
Research on Side-Channel Analysis Based on Deep Learning with Different Sample Data

Abstract
:1. Introduction
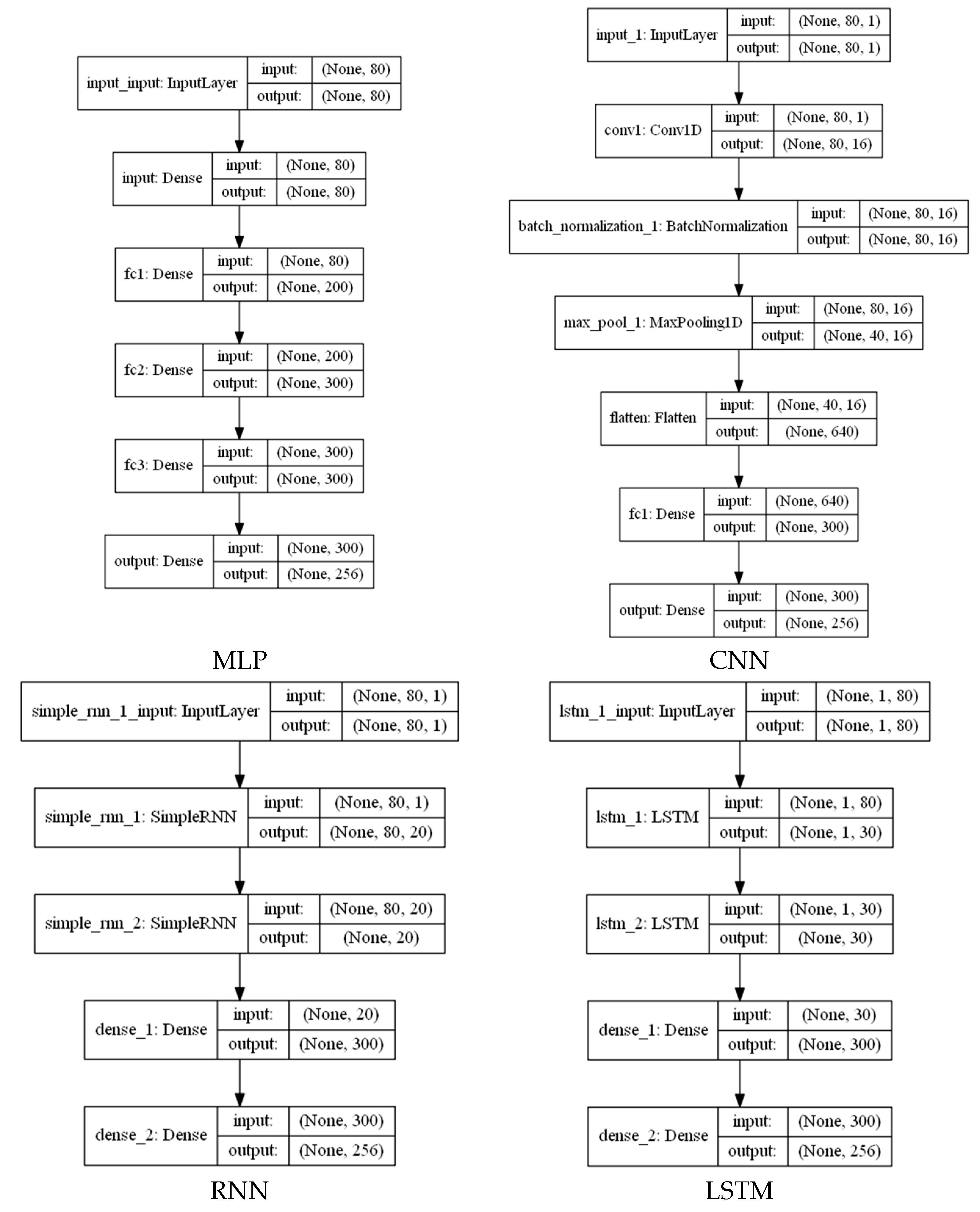
2. Four Deep Learning Models
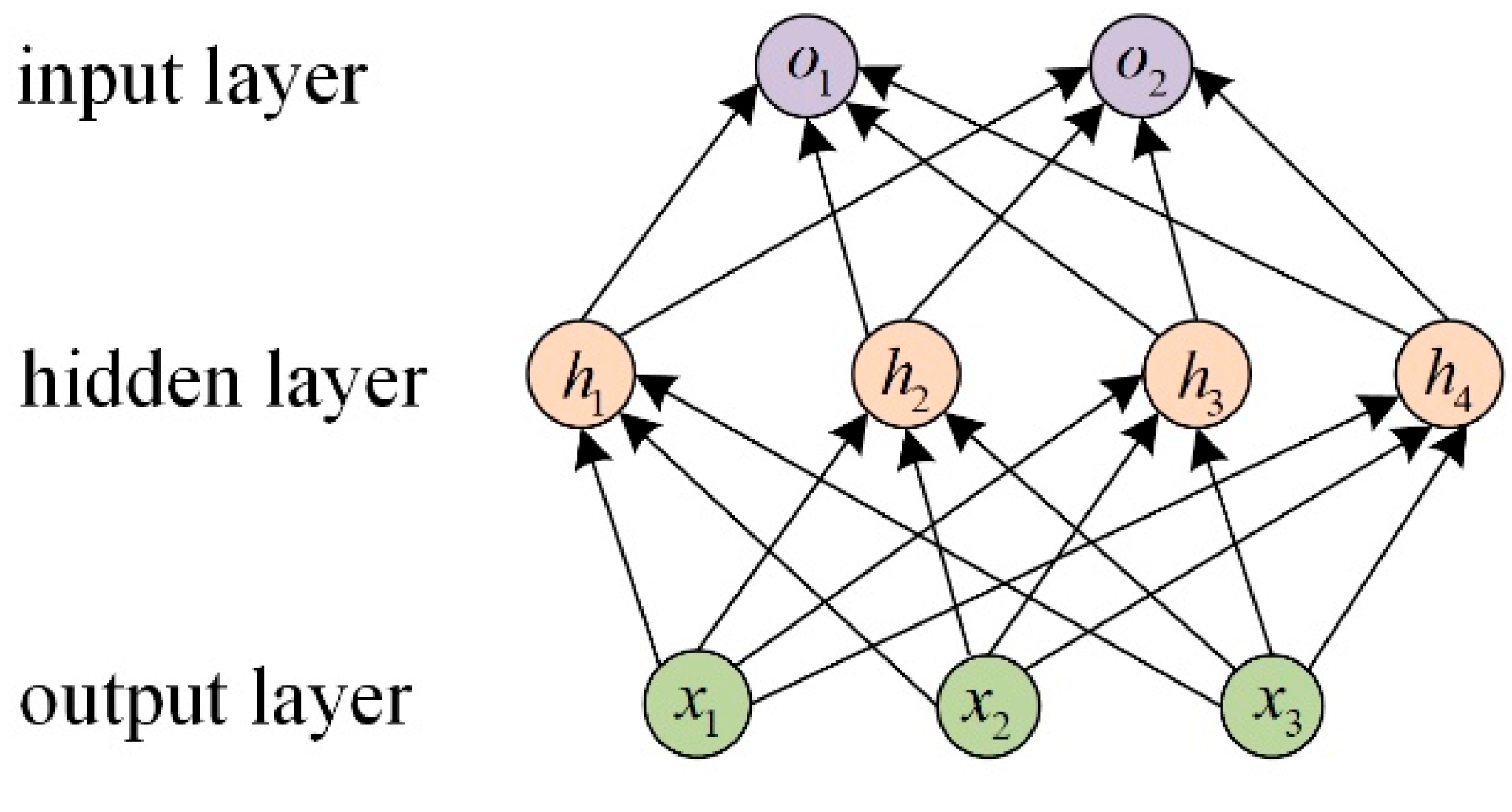
2.1. Multilayer Perceptron
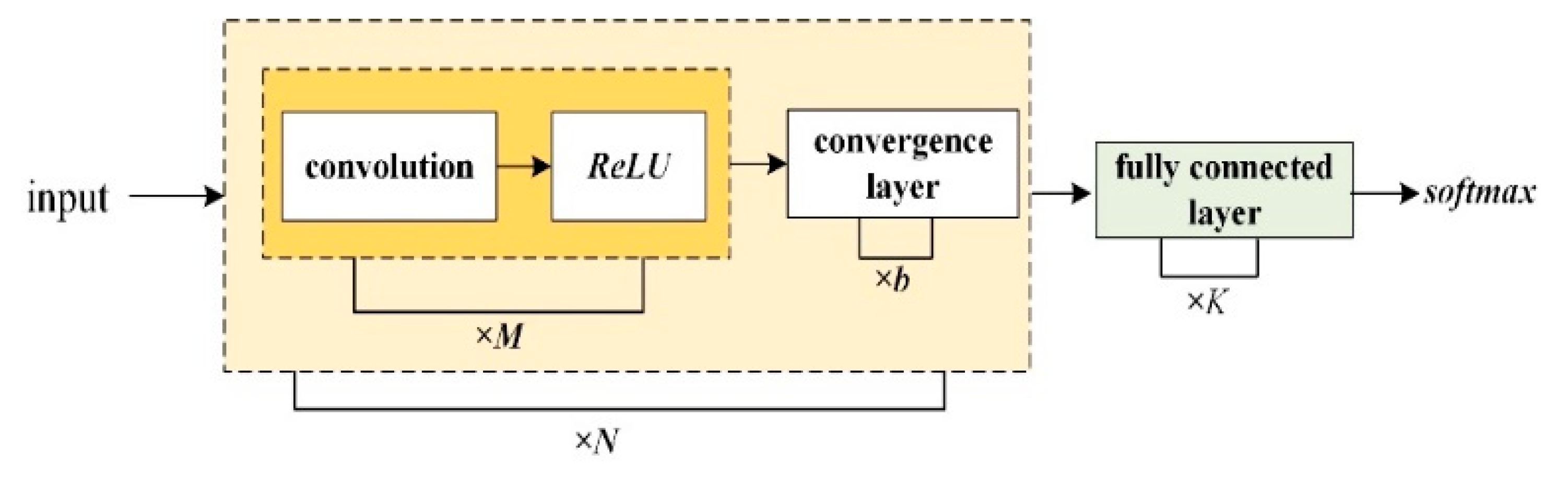
2.2. Convolutional Neural Network
2.2.1. Softmax Function
2.2.2. Softmax Regression
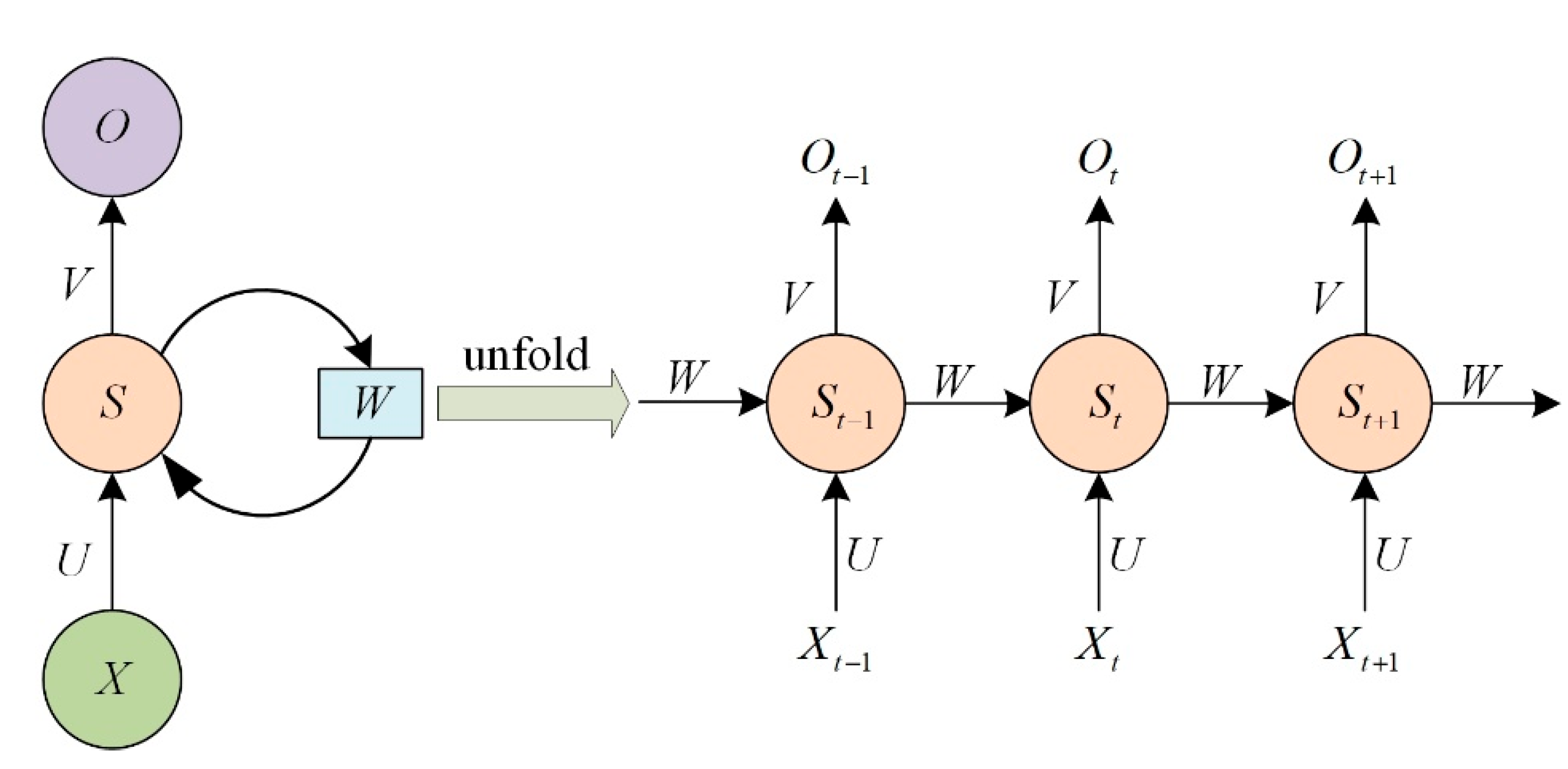
2.3. Recurrent Neural Network
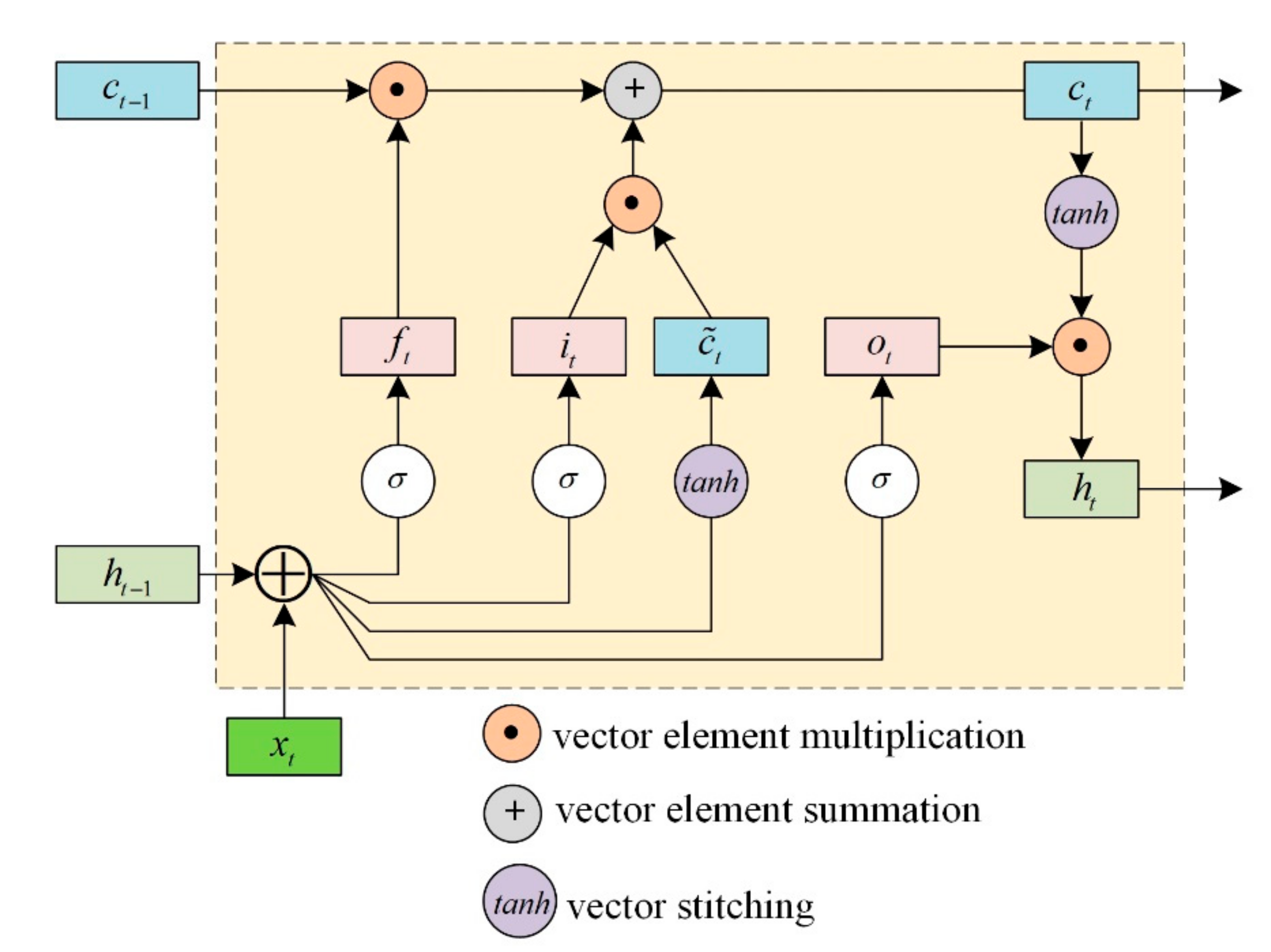
2.4. Long Short-Term Memory Network
3. AES-128 Algorithm
| Algorithm 1: Preudocode of the AES-128 algorithm |
| //AES-128 Cipher //in: 128 bits (plaintext) //out: 128 bits (ciphertext) //Nr: number of rounds, Nr = 10 //Nb: number of columns in state, Nb = 4 //w: expanded key K, Nb * (Nr + 1) = 44 words, (1 word = Nb bytes) state = in; AddRoundKey (state, w [0, Nb − 1]); for round = 1 step 1 to Nr − 1 do SubBytes (state); // Attack Point, at round 1. ShiftRows (state); MixColumns (state); AddRoundKey (state, w [round * Nb, (round + 1) * Nb − 1]); end for SubBytes (state); ShiftRows (state); AddRoundKey (state, w [Nr * Nb, (Nr + 1) * Nb − 1]); out = state; |
4. CPA Side-Channel Analysis Based on Deep Learning
4.1. CPA-Related Principles
| Algorithm 2: Randomly select plaintext and collect a power trace; each power trace has M sampling points |
