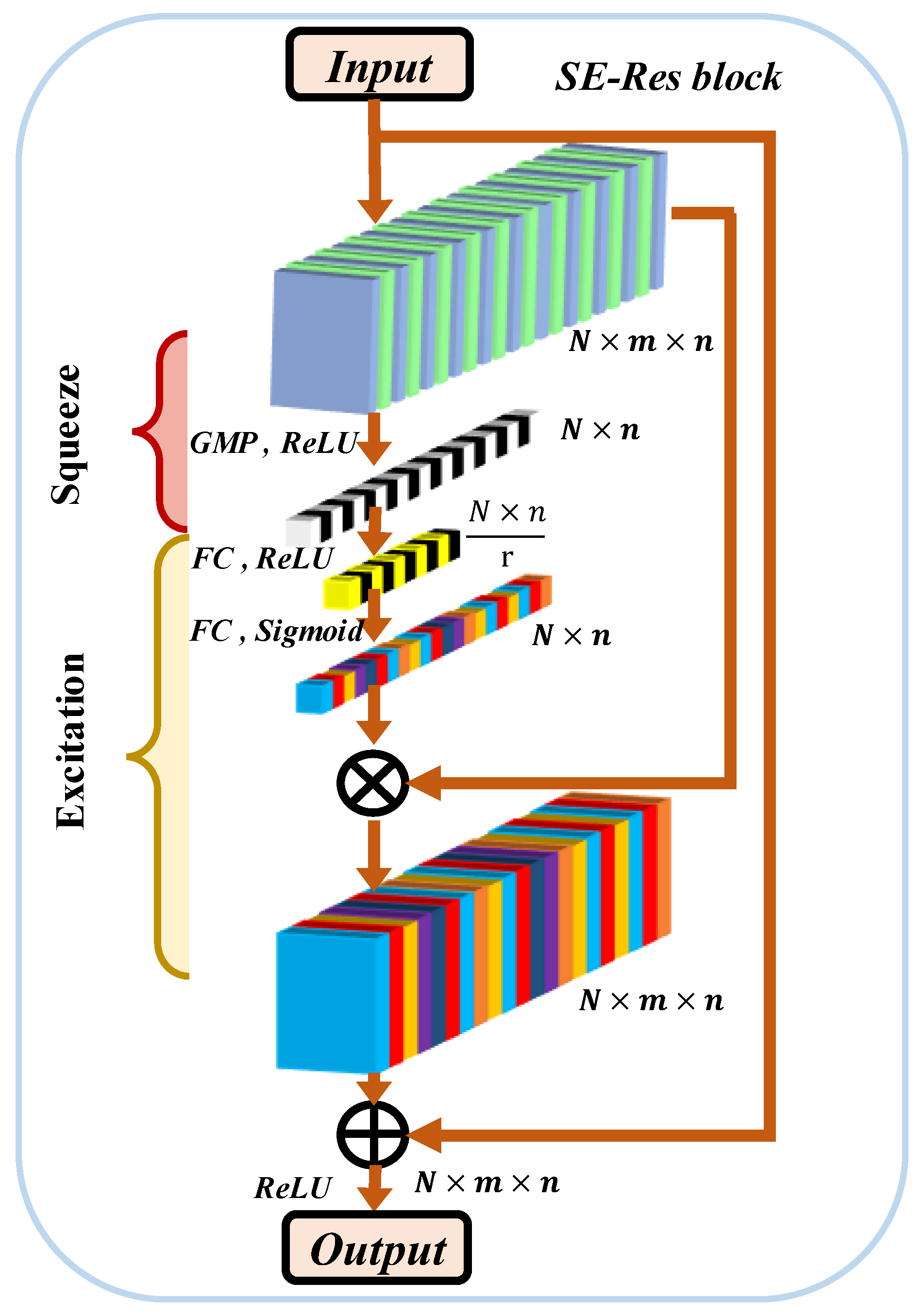
- The adaptability of the model to the length of the data is preserved from noise using the convolution block. The feature extraction stage introduces a Squeeze-Excitation one-dimensional residual block (SE-Res block), which removes redundant features contained in the residual connections and captures the nonlinear interactions between channels. This is achieved through the multi-level linkage of attention, focusing on the relationship between feature maps with high fault correlation and channels.
- (3)
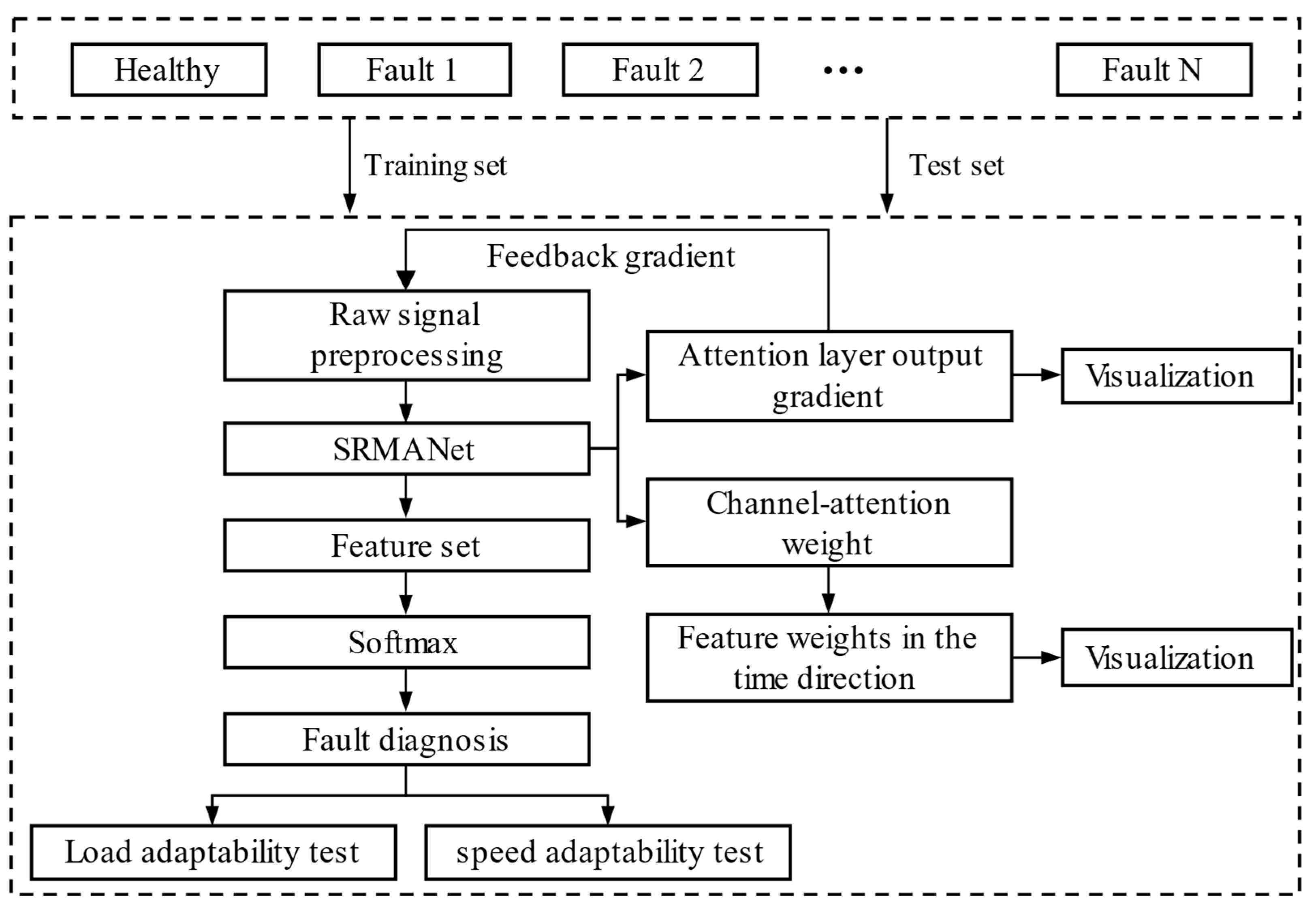
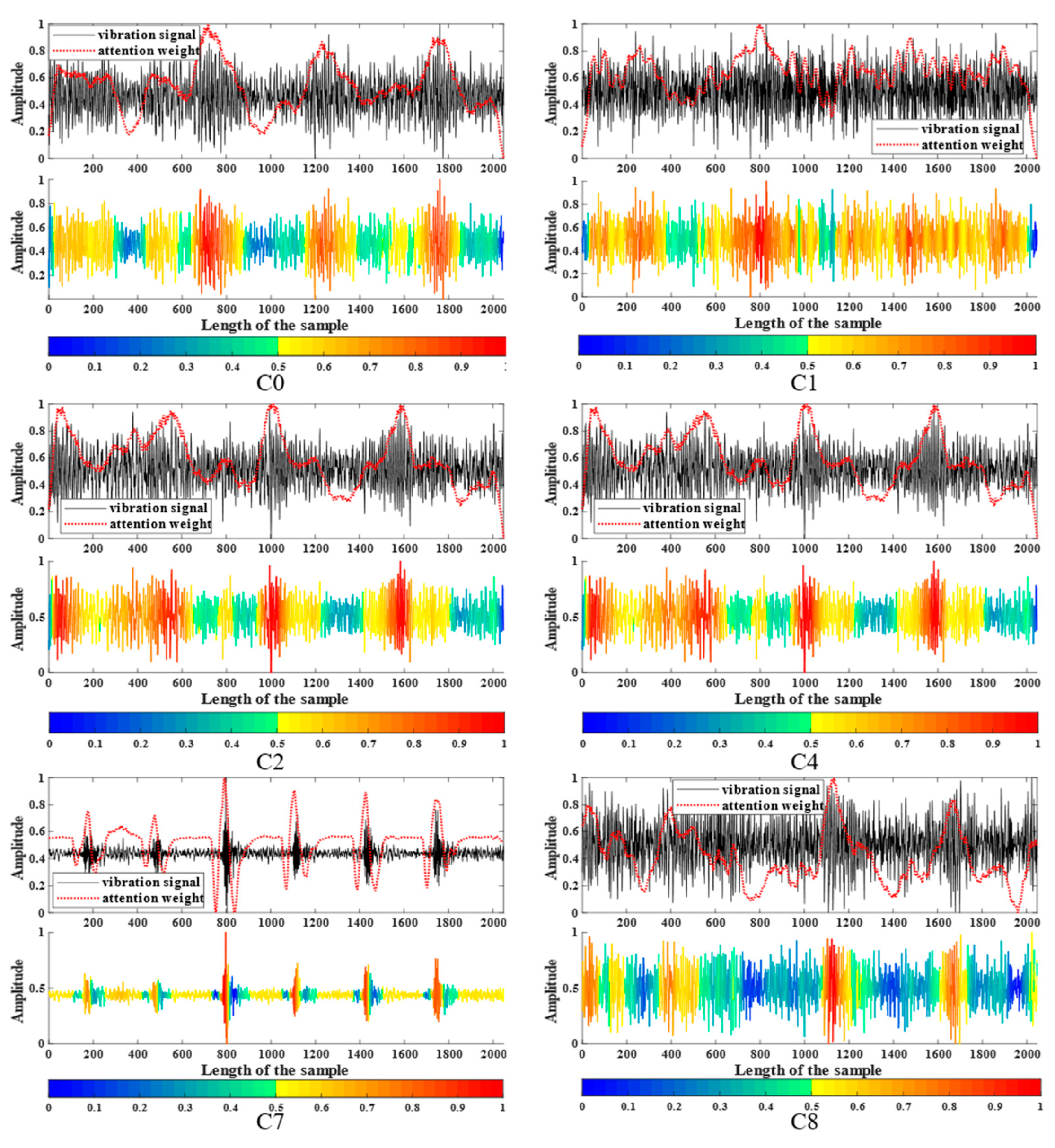
- Visualizing arbitrary layer attention weights on input signals using reverse gradients makes the model interpretable. According to the results, it is found that the attention mechanism can assign higher weights to the impulse components of the time-domain signal and lower weights to the fault-independent feature components.
- (4)
- Laboratory planetary gearbox compound faults and single faults of different levels are effectively identified. SRMANet has also been shown in adaptive experiments to be more robust when the load/speed changes.
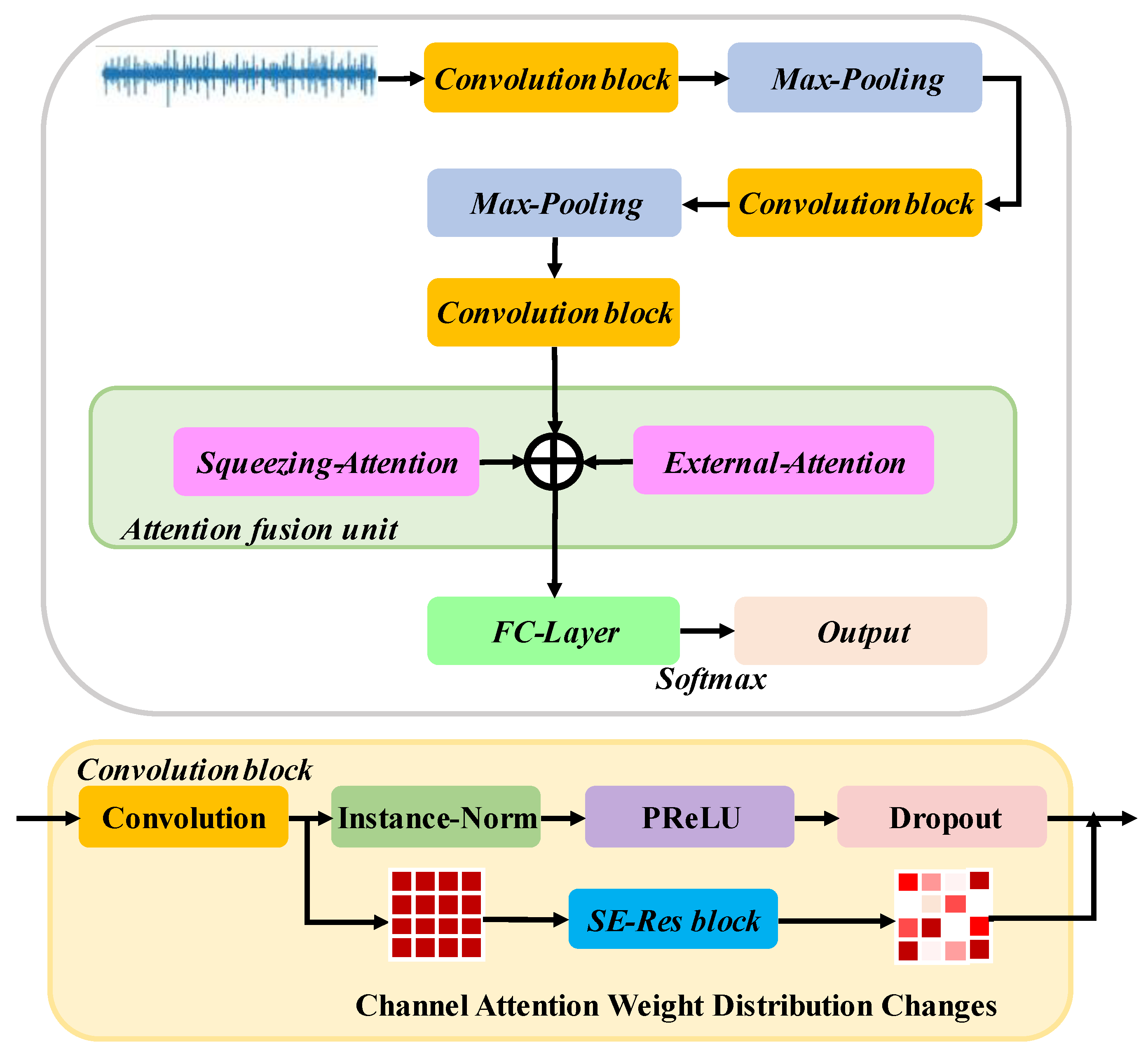
2. Stacked Residual Multi-Attention Network Framework
2.1. Convolutional Operations and Interpretability Explored
2.2. Instance Normalization Layer
2.3. Parametric Rectified Linear Unit (PReLU)
2.4. Dropout
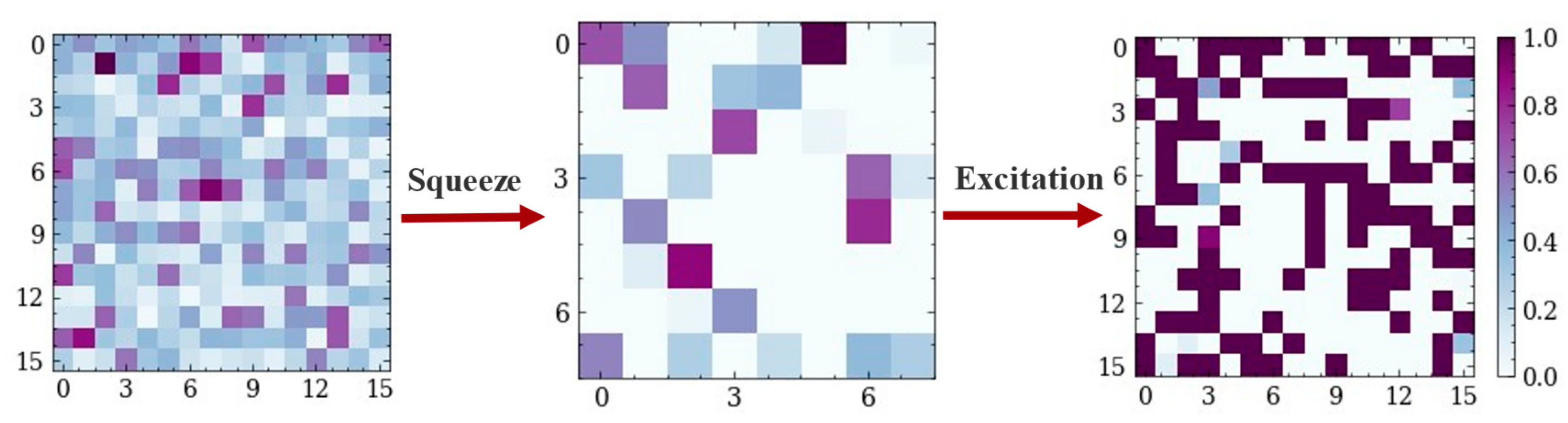
2.5. SE-Res Block
2.6. Attention Fusion Unit
| Algorithm 1: SRMANet training process |
| Input: single channel training data of any cut length , corresponding labels and position set of visualization layer , where indicates the model depth Parameters: learning rate , epoch , SRMANet model parameter , class number K, Gating ratio in Equation (8) and hyperparameter of the memory unit in Equation (12) Output: SRMANet model M and Gradient set ofvisualization layer 1: Initialize and shuffle the train set 2: for do 3: Calculate cross entropy loss 4: Calculate model gradient 5: update 6: if then 7: return model parameter and 8: end if 9: end for |