| For byte = 1:16 For k = 0:255 H = HammingWeight(Sbox(Pbyte⊕k)) // Pbyte: The byte-th byte of each Pn For m = 1:M V = vm // vm: The m-th sampling point of each power trace v Corr (k) = r(V,H) rightkeybyte = find(max{Corr}) |
4.2. CPA Experimental Environment Configuration
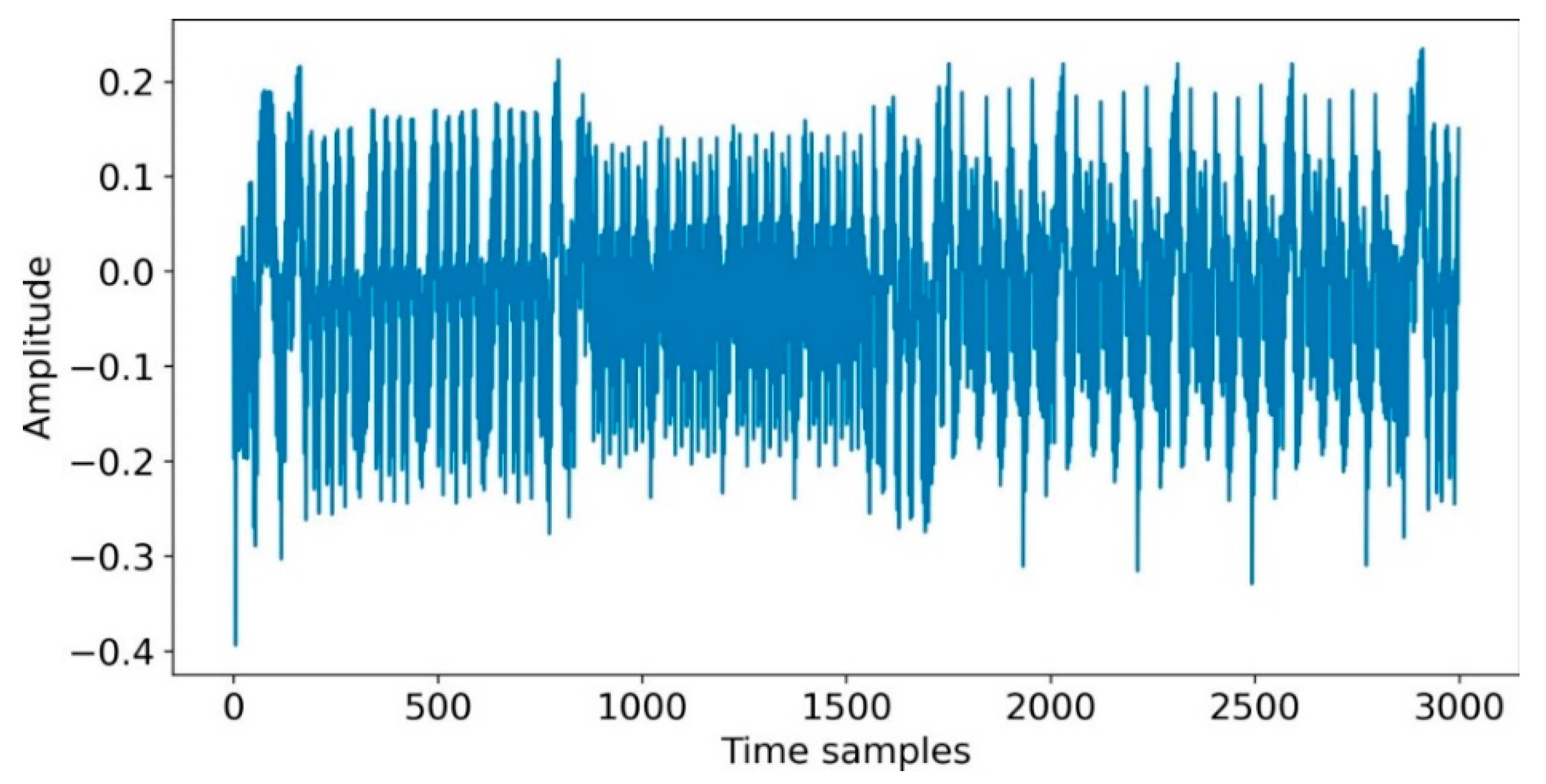
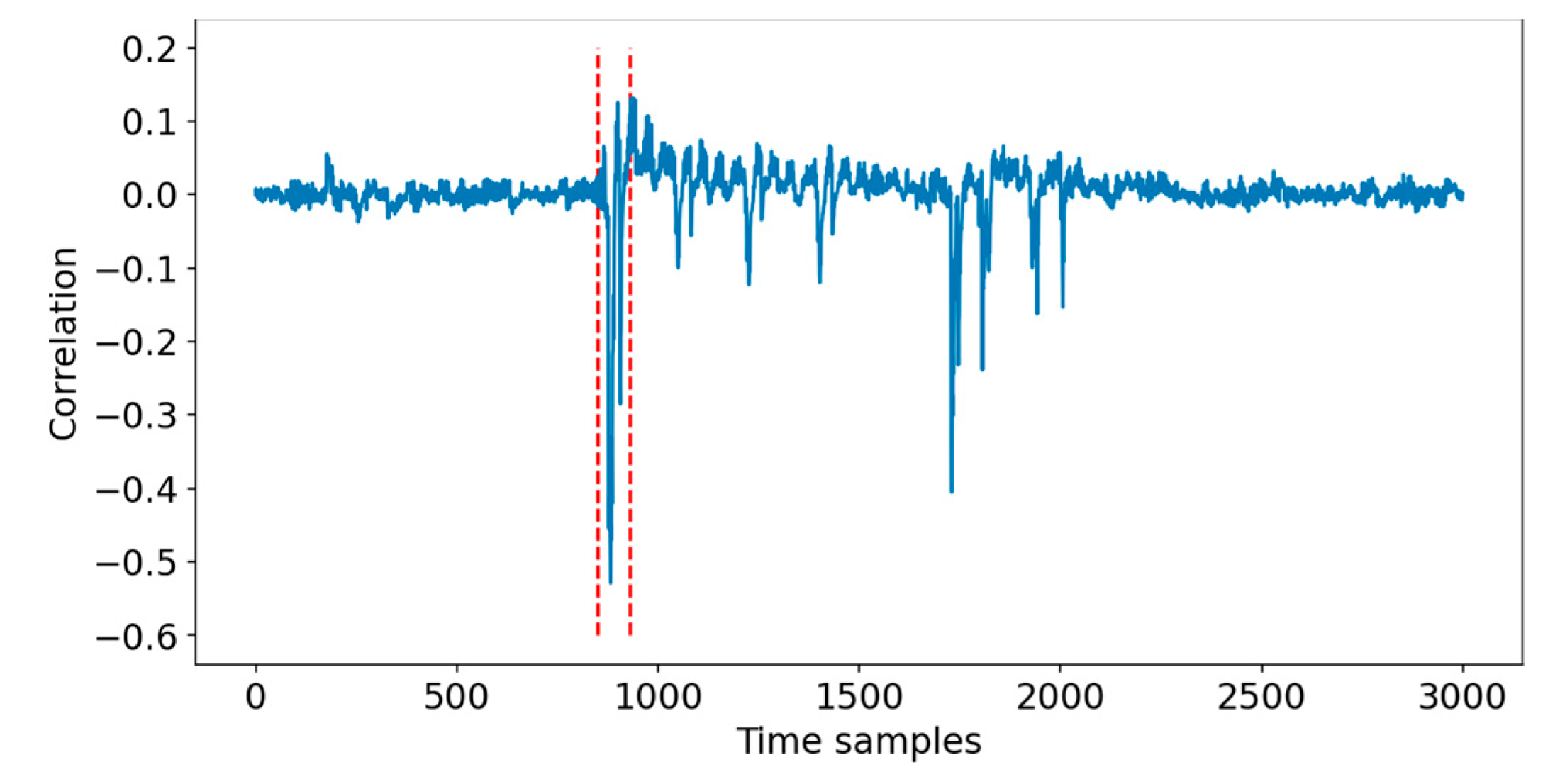
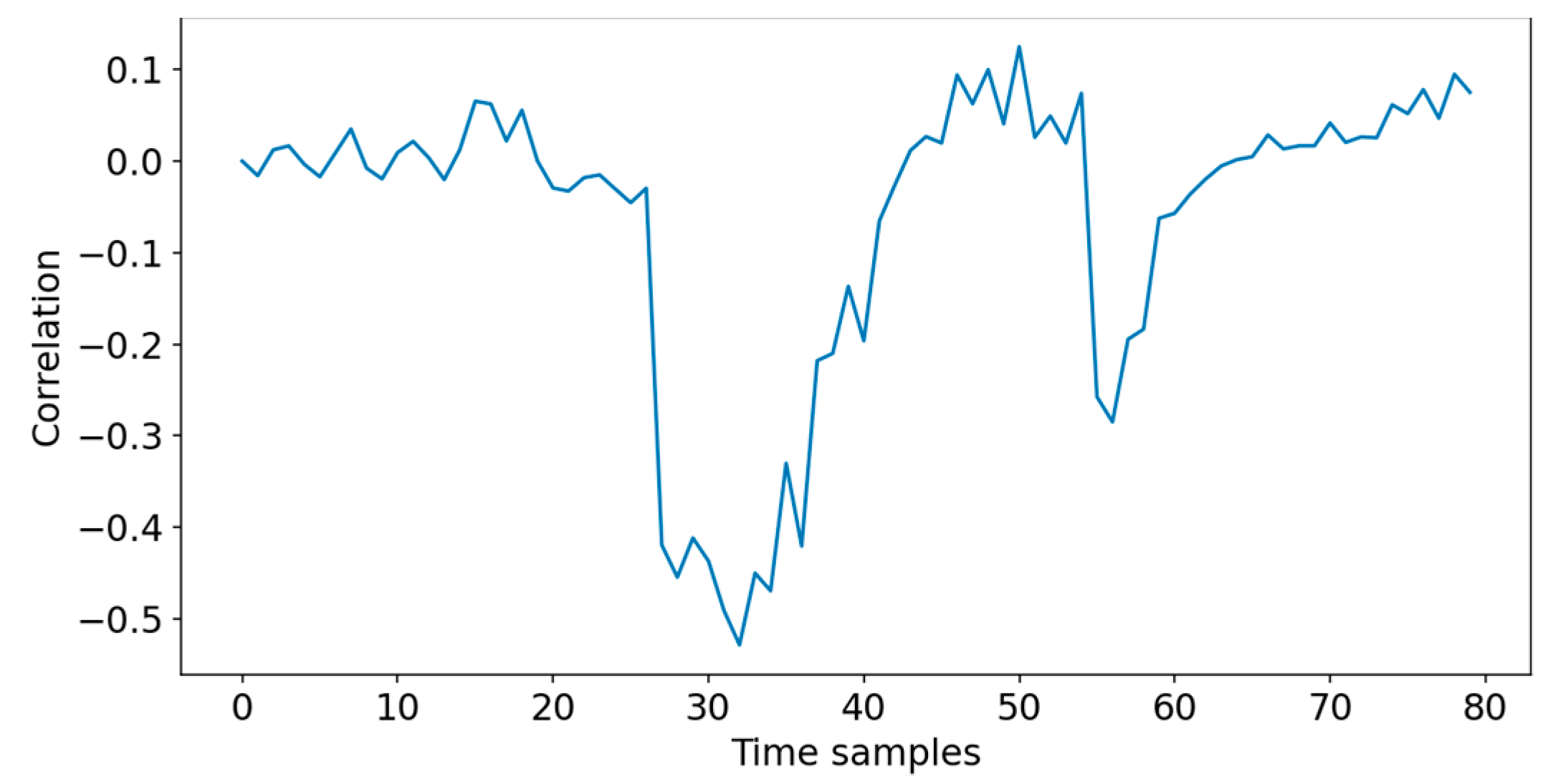
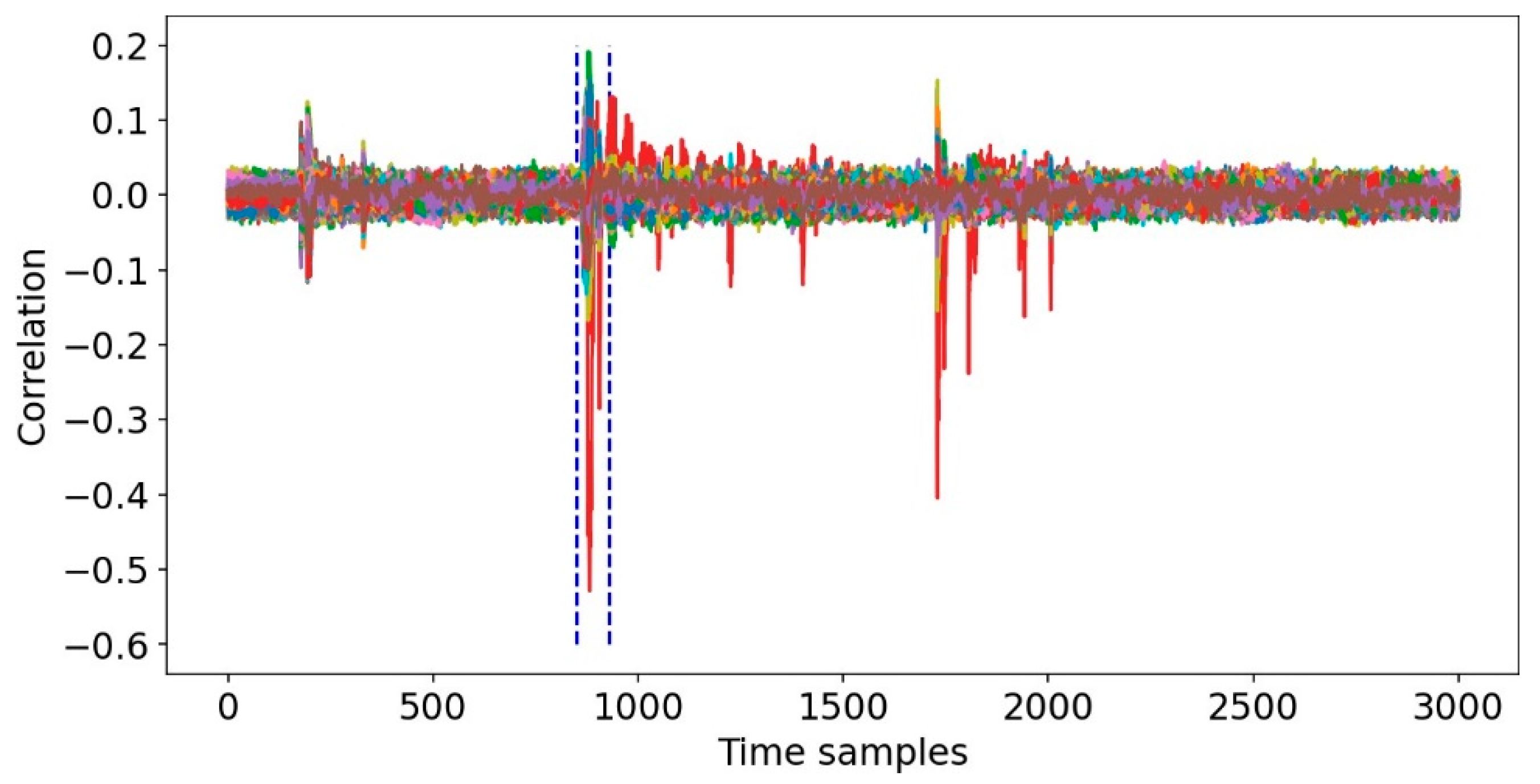
4.3. CPA Experimental Analysis Process
5. Experiment and Model Evaluation
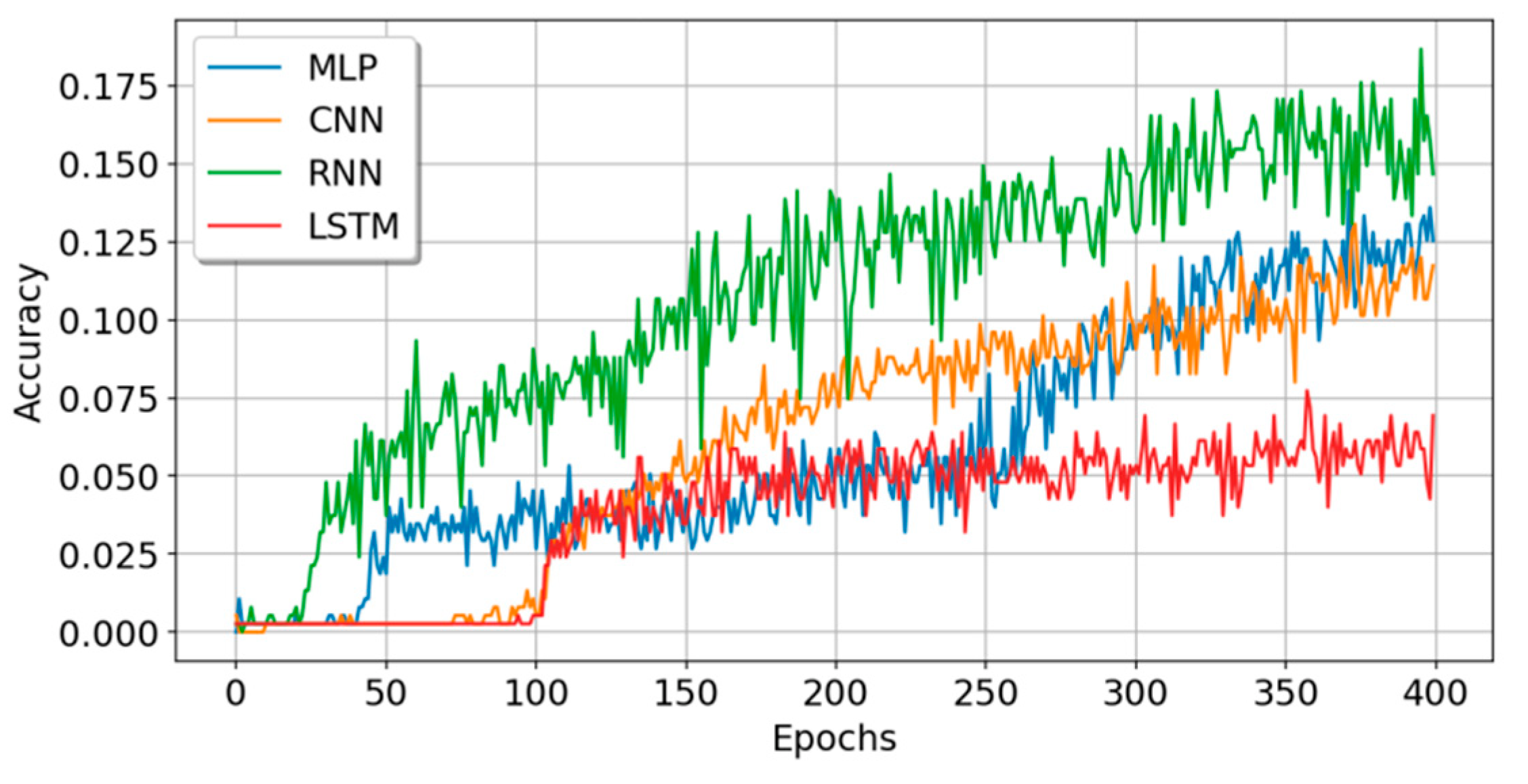
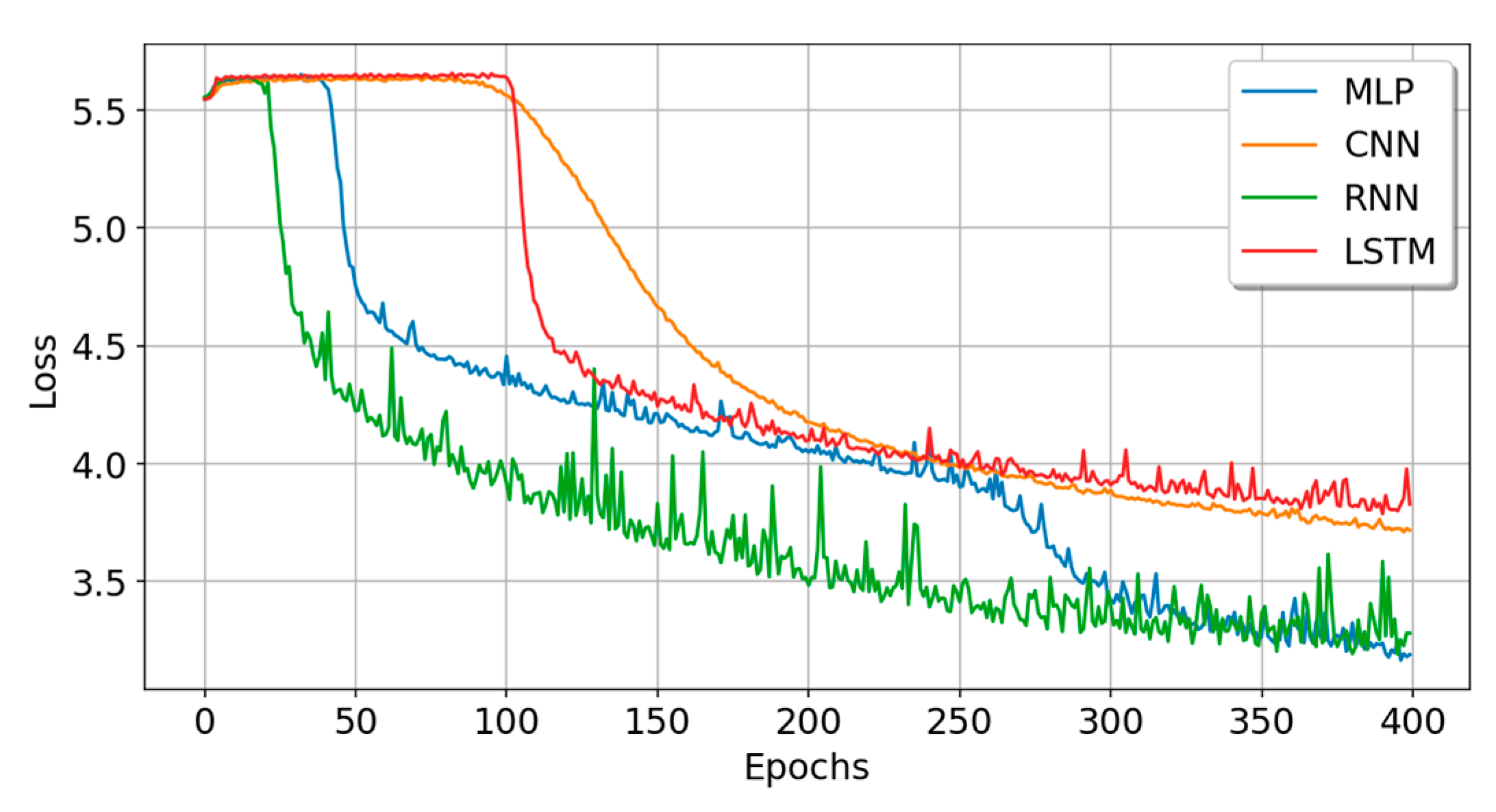
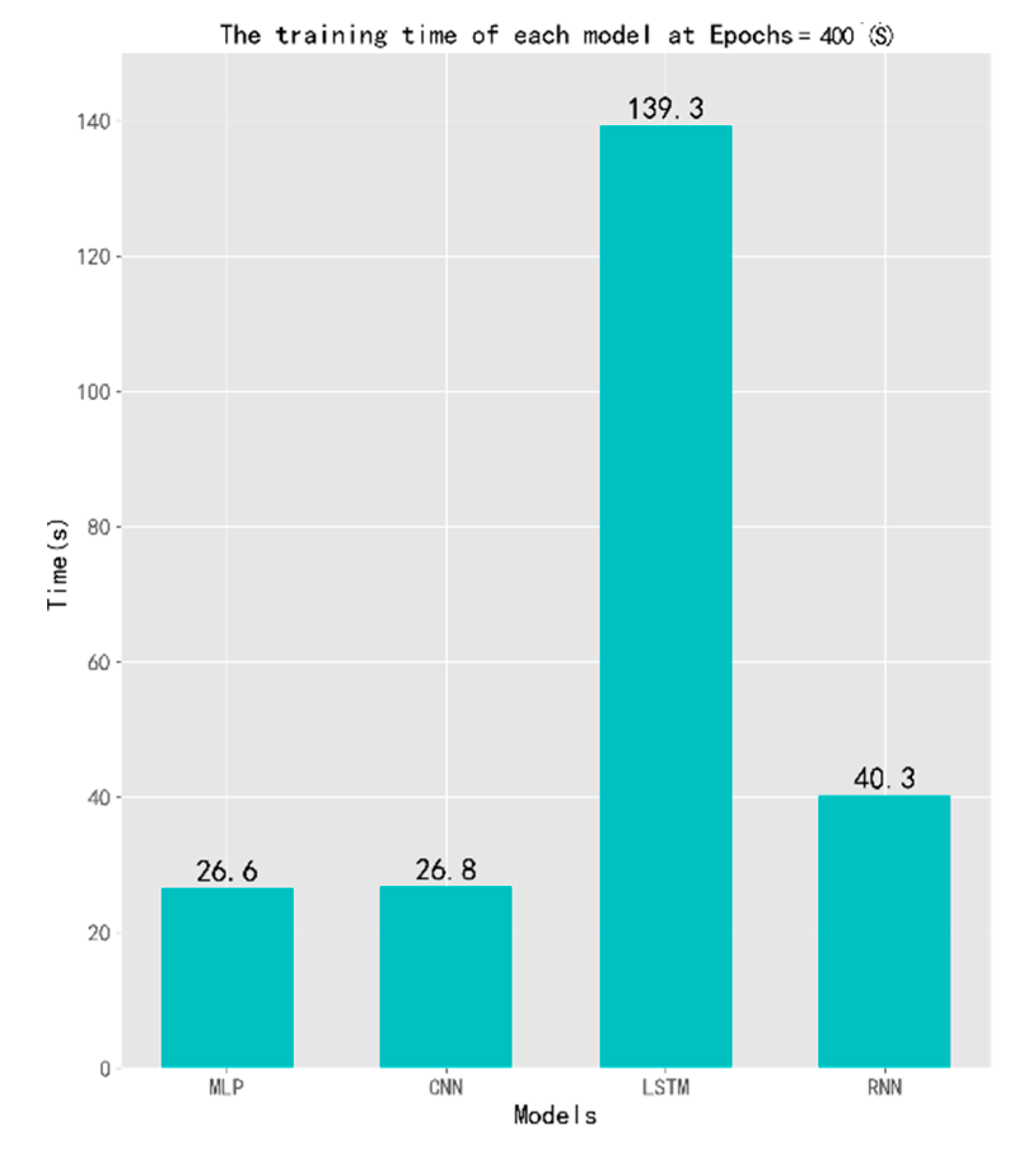
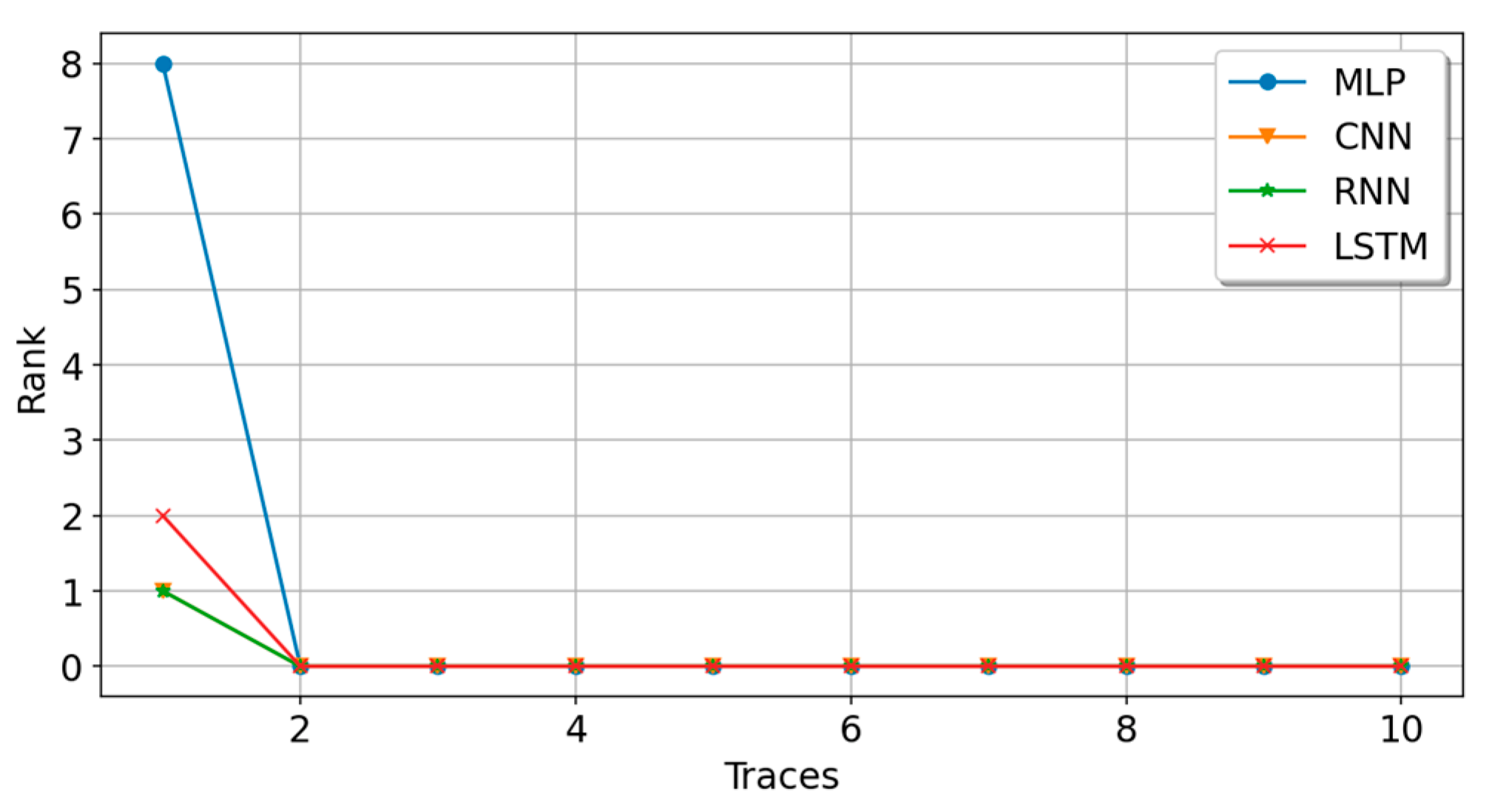
5.1. Experiment A: Small Sample Data Experiment
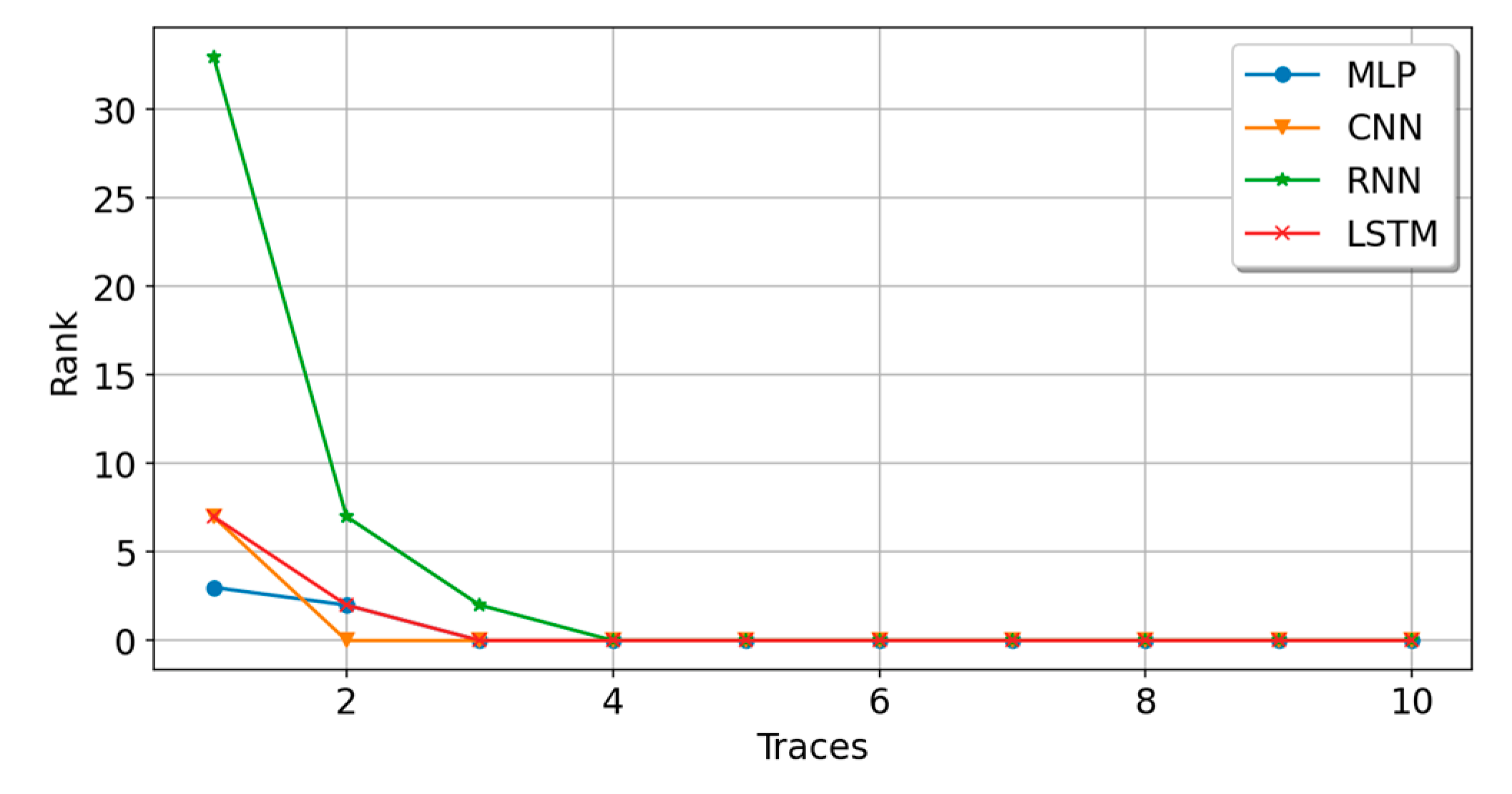
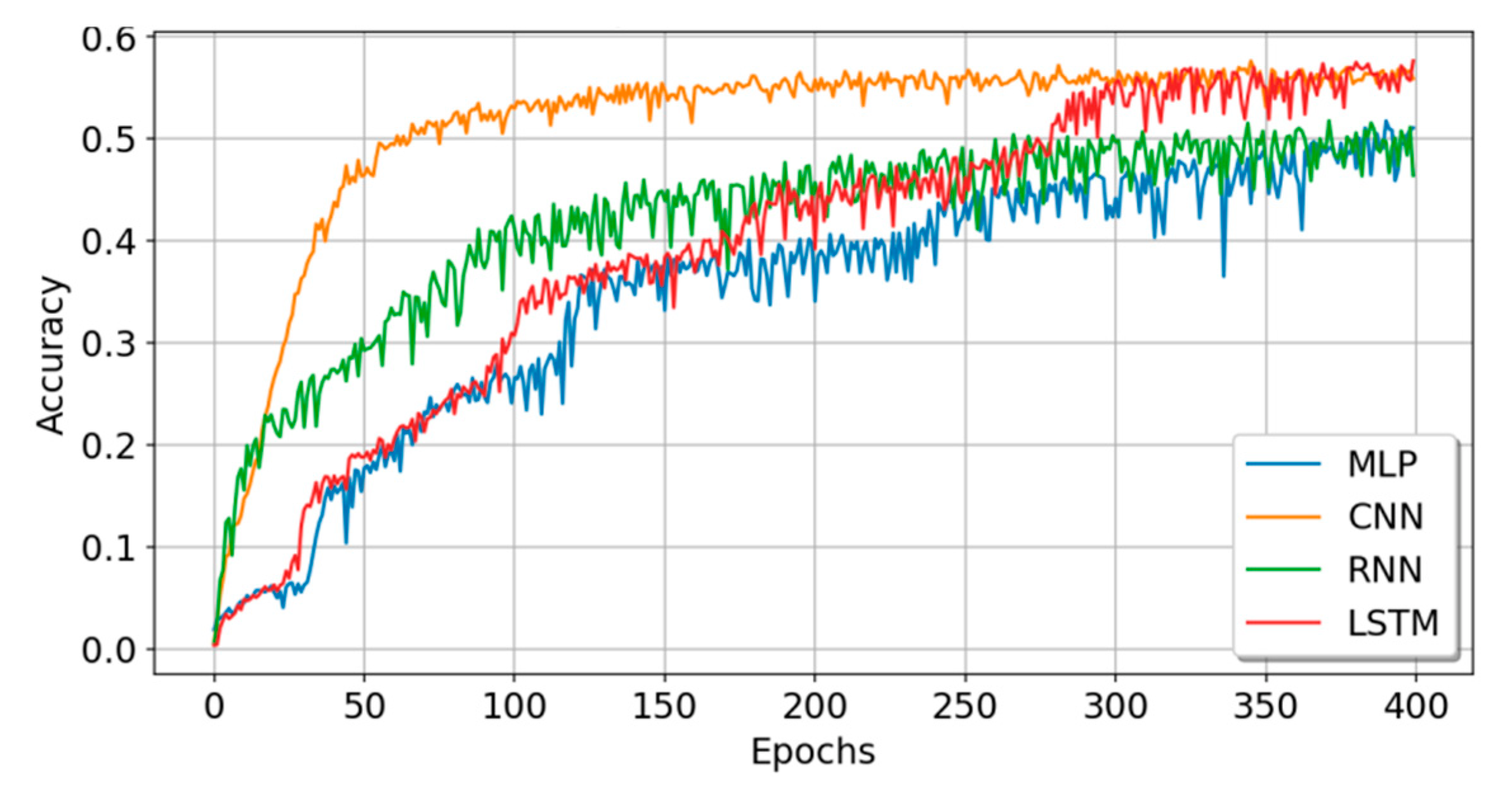
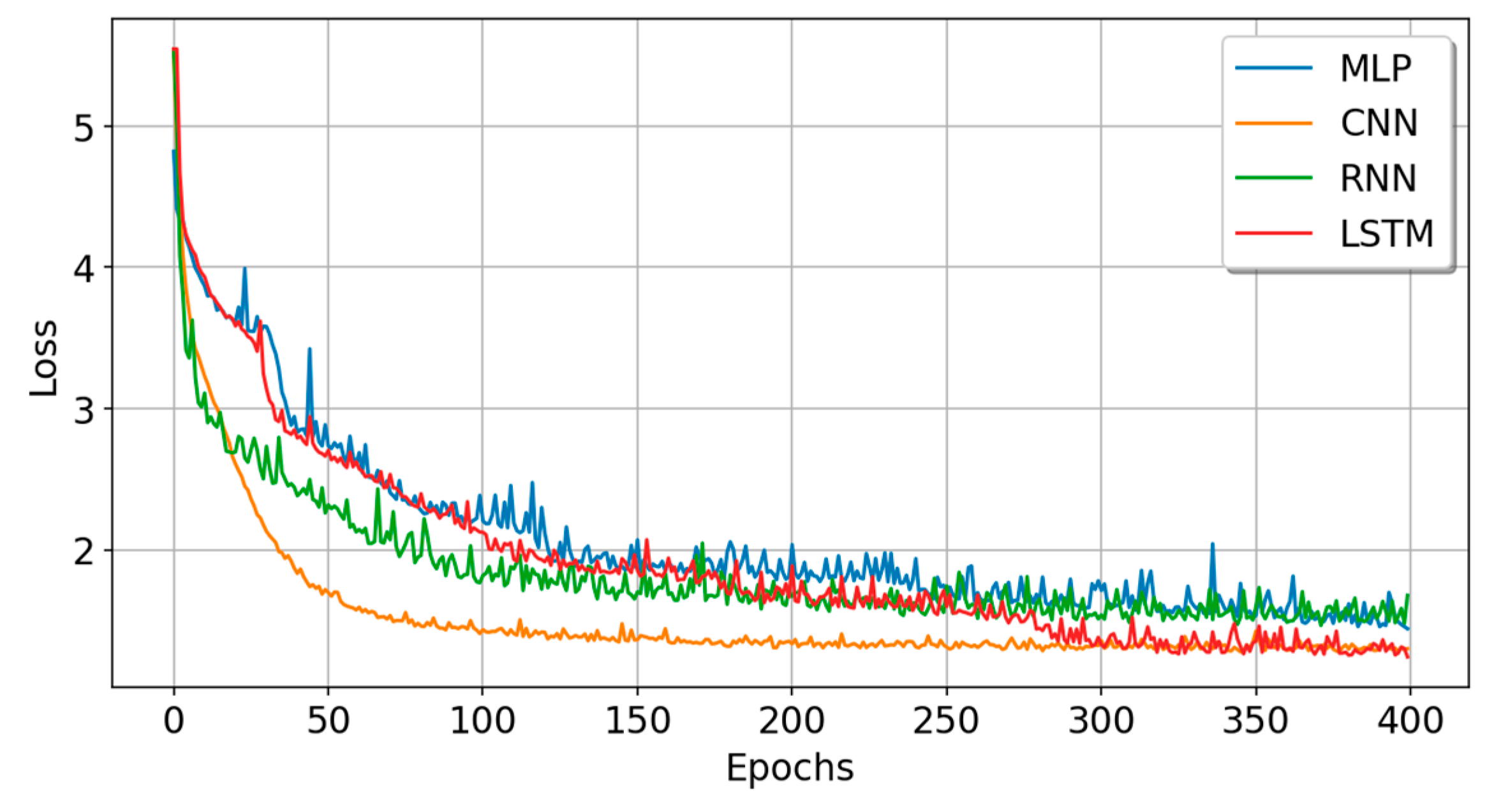
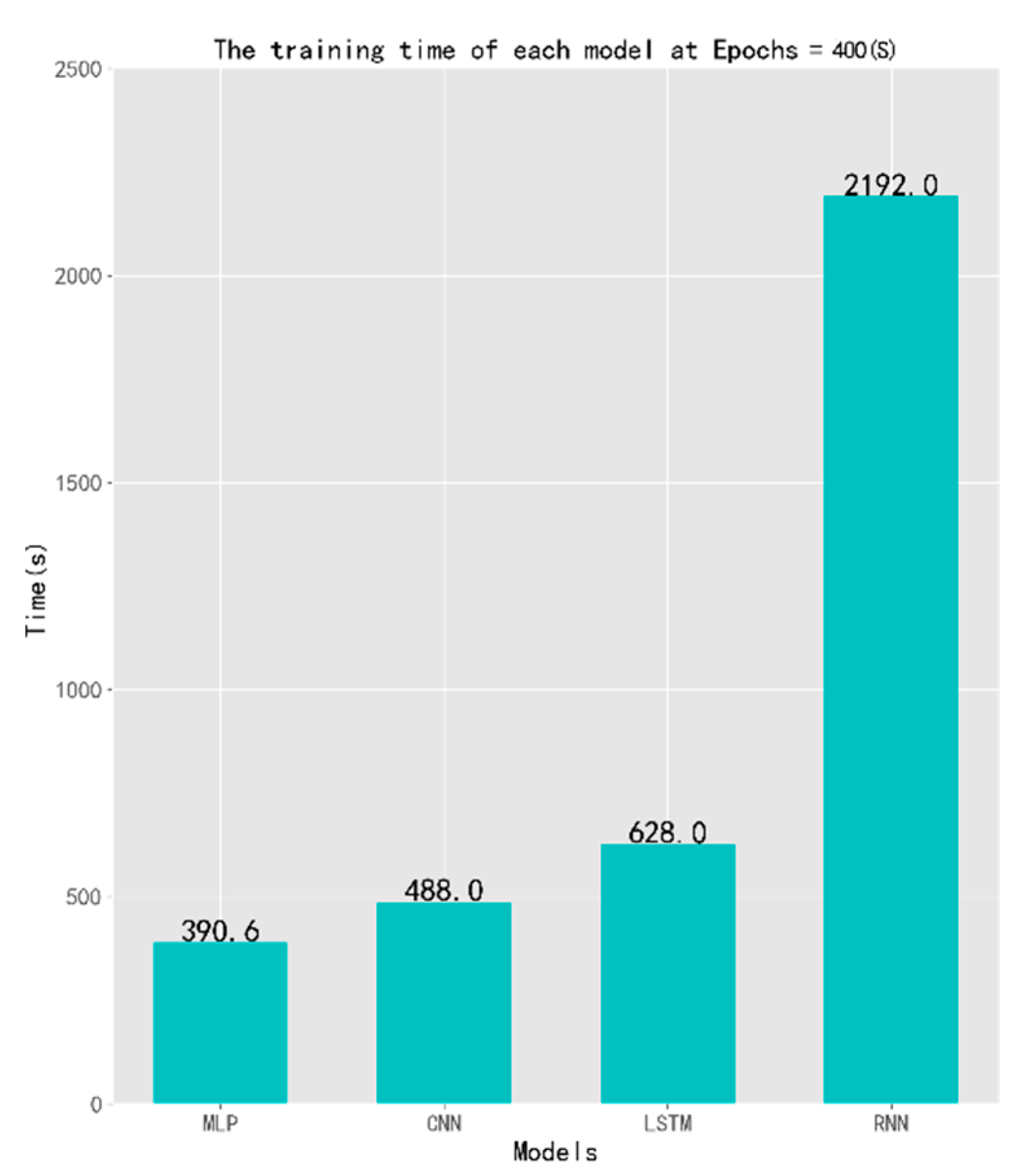
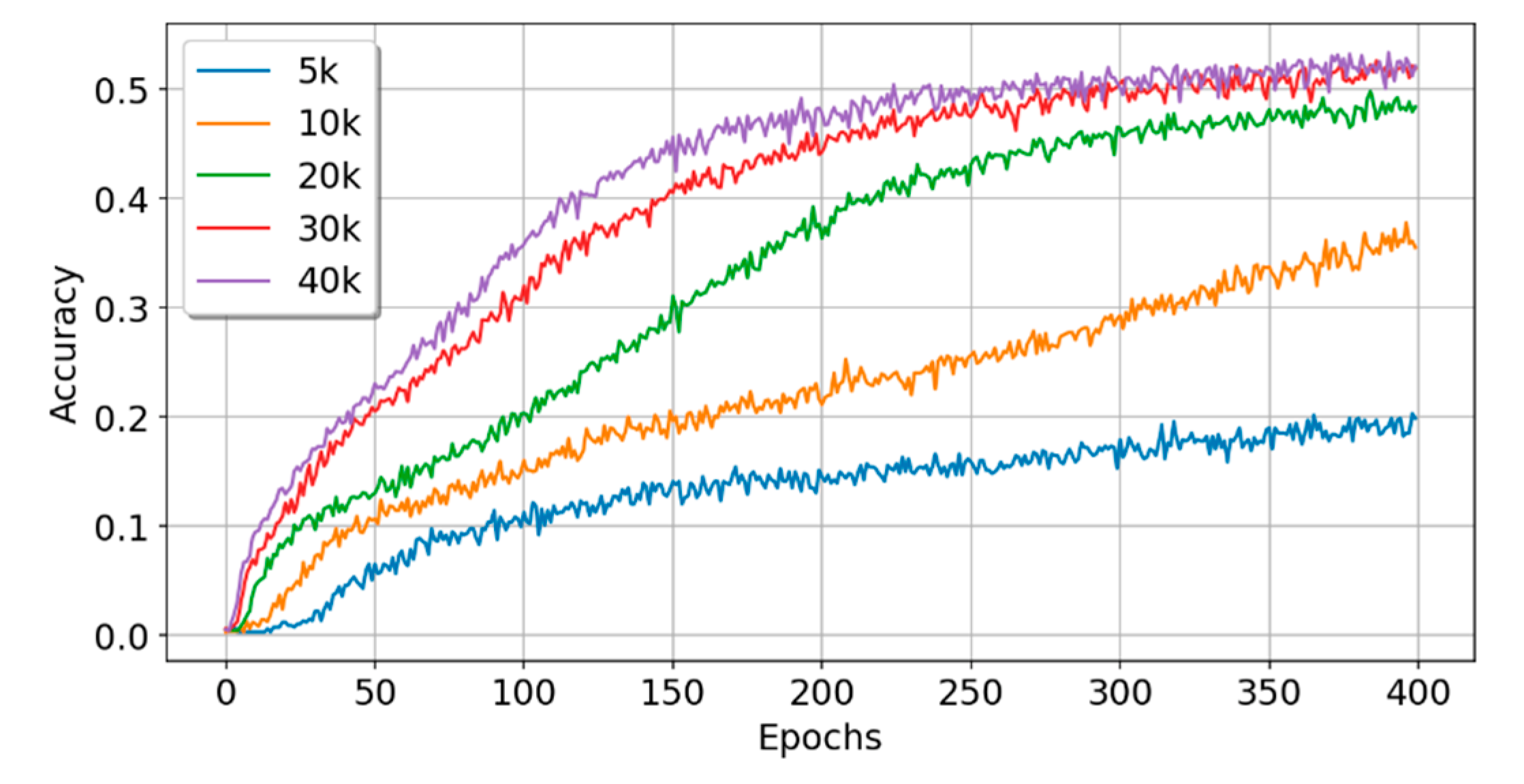
5.2. Experiment B: Sufficient Sample Data Experiment
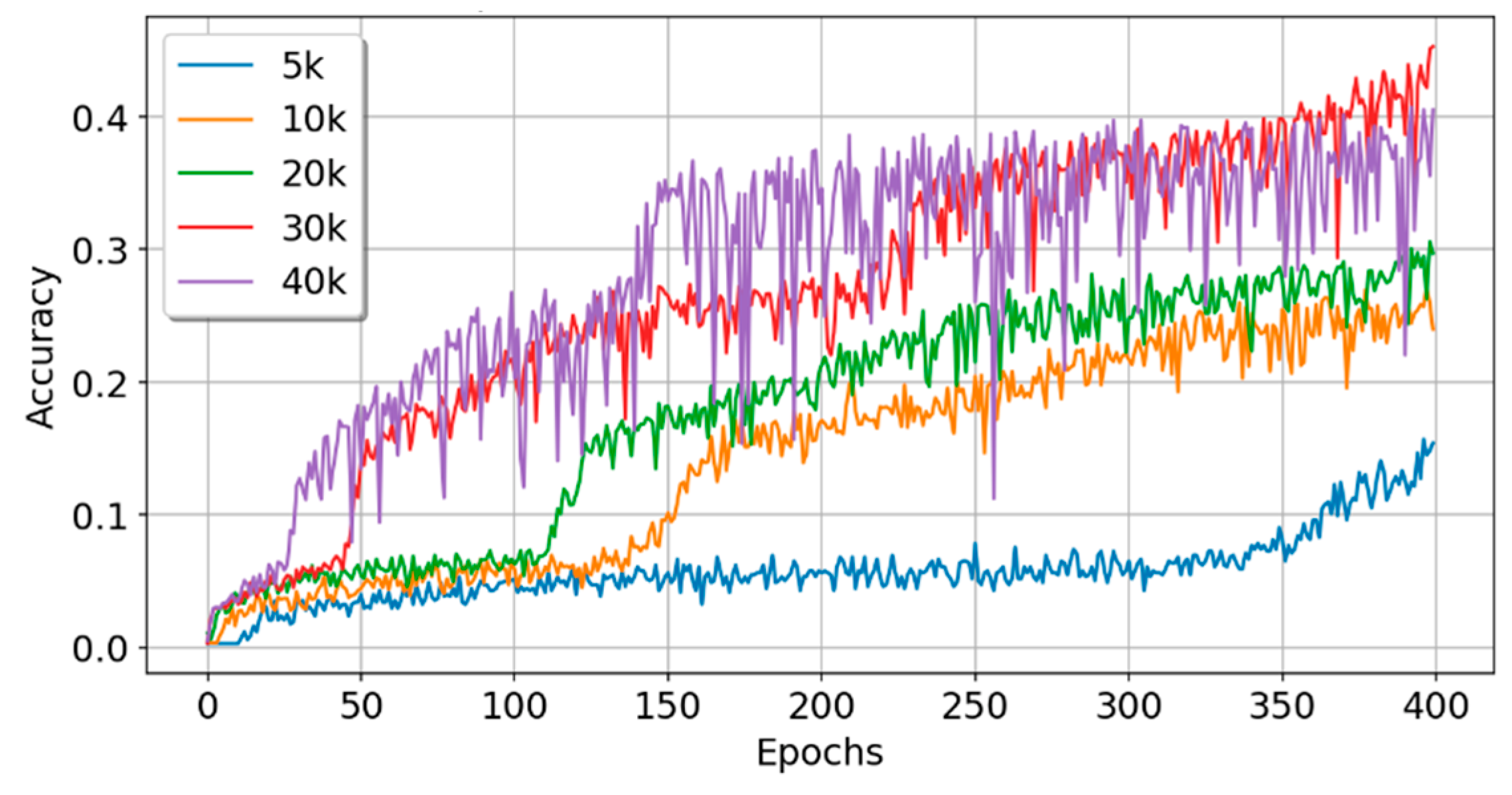
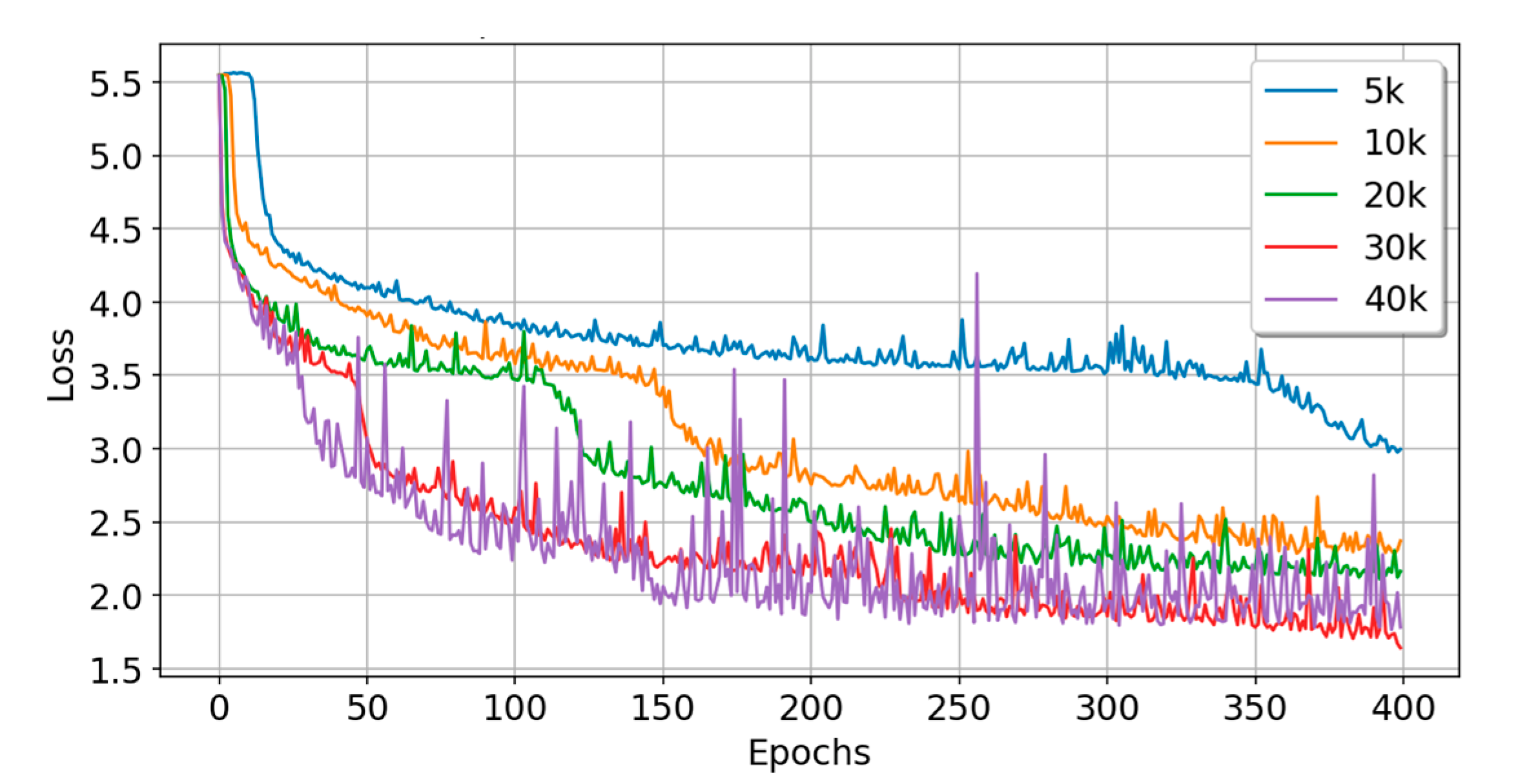
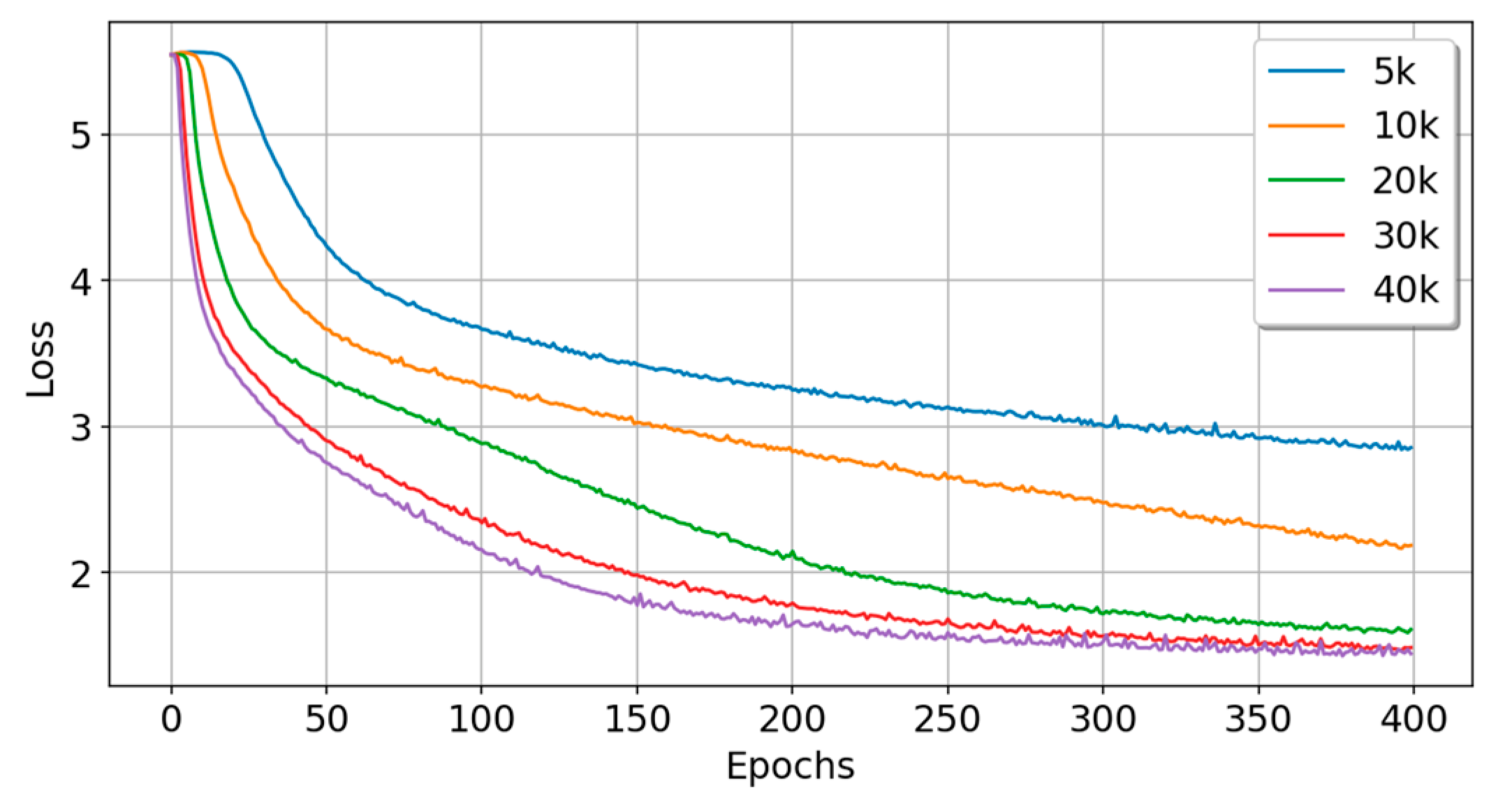
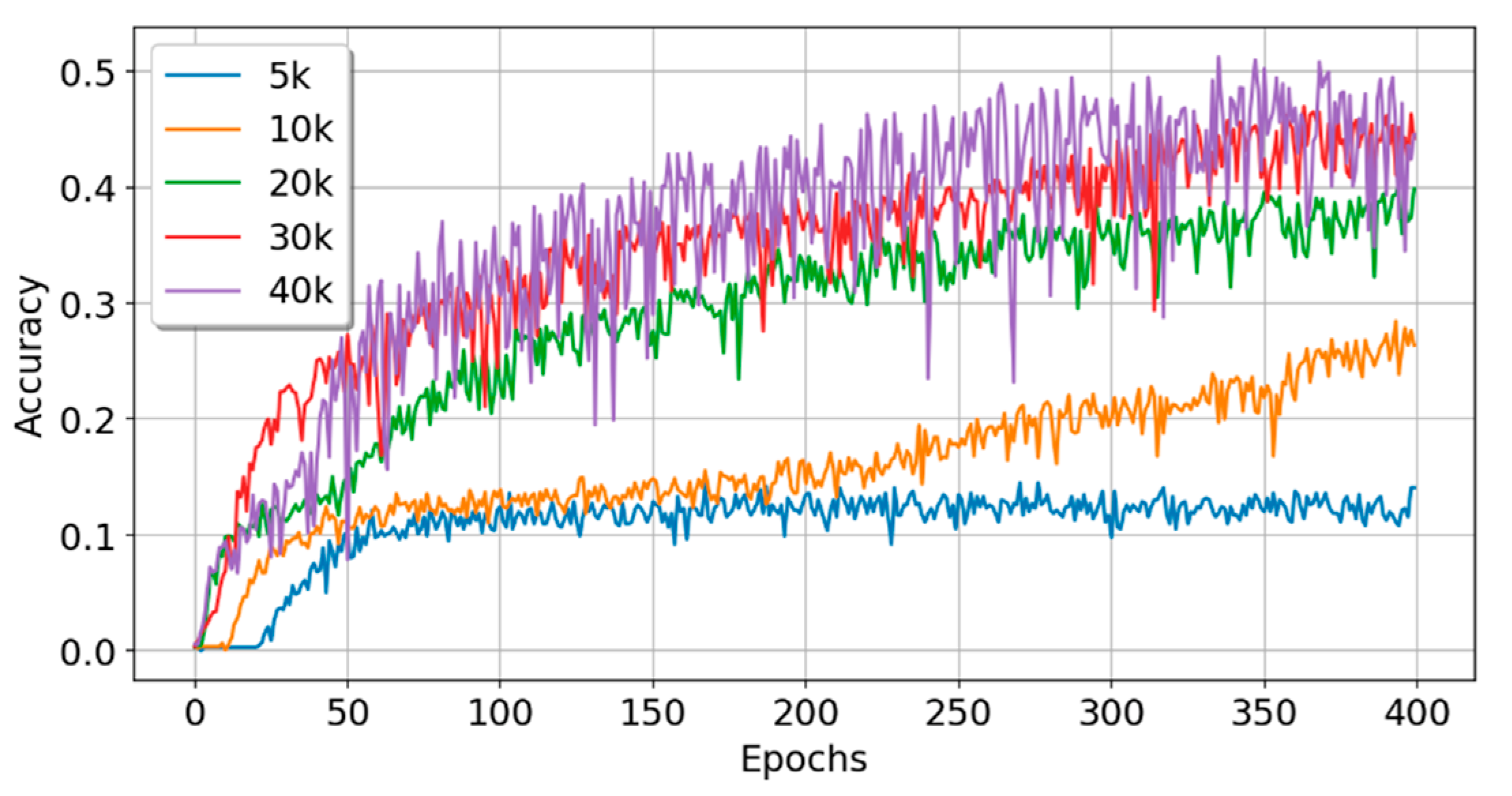
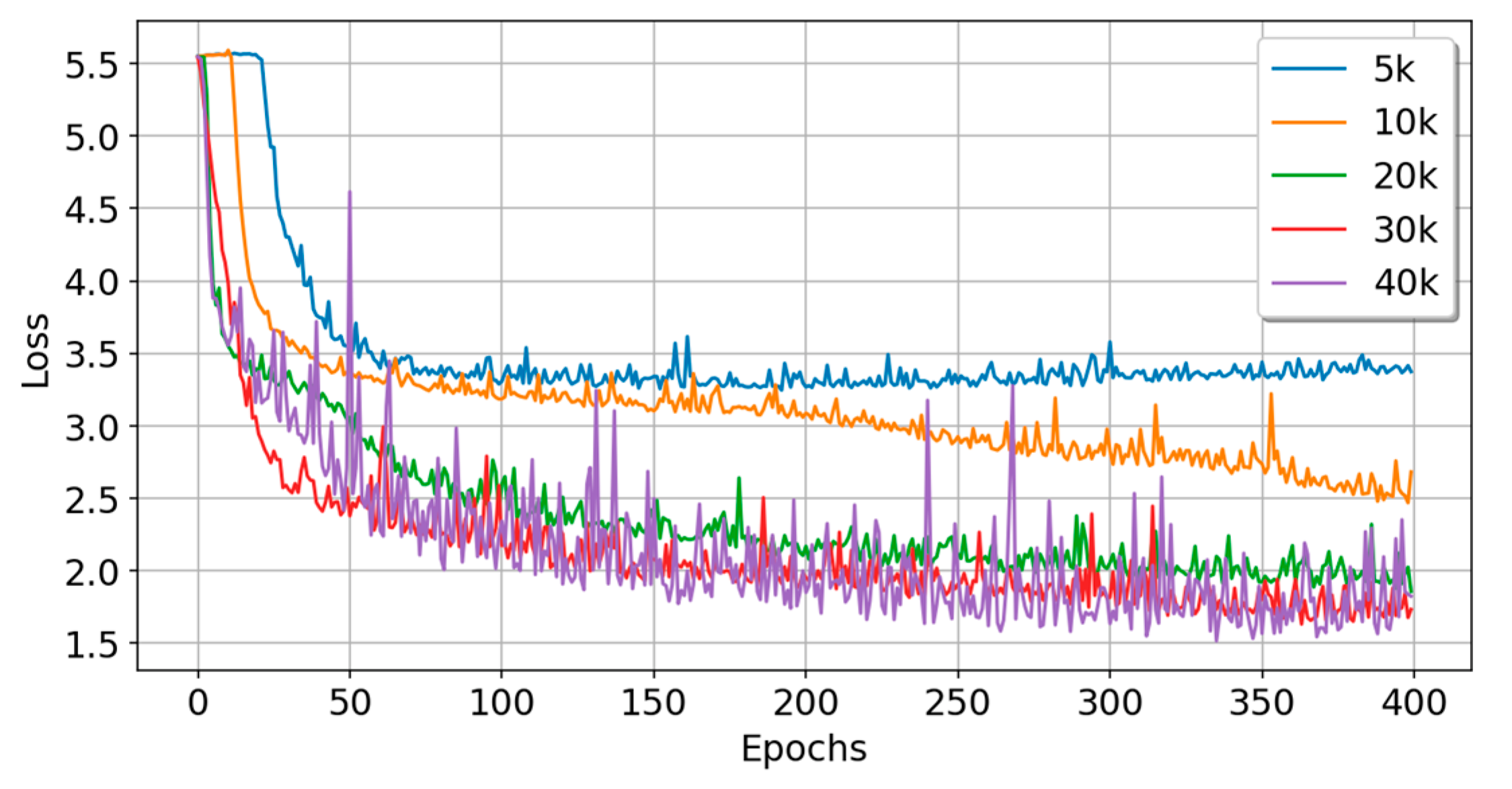
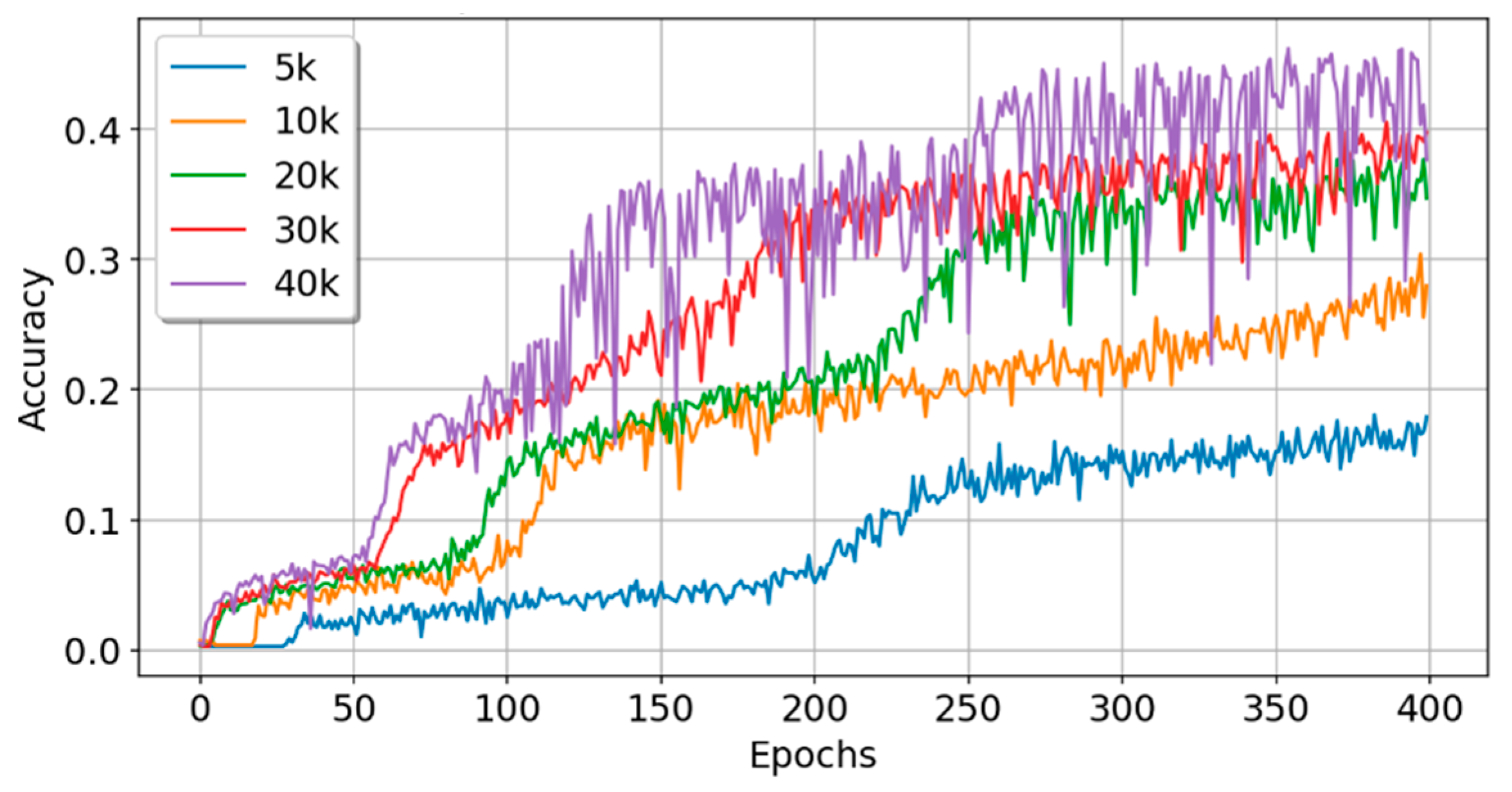
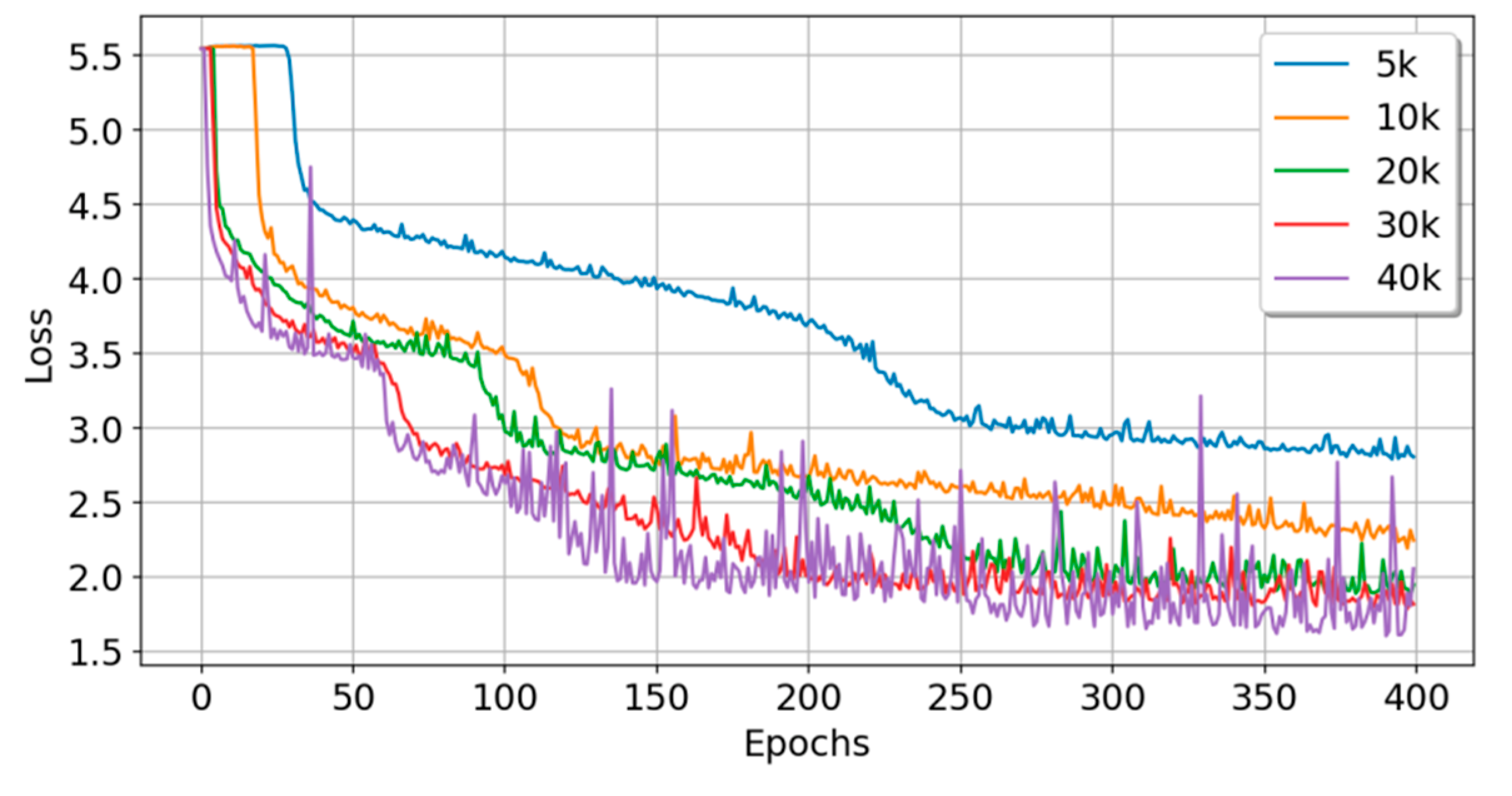
5.3. Experiment C: Experiments with Sample Data of Different Scales
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kocher, P.C. Timing attacks on implementations of Diffie-Hellman, RSA, DSS, and other systems. In Annual International Cryptology Conference; Springer: Berlin/Heidelberg, Germany, 1996; pp. 104–113. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Rokach, L.; Maimon, O.Z. Data Mining with Decision Trees: Theory and Applications; World Scientific: Hackensack, NJ, USA, 2007. [Google Scholar]
- Hospodar, G.; Gierlichs, B.; Mulder, E.D.; Verbauwhede, I.; Vandewalle, J. Machine learning in side-channel analysis: A first study. J. Cryptogr. Eng. 2011, 1, 293–302. [Google Scholar] [CrossRef]
- Lerman, L.; Bontempi, G.; Markowitch, O. Side-Channel Attack: An Approach Based on Machine Learning; Center for Advanced Security Research Darmstadt: Darmstadt, Germany, 2011; Volume 29. [Google Scholar]
- Picek, S.; Heuser, A.; Jovic, A.; Ludwig, S.A.; Guilley, S.; Jakobovic, D.; Mentens, N. Side-channel analysis and machine learning: A practical perspective. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 4095–4102. [Google Scholar]
- Robissout, D.; Bossuet, L.; Habrard, A.; Grosso, V. Improving Deep Learning Networks for Profiled Side-channel Analysis Using Performance Improvement Techniques. ACM J. Emerg. Technol. Comput. Syst. 2021, 17, 1–30. [Google Scholar] [CrossRef]
- Timon, B. Non-profiled deep learning-based side-channel attacks with sensitivity analysis. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2019, 107–131. [Google Scholar] [CrossRef]