3. Experimental Verification
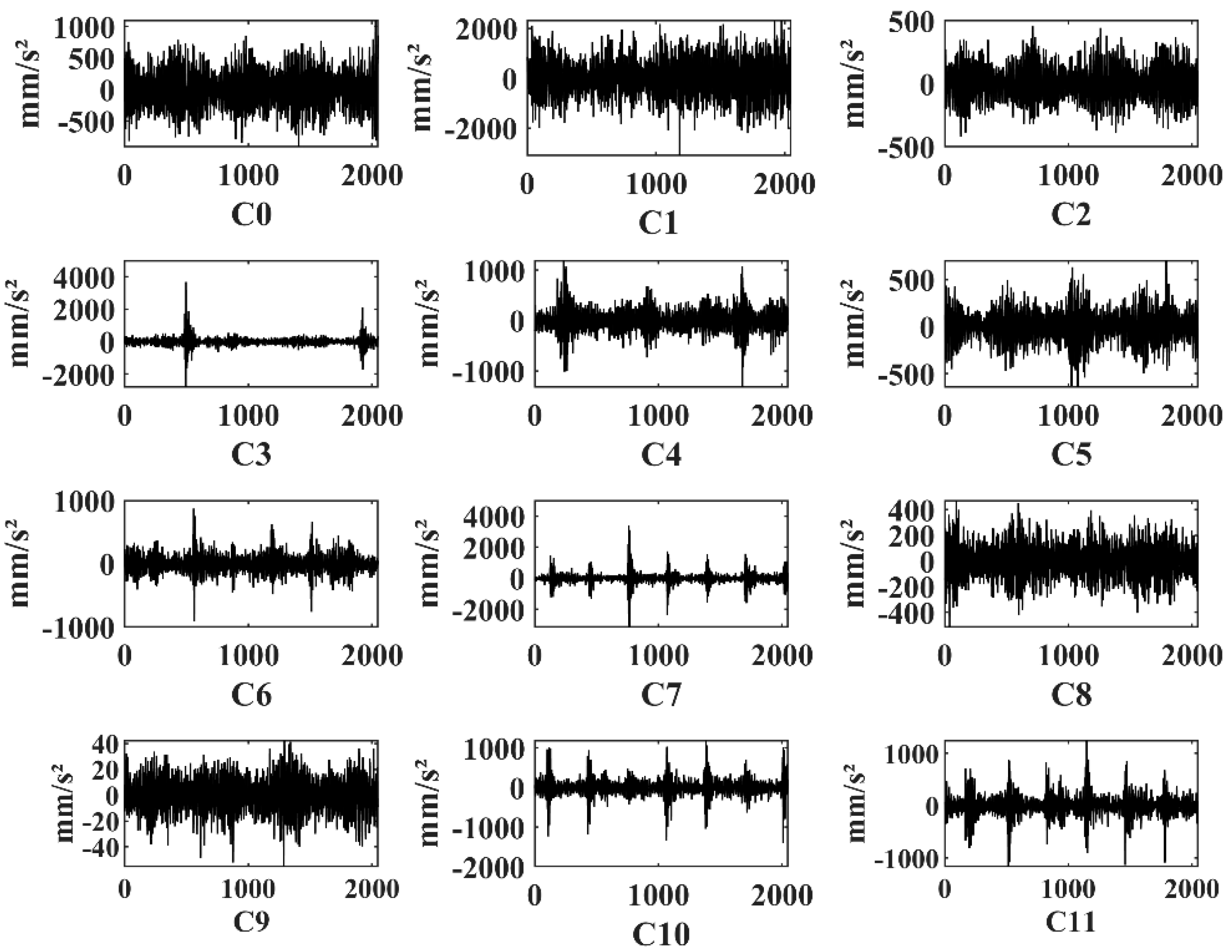
3.1. Description of the Dataset
3.2. Experimental Results and Analysis
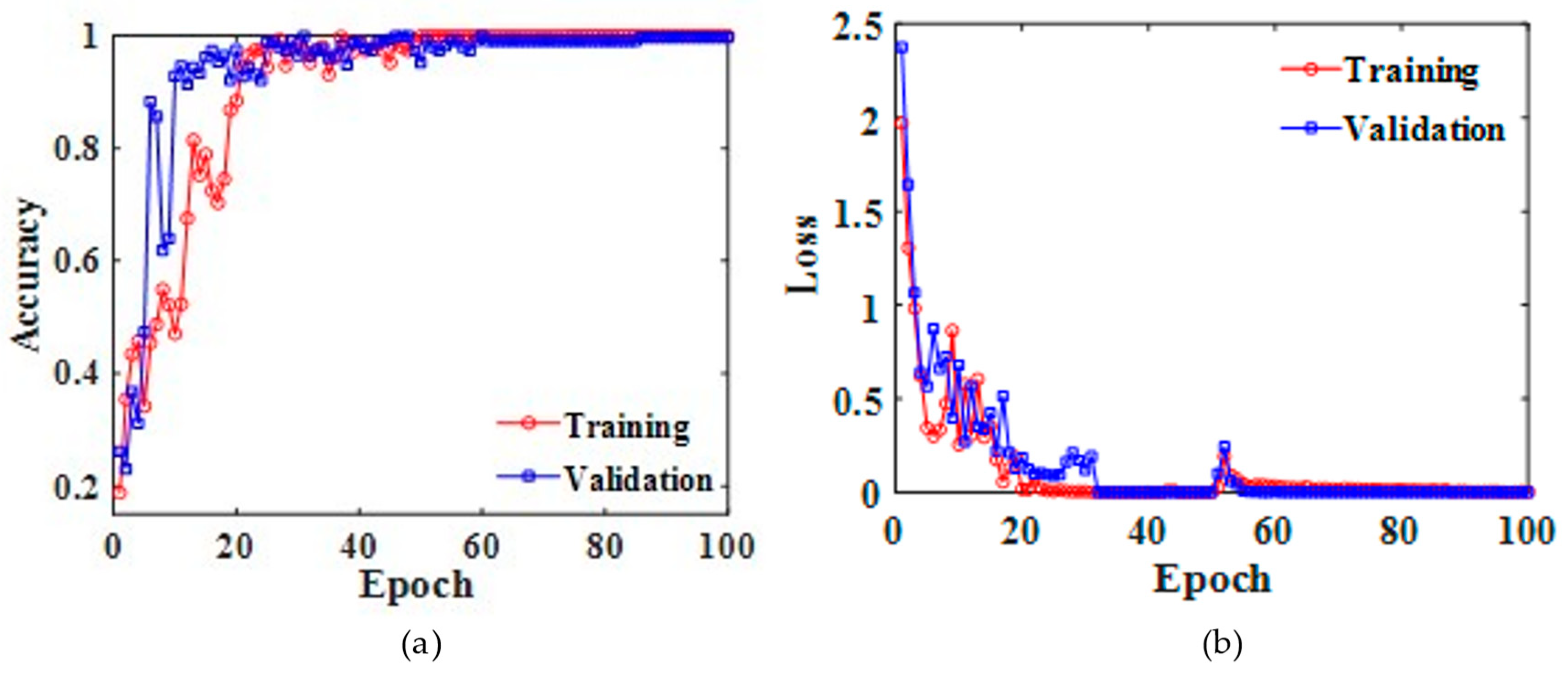
3.2.1. Parameter Settings and Training Process
3.2.2. Visualization Analysis of SE-Res Block
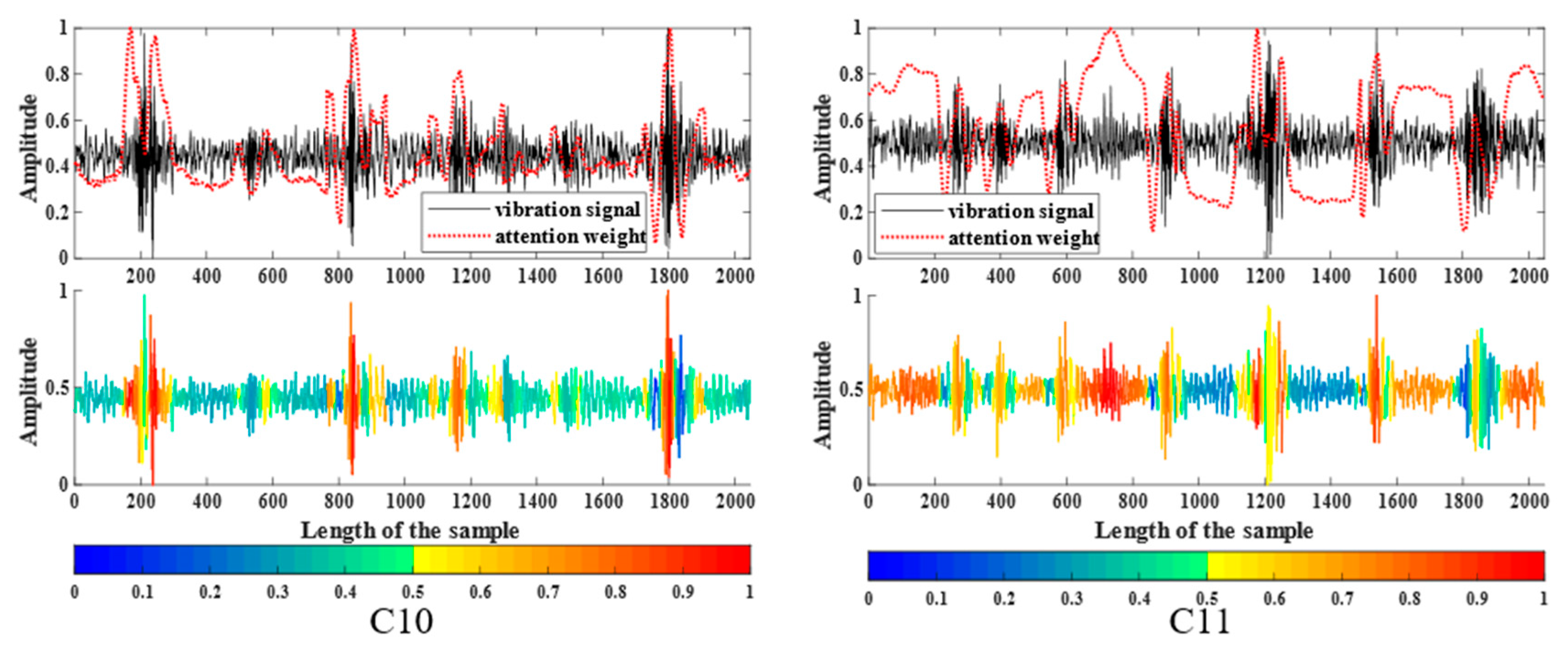
3.2.3. Attention Fusion Unit Visualization
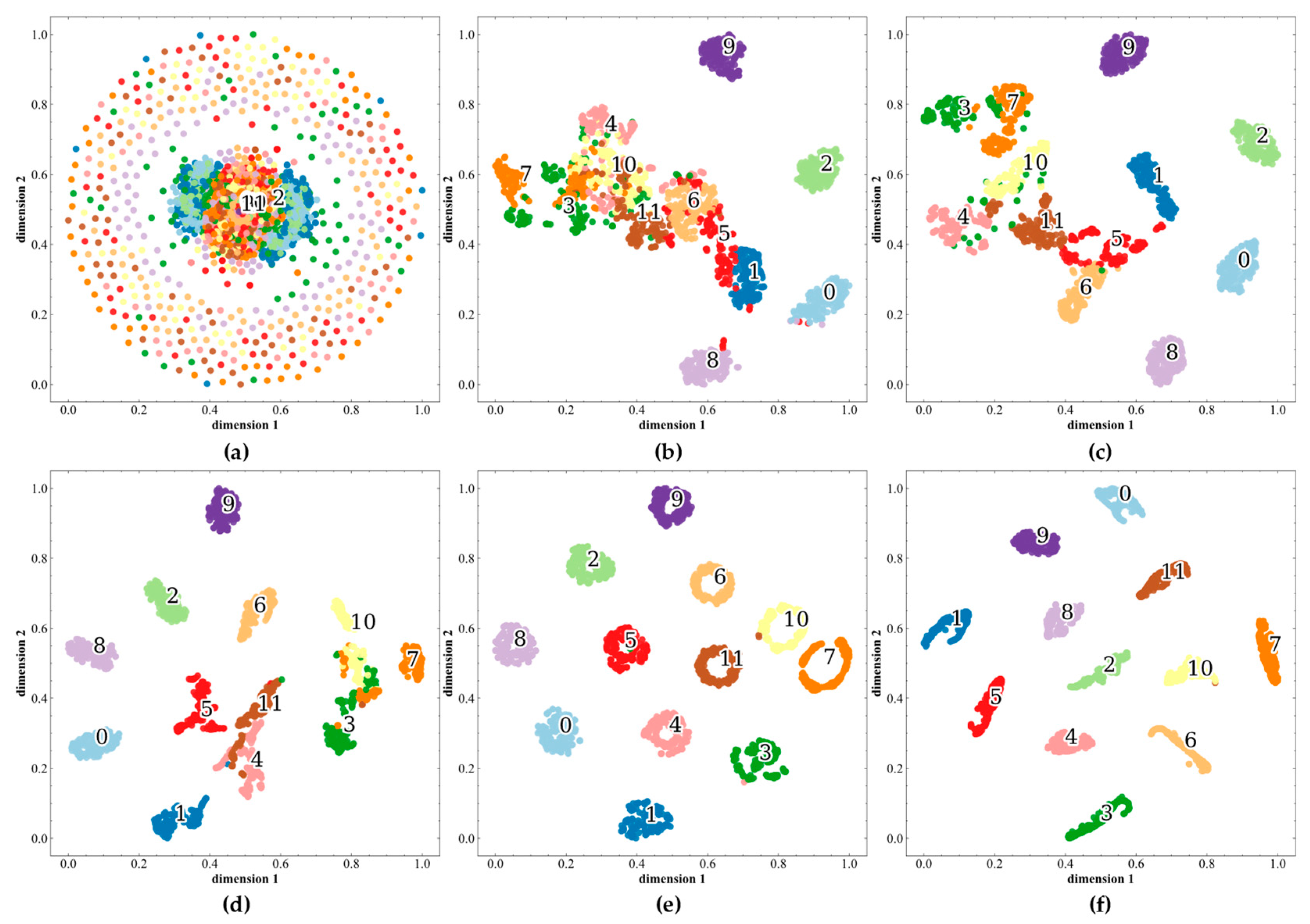
3.2.4. Network Middle Layer Visualization
3.3. Discussion
4. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Elbi, M.D.; Kizilkaya, A. Multicomponent signal analysis: Interwoven Fourier decomposition method. Digit. Signal Processing 2020, 104, 102771. [Google Scholar] [CrossRef]
- Cheng, J.; Yang, Y.; Shao, H.; Pan, H.; Zheng, J.; Cheng, J. Enhanced periodic mode decomposition and its application to composite fault diagnosis of rolling bearings. ISA Trans. 2022, 125, 474–491. [Google Scholar] [CrossRef] [PubMed]
- Zhou, W.; Feng, Z.; Xu, Y.F.; Wang, X.; Lv, H. Empirical Fourier Decomposition: An Accurate Adaptive Signal Decomposition Method. arXiv 2020, arXiv:2009.08047. [Google Scholar]
- Liu, Y.; Han, J.; Zhao, S.; Meng, Q.; Shi, T.; Ma, H. Study on the Dynamic Problems of Double-Disk Rotor System Supported by Deep Groove Ball Bearing. Shock. Vib. 2019, 2019, 8120569. [Google Scholar] [CrossRef]
- Luo, Z.; Wang, J.; Tang, R.; Wang, D. Research on vibration performance of the nonlinear combined support-flexible rotor system. Nonlinear Dyn. 2019, 98, 113–128. [Google Scholar] [CrossRef]
- Singh, P.; Joshi, S.D.; Patney, R.K.; Saha, K. The Fourier decomposition method for nonlinear and non-stationary time series analysis. Proc. R. Soc. A 2017, 473, 20160871. [Google Scholar] [CrossRef] [Green Version]
- Wang, B.; Lei, Y.; Li, N.; Yan, T. Deep separable convolutional network for remaining useful life prediction of machinery. Mech. Syst. Signal Processing 2019, 134, 106330. [Google Scholar] [CrossRef]