- Kocher, P.; Jaffe, J.; Jun, B. Differential power analysis. In Annual International Cryptology Conference; Springer: Berlin/Heidelberg, Germany, 1999; pp. 388–397. [Google Scholar]
- Brier, E.; Clavier, C.; Olivier, F. Correlation power analysis with a leakage model. In International Workshop on Cryptographic Hardware and Embedded Systems; Springer: Berlin/Heidelberg, Germany, 2004; pp. 16–29. [Google Scholar]
- Gierlichs, B.; Batina, L.; Tuyls, P.; Preneel, B. Mutual information analysis. In International Workshop on Cryptographic Hardware and Embedded Systems; Springer: Berlin/Heidelberg, Germany, 2008; pp. 426–442. [Google Scholar]
- Chari, S.; Rao, J.R.; Rohatgi, P. Template attacks. In International Workshop on Cryptographic Hardware and Embedded Systems; Springer: Berlin/Heidelberg, Germany, 2002; pp. 13–28. [Google Scholar]
- Schindler, W.; Lemke, K.; Paar, C. A stochastic model for differential side channel cryptanalysis. In International Workshop on Cryptographic Hardware and Embedded Systems; Springer: Berlin/Heidelberg, Germany, 2005; pp. 30–46. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Maghrebi, H.; Portigliatti, T.; Prouff, E. Breaking cryptographic implementations using deep learning techniques. In International Conference on Security, Privacy, and Applied Cryptography Engineering; Springer: Cham, Switzerland, 2016; pp. 3–26. [Google Scholar]
- Benadjila, R.; Prouff, E.; Strullu, R.; Cagli, E.; Dumas, C. Deep learning for side-channel analysis and introduction to ASCAD database. J. Cryptogr. Eng. 2020, 10, 163–188. [Google Scholar] [CrossRef]
- Wang, H.; Forsmark, S.; Brisfors, M.; Dubrova, E. Multi-Source Training Deep-Learning Side-Channel Attacks. In Proceedings of the 2020 IEEE 50th International Symposium on Multiple-Valued Logic (ISMVL), Miyazaki, Japan, 9–11 November 2020; pp. 58–63. [Google Scholar]
- Masure, L.; Dumas, C.; Prouff, E. A comprehensive study of deep learning for side-channel analysis. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2020, 348–375. [Google Scholar] [CrossRef]
- Wang, J.; Wang, W.; Yu, W.; Hu, F. Side-channel attack based on dendritic network. J. Xiangtan Univ. Nat. Sci. Ed. 2021, 43, 16–30. [Google Scholar]
- Ou, Y.; Li, L. Side-channel analysis attacks based on deep learning network. Front. Comput. Sci. 2022, 16, 162303. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, Z.; Ling, M. Side-channel Attack Using Word Embedding and Long Short Term Memories. J. Web Eng. 2022, 21, 285–306. [Google Scholar] [CrossRef]
- Hu, F.; Wang, H.; Wang, J. Cross subkey side channel analysis based on small samples. Sci. Rep. 2022, 12, 6254. [Google Scholar] [CrossRef] [PubMed]