- Luo, J.; Huang, J.; Li, H. A Case study of conditional deep convolutional generative adversarial networks in machine fault diagnosis. J. Intell. Manuf. 2021, 32, 407–425. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, X.; Gao, L.; Chen, W.; Li, P. Ensemble deep contractive auto-encoders for intelligent fault diagnosis of machines under noisy environment. Knowl. -Based Syst. 2020, 196, 105764. [Google Scholar] [CrossRef]
- Xiang, S.; Qin, Y.; Zhu, C.; Wang, Y.; Chen, H. Long short-term memory neural network with weight amplification and its application into gear remaining useful life prediction. Eng. Appl. Artif. Intell. 2020, 91, 103587. [Google Scholar] [CrossRef]
- Jin, Y.; Qin, C.; Huang, Y.; Liu, C. Actual bearing compound fault diagnosis based on active learning and decoupling attentional residual network. Measurement 2021, 173, 108500. [Google Scholar] [CrossRef]
- Ma, P.; Zhang, H.; Fan, W.; Wang, C. A diagnosis framework based on domain adaptation for bearing fault diagnosis across diverse domains. ISA Trans. 2020, 99, 465–478. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Peng, G.; Xie, C.; Zhang, W.; Li, C.; Liu, S. ACDIN: Bridging the gap between artificial and real bearing damages for bearing fault diagnosis. Neurocomputing 2018, 294, 61–71. [Google Scholar] [CrossRef]
- Ma, S.; Chu, F.; Han, Q. Deep residual learning with demodulated time-frequency features for fault diagnosis of planetary gearbox under nonstationary running conditions. Mech. Syst. Signal Processing 2019, 127, 190–201. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X.; Ding, Q. Deep residual learning-based fault diagnosis method for rotating machinery. ISA Trans. 2019, 95, 295–305. [Google Scholar] [CrossRef]
- Zhao, M.; Zhong, S.; Fu, X.; Tang, B.; Dong, S.; Pecht, M. Deep Residual Networks With Adaptively Parametric Rectifier Linear Units for Fault Diagnosis. IEEE Trans. Ind. Electron. 2021, 68, 2587–2597. [Google Scholar] [CrossRef]