- O’Flynn, C.; Chen, Z.D. Chipwhisperer: An open-source platform for hardware embedded security research. In International Workshop on Constructive Side-Channel Analysis and Secure Design; Springer: Cham, Switzerland, 2014; pp. 243–260. [Google Scholar]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press: Oxford, UK, 1996. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 25, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A critical review of recurrent neural networks for sequence learning. arXiv 2015, arXiv:1506.00019. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef] [PubMed]
- Daemen, J.; Rijmen, V. The Design of Rijndael; Springer: New York, NY, USA, 2002. [Google Scholar]
- Mangard, S.; Oswald, E.; Popp, T. Power Analysis Attacks: Revealing the Secrets of Smart Cards; Springer: Heidelberg, Germany, 2007. [Google Scholar]
- Gulli, A.; Pal, S. Deep Learning with Keras; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Optimizer | Learning_Rate | Mini_Batch | Epochs |
|---|---|---|---|---|
| MLP | Adam | 0.0005 | 128 | 400 |
| CNN | Adam | 0.0005 | 128 | 400 |
| RNN | Adam | 0.0005 | 128 | 400 |
| LSTM | Adam | 0.0005 | 128 | 400 |
| Model | Train_Acc | Train_Loss | Test_Acc | Test_Loss | Time (s) | Param# | Rank |
|---|---|---|---|---|---|---|---|
| MLP | 0.1399 | 3.0573 | 0.1180 | 3.1467 | 26.6 | 250,336 | 3 |
| CNN | 0.1438 | 3.4043 | 0.0940 | 3.6542 | 26.8 | 269,484 | 2 |
| RNN | 0.2471 | 2.5843 | 0.1300 | 3.4500 | 139.3 | 84,616 | 3 |
| LSTM | 0.0676 | 3.6082 | 0.0600 | 3.8582 | 40.3 | 106,996 | 4 |