- Zhao, M.; Tang, B.; Deng, L.; Pecht, M. multiple wavelet regularized deep residual networks for fault diagnosis. Measurement 2020, 152, 107331. [Google Scholar] [CrossRef]
- He, M.; He, D. A new hybrid deep signal processing approach for bearing fault diagnosis using vibration signals. Neurocomputing 2020, 396, 542–555. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, S.; Wang, J.; Xin, Y.; An, Z.; Jiang, X. Enhanced sparse filtering with strong noise adaptability and its application on rotating machinery fault diagnosis. Neurocomputing 2020, 398, 31–44. [Google Scholar] [CrossRef]
- Zhang, D.; Chen, Y.; Guo, F.; Karimi, H.R.; Dong, H.; Xuan, Q. A New Interpretable Learning Method for Fault Diagnosis of Rolling Bearings. IEEE Trans. Instrum. Meas. 2021, 70, 3507010. [Google Scholar] [CrossRef]
- Wang, H.; Liu, C.; Jiang, D.; Jiang, Z. Collaborative deep learning framework for fault diagnosis in distributed complex systems. Mech. Syst. Signal Processing 2021, 156, 107650. [Google Scholar] [CrossRef]
- Grezmak, J.; Zhang, J.; Wang, P.; Loparo, K.A.; Gao, R.X. Interpretable Convolutional Neural Network Through Layer-wise Relevance Propagation for Machine Fault Diagnosis. IEEE Sensors J. 2020, 20, 3172–3181. [Google Scholar] [CrossRef]
- Chang, X.; Tang, B.; Tan, Q.; Deng, L.; Zhang, F. One-dimensional fully decoupled networks for fault diagnosis of planetary gearboxes. Mech. Syst. Signal Processing 2020, 141, 106482. [Google Scholar] [CrossRef]
- Abid, F.B.; Sallem, M.; Braham, A. Robust Interpretable Deep Learning for Intelligent Fault Diagnosis of Induction Motors. IEEE Trans. Instrum. Meas. 2020, 69, 3506–3515. [Google Scholar] [CrossRef]
- Liu, C.; Qin, C.; Shi, X.; Wang, Z.; Zhang, G.; Han, Y. TScatNet: An Interpretable Cross-Domain Intelligent Diagnosis Model with Antinoise and Few-Shot Learning Capability. IEEE Trans. Instrum. Meas. 2021, 70, 3506110. [Google Scholar] [CrossRef]
- Li, T.; Zhao, Z.; Sun, C.; Cheng, L.; Chen, X.; Yan, R.; Gao, R.X. WaveletKernelNet: An Interpretable Deep Neural Network for Industrial Intelligent Diagnosis. IEEE Trans. Syst. Man Cybern Syst. 2021, 52, 2302–2312. [Google Scholar] [CrossRef]
- Yin, J.; Yan, X. Stacked sparse autoencoders monitoring model based on fault-related variable selection. Soft Comput. 2021, 25, 3531–3543. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–7 December 2017. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Miao, M.; Liu, C.; Yu, J. Adaptive Densely Connected Convolutional Auto-Encoder-Based Feature Learning of Gearbox Vibration Signals. IEEE Trans. Instrum. Meas. 2021, 70, 3505511. [Google Scholar] [CrossRef]
- Plakias, S.; Boutalis, Y.S. Fault detection and identification of rolling element bearings with attentive dense CNN. Neurocomputing 2020, 405, 208–217. [Google Scholar] [CrossRef]
- Ye, Z.; Yu, J. AKRNet: A novel convolutional neural network with attentive kernel residual learning for feature learning of gearbox vibration signals. Neurocomputing 2021, 447, 23–37. [Google Scholar] [CrossRef]
- Xu, Z.; Li, C.; Yang, Y. Fault diagnosis of rolling bearings using an improved multi-scale convolutional neural network with feature attention mechanism. ISA Trans. 2021, 110, 379–393. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Xu, J.; Yan, R.; Sun, C.; Chen, X. Intelligent Bearing Fault Diagnosis Using Multi-Head Attention-Based CNN. Procedia Manufacturing 2020, 49, 112–118. [Google Scholar] [CrossRef]
- Fang, H.; Deng, J.; Zhao, B.; Shi, Y.; Zhou, J.; Shao, S. LEFE-Net: A Lightweight Efficient Feature Extraction Network With Strong Robustness for Bearing Fault Diagnosis. IEEE Trans. Instrum. Meas. 2021, 70, 3513311. [Google Scholar] [CrossRef]
- Yang, Z.; Zhang, J.; Zhao, Z.; Zhai, Z.; Chen, X. Interpreting network knowledge with attention mechanism for bearing fault diagnosis. Appl. Soft Comput. 2020, 97, 106829. [Google Scholar] [CrossRef]
- Li, X.; Zhang, W.; Ding, Q. Understanding and improving deep learning-based rolling bearing fault diagnosis with attention mechanism. Signal Processing 2019, 161, 136–154. [Google Scholar] [CrossRef]