| Model | Train_Acc | Train_Loss | Test_Acc | Test_Loss | Time (s) | Param# | Rank |
|---|---|---|---|---|---|---|---|
| MLP | 0.4944 | 1.4880 | 0.5084 | 1.4599 | 390.6 | 250,336 | 2 |
| CNN | 0.5745 | 1.2589 | 0.5496 | 1.3214 | 488.0 | 269,484 | 2 |
| RNN | 0.5128 | 1.4618 | 0.4550 | 1.6926 | 2192.0 | 84,616 | 2 |
| LSTM | 0.5666 | 1.2700 | 0.5680 | 1.2813 | 628.0 | 106,996 | 2 |
| Data Size | Train_Acc | Train_Loss | Test_Acc | Test_Loss | Time (s) | Param# | Rank |
|---|---|---|---|---|---|---|---|
| 5k | 0.1358 | 3.0848 | 0.1480 | 2.9956 | 40.1 | 250,336 | 2 |
| 10k | 0.2606 | 2.2648 | 0.2470 | 2.3530 | 81.7 | 250,336 | 3 |
| 20k | 0.2884 | 2.1439 | 0.3055 | 2.1393 | 156.7 | 250,336 | 2 |
| 30k | 0.4164 | 1.7370 | 0.4350 | 1.6421 | 236.6 | 250,336 | 2 |
| 40k | 0.4023 | 1.7705 | 0.4145 | 1.7597 | 312.1 | 250,336 | 2 |
| Data Size | Train_Acc | Train_Loss | Test_Acc | Test_Loss | Time (s) | Param# | Rank |
|---|---|---|---|---|---|---|---|
| 5k | 0.3045 | 2.4804 | 0.2180 | 2.8696 | 45.9 | 269,484 | 2 |
| 10k | 0.3826 | 2.1234 | 0.3450 | 2.2371 | 84.0 | 269,484 | 2 |
| 20k | 0.5258 | 1.4856 | 0.4820 | 1.6300 | 163.8 | 269,484 | 2 |
| 30k | 0.5352 | 1.4234 | 0.5133 | 1.4520 | 247.8 | 269,484 | 2 |
| 40k | 0.5441 | 1.3806 | 0.5265 | 1.4232 | 328.5 | 269,484 | 2 |
| Data Size | Train_Acc | Train_Loss | Test_Acc | Test_Loss | Time (s) | Param# | Rank |
|---|---|---|---|---|---|---|---|