- Decherchi, S.; Parodi, M.; Ridella, S. Learning the mean: A neural network approach. Neurocomputing 2012, 77, 129–143. [Google Scholar] [CrossRef]
- Lin, H.-C.; Ye, Y.-C. Reviews of bearing vibration measurement using fast fourier transform and enhanced fast fourier transform algorithms. Adv. Mech. Eng. 2019, 11, 168781401881675. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Guo, M.-H.; Liu, Z.-N.; Mu, T.-J.; Hu, S.-M. Beyond Self-Attention: External Attention Using Two Linear Layers for Visual Tasks. arXiv 2021, arXiv:2105.02358. [Google Scholar]
- Zhao, Z.; Li, T.; Wu, J.; Sun, C.; Wang, S.; Yan, R.; Chen, X. Deep learning algorithms for rotating machinery intelligent diagnosis: An open source benchmark study. ISA Trans. 2020, 107, 224–255. [Google Scholar] [CrossRef] [PubMed]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Ring Gear Teeth (Nr) | Planetary Gear Teeth (Np) | Sun Gear Teeth (Ns) | Planet Gears | Type of Planetary Gear Box |
|---|---|---|---|---|---|
| numbers | 72 | 27 | 18 | 3 | single |
| Pattern Label | Gearbox | Rotating Speed (Hz) + Load (A) | Length of Samples | Training Ratio |
|---|---|---|---|---|
| C0 | Normal | 40 + 1/30 + 0.5/20 + 0.3 | 1024/2048/4096 | 30% |
| C1 | Gear pitting | 40 + 1/30 + 0.5/20 + 0.3 | 1024/2048/4096 | 30% |
| C2 | Gear crack | 40 + 1/30 + 0.5/20 + 0.3 | 1024/2048/4096 | 30% |
| C3 | Gear wear (level 1) | 40 + 1/30 + 0.5/20 + 0.3 | 1024/2048/4096 | 30% |
| C4 | Gear wear (level 2) | 40 + 1/30 + 0.5/20 + 0.3 | 1024/2048/4096 | 30% |
| C5 | Gear wear (level 3) | 40 + 1/30 + 0.5/20 + 0.3 | 1024/2048/4096 | 30% |
| C6 | Sun gear broken teeth (level 1) | 40 + 1/30 + 0.5/20 + 0.3 | 1024/2048/4096 | 30% |
| C7 | Sun gear broken teeth (level 2) | 40 + 1/30 + 0.5/20 + 0.3 | 1024/2048/4096 | 30% |
| C8 | Inner race defect | 40 + 1/30 + 0.5/20 + 0.3 | 1024/2048/4096 | 30% |
| C9 | Outer race defect | 40 + 1/30 + 0.5/20 + 0.3 | 1024/2048/4096 | 30% |
| C10 | Sun gear wear + C1 | 40 + 1/30 + 0.5/20 + 0.3 | 1024/2048/4096 | 30% |
| C11 | Sun gear wear + C4 | 40 + 1/30 + 0.5/20 + 0.3 | 1024/2048/4096 | 30% |
| Structure | Parameters | Outputs Size |
|---|---|---|
| Input | vibration signal | [1024 × 1]/[2048 × 1]/[4096 × 1] |
| Convolution block 1 | F = 128; KS = 5; S = 1; DR = 0.5; r = 4 | [128@1024 × 1]/[128@2048 × 1]/[128@4096 × 1] |
| Max-Pooling | Pool size = 2 | [128@512 × 1]/[128@1024 × 1]/[128@2048 × 1] |
| Convolution block 2 | F = 256; KS = 11; S = 1; DR = 0.5; r = 4 | [256@512 × 1]/[256@1024 × 1]/[256@2048 × 1] |
| Max-Pooling | Pool size = 2 | [256@256 × 1]/[256@512 × 1]/[256@1024 × 1] |
| Convolution block 2 | F = 512; KS = 11; S = 1; DR = 0.5; r = 4 | [512@256 × 1]/ [512@512 × 1]/[512@1024 × 1] |
| Attention fusion unit | SR = 0.5; GS = 64 | [256@256 × 1]/[256@512 × 1]/[256@1024 × 1] |
| FC (linear Projection) | Hidden Nodes = 32; activation = Sigmoid | [32@256 × 1]/[32@512 × 1]/[32@1024 × 1] |
| Flatten | None | 8192/16384/24576 |
| FC | Hidden Nodes = 12; activation = Softmax | [12 × 1] |
| hyper-parameters | Loss: cross entropy loss; Batch size = 16; Validation ratio = 0.1; Optimizer: Adam; Learning rate = 0.0003 | |
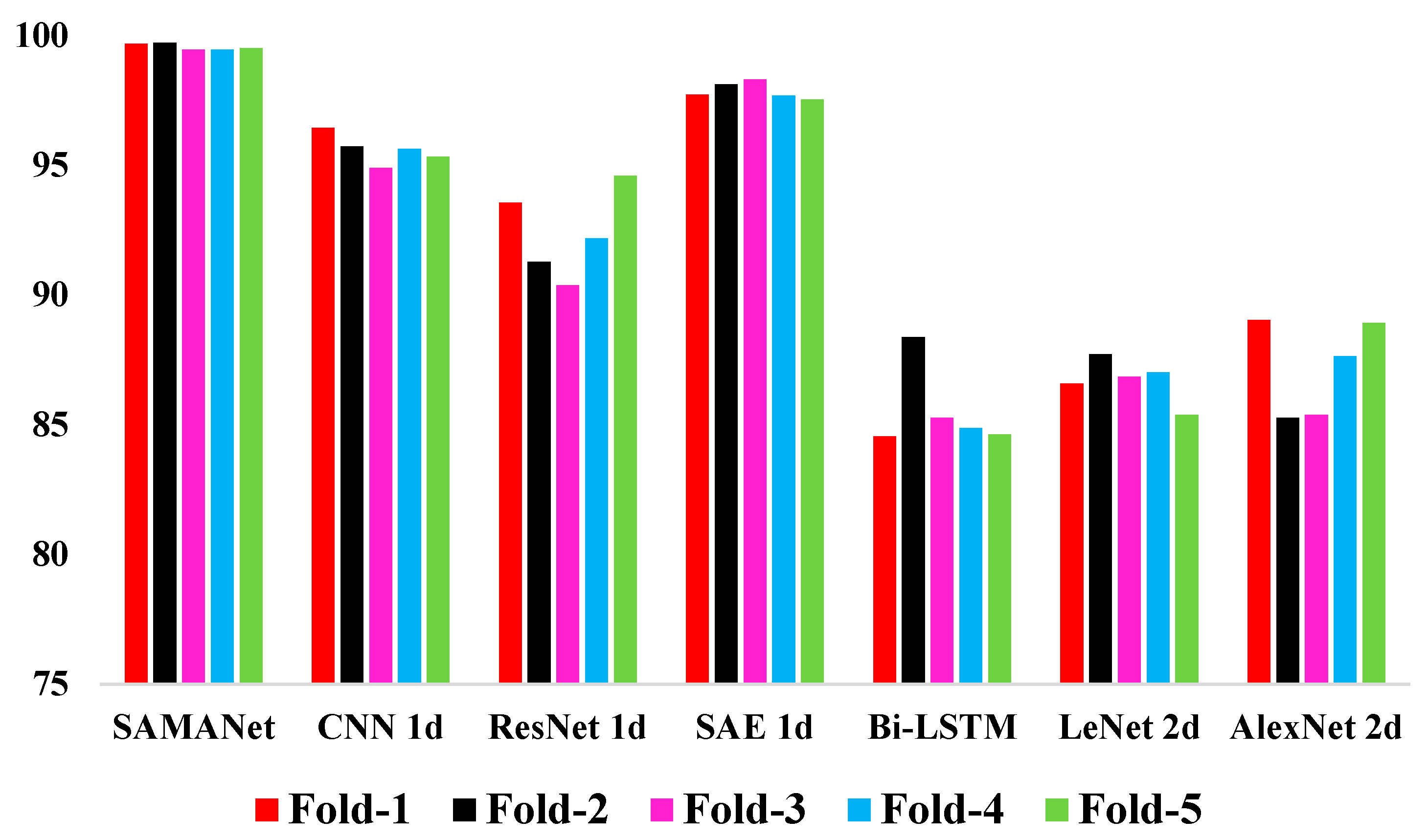
| SRMANet | CNN 1d | ResNet 1d | SAE 1d | Bi-LSTM | Lenet 2d | Alexnet 2d | |
|---|---|---|---|---|---|---|---|
| C0 | 99.98 | 97.53 | 94.76 | 98.71 | 79.93 | 81.37 | 90.42 |
| C1 | 99.70 | 98.41 | 96.13 | 99.93 | 84.71 | 84.72 | 90.75 |
| C2 | 99.03 | 97.16 | 95.28 | 98.32 | 91.77 | 94.37 | 88.71 |
| C3 | 99.64 | 94.32 | 93.26 | 96.52 | 92.19 | 87.50 | 84.37 |
| C4 | 99.50 | 95.01 | 92.50 | 94.37 | 82.73 | 92.71 | 89.22 |
| C5 | 99.49 | 96.71 | 91.59 | 95.92 | 82.37 | 85.37 | 80.07 |
| C6 | 100.00 | 96.47 | 97.12 | 97.87 | 78.56 | 82.54 | 83.94 |
| C7 | 99.90 | 94.73 | 94.93 | 98.12 | 74.37 | 93.78 | 94.36 |
| C8 | 99.70 | 95.32 | 93.42 | 98.37 | 88.70 | 78.54 | 92.51 |
| C9 | 99.67 | 96.50 | 89.71 | 99.24 | 78.92 | 77.32 | 85.63 |
| C10 | 99.46 | 96.31 | 91.73 | 97.52 | 89.75 | 88.64 | 93.65 |