| 5k | 0.2025 | 2.7272 | 0.1100 | 3.5471 | 238.0 | 84,616 | 3 |
| 10k | 0.2809 | 2.3556 | 0.2350 | 2.7587 | 464.7 | 84,616 | 2 |
| 20k | 0.4281 | 1.7523 | 0.4105 | 1.8600 | 927.3 | 84,616 | 2 |
| 30k | 0.4818 | 1.5794 | 0.4390 | 1.7173 | 1410.2 | 84,616 | 2 |
| 40k | 0.5237 | 1.4271 | 0.4265 | 1.8233 | 1895.4 | 84,616 | 2 |
| Data Size | Train_Acc | Train_Loss | Test_Acc | Test_Loss | Time (s) | Param# | Rank |
|---|---|---|---|---|---|---|---|
| 5k | 0.1932 | 2.6546 | 0.1780 | 2.8335 | 68.0 | 106,996 | 3 |
| 10k | 0.2820 | 2.2234 | 0.2770 | 2.2410 | 128.0 | 106,996 | 2 |
| 20k | 0.3826 | 1.8559 | 0.3695 | 1.9201 | 255.0 | 106,996 | 3 |
| 30k | 0.3954 | 1.7949 | 0.3863 | 1.8032 | 386.0 | 106,996 | 2 |
| 40k | 0.4671 | 1.5768 | 0.3718 | 2.0258 | 511.2 | 106,996 | 2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, L.; Wei, Y.; He, S.; Pan, X. Research on Side-Channel Analysis Based on Deep Learning with Different Sample Data. Appl. Sci. 2022, 12, 8246. https://doi.org/10.3390/app12168246
Chang L, Wei Y, He S, Pan X. Research on Side-Channel Analysis Based on Deep Learning with Different Sample Data. Applied Sciences. 2022; 12(16):8246. https://doi.org/10.3390/app12168246
Chicago/Turabian StyleChang, Lipeng, Yuechuan Wei, Shuiyu He, and Xiaozhong Pan. 2022. "Research on Side-Channel Analysis Based on Deep Learning with Different Sample Data" Applied Sciences 12, no. 16: 8246. https://doi.org/10.3390/app12168246