| C11 | 100.00 | 98.72 | 92.14 | 99.80 | 90.42 | 92.21 | 94.77 |
| Average | 99.67 | 96.43 | 93.55 | 97.72 | 84.54 | 86.59 | 89.03 |
| Rotating Speed (Hz) + Load (A) | Sample Length 1024 | Sample Length 2048 | Sample Length 4096 |
|---|---|---|---|
| 40 Hz + 1 A | 98.92 ± 0.42 | 99.67 ± 0.07 | 99.92 ± 0.01 |
| 30 Hz + 0.5 A | 99.14 ± 0.24 | 99.84 ± 0.11 | 99.91 ± 0.03 |
| 20 Hz + 0.3 A | 98.64 ± 0.17 | 99.86 ± 0.02 | 99.95 ± 0.01 |
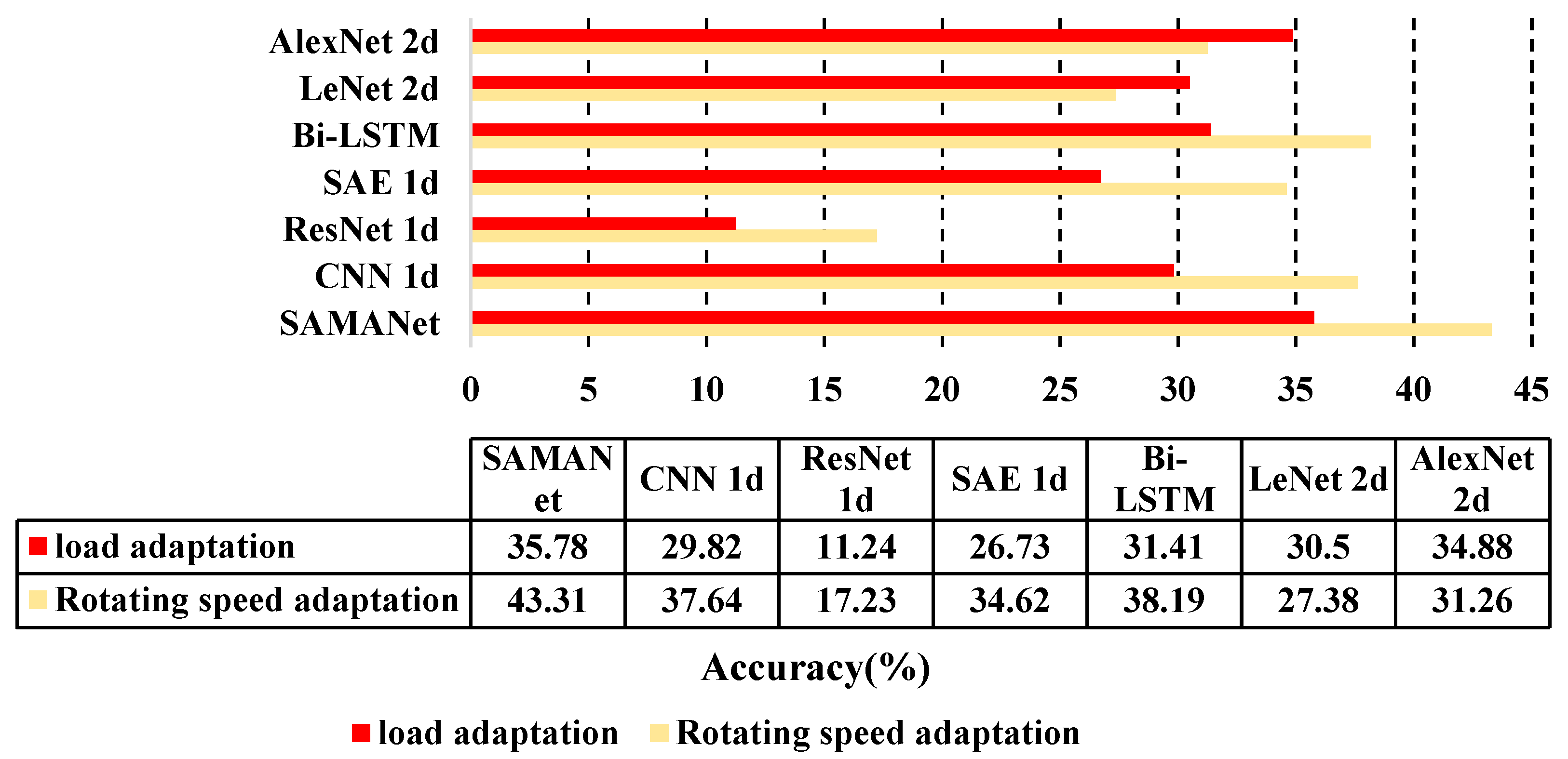
| Length/Rotating Speed | 1 A→0.5 A | 1 A→0.3 A | 0.5 A→0.3 A | 0.3 A→0.5 A | 0.3 A→1 A | 0.5 A→1 A | Average |
|---|---|---|---|---|---|---|---|
| 1024/30 Hz | 44.71 | 37.63 | 34.26 | 32.61 | 29.71 | 27.24 | 34.36 |
| 2048/30 Hz | 46.27 | 39.92 | 34.18 | 34.50 | 31.24 | 25.32 | 35.24 |
| 4096/30 Hz | 49.10 | 40.33 | 38.77 | 36.67 | 32.22 | 29.36 | 37.74 |
| Average | 46.69 | 39.29 | 35.74 | 34.59 | 31.06 | 27.31 | 35.78 |
| Length/Load | 40 Hz→30 Hz | 40 Hz→20 Hz | 30 Hz→20 Hz | 20 Hz→30 Hz | 20 Hz→40 Hz | 30 Hz→40 Hz | Average |
|---|---|---|---|---|---|---|---|
| 1024/1 A | 41.37 | 39.28 | 46.36 | 38.14 | 33.44 | 36.10 | 39.12 |
| 2048/1 A | 48.93 | 44.88 | 51.21 | 39.62 | 43.27 | 39.19 | 44.52 |
| 4096/1 A | 54.31 | 49.37 | 42.53 | 43.20 | 45.12 | 43.18 | 46.29 |
| Average | 48.20 | 44.51 | 46.70 | 40.32 | 40.61 | 39.49 | 43.31 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Huang, J.; Ma, J.; Luo, J. SRMANet: Toward an Interpretable Neural Network with Multi-Attention Mechanism for Gearbox Fault Diagnosis. Appl. Sci. 2022, 12, 8388. https://doi.org/10.3390/app12168388
Liu S, Huang J, Ma J, Luo J. SRMANet: Toward an Interpretable Neural Network with Multi-Attention Mechanism for Gearbox Fault Diagnosis. Applied Sciences. 2022; 12(16):8388. https://doi.org/10.3390/app12168388
Chicago/Turabian StyleLiu, Siyuan, Jinying Huang, Jiancheng Ma, and Jia Luo. 2022. "SRMANet: Toward an Interpretable Neural Network with Multi-Attention Mechanism for Gearbox Fault Diagnosis" Applied Sciences 12, no. 16: 8388. https://doi.org/10.3390/app12168